[jira] [Commented] (KAFKA-8940) Flaky Test SmokeTestDriverIntegrationTest.shouldWorkWithRebalance
[
https://issues.apache.org/jira/browse/KAFKA-8940?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360614#comment-17360614
]
Josep Prat commented on KAFKA-8940:
---
It failed again today:
{code:java}
Build / JDK 15 and Scala 2.13 /
org.apache.kafka.streams.integration.SmokeTestDriverIntegrationTest.shouldWorkWithRebalance
java.lang.AssertionError: verifying tagg
fail: key=770 tagg=[ConsumerRecord(topic = tagg, partition = 0, leaderEpoch =
0, offset = 7, CreateTime = 1623283465319, serialized key size = 3, serialized
value size = 8, headers = RecordHeaders(headers = [], isReadOnly = false), key
= 770, value = 1)] expected=0
taggEvents: [ConsumerRecord(topic = tagg, partition = 0, leaderEpoch =
0, offset = 7, CreateTime = 1623283465319, serialized key size = 3, serialized
value size = 8, headers = RecordHeaders(headers = [], isReadOnly = false), key
= 770, value = 1)]
verifying suppressed min-suppressed
verifying min-suppressed with 10 keys
verifying suppressed sws-suppressed
verifying min with 10 keys
verifying max with 10 keys
verifying dif with 10 keys
verifying sum with 10 keys
verifying cnt with 10 keys
verifying avg with 10 keys
{code}
https://ci-builds.apache.org/job/Kafka/job/kafka-pr/job/PR-10855/2/testReport/junit/org.apache.kafka.streams.integration/SmokeTestDriverIntegrationTest/Build___JDK_15_and_Scala_2_13___shouldWorkWithRebalance/
> Flaky Test SmokeTestDriverIntegrationTest.shouldWorkWithRebalance
> -
>
> Key: KAFKA-8940
> URL: https://issues.apache.org/jira/browse/KAFKA-8940
> Project: Kafka
> Issue Type: Bug
> Components: streams, unit tests
>Reporter: Guozhang Wang
>Priority: Major
> Labels: flaky-test, newbie++
>
> The test does not properly account for windowing. See this comment for full
> details.
> We can patch this test by fixing the timestamps of the input data to avoid
> crossing over a window boundary, or account for this when verifying the
> output. Since we have access to the input data it should be possible to
> compute whether/when we do cross a window boundary, and adjust the expected
> output accordingly
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] showuon commented on pull request #10736: KAFKA-9295: revert session timeout to default value
showuon commented on pull request #10736: URL: https://github.com/apache/kafka/pull/10736#issuecomment-858384704 Thanks @mjsax ! I'll further investigate it and let you know~ @ableegoldman , since #10803 is already merged into trunk, now the default session timeout is 45 seconds. I think we can merge this PR to revert previous session timeout increasing workaround. Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10579: KAFKA-9555 Added default RLMM implementation based on internal topic storage.
satishd commented on a change in pull request #10579:
URL: https://github.com/apache/kafka/pull/10579#discussion_r648927106
##
File path:
storage/src/main/java/org/apache/kafka/server/log/remote/metadata/storage/TopicBasedRemoteLogMetadataManagerConfig.java
##
@@ -0,0 +1,197 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.metadata.storage;
+
+import org.apache.kafka.clients.CommonClientConfigs;
+import org.apache.kafka.clients.consumer.ConsumerConfig;
+import org.apache.kafka.clients.producer.ProducerConfig;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.serialization.ByteArrayDeserializer;
+import org.apache.kafka.common.serialization.ByteArraySerializer;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.Map;
+import java.util.Objects;
+
+import static
org.apache.kafka.clients.CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG;
+import static org.apache.kafka.common.config.ConfigDef.Importance.LOW;
+import static org.apache.kafka.common.config.ConfigDef.Range.atLeast;
+import static org.apache.kafka.common.config.ConfigDef.Type.INT;
+import static org.apache.kafka.common.config.ConfigDef.Type.LONG;
+
+public final class TopicBasedRemoteLogMetadataManagerConfig {
+private static final Logger log =
LoggerFactory.getLogger(TopicBasedRemoteLogMetadataManagerConfig.class.getName());
+
+public static final String REMOTE_LOG_METADATA_TOPIC_NAME =
"__remote_log_metadata";
+
+public static final String
REMOTE_LOG_METADATA_TOPIC_REPLICATION_FACTOR_PROP =
"remote.log.metadata.topic.replication.factor";
+public static final String REMOTE_LOG_METADATA_TOPIC_PARTITIONS_PROP =
"remote.log.metadata.topic.num.partitions";
+public static final String REMOTE_LOG_METADATA_TOPIC_RETENTION_MILLIS_PROP
= "remote.log.metadata.topic.retention.ms";
+public static final String REMOTE_LOG_METADATA_CONSUME_WAIT_MS_PROP =
"remote.log.metadata.publish.wait.ms";
+
+public static final int DEFAULT_REMOTE_LOG_METADATA_TOPIC_PARTITIONS = 50;
+public static final long
DEFAULT_REMOTE_LOG_METADATA_TOPIC_RETENTION_MILLIS = -1L;
+public static final int
DEFAULT_REMOTE_LOG_METADATA_TOPIC_REPLICATION_FACTOR = 3;
+public static final long DEFAULT_REMOTE_LOG_METADATA_CONSUME_WAIT_MS = 60
* 1000L;
+
+public static final String
REMOTE_LOG_METADATA_TOPIC_REPLICATION_FACTOR_DOC = "Replication factor of
remote log metadata Topic.";
+public static final String REMOTE_LOG_METADATA_TOPIC_PARTITIONS_DOC = "The
number of partitions for remote log metadata Topic.";
+public static final String REMOTE_LOG_METADATA_TOPIC_RETENTION_MILLIS_DOC
= "Remote log metadata topic log retention in milli seconds." +
+"Default: -1, that means unlimited. Users can configure this value
based on their use cases. " +
+"To avoid any data loss, this value should be more than the
maximum retention period of any topic enabled with " +
+"tiered storage in the cluster.";
+public static final String REMOTE_LOG_METADATA_CONSUME_WAIT_MS_DOC = "The
amount of time in milli seconds to wait for the local consumer to " +
+"receive the published event.";
+
+public static final String REMOTE_LOG_METADATA_COMMON_CLIENT_PREFIX =
"remote.log.metadata.common.client.";
+public static final String REMOTE_LOG_METADATA_PRODUCER_PREFIX =
"remote.log.metadata.producer.";
+public static final String REMOTE_LOG_METADATA_CONSUMER_PREFIX =
"remote.log.metadata.consumer.";
+
+private static final String REMOTE_LOG_METADATA_CLIENT_PREFIX =
"__remote_log_metadata_client";
+private static final String BROKER_ID = "broker.id";
+
+private static final ConfigDef CONFIG = new ConfigDef();
+static {
+CONFIG.define(REMOTE_LOG_METADATA_TOPIC_REPLICATION_FACTOR_PROP, INT,
DEFAULT_REMOTE_LOG_METADATA_TOPIC_REPLICATION_FACTOR, atLeast(1), LOW,
+ REMOTE_LOG_METADATA_TOPIC_REPLICATION_FACTOR_DOC)
+ .define(REMOTE_LOG_METADATA_TOPIC_PARTITIONS_PROP, INT,
DEFAULT_REMOTE_LOG_METADATA_TOPIC_PARTITION
[GitHub] [kafka] mdedetrich commented on pull request #10839: KAFKA-12913: Make case class's final
mdedetrich commented on pull request #10839: URL: https://github.com/apache/kafka/pull/10839#issuecomment-858409809 PR ready for review -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kowshik commented on a change in pull request #10280: KAFKA-12554: Refactor Log layer
kowshik commented on a change in pull request #10280:
URL: https://github.com/apache/kafka/pull/10280#discussion_r648955649
##
File path: core/src/main/scala/kafka/log/Log.scala
##
@@ -1812,37 +1570,39 @@ class Log(@volatile private var _dir: File,
endOffset: Long
): Unit = {
logStartOffset = startOffset
-nextOffsetMetadata = LogOffsetMetadata(endOffset,
activeSegment.baseOffset, activeSegment.size)
-recoveryPoint = math.min(recoveryPoint, endOffset)
+localLog.updateLogEndOffset(endOffset)
rebuildProducerState(endOffset, producerStateManager)
-updateHighWatermark(math.min(highWatermark, endOffset))
+if (highWatermark < localLog.logEndOffset)
Review comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] satishd commented on pull request #10733: KAFKA-12816 Added tiered storage related configs including remote log manager configs.
satishd commented on pull request #10733: URL: https://github.com/apache/kafka/pull/10733#issuecomment-858418575 @junrao @kowshik Gentle reminder to review these changes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #10820: KAFKA-12892: disable testChrootExistsAndRootIsLocked
showuon commented on pull request #10820: URL: https://github.com/apache/kafka/pull/10820#issuecomment-858424436 @omkreddy @ijuma , the trunk build keeps failing with `InvalidAclException` at least 1 build group (sometimes 2 or 3 failed) after the fix merged (in build # 199). I think this is worse than flaky tests since the build terminated suddenly without build report output. I still think we need to disable the failing test soon, and have further investigation. What do you think? 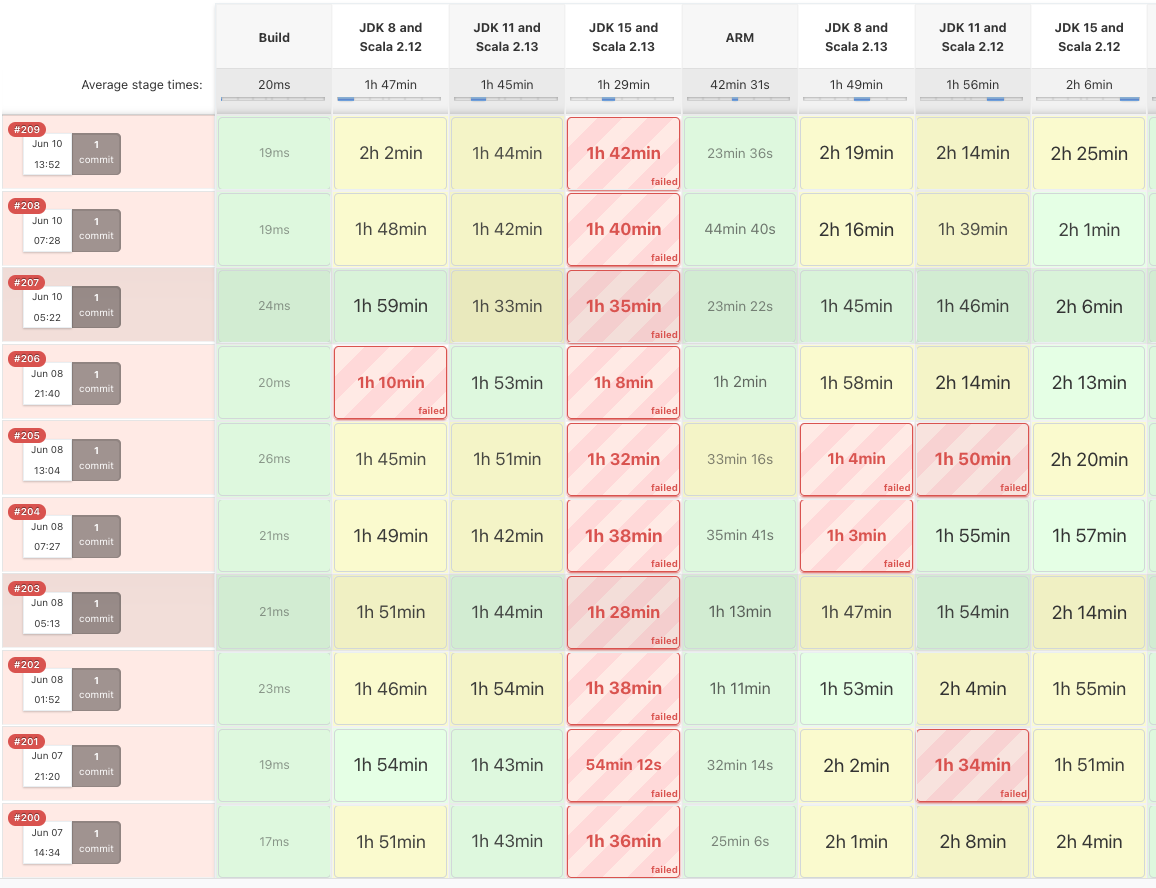 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-8335) Log cleaner skips Transactional mark and batch record, causing unlimited growth of __consumer_offsets
[ https://issues.apache.org/jira/browse/KAFKA-8335?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360656#comment-17360656 ] Francisco Juan commented on KAFKA-8335: --- We solved the issue by updating to version 2.5.1, then the [offsets.retention.minutes|https://kafka.apache.org/documentation/#brokerconfigs_offsets.retention.minutes] kicked in and the problem disappeared. > Log cleaner skips Transactional mark and batch record, causing unlimited > growth of __consumer_offsets > - > > Key: KAFKA-8335 > URL: https://issues.apache.org/jira/browse/KAFKA-8335 > Project: Kafka > Issue Type: Bug >Affects Versions: 2.2.0 >Reporter: Boquan Tang >Assignee: Jason Gustafson >Priority: Major > Fix For: 2.0.2, 2.1.2, 2.2.1 > > Attachments: seg_april_25.zip, segment.zip > > > My Colleague Weichu already sent out a mail to kafka user mailing list > regarding this issue, but we think it's worth having a ticket tracking it. > We are using Kafka Streams with exactly-once enabled on a Kafka cluster for > a while. > Recently we found that the size of __consumer_offsets partitions grew huge. > Some partition went over 30G. This caused Kafka to take quite long to load > "__consumer_offsets" topic on startup (it loads the topic in order to > become group coordinator). > We dumped the __consumer_offsets segments and found that while normal > offset commits are nicely compacted, transaction records (COMMIT, etc) are > all preserved. Looks like that since these messages don't have a key, the > LogCleaner is keeping them all: > -- > $ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files > /003484332061.log --key-decoder-class > kafka.serializer.StringDecoder 2>/dev/null | cat -v | head > Dumping 003484332061.log > Starting offset: 3484332061 > offset: 3484332089 position: 549 CreateTime: 1556003706952 isvalid: true > keysize: 4 valuesize: 6 magic: 2 compresscodec: NONE producerId: 1006 > producerEpoch: 2530 sequence: -1 isTransactional: true headerKeys: [] > endTxnMarker: COMMIT coordinatorEpoch: 81 > offset: 3484332090 position: 627 CreateTime: 1556003706952 isvalid: true > keysize: 4 valuesize: 6 magic: 2 compresscodec: NONE producerId: 4005 > producerEpoch: 2520 sequence: -1 isTransactional: true headerKeys: [] > endTxnMarker: COMMIT coordinatorEpoch: 84 > ... > -- > Streams is doing transaction commits per 100ms (commit.interval.ms=100 when > exactly-once) so the __consumer_offsets is growing really fast. > Is this (to keep all transactions) by design, or is that a bug for > LogCleaner? What would be the way to clean up the topic? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] kowshik commented on a change in pull request #10280: KAFKA-12554: Refactor Log layer
kowshik commented on a change in pull request #10280:
URL: https://github.com/apache/kafka/pull/10280#discussion_r648978604
##
File path: core/src/main/scala/kafka/log/Log.scala
##
@@ -1788,17 +1554,9 @@ class Log(@volatile private var _dir: File,
maybeHandleIOException(s"Error while truncating the entire log for
$topicPartition in dir ${dir.getParent}") {
debug(s"Truncate and start at offset $newOffset")
lock synchronized {
-checkIfMemoryMappedBufferClosed()
-removeAndDeleteSegments(logSegments, asyncDelete = true, LogTruncation)
-addSegment(LogSegment.open(dir,
- baseOffset = newOffset,
- config = config,
- time = time,
- initFileSize = config.initFileSize,
- preallocate = config.preallocate))
+localLog.truncateFullyAndStartAt(newOffset)
Review comment:
Done in 28bf22af168ca0db76796b5d3cd67a38ed8ed1c2.
