[jira] [Created] (KAFKA-10013) Consumer hang-up in case of unclean leader election
Dmitry created KAFKA-10013:
--
Summary: Consumer hang-up in case of unclean leader election
Key: KAFKA-10013
URL: https://issues.apache.org/jira/browse/KAFKA-10013
Project: Kafka
Issue Type: Bug
Components: consumer
Affects Versions: 2.4.1, 2.5.0, 2.3.1, 2.4.0, 2.3.0
Reporter: Dmitry
Starting from kafka 2.3 new offset reset negotiation algorithm added
(org.apache.kafka.clients.consumer.internals.Fetcher#validateOffsetsAsync)
During this validation, Fetcher
`org.apache.kafka.clients.consumer.internals.SubscriptionState` is held in
`AWAIT_VALIDATION` fetch state.
This effectively means that fetch requests are not issued and consumption
stopped.
In case if unclean leader election is happening during this time,
`LogTruncationException` is thrown from future listener in method
`validateOffsetsAsync` (probably in order to turn on the logic defined by
`auto.offset.reset` parameter).
The main problem is that this exception (thrown from listener of future) is
effectively swallowed by
`org.apache.kafka.clients.consumer.internals.AsyncClient#sendAsyncRequest`
by this part of code
} catch (RuntimeException e) {
if (!future.isDone()) {
future.raise(e);
}
}
In the end the result is: The only way to get out of AWAIT_VALIDATION and
continue consumption is to successfully finish validation, but it can not be
finished.
However - consumer is alive, but is consuming nothing. The only way to resume
consumption is to terminate consumer and start another one.
We discovered this situation by means of kstreams application, where valid
value of `auto.offset.reset` provided by our code is replaced by `None` value
for a purpose of position reset
(org.apache.kafka.streams.processor.internals.StreamThread#create).
And with kstreams it is even worse, as application may be working, logging warn
messages of format `Truncation detected for partition ...,` but data is not
generated for a long time and in the end is lost, making kstreams application
unreliable.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-10014) Always try to close all channels in Selector#close
Chia-Ping Tsai created KAFKA-10014:
--
Summary: Always try to close all channels in Selector#close
Key: KAFKA-10014
URL: https://issues.apache.org/jira/browse/KAFKA-10014
Project: Kafka
Issue Type: Bug
Reporter: Chia-Ping Tsai
Assignee: Chia-Ping Tsai
{code:java}
public void close() {
List connections = new ArrayList<>(channels.keySet());
try {
for (String id : connections)
close(id); // this line
} finally {
{code}
KafkaChannel has a lot of releasable objects so we ought to try to close all
channels.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-8398) NPE when unmapping files after moving log directories using AlterReplicaLogDirs
[
https://issues.apache.org/jira/browse/KAFKA-8398?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17109987#comment-17109987
]
Chia-Ping Tsai commented on KAFKA-8398:
---
seems
https://github.com/apache/kafka/commit/e554dc518eaaa0747899e708160275f95c4e525f
had resolved this issue.
{code:scala}
protected def safeForceUnmap(): Unit = {
try forceUnmap()
catch {
case t: Throwable => error(s"Error unmapping index $file", t)
}
}
{code}
Although, it would be better to avoid NPE even if NPE is swallowed.
> NPE when unmapping files after moving log directories using
> AlterReplicaLogDirs
> ---
>
> Key: KAFKA-8398
> URL: https://issues.apache.org/jira/browse/KAFKA-8398
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 2.2.0
>Reporter: Vikas Singh
>Priority: Minor
> Attachments: AlterReplicaLogDirs.txt
>
>
> The NPE occurs after the AlterReplicaLogDirs command completes successfully
> and when unmapping older regions. The relevant part of log is in attached log
> file. Here is the stacktrace (which is repeated for both index files):
>
> {code:java}
> [2019-05-20 14:08:13,999] ERROR Error unmapping index
> /tmp/kafka-logs/test-0.567a0d8ff88b45ab95794020d0b2e66f-delete/.index
> (kafka.log.OffsetIndex)
> java.lang.NullPointerException
> at
> org.apache.kafka.common.utils.MappedByteBuffers.unmap(MappedByteBuffers.java:73)
> at kafka.log.AbstractIndex.forceUnmap(AbstractIndex.scala:318)
> at kafka.log.AbstractIndex.safeForceUnmap(AbstractIndex.scala:308)
> at kafka.log.AbstractIndex.$anonfun$closeHandler$1(AbstractIndex.scala:257)
> at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
> at kafka.utils.CoreUtils$.inLock(CoreUtils.scala:251)
> at kafka.log.AbstractIndex.closeHandler(AbstractIndex.scala:257)
> at kafka.log.AbstractIndex.deleteIfExists(AbstractIndex.scala:226)
> at kafka.log.LogSegment.$anonfun$deleteIfExists$6(LogSegment.scala:597)
> at kafka.log.LogSegment.delete$1(LogSegment.scala:585)
> at kafka.log.LogSegment.$anonfun$deleteIfExists$5(LogSegment.scala:597)
> at kafka.utils.CoreUtils$.$anonfun$tryAll$1(CoreUtils.scala:115)
> at kafka.utils.CoreUtils$.$anonfun$tryAll$1$adapted(CoreUtils.scala:114)
> at scala.collection.immutable.List.foreach(List.scala:392)
> at kafka.utils.CoreUtils$.tryAll(CoreUtils.scala:114)
> at kafka.log.LogSegment.deleteIfExists(LogSegment.scala:599)
> at kafka.log.Log.$anonfun$delete$3(Log.scala:1762)
> at kafka.log.Log.$anonfun$delete$3$adapted(Log.scala:1762)
> at scala.collection.Iterator.foreach(Iterator.scala:941)
> at scala.collection.Iterator.foreach$(Iterator.scala:941)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
> at scala.collection.IterableLike.foreach(IterableLike.scala:74)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
> at kafka.log.Log.$anonfun$delete$2(Log.scala:1762)
> at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
> at kafka.log.Log.maybeHandleIOException(Log.scala:2013)
