That article gives the best technical assessment I've seen of Intel's architecture bug. I noted the discussion's subject and thought I'd add some clarity. Nothing more.
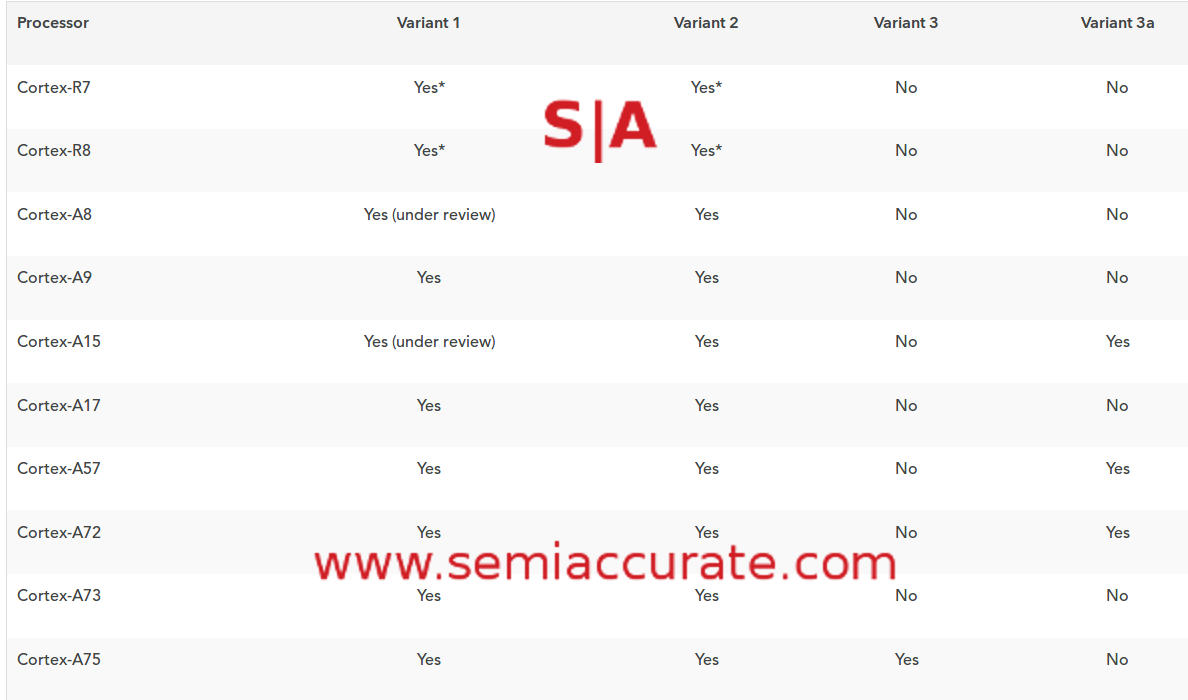
For the TL;DR crowd: get an AMD chip in your computer. On Thursday, January 4, 2018, r...@open-mpi.org <r...@open-mpi.org> wrote: > Yes, please - that was totally inappropriate for this mailing list. > Ralph > > > On Jan 4, 2018, at 4:33 PM, Jeff Hammond <jeff.scie...@gmail.com> wrote: > > Can we restrain ourselves to talk about Open-MPI or at least technical > aspects of HPC communication on this list and leave the stock market tips > for Hacker News and Twitter? > > Thanks, > > Jeff > > On Thu, Jan 4, 2018 at 3:53 PM, John Chludzinski <john.chludzinski@ > gmail.com> wrote: > >> From https://semiaccurate.com/2018/01/04/kaiser-security- >> holes-will-devastate-intels-marketshare/ >> >> Kaiser security holes will devastate Intel’s marketshareAnalysis: This >> one tips the balance toward AMD in a big wayJan 4, 2018 by Charlie >> Demerjian <https://semiaccurate.com/author/charlie/> >> >> >> >> This latest decade-long critical security hole in Intel CPUs is going to >> cost the company significant market share. SemiAccurate thinks it is not >> only consequential but will shift the balance of power away from Intel CPUs >> for at least the next several years. >> >> Today’s latest crop of gaping security flaws have three sets of holes >> across Intel, AMD, and ARM processors along with a slew of official >> statements and detailed analyses. On top of that the statements from >> vendors range from detailed and direct to intentionally misleading and >> slimy. Lets take a look at what the problems are, who they effect and what >> the outcome will be. Those outcomes range from trivial patching to >> destroying the market share of Intel servers, and no we are not joking. >> >> (*Authors Note 1:* For the technical readers we are simplifying a lot, >> sorry we know this hurts. The full disclosure docs are linked, read them >> for the details.) >> >> (*Authors Note 2:* For the financial oriented subscribers out there, the >> parts relevant to you are at the very end, the section is titled *Rubber >> Meet Road*.) >> >> *The Problem(s):* >> >> As we said earlier there are three distinct security flaws that all fall >> somewhat under the same umbrella. All are ‘new’ in the sense that the class >> of attacks hasn’t been publicly described before, and all are very obscure >> CPU speculative execution and timing related problems. The extent the fixes >> affect differing architectures also ranges from minor to near-crippling >> slowdowns. Worse yet is that all three flaws aren’t bugs or errors, they >> exploit correct CPU behavior to allow the systems to be hacked. >> >> The three problems are cleverly labeled Variant One, Variant Two, and >> Variant Three. Google Project Zero was the original discoverer of them and >> has labeled the classes as Bounds Bypass Check, Branch Target Injection, >> and Rogue Data Cache Load respectively. You can read up on the extensive >> and gory details here >> <https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html> >> if >> you wish. >> >> If you are the TLDR type the very simplified summary is that modern CPUs >> will speculatively execute operations ahead of the one they are currently >> running. Some architectures will allow these executions to start even when >> they violate privilege levels, but those instructions are killed or rolled >> back hopefully before they actually complete running. >> >> Another feature of modern CPUs is virtual memory which can allow memory >> from two or more processes to occupy the same physical page. This is a good >> thing because if you have memory from the kernel and a bit of user code in >> the same physical page but different