##
File path: core/src/main/scala/kafka/log/Log.scala
##
@@ -1812,37 +1570,39 @@ class Log(@volatile private var _dir: File,
endOffset: Long
): Unit = {
logStartOffset = startOffset
-nextOffsetMetadata = LogOffsetMetadata(endOffset,
activeSegment.baseOffset, activeSegment.size)
-recoveryPoint = math.min(recoveryPoint, endOffset)
+localLog.updateLogEndOffset(endOffset)
rebuildProducerState(endOffset, producerStateManager)
-updateHighWatermark(math.min(highWatermark, endOffset))
+if (highWatermark < localLog.logEndOffset)
Review comment:
Done in 28bf22af168ca0db76796b5d3cd67a38ed8ed1c2.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 opened a new pull request #10860: MINOR: fix client_compatibility_features_test.py - DescribeAcls is al…
chia7712 opened a new pull request #10860: URL: https://github.com/apache/kafka/pull/10860 Kraft already supports `DescribeAcls` (see 5b0c58ed53c420e93957369516f34346580dac95). Hence, the flag `describe-acls-supported` should be `True` rather than `False` ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #10860: MINOR: fix client_compatibility_features_test.py - DescribeAcls is al…
chia7712 commented on pull request #10860: URL: https://github.com/apache/kafka/pull/10860#issuecomment-858436731 @rondagostino @ijuma Could you take a look? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10501) Log Cleaner never clean up some __consumer_offsets partitions
[
https://issues.apache.org/jira/browse/KAFKA-10501?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360662#comment-17360662
]
Victor Garcia commented on KAFKA-10501:
---
As per this response
https://issues.apache.org/jira/browse/KAFKA-8335?focusedCommentId=17360656&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17360656
It seems the issue gets fixed in 2.5.1
> Log Cleaner never clean up some __consumer_offsets partitions
> -
>
> Key: KAFKA-10501
> URL: https://issues.apache.org/jira/browse/KAFKA-10501
> Project: Kafka
> Issue Type: Bug
> Components: log, log cleaner
>Affects Versions: 2.5.0
>Reporter: Mykhailo Baluta
>Priority: Major
>
> Some __consumer_offsets partitions contain "broken" messages in the second
> log segment.
> Example:
> {code:java}
> offset: 745253728 position: 49793647 CreateTime: 1594539245536 isvalid: true
> keysize: 99 valuesize: 28 magic: 2 compresscodec: NONE producerId: 37146
> producerEpoch: 0 sequence: 0 isTransactional: true headerKeys: []
> offset: 745253729 position: 49793844 CreateTime: 1594539245548 isvalid: true
> keysize: 4 valuesize: 6 magic: 2 compresscodec: NONE producerId: 37146
> producerEpoch: 0 sequence: -1 isTransactional: true headerKeys: []
> endTxnMarker: COMMIT coordinatorEpoch: 59
> offset: 745256523 position: 50070884 CreateTime: 1594540927673 isvalid: true
> keysize: 4 valuesize: 6 magic: 2 compresscodec: NONE producerId: 37146
> producerEpoch: 1 sequence: -1 isTransactional: true headerKeys: []
> endTxnMarker: ABORT coordinatorEpoch: 59
> offset: 745256543 position: 50073185 CreateTime: 1594541667798 isvalid: true
> keysize: 99 valuesize: 28 magic: 2 compresscodec: NONE producerId: 37146
> producerEpoch: 0 sequence: 0 isTransactional: true headerKeys: []
> {code}
> Seems like the last 2 records are stored in the wrong order. As a result the
> last message is transactional and not any ABORT/COMMIT message after. It
> leads to a producer state with ongoing transactions and
> firstUncleanableDirtyOffset = 745256543. Thus, compaction always skips for
> such topic partitions.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] kowshik commented on pull request #10280: KAFKA-12554: Refactor Log layer
kowshik commented on pull request #10280: URL: https://github.com/apache/kafka/pull/10280#issuecomment-858438516 Thanks for the review @junrao! I've addressed your most recent comments in 28bf22af168ca0db76796b5d3cd67a38ed8ed1c2. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on a change in pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
cadonna commented on a change in pull request #10856:
URL: https://github.com/apache/kafka/pull/10856#discussion_r648988189
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/metrics/StreamsMetricsImpl.java
##
@@ -562,10 +553,6 @@ private String externalChildSensorName(final String
threadId, final String opera
+ SENSOR_NAME_DELIMITER + operationName;
}
-private String externalParentSensorName(final String threadId, final
String operationName) {
Review comment:
Same here
##
File path:
streams/src/main/java/org/apache/kafka/streams/StoreQueryParameters.java
##
@@ -25,8 +25,8 @@
*/
public class StoreQueryParameters {
-private Integer partition;
-private boolean staleStores;
+private final Integer partition;
+private final boolean staleStores;
Review comment:
The checkstyle rule used only checks local variables, not member fields:
```
```
See
https://checkstyle.sourceforge.io/apidocs/com/puppycrawl/tools/checkstyle/checks/coding/FinalLocalVariableCheck.html
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/metrics/StreamsMetricsImpl.java
##
@@ -294,14 +293,6 @@ public final void removeAllThreadLevelSensors(final String
threadId) {
return tagMap;
}
-public Map bufferLevelTagMap(final String threadId,
Review comment:
That is fine! Apparently I missed this method when I removed the old
Streams metrics structure. Thanks @jlprat !
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on pull request #9414: KAFKA-10585: Kafka Streams should clean up the state store directory from cleanup
dongjinleekr commented on pull request #9414: URL: https://github.com/apache/kafka/pull/9414#issuecomment-858453218 Rebased onto the latest trunk. cc/ @vvcephei -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mimaison commented on pull request #10665: KAFKA-9009: increase replica.lag.time.max.ms to make the test reliable
mimaison commented on pull request #10665: URL: https://github.com/apache/kafka/pull/10665#issuecomment-858466707 @showuon Sorry for the delay, thanks for the PR -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #10665: KAFKA-9009: increase replica.lag.time.max.ms to make the test reliable
showuon commented on pull request #10665: URL: https://github.com/apache/kafka/pull/10665#issuecomment-858472811 @mimaison , thanks for your time to review. :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-12928) Add a check whether the Task's statestore is actually a directory
Dongjin Lee created KAFKA-12928: --- Summary: Add a check whether the Task's statestore is actually a directory Key: KAFKA-12928 URL: https://issues.apache.org/jira/browse/KAFKA-12928 Project: Kafka Issue Type: Bug Components: streams Reporter: Dongjin Lee Assignee: Dongjin Lee I found this problem while working on [KAFKA-10585|https://issues.apache.org/jira/browse/KAFKA-10585]. As of present, StateDirectory checks whether the Task's statestore directory exists and, if not, creates it. Since it does not check whether it is actually a directory, for example, if a regular file occupies the Task's statestore's path, the validation logic may be detoured. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] mimaison merged pull request #10665: KAFKA-9009: increase replica.lag.time.max.ms to make the test reliable
mimaison merged pull request #10665: URL: https://github.com/apache/kafka/pull/10665 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jlprat commented on pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
jlprat commented on pull request #10856: URL: https://github.com/apache/kafka/pull/10856#issuecomment-858471996 Thanks both for the review! Shall I do something else, or is it ready to merge? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax opened a new pull request #10861: KAFKA-12909: disable spurious left/outer stream-stream join fix for old JoinWindows API
mjsax opened a new pull request #10861: URL: https://github.com/apache/kafka/pull/10861 We changed the behavior of left/outer stream-stream join via KAFKA-10847. To avoid a breaking change during an upgrade, we need to disable this fix by default. We only enable the fix if users opt-in expliclity by changing their code. We leverage KIP-633 (KAFKA-8613) that offers a new JoinWindows API with mandatory grace-period to enable the fix. Call for review @guozhangwang @spena @ableegoldman @izzyacademy -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr opened a new pull request #10862: KAFKA-12928: Add a check whether the Task's statestore is actually a directory
dongjinleekr opened a new pull request #10862: URL: https://github.com/apache/kafka/pull/10862 The first commit shows how to reproduce the problem, and the second commit is the fix. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on pull request #10862: KAFKA-12928: Add a check whether the Task's statestore is actually a directory
dongjinleekr commented on pull request #10862: URL: https://github.com/apache/kafka/pull/10862#issuecomment-858481552 @ableegoldman Please have a look when you are free. :pray: -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on a change in pull request #10861: KAFKA-12909: disable spurious left/outer stream-stream join fix for old JoinWindows API
mjsax commented on a change in pull request #10861:
URL: https://github.com/apache/kafka/pull/10861#discussion_r649031614
##
File path:
streams/src/main/java/org/apache/kafka/streams/kstream/JoinWindows.java
##
@@ -67,7 +67,7 @@
* @see KStream#outerJoin(KStream, ValueJoiner, JoinWindows, StreamJoined)
* @see TimestampExtractor
*/
-public final class JoinWindows extends Windows {
+public class JoinWindows extends Windows {
Review comment:
Need to change this to be able to add an `JoinWindowsInternal` to access
the newly added flag.
##
File path:
streams/src/main/java/org/apache/kafka/streams/kstream/internals/KStreamKStreamJoin.java
##
@@ -57,18 +58,22 @@
KStreamKStreamJoin(final boolean isLeftSide,
final String otherWindowName,
- final long joinBeforeMs,
- final long joinAfterMs,
- final long joinGraceMs,
+ final JoinWindowsInternal windows,
final ValueJoinerWithKey joiner,
final boolean outer,
final Optional outerJoinWindowName,
final KStreamImplJoin.MaxObservedStreamTime
maxObservedStreamTime) {
this.isLeftSide = isLeftSide;
this.otherWindowName = otherWindowName;
-this.joinBeforeMs = joinBeforeMs;
-this.joinAfterMs = joinAfterMs;
-this.joinGraceMs = joinGraceMs;
+if (isLeftSide) {
Review comment:
This was done by the caller before, ie, `KStreamImplJoin` from above. As
we only pass one parameter now, we need to do the flip here if necessary.
##
File path:
streams/src/test/java/org/apache/kafka/streams/kstream/internals/KStreamKStreamLeftJoinTest.java
##
@@ -88,7 +90,22 @@ public void testLeftJoinWithInvalidSpuriousResultFixFlag() {
}
@Test
-public void testLeftJoinWithSpuriousResultFixDisabled() {
+public void testLeftJoinWithSpuriousResultFixDisabledViaFeatureFlag() {
+runLeftJoinWithoutSpuriousResultFix(
+JoinWindows.ofTimeDifferenceAndGrace(ofMillis(100L), ofHours(24L)),
+false
+);
+}
+@Test
+public void testLeftJoinWithSpuriousResultFixDisabledOldApi() {
Review comment:
I duplicate this test, to verify that the feature flag, as well as the
old API disables this fix. Thus, the usage of the old API in this method should
not be changes via KIP-633 PR.
##
File path:
streams/src/main/java/org/apache/kafka/streams/kstream/internals/KStreamImplJoin.java
##
@@ -150,12 +150,11 @@ public long get() {
// Time shared between joins to keep track of the maximum stream time
final MaxObservedStreamTime maxObservedStreamTime = new
MaxObservedStreamTime();
+final JoinWindowsInternal internalWindows = new
JoinWindowsInternal(windows);
final KStreamKStreamJoin joinThis = new
KStreamKStreamJoin<>(
true,
otherWindowStore.name(),
-windows.beforeMs,
-windows.afterMs,
-windows.gracePeriodMs(),
+internalWindows,
Review comment:
Easier to pass one parameter instead of 4
##
File path:
streams/src/main/java/org/apache/kafka/streams/kstream/JoinWindows.java
##
@@ -76,18 +76,37 @@
private final long graceMs;
+protected final boolean enableSpuriousResultFix;
Review comment:
This is the new flag. We set it to `false` if the old methods are used,
and to `true` for the new methods from KIP-633.
##
File path:
streams/src/main/java/org/apache/kafka/streams/kstream/JoinWindows.java
##
@@ -114,7 +133,7 @@ public static JoinWindows of(final Duration timeDifference)
throws IllegalArgume
public JoinWindows before(final Duration timeDifference) throws
IllegalArgumentException {
final String msgPrefix =
prepareMillisCheckFailMsgPrefix(timeDifference, "timeDifference");
final long timeDifferenceMs =
validateMillisecondDuration(timeDifference, msgPrefix);
-return new JoinWindows(timeDifferenceMs, afterMs,
DEFAULT_GRACE_PERIOD_MS);
+return new JoinWindows(timeDifferenceMs, afterMs, graceMs,
enableSpuriousResultFix);
Review comment:
Side fix: `before()` resets grace to 24h (not sure why -- seems to be a
bug)
same for `after()` below.
##
File path:
streams/src/main/java/org/apache/kafka/streams/kstream/internals/KStreamKStreamJoin.java
##
@@ -82,20 +87,23 @@
private class KStreamKStreamJoinProcessor extends AbstractProcessor
{
private WindowStore otherWindowStore;
-private StreamsMetricsImpl metrics;
Review comment:
Side cleanup
##
File path:
streams/src/main/java/org/apache/kafka/streams/kstream/internals/graph/StreamStreamJoinNode.java
##
@@ -36,15 +36,13 @@
* Too much information to generalize, so St
[GitHub] [kafka] cadonna commented on pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
cadonna commented on pull request #10856: URL: https://github.com/apache/kafka/pull/10856#issuecomment-858494872 I restarted the checks since all three builds failed with exit code 1, which seems to be related to https://issues.apache.org/jira/browse/KAFKA-12892 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on pull request #10740: Kafka 8613 kip 633 drop default grace period streams
mjsax commented on pull request #10740: URL: https://github.com/apache/kafka/pull/10740#issuecomment-858495684 Please consider https://github.com/apache/kafka/pull/10861 that slightly overlaps with this PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on pull request #10835: KAFKA-12905: Replace EasyMock and PowerMock with Mockito for NamedCacheMetricsTest
cadonna commented on pull request #10835: URL: https://github.com/apache/kafka/pull/10835#issuecomment-858498491 Test failures are unrelated and known to be flaky: ``` Build / JDK 8 and Scala 2.12 / kafka.server.RaftClusterTest.testCreateClusterAndCreateAndManyTopicsWithManyPartitions() Build / JDK 15 and Scala 2.13 / kafka.server.RaftClusterTest.testCreateClusterAndCreateAndManyTopics() ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna merged pull request #10835: KAFKA-12905: Replace EasyMock and PowerMock with Mockito for NamedCacheMetricsTest
cadonna merged pull request #10835: URL: https://github.com/apache/kafka/pull/10835 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] satishd commented on a change in pull request #10848: MINOR Updated transaction index as optional in LogSegmentData.
satishd commented on a change in pull request #10848: URL: https://github.com/apache/kafka/pull/10848#discussion_r648768897 ## File path: storage/api/src/main/java/org/apache/kafka/server/log/remote/storage/LogSegmentData.java ## @@ -33,31 +34,32 @@ private final Path logSegment; private final Path offsetIndex; private final Path timeIndex; -private final Path txnIndex; +private final Optional transactionIndex; private final Path producerSnapshotIndex; private final ByteBuffer leaderEpochIndex; /** * Creates a LogSegmentData instance with data and indexes. - * @param logSegmentactual log segment file + * + * @param logSegmentactual log segment file * @param offsetIndex offset index file * @param timeIndex time index file - * @param txnIndex transaction index file + * @param transactionIndex transaction index file, which can be null * @param producerSnapshotIndex producer snapshot until this segment * @param leaderEpochIndex leader-epoch-index until this segment */ public LogSegmentData(Path logSegment, Path offsetIndex, Path timeIndex, - Path txnIndex, + Path transactionIndex, Review comment: Passing `Optional` as arguments is not considered as a good practice. We still need to do null check for that Optional instance. [SO answer from Brian Goetz](https://stackoverflow.com/questions/26327957/should-java-8-getters-return-optional-type/26328555#26328555) mentioned the right usage of `Optional`. I have also updated PR not to use it as a field. ``` You should almost never use it as a field of something or a method parameter. ``` [Javadoc of Optional ](https://docs.oracle.com/javase/10/docs/api/java/util/Optional.html)suggests returning as an argument mentioned below. ``` API Note: Optional is primarily intended for use as a method return type where there is a clear need to represent "no result," and where using null is likely to cause errors. A variable whose type is Optional should never itself be null; it should always point to an Optional instance. ``` Having said that, I do not have strong opinions on the above. I am fine with the conventions that we are following in this project if we have any on `Optional` usage. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] edoardocomar commented on pull request #10649: KAFKA-12762: Use connection timeout when polling the network for new …
edoardocomar commented on pull request #10649: URL: https://github.com/apache/kafka/pull/10649#issuecomment-858526433 Hi @rajinisivaram would you be able to take a look ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] wycccccc commented on a change in pull request #10850: KAFKA-12924 Replace EasyMock and PowerMock with Mockito in streams (metrics)
wycc commented on a change in pull request #10850:
URL: https://github.com/apache/kafka/pull/10850#discussion_r649082247
##
File path:
streams/src/test/java/org/apache/kafka/streams/processor/internals/metrics/ProcessorNodeMetricsTest.java
##
@@ -18,87 +18,73 @@
import org.apache.kafka.common.metrics.Sensor;
import org.apache.kafka.common.metrics.Sensor.RecordingLevel;
-import
org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.Version;
-import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
-import org.powermock.core.classloader.annotations.PrepareForTest;
-import org.powermock.modules.junit4.PowerMockRunner;
+import org.mockito.Mockito;
+import org.mockito.junit.MockitoJUnitRunner;
+
import java.util.Collections;
import java.util.Map;
import java.util.function.Supplier;
import static
org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.PROCESSOR_NODE_LEVEL_GROUP;
-import static org.easymock.EasyMock.expect;
-import static org.easymock.EasyMock.mock;
import static org.hamcrest.CoreMatchers.is;
import static org.hamcrest.MatcherAssert.assertThat;
-import static org.powermock.api.easymock.PowerMock.createMock;
-import static org.powermock.api.easymock.PowerMock.mockStatic;
-import static org.powermock.api.easymock.PowerMock.replay;
-import static org.powermock.api.easymock.PowerMock.verify;
-@RunWith(PowerMockRunner.class)
-@PrepareForTest({StreamsMetricsImpl.class, Sensor.class})
+@RunWith(MockitoJUnitRunner.class)
public class ProcessorNodeMetricsTest {
private static final String THREAD_ID = "test-thread";
private static final String TASK_ID = "test-task";
private static final String PROCESSOR_NODE_ID = "test-processor";
-private final Sensor expectedSensor = mock(Sensor.class);
-private final Sensor expectedParentSensor = mock(Sensor.class);
-private final StreamsMetricsImpl streamsMetrics =
createMock(StreamsMetricsImpl.class);
private final Map tagMap =
Collections.singletonMap("hello", "world");
private final Map parentTagMap =
Collections.singletonMap("hi", "universe");
-@Before
-public void setUp() {
-expect(streamsMetrics.version()).andStubReturn(Version.LATEST);
-mockStatic(StreamsMetricsImpl.class);
-}
+private final Sensor expectedSensor = Mockito.mock(Sensor.class);
Review comment:
Thanks for the reminder, I will pay attention it in next pr.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-12847) Dockerfile needed for kafka system tests needs changes
[
https://issues.apache.org/jira/browse/KAFKA-12847?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360752#comment-17360752
]
Abhijit Mane commented on KAFKA-12847:
--
Thanks [~chia7712] for the explanation. I understand the above concept. I
analyzed further & seem to have narrowed down the issue: -
As you are aware, sysTests ("bash tests/docker/run_tests.sh") first build the
image below: -
-
As root,
root> docker build
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=0*_ \
-t ducker-ak-openjdk-8 .