> at kafka.log.Log.delete(Log.scala:1759)
> at kafka.log.LogManager.deleteLogs(LogManager.scala:761)
> at kafka.log.LogManager.$anonfun$deleteLogs$6(LogManager.scala:775)
> at kafka.utils.KafkaScheduler.$anonfun$schedule$2(KafkaScheduler.scala:114)
> at kafka.utils.CoreUtils$$anon$1.run(CoreUtils.scala:63)
> at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> at java.util.concurrent.FutureTask.run(FutureTask.java:266)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> [{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-9893) Configurable TCP connection timeout and improve the initial metadata fetch
[ https://issues.apache.org/jira/browse/KAFKA-9893?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Cheng Tan updated KAFKA-9893: - Description: This issue has two parts: # Support transportation layer connection timeout described in KIP-601 # Optimize the logic for NetworkClient.leastLoadedNode() Changes: # Added a new common client configuration parameter socket.connection.setup.timeout.ms to the NetworkClient. Handle potential transportation layer timeout using the same approach as it handling potential request timeout. # When no connected channel exists, leastLoadedNode() will now provide a disconnected node that has the least number of failed attempts. was: This issue has two parts: # Support TCP connection timeout described in KIP-601 # Currently, the LeastLoadedNodeProvider might provide an offline/invalid node when no nodes provided in --boostrap-server option is not connected. The Cluster class shuffled the nodes to balance the initial pressure (I guess) and the LeastLoadedNodeProvider will always provide the same node, which is the last node after shuffling. Consequently, though we may provide several bootstrap servers, we might hit timeout if any of the servers shutdown. The implementation strategy for 1 is described in KIP-601 The solution for 2 is to implement a round-robin candidate node selection when every node is unconnected. We can either # shuffle the nodes every time we hit the "no node connected" status # keep the status of the nodes' try times and clean the try times after any of the nodes gets connected. > Configurable TCP connection timeout and improve the initial metadata fetch > -- > > Key: KAFKA-9893 > URL: https://issues.apache.org/jira/browse/KAFKA-9893 > Project: Kafka > Issue Type: New Feature >Reporter: Cheng Tan >Assignee: Cheng Tan >Priority: Major > > This issue has two parts: > # Support transportation layer connection timeout described in KIP-601 > # Optimize the logic for NetworkClient.leastLoadedNode() > Changes: > # Added a new common client configuration parameter > socket.connection.setup.timeout.ms to the NetworkClient. Handle potential > transportation layer timeout using the same approach as it handling potential > request timeout. > # When no connected channel exists, leastLoadedNode() will now provide a > disconnected node that has the least number of failed attempts. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-9893) Configurable TCP connection timeout and improve the initial metadata fetch
[ https://issues.apache.org/jira/browse/KAFKA-9893?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Cheng Tan updated KAFKA-9893: - Description: This issue has two parts: # Support transportation layer connection timeout described in KIP-601 # Optimize the logic for NetworkClient.leastLoadedNode() Changes: # Added a new common client configuration parameter socket.connection.setup.timeout.ms to the NetworkClient. Handle potential transportation layer timeout using the same approach as it handling potential request timeout. # When no connected channel exists, leastLoadedNode() will now provide a disconnected node that has the least number of failed attempts. # ClusterConnectionStates will keep the connecting node ids. Now it also has several new public methods to provide per connection relavant data. was: This issue has two parts: # Support transportation layer connection timeout described in KIP-601 # Optimize the logic for NetworkClient.leastLoadedNode() Changes: # Added a new common client configuration parameter socket.connection.setup.timeout.ms to the NetworkClient. Handle potential transportation layer timeout using the same approach as it handling potential request timeout. # When no connected channel exists, leastLoadedNode() will now provide a disconnected node that has the least number of failed attempts. > Configurable TCP connection timeout and improve the initial metadata fetch > -- > > Key: KAFKA-9893 > URL: https://issues.apache.org/jira/browse/KAFKA-9893 > Project: Kafka > Issue Type: New Feature >Reporter: Cheng Tan >Assignee: Cheng Tan >Priority: Major > > This issue has two parts: > # Support transportation layer connection timeout described in KIP-601 > # Optimize the logic for NetworkClient.leastLoadedNode() > Changes: > # Added a new common client configuration parameter > socket.connection.setup.timeout.ms to the NetworkClient. Handle potential > transportation layer timeout using the same approach as it handling potential > request timeout. > # When no connected channel exists, leastLoadedNode() will now provide a > disconnected node that has the least number of failed attempts. > # ClusterConnectionStates will keep the connecting node ids. Now it also has > several new public methods to provide per connection relavant data. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Issue Comment Deleted] (KAFKA-9845) plugin.path property does not work with config provider
[
https://issues.apache.org/jira/browse/KAFKA-9845?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
victor updated KAFKA-9845:
--
Comment: was deleted
(was: [~ alexlumpov]人名提及某人..)
