kirktrue opened a new pull request, #18795: URL: https://github.com/apache/kafka/pull/18795
This change reduces fetch session cache evictions on the broker for `AsyncKafkaConsumer` by altering its logic to determine which partitions it includes in fetch requests. # Background `Consumer` implementations fetch data from the cluster and temporarily buffer it in memory until the user next calls `Consumer.poll()`. When a fetch request is being generated, partitions that already have buffered data are not included in the fetch request. The `ClassicKafkaConsumer` performs much of its fetch logic and network I/O in the application thread. On `poll()`, if there is any locally-buffered data, the `ClassicKafkaConsumer` does not fetch _any_ new data and simply returns the buffered data to the user from `poll()`. On the other hand, the `AsyncKafkaConsumer` consumer splits its logic and network I/O between two threads, which results in a potential race condition during fetch. The `AsyncKafkaConsumer` also checks for buffered data on its application thread. If it finds there is none, it signals the background thread to create a fetch request. However, it's possible for the background thread to receive data from a previous fetch and buffer it before the fetch request logic starts. When that occurs, as the background thread creates a new fetch request, it skips any buffered data, which has the unintended result that those partitions get added to the fetch request's "to remove" set. This signals to the broker to remove those partitions from its internal cache. This issue is technically possible in the `ClassicKafkaConsumer` too, since the heartbeat thread performs network I/O in addition to the application thread. However, because of the frequency at which the `AsyncKafkaConsumer`'s background thread runs, it is ~100x more likely to happen. # Options The core decision is: what should the background thread do if it is asked to create a fetch request and it discovers there's buffered data. There were multiple proposals to address this issue in the `AsyncKafkaConsumer`. Among them are: 1. The background thread should omit buffered partitions from the fetch request as before (this is the existing behavior) 2. The background thread should skip the fetch request generation entirely if there are *any* buffered partitions 3. The background thread should include buffered partitions in the fetch request, but use a small “max bytes” value 4. The background thread should skip fetching from the nodes that have buffered partitions Option 4 won out. The change is localized to `AbstractFetch` where the basic idea is to skip fetch requests to a given node if that node is the leader for buffered data. By preventing a fetch request from being sent to that node, it won't have any "holes" where the buffered partitions should be. # Testing ## Eviction rate testing Here are the