*Fails - useradd: UID 0 is not unique**_, root user id is 0_***
As non-root (postgres: uid=26, '*ducker*' uid inside container is also 26), it
succeeds.
postgres> docker build \
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=26*_ \
-t ducker-ak-openjdk-8 .
-
So, it works as non-root but as root user running the sysTests, they fail as
shown above. So, using a non-conflicting name such as UID_DUCKER should allow
it to work for root as well which I believe is valid or maybe a note in README
asking to run only as non-root is also suitable.
Please let me know your thoughts.
> Dockerfile needed for kafka system tests needs changes
> --
>
> Key: KAFKA-12847
> URL: https://issues.apache.org/jira/browse/KAFKA-12847
> Project: Kafka
> Issue Type: Bug
> Components: system tests
>Affects Versions: 2.8.0, 2.7.1
> Environment: Issue tested in environments below but is independent of
> h/w arch. or Linux flavor: -
> 1.) RHEL-8.3 on x86_64
> 2.) RHEL-8.3 on IBM Power (ppc64le)
> 3.) apache/kafka branch tested: trunk (master)
>Reporter: Abhijit Mane
>Assignee: Abhijit Mane
>Priority: Major
> Labels: easyfix
> Attachments: Dockerfile.upstream, 截圖 2021-06-05 上午1.53.17.png
>
>
> Hello,
> I tried apache/kafka system tests as per documentation: -
> ([https://github.com/apache/kafka/tree/trunk/tests#readme|https://github.com/apache/kafka/tree/trunk/tests#readme_])
> =
> PROBLEM
> ~~
> 1.) As root user, clone kafka github repo and start "kafka system tests"
> # git clone [https://github.com/apache/kafka.git]
> # cd kafka
> # ./gradlew clean systemTestLibs
> # bash tests/docker/run_tests.sh
> 2.) Dockerfile issue -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> This file has an *UID* entry as shown below: -
> ---
> ARG *UID*="1000"
> RUN useradd -u $*UID* ducker
> // {color:#de350b}*Error during docker build*{color} => useradd: UID 0 is not
> unique, root user id is 0
> ---
> I ran everything as root which means the built-in bash environment variable
> 'UID' always
> resolves to 0 and can't be changed. Hence, the docker build fails. The issue
> should be seen even if run as non-root.
> 3.) Next, as root, as per README, I ran: -
> server:/kafka> *bash tests/docker/run_tests.sh*
> The ducker tool builds the container images & switches to user '*ducker*'
> inside the container
> & maps kafka root dir ('kafka') from host to '/opt/kafka-dev' in the
> container.
> Ref:
> [https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak|https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak]
> Ex: docker run -d *-v "${kafka_dir}:/opt/kafka-dev"*
> This fails as the 'ducker' user has *no write permissions* to create files
> under 'kafka' root dir. Hence, it needs to be made writeable.
> // *chmod -R a+w kafka*
> – needed as container is run as 'ducker' and needs write access since kafka
> root volume from host is mapped to container as "/opt/kafka-dev" where the
> 'ducker' user writes logs
> =
> =
> *FIXES needed*
> ~
> 1.) Dockerfile -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> Change 'UID' to '*UID_DUCKER*'.
> This won't conflict with built in bash env. var UID and the docker image
> build should succeed.
> ---
> ARG *UID_DUCKER*="1000"
> RUN useradd -u $*UID_DUCKER* ducker
> // *{color:#57d9a3}No Error{color}* => No conflict with built-in UID
> ---
> 2.) README needs an update where we must ensure the kafka root dir from where
> the tests
> are launched is writeable to allow the 'ducker' user to create results/logs.
> # chmod -R a+w kafka
> With this, I was able to get the docker images built and system tests started
> successfully.
> =
> Also
[jira] [Comment Edited] (KAFKA-12847) Dockerfile needed for kafka system tests needs changes
[
https://issues.apache.org/jira/browse/KAFKA-12847?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360752#comment-17360752
]
Abhijit Mane edited comment on KAFKA-12847 at 6/10/21, 11:11 AM:
-
Thanks [~chia7712] for the explanation. I understand the above concept. I
analyzed further & seem to have narrowed down the issue: -
As you are aware, sysTests ("bash tests/docker/run_tests.sh") first builds the
image below: -
-
As root,
root> docker build
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=0*_ \
-t ducker-ak-openjdk-8 .
*Fails - useradd: UID 0 is not unique**_, root user id is 0_***
As non-root (postgres: uid=26, '*ducker*' uid inside container is also 26), it
succeeds.
postgres> docker build \
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=26*_ \
-t ducker-ak-openjdk-8 .
-
So, it works as non-root but as root user running the sysTests, they fail as
shown above. So, using a non-conflicting name such as UID_DUCKER should allow
it to work for root as well which I believe is valid or maybe a note in README
asking to run only as non-root is also suitable.
Please let me know your thoughts.
was (Author: abhijmanrh):
Thanks [~chia7712] for the explanation. I understand the above concept. I
analyzed further & seem to have narrowed down the issue: -
As you are aware, sysTests ("bash tests/docker/run_tests.sh") first build the
image below: -
-
As root,
root> docker build
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=0*_ \
-t ducker-ak-openjdk-8 .
*Fails - useradd: UID 0 is not unique**_, root user id is 0_***
As non-root (postgres: uid=26, '*ducker*' uid inside container is also 26), it
succeeds.
postgres> docker build \
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=26*_ \
-t ducker-ak-openjdk-8 .
-
So, it works as non-root but as root user running the sysTests, they fail as
shown above. So, using a non-conflicting name such as UID_DUCKER should allow
it to work for root as well which I believe is valid or maybe a note in README
asking to run only as non-root is also suitable.
Please let me know your thoughts.
> Dockerfile needed for kafka system tests needs changes
> --
>
> Key: KAFKA-12847
> URL: https://issues.apache.org/jira/browse/KAFKA-12847
> Project: Kafka
> Issue Type: Bug
> Components: system tests
>Affects Versions: 2.8.0, 2.7.1
> Environment: Issue tested in environments below but is independent of
> h/w arch. or Linux flavor: -
> 1.) RHEL-8.3 on x86_64
> 2.) RHEL-8.3 on IBM Power (ppc64le)
> 3.) apache/kafka branch tested: trunk (master)
>Reporter: Abhijit Mane
>Assignee: Abhijit Mane
>Priority: Major
> Labels: easyfix
> Attachments: Dockerfile.upstream, 截圖 2021-06-05 上午1.53.17.png
>
>
> Hello,
> I tried apache/kafka system tests as per documentation: -
> ([https://github.com/apache/kafka/tree/trunk/tests#readme|https://github.com/apache/kafka/tree/trunk/tests#readme_])
> =
> PROBLEM
> ~~
> 1.) As root user, clone kafka github repo and start "kafka system tests"
> # git clone [https://github.com/apache/kafka.git]
> # cd kafka
> # ./gradlew clean systemTestLibs
> # bash tests/docker/run_tests.sh
> 2.) Dockerfile issue -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> This file has an *UID* entry as shown below: -
> ---
> ARG *UID*="1000"
> RUN useradd -u $*UID* ducker
> // {color:#de350b}*Error during docker build*{color} => useradd: UID 0 is not
> unique, root user id is 0
> ---
> I ran everything as root which means the built-in bash environment variable
> 'UID' always
> resolves to 0 and can't be changed. Hence, the docker build fails. The issue
> should be seen even if run as non-root.
> 3.) Next, as root, as per README, I ran: -
> server:/kafka> *bash tests/docker/run_tests.sh*
> The ducker tool builds the container images & switches to user '*ducker*'
> inside the container
> & maps kafka root dir ('kafka') from host to '/opt/kafka-dev' in the
> container.
> Ref:
> [https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak|https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak]
> Ex: docker run -d *-v "${kafka_dir}:/opt/kafka-dev"*
> Th
[jira] [Comment Edited] (KAFKA-12847) Dockerfile needed for kafka system tests needs changes
[
https://issues.apache.org/jira/browse/KAFKA-12847?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360752#comment-17360752
]
Abhijit Mane edited comment on KAFKA-12847 at 6/10/21, 11:12 AM:
-
Thanks [~chia7712] for the explanation. I understand the above concept. I
analyzed further & seem to have narrowed down the issue: -
As you are aware, sysTests ("bash tests/docker/run_tests.sh") first builds the
image below: -
-
As root,
root> docker build
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=0*_ \
-t ducker-ak-openjdk-8 .
"RUN useradd -u $UID ducker" step => *Fails - useradd: UID 0 is not unique**_,
root user id is 0_***
As non-root (postgres: uid=26, '*ducker*' uid inside container is also 26), it
succeeds.
postgres> docker build \
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=26*_ \
-t ducker-ak-openjdk-8 .
-
So, it works as non-root but as root user running the sysTests, they fail as
shown above. So, using a non-conflicting name such as UID_DUCKER should allow
it to work for root as well which I believe is valid or maybe a note in README
asking to run only as non-root is also suitable.
Please let me know your thoughts.
was (Author: abhijmanrh):
Thanks [~chia7712] for the explanation. I understand the above concept. I
analyzed further & seem to have narrowed down the issue: -
As you are aware, sysTests ("bash tests/docker/run_tests.sh") first builds the
image below: -
-
As root,
root> docker build
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=0*_ \
-t ducker-ak-openjdk-8 .
*Fails - useradd: UID 0 is not unique**_, root user id is 0_***
As non-root (postgres: uid=26, '*ducker*' uid inside container is also 26), it
succeeds.
postgres> docker build \
--build-arg ducker_creator= \
--build-arg jdk_version=openjdk:8 \
--build-arg _*UID=26*_ \
-t ducker-ak-openjdk-8 .
-
So, it works as non-root but as root user running the sysTests, they fail as
shown above. So, using a non-conflicting name such as UID_DUCKER should allow
it to work for root as well which I believe is valid or maybe a note in README
asking to run only as non-root is also suitable.
Please let me know your thoughts.
> Dockerfile needed for kafka system tests needs changes
> --
>
> Key: KAFKA-12847
> URL: https://issues.apache.org/jira/browse/KAFKA-12847
> Project: Kafka
> Issue Type: Bug
> Components: system tests
>Affects Versions: 2.8.0, 2.7.1
> Environment: Issue tested in environments below but is independent of
> h/w arch. or Linux flavor: -
> 1.) RHEL-8.3 on x86_64
> 2.) RHEL-8.3 on IBM Power (ppc64le)
> 3.) apache/kafka branch tested: trunk (master)
>Reporter: Abhijit Mane
>Assignee: Abhijit Mane
>Priority: Major
> Labels: easyfix
> Attachments: Dockerfile.upstream, 截圖 2021-06-05 上午1.53.17.png
>
>
> Hello,
> I tried apache/kafka system tests as per documentation: -
> ([https://github.com/apache/kafka/tree/trunk/tests#readme|https://github.com/apache/kafka/tree/trunk/tests#readme_])
> =
> PROBLEM
> ~~
> 1.) As root user, clone kafka github repo and start "kafka system tests"
> # git clone [https://github.com/apache/kafka.git]
> # cd kafka
> # ./gradlew clean systemTestLibs
> # bash tests/docker/run_tests.sh
> 2.) Dockerfile issue -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> This file has an *UID* entry as shown below: -
> ---
> ARG *UID*="1000"
> RUN useradd -u $*UID* ducker
> // {color:#de350b}*Error during docker build*{color} => useradd: UID 0 is not
> unique, root user id is 0
> ---
> I ran everything as root which means the built-in bash environment variable
> 'UID' always
> resolves to 0 and can't be changed. Hence, the docker build fails. The issue
> should be seen even if run as non-root.
> 3.) Next, as root, as per README, I ran: -
> server:/kafka> *bash tests/docker/run_tests.sh*
> The ducker tool builds the container images & switches to user '*ducker*'
> inside the container
> & maps kafka root dir ('kafka') from host to '/opt/kafka-dev' in the
> container.
> Ref:
> [https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak|https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak]
> Ex: docker run -d
[jira] [Commented] (KAFKA-12847) Dockerfile needed for kafka system tests needs changes
[
https://issues.apache.org/jira/browse/KAFKA-12847?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360767#comment-17360767
]
Chia-Ping Tsai commented on KAFKA-12847:
> it works as non-root but as root user running the sysTests, they fail as
> shown above. So, it works as non-root but as root user running the sysTests,
> they fail as shown above. So, using a non-conflicting name such as UID_DUCKER
> should allow it to work for root as well which
Please take a look at my first comment "Not only system tests but also UT/IT
expect to be run by non-root. ". I'm not convinced that running test by root is
a normal way.
> I believe is valid or maybe a note in README asking to run only as non-root
> is also suitable.
this is a good idea.
> Dockerfile needed for kafka system tests needs changes
> --
>
> Key: KAFKA-12847
> URL: https://issues.apache.org/jira/browse/KAFKA-12847
> Project: Kafka
> Issue Type: Bug
> Components: system tests
>Affects Versions: 2.8.0, 2.7.1
> Environment: Issue tested in environments below but is independent of
> h/w arch. or Linux flavor: -
> 1.) RHEL-8.3 on x86_64
> 2.) RHEL-8.3 on IBM Power (ppc64le)
> 3.) apache/kafka branch tested: trunk (master)
>Reporter: Abhijit Mane
>Assignee: Abhijit Mane
>Priority: Major
> Labels: easyfix
> Attachments: Dockerfile.upstream, 截圖 2021-06-05 上午1.53.17.png
>
>
> Hello,
> I tried apache/kafka system tests as per documentation: -
> ([https://github.com/apache/kafka/tree/trunk/tests#readme|https://github.com/apache/kafka/tree/trunk/tests#readme_])
> =
> PROBLEM
> ~~
> 1.) As root user, clone kafka github repo and start "kafka system tests"
> # git clone [https://github.com/apache/kafka.git]
> # cd kafka
> # ./gradlew clean systemTestLibs
> # bash tests/docker/run_tests.sh
> 2.) Dockerfile issue -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> This file has an *UID* entry as shown below: -
> ---
> ARG *UID*="1000"
> RUN useradd -u $*UID* ducker
> // {color:#de350b}*Error during docker build*{color} => useradd: UID 0 is not
> unique, root user id is 0
> ---
> I ran everything as root which means the built-in bash environment variable
> 'UID' always
> resolves to 0 and can't be changed. Hence, the docker build fails. The issue
> should be seen even if run as non-root.
> 3.) Next, as root, as per README, I ran: -
> server:/kafka> *bash tests/docker/run_tests.sh*
> The ducker tool builds the container images & switches to user '*ducker*'
> inside the container
> & maps kafka root dir ('kafka') from host to '/opt/kafka-dev' in the
> container.
> Ref:
> [https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak|https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak]
> Ex: docker run -d *-v "${kafka_dir}:/opt/kafka-dev"*
> This fails as the 'ducker' user has *no write permissions* to create files
> under 'kafka' root dir. Hence, it needs to be made writeable.
> // *chmod -R a+w kafka*
> – needed as container is run as 'ducker' and needs write access since kafka
> root volume from host is mapped to container as "/opt/kafka-dev" where the
> 'ducker' user writes logs
> =
> =
> *FIXES needed*
> ~
> 1.) Dockerfile -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> Change 'UID' to '*UID_DUCKER*'.
> This won't conflict with built in bash env. var UID and the docker image
> build should succeed.
> ---
> ARG *UID_DUCKER*="1000"
> RUN useradd -u $*UID_DUCKER* ducker
> // *{color:#57d9a3}No Error{color}* => No conflict with built-in UID
> ---
> 2.) README needs an update where we must ensure the kafka root dir from where
> the tests
> are launched is writeable to allow the 'ducker' user to create results/logs.