> plugin.path property does not work with config provider
> ---
>
> Key: KAFKA-9845
> URL: https://issues.apache.org/jira/browse/KAFKA-9845
> Project: Kafka
> Issue Type: Bug
> Components: KafkaConnect
>Affects Versions: 2.3.0, 2.4.0, 2.3.1, 2.5.0, 2.4.1
>Reporter: Chris Egerton
>Assignee: Chris Egerton
>Priority: Minor
>
> The config provider mechanism doesn't work if used for the {{plugin.path}}
> property of a standalone or distributed Connect worker. This is because the
> {{Plugins}} instance which performs plugin path scanning is created using the
> raw worker config, pre-transformation (see
> [ConnectStandalone|https://github.com/apache/kafka/blob/371ad143a6bb973927c89c0788d048a17ebac91a/connect/runtime/src/main/java/org/apache/kafka/connect/cli/ConnectStandalone.java#L79]
> and
> [ConnectDistributed|https://github.com/apache/kafka/blob/371ad143a6bb973927c89c0788d048a17ebac91a/connect/runtime/src/main/java/org/apache/kafka/connect/cli/ConnectDistributed.java#L91]).
> Unfortunately, because config providers are loaded as plugins, there's a
> circular dependency issue here. The {{Plugins}} instance needs to be created
> _before_ the {{DistributedConfig}}/{{StandaloneConfig}} is created in order
> for the config providers to be loaded correctly, and the config providers
> need to be loaded in order to perform their logic on any properties
> (including the {{plugin.path}} property).
> There is no clear fix for this issue in the code base, and the only known
> workaround is to refrain from using config providers for the {{plugin.path}}
> property.
> A couple improvements could potentially be made to improve the UX when this
> issue arises:
> # Alter the config logging performed by the {{DistributedConfig}} and
> {{StandaloneConfig}} classes to _always_ log the raw value for the
> {{plugin.path}} property. Right now, the transformed value is logged even
> though it isn't used, which is likely to cause confusion.
> # Issue a {{WARN}}- or even {{ERROR}}-level log message when it's detected
> that the user is attempting to use config providers for the {{plugin.path}}
> property, which states that config providers cannot be used for that specific
> property, instructs them to change the value for the property accordingly,
> and/or informs them of the actual value that the framework will use for that
> property when performing plugin path scanning.
> We should _not_ throw an error on startup if this condition is detected, as
> this could cause previously-functioning, benignly-misconfigured Connect
> workers to fail to start after an upgrade.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-9845) plugin.path property does not work with config provider
[
https://issues.apache.org/jira/browse/KAFKA-9845?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110023#comment-17110023
]
victor commented on KAFKA-9845:
---
[~ alexlumpov]人名提及某人..
> plugin.path property does not work with config provider
> ---
>
> Key: KAFKA-9845
> URL: https://issues.apache.org/jira/browse/KAFKA-9845
> Project: Kafka
> Issue Type: Bug
> Components: KafkaConnect
>Affects Versions: 2.3.0, 2.4.0, 2.3.1, 2.5.0, 2.4.1
>Reporter: Chris Egerton
>Assignee: Chris Egerton
>Priority: Minor
>
> The config provider mechanism doesn't work if used for the {{plugin.path}}
> property of a standalone or distributed Connect worker. This is because the
> {{Plugins}} instance which performs plugin path scanning is created using the
> raw worker config, pre-transformation (see
> [ConnectStandalone|https://github.com/apache/kafka/blob/371ad143a6bb973927c89c0788d048a17ebac91a/connect/runtime/src/main/java/org/apache/kafka/connect/cli/ConnectStandalone.java#L79]
> and
> [ConnectDistributed|https://github.com/apache/kafka/blob/371ad143a6bb973927c89c0788d048a17ebac91a/connect/runtime/src/main/java/org/apache/kafka/connect/cli/ConnectDistributed.java#L91]).
> Unfortunately, because config providers are loaded as plugins, there's a
> circular dependency issue here. The {{Plugins}} instance needs to be created
> _before_ the {{DistributedConfig}}/{{StandaloneConfig}} is created in order
> for the config providers to be loaded correctly, and the config providers
> need to be loaded in order to perform their logic on any properties
> (including the {{plugin.path}} property).
> There is no clear fix for this issue in the code base, and the only known
> workaround is to refrain from using config providers for the {{plugin.path}}
> property.
> A couple improvements could potentially be made to improve the UX when this
> issue arises:
> # Alter the config logging performed by the {{DistributedConfig}} and
> {{StandaloneConfig}} classes to _always_ log the raw value for the
> {{plugin.path}} property. Right now, the transformed value is logged even
> though it isn't used, which is likely to cause confusion.
> # Issue a {{WARN}}- or even {{ERROR}}-level log message when it's detected
> that the user is attempting to use config providers for the {{plugin.path}}
> property, which states that config providers cannot be used for that specific
> property, instructs them to change the value for the property accordingly,
> and/or informs them of the actual value that the framework will use for that
> property when performing plugin path scanning.