virtual pages, changing from kernel to >> userspace execution doesn’t require a page fault. This saves massive >> amounts of time and overhead giving modern CPUs a huge speed boost. (For >> the really technical out there, I know you are cringing at this >> simplification, sorry). >> >> These two things together allow you to do some interesting things and >> along with timing attacks add new weapons to your hacking arsenal. If you >> have code executing on one side of a virtual memory page boundary, it can >> speculatively execute the next few instructions on the physical page that >> cross the virtual page boundary. This isn’t a big deal unless the two >> virtual pages are mapped to processes that are from different users or >> different privilege levels. Then you have a problem. (Again painfully >> simplified and liberties taken with the explanation, read the Google paper >> for the full detail.) >> >> This speculative execution allows you to get a few short (low latency) >> instructions in before the speculation ends. Under certain circumstances >> you can read memory from different threads or privilege levels, write those >> things somewhere, and figure out what addresses other bits of code are >> using. The latter bit has the nasty effect of potentially blowing through >> address space randomization defenses which are a keystone of modern >> security efforts. It is ugly. >> >> *Who Gets Hit:* >> >> So we have three attack vectors and three affected companies, Intel, AMD, >> and ARM. Each has a different set of vulnerabilities to the different >> attacks due to differences in underlying architectures. AMD put out a >> pretty clear statement of what is affected, ARM put out by far the best and >> most comprehensive description, and Intel obfuscated, denied, blamed >> others, and downplayed the problem. If this was a contest for misleading >> with doublespeak and misdirection, Intel won with a gold star, the others >> weren’t even in the game. Lets look at who said what and why. >> >> *ARM:* >> >> ARM has a page up <https://developer.arm.com/support/security-update> listing >> vulnerable processor cores, descriptions of the attacks, and plenty of >> links to more information. They also put up a very comprehensive white >> paper that rivals Google’s original writeup, complete with code examples >> and a new 3a variant. You can find it here >> <https://developer.arm.com/support/security-update/download-the-whitepaper>. >> Just for completeness we are putting up ARM’s excellent table of affected >> processors, enjoy. >> >> [image: ARM Kaiser core table] >> <https://www.semiaccurate.com/assets/uploads/2018/01/ARM_Kaiser_response_table.jpg> >> >> *Affected ARM cores* >> >> *AMD:* >> >> AMD gave us the following table which lays out their position pretty >> clearly. The short version is that architecturally speaking they are >> vulnerable to 1 and 2 but three is not possible due to microarchitecture. >> More on this in a bit, it is very important. AMD also went on to describe >> some of the issues and mitigations to SemiAccurate, but again, more in a >> bit. >> >> [image: AMD Kaiser response Matrix] >> <https://www.semiaccurate.com/assets/uploads/2018/01/AMD_Kaiser_response.jpg> >> >> *AMD’s response matrix* >> >> *Intel:* >> >> Intel is continuing to be the running joke of the industry as far as >> messaging is concerned. Their statement is a pretty awe-inspiring example >> of saying nothing while desperately trying to minimize the problem. You can >> find >> it here >> <https://newsroom.intel.com/news/intel-responds-to-security-research-findings/> >> but >> it contains zero useful information. SemiAccurate is getting tired of >> saying this but Intel should be ashamed of how their messaging is done, not >> saying anything would do less damage than their current course of action. >> >> You will notice the line in the second paragraph, “*Recent reports that >> these exploits are caused by a “bug” or a “flaw” and are unique to Intel >> products are incorrect.”