Hi Igor, (Apologies for not threading this, I haven't received my digest for this list yet....)
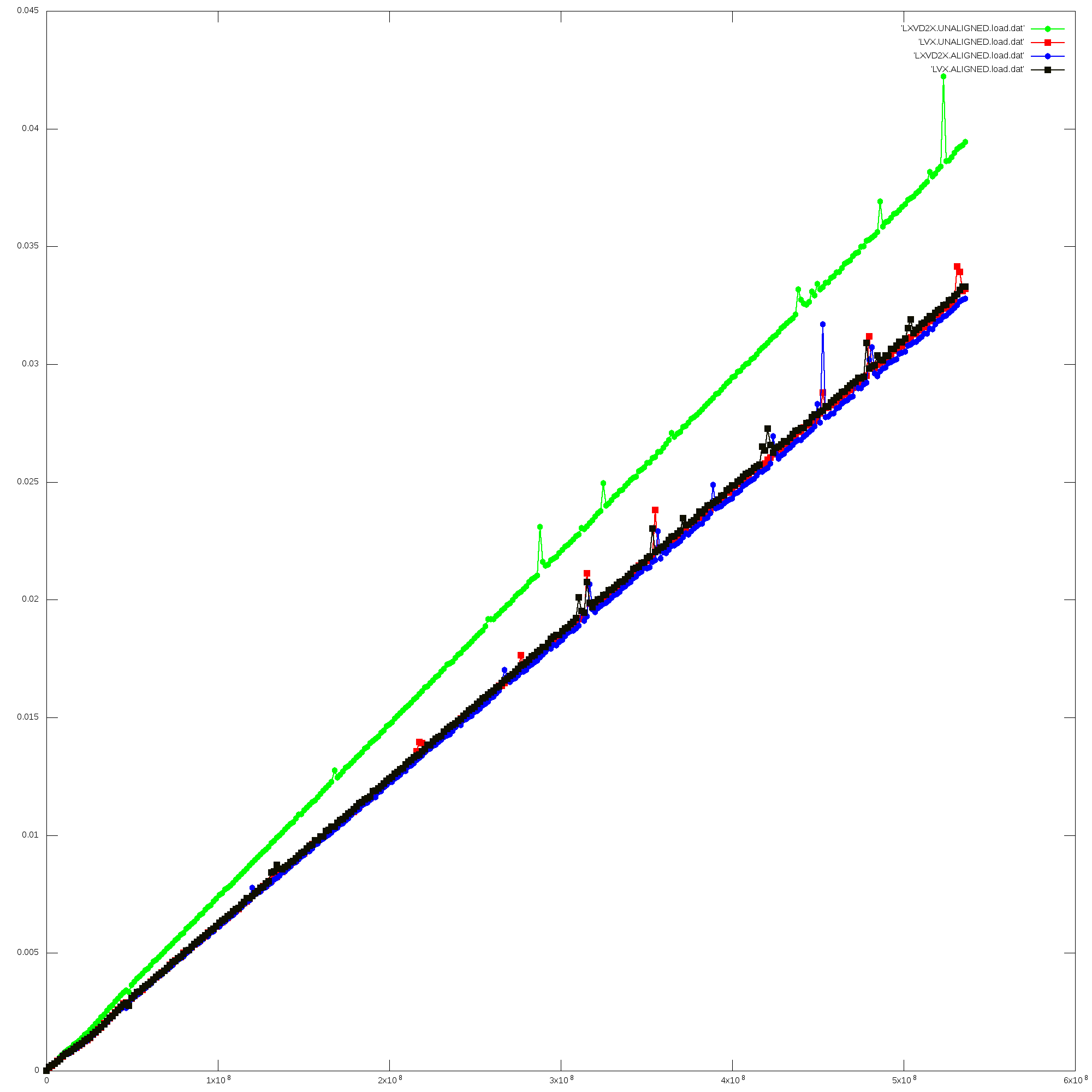
You wrote: >I recently checked this old discussion about when/why to use lxvd2x instead of >lvsl/lvx/vperm/lvx to load elements from memory to vector: >https://gcc.gnu.org/ml/gcc/2015-03/msg00135.html >I had the same doubt and I was also concerned how performance influences on >these >approaches. So that, I created the following project to check which one is >faster >and how memory alignment can influence on results: >https://github.com/PPC64/load_vec_cmp >This is a simple code, that many loads (using both approaches) are executed in >a >simple loop in order to measure which implementation is slower. The project >also >considers alignment. >As it can be seen on this plot >(https://raw.githubusercontent.com/igorsnunes/load_vec_cmp/master/doc/LoadVecCompare.png) >an unaligned load using lxvd2x takes more time. >The previous discussion (as far as I could see) addresses that lxvd2x performs >better than lvsl/lvx/vperm/lvx in all cases. Is that correct? Is my analysis >wrong? >This issue concerned me, once lxvd2x is heavily used on compiled code. One problem with your analysis is that you are forcing the use of the xxswapd following the lxvd2x. Although this is technically required for a load in isolation to place elements in the correct lanes, in practice the compiler is able to remove almost all of the xxswapd instructions during optimization. Most SIMD code does not care about which lanes are used for calculation, so long as results in memory are placed properly. For computations that do care, we can often adjust the computations to still allow the swaps to be removed. So your analysis does not show anything about how code is produced in practice. Another issue is that you're throwing away the results of the loads, which isn't a particularly useful way to measure the costs of the latencies of the instructions. Typically with the pipelined lvx implementation, you will have an lvx feeding the vperm feeding at least one use of the loaded value in each iteration of the loop, while with lxvd2x and optimization you will only have an lxvd2x feeding the use(s). The latter is easier for the scheduler to cover latencies in most cases. Finally, as a rule of thumb, these kind of "loop kernels" are really bad for predicting performance, particularly on POWER. In the upcoming POWER9 processors, the swap issue goes away entirely, as we will have true little-endian unaligned loads (the indexed-form lxvx to replace lxvd2x/ xxswapd, and the offset-form lxv to reduce register pressure). Now, you will of course see slightly worse unaligned performance for lxvd2x versus aligned performance for lxvd2x. This happens at specific crossing points where the hardware has to work a bit harder. I hate to just say "trust me" but I want you to understand that we have been looking at these kinds of performance issues for several years. This does not mean that there are no cases where the pipelined lvx solution works better for a particular loop, but if you let the compiler optimize it (or do similar optimization in your own assembly code), lxvd2x is almost always better. Thanks, Bill
{kind=link}