results of our internal stress testing: - `ClassicKafkaConsumer`—after the initial spike during test start up, the average rate settles down to ~0.14 evictions/second 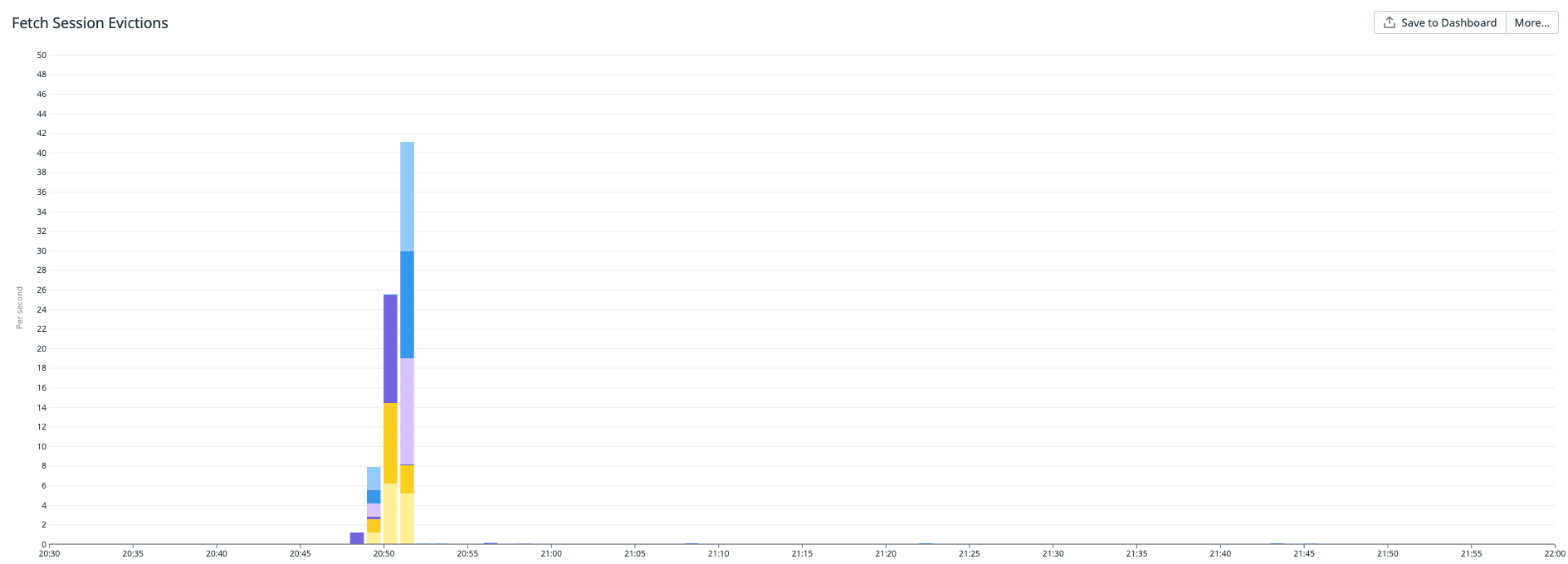 - `AsyncKafkaConsumer`, (w/o fix)—after startup, the evictions still settle down, but they are about 100x higher than the `ClassicKafkaConsumer` at ~1.48 evictions/second  - `AsyncKafkaConsumer` (w/ fix)—the eviction rate is now closer to the `ClassicKafkaConsumer` at ~0.22 evictions/second 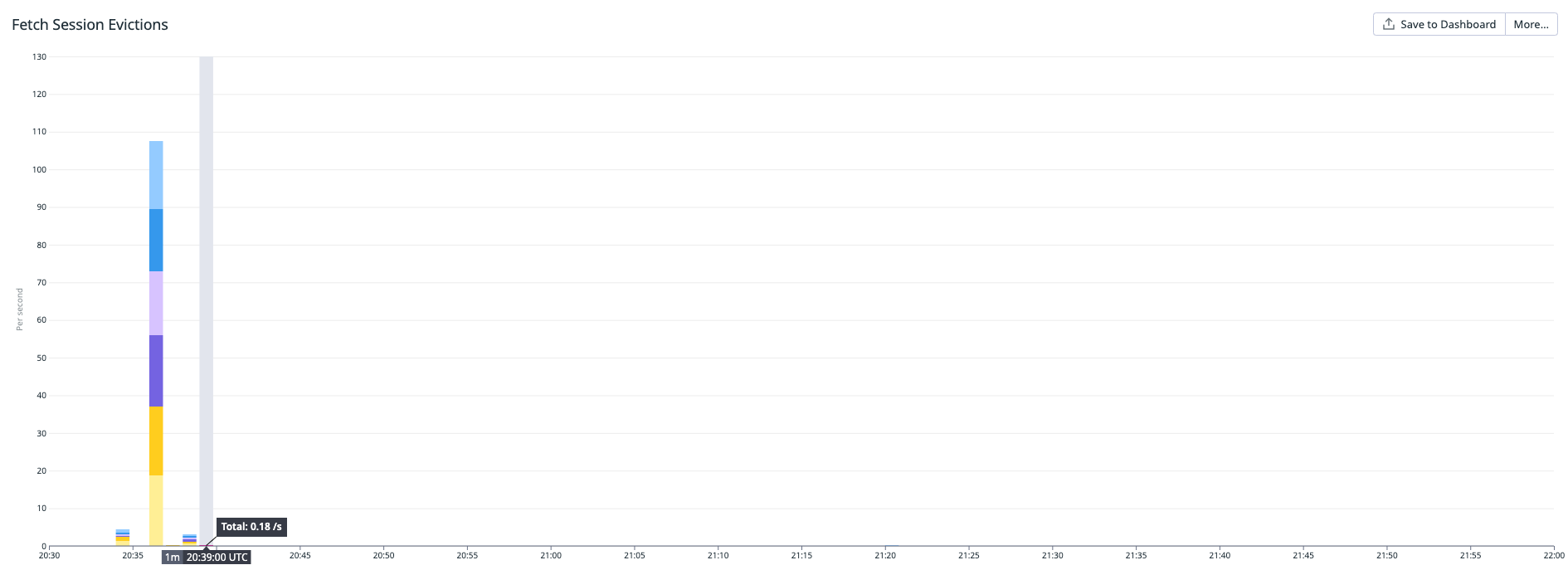 ## `EndToEndLatency` testing The bundled `EndToEndLatency` test runner was executed on a single machine using Docker. The `apache/kafka:latest` Docker image was used and either the `cluster/combined/plaintext/docker-compose.yml` or `single-node/plaintext/docker-compose.yml` Docker Compose configuration files, depending on the test. The Docker containers were recreated from scratch before each test. A single topic was created with 30 partitions and with a replication factor of either 1 or 3, depending on a single- or multi-node setup. For each of the test runs these argument values were used: - Message count: 100000 - `acks`: 1 - Message size: 128 bytes A configuration file which contained a single configuration value of `group.protocol=<$group_protocol>` was also provided to the test, where `$group_protocol` was either `CLASSIC` or `CONSUMER`. ### Test results #### Test 1—`CLASSIC` group protocol, cluster size: 3 nodes, replication factor: 3 | Metric | `trunk` | PR | |-------------------|---------|--------| | Average latency | 1.4901 | 1.4871 | | 50th percentile | 1 | 1 | | 99th percentile | 3 | 3 | | 99.9th percentile | 6 | 6 | #### Test 2—`CONSUMER` group protocol, cluster size: 3 nodes, replication factor: 3 | Metric | `trunk` | PR | |-------------------|---------|--------| | Average latency | 1.4704 | 1.4807 | | 50th percentile | 1 | 1 | | 99th percentile | 3 | 3 | | 99.9th percentile | 6 | 7 | #### Test 3—`CLASSIC` group protocol, cluster size: 1 node, replication factor: 1 | Metric | `trunk` | PR | |-------------------|---------|--------| | Average latency | 1.0777 | 1.0193 | | 50th percentile | 1 | 1 | | 99th percentile | 2 | 2 | | 99.9th percentile | 5 | 4 | #### Test 4—`CONSUMER` group protocol, cluster size: 1 node, replication factor: 1 | Metric | `trunk` | PR | |-------------------|---------|--------| | Average latency | 1.0937 | 1.0503 | | 50th percentile | 1 | 1 | | 99th percentile | 2 | 2 | | 99.9th percentile | 4 | 4 | ### Conclusion These tests did not reveal any significant differences between the current fetcher logic on `trunk` and the one proposed in this PR. Addition test runs using larger message counts and/or larger message sizes did not affect the result. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: jira-unsubscr...@kafka.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org