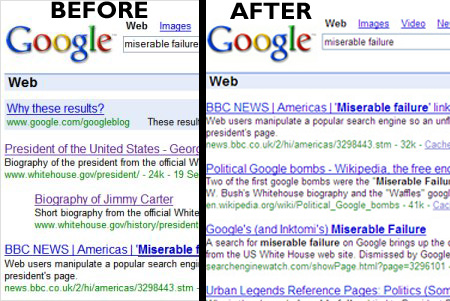
... > detto in altri termini, il dato e' solo quello codificato "non lossy" e > inserito in un > record di un DB relazionale o anche quello codificato "lossy" e sparso in una > matrice ? A proposito del dato "lossy" sparso in una matrice mi viene in mente il "google bombing" [1]. Chi è su Internet da più di ventanni se lo ricorderà sicuramente, cercavi "miserable failure" e ti veniva fuori la biografia di George Bush [2]. Mutatis mutandis, cosa succederebbe se un ingegnere (buontempone) di OpenAI immettesse, assieme a miliardi di altre frasi, anche un milione di "tizio è gay" (dato personale /sensibile/ in quanto relativo alla vita sessuale di una persona)? Una volta /processato/ il dato di partenza potrebbe anche essere cancellato, ma alla richiesta di un ignaro utente: "chi è tizio?", la risposta sarebbe una sola. E ancora, dato che i dati delle conversazioni "rientrano in circolo" per produrre altri modelli, mettiamo il caso che, invece del programmatore di OpenAI, quella frase venisse scritta da mille utenti, mille volte ciascuno. Si otterrebbe lo stesso risultato, insomma un "gpt bombing".
Antonio [1] https://it.wikipedia.org/wiki/Google_bombing [2] https://searchengineland.com/wp-content/seloads/2012/10/369539947_e3f05b50e5_o.jpg _______________________________________________ nexa mailing list nexa@server-nexa.polito.it https://server-nexa.polito.it/cgi-bin/mailman/listinfo/nexa
{kind=link}