On Tue, Jun 17, 2014 at 11:33:56PM -0700, Dave Hansen wrote:
> On 06/17/2014 05:18 PM, Paul E. McKenney wrote:
> > So if I understand correctly, a goodly part of the regression is due not
> > to the overhead added to cond_resched(), but rather because grace periods
> > are now happening faster, thus incurring more overhead. Is that correct?
>
> Yes, that's the theory at least.
>
> > If this is the case, could you please let me know roughly how sensitive is
> > the performance to the time delay in RCU_COND_RESCHED_EVERY_THIS_JIFFIES?
>
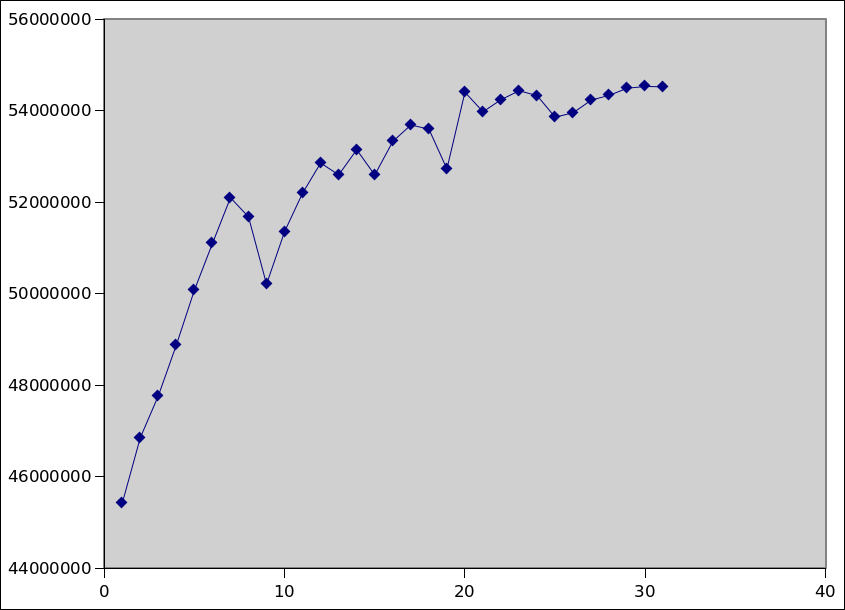
> This is the previous kernel, plus RCU tracing, so it's not 100%
> apples-to-apples (and it peaks a bit lower than the other kernel). But
> here's the will-it-scale open1 throughput on the y axis vs
> RCU_COND_RESCHED_EVERY_THIS_JIFFIES on x:
>
> http://sr71.net/~dave/intel/jiffies-vs-openops.png
>
> This was a quick and dirty single run with very little averaging, so I
> expect there to be a good amount of noise. I ran it from 1->100, but it
> seemed to peak at about 30.
OK, so a default setting on the order of 20-30 jiffies looks promising.
> > The patch looks promising. I will probably drive the time-setup deeper
> > into the guts of RCU, which should allow moving the access to jiffies
> > and the comparison off of the fast path as well, but this appears to
> > me to be good and sufficient for others encountering this same problem
> > in the meantime.
>
> Yeah, the more overhead we can push out of cond_resched(), the better.
> I had no idea how much we call it!
Me neither!
Thanx, Paul
--
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to [email protected]
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
{kind=link}