any progress update about this feature? Thanks
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/apache/incubator-tvm/issues/4118#issuecomment-636596566
> 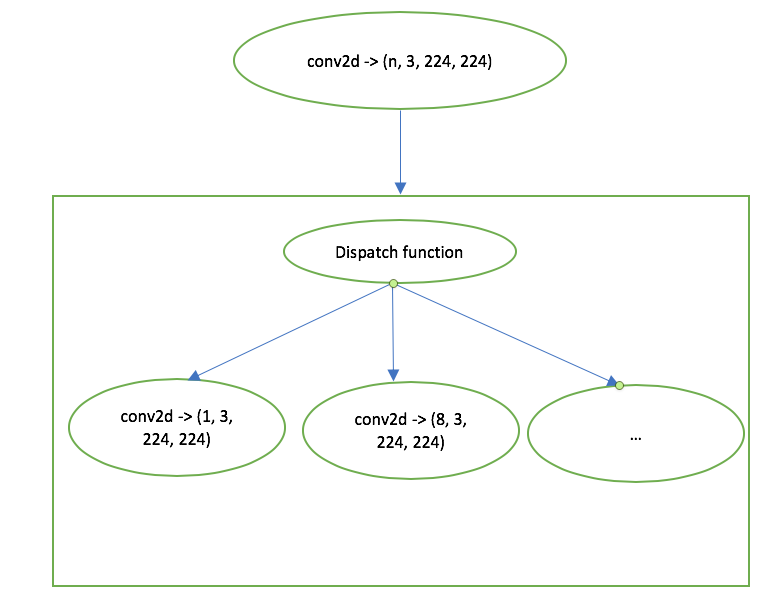
I'm still curious what will happen if we have conv2d(5, 3, 224, 224)? We'll use
conv2d(8, 3, 224, 224)? Do we need to do some padding to use the kernel
conv2d(8, 3, 224, 224)?
T
> > 
>
> I'm still curious what will happen if we have conv2d(5, 3, 224, 224)? We'll
> use conv2d(8, 3, 224, 224)? Do we need to do some padding to use the kernel
> conv2d(8, 3, 2
# Motivation
Cloud devices are more powerful than Edge devices, which provides higher
computation capabilities for deep learning workloads. For example, for the VTA
core, with Cloud devices, we have more resources to support larger GEMM cores
(e.g., 32\*32 or even 64\*64) and device buffers,
# Motivation
Cloud devices are more powerful than Edge devices, which provides higher
computation capabilities for deep learning workloads. For example, for the VTA
core, with Cloud devices, we have more resources to support larger GEMM cores
(e.g., 32\*32 or even 64\*64) and device buffers
ping @thierry
also cc @hjiang
---
[Visit
Topic](https://discuss.tvm.ai/t/rfc-vta-support-for-cloud-devices-opencl-compatible/6676/3)
to respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [click
here](https://discuss.tvm.ai/email/uns
Thanks @hjiang for the comments.
[quote="hjiang, post:6, topic:6676"]
#1 about “cloud device may use PCIE instead of memory share”, that make sense,
but seems like a new driver with pcie support would can fix and no need such
big change,
[/quote]
#1 a new driver with PCIe support is not enou
@kevinthesun @haichen any update on this work? I'm also quite interested in
this feature.
---
[Visit
Topic](https://discuss.tvm.ai/t/whether-tvm-will-support-dynamic-shapes-in-the-future/3700/10)
to respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe fr
@tqchen @thierry @liangfu @hjiang @vegaluis
All the features proposed have been implemented. Do you have any other
comments/concerns? Is it ok that we proceed with a formal RFC and PR?
Thanks.
---
[Visit
Topic](https://discuss.tvm.ai/t/rfc-vta-support-for-cloud-devices-opencl-compatible/
[quote="thierry, post:14, topic:6676, full:true"]
Finally some lower level comments for @zhanghaohit and @remotego:
* I agree with @liangfu that leveraging Chisel would be ideal in the spirit of
minimizing the number of design sources. There is an initial scaffold of the
Chisel design to work
Hi,
I think the runtime support here
(https://github.com/apache/incubator-tvm/pull/3554) is for uop and instructions
sync via PCIe. However, if we want to run a full network (e.g., Resnet), we're
still missing layer-wise synchronization/device_copy if two adjacent layers are
resident in diff
Hi @elnaz92
Thanks for your interest. Yes, we've tested some models, e.g., Resnet_XX.
Currently we're using Intel A10. The performance on Cloud FPGA is much better
than Edge FPGA (e.g., ultra96), as we have more resources to enlarge the GEMM
core size. We're still doing much performance opt
Hi @elnaz92
I'm not familiar with this. Maybe @remotego can comment a bit?
---
[Visit
Topic](https://discuss.tvm.ai/t/rfc-vta-support-for-cloud-devices-opencl-compatible/6676/27)
to respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails,
Formal RFC is here: https://github.com/apache/incubator-tvm/issues/5840
PRs are here:
https://github.com/apache/incubator-tvm-vta/pull/9
https://github.com/apache/incubator-tvm/pull/5842
@elnaz92 You may checkout the code and try first.
---
[Visit
Topic](https://discuss.tvm.ai/t/rfc-vta-s
14 matches
Mail list logo