* This is technically true and pretty damning. >> They are directly saying that the problem is not a bug but is due to *misuse >> of correct processor behavior*. This a a critical problem because it >> can’t be ‘patched’ or ‘updated’ like a bug or flaw without breaking the >> CPU. In short you can’t fix it, and this will be important later. Intel >> mentions this but others don’t for a good reason, again later. >> >> Then Intel goes on to say, *“Intel is committed to the industry best >> practice of responsible disclosure of potential security issues, which is >> why Intel and other vendors had planned to disclose this issue next week >> when more software and firmware updates will be available. However, Intel >> is making this statement today because of the current inaccurate media >> reports.*” This is simply not true, or at least the part about industry >> best practices of responsible disclosure. Intel sat on the last critical >> security flaw affecting 10+ years of CPUs which SemiAccurate exclusively >> disclosed >> <https://www.semiaccurate.com/2017/05/01/remote-security-exploit-2008-intel-platforms/> >> for >> 6+ weeks after a patch was released. Why? PR reasons. >> >> SemiAccurate feels that Intel holding back knowledge of what we believe >> were flaws being actively exploited in the field even though there were >> simple mitigation steps available is not responsible. Or best practices. Or >> ethical. Or anything even intoning goodness. It is simply unethical, but >> only that good if you are feeling kind. Intel does not do the right thing >> for security breaches and has not even attempted to do so in the 15+ years >> this reporter has been tracking them on the topic. They are by far the >> worst major company in this regard, and getting worse. >> >> *Mitigation:* >> >> As is described by Google, ARM, and AMD, but not Intel, there are >> workarounds for the three new vulnerabilities. Since Google first >> discovered these holes in June, 2017, there have been patches pushed up to >> various Linux kernel and related repositories. The first one SemiAccurate >> can find was dated October 2017 and the industry coordinated announcement >> was set for Monday, January 9, 2018 so you can be pretty sure that the >> patches are in place and ready to be pushed out if not on your systems >> already. Microsoft and Apple are said to be at a similar state of readiness >> too. In short by the time you read this, it will likely be fixed. >> >> That said the fixes do have consequences, and all are heavily workload >> dependent. For variants 1 and 2 the performance hit is pretty minor with >> reports of ~1% performance hits under certain circumstances but for the >> most part you won’t notice anything if you patch, and you should patch. >> Basically 1 and 2 are irrelevant from any performance perspective as long >> as your system is patched. >> >> The big problem is with variant 3 which ARM claims has a similar effect >> on devices like phones or tablets, IE low single digit performance hits if >> that. Given the way ARM CPUs are used in the majority of devices, they >> don’t tend to have the multi-user, multi-tenant, heavily virtualized >> workloads that servers do. For the few ARM cores that are affected, their >> users will see a minor, likely unnoticeable performance hit when patched. >> >> User x86 systems will likely be closer to the ARM model for performance >> hits. Why? Because while they can run heavily virtualized, multi-user, >> multi-tenant workloads, most desktop users don’t. Even if they do, it is >> pretty rare that these users are CPU bound for performance, memory and >> storage bandwidth will hammer performance on these