> # chmod -R a+w kafka
> With this, I was able to get the docker images built and system tests started
> successfully.
> =
> Also, I wonder whether or not upstream Dockerfile & System tests are part of
> CI/CD and get tested for every PR. If so, this issue should have been caught.
>
> *Question to kafka SME*
> -
> Do you believe this is a valid problem with the Dockerfile and the fix is
> acceptable?
> Please let me know and I am happy to submit a PR with this fix.
> Thanks,
> Abhijit
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] jlprat commented on pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
jlprat commented on pull request #10856: URL: https://github.com/apache/kafka/pull/10856#issuecomment-858573500 Yes, I see that the part of the build running the test is finishing with exit code 1. The one checking the compilation, spotbugs, and co finished successfully, though. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mdedetrich commented on pull request #10775: KAFKA-12668: Making MockScheduler.schedule safe to use in concurrent code
mdedetrich commented on pull request #10775: URL: https://github.com/apache/kafka/pull/10775#issuecomment-858574856 It seems that the `scheduler.tick()` method is a workaround rather than solving the actual problem. From what I understand you are just suspending the scheduler and as a result of that the scheduler then hops back into the original background thread. If the `MockScheduler` changes the internal workings of task execution on threads then this can break the unspecified behavior? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on a change in pull request #10428: KAFKA-12572: Add import ordering checkstyle rule and configure an automatic formatter
cadonna commented on a change in pull request #10428:
URL: https://github.com/apache/kafka/pull/10428#discussion_r649131550
##
File path: build.gradle
##
@@ -604,6 +625,9 @@ subprojects {
description = 'Run checkstyle on all main Java sources'
}
+ checkstyleMain.dependsOn('spotlessApply')
+ checkstyleTest.dependsOn('spotlessApply')
Review comment:
Ah, now I see. I missed the if statement for the modules above on line
602.
##
File path: README.md
##
@@ -207,6 +207,20 @@ You can run checkstyle using:
The checkstyle warnings will be found in
`reports/checkstyle/reports/main.html` and
`reports/checkstyle/reports/test.html` files in the
subproject build directories. They are also printed to the console. The build
will fail if Checkstyle fails.
+As of present, the auto-formatting configuration is work in progress.
Auto-formatting is automatically invoked for the modules listed below when the
'checkstyleMain' or 'checkstyleTest' task is run.
+
+- (No modules specified yet)
+
+You can also run auto-formatting independently for a single module listed
above, like:
+
+./gradlew :core:spotlessApply # auto-format *.java files in core module,
without running checkstyleMain or checkstyleTest.
+
+If you are using an IDE, you can use a plugin that provides real-time
automatic formatting. For detailed information, refer to the following links:
+
+- [Eclipse](https://checkstyle.org/eclipse-cs)
+- [Intellij](https://plugins.jetbrains.com/plugin/1065-checkstyle-idea)
+-
[Vscode](https://marketplace.visualstudio.com/items?itemName=shengchen.vscode-checkstyle)
+
Review comment:
Yes, but before at least one module does not apply automatic formatting,
I would remove this description because until then it is useless.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cadonna commented on a change in pull request #10428: KAFKA-12572: Add import ordering checkstyle rule and configure an automatic formatter
cadonna commented on a change in pull request #10428: URL: https://github.com/apache/kafka/pull/10428#discussion_r649130665 ## File path: README.md ## @@ -207,6 +207,20 @@ You can run checkstyle using: The checkstyle warnings will be found in `reports/checkstyle/reports/main.html` and `reports/checkstyle/reports/test.html` files in the subproject build directories. They are also printed to the console. The build will fail if Checkstyle fails. +As of present, the auto-formatting configuration is work in progress. Auto-formatting is automatically invoked for the modules listed below when the 'checkstyleMain' or 'checkstyleTest' task is run. + +- (No modules specified yet) + +You can also run auto-formatting independently for a single module listed above, like: + +./gradlew :core:spotlessApply # auto-format *.java files in core module, without running checkstyleMain or checkstyleTest. + +If you are using an IDE, you can use a plugin that provides real-time automatic formatting. For detailed information, refer to the following links: + +- [Eclipse](https://checkstyle.org/eclipse-cs) +- [Intellij](https://plugins.jetbrains.com/plugin/1065-checkstyle-idea) +- [Vscode](https://marketplace.visualstudio.com/items?itemName=shengchen.vscode-checkstyle) + Review comment: Yes, but before at least one module applies automatic formatting, I would remove this description because until then it is useless. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on a change in pull request #10428: KAFKA-12572: Add import ordering checkstyle rule and configure an automatic formatter
dongjinleekr commented on a change in pull request #10428: URL: https://github.com/apache/kafka/pull/10428#discussion_r649135659 ## File path: README.md ## @@ -207,6 +207,20 @@ You can run checkstyle using: The checkstyle warnings will be found in `reports/checkstyle/reports/main.html` and `reports/checkstyle/reports/test.html` files in the subproject build directories. They are also printed to the console. The build will fail if Checkstyle fails. +As of present, the auto-formatting configuration is work in progress. Auto-formatting is automatically invoked for the modules listed below when the 'checkstyleMain' or 'checkstyleTest' task is run. + +- (No modules specified yet) + +You can also run auto-formatting independently for a single module listed above, like: + +./gradlew :core:spotlessApply # auto-format *.java files in core module, without running checkstyleMain or checkstyleTest. + +If you are using an IDE, you can use a plugin that provides real-time automatic formatting. For detailed information, refer to the following links: + +- [Eclipse](https://checkstyle.org/eclipse-cs) +- [Intellij](https://plugins.jetbrains.com/plugin/1065-checkstyle-idea) +- [Vscode](https://marketplace.visualstudio.com/items?itemName=shengchen.vscode-checkstyle) + Review comment: Okay. I will move this section into the other subissue. :+1: -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on pull request #10428: KAFKA-12572: Add import ordering checkstyle rule and configure an automatic formatter
dongjinleekr commented on pull request #10428: URL: https://github.com/apache/kafka/pull/10428#issuecomment-858588665 @cadonna Here it is. Rebased onto the latest trunk and removed the formatting section from `README.md`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12468) Initial offsets are copied from source to target cluster
[
https://issues.apache.org/jira/browse/KAFKA-12468?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360866#comment-17360866
]
Alan Ning commented on KAFKA-12468:
---
I am running standalone mode, so I am not sure if tasks.max propagate to all
connectors. I think it does. Which mode are you running in? If you are in
distributed mode, I would consider setting tasks.max on each connector.
> Initial offsets are copied from source to target cluster
>
>
> Key: KAFKA-12468
> URL: https://issues.apache.org/jira/browse/KAFKA-12468
> Project: Kafka
> Issue Type: Bug
> Components: mirrormaker
>Affects Versions: 2.7.0
>Reporter: Bart De Neuter
>Priority: Major
>
> We have an active-passive setup where the 3 connectors from mirror maker 2
> (heartbeat, checkpoint and source) are running on a dedicated Kafka connect
> cluster on the target cluster.
> Offset syncing is enabled as specified by KIP-545. But when activated, it
> seems the offsets from the source cluster are initially copied to the target
> cluster without translation. This causes a negative lag for all synced
> consumer groups. Only when we reset the offsets for each topic/partition on
> the target cluster and produce a record on the topic/partition in the source,
> the sync starts working correctly.
> I would expect that the consumer groups are synced but that the current
> offsets of the source cluster are not copied to the target cluster.
> This is the configuration we are currently using:
> Heartbeat connector
>
> {code:xml}
> {
> "name": "mm2-mirror-heartbeat",
> "config": {
> "name": "mm2-mirror-heartbeat",
> "connector.class":
> "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector",
> "source.cluster.alias": "eventador",
> "target.cluster.alias": "msk",
> "source.cluster.bootstrap.servers": "",
> "target.cluster.bootstrap.servers": "",
> "topics": ".*",
> "groups": ".*",
> "tasks.max": "1",
> "replication.policy.class": "CustomReplicationPolicy",
> "sync.group.offsets.enabled": "true",
> "sync.group.offsets.interval.seconds": "5",
> "emit.checkpoints.enabled": "true",
> "emit.checkpoints.interval.seconds": "30",
> "emit.heartbeats.interval.seconds": "30",
> "key.converter": "
> org.apache.kafka.connect.converters.ByteArrayConverter",
> "value.converter":
> "org.apache.kafka.connect.converters.ByteArrayConverter"
> }
> }
> {code}
> Checkpoint connector:
> {code:xml}
> {
> "name": "mm2-mirror-checkpoint",
> "config": {
> "name": "mm2-mirror-checkpoint",
> "connector.class":
> "org.apache.kafka.connect.mirror.MirrorCheckpointConnector",
> "source.cluster.alias": "eventador",
> "target.cluster.alias": "msk",
> "source.cluster.bootstrap.servers": "",
> "target.cluster.bootstrap.servers": "",
> "topics": ".*",
> "groups": ".*",
> "tasks.max": "40",
> "replication.policy.class": "CustomReplicationPolicy",
> "sync.group.offsets.enabled": "true",
> "sync.group.offsets.interval.seconds": "5",
> "emit.checkpoints.enabled": "true",
> "emit.checkpoints.interval.seconds": "30",
> "emit.heartbeats.interval.seconds": "30",
> "key.converter": "
> org.apache.kafka.connect.converters.ByteArrayConverter",
> "value.converter":
> "org.apache.kafka.connect.converters.ByteArrayConverter"
> }
> }
> {code}
> Source connector:
> {code:xml}
> {
> "name": "mm2-mirror-source",
> "config": {
> "name": "mm2-mirror-source",
> "connector.class":
> "org.apache.kafka.connect.mirror.MirrorSourceConnector",
> "source.cluster.alias": "eventador",
> "target.cluster.alias": "msk",
> "source.cluster.bootstrap.servers": "",
> "target.cluster.bootstrap.servers": "",
> "topics": ".*",
> "groups": ".*",
> "tasks.max": "40",
> "replication.policy.class": "CustomReplicationPolicy",
> "sync.group.offsets.enabled": "true",
> "sync.group.offsets.interval.seconds": "5",
> "emit.checkpoints.enabled": "true",
> "emit.checkpoints.interval.seconds": "30",
> "emit.heartbeats.interval.seconds": "30",
> "key.converter": "
> org.apache.kafka.connect.converters.ByteArrayConverter",
> "value.converter":
> "org.apache.kafka.connect.converters.ByteArrayConverter"
> }
> }
> {code}
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] tang7526 commented on a change in pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 commented on a change in pull request #10588:
URL: https://github.com/apache/kafka/pull/10588#discussion_r649155161
##
File path:
tools/src/test/java/org/apache/kafka/tools/ProducerPerformanceTest.java
##
@@ -0,0 +1,164 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.tools;
+
+import org.apache.kafka.clients.producer.KafkaProducer;
+import org.apache.kafka.clients.producer.Callback;
+import org.junit.jupiter.api.Test;
+import org.junit.jupiter.api.extension.ExtendWith;
+import org.mockito.ArgumentMatchers;
+import org.mockito.Mock;
+import org.mockito.Spy;
+import org.mockito.junit.jupiter.MockitoExtension;
+
+import net.sourceforge.argparse4j.inf.ArgumentParser;
+import net.sourceforge.argparse4j.inf.ArgumentParserException;
+
+import java.io.File;
+import java.io.FileWriter;
+import java.io.IOException;
+import java.io.UnsupportedEncodingException;
+import java.nio.charset.StandardCharsets;
+import java.util.ArrayList;
+import java.util.Collections;
+import java.util.List;
+import java.util.Properties;
+import java.util.Random;
+
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import static org.junit.jupiter.api.Assertions.assertFalse;
+import static org.junit.jupiter.api.Assertions.assertNotNull;
+import static org.junit.jupiter.api.Assertions.assertThrows;
+import static org.mockito.ArgumentMatchers.any;
+import static org.mockito.Mockito.doReturn;
+import static org.mockito.Mockito.times;
+import static org.mockito.Mockito.verify;
+
+@ExtendWith(MockitoExtension.class)
+public class ProducerPerformanceTest {
+
+@Mock
+KafkaProducer producerMock;
+
+@Spy
+ProducerPerformance producerPerformanceSpy;
+
+private File createTempFile(String contents) throws IOException {
+File file = File.createTempFile("ProducerPerformanceTest", ".tmp");
+file.deleteOnExit();
+final FileWriter writer = new FileWriter(file);
+writer.write(contents);
+writer.close();
+return file;
+}
+
+@Test
+public void testReadPayloadFile() throws Exception {
+File payloadFile = createTempFile("Hello\nKafka");
+String payloadFilePath = payloadFile.getAbsolutePath();
+String payloadDelimiter = "\n";
+
+List payloadByteList =
ProducerPerformance.readPayloadFile(payloadFilePath, payloadDelimiter);
+
+assertEquals(2, payloadByteList.size());
+assertEquals("Hello", new String(payloadByteList.get(0)));
+assertEquals("Kafka", new String(payloadByteList.get(1)));
+}
+
+@Test
+public void testReadProps() throws Exception {
+
+List producerProps =
Collections.singletonList("bootstrap.servers=localhost:9000");
+String producerConfig = createTempFile("acks=1").getAbsolutePath();
+String transactionalId = "1234";
+boolean transactionsEnabled = true;
+
+Properties prop = ProducerPerformance.readProps(producerProps,
producerConfig, transactionalId, transactionsEnabled);
+
+assertNotNull(prop);
+assertEquals(5, prop.size());
+}
+
+@Test
+public void testNumberOfCallsForSendAndClose() throws IOException {
+
+doReturn(null).when(producerMock).send(any(),
ArgumentMatchers.any());
+
doReturn(producerMock).when(producerPerformanceSpy).createKafkaProducer(any(Properties.class));
+
+String[] args = new String[] {"--topic", "Hello-Kafka",
"--num-records", "5", "--throughput", "100", "--record-size", "100",
"--producer-props", "bootstrap.servers=localhost:9000"};
+producerPerformanceSpy.start(args);
+verify(producerMock, times(5)).send(any(),
ArgumentMatchers.any());
Review comment:
Done. I have removed it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] tang7526 commented on a change in pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 commented on a change in pull request #10588:
URL: https://github.com/apache/kafka/pull/10588#discussion_r649155454
##
File path:
tools/src/test/java/org/apache/kafka/tools/ProducerPerformanceTest.java
##
@@ -0,0 +1,164 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.tools;
+
+import org.apache.kafka.clients.producer.KafkaProducer;
+import org.apache.kafka.clients.producer.Callback;
+import org.junit.jupiter.api.Test;
+import org.junit.jupiter.api.extension.ExtendWith;
+import org.mockito.ArgumentMatchers;
+import org.mockito.Mock;
+import org.mockito.Spy;
+import org.mockito.junit.jupiter.MockitoExtension;
+
+import net.sourceforge.argparse4j.inf.ArgumentParser;
+import net.sourceforge.argparse4j.inf.ArgumentParserException;
+
+import java.io.File;
+import java.io.FileWriter;
+import java.io.IOException;
+import java.io.UnsupportedEncodingException;
+import java.nio.charset.StandardCharsets;
+import java.util.ArrayList;
+import java.util.Collections;
+import java.util.List;
+import java.util.Properties;
+import java.util.Random;
+
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import static org.junit.jupiter.api.Assertions.assertFalse;
+import static org.junit.jupiter.api.Assertions.assertNotNull;
+import static org.junit.jupiter.api.Assertions.assertThrows;
+import static org.mockito.ArgumentMatchers.any;
+import static org.mockito.Mockito.doReturn;
+import static org.mockito.Mockito.times;
+import static org.mockito.Mockito.verify;
+
+@ExtendWith(MockitoExtension.class)
+public class ProducerPerformanceTest {
+
+@Mock
+KafkaProducer producerMock;
+
+@Spy
+ProducerPerformance producerPerformanceSpy;
+
+private File createTempFile(String contents) throws IOException {
+File file = File.createTempFile("ProducerPerformanceTest", ".tmp");
+file.deleteOnExit();
+final FileWriter writer = new FileWriter(file);
+writer.write(contents);
+writer.close();
+return file;
+}
+
+@Test
+public void testReadPayloadFile() throws Exception {
+File payloadFile = createTempFile("Hello\nKafka");
+String payloadFilePath = payloadFile.getAbsolutePath();
+String payloadDelimiter = "\n";
+
+List payloadByteList =
ProducerPerformance.readPayloadFile(payloadFilePath, payloadDelimiter);
+
+assertEquals(2, payloadByteList.size());
+assertEquals("Hello", new String(payloadByteList.get(0)));
+assertEquals("Kafka", new String(payloadByteList.get(1)));
+}
+
+@Test
+public void testReadProps() throws Exception {
+
+List producerProps =
Collections.singletonList("bootstrap.servers=localhost:9000");
+String producerConfig = createTempFile("acks=1").getAbsolutePath();
+String transactionalId = "1234";
+boolean transactionsEnabled = true;
+
