You're right that variable length encoded integers aren't well suited for an in-memory specification. (I thought maybe GoB wouldn't, it too makes the same choice. https://golang.org/pkg/encoding/gob/)
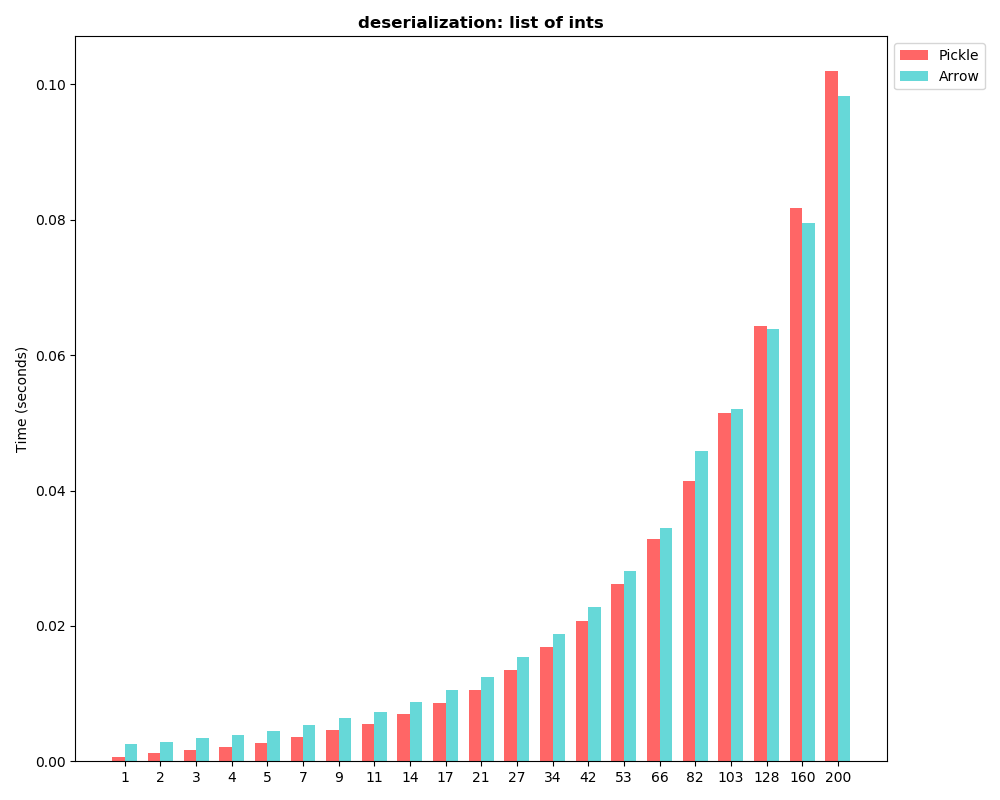
Avro files are basically impossible to parse in parallel because most fields are variable-length. I like your proposed idea to separate variable length values from fixed size, that way you can skip to the row / column you want without having to parse the whole row into a dictionary. I wonder if small batches of Arrow buffers would suit this use case just as well, though? Since there needs to be a buffer of all the variable length strings, structs, etc, you end up having to batch rows into groups anyway, right? *From: *Shawn Yang <[email protected]> *Date: *Thu, May 9, 2019 at 8:09 AM *To: * <[email protected]> Hi Wes, > Thanks for the suggestion. Avro is a good fit for record format. Its > GenericRecord can satisfy the requirement of serialization between > java/python without a schema compile ahead. > The only problem is it deserialize data to GenericRecord in java or dict in > python, which is not necessary and may incur overhead in our cases. In our > streaming data processing scenario, > filter/join/map/union happens very often. In scenario like this, we > actually only need to read one or two field, deserialize whole data to > java/python object would be unnecessary, > and can incur significant overhead. Maybe this is why spark uses > org.apache.spark.sql.catalyst.expressions.UnsafeRow and flink uses > org.apache.flink.table.dataformat.BinaryRow. > We want to implement a similar row format. What makes a difference is > that spark/flink > only need to support binary row in java, but our system is written in > java/python/c++, and data > flow between java/python/c++ process. Thus has a requirement for > java/python/c++ > implementation. Since arrow standardizes in-memory columnar format and > provides > cross-lang implements, maybe we can add in-memory record format support in > arrow and make a standardization. > The specification document and implements prototype would take some time. > I'll give the doc after I made a design doc and give code after made a > prototype. Any suggestion would be really appreciate。 > > 1. The overall requirements is: > fixed-size field: > > ByteType: 1Byte > > ShortType > > IntegerType > > LongType > > FloatType > > DoubleType > > BooleanType > > DecimalType > > DateType > > TimestampType > > variable-length field: > > BinaryType: byte sequence > > StringType > > ArrayType(elementType, containsNull) > > MapType(keyType, valueType, valueContainsNull) > > StructType(fields) > > > 2. The implements can take inspiration from spark/flink row and arrow > array. The more type to design and support, it would take more time. > > On Tue, Apr 30, 2019 at 10:58 PM Wes McKinney <[email protected]> wrote: > > > hi Shawn, > > > > The first step would be to write a more formalized requirements / > > specification document for discussion, but it is definitely no small > > project. Ultimately as they say "code settles arguments" so creating > > implementations based on a design document will help move along the > > process. > > > > I'd like to point out that Apache Avro is the nearest thing to an > > "in-memory record format" that does not require a schema compilation > > step (like Thrift and Protocol Buffers do). So it might first be > > worthwhile to analyze whether Avro is a solution to the problem, and > > if not why exactly not. > > > > - Wes > > > > On Tue, Apr 30, 2019 at 1:36 AM Shawn Yang <[email protected]> > > wrote: > > > > > > Hi Micah, > > > Thank you for your information about in-memory row-oriented standard. > > > After days of work, I find that it is exactly