workloads long before >> the CPU becomes a bottleneck. Why do we bring this up? >> >> Because in those heavily virtualized, multi-tenant, multi-user workloads >> that most servers run in the modern world, the patches for 3 are painful. >> How painful? SemiAccurate’s research has found reports of between 5-50% >> slowdowns, again workload and software dependent, with the average being >> around 30%. This stands to reason because the fixes we have found >> essentially force a demapping of kernel code on a context switch. >> >> *The Pain:* >> >> This may sound like techno-babble but it isn’t, and it happens a many >> thousands of times a second on modern machines if not more. Because as >> Intel pointed out, the CPU is operating correctly and the exploit uses >> correct behavior, it can’t be patched or ‘fixed’ without breaking the CPU >> itself. Instead what you have to do is make sure the circumstances that can >> be exploited don’t happen. Consider this a software workaround or avoidance >> mechanism, not a patch or bug fix, the underlying problem is still there >> and exploitable, there is just nothing to exploit. >> >> Since the root cause of 3 is a mechanism that results in a huge >> performance benefit by not having to take a few thousand or perhaps >> millions page faults a second, at the very least you now have to take the >> hit of those page faults. Worse yet the fix, from what SemiAccurate has >> gathered so far, has to unload the kernel pages from virtual memory maps on >> a context switch. So with the patch not only do you have to take the hit >> you previously avoided, but you have to also do a lot of work >> copying/scrubbing virtual memory every time you do. This explains the hit >> of ~1/3rd of your total CPU performance quite nicely. >> >> Going back to user x86 machines and ARM devices, they aren’t doing nearly >> as many context switches as the servers are but likely have to do the same >> work when doing a switch. In short if you do a theoretical 5% of the >> switches, you take 5% of that 30% hit. It isn’t this simple but you get the >> idea, it is unlikely to cripple a consumer desktop PC or phone but will >> probably cripple a server. Workload dependent, we meant it. >> >> *The Knife Goes In:* >> >> So x86 servers are in deep trouble, what was doable on two racks of >> machines now needs three if you apply the patch for 3. If not, well >> customers have lawyers, will you risk it? Worse yet would you buy cloud >> services from someone who didn’t apply the patch? Think about this for the >> economics of the megadatacenters, if you are buying 100K+ servers a month, >> you now need closer to 150K, not a trivial added outlay for even the big >> guys. >> >> But there is one big caveat and it comes down to the part we said we >> would get to later. Later is now. Go back and look at that AMD chart near >> the top of the article, specifically their vulnerability for Variant 3 >> attacks. Note the bit about, “*Zero AMD vulnerability or risk because of >> AMD architecture differences.*” See an issue here? >> >> What AMD didn’t spell out in detail is a minor difference in >> microarchitecture between Intel and AMD CPUs. When a CPU speculatively >> executes and crosses a privilege level boundary, any idiot would probably >> say that the CPU should see this crossing and not execute the following >> instructions that are out of it’s privilege level. This isn’t rocket >> science, just basic common sense. >> >> AMD’s microarchitecture sees this privilege level change and throws the >> microarchitectural equivalent of a hissy fit and doesn’t execute the code. >> Common sense wins out. Intel’s implementation does execute the following >> code across privilege levels which sounds on the surface like a bit of a >> face-palm implementation but it really isn’t. >> >> What saves Intel is that the