+Properties prop = ProducerPerformance.readProps(producerProps,
producerConfig, transactionalId, transactionsEnabled);
+
+assertNotNull(prop);
+assertEquals(5, prop.size());
+}
+
+@Test
+public void testNumberOfCallsForSendAndClose() throws IOException {
+
+doReturn(null).when(producerMock).send(any(),
ArgumentMatchers.any());
+
doReturn(producerMock).when(producerPerformanceSpy).createKafkaProducer(any(Properties.class));
+
+String[] args = new String[] {"--topic", "Hello-Kafka",
"--num-records", "5", "--throughput", "100", "--record-size", "100",
"--producer-props", "bootstrap.servers=localhost:9000"};
+producerPerformanceSpy.start(args);
+verify(producerMock, times(5)).send(any(),
ArgumentMatchers.any());
+verify(producerMock, times(1)).close();
+}
+
+@Test
+public void testUnexpectedArg() {
+
+String[] args = new String[] {"--test", "test", "--topic",
"Hello-Kafka", "--num-records", "5", "--throughput", "100", "--record-size",
"100", "--producer-props", "bootstrap.servers=localhost:9000"};
+ArgumentParser parser = ProducerPerformance.argParser();
+ArgumentParserException thrown =
assertThrows(ArgumentParserException.class, () -> parser.parseArgs(args));
+
[GitHub] [kafka] tang7526 commented on a change in pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 commented on a change in pull request #10588:
URL: https://github.com/apache/kafka/pull/10588#discussion_r649155812
##
File path:
tools/src/test/java/org/apache/kafka/tools/ProducerPerformanceTest.java
##
@@ -0,0 +1,164 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.tools;
+
+import org.apache.kafka.clients.producer.KafkaProducer;
+import org.apache.kafka.clients.producer.Callback;
+import org.junit.jupiter.api.Test;
+import org.junit.jupiter.api.extension.ExtendWith;
+import org.mockito.ArgumentMatchers;
+import org.mockito.Mock;
+import org.mockito.Spy;
+import org.mockito.junit.jupiter.MockitoExtension;
+
+import net.sourceforge.argparse4j.inf.ArgumentParser;
+import net.sourceforge.argparse4j.inf.ArgumentParserException;
+
+import java.io.File;
+import java.io.FileWriter;
+import java.io.IOException;
+import java.io.UnsupportedEncodingException;
+import java.nio.charset.StandardCharsets;
+import java.util.ArrayList;
+import java.util.Collections;
+import java.util.List;
+import java.util.Properties;
+import java.util.Random;
+
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import static org.junit.jupiter.api.Assertions.assertFalse;
+import static org.junit.jupiter.api.Assertions.assertNotNull;
+import static org.junit.jupiter.api.Assertions.assertThrows;
+import static org.mockito.ArgumentMatchers.any;
+import static org.mockito.Mockito.doReturn;
+import static org.mockito.Mockito.times;
+import static org.mockito.Mockito.verify;
+
+@ExtendWith(MockitoExtension.class)
+public class ProducerPerformanceTest {
+
+@Mock
+KafkaProducer producerMock;
+
+@Spy
+ProducerPerformance producerPerformanceSpy;
+
+private File createTempFile(String contents) throws IOException {
+File file = File.createTempFile("ProducerPerformanceTest", ".tmp");
+file.deleteOnExit();
+final FileWriter writer = new FileWriter(file);
+writer.write(contents);
+writer.close();
+return file;
+}
+
+@Test
+public void testReadPayloadFile() throws Exception {
+File payloadFile = createTempFile("Hello\nKafka");
+String payloadFilePath = payloadFile.getAbsolutePath();
+String payloadDelimiter = "\n";
+
+List payloadByteList =
ProducerPerformance.readPayloadFile(payloadFilePath, payloadDelimiter);
+
+assertEquals(2, payloadByteList.size());
+assertEquals("Hello", new String(payloadByteList.get(0)));
+assertEquals("Kafka", new String(payloadByteList.get(1)));
+}
+
+@Test
+public void testReadProps() throws Exception {
+
+List producerProps =
Collections.singletonList("bootstrap.servers=localhost:9000");
+String producerConfig = createTempFile("acks=1").getAbsolutePath();
+String transactionalId = "1234";
+boolean transactionsEnabled = true;
+
+Properties prop = ProducerPerformance.readProps(producerProps,
producerConfig, transactionalId, transactionsEnabled);
+
+assertNotNull(prop);
+assertEquals(5, prop.size());
+}
+
+@Test
+public void testNumberOfCallsForSendAndClose() throws IOException {
+
+doReturn(null).when(producerMock).send(any(),
ArgumentMatchers.any());
+
doReturn(producerMock).when(producerPerformanceSpy).createKafkaProducer(any(Properties.class));
+
+String[] args = new String[] {"--topic", "Hello-Kafka",
"--num-records", "5", "--throughput", "100", "--record-size", "100",
"--producer-props", "bootstrap.servers=localhost:9000"};
+producerPerformanceSpy.start(args);
+verify(producerMock, times(5)).send(any(),
ArgumentMatchers.any());
+verify(producerMock, times(1)).close();
+}
+
+@Test
+public void testUnexpectedArg() {
+
+String[] args = new String[] {"--test", "test", "--topic",
"Hello-Kafka", "--num-records", "5", "--throughput", "100", "--record-size",
"100", "--producer-props", "bootstrap.servers=localhost:9000"};
+ArgumentParser parser = ProducerPerformance.argParser();
+ArgumentParserException thrown =
assertThrows(ArgumentParserException.class, () -> parser.parseArgs(args));
+
[GitHub] [kafka] tang7526 commented on a change in pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 commented on a change in pull request #10588:
URL: https://github.com/apache/kafka/pull/10588#discussion_r649156123
##
File path: tools/src/main/java/org/apache/kafka/tools/ProducerPerformance.java
##
@@ -190,8 +160,66 @@ public static void main(String[] args) throws Exception {
}
+KafkaProducer createKafkaProducer(Properties props) {
+return new KafkaProducer<>(props);
+}
+
+static byte[] generateRandomPayload(Integer recordSize, Boolean
hasPayloadFile, List payloadByteList, byte[] payload,
+Random random) {
+if (hasPayloadFile) {
Review comment:
OK, Done.
##
File path:
tools/src/test/java/org/apache/kafka/tools/ProducerPerformanceTest.java
##
@@ -0,0 +1,164 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.tools;
+
+import org.apache.kafka.clients.producer.KafkaProducer;
+import org.apache.kafka.clients.producer.Callback;
+import org.junit.jupiter.api.Test;
+import org.junit.jupiter.api.extension.ExtendWith;
+import org.mockito.ArgumentMatchers;
+import org.mockito.Mock;
+import org.mockito.Spy;
+import org.mockito.junit.jupiter.MockitoExtension;
+
+import net.sourceforge.argparse4j.inf.ArgumentParser;
+import net.sourceforge.argparse4j.inf.ArgumentParserException;
+
+import java.io.File;
+import java.io.FileWriter;
+import java.io.IOException;
+import java.io.UnsupportedEncodingException;
+import java.nio.charset.StandardCharsets;
+import java.util.ArrayList;
+import java.util.Collections;
+import java.util.List;
+import java.util.Properties;
+import java.util.Random;
+
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import static org.junit.jupiter.api.Assertions.assertFalse;
+import static org.junit.jupiter.api.Assertions.assertNotNull;
+import static org.junit.jupiter.api.Assertions.assertThrows;
+import static org.mockito.ArgumentMatchers.any;
+import static org.mockito.Mockito.doReturn;
+import static org.mockito.Mockito.times;
+import static org.mockito.Mockito.verify;
+
+@ExtendWith(MockitoExtension.class)
+public class ProducerPerformanceTest {
+
+@Mock
+KafkaProducer producerMock;
+
+@Spy
+ProducerPerformance producerPerformanceSpy;
+
+private File createTempFile(String contents) throws IOException {
+File file = File.createTempFile("ProducerPerformanceTest", ".tmp");
+file.deleteOnExit();
+final FileWriter writer = new FileWriter(file);
Review comment:
OK. Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] tang7526 commented on a change in pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 commented on a change in pull request #10588:
URL: https://github.com/apache/kafka/pull/10588#discussion_r649156123
##
File path: tools/src/main/java/org/apache/kafka/tools/ProducerPerformance.java
##
@@ -190,8 +160,66 @@ public static void main(String[] args) throws Exception {
}
+KafkaProducer createKafkaProducer(Properties props) {
+return new KafkaProducer<>(props);
+}
+
+static byte[] generateRandomPayload(Integer recordSize, Boolean
hasPayloadFile, List payloadByteList, byte[] payload,
+Random random) {
+if (hasPayloadFile) {
Review comment:
OK. Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #10852: MINOR: Replace easymock with mockito in log4j-appender
ijuma commented on a change in pull request #10852:
URL: https://github.com/apache/kafka/pull/10852#discussion_r649169159
##
File path:
log4j-appender/src/test/java/org/apache/kafka/log4jappender/KafkaLog4jAppenderTest.java
##
@@ -158,18 +160,18 @@ public void
testRealProducerConfigWithSyncSendAndNotIgnoringExceptionsShouldThro
assertThrows(RuntimeException.class, () ->
logger.error(getMessage(0)));
}
+@SuppressWarnings("unchecked")
Review comment:
Why do we need this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #10852: MINOR: Replace easymock with mockito in log4j-appender
ijuma commented on a change in pull request #10852:
URL: https://github.com/apache/kafka/pull/10852#discussion_r649169530
##
File path:
log4j-appender/src/test/java/org/apache/kafka/log4jappender/KafkaLog4jAppenderTest.java
##
@@ -158,18 +160,18 @@ public void
testRealProducerConfigWithSyncSendAndNotIgnoringExceptionsShouldThro
assertThrows(RuntimeException.class, () ->
logger.error(getMessage(0)));
}
+@SuppressWarnings("unchecked")
private void replaceProducerWithMocked(MockKafkaLog4jAppender
mockKafkaLog4jAppender, boolean success) {
-MockProducer producer =
EasyMock.niceMock(MockProducer.class);
-Future futureMock = EasyMock.niceMock(Future.class);
+MockProducer producer = mock(MockProducer.class);
+Future futureMock = mock(Future.class);
try {
if (!success)
-EasyMock.expect(futureMock.get())
-.andThrow(new ExecutionException("simulated timeout", new
TimeoutException()));
+Mockito.when(futureMock.get())
Review comment:
Please use static imports to make this more readable.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #10848: MINOR Updated transaction index as optional in LogSegmentData.
ijuma commented on a change in pull request #10848: URL: https://github.com/apache/kafka/pull/10848#discussion_r649171232 ## File path: storage/api/src/main/java/org/apache/kafka/server/log/remote/storage/LogSegmentData.java ## @@ -33,31 +34,32 @@ private final Path logSegment; private final Path offsetIndex; private final Path timeIndex; -private final Path txnIndex; +private final Optional transactionIndex; private final Path producerSnapshotIndex; private final ByteBuffer leaderEpochIndex; /** * Creates a LogSegmentData instance with data and indexes. - * @param logSegmentactual log segment file + * + * @param logSegmentactual log segment file * @param offsetIndex offset index file * @param timeIndex time index file - * @param txnIndex transaction index file + * @param transactionIndex transaction index file, which can be null * @param producerSnapshotIndex producer snapshot until this segment * @param leaderEpochIndex leader-epoch-index until this segment */ public LogSegmentData(Path logSegment, Path offsetIndex, Path timeIndex, - Path txnIndex, + Path transactionIndex, Review comment: The Java reasoning is pretty arbitrary and is inconsistent with the Scala recommendation (which we've been following and has worked pretty well for us). I suggest we stick with our approach. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #10848: MINOR Updated transaction index as optional in LogSegmentData.
ijuma commented on a change in pull request #10848:
URL: https://github.com/apache/kafka/pull/10848#discussion_r649171869
##
File path:
storage/api/src/test/java/org/apache/kafka/server/log/remote/storage/LogSegmentDataTest.java
##
@@ -0,0 +1,51 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.server.log.remote.storage;
+
+import org.apache.kafka.test.TestUtils;
+import org.junit.jupiter.api.Assertions;
+import org.junit.jupiter.api.Test;
+
+import java.io.File;
+import java.nio.ByteBuffer;
+
+public class LogSegmentDataTest {
+
+@Test
+public void testOptionalTransactionIndex() {
+File dir = TestUtils.tempDirectory();
+LogSegmentData logSegmentDataWithTransactionIndex = new LogSegmentData(
+new File(dir, "log-segment").toPath(),
+new File(dir, "offset-index").toPath(),
+new File(dir, "time-index").toPath(),
+new File(dir, "transaction-index").toPath(),
+new File(dir, "producer-snapshot").toPath(),
+ByteBuffer.allocate(1)
+);
+
Assertions.assertTrue(logSegmentDataWithTransactionIndex.transactionIndex().isPresent());
Review comment:
Please use static imports to stick with the usual more concise assert
style.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #10847: KAFKA-12921: Upgrade ZSTD JNI from 1.4.9-1 to 1.5.0-1
ijuma commented on pull request #10847: URL: https://github.com/apache/kafka/pull/10847#issuecomment-858614341 This is a good change, but can we please quality the perf improvements claim? My understanding is that only applies to certain compression levels and Kafka currently always picks a specific one. @dongjinleekr is working on making that configurable via a separate KIP. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #10847: KAFKA-12921: Upgrade ZSTD JNI from 1.4.9-1 to 1.5.0-1
ijuma commented on pull request #10847: URL: https://github.com/apache/kafka/pull/10847#issuecomment-858615783 Also, why are we listing versions in the PR description that are not relevant to this upgrade? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #10860: MINOR: fix client_compatibility_features_test.py - DescribeAcls is al…
ijuma commented on pull request #10860: URL: https://github.com/apache/kafka/pull/10860#issuecomment-858624143 Do the system tests pass with this change? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #10584: KAFKA-12701: NPE in MetadataRequest when using topic IDs
ijuma commented on a change in pull request #10584:
URL: https://github.com/apache/kafka/pull/10584#discussion_r649187595
##
File path:
clients/src/main/java/org/apache/kafka/common/requests/MetadataRequest.java
##
@@ -92,6 +93,15 @@ public MetadataRequest build(short version) {
if (!data.allowAutoTopicCreation() && version < 4)
throw new UnsupportedVersionException("MetadataRequest
versions older than 4 don't support the " +
"allowAutoTopicCreation field");
+if (version >= 10) {
+if (data.topics() != null) {
+data.topics().forEach(topic -> {
+if (topic.name() == null || topic.topicId() !=
Uuid.ZERO_UUID)
+throw new
UnsupportedVersionException("MetadataRequest version " + version +
+" does not support null topic names or
topic IDs.");
Review comment:
Slight clarification: `or non-null topic IDs`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #10584: KAFKA-12701: NPE in MetadataRequest when using topic IDs
ijuma commented on a change in pull request #10584:
URL: https://github.com/apache/kafka/pull/10584#discussion_r649189502
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1135,6 +1135,19 @@ class KafkaApis(val requestChannel: RequestChannel,
val metadataRequest = request.body[MetadataRequest]
val requestVersion = request.header.apiVersion
+// Topic IDs are not supported for versions 10 and 11. Topic names can not
be null in these versions.
+if (metadataRequest.version() >= 10 && !metadataRequest.isAllTopics) {
Review comment:
Do we need to check the version at all?
##
File path: core/src/test/scala/unit/kafka/server/MetadataRequestTest.scala
##
@@ -234,6 +235,32 @@ class MetadataRequestTest extends
AbstractMetadataRequestTest {
}
}
+ @Test
+ def testInvalidMetadataRequestReturnsError(): Unit = {
Review comment:
Do we need a full blown slow request test for this or can we rely on
unit tests only?
##
File path:
clients/src/main/java/org/apache/kafka/common/requests/MetadataRequest.java
##
@@ -92,6 +93,15 @@ public MetadataRequest build(short version) {
if (!data.allowAutoTopicCreation() && version < 4)
throw new UnsupportedVersionException("MetadataRequest
versions older than 4 don't support the " +
"allowAutoTopicCreation field");
+if (version >= 10) {
Review comment:
Is this version check needed at all?
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1142,6 +1142,19 @@ class KafkaApis(val requestChannel: RequestChannel,
val metadataRequest = request.body[MetadataRequest]
val requestVersion = request.header.apiVersion
+// Topic IDs are not supported for versions 10 and 11. Topic names can not
be null in these versions.
+if (metadataRequest.version() >= 10 && !metadataRequest.isAllTopics) {
+ metadataRequest.data().topics().forEach{ topic =>
+// If null, set to the empty string, since the response does not allow
null.
+if (topic.name() == null) {
+ topic.setName("")
+ throw new InvalidRequestException(s"Topic name can not be null for
version ${metadataRequest.version()}")
+} else if (topic.topicId() != Uuid.ZERO_UUID) {
+ throw new InvalidRequestException(s"Topic IDs are not supported in
requests for version ${metadataRequest.version()}")
+}
+ }
+}
Review comment:
What I mean is that this logic could exist in the request class and you
can then call the method from here. That way it's much easier to test.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-12468) Initial offsets are copied from source to target cluster
[
https://issues.apache.org/jira/browse/KAFKA-12468?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360912#comment-17360912
]
Alexis Josephides commented on KAFKA-12468:
---
We are running in distributed mode and are stipulating a `tasks.max` on each
connector (Source, Checkpoint and Heartbeat, 500, 50 and 1 respectively).