> We should _not_ throw an error on startup if this condition is detected, as
> this could cause previously-functioning, benignly-misconfigured Connect
> workers to fail to start after an upgrade.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] chia7712 opened a new pull request #8685: KAFKA-10014 Always try to close all channels in Selector#close
chia7712 opened a new pull request #8685: URL: https://github.com/apache/kafka/pull/8685 https://issues.apache.org/jira/browse/KAFKA-10014 ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-9981) Running a dedicated mm2 cluster with more than one nodes,When the configuration is updated the task is not aware and will lose the update operation.
[
https://issues.apache.org/jira/browse/KAFKA-9981?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110047#comment-17110047
]
victor commented on KAFKA-9981:
---
[~ChrisEgerton] [~ryannedolan] hi.
In case of dedicated mm2 clusters, If the configBackingStore task is hosted on
a follower node,Can the following node write directly into the config topic?
> Running a dedicated mm2 cluster with more than one nodes,When the
> configuration is updated the task is not aware and will lose the update
> operation.
>
>
> Key: KAFKA-9981
> URL: https://issues.apache.org/jira/browse/KAFKA-9981
> Project: Kafka
> Issue Type: Bug
> Components: mirrormaker
>Affects Versions: 2.4.0, 2.5.0, 2.4.1
>Reporter: victor
>Priority: Major
>
> DistributedHerder.reconfigureConnector induction config update as follows:
> {code:java}
> if (changed) {
> List> rawTaskProps = reverseTransform(connName,
> configState, taskProps);
> if (isLeader()) {
> configBackingStore.putTaskConfigs(connName, rawTaskProps);
> cb.onCompletion(null, null);
> } else {
> // We cannot forward the request on the same thread because this
> reconfiguration can happen as a result of connector
> // addition or removal. If we blocked waiting for the response from
> leader, we may be kicked out of the worker group.
> forwardRequestExecutor.submit(new Runnable() {
> @Override
> public void run() {
> try {
> String leaderUrl = leaderUrl();
> if (leaderUrl == null || leaderUrl.trim().isEmpty()) {
> cb.onCompletion(new ConnectException("Request to
> leader to " +
> "reconfigure connector tasks failed " +
> "because the URL of the leader's REST
> interface is empty!"), null);
> return;
> }
> String reconfigUrl = RestServer.urlJoin(leaderUrl,
> "/connectors/" + connName + "/tasks");
> log.trace("Forwarding task configurations for connector
> {} to leader", connName);
> RestClient.httpRequest(reconfigUrl, "POST", null,
> rawTaskProps, null, config, sessionKey, requestSignatureAlgorithm);
> cb.onCompletion(null, null);
> } catch (ConnectException e) {
> log.error("Request to leader to reconfigure connector
> tasks failed", e);
> cb.onCompletion(e, null);
> }
> }
> });
> }
> }
> {code}
> KafkaConfigBackingStore task checks for configuration updates,such as topic
> whitelist update.If KafkaConfigBackingStore task is not running on leader
> node,an HTTP request will be send to notify the leader of the configuration
> update.However,dedicated mm2 cluster does not have the HTTP server turned
> on,so the request will fail to be sent,causing the update operation to be
> lost.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] qq619618919 commented on pull request #8656: KAFKA-9981; dedicated mm2 cluster lose the update operation.
qq619618919 commented on pull request #8656: URL: https://github.com/apache/kafka/pull/8656#issuecomment-630040397 > I'm still not sure what is going on here. What does it mean to update the config if !isLeader()? Only the leader actually has a config store. The following links,Chris Egerton's response was exactly what I wanted to say. https://issues.apache.org/jira/browse/KAFKA-9981?focusedCommentId=17108867&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-17108867 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] brary commented on a change in pull request #8395: Added doc for KIP-535 and updated it for KIP-562
brary commented on a change in pull request #8395: URL: https://github.com/apache/kafka/pull/8395#discussion_r426485550 ## File path: docs/upgrade.html ## @@ -39,7 +39,8 @@ Notable changes in 2 https://github.com/apache/kafka/tree/2.5/examples";>examples folder. Check out https://cwiki.apache.org/confluence/display/KAFKA/KIP-447%3A+Producer+scalability+for+exactly+once+semantics";>KIP-447 for the full details. -Deprecated KafkaStreams.store(String, QueryableStoreType) and replaced it with KafkaStreams.store(StoreQueryParameters). +Provided support to query stale stores(for high availability) and the stores belonging to a specific partition by deprecating KafkaStreams.store(String, QueryableStoreType) and replacing it with KafkaStreams.store(StoreQueryParameters). Review comment: Thanks @abbccdda . Addressed both the comments in the latest commit. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #8517: MINOR: use monotonic clock for replica fetcher DelayedItem
chia7712 commented on pull request #8517: URL: https://github.com/apache/kafka/pull/8517#issuecomment-630066071 ```EmbeddedKafkaCluster``` created by Stream UT uses ```MockTime``` to create ```KafkaServer```( https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/utils/EmbeddedKafkaCluster.java#L81) so the check of delayed item gets impacted by ```MockTime```. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] avalsa commented on a change in pull request #8221: KAFKA-9561: update task input partitions after rebalance
avalsa commented on a change in pull request #8221:
URL: https://github.com/apache/kafka/pull/8221#discussion_r426498753
