On 06/18/2014 05:58 AM, Paul E. McKenney wrote:
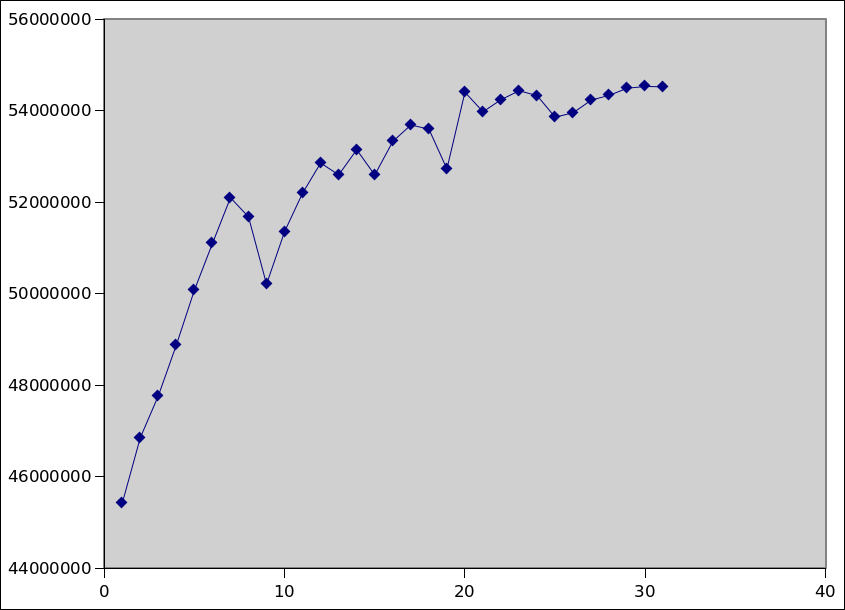
>> > This is the previous kernel, plus RCU tracing, so it's not 100%
>> > apples-to-apples (and it peaks a bit lower than the other kernel). But
>> > here's the will-it-scale open1 throughput on the y axis vs
>> > RCU_COND_RESCHED_EVERY_THIS_JIFFIES on x:
>> >
>> > http://sr71.net/~dave/intel/jiffies-vs-openops.png
>> >
>> > This was a quick and dirty single run with very little averaging, so I
>> > expect there to be a good amount of noise. I ran it from 1->100, but it
>> > seemed to peak at about 30.
> OK, so a default setting on the order of 20-30 jiffies looks promising.
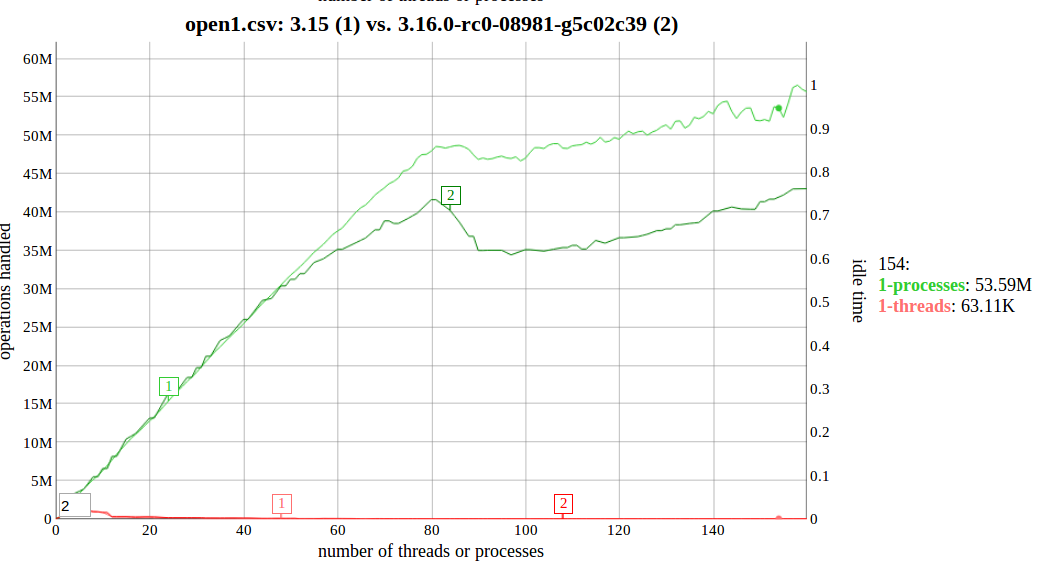
For the biggest machine I have today, yeah. But, we need to be a bit
careful here. The CPUs I'm running it on were released 3 years ago and
I think we need to be planning at _least_ for today's large systems. I
would guess that by raising ...EVERY_THIS_JIFFIES, we're shifting this
curve out to the right:
http://sr71.net/~dave/intel/3.16-open1regression-0.png
so that we're _just_ before the regression hits us. But that just
guarantees I'll hit this again when I get new CPUs. :)
If we go this route, I think we should probably take it up in to the
100-200 range, or even scale it to something on the order of what the
rcu stall timeout is. Other than the stall detector, is there some
other reason to be forcing frequent quiescent states?
--
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to [email protected]
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
{kind=link}
{kind=link}