We are still seeing this issue with negative offsets on our target cluster.
> Initial offsets are copied from source to target cluster
>
>
> Key: KAFKA-12468
> URL: https://issues.apache.org/jira/browse/KAFKA-12468
> Project: Kafka
> Issue Type: Bug
> Components: mirrormaker
>Affects Versions: 2.7.0
>Reporter: Bart De Neuter
>Priority: Major
>
> We have an active-passive setup where the 3 connectors from mirror maker 2
> (heartbeat, checkpoint and source) are running on a dedicated Kafka connect
> cluster on the target cluster.
> Offset syncing is enabled as specified by KIP-545. But when activated, it
> seems the offsets from the source cluster are initially copied to the target
> cluster without translation. This causes a negative lag for all synced
> consumer groups. Only when we reset the offsets for each topic/partition on
> the target cluster and produce a record on the topic/partition in the source,
> the sync starts working correctly.
> I would expect that the consumer groups are synced but that the current
> offsets of the source cluster are not copied to the target cluster.
> This is the configuration we are currently using:
> Heartbeat connector
>
> {code:xml}
> {
> "name": "mm2-mirror-heartbeat",
> "config": {
> "name": "mm2-mirror-heartbeat",
> "connector.class":
> "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector",
> "source.cluster.alias": "eventador",
> "target.cluster.alias": "msk",
> "source.cluster.bootstrap.servers": "",
> "target.cluster.bootstrap.servers": "",
> "topics": ".*",
> "groups": ".*",
> "tasks.max": "1",
> "replication.policy.class": "CustomReplicationPolicy",
> "sync.group.offsets.enabled": "true",
> "sync.group.offsets.interval.seconds": "5",
> "emit.checkpoints.enabled": "true",
> "emit.checkpoints.interval.seconds": "30",
> "emit.heartbeats.interval.seconds": "30",
> "key.converter": "
> org.apache.kafka.connect.converters.ByteArrayConverter",
> "value.converter":
> "org.apache.kafka.connect.converters.ByteArrayConverter"
> }
> }
> {code}
> Checkpoint connector:
> {code:xml}
> {
> "name": "mm2-mirror-checkpoint",
> "config": {
> "name": "mm2-mirror-checkpoint",
> "connector.class":
> "org.apache.kafka.connect.mirror.MirrorCheckpointConnector",
> "source.cluster.alias": "eventador",
> "target.cluster.alias": "msk",
> "source.cluster.bootstrap.servers": "",
> "target.cluster.bootstrap.servers": "",
> "topics": ".*",
> "groups": ".*",
> "tasks.max": "40",
> "replication.policy.class": "CustomReplicationPolicy",
> "sync.group.offsets.enabled": "true",
> "sync.group.offsets.interval.seconds": "5",
> "emit.checkpoints.enabled": "true",
> "emit.checkpoints.interval.seconds": "30",
> "emit.heartbeats.interval.seconds": "30",
> "key.converter": "
> org.apache.kafka.connect.converters.ByteArrayConverter",
> "value.converter":
> "org.apache.kafka.connect.converters.ByteArrayConverter"
> }
> }
> {code}
> Source connector:
> {code:xml}
> {
> "name": "mm2-mirror-source",
> "config": {
> "name": "mm2-mirror-source",
> "connector.class":
> "org.apache.kafka.connect.mirror.MirrorSourceConnector",
> "source.cluster.alias": "eventador",
> "target.cluster.alias": "msk",
> "source.cluster.bootstrap.servers": "",
> "target.cluster.bootstrap.servers": "",
> "topics": ".*",
> "groups": ".*",
> "tasks.max": "40",
> "replication.policy.class": "CustomReplicationPolicy",
> "sync.group.offsets.enabled": "true",
> "sync.group.offsets.interval.seconds": "5",
> "emit.checkpoints.enabled": "true",
> "emit.checkpoints.interval.seconds": "30",
> "emit.heartbeats.interval.seconds": "30",
> "key.converter": "
> org.apache.kafka.connect.converters.ByteArrayConverter",
> "value.converter":
> "org.apache.kafka.connect.converters.ByteArrayConverter"
> }
> }
> {code}
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] dajac opened a new pull request #10863: KAFKA-12890; Consumer group stuck in `CompletingRebalance`
dajac opened a new pull request #10863: URL: https://github.com/apache/kafka/pull/10863 TODO ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12894) KIP-750: Drop support for Java 8 in Kafka 4.0 (deprecate in 3.0)
[ https://issues.apache.org/jira/browse/KAFKA-12894?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360918#comment-17360918 ] Ismael Juma commented on KAFKA-12894: - The KIP vote passed. > KIP-750: Drop support for Java 8 in Kafka 4.0 (deprecate in 3.0) > > > Key: KAFKA-12894 > URL: https://issues.apache.org/jira/browse/KAFKA-12894 > Project: Kafka > Issue Type: Improvement >Reporter: Ismael Juma >Assignee: Ismael Juma >Priority: Major > Labels: kip > > We propose deprecating Java 8 support in Apache Kafka 3.0 and dropping > support in Apache Kafka 4.0. > KIP: > https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=181308223 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-12894) KIP-750: Drop support for Java 8 in Kafka 4.0 (deprecate in 3.0)
[ https://issues.apache.org/jira/browse/KAFKA-12894?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360918#comment-17360918 ] Ismael Juma edited comment on KAFKA-12894 at 6/10/21, 1:49 PM: --- The KIP vote passed, will create a subtask for the 3.0 documentation updates. was (Author: ijuma): The KIP vote passed. > KIP-750: Drop support for Java 8 in Kafka 4.0 (deprecate in 3.0) > > > Key: KAFKA-12894 > URL: https://issues.apache.org/jira/browse/KAFKA-12894 > Project: Kafka > Issue Type: Improvement >Reporter: Ismael Juma >Assignee: Ismael Juma >Priority: Major > Labels: kip > > We propose deprecating Java 8 support in Apache Kafka 3.0 and dropping > support in Apache Kafka 4.0. > KIP: > https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=181308223 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] mimaison commented on a change in pull request #10743: KIP-699: Update FindCoordinator to resolve multiple Coordinators at a time
mimaison commented on a change in pull request #10743: URL: https://github.com/apache/kafka/pull/10743#discussion_r649208497 ## File path: clients/src/main/java/org/apache/kafka/clients/admin/internals/AdminApiHandler.java ## @@ -63,7 +64,7 @@ * * @return result indicating key completion, failure, and unmapping */ -ApiResult handleResponse(int brokerId, Set keys, AbstractResponse response); +ApiResult handleResponse(int brokerId, Set keys, AbstractResponse response, Node node); Review comment: I've actually replaced the first argument `int brokerId` by `Node broker` and removed the last argument. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] rqode commented on pull request #9671: KAFKA-10793: move handling of FindCoordinatorFuture to fix race condition
rqode commented on pull request #9671: URL: https://github.com/apache/kafka/pull/9671#issuecomment-858645412 When you experience this issue on 2.6.0 consumers is it enough to only upgrade the kafka client to 2.6.2 or does this fix require a server upgrade? Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jlprat commented on pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
jlprat commented on pull request #10856: URL: https://github.com/apache/kafka/pull/10856#issuecomment-858645362 Some steps of the build seem to have passed while some others failed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12895) KIP-751: Drop support for Scala 2.12 in Kafka 4.0 (deprecate in 3.0)
[ https://issues.apache.org/jira/browse/KAFKA-12895?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360923#comment-17360923 ] Ismael Juma commented on KAFKA-12895: - The KIP vote passed. I will create a subtask for the work required for 3.0. > KIP-751: Drop support for Scala 2.12 in Kafka 4.0 (deprecate in 3.0) > > > Key: KAFKA-12895 > URL: https://issues.apache.org/jira/browse/KAFKA-12895 > Project: Kafka > Issue Type: Improvement >Reporter: Ismael Juma >Assignee: Ismael Juma >Priority: Major > Labels: kip > > We propose to deprecate Scala 2.12 support n Apache Kafka 3.0 and to drop it > in Apache Kafka 4.0. > > KIP: > https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=181308218 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12929) KIP-750: Deprecate Java 8 in Kafka 3.0
Ismael Juma created KAFKA-12929: --- Summary: KIP-750: Deprecate Java 8 in Kafka 3.0 Key: KAFKA-12929 URL: https://issues.apache.org/jira/browse/KAFKA-12929 Project: Kafka Issue Type: Sub-task Reporter: Ismael Juma Assignee: Ismael Juma Fix For: 3.0.0 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12930) Deprecate support for Scala 2.12 in Kafka 3.0
Ismael Juma created KAFKA-12930: --- Summary: Deprecate support for Scala 2.12 in Kafka 3.0 Key: KAFKA-12930 URL: https://issues.apache.org/jira/browse/KAFKA-12930 Project: Kafka Issue Type: Sub-task Reporter: Ismael Juma Assignee: Ismael Juma Fix For: 3.0.0 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-12930) KIP-751: Deprecate support for Scala 2.12 in Kafka 3.0
[ https://issues.apache.org/jira/browse/KAFKA-12930?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ismael Juma updated KAFKA-12930: Summary: KIP-751: Deprecate support for Scala 2.12 in Kafka 3.0 (was: Deprecate support for Scala 2.12 in Kafka 3.0) > KIP-751: Deprecate support for Scala 2.12 in Kafka 3.0 > -- > > Key: KAFKA-12930 > URL: https://issues.apache.org/jira/browse/KAFKA-12930 > Project: Kafka > Issue Type: Sub-task >Reporter: Ismael Juma >Assignee: Ismael Juma >Priority: Major > Fix For: 3.0.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-12929) KIP-750: Deprecate support for Java 8 in Kafka 3.0
[ https://issues.apache.org/jira/browse/KAFKA-12929?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ismael Juma updated KAFKA-12929: Summary: KIP-750: Deprecate support for Java 8 in Kafka 3.0 (was: KIP-750: Deprecate Java 8 in Kafka 3.0) > KIP-750: Deprecate support for Java 8 in Kafka 3.0 > -- > > Key: KAFKA-12929 > URL: https://issues.apache.org/jira/browse/KAFKA-12929 > Project: Kafka > Issue Type: Sub-task >Reporter: Ismael Juma >Assignee: Ismael Juma >Priority: Major > Fix For: 3.0.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] chia7712 commented on pull request #10860: MINOR: fix client_compatibility_features_test.py - DescribeAcls is al…
chia7712 commented on pull request #10860: URL: https://github.com/apache/kafka/pull/10860#issuecomment-858649375 > Do the system tests pass with this change? yep. This system test shows following error message without this patch. ``` java.lang.RuntimeException: Did not expect describeAclsSupported to be supported, but it was. at org.apache.kafka.tools.ClientCompatibilityTest.tryFeature(ClientCompatibilityTest.java:525) at org.apache.kafka.tools.ClientCompatibilityTest.tryFeature(ClientCompatibilityTest.java:509) at org.apache.kafka.tools.ClientCompatibilityTest.testAdminClient(ClientCompatibilityTest.java:301) at org.apache.kafka.tools.ClientCompatibilityTest.run(ClientCompatibilityTest.java:238) at org.apache.kafka.tools.ClientCompatibilityTest.main(ClientCompatibilityTest.java:191) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mimaison commented on a change in pull request #10743: KIP-699: Update FindCoordinator to resolve multiple Coordinators at a time
mimaison commented on a change in pull request #10743:
URL: https://github.com/apache/kafka/pull/10743#discussion_r649213934
##
File path:
clients/src/main/java/org/apache/kafka/clients/consumer/internals/AbstractCoordinator.java
##
@@ -858,6 +885,12 @@ public void onSuccess(ClientResponse resp,
RequestFuture future) {
public void onFailure(RuntimeException e, RequestFuture future) {
log.debug("FindCoordinator request failed due to {}",
e.toString());
+if (e instanceof UnsupportedBatchLookupException) {
Review comment:
I've only taken a very brief look and I think this approach would work
well for Connect, Producer and Consumer, however it's a bit more complicated
with Admin.
In Admin, requests are built by lookup strategies. Lookups can be sent to
any broker so knowing the max version for a specific call is not completely
trivial. That said, it's not impossible either so if there's concensus it would
be preferable I can give that a try.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] chia7712 merged pull request #10860: MINOR: fix client_compatibility_features_test.py - DescribeAcls is al…
chia7712 merged pull request #10860: URL: https://github.com/apache/kafka/pull/10860 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on pull request #10847: KAFKA-12921: Upgrade ZSTD JNI from 1.4.9-1 to 1.5.0-1
dongjinleekr commented on pull request #10847: URL: https://github.com/apache/kafka/pull/10847#issuecomment-858653169 @ijuma @dchristle Since we have more time for [KIP-390](https://cwiki.apache.org/confluence/display/KAFKA/KIP-390%3A+Allow+fine-grained+configuration+for+compression), I will run the benchmark with this zstd binding. Stay tuned! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-12870) RecordAccumulator stuck in a flushing state
[ https://issues.apache.org/jira/browse/KAFKA-12870?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ismael Juma updated KAFKA-12870: Fix Version/s: 3.0.0 > RecordAccumulator stuck in a flushing state > --- > > Key: KAFKA-12870 > URL: https://issues.apache.org/jira/browse/KAFKA-12870 > Project: Kafka > Issue Type: Bug > Components: producer , streams >Affects Versions: 2.5.1, 2.8.0, 2.7.1, 2.6.2 >Reporter: Niclas Lockner >Priority: Major > Fix For: 3.0.0 > > Attachments: RecordAccumulator.log, full.log > > > After a Kafka Stream with exactly once enabled has performed its first > commit, the RecordAccumulator within the stream's internal producer gets > stuck in a state where all subsequent ProducerBatches that get allocated are > immediately flushed instead of being held in memory until they expire, > regardless of the stream's linger or batch size config. > This is reproduced in the example code found at > [https://github.com/niclaslockner/kafka-12870] which can be run with > ./gradlew run --args= > The example has a producer that sends 1 record/sec to one topic, and a Kafka > stream with EOS enabled that forwards the records from that topic to another > topic with the configuration linger = 5 sec, commit interval = 10 sec. > > The expected behavior when running the example is that the stream's > ProducerBatches will expire (or get flushed because of the commit) every 5th > second, and that the stream's producer will send a ProduceRequest every 5th > second with an expired ProducerBatch that contains 5 records. > The actual behavior is that the ProducerBatch is made immediately available > for the Sender, and the Sender sends one ProduceRequest for each record. > > The example code contains a copy of the RecordAccumulator class (copied from > kafka-clients 2.8.0) with some additional logging added to > * RecordAccumulator#ready(Cluster, long) > * RecordAccumulator#beginFlush() > * RecordAccumulator#awaitFlushCompletion() > These log entries show (see the attached RecordsAccumulator.log) > * that the batches are considered sendable because a flush is in progress > * that Sender.maybeSendAndPollTransactionalRequest() calls > RecordAccumulator's beginFlush() without also calling awaitFlushCompletion(), > and that this makes RecordAccumulator's flushesInProgress jump between 1-2 > instead of the expected 0-1. > > This issue is not reproducible in version 2.3.1 or 2.4.1. > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-12870) RecordAccumulator stuck in a flushing state
[ https://issues.apache.org/jira/browse/KAFKA-12870?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360937#comment-17360937 ] Ismael Juma commented on KAFKA-12870: - I think the claim is that there's a bug in the `Sender` when exactly-once is used. > RecordAccumulator stuck in a flushing state > --- > > Key: KAFKA-12870 > URL: https://issues.apache.org/jira/browse/KAFKA-12870 > Project: Kafka > Issue Type: Bug > Components: producer , streams >Affects Versions: 2.5.1, 2.8.0, 2.7.1, 2.6.2 >Reporter: Niclas Lockner >Priority: Major > Fix For: 3.0.0 > > Attachments: RecordAccumulator.log, full.log > > > After a Kafka Stream with exactly once enabled has performed its first > commit, the RecordAccumulator within the stream's internal producer gets > stuck in a state where all subsequent ProducerBatches that get allocated are > immediately flushed instead of being held in memory until they expire, > regardless of the stream's linger or batch size config. > This is reproduced in the example code found at > [https://github.com/niclaslockner/kafka-12870] which can be run with > ./gradlew run --args= > The example has a producer that sends 1 record/sec to one topic, and a Kafka > stream with EOS enabled that forwards the records from that topic to another > topic with the configuration linger = 5 sec, commit interval = 10 sec. > > The expected behavior when running the example is that the stream's > ProducerBatches will expire (or get flushed because of the commit) every 5th > second, and that the stream's producer will send a ProduceRequest every 5th > second with an expired ProducerBatch that contains 5 records. > The actual behavior is that the ProducerBatch is made immediately available > for the Sender, and the Sender sends one ProduceRequest for each record. > > The example code contains a copy of the RecordAccumulator class (copied from > kafka-clients 2.8.0) with some additional logging added to > * RecordAccumulator#ready(Cluster, long) > * RecordAccumulator#beginFlush() > * RecordAccumulator#awaitFlushCompletion() > These log entries show (see the attached RecordsAccumulator.log) > * that the batches are considered sendable because a flush is in progress > * that Sender.maybeSendAndPollTransactionalRequest() calls > RecordAccumulator's beginFlush() without also calling awaitFlushCompletion(), > and that this makes RecordAccumulator's flushesInProgress jump between 1-2 > instead of the expected 0-1. > > This issue is not reproducible in version 2.3.1 or 2.4.1. > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] mimaison commented on a change in pull request #9878: KAFKA-6987: Add KafkaFuture.toCompletionStage()
mimaison commented on a change in pull request #9878:
URL: https://github.com/apache/kafka/pull/9878#discussion_r649241897
##
File path: clients/src/test/java/org/apache/kafka/common/KafkaFutureTest.java
##
@@ -17,68 +17,261 @@
package org.apache.kafka.common;
import org.apache.kafka.common.internals.KafkaFutureImpl;
+import org.apache.kafka.common.utils.Java;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.Timeout;
+import java.lang.reflect.InvocationTargetException;
+import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
+import java.util.concurrent.CancellationException;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.CompletionException;
+import java.util.concurrent.CompletionStage;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
+import java.util.function.Supplier;
+import static org.junit.jupiter.api.Assertions.assertNotEquals;
import static org.junit.jupiter.api.Assertions.assertNull;
import static org.junit.jupiter.api.Assertions.assertThrows;
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertEquals;
+import static org.junit.jupiter.api.Assertions.fail;
/**
* A unit test for KafkaFuture.