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/PartitionGroup.java
##
@@ -93,6 +96,28 @@ long partitionTimestamp(final TopicPartition partition) {
return queue.partitionTime();
}
+// creates queues for new partitions, removes old queues, saves cached
records for previously assigned partitions
+void updatePartitions(final Set newInputPartitions, final
Function recordQueueCreator) {
+final Set removedPartitions = new HashSet<>();
+final Iterator> queuesIterator
= partitionQueues.entrySet().iterator();
+while (queuesIterator.hasNext()) {
+final Map.Entry queueEntry =
queuesIterator.next();
+final TopicPartition topicPartition = queueEntry.getKey();
+if (!newInputPartitions.contains(topicPartition)) {
+// if partition is removed should delete it's queue
Review comment:
fixed
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] avalsa commented on a change in pull request #8221: KAFKA-9561: update task input partitions after rebalance
avalsa commented on a change in pull request #8221:
URL: https://github.com/apache/kafka/pull/8221#discussion_r426498877
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/PartitionGroup.java
##
@@ -93,6 +96,28 @@ long partitionTimestamp(final TopicPartition partition) {
return queue.partitionTime();
}
+// creates queues for new partitions, removes old queues, saves cached
records for previously assigned partitions
+void updatePartitions(final Set newInputPartitions, final
Function recordQueueCreator) {
+final Set removedPartitions = new HashSet<>();
+final Iterator> queuesIterator
= partitionQueues.entrySet().iterator();
+while (queuesIterator.hasNext()) {
+final Map.Entry queueEntry =
queuesIterator.next();
+final TopicPartition topicPartition = queueEntry.getKey();
+if (!newInputPartitions.contains(topicPartition)) {
+// if partition is removed should delete it's queue
+totalBuffered -= queueEntry.getValue().size();
+queuesIterator.remove();
+removedPartitions.add(topicPartition);
+}
+newInputPartitions.remove(topicPartition);
+}
+for (final TopicPartition newInputPartition : newInputPartitions) {
+partitionQueues.put(newInputPartition,
recordQueueCreator.apply(newInputPartition));
+}
+nonEmptyQueuesByTime.removeIf(q ->
removedPartitions.contains(q.partition()));
+allBuffered = allBuffered && newInputPartitions.isEmpty();
Review comment:
fixed
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] avalsa commented on a change in pull request #8221: KAFKA-9561: update task input partitions after rebalance
avalsa commented on a change in pull request #8221:
URL: https://github.com/apache/kafka/pull/8221#discussion_r426499189
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/Task.java
##
@@ -170,6 +170,8 @@ public boolean isValidTransition(final State newState) {
*/
void closeDirty();
+void update(final Set topicPartitions, final
ProcessorTopology processorTopology);
Review comment:
yes, added short description
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-4748) Need a way to shutdown all workers in a Streams application at the same time
[ https://issues.apache.org/jira/browse/KAFKA-4748?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110133#comment-17110133 ] Antony Stubbs commented on KAFKA-4748: -- FYI [~mjsax], my intention for Kafka-6943 was for a single KS instance, not an entire cluster. This (Kafka-4748) would be for the entire cluster (all KS instances), from what I understand. Extending Kafka-6943 to have an option to shutdown the entire cluster upon a thread crash in a single instance or all threads crashing could be interesting, but would seem an order of magnitude more complex than triggering the shutdown of the instance the thread was living on. > Need a way to shutdown all workers in a Streams application at the same time > > > Key: KAFKA-4748 > URL: https://issues.apache.org/jira/browse/KAFKA-4748 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 0.10.1.1 >Reporter: Elias Levy >Priority: Major > > If you have a fleet of Stream workers for an application and attempt to shut > them down simultaneously (e.g. via SIGTERM and > Runtime.getRuntime().addShutdownHook() and streams.close())), a large number > of the workers fail to shutdown. > The problem appears to be a race condition between the shutdown signal and > the consumer rebalancing that is triggered by some of the workers existing > before others. Apparently, workers that receive the signal later fail to > exit apparently as they are caught in the rebalance. > Terminating workers in a rolling fashion is not advisable in some situations. > The rolling shutdown will result in many unnecessary rebalances and may > fail, as the application may have large amount of local state that a smaller > number of nodes may not be able to store. > It would appear that there is a need for a protocol change to allow the > coordinator to signal a consumer group to shutdown without leading to > rebalancing. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-4748) Need a way to shutdown all workers in a Streams application at the same time