the thing we need now. I > > > looked into the > > > discuss you mentioned. It seems no one takes up the work. Is there > > anything > > > I can > > > do to speed up us having in-memory row-oriented standard? > > > > > > On Fri, Apr 26, 2019 at 11:49 AM Micah Kornfield < > [email protected]> > > > wrote: > > > > > > > There has also been talk previously on the mailing list of creating > an > > > > in-memory row-oriented standard [1], but I don't think anyone has had > > > > bandwidth to take up the work to gather requirements, design or > > implement > > > > it yet. > > > > > > > > I think this would be valuable but personally, I'd like to get the > > column > > > > oriented standard to "1.0" before taking on this work. > > > > > > > > > > > > [1] > > > > > > > > > > > https://lists.apache.org/thread.html/4818cb3d2ffb4677b24a4279c329fc518a1ac1c9d3017399a4269199@%3Cdev.arrow.apache.org%3E > > > > > > > > On Thu, Apr 25, 2019 at 7:38 PM Philipp Moritz <[email protected]> > > wrote: > > > > > > > > > Hey Shawn, > > > > > > > > > > Thanks for these benchmarks! This is indeed a workload we would > like > > to > > > > > support well in Arrow/Plasma/Ray (if you are using Ray, using > Plasma > > as a > > > > > shared memory transport but some of the issues this raises will > apply > > > > more > > > > > widely to Arrow and other possible IPC/RPC transports like Flight > > etc.). > > > > > > > > > > So far the serialization is mostly optimized for larger objects (as > > you > > > > > have seen). We should be able tooptimize this more, there should be > > some > > > > > low-hanging fruit here since I don't think there has been much work > > going > > > > > into optimizing the serialization for latency yet. If you are > > willing to > > > > > help that would be great! A good place to start is to do an > > end-to-end > > > > > profiling of your benchmark script so we see where the time is > spent. > > > > This > > > > > can be done conveniently with yep (https://github.com/fabianp/yep > ). > > > > > Running > > > > > it through the profiler and posting the image here would be a good > > > > starting > > > > > point, then we can see how we can best improve this. > > > > > > > > > > Let us know if you have any questions! > > > > > > > > > > Best, > > > > > Philipp. > > > > > > > > > > On Thu, Apr 25, 2019 at 7:34 PM Shawn Yang < > [email protected]> > > > > > wrote: > > > > > > > > > > > Hi Wes, > > > > > > Maybe we can classify all dataset into two categories: > > > > > > 1. batch data: spark dataframe, pandas; > > > > > > 2. streaming data: flink DataStream<Row>. data is transferred row > > by > > > > row. > > > > > > For batch data, Arrow's columnar binary IPC protocol already > have > > > > > perfect > > > > > > support for batch data. Spark use arrow > > > > > > to efficiently transfer data between JVM and Python processes. > > > > > > For streaming data, maybe we need to develop a new > > > > language-independent > > > > > > serialization protocol. The protocol is for > > > > > > use row by row, not in columnar way. Because in streaming, the > > data is > > > > > row > > > > > > by row by nature. Since every row in streaming > > > > > > have same schema, there maybe a way to reduce metadata size and > > parse > > > > > > overhead. > > > > > > Arrow already have perfect support for batch data, if it add > > support > > > > > > for streaming > > > > > > data, then it covers all data processing > > > > > > scenario. > > > > > > > > > > > > Regards > > > > > > > > > > > > On Thu, Apr 25, 2019 at 8:59 PM Wes McKinney < > [email protected]> > > > > > wrote: > > > > > > > > > > > > > Since Apache Arrow is a "development platform for in-memory > > data" if > > > > > > > the columnar binary IPC protocol is not an appropriate solution > > for > > > > > > > this use case we might contemplate developing a > > language-independent > > > > > > > serialization protocol for "less-structured" datasets (e.g. > > > > addressing > > > > > > > the way that Ray is using UnionArray now) in a more efficient > > way. > > > > > > > > > > > > > > I would still like to understand in these particular benchmarks > > where > > > > > > > the performance issue is, whether in a flamegraph or something > > else. > > > > > > > Is data being copied that should not be? > > > > > > > > > > > > > > On Thu, Apr 25, 2019 at 6:57 AM Shawn Yang < > > [email protected]> > > > > > > > wrote: > > > > > > > > > > > > > > > > Hi Antoine, > > > > > > > > Thanks, I'll try PEP 574 for python worker to python worker > > data > > > > > > > transfer. > > > > > > > > But there is another question. In my scenario, the data is > > coming > > > > > from > > > > > > > java > > > > > > > > worker, and python worker is receiving streaming data from > > java. So > > > > > > > pickle5 > > > > > > > > is a great solution for python to python data transfer. But > > form > > > > java > > > > > > to > > > > > > > > python, there is still need a framework such as arrow to > enable > > > > > > > > cross-language serialization for realtime streaming data. > From > > the > > > > > > > > benchmark, it seems arrow is not appropriate > > > > > > > > for realtime streaming data. So is there a better solution > for > > > > this? > > > > > > Or > > > > > > > I > > > > > > > > need use something such as flatbuffer to do my own? > > > > > > > > > > > > > > > > On Thu, Apr 25, 2019 at 5:57 PM Antoine Pitrou < > > [email protected] > > > > > > > > > > > > wrote: > > > > > > > > > > > > > > > > > > > > > > > > > > Hi Shawn, > > > > > > > > > > > > > > > > > > So it seems that RecordBatch serialization is able to avoid > > > > copies, > > > > > > > > > otherwise there's no benefit to using Arrow over pickle. > > > > > > > > > > > > > > > > > > Perhaps would you like to try and use pickle5 with > > out-of-band > > > > > > buffers > > > > > > > > > in your benchmark. See https://pypi.org/project/pickle5/ > > > > > > > > > > > > > > > > > > Regards > > > > > > > > > > > > > > > > > > Antoine. > > > > > > > > > > > > > > > > > > > > > > > > > > > Le 25/04/2019 à 11:23, Shawn Yang a écrit : > > > > > > > > > > Hi Antoine, > > > > > > > > > > Here are the images: > > > > > > > > > > 1. use |UnionArray| benchmark: > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > https://user-images.githubusercontent.com/12445254/56651475-aaaea300-66bb-11e9-8b4f-4632e96bd079.png > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > https://user-images.githubusercontent.com/12445254/56651484-b5693800-66bb-11e9-9b1f-d004212e6aac.png > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > https://user-images.githubusercontent.com/12445254/56651490-b8fcbf00-66bb-11e9-8f01-ef4919b6af8b.png > > > > > > > > > > 2. use |RecordBatch| > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > https://user-images.githubusercontent.com/12445254/56629689-c9437880-6680-11e9-8756-02acb47fdb30.png > > > > > > > > > > > > > > > > > > > > Regards > > > > > > > > > > Shawn. > > > > > > > > > > > > > > > > > > > > On Thu, Apr 25, 2019 at 4:03 PM Antoine Pitrou < > > > > > [email protected] > > > > > > > > > > <mailto:[email protected]>> wrote: > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > Hi Shawn, > > > > > > > > > > > > > > > > > > > > Your images don't appear here. It seems they weren't > > > > > attached > > > > > > to > > > > > > > > > your > > > > > > > > > > e-mail? > > > > > > > > > > > > > > > > > > > > About serialization: I am still working on PEP 574 > (*), > > > > > which I > > > > > > > hope > > > > > > > > > > will be integrated in Python 3.8. The