*/
@Timeout(120)
public class KafkaFutureTest {
+/** Asserts that the given future is done, didn't fail and wasn't
cancelled. */
+private void assertIsSuccessful(KafkaFuture future) {
+assertTrue(future.isDone());
+assertFalse(future.isCompletedExceptionally());
+assertFalse(future.isCancelled());
+}
+
+/** Asserts that the given future is done, failed and wasn't cancelled. */
+private void assertIsFailed(KafkaFuture future) {
+assertTrue(future.isDone());
+assertFalse(future.isCancelled());
+assertTrue(future.isCompletedExceptionally());
+}
+
+/** Asserts that the given future is done, didn't fail and was cancelled.
*/
+private void assertIsCancelled(KafkaFuture future) {
+assertTrue(future.isDone());
+assertTrue(future.isCancelled());
+assertTrue(future.isCompletedExceptionally());
+}
+
+private void awaitAndAssertResult(KafkaFuture future,
+ T expectedResult,
+ T alternativeValue) {
+assertNotEquals(expectedResult, alternativeValue);
+try {
+assertEquals(expectedResult, future.get(5, TimeUnit.MINUTES));
+} catch (Exception e) {
+throw new AssertionError("Unexpected exception", e);
+}
+try {
+assertEquals(expectedResult, future.get());
+} catch (Exception e) {
+throw new AssertionError("Unexpected exception", e);
+}
+try {
+assertEquals(expectedResult, future.getNow(alternativeValue));
+} catch (Exception e) {
+throw new AssertionError("Unexpected exception", e);
+}
+}
+
+private void awaitAndAssertFailure(KafkaFuture future,
+ Class
expectedException,
+ String expectedMessage) {
+try {
+future.get(5, TimeUnit.MINUTES);
+fail("Expected an exception");
+} catch (ExecutionException e) {
+assertEquals(expectedException, e.getCause().getClass());
+assertEquals(expectedMessage, e.getCause().getMessage());
+} catch (Exception e) {
+throw new AssertionError("Unexpected exception", e);
+}
+try {
+future.get();
+fail("Expected an exception");
+} catch (ExecutionException e) {
+assertEquals(expectedException, e.getCause().getClass());
+assertEquals(expectedMessage, e.getCause().getMessage());
+} catch (Exception e) {
+throw new AssertionError("Unexpected exception", e);
+}
+try {
+future.getNow(null);
+fail("Expected an exception");
+} catch (ExecutionException e) {
+assertEquals(expectedException, e.getCause().getClass());
+assertEquals(expectedMessage, e.getCause().getMessage());
+} catch (Exception e) {
+throw new AssertionError("Unexpected exception", e);
+}
+}
+
+
+private void awaitAndAssertCancelled(KafkaFuture future, String
expectedMessage) {
+try {
+future.get(5, TimeUnit.MINUTES);
+fail("Expected an exception");
+} catch (CancellationException e) {
+assertEquals(CancellationException.class, e.getClass());
+assertEquals(expectedMessage, e.getMessage());
+} catch (Exception e) {
+throw new AssertionEr
[jira] [Commented] (KAFKA-12892) InvalidACLException thrown in tests caused jenkins build unstable
[
https://issues.apache.org/jira/browse/KAFKA-12892?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17360983#comment-17360983
]
Bruno Cadonna commented on KAFKA-12892:
---
Is PR #10821 supposed to solve the issue?
I still see a lot of
{code:java}
MultipleListenersWithAdditionalJaasContextTest > testProduceConsume() FAILED
[2021-06-10T11:11:52.209Z]
org.apache.zookeeper.KeeperException$InvalidACLException: KeeperErrorCode =
InvalidACL for /brokers/ids
[2021-06-10T11:11:52.209Z] at
org.apache.zookeeper.KeeperException.create(KeeperException.java:128)
[2021-06-10T11:11:52.209Z] at
org.apache.zookeeper.KeeperException.create(KeeperException.java:54)
[2021-06-10T11:11:52.209Z] at
kafka.zookeeper.AsyncResponse.maybeThrow(ZooKeeperClient.scala:583)
[2021-06-10T11:11:52.209Z] at
kafka.zk.KafkaZkClient.createRecursive(KafkaZkClient.scala:1729)
[2021-06-10T11:11:52.209Z] at
kafka.zk.KafkaZkClient.makeSurePersistentPathExists(KafkaZkClient.scala:1627)
[2021-06-10T11:11:52.209Z] at
kafka.zk.KafkaZkClient.$anonfun$createTopLevelPaths$1(KafkaZkClient.scala:1619)
[2021-06-10T11:11:52.209Z] at
kafka.zk.KafkaZkClient.$anonfun$createTopLevelPaths$1$adapted(KafkaZkClient.scala:1619)
[2021-06-10T11:11:52.209Z] at
scala.collection.immutable.List.foreach(List.scala:333)
[2021-06-10T11:11:52.209Z] at
kafka.zk.KafkaZkClient.createTopLevelPaths(KafkaZkClient.scala:1619)
[2021-06-10T11:11:52.209Z] at
kafka.server.KafkaServer.initZkClient(KafkaServer.scala:454)
[2021-06-10T11:11:52.209Z] at
kafka.server.KafkaServer.startup(KafkaServer.scala:192)
[2021-06-10T11:11:52.209Z] at
kafka.utils.TestUtils$.createServer(TestUtils.scala:166)
[2021-06-10T11:11:52.209Z] at
kafka.server.MultipleListenersWithSameSecurityProtocolBaseTest.$anonfun$setUp$1(MultipleListenersWithSameSecurityProtocolBaseTest.scala:103)
[2021-06-10T11:11:52.210Z] at
kafka.server.MultipleListenersWithSameSecurityProtocolBaseTest.$anonfun$setUp$1$adapted(MultipleListenersWithSameSecurityProtocolBaseTest.scala:76)
[2021-06-10T11:11:52.210Z] at
scala.collection.immutable.Range.foreach(Range.scala:190)
{code}
Also on PRs that contain PR #10821. For example
https://ci-builds.apache.org/blue/rest/organizations/jenkins/pipelines/Kafka/pipelines/kafka-pr/branches/PR-10856/runs/3/nodes/14/steps/121/log/?start=0
> InvalidACLException thrown in tests caused jenkins build unstable
> -
>
> Key: KAFKA-12892
> URL: https://issues.apache.org/jira/browse/KAFKA-12892
> Project: Kafka
> Issue Type: Bug
>Reporter: Luke Chen
>Assignee: Igor Soarez
>Priority: Major
> Attachments: image-2021-06-04-21-05-57-222.png
>
>
> In KAFKA-12866, we fixed the issue that Kafka required ZK root access even
> when using a chroot. But after the PR merged (build #183), trunk build keeps
> failing at least one test group (mostly, JDK 15 and Scala 2.13). The build
> result will said nothing useful:
> {code:java}
> > Task :core:integrationTest FAILED
> [2021-06-04T03:19:18.974Z]
> [2021-06-04T03:19:18.974Z] FAILURE: Build failed with an exception.
> [2021-06-04T03:19:18.974Z]
> [2021-06-04T03:19:18.974Z] * What went wrong:
> [2021-06-04T03:19:18.974Z] Execution failed for task ':core:integrationTest'.
> [2021-06-04T03:19:18.974Z] > Process 'Gradle Test Executor 128' finished with
> non-zero exit value 1
> [2021-06-04T03:19:18.974Z] This problem might be caused by incorrect test
> process configuration.
> [2021-06-04T03:19:18.974Z] Please refer to the test execution section in
> the User Manual at
> https://docs.gradle.org/7.0.2/userguide/java_testing.html#sec:test_execution
> {code}
>
> After investigation, I found the failed tests is because there are many
> `InvalidACLException` thrown during the tests, ex:
>
> {code:java}
> GssapiAuthenticationTest > testServerNotFoundInKerberosDatabase() FAILED
> [2021-06-04T02:25:45.419Z]
> org.apache.zookeeper.KeeperException$InvalidACLException: KeeperErrorCode =
> InvalidACL for /config/topics/__consumer_offsets
> [2021-06-04T02:25:45.419Z] at
> org.apache.zookeeper.KeeperException.create(KeeperException.java:128)
> [2021-06-04T02:25:45.419Z] at
> org.apache.zookeeper.KeeperException.create(KeeperException.java:54)
> [2021-06-04T02:25:45.419Z] at
> kafka.zookeeper.AsyncResponse.maybeThrow(ZooKeeperClient.scala:583)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.KafkaZkClient.createRecursive(KafkaZkClient.scala:1729)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.KafkaZkClient.createOrSet$1(KafkaZkClient.scala:366)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.KafkaZkClient.setOrCreateEntityConfigs(KafkaZkClient.scala:376
[GitHub] [kafka] satishd commented on pull request #10848: MINOR Updated transaction index as optional in LogSegmentData.
satishd commented on pull request #10848: URL: https://github.com/apache/kafka/pull/10848#issuecomment-858686600 Thanks @junrao @ijuma for the review. Addressed the review comments with the latest commit. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
cadonna commented on pull request #10856: URL: https://github.com/apache/kafka/pull/10856#issuecomment-858689473 JDK 11 and ARM passed. Failed tests are unrelated and the issue is known. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna merged pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
cadonna merged pull request #10856: URL: https://github.com/apache/kafka/pull/10856 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jlprat commented on pull request #10856: MINOR: Small optimizations and removal of unused code in Streams
jlprat commented on pull request #10856: URL: https://github.com/apache/kafka/pull/10856#issuecomment-858694138 Thanks both for the reviews -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mimaison commented on a change in pull request #10652: KAFKA-9726 IdentityReplicationPolicy
mimaison commented on a change in pull request #10652:
URL: https://github.com/apache/kafka/pull/10652#discussion_r649253273
##
File path:
connect/mirror-client/src/test/java/org/apache/kafka/connect/mirror/MirrorClientTest.java
##
@@ -159,4 +191,12 @@ public void remoteTopicsSeparatorTest() throws
InterruptedException {
assertTrue(remoteTopics.contains("source3__source4__source5__topic6"));
}
+public void testIdentityReplicationTopicSource() {
Review comment:
Missing `@Test` annotation
##
File path:
connect/mirror/src/main/java/org/apache/kafka/connect/mirror/MirrorSourceConnector.java
##
@@ -492,7 +492,12 @@ boolean isCycle(String topic) {
} else if (source.equals(sourceAndTarget.target())) {
return true;
} else {
-return isCycle(replicationPolicy.upstreamTopic(topic));
+String upstreamTopic = replicationPolicy.upstreamTopic(topic);
+if (upstreamTopic.equals(topic)) {
Review comment:
Can we cover this new branch with a test in `MirrorSourceConnectorTest`?
##
File path:
connect/mirror-client/src/test/java/org/apache/kafka/connect/mirror/MirrorClientTest.java
##
@@ -159,4 +191,12 @@ public void remoteTopicsSeparatorTest() throws
InterruptedException {
assertTrue(remoteTopics.contains("source3__source4__source5__topic6"));
}
+public void testIdentityReplicationTopicSource() {
+MirrorClient client = new FakeMirrorClient(
+new IdentityReplicationPolicy("primary"), Arrays.asList());
+assertEquals("topic1", client.replicationPolicy()
+.formatRemoteTopic("primary", "topic1"));
Review comment:
Should we also try `formatRemoteTopic()` with a heartbeat topic?
##
File path:
connect/mirror-client/src/main/java/org/apache/kafka/connect/mirror/MirrorClient.java
##
@@ -60,7 +60,7 @@
private ReplicationPolicy replicationPolicy;
private Map consumerConfig;
-public MirrorClient(Map props) {
+public MirrorClient(Map props) {
Review comment:
Is this actually needed?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] IgnacioAcunaF commented on pull request #10858: KAFKA-12926: ConsumerGroupCommand's java.lang.NullPointerException at negative offsets while running kafka-consumer-groups.sh
IgnacioAcunaF commented on pull request #10858: URL: https://github.com/apache/kafka/pull/10858#issuecomment-858703098 PING @hachikuji @apovzner as I saw you on [KAFKA-9507](https://github.com/apache/kafka/pull/8057) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] IgnacioAcunaF edited a comment on pull request #10858: KAFKA-12926: ConsumerGroupCommand's java.lang.NullPointerException at negative offsets while running kafka-consumer-groups.sh
IgnacioAcunaF edited a comment on pull request #10858: URL: https://github.com/apache/kafka/pull/10858#issuecomment-858703098 PING @hachikuji @apovzner (as I saw you on [KAFKA-9507](https://github.com/apache/kafka/pull/8057)) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jsancio commented on a change in pull request #10786: KAFKA-12787: Integrate controller snapshoting with raft client
jsancio commented on a change in pull request #10786:
URL: https://github.com/apache/kafka/pull/10786#discussion_r649273990
##
File path: core/src/main/scala/kafka/raft/KafkaMetadataLog.scala
##
@@ -233,18 +233,40 @@ final class KafkaMetadataLog private (
log.topicId.get
}
- override def createSnapshot(snapshotId: OffsetAndEpoch): RawSnapshotWriter =
{
-// Do not let the state machine create snapshots older than the latest
snapshot
-latestSnapshotId().ifPresent { latest =>
- if (latest.epoch > snapshotId.epoch || latest.offset >
snapshotId.offset) {
-// Since snapshots are less than the high-watermark absolute offset
comparison is okay.
-throw new IllegalArgumentException(
- s"Attempting to create a snapshot ($snapshotId) that is not greater
than the latest snapshot ($latest)"
-)
- }
+ override def createSnapshot(snapshotId: OffsetAndEpoch):
Optional[RawSnapshotWriter] = {
+if (snapshots.contains(snapshotId)) {
+ Optional.empty()
+} else {
+ Optional.of(FileRawSnapshotWriter.create(log.dir.toPath, snapshotId,
Optional.of(this)))
+}
+ }
+
+ override def createSnapshotFromEndOffset(endOffset: Long):
Optional[RawSnapshotWriter] = {
+val highWatermarkOffset = highWatermark.offset
+if (endOffset > highWatermarkOffset) {
+ throw new IllegalArgumentException(
+s"Cannot create a snapshot for an end offset ($endOffset) greater than
the high-watermark ($highWatermarkOffset)"
+ )
+}
+
+if (endOffset < startOffset) {
+ throw new IllegalArgumentException(
+s"Cannot create a snapshot for an end offset ($endOffset) less than
the log start offset ($startOffset)"
+ )
+}
+
+val epoch =
log.leaderEpochCache.flatMap(_.findEpochEntryByEndOffset(endOffset)) match {
+ case Some(epochEntry) =>
+epochEntry.epoch
+ case None =>
+// Assume that the end offset falls in the current epoch since based
on the check above:
Review comment:
I remove this code. To avoid scanning the leader epoch cache, I reverted
the snapshot creation API so that both the offset and the epoch is pass to
`createSnapshot`. The new code just validates that the given offset and epoch
are valid according to the record batches in the log and leader epoch cache.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jsancio commented on a change in pull request #10786: KAFKA-12787: Integrate controller snapshoting with raft client
jsancio commented on a change in pull request #10786: URL: https://github.com/apache/kafka/pull/10786#discussion_r649281362 ## File path: metadata/src/main/java/org/apache/kafka/controller/QuorumController.java ## @@ -1009,7 +999,7 @@ private QuorumController(LogContext logContext, snapshotRegistry, sessionTimeoutNs, replicaPlacer); this.featureControl = new FeatureControlManager(supportedFeatures, snapshotRegistry); this.producerIdControlManager = new ProducerIdControlManager(clusterControl, snapshotRegistry); -this.snapshotGeneratorManager = new SnapshotGeneratorManager(snapshotWriterBuilder); +this.snapshotGeneratorManager = new SnapshotGeneratorManager(raftClient::createSnapshot); Review comment: Fair enough. Removing the `BiFunction` from the constructor. `SnapshotGeneratorManager` is an inner class so it should have access to the `raftClient`. > Was this done for testing or something? I am not sure why this was added. It is not used on tests. I think the previous code didn't have access to the `raftClient` because this code was merged before reversing the dependency between the `metadata` project and the `raft` project. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12892) InvalidACLException thrown in tests caused jenkins build unstable
[
https://issues.apache.org/jira/browse/KAFKA-12892?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17361026#comment-17361026
]
Igor Soarez commented on KAFKA-12892:
-
Yes it was - by applying the ACL changes to a unique child znode instead of to
the root, there shouldn't be any interference with other tests. I'm not sure if
this is the new test that's still a problem or if there's any lingering state
in zookeeper across builds. It is strange that only some test runs are
affected. Disabling the test will let us know.