[ https://issues.apache.org/jira/browse/KAFKA-4748?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110133#comment-17110133 ] Antony Stubbs edited comment on KAFKA-4748 at 5/18/20, 10:47 AM: - FYI [~mjsax], my intention for KAFKA-6943 was for a single KS instance, not an entire cluster. This (KAFKA-4748) would be for the entire cluster (all KS instances), from what I understand. Extending KAFKA-6943 to have an option to shutdown the entire cluster upon a thread crash in a single instance or all threads crashing could be interesting, but would seem an order of magnitude more complex than triggering the shutdown of the instance the thread was living on. was (Author: astubbs): FYI [~mjsax], my intention for Kafka-6943 was for a single KS instance, not an entire cluster. This (Kafka-4748) would be for the entire cluster (all KS instances), from what I understand. Extending Kafka-6943 to have an option to shutdown the entire cluster upon a thread crash in a single instance or all threads crashing could be interesting, but would seem an order of magnitude more complex than triggering the shutdown of the instance the thread was living on. > Need a way to shutdown all workers in a Streams application at the same time > > > Key: KAFKA-4748 > URL: https://issues.apache.org/jira/browse/KAFKA-4748 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 0.10.1.1 >Reporter: Elias Levy >Priority: Major > > If you have a fleet of Stream workers for an application and attempt to shut > them down simultaneously (e.g. via SIGTERM and > Runtime.getRuntime().addShutdownHook() and streams.close())), a large number > of the workers fail to shutdown. > The problem appears to be a race condition between the shutdown signal and > the consumer rebalancing that is triggered by some of the workers existing > before others. Apparently, workers that receive the signal later fail to > exit apparently as they are caught in the rebalance. > Terminating workers in a rolling fashion is not advisable in some situations. > The rolling shutdown will result in many unnecessary rebalances and may > fail, as the application may have large amount of local state that a smaller > number of nodes may not be able to store. > It would appear that there is a need for a protocol change to allow the > coordinator to signal a consumer group to shutdown without leading to > rebalancing. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-6182) Automatic co-partitioning of topics via automatic intermediate topic with matching partitions
[ https://issues.apache.org/jira/browse/KAFKA-6182?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110137#comment-17110137 ] Antony Stubbs commented on KAFKA-6182: -- Ah yes that makes sense. Assuming the exception thrown when the partition mismatch is found at runtime would cause the entire system to fail fast, I think yes, this repartition operation solves the issue. > Automatic co-partitioning of topics via automatic intermediate topic with > matching partitions > - > > Key: KAFKA-6182 > URL: https://issues.apache.org/jira/browse/KAFKA-6182 > Project: Kafka > Issue Type: New Feature > Components: streams >Affects Versions: 1.0.0 >Reporter: Antony Stubbs >Priority: Major > > Currently it is up to the user to ensure that two input topics for a join > have the same number of partitions, and if they don't, manually create an > intermediate topic, and send the stream #through that topic first, and then > performing the join. > It would be great to have Kafka streams detect this and at least give the > user the option to create an intermediate topic automatically with the same > number of partitions as the topic being joined with. > See > https://docs.confluent.io/current/streams/developer-guide.html#joins-require-co-partitioning-of-the-input-data -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] showuon opened a new pull request #8686: MINOR: Remove redundant TOC and introduction in Running Streams Applications
showuon opened a new pull request #8686: URL: https://github.com/apache/kafka/pull/8686 Remove redundant TOC and introduction in Running Streams Applications before:  after: 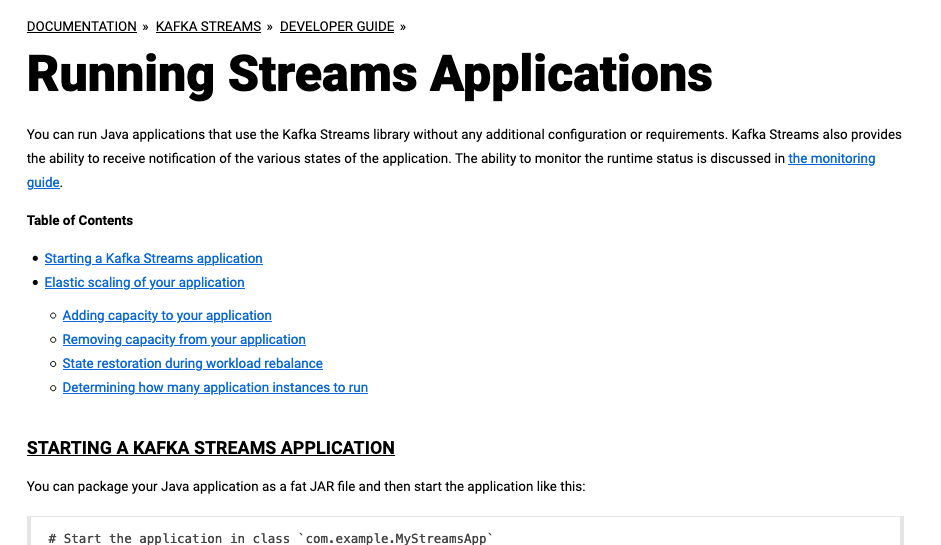 ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #8686: MINOR: Remove redundant TOC and introduction in Running Streams Applications
showuon commented on pull request #8686: URL: https://github.com/apache/kafka/pull/8686#issuecomment-630148688 @guozhangwang , a small documentation update PR in streams page. Please help review. Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on a change in pull request #8669: MINOR: consolidate processor context for active/standby
cadonna commented on a change in pull request #8669:
URL: https://github.com/apache/kafka/pull/8669#discussion_r426592363
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/ProcessorContextImpl.java
##
@@ -16,87 +16,129 @@
*/
package org.apache.kafka.streams.processor.internals;
-import org.apache.kafka.streams.KeyValue;
+import java.util.HashMap;
+import java.util.Map;
+import org.apache.kafka.common.serialization.ByteArraySerializer;
+import org.apache.kafka.common.serialization.BytesSerializer;
+import org.apache.kafka.common.utils.Bytes;
+import org.apache.kafka.common.utils.LogContext;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.errors.StreamsException;
import org.apache.kafka.streams.internals.ApiUtils;
-import org.apache.kafka.streams.kstream.Windowed;
import org.apache.kafka.streams.processor.Cancellable;
-import org.apache.kafka.streams.processor.ProcessorContext;
import org.apache.kafka.streams.processor.PunctuationType;
import org.apache.kafka.streams.processor.Punctuator;
+import org.apache.kafka.streams.processor.StateRestoreCallback;
import org.apache.kafka.streams.processor.StateStore;
import org.apache.kafka.streams.processor.TaskId;
import org.apache.kafka.streams.processor.To;
+import org.apache.kafka.streams.processor.internals.Task.TaskType;
import org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl;
-import org.apache.kafka.streams.state.KeyValueIterator;
-import org.apache.kafka.streams.state.KeyValueStore;
-import org.apache.kafka.streams.state.SessionStore;
-import org.apache.kafka.streams.state.TimestampedKeyValueStore;
-import org.apache.kafka.streams.state.TimestampedWindowStore;