speculative execution goes on but, to the >> best of our knowledge, is unwound when the privilege level changes a few >> instructions later. Since Intel CPUs in the wild don’t crash or violate >> privilege levels, it looks like that mechanism works properly in practice. >> What these new exploits do is slip a few very short instructions in that >> can read data from the other user or privilege level before the context >> change happens. If crafted correctly the instructions are unwound but the >> data can be stashed in a place that is persistent. >> >> Intel probably get a slight performance gain from doing this ‘sloppy’ >> method but AMD seems to have have done the right thing for the right >> reasons. That extra bounds check probably take a bit of time but in >> retrospect, doing the right thing was worth it. Since both are fundamental >> ‘correct’ behaviors for their respective microarchitectures, there is no >> possible fix, just code that avoids scenarios where it can be abused. >> >> For Intel this avoidance comes with a 30% performance hit on server type >> workloads, less on desktop workloads. For AMD the problem was avoided by >> design and the performance hit is zero. Doing the right thing for the right >> reasons even if it is marginally slower seems to have paid off in this >> circumstance. Mother was right, AMD listened, Intel didn’t. >> >> *Weasel Words:* >> >> Now you have a bit more context about why Intel’s response was, well, a >> non-response. They blamed others, correctly, for having the same problem >> but their blanket statement avoided the obvious issue of the others aren’t >> crippled by the effects of the patches like Intel. Intel screwed up, badly, >> and are facing a 30% performance hit going forward for it. AMD did right >> and are probably breaking out the champagne at HQ about now. >> >> Intel also tried to deflect lawyers by saying they follow industry best >> practices. They don’t and the AMT hole was a shining example of them >> putting PR above customer security. Similarly their sitting on the fix >> for the TXT flaw for *THREE*YEARS* >> <https://www.semiaccurate.com/2016/01/20/intel-puts-out-secure-cpus-based-on-insecurity/> >> because >> they didn’t want to admit to architectural security blunders and reveal >> publicly embarrassing policies until forced to disclose by a governmental >> agency being exploited by a foreign power is another example that shines a >> harsh light on their ‘best practices’ line. There are many more like this. >> Intel isn’t to be trusted for security practices or disclosures because PR >> takes precedence over customer security. >> >> *Rubber Meet Road:* >> >> Unfortunately security doesn’t sell and rarely affects marketshare. This >> time however is different and will hit Intel were it hurts, in the wallet. >> SemiAccurate thinks this exploit is going to devastate Intel’s marketshare. >> Why? Read on subscribers. >> >> *Note: The following is analysis for professional level subscribers only.* >> >> *Disclosures: Charlie Demerjian and Stone Arch Networking Services, Inc. >> have no consulting relationships, investment relationships, or hold any >> investment positions with any of the companies mentioned in this report.* >> >> >> On Thu, Jan 4, 2018 at 6:21 PM, Reuti <re...@staff.uni-marburg.de> wrote: >> >>> >>> Am 04.01.2018 um 23:45 schrieb r...