standalone > > "pickle5" > > > > > > > module is > > > > > > > > > > also available as a backport. Both Arrow and Numpy > > support > > > > > it. > > > > > > > You > > > > > > > > > may > > > > > > > > > > get different pickle performance using it, especially > > on > > > > > large > > > > > > > data. > > > > > > > > > > > > > > > > > > > > (*) https://www.python.org/dev/peps/pep-0574/ > > > > > > > > > > > > > > > > > > > > Regards > > > > > > > > > > > > > > > > > > > > Antoine. > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > Le 25/04/2019 à 05:19, Shawn Yang a écrit : > > > > > > > > > > > > > > > > > > > > > > Motivate > > > > > > > > > > > > > > > > > > > > > > We want to use arrow as a general data > serialization > > > > > > framework > > > > > > > in > > > > > > > > > > > distributed stream data processing. We are working > > on ray > > > > > > > > > > > <https://github.com/ray-project/ray>, written in > > c++ in > > > > > > > low-level > > > > > > > > > and > > > > > > > > > > > java/python in high-level. We want to transfer > > streaming > > > > > data > > > > > > > > > between > > > > > > > > > > > java/python/c++ efficiently. Arrow is a great > > framework > > > > for > > > > > > > > > > > cross-language data transfer. But it seems more > > > > appropriate > > > > > > for > > > > > > > > > batch > > > > > > > > > > > columnar data. Is is appropriate for distributed > > stream > > > > > data > > > > > > > > > > processing? > > > > > > > > > > > If not, will there be more support in stream data > > > > > processing? > > > > > > > Or is > > > > > > > > > > > there something I miss? > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > Benchmark > > > > > > > > > > > > > > > > > > > > > > 1. if use |UnionArray| > > > > > > > > > > > image.png > > > > > > > > > > > image.png > > > > > > > > > > > image.png > > > > > > > > > > > 2. If use |RecordBatch|, the batch size need to be > > > > greater > > > > > > than > > > > > > > > > 50~200 > > > > > > > > > > > to have e better deserialization performance than > > pickle. > > > > > But > > > > > > > the > > > > > > > > > > > latency won't be acceptable in streaming. > > > > > > > > > > > image.png > > > > > > > > > > > > > > > > > > > > > > Seems neither is an appropriate way or is there a > > better > > > > > way? > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > Benchmark code > > > > > > > > > > > > > > > > > > > > > > ''' > > > > > > > > > > > test arrow/pickle performance > > > > > > > > > > > ''' > > > > > > > > > > > import pickle > > > > > > > > > > > import pyarrow as pa > > > > > > > > > > > import matplotlib.pyplot as plt > > > > > > > > > > > import numpy as np > > > > > > > > > > > import timeit > > > > > > > > > > > import datetime > > > > > > > > > > > import copy > > > > > > > > > > > import os > > > > > > > > > > > from collections import OrderedDict > > > > > > > > > > > dir_path = > > os.path.dirname(os.path.realpath(__file__)) > > > > > > > > > > > > > > > > > > > > > > def benchmark_ser(batches, number=10): > > > > > > > > > > > pickle_results = [] > > > > > > > > > > > arrow_results = [] > > > > > > > > > > > pickle_sizes = [] > > > > > > > > > > > arrow_sizes = [] > > > > > > > > > > > for obj_batch in batches: > > > > > > > > > > > pickle_serialize = timeit.timeit( > > > > > > > > > > > lambda: pickle.dumps(obj_batch, > > > > > > > > > > protocol=pickle.HIGHEST_PROTOCOL), > > > > > > > > > > > number=number) > > > > > > > > > > > pickle_results.append(pickle_serialize) > > > > > > > > > > > > > pickle_sizes.append(len(pickle.dumps(obj_batch, > > > > > > > > > > protocol=pickle.HIGHEST_PROTOCOL))) > > > > > > > > > > > arrow_serialize = timeit.timeit( > > > > > > > > > > > lambda: > > serialize_by_arrow_array(obj_batch), > > > > > > > > > > number=number) > > > > > > > > > > > arrow_results.append(arrow_serialize) > > > > > > > > > > > > > > > > > > > > > arrow_sizes.append(serialize_by_arrow_array(obj_batch).size) > > > > > > > > > > > return [pickle_results, arrow_results, > > pickle_sizes, > > > > > > > > > arrow_sizes] > > > > > > > > > > > > > > > > > > > > > > def benchmark_deser(batches, number=10): > > > > > > > > > > > pickle_results = [] > > > > > > > > > > > arrow_results = [] > > > > > > > > > > > for obj_batch in batches: > > > > > > > > > > > serialized_obj = pickle.dumps(obj_batch, > > > > > > > > > > pickle.HIGHEST_PROTOCOL) > > > > > > > > > > > pickle_deserialize = timeit.timeit(lambda: > > > > > > > > > > pickle.loads(serialized_obj), > > > > > > > > > > > > > number=number) > > > > > > > > > > > pickle_results.append(pickle_deserialize) > > > > > > > > > > > serialized_obj = > > > > > serialize_by_arrow_array(obj_batch) > > > > > > > > > > > arrow_deserialize = timeit.timeit( > > > > > > > > > > > lambda: pa.deserialize(serialized_obj), > > > > > > > number=number) > > > > > > > > > > > arrow_results.append(arrow_deserialize) > > > > > > > > > > > return [pickle_results, arrow_results] > > > > > > > > > > > > > > > > > > > > > > def serialize_by_arrow_array(obj_batch): > > > > > > > > > > > arrow_arrays = [pa.array(record) if not > > > > > > isinstance(record, > > > > > > > > > > pa.Array) else record for record in obj_batch] > > > > > > > > > > > return pa.serialize(arrow_arrays).to_buffer() > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > plot_dir = '{}/{}'.format(dir_path, > > > > > > > > > > datetime.datetime.now().strftime('%m%d_%H%M_%S')) > > > > > > > > > > > if not os.path.exists(plot_dir): > > > > > > > > > > > os.makedirs(plot_dir) > > > > > > > > > > > > > > > > > > > > > > def plot_time(pickle_times, arrow_times, > batch_sizes, > > > > > title, > > > > > > > > > > filename): > > > > > > > > > > > fig, ax = plt.subplots() > > > > > > > > > > > fig.set_size_inches(10, 8) > > > > > > > > > > > > > > > > > > > > > > bar_width = 0.35 > > > > > > > > > > > n_groups = len(batch_sizes) > > > > > > > > > > > index = np.arange(n_groups) > > > > > > > > > > > opacity = 0.6 > > > > > > > > > > > > > > > > > > > > > > plt.bar(index, pickle_times, bar_width, > > > > > > > > > > > alpha=opacity, color='r', > label='Pickle') > > > > > > > > > > > > > > > > > > > > > > plt.bar(index + bar_width, arrow_times, > > bar_width, > > > > > > > > > > > alpha=opacity, color='c', > label='Arrow') > > > > > > > > > > > > > > > > > > > > > > plt.title(title, fontweight='bold') > > > > > > > > > > > plt.ylabel('Time (seconds)', fontsize=10) > > > > > > > > > > > plt.xticks(index + bar_width / 2, batch_sizes, > > > > > > fontsize=10) > > > > > > > > > > > plt.legend(fontsize=10, bbox_to_anchor=(1, 1)) > > > > > > > > > > > plt.tight_layout() > > > > > > > > > > > plt.yticks(fontsize=10) > > > > > > > > > > > plt.savefig(plot_dir + '/plot-' + filename + > > '.png', > > > > > > > > > format='png') > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > def plot_size(pickle_sizes, arrow_sizes, > batch_sizes, > > > > > title, > > > > > > > > > > filename): > > > > > > > > > > > fig, ax = plt.subplots() > > > > > > > > > > > fig.set_size_inches(10, 8) > > > > > > > > > > > > > > > > > > > > > > bar_width = 0.35 > > > > > > > > > > > n_groups = len(batch_sizes) > > > > > > > > > > > index = np.arange(n_groups) > > > > > > > > > > > opacity = 0.6 > > > > > > > > > > > > > > > > > > > > > > plt.bar(index, pickle_sizes, bar_width, > > > > > > > > > > > alpha=opacity, color='r', > label='Pickle') > > > > > > > > > > > > > > > > > > > > > > plt.bar(index + bar_width, arrow_sizes, > > bar_width, > > > > > > > > > > > alpha=opacity, color='c', > label='Arrow') > > > > > > > > > > > > > > > > > > > > > > plt.title(title, fontweight='bold') > > > > > > > > > > > plt.ylabel('Space (Byte)', fontsize=10) > > > > > > > > > > > plt.xticks(index + bar_width / 2, batch_sizes, > > > > > > fontsize=10) > > > > > > > > > > > plt.legend(fontsize=10, bbox_to_anchor=(1, 1)) > > > > > > > > > > > plt.tight_layout() > > > > > > > > > > > plt.yticks(fontsize=10) > > > > > > > > > > > plt.savefig(plot_dir + '/plot-' + filename + > > '.png', > > > > > > > > > format='png') > > > > > > > > > > > > > > > > > > > > > > def get_union_obj(): > > > > > > > > > > > size = 200 > > > > > > > > > > > str_array = pa.array(['str-' + str(i) for i in > > > > > > > range(size)]) > > > > > > > > > > > int_array = > > pa.array(np.random.randn(size).tolist()) > > > > > > > > > > > types = pa.array([0 for _ in range(size)]+[1 > for > > _ in > > > > > > > > > > range(size)], type=pa.int8()) > > > > > > > > > > > offsets = > > > > pa.array(list(range(size))+list(range(size)), > > > > > > > > > > type=pa.int32()) > > > > > > > > > > > union_arr = pa.UnionArray.from_dense(types, > > offsets, > > > > > > > > > > [str_array, int_array]) > > > > > > > > > > > return union_arr > > > > > > > > > > > > > > > > > > > > > > test_objects_generater = [ > > > > > > > > > > > lambda: np.random.randn(500), > > > > > > > > > > > lambda: np.random.randn(500).tolist(), > > > > > > > > > > > lambda: get_union_obj() > > > > > > > > > > > ] > > > > > > > > > > > > > > > > > > > > > > titles = [ > > > > > > > > > > > 'numpy arrays', > > > > > > > > > > > 'list of ints', > > > > > > > > > > > 'union array of strings and ints' > > > > > > > > > > > ] > > > > > > > > > > > > > > > > > > > > > > def plot_benchmark(): > > > > > > > > > > > batch_sizes = list(OrderedDict.fromkeys(int(i) > > for i > > > > in > > > > > > > > > > np.geomspace(1, 1000, num=25))) > > > > > > > > > > > for i in range(len(test_objects_generater)): > > > > > > > > > > > batches = [[test_objects_generater[i]() for > > _ in > > > > > > > > > > range(batch_size)] for batch_size in batch_sizes] > > > > > > > > > > > ser_result = benchmark_ser(batches=batches) > > > > > > > > > > > plot_time(*ser_result[0:2], batch_sizes, > > > > > > > 'serialization: ' > > > > > > > > > > + titles[i], 'ser_time'+str(i)) > > > > > > > > > > > plot_size(*ser_result[2:], batch_sizes, > > > > > > 'serialization > > > > > > > > > > byte size: ' + titles[i], 'ser_size'+str(i)) > > > > > > > > > > > deser = benchmark_deser(batches=batches) > > > > > > > > > > > plot_time(*deser, batch_sizes, > > 'deserialization: > > > > ' > > > > > + > > > > > > > > > > titles[i], 'deser_time-'+str(i)) > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > if __name__ == "__main__": > > > > > > > > > > > plot_benchmark() > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > Question > > > > > > > > > > > > > > > > > > > > > > So if i want to use arrow as data serialization > > > > framework > > > > > in > > > > > > > > > > > distributed stream data processing, what's the > right > > way? > > > > > > > > > > > Since streaming processing is a widespread scenario > > in > > > > > > > > > > data processing, > > > > > > > > > > > framework such as flink, spark structural streaming > > is > > > > > > becoming > > > > > > > > > > more and > > > > > > > > > > > more popular. Is there a possibility to add special > > > > support > > > > > > > > > > > for streaming processing in arrow, such that we can > > also > > > > > > > benefit > > > > > > > > > from > > > > > > > > > > > cross-language and efficient memory layout. > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > -- * • **Tim Swast* * • *Software Friendliness Engineer * • *Google Cloud Developer Relations * • *Seattle, WA, USA
{kind=link}
{kind=link}
{kind=link}
{kind=link}