Hi all, I recently checked this old discussion about when/why to use lxvd2x instead of lvsl/lvx/vperm/lvx to load elements from memory to vector: https://gcc.gnu.org/ml/gcc/2015-03/msg00135.html
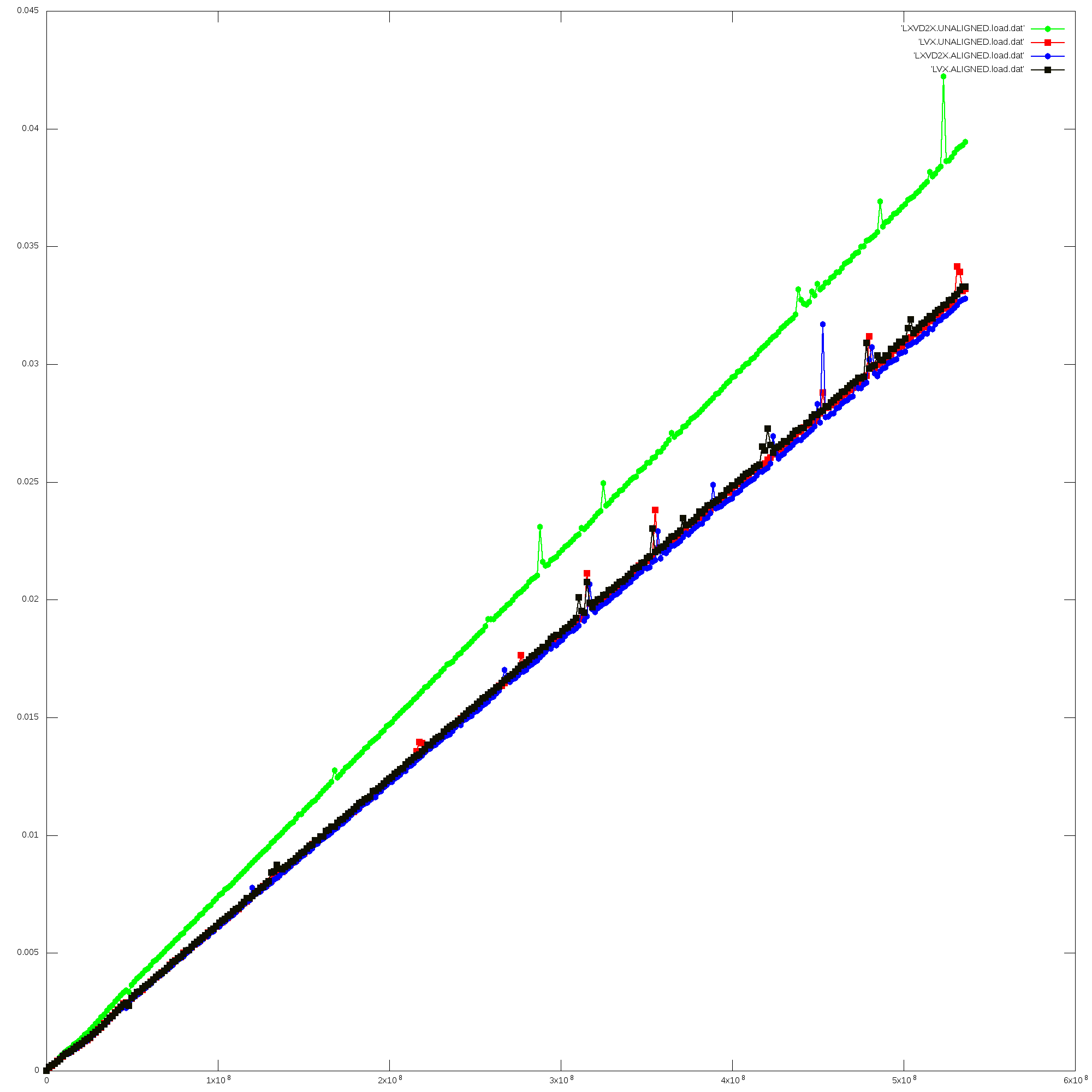
I had the same doubt and I was also concerned how performance influences on these approaches. So that, I created the following project to check which one is faster and how memory alignment can influence on results: https://github.com/PPC64/load_vec_cmp This is a simple code, that many loads (using both approaches) are executed in a simple loop in order to measure which implementation is slower. The project also considers alignment. As it can be seen on this plot (https://raw.githubusercontent.com/igorsnunes/load_vec_cmp/master/doc/LoadVecCompare.png) an unaligned load using lxvd2x takes more time. The previous discussion (as far as I could see) addresses that lxvd2x performs better than lvsl/lvx/vperm/lvx in all cases. Is that correct? Is my analysis wrong? This issue concerned me, once lxvd2x is heavily used on compiled code. Regards, Igor
{kind=link}