@open-mpi.org: >>> >>> > As more information continues to surface, it is clear that this >>> original article that spurred this thread was somewhat incomplete - >>> probably released a little too quickly, before full information was >>> available. There is still some confusion out there, but the gist from >>> surfing the various articles (and trimming away the hysteria) appears to be: >>> > >>> > * there are two security issues, both stemming from the same root >>> cause. The “problem” has actually been around for nearly 20 years, but >>> faster processors are making it much more visible. >>> > >>> > * one problem (Meltdown) specifically impacts at least Intel, ARM, and >>> AMD processors. This problem is the one that the kernel patches address as >>> it can be corrected via software, albeit with some impact that varies based >>> on application. Those apps that perform lots of kernel services will see >>> larger impacts than those that don’t use the kernel much. >>> > >>> > * the other problem (Spectre) appears to impact _all_ processors >>> (including, by some reports, SPARC and Power). This problem lacks a >>> software solution >>> > >>> > * the “problem” is only a problem if you are running on shared nodes - >>> i.e., if multiple users share a common OS instance as it allows a user to >>> potentially access the kernel information of the other user. So HPC >>> installations that allocate complete nodes to a single user might want to >>> take a closer look before installing the patches. Ditto for your desktop >>> and laptop - unless someone can gain access to the machine, it isn’t really >>> a “problem”. >>> >>> Weren't there some PowerPC with strict in-order-execution which could >>> circumvent this? I find a hint about an "EIEIO" command only. Sure, >>> in-order-execution might slow down the system too. >>> >>> -- Reuti >>> >>> >>> > >>> > * containers and VMs don’t fully resolve the problem - the only >>> solution other than the patches is to limit allocations to single users on >>> a node >>> > >>> > HTH >>> > Ralph >>> > >>> > >>> >> On Jan 3, 2018, at 10:47 AM, r...@open-mpi.org wrote: >>> >> >>> >> Well, it appears from that article that the primary impact comes from >>> accessing kernel services. With an OS-bypass network, that shouldn’t happen >>> all that frequently, and so I would naively expect the impact to be at the >>> lower end of the reported scale for those environments. TCP-based systems, >>> though, might be on the other end. >>> >> >>> >> Probably something we’ll only really know after testing. >>> >> >>> >>> On Jan 3, 2018, at 10:24 AM, Noam Bernstein < >>> noam.bernst...@nrl.navy.mil> wrote: >>> >>> >>> >>> Out of curiosity, have any of the OpenMPI developers tested (or care >>> to speculate) how strongly affected OpenMPI based codes (just the MPI part, >>> obviously) will be by the proposed Intel CPU memory-mapping-related kernel >>> patches that are all the rage? >>> >>> >>> >>> https://arstechnica.com/gadgets/2018/01/whats-behind-the-in >>> tel-design-flaw-forcing-numerous-patches/ >>> >>> >>> >>> >>> Noam >>> >>> _______________________________________________ >>> >>> users mailing list >>> >>> users@lists.open-mpi.org >>> >>> https://lists.open-mpi.org/mailman/listinfo/users >>> >> >>> >> _______________________________________________ >>> >> users mailing list >>> >> users@lists.open-mpi.org >>> >> https://lists.open-mpi.org/mailman/listinfo/users >>> > >>> > _______________________________________________ >>> > users mailing list >>> > users@lists.open-mpi.org >>> > https://lists.open-mpi.org/mailman/listinfo/users >>> > >>> >>> _______________________________________________ >>> users mailing list >>> users@lists.open-mpi.org >>> https://lists.open-mpi.org/mailman/listinfo/users >>> >> >> >> _______________________________________________ >> users mailing list >> users@lists.open-mpi.org >> https://lists.open-mpi.org/mailman/listinfo/users >> > > > > -- > Jeff Hammond > jeff.scie...@gmail.com > http://jeffhammond.github.io/ > _______________________________________________ > users mailing list > users@lists.open-mpi.org > https://lists.open-mpi.org/mailman/listinfo/users > > >
{kind=link}
{kind=link}
_______________________________________________ users mailing list users@lists.open-mpi.org https://lists.open-mpi.org/mailman/listinfo/users