-import org.apache.kafka.streams.state.ValueAndTimestamp;
-import org.apache.kafka.streams.state.WindowStore;
-import org.apache.kafka.streams.state.WindowStoreIterator;
import org.apache.kafka.streams.state.internals.ThreadCache;
-import org.apache.kafka.streams.state.internals.WrappedStateStore;
import java.time.Duration;
import java.util.List;
import static
org.apache.kafka.streams.internals.ApiUtils.prepareMillisCheckFailMsgPrefix;
+import static
org.apache.kafka.streams.processor.internals.AbstractReadOnlyDecorator.getReadOnlyStore;
+import static
org.apache.kafka.streams.processor.internals.AbstractReadWriteDecorator.getReadWriteStore;
public class ProcessorContextImpl extends AbstractProcessorContext implements
RecordCollector.Supplier {
+public static final BytesSerializer KEY_SERIALIZER = new BytesSerializer();
+public static final ByteArraySerializer VALUE_SERIALIZER = new
ByteArraySerializer();
-private final StreamTask task;
+// The below are both null for standby tasks
+private final StreamTask streamTask;
private final RecordCollector collector;
+
private final ToInternal toInternal = new ToInternal();
private final static To SEND_TO_ALL = To.all();
+final Map storeToChangelogTopic = new HashMap<>();
+
ProcessorContextImpl(final TaskId id,
- final StreamTask task,
+ final StreamTask streamTask,
final StreamsConfig config,
final RecordCollector collector,
final ProcessorStateManager stateMgr,
final StreamsMetricsImpl metrics,
final ThreadCache cache) {
super(id, config, metrics, stateMgr, cache);
-this.task = task;
+this.streamTask = streamTask;
this.collector = collector;
+
+if (streamTask == null && taskType() == TaskType.ACTIVE) {
+throw new IllegalStateException("Tried to create context for
active task but the streamtask was null");
+}
+}
+
+ProcessorContextImpl(final TaskId id,
+ final StreamsConfig config,
+ final ProcessorStateManager stateMgr,
+ final StreamsMetricsImpl metrics) {
+this(
+id,
+null,
+config,
+null,
+stateMgr,
+metrics,
+new ThreadCache(
+new LogContext(String.format("stream-thread [%s] ",
Thread.currentThread().getName())),
+0,
+metrics
+)
+);
}
-public ProcessorStateManager getStateMgr() {
+public ProcessorStateManager stateManager() {
return (ProcessorStateManager) stateManager;
}
+@Override
+public void register(final StateStore store,
+ final StateRestoreCallback stateRestoreCallback) {
+storeToChangelogTopic.put(store.name(),
ProcessorStateManager.storeChangelogTopic(applicationId(), store.name()));
+super.register(store, stateRestoreCallback);
+}
+
@Override
public RecordCollector recordCollector() {
retu
[GitHub] [kafka] cadonna commented on pull request #8157: KAFKA-9088: Consolidate InternalMockProcessorContext and MockInternalProcessorContext
cadonna commented on pull request #8157: URL: https://github.com/apache/kafka/pull/8157#issuecomment-630245364 @pierDipi FYI: We need to make some changes to the `InternalProcessorContext` that are needed for two high priority tickets. The changes are done in PR #8669. The changes affect also this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] lbradstreet commented on pull request #8517: MINOR: use monotonic clock for replica fetcher DelayedItem
lbradstreet commented on pull request #8517: URL: https://github.com/apache/kafka/pull/8517#issuecomment-630249725 > `EmbeddedKafkaCluster` created by Stream UT uses `MockTime` to create `KafkaServer`( > https://github.com/apache/kafka/blob/trunk/streams/src/test/java/org/apache/kafka/streams/integration/utils/EmbeddedKafkaCluster.java#L81) so the check of delayed item gets impacted by `MockTime`. @chia7712 thanks, nice catch. That does make things trickier. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #8669: MINOR: consolidate processor context for active/standby
ableegoldman commented on a change in pull request #8669: URL: https://github.com/apache/kafka/pull/8669#discussion_r426700737 ## File path: streams/src/test/java/org/apache/kafka/test/InternalMockProcessorContext.java ## @@ -52,6 +54,8 @@ import java.util.List; import java.util.Map; +import static org.apache.kafka.streams.processor.internals.ProcessorContextImpl.KEY_SERIALIZER; +import static org.apache.kafka.streams.processor.internals.ProcessorContextImpl.VALUE_SERIALIZER; Review comment: Ack This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-10015) React to Unexpected Errors on Stream Threads
Bruno Cadonna created KAFKA-10015: - Summary: React to Unexpected Errors on Stream Threads Key: KAFKA-10015 URL: https://issues.apache.org/jira/browse/KAFKA-10015 Project: Kafka Issue Type: Improvement Components: streams Reporter: Bruno Cadonna Currently, if an unexpected error occurs on a stream thread, the stream thread dies, a rebalance is triggered, and the Streams' client continues to run with less stream threads. Some errors trigger a cascading of stream thread death, i.e., after the rebalance that resulted from the death of the first thread the next thread dies, then a rebalance is triggered, the next thread dies, and so forth until all stream threads are dead and the instance shuts down. Such a chain of rebalances could be avoided if an error could be recognized as the cause of cascading stream deaths and as a consequence the Streams' client could be shut down after the first stream thread death. On the other hand, some unexpected errors are transient and the stream thread could safely be restarted without causing further errors and without the need to restart the Streams' client. The goal of this ticket is to classify errors and to automatically react to the errors in a way to avoid cascading deaths and to recover stream threads if possible. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10015) React Smartly to Unexpected Errors on Stream Threads