> InvalidACLException thrown in tests caused jenkins build unstable
> -
>
> Key: KAFKA-12892
> URL: https://issues.apache.org/jira/browse/KAFKA-12892
> Project: Kafka
> Issue Type: Bug
>Reporter: Luke Chen
>Assignee: Igor Soarez
>Priority: Major
> Attachments: image-2021-06-04-21-05-57-222.png
>
>
> In KAFKA-12866, we fixed the issue that Kafka required ZK root access even
> when using a chroot. But after the PR merged (build #183), trunk build keeps
> failing at least one test group (mostly, JDK 15 and Scala 2.13). The build
> result will said nothing useful:
> {code:java}
> > Task :core:integrationTest FAILED
> [2021-06-04T03:19:18.974Z]
> [2021-06-04T03:19:18.974Z] FAILURE: Build failed with an exception.
> [2021-06-04T03:19:18.974Z]
> [2021-06-04T03:19:18.974Z] * What went wrong:
> [2021-06-04T03:19:18.974Z] Execution failed for task ':core:integrationTest'.
> [2021-06-04T03:19:18.974Z] > Process 'Gradle Test Executor 128' finished with
> non-zero exit value 1
> [2021-06-04T03:19:18.974Z] This problem might be caused by incorrect test
> process configuration.
> [2021-06-04T03:19:18.974Z] Please refer to the test execution section in
> the User Manual at
> https://docs.gradle.org/7.0.2/userguide/java_testing.html#sec:test_execution
> {code}
>
> After investigation, I found the failed tests is because there are many
> `InvalidACLException` thrown during the tests, ex:
>
> {code:java}
> GssapiAuthenticationTest > testServerNotFoundInKerberosDatabase() FAILED
> [2021-06-04T02:25:45.419Z]
> org.apache.zookeeper.KeeperException$InvalidACLException: KeeperErrorCode =
> InvalidACL for /config/topics/__consumer_offsets
> [2021-06-04T02:25:45.419Z] at
> org.apache.zookeeper.KeeperException.create(KeeperException.java:128)
> [2021-06-04T02:25:45.419Z] at
> org.apache.zookeeper.KeeperException.create(KeeperException.java:54)
> [2021-06-04T02:25:45.419Z] at
> kafka.zookeeper.AsyncResponse.maybeThrow(ZooKeeperClient.scala:583)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.KafkaZkClient.createRecursive(KafkaZkClient.scala:1729)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.KafkaZkClient.createOrSet$1(KafkaZkClient.scala:366)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.KafkaZkClient.setOrCreateEntityConfigs(KafkaZkClient.scala:376)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.AdminZkClient.createTopicWithAssignment(AdminZkClient.scala:109)
> [2021-06-04T02:25:45.419Z] at
> kafka.zk.AdminZkClient.createTopic(AdminZkClient.scala:60)
> [2021-06-04T02:25:45.419Z] at
> kafka.utils.TestUtils$.$anonfun$createTopic$1(TestUtils.scala:357)
> [2021-06-04T02:25:45.419Z] at
> kafka.utils.TestUtils$.createTopic(TestUtils.scala:848)
> [2021-06-04T02:25:45.419Z] at
> kafka.utils.TestUtils$.createOffsetsTopic(TestUtils.scala:428)
> [2021-06-04T02:25:45.419Z] at
> kafka.api.IntegrationTestHarness.doSetup(IntegrationTestHarness.scala:109)
> [2021-06-04T02:25:45.419Z] at
> kafka.api.IntegrationTestHarness.setUp(IntegrationTestHarness.scala:84)
> [2021-06-04T02:25:45.419Z] at
> kafka.server.GssapiAuthenticationTest.setUp(GssapiAuthenticationTest.scala:68)
> {code}
>
> Log can be found
> [here|[https://ci-builds.apache.org/blue/rest/organizations/jenkins/pipelines/Kafka/pipelines/kafka/branches/trunk/runs/195/nodes/14/steps/145/log/?start=0]]
> After tracing back, I found it could because we add a test in the KAFKA-12866
> to lock root access in zookeeper, but somehow it didn't unlock after the test
> in testChrootExistsAndRootIsLocked. Also, while all the InvalidACLException
> failed tests happened right after testChrootExistsAndRootIsLocked not long.
> Ex: below testChrootExistsAndRootIsLocked completed at 02:24:30, and the
> above failed test is at 02:25:45 (and following more than 10 tests with the
> same InvalidACLException.
> {code:java}
> [2021-06-04T02:24:29.370Z] ZkClientAclTest >
> testChrootExistsAndRootIsLocked() STARTED
> [2021-06-04T02:24:30.321Z]
> [2021-06-04T02:24:30.321Z] ZkClientAclTest >
> testChrootExistsAndRootIsLocked() PASSED{code}
>
> !image-2021-06-04-21-05-57-222.png|width=489,height=!
> We should
[GitHub] [kafka] socutes commented on a change in pull request #10749: KAFKA-12773: Use UncheckedIOException when wrapping IOException
socutes commented on a change in pull request #10749:
URL: https://github.com/apache/kafka/pull/10749#discussion_r649316231
##
File path: raft/src/main/java/org/apache/kafka/snapshot/Snapshots.java
##
@@ -68,15 +68,22 @@ public static Path snapshotPath(Path logDir, OffsetAndEpoch
snapshotId) {
return snapshotDir(logDir).resolve(filenameFromSnapshotId(snapshotId)
+ SUFFIX);
}
-public static Path createTempFile(Path logDir, OffsetAndEpoch snapshotId)
throws IOException {
+public static Path createTempFile(Path logDir, OffsetAndEpoch snapshotId) {
Path dir = snapshotDir(logDir);
+Path tempFile;
-// Create the snapshot directory if it doesn't exists
-Files.createDirectories(dir);
-
-String prefix = String.format("%s-",
filenameFromSnapshotId(snapshotId));
+try {
+// Create the snapshot directory if it doesn't exists
+Files.createDirectories(dir);
-return Files.createTempFile(dir, prefix, PARTIAL_SUFFIX);
+String prefix = String.format("%s-",
filenameFromSnapshotId(snapshotId));
+tempFile = Files.createTempFile(dir, prefix, PARTIAL_SUFFIX);
Review comment:
You're right!Thanks
##
File path:
raft/src/main/java/org/apache/kafka/snapshot/FileRawSnapshotWriter.java
##
@@ -78,7 +85,11 @@ public void append(MemoryRecords records) {
checkIfFrozen("Append");
Utils.writeFully(channel, records.buffer());
} catch (IOException e) {
-throw new RuntimeException(e);
+throw new UncheckedIOException(
+String.format("Error writing file snapshot," +
Review comment:
Fixed!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] socutes commented on pull request #10749: KAFKA-12773: Use UncheckedIOException when wrapping IOException
socutes commented on pull request #10749: URL: https://github.com/apache/kafka/pull/10749#issuecomment-858743167 @hachikuji Please review the changes again! Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jsancio commented on a change in pull request #10786: KAFKA-12787: Integrate controller snapshoting with raft client
jsancio commented on a change in pull request #10786:
URL: https://github.com/apache/kafka/pull/10786#discussion_r649320552
##
File path:
metadata/src/main/java/org/apache/kafka/controller/SnapshotGenerator.java
##
@@ -74,56 +74,49 @@ String name() {
this.batch = null;
this.section = null;
this.numRecords = 0;
-this.numWriteTries = 0;
}
/**
* Returns the epoch of the snapshot that we are generating.
*/
long epoch() {
-return writer.epoch();
+return writer.lastOffset();
Review comment:
Yes but the names are not great. Updated the names of
`SnapshotGenerator.epoch` and `SnapshotWriter.lastOffset` to
`lastOffsetFromLog`. This should make it clear that the offset of the batches
in the snapshots are independent of the last offset from the log that is
included in the snapshot.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jsancio commented on a change in pull request #10786: KAFKA-12787: Integrate controller snapshoting with raft client
jsancio commented on a change in pull request #10786:
URL: https://github.com/apache/kafka/pull/10786#discussion_r649273990
##
File path: core/src/main/scala/kafka/raft/KafkaMetadataLog.scala
##
@@ -233,18 +233,40 @@ final class KafkaMetadataLog private (
log.topicId.get
}
- override def createSnapshot(snapshotId: OffsetAndEpoch): RawSnapshotWriter =
{
-// Do not let the state machine create snapshots older than the latest
snapshot
-latestSnapshotId().ifPresent { latest =>
- if (latest.epoch > snapshotId.epoch || latest.offset >
snapshotId.offset) {
-// Since snapshots are less than the high-watermark absolute offset
comparison is okay.
-throw new IllegalArgumentException(
- s"Attempting to create a snapshot ($snapshotId) that is not greater
than the latest snapshot ($latest)"
-)
- }
+ override def createSnapshot(snapshotId: OffsetAndEpoch):
Optional[RawSnapshotWriter] = {
+if (snapshots.contains(snapshotId)) {
+ Optional.empty()
+} else {
+ Optional.of(FileRawSnapshotWriter.create(log.dir.toPath, snapshotId,
Optional.of(this)))
+}
+ }
+
+ override def createSnapshotFromEndOffset(endOffset: Long):
Optional[RawSnapshotWriter] = {
+val highWatermarkOffset = highWatermark.offset
+if (endOffset > highWatermarkOffset) {
+ throw new IllegalArgumentException(
+s"Cannot create a snapshot for an end offset ($endOffset) greater than
the high-watermark ($highWatermarkOffset)"
+ )
+}
+
+if (endOffset < startOffset) {
+ throw new IllegalArgumentException(
+s"Cannot create a snapshot for an end offset ($endOffset) less than
the log start offset ($startOffset)"
+ )
+}
+
+val epoch =
log.leaderEpochCache.flatMap(_.findEpochEntryByEndOffset(endOffset)) match {
+ case Some(epochEntry) =>
+epochEntry.epoch
+ case None =>
+// Assume that the end offset falls in the current epoch since based
on the check above:
Review comment:
I removed this code. To avoid scanning the leader epoch cache, I
reverted the snapshot creation API so that both the offset and the epoch is
pass to `createSnapshot`. The new code just validates that the given offset and
epoch are valid according to the record batches in the log and leader epoch
cache.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jsancio commented on pull request #10786: KAFKA-12787: Integrate controller snapshoting with raft client
jsancio commented on pull request #10786: URL: https://github.com/apache/kafka/pull/10786#issuecomment-858750625 @hachikuji thanks for the review. Updated the PR to address your comments. cc @cmccabe -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] edoardocomar commented on pull request #10649: KAFKA-12762: Use connection timeout when polling the network for new …
edoardocomar commented on pull request #10649: URL: https://github.com/apache/kafka/pull/10649#issuecomment-858752590 This last commit (thanks @tombentley ) allows the integration test to leave the Admin interface unchanged, the expanded factory method is only part of test classes -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mimaison merged pull request #10849: KAFKA-12922: MirrorCheckpointTask should close topic filter
mimaison merged pull request #10849: URL: https://github.com/apache/kafka/pull/10849 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12925) prefixScan missing from intermediate interfaces
[
https://issues.apache.org/jira/browse/KAFKA-12925?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17361062#comment-17361062
]
Michael Viamari commented on KAFKA-12925:
-
I can flesh out a larger example if needed, but the basic usage for me was
getting a reference to the state store using {{context.getStateStore()}} inside
{{Transformer#init}}, and then when attempting to use
{{TimestampedKeyValueStore#prefixScan}}, the exception was thrown.
{code:java}
public class TransformerPrefixScan implements Transformer> {
private ProcessorContext context;
private TimestampedKeyValueStore lookupStore;
public TransformerPrefixScan() {}
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
lookupStore = context.getStateStore(lookupStoreName);
}
@Override
public KeyValue transform(K key, V value) {
String keyPrefix = extractPrefix(key);
try (KeyValueIterator> lookupIterator =
lookupStore.prefixScan(keyPrefix, Serdes.String())) {
//handle results
}
return null;
}
@Override
public void close() {
}
}
{code}
> prefixScan missing from intermediate interfaces
> ---
>
> Key: KAFKA-12925
> URL: https://issues.apache.org/jira/browse/KAFKA-12925
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.8.0
>Reporter: Michael Viamari
>Assignee: Sagar Rao
>Priority: Major
> Fix For: 3.0.0, 2.8.1
>
>
> [KIP-614|https://cwiki.apache.org/confluence/display/KAFKA/KIP-614%3A+Add+Prefix+Scan+support+for+State+Stores]
> and [KAFKA-10648|https://issues.apache.org/jira/browse/KAFKA-10648]
> introduced support for {{prefixScan}} to StateStores.
> It seems that many of the intermediate {{StateStore}} interfaces are missing
> a definition for {{prefixScan}}, and as such is not accessible in all cases.
> For example, when accessing the state stores through a the processor context,
> the {{KeyValueStoreReadWriteDecorator}} and associated interfaces do not
> define {{prefixScan}} and it falls back to the default implementation in
> {{KeyValueStore}}, which throws {{UnsupportedOperationException}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] mimaison commented on pull request #10805: KAFKA-12436 KIP-720 Deprecate MirrorMaker v1
mimaison commented on pull request #10805: URL: https://github.com/apache/kafka/pull/10805#issuecomment-858766776 This KIP was adopted on the basis of having an IdentityReplicationPolicy which is in this PR: https://github.com/apache/kafka/pull/10652 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jolshan commented on a change in pull request #10584: KAFKA-12701: NPE in MetadataRequest when using topic IDs
jolshan commented on a change in pull request #10584:
URL: https://github.com/apache/kafka/pull/10584#discussion_r649352099
##
File path: core/src/test/scala/unit/kafka/server/MetadataRequestTest.scala
##
@@ -234,6 +235,32 @@ class MetadataRequestTest extends
AbstractMetadataRequestTest {
}
}
+ @Test
+ def testInvalidMetadataRequestReturnsError(): Unit = {
Review comment:
This was one way to test the KafkaApis code, but I suppose I could move
this to a unit test that only tests the method itself (and not the whole
request path)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jolshan commented on a change in pull request #10584: KAFKA-12701: NPE in MetadataRequest when using topic IDs
jolshan commented on a change in pull request #10584:
URL: https://github.com/apache/kafka/pull/10584#discussion_r649352825
##
File path:
clients/src/main/java/org/apache/kafka/common/requests/MetadataRequest.java
##
@@ -92,6 +93,15 @@ public MetadataRequest build(short version) {
if (!data.allowAutoTopicCreation() && version < 4)
throw new UnsupportedVersionException("MetadataRequest
versions older than 4 don't support the " +
"allowAutoTopicCreation field");
+if (version >= 10) {
Review comment:
We will need to check the version when this is fixed, but I can remove
the version check for now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jolshan commented on a change in pull request #10584: KAFKA-12701: NPE in MetadataRequest when using topic IDs
jolshan commented on a change in pull request #10584:
URL: https://github.com/apache/kafka/pull/10584#discussion_r649353683
##
File path:
clients/src/main/java/org/apache/kafka/common/requests/MetadataRequest.java
##
@@ -92,6 +93,15 @@ public MetadataRequest build(short version) {
if (!data.allowAutoTopicCreation() && version < 4)
throw new UnsupportedVersionException("MetadataRequest
versions older than 4 don't support the " +
"allowAutoTopicCreation field");
+if (version >= 10) {
+if (data.topics() != null) {
+data.topics().forEach(topic -> {
+if (topic.name() == null || topic.topicId() !=
Uuid.ZERO_UUID)
+throw new
UnsupportedVersionException("MetadataRequest version " + version +
+" does not support null topic names or
topic IDs.");
Review comment:
Would it make sense to say non-zero topic IDs? Since the null ID is
represented with all zeros?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] mimaison merged pull request #10653: MINOR: Add missing parameter description from AdminZkClient
mimaison merged pull request #10653: URL: https://github.com/apache/kafka/pull/10653 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jolshan commented on a change in pull request #10584: KAFKA-12701: NPE in MetadataRequest when using topic IDs
jolshan commented on a change in pull request #10584:
URL: https://github.com/apache/kafka/pull/10584#discussion_r649360987
##
File path: core/src/test/scala/unit/kafka/server/MetadataRequestTest.scala
##
@@ -234,6 +235,32 @@ class MetadataRequestTest extends
AbstractMetadataRequestTest {
}
}
+ @Test
+ def testInvalidMetadataRequestReturnsError(): Unit = {
Review comment:
I guess the only other reason I tested the whole path was to make sure
the response could be sent back (if the name was null, it could not have), but
it should suffice to also have a non-null check.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org