[ https://issues.apache.org/jira/browse/KAFKA-10015?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bruno Cadonna updated KAFKA-10015: -- Summary: React Smartly to Unexpected Errors on Stream Threads (was: React to Unexpected Errors on Stream Threads) > React Smartly to Unexpected Errors on Stream Threads > > > Key: KAFKA-10015 > URL: https://issues.apache.org/jira/browse/KAFKA-10015 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Bruno Cadonna >Priority: Major > > Currently, if an unexpected error occurs on a stream thread, the stream > thread dies, a rebalance is triggered, and the Streams' client continues to > run with less stream threads. > > Some errors trigger a cascading of stream thread death, i.e., after the > rebalance that resulted from the death of the first thread the next thread > dies, then a rebalance is triggered, the next thread dies, and so forth until > all stream threads are dead and the instance shuts down. Such a chain of > rebalances could be avoided if an error could be recognized as the cause of > cascading stream deaths and as a consequence the Streams' client could be > shut down after the first stream thread death. > On the other hand, some unexpected errors are transient and the stream thread > could safely be restarted without causing further errors and without the need > to restart the Streams' client. > The goal of this ticket is to classify errors and to automatically react to > the errors in a way to avoid cascading deaths and to recover stream threads > if possible. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (KAFKA-10015) React Smartly to Unexpected Errors on Stream Threads
[ https://issues.apache.org/jira/browse/KAFKA-10015?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bruno Cadonna reassigned KAFKA-10015: - Assignee: Bruno Cadonna > React Smartly to Unexpected Errors on Stream Threads > > > Key: KAFKA-10015 > URL: https://issues.apache.org/jira/browse/KAFKA-10015 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Bruno Cadonna >Assignee: Bruno Cadonna >Priority: Major > Labels: needs-kip > > Currently, if an unexpected error occurs on a stream thread, the stream > thread dies, a rebalance is triggered, and the Streams' client continues to > run with less stream threads. > > Some errors trigger a cascading of stream thread death, i.e., after the > rebalance that resulted from the death of the first thread the next thread > dies, then a rebalance is triggered, the next thread dies, and so forth until > all stream threads are dead and the instance shuts down. Such a chain of > rebalances could be avoided if an error could be recognized as the cause of > cascading stream deaths and as a consequence the Streams' client could be > shut down after the first stream thread death. > On the other hand, some unexpected errors are transient and the stream thread > could safely be restarted without causing further errors and without the need > to restart the Streams' client. > The goal of this ticket is to classify errors and to automatically react to > the errors in a way to avoid cascading deaths and to recover stream threads > if possible. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10015) React Smartly to Unexpected Errors on Stream Threads
[ https://issues.apache.org/jira/browse/KAFKA-10015?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bruno Cadonna updated KAFKA-10015: -- Labels: needs-kip (was: ) > React Smartly to Unexpected Errors on Stream Threads > > > Key: KAFKA-10015 > URL: https://issues.apache.org/jira/browse/KAFKA-10015 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Bruno Cadonna >Priority: Major > Labels: needs-kip > > Currently, if an unexpected error occurs on a stream thread, the stream > thread dies, a rebalance is triggered, and the Streams' client continues to > run with less stream threads. > > Some errors trigger a cascading of stream thread death, i.e., after the > rebalance that resulted from the death of the first thread the next thread > dies, then a rebalance is triggered, the next thread dies, and so forth until > all stream threads are dead and the instance shuts down. Such a chain of > rebalances could be avoided if an error could be recognized as the cause of > cascading stream deaths and as a consequence the Streams' client could be > shut down after the first stream thread death. > On the other hand, some unexpected errors are transient and the stream thread > could safely be restarted without causing further errors and without the need > to restart the Streams' client. > The goal of this ticket is to classify errors and to automatically react to > the errors in a way to avoid cascading deaths and to recover stream threads > if possible. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10015) React Smartly to Unexpected Errors on Stream Threads
[ https://issues.apache.org/jira/browse/KAFKA-10015?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bruno Cadonna updated KAFKA-10015: -- Affects Version/s: 2.5.0 > React Smartly to Unexpected Errors on Stream Threads > > > Key: KAFKA-10015 > URL: https://issues.apache.org/jira/browse/KAFKA-10015 > Project: Kafka > Issue Type: Improvement > Components: streams >Affects Versions: 2.5.0 >Reporter: Bruno Cadonna >Assignee: Bruno Cadonna >Priority: Major > Labels: needs-kip > > Currently, if an unexpected error occurs on a stream thread, the stream > thread dies, a rebalance is triggered, and the Streams' client continues to > run with less stream threads. > > Some errors trigger a cascading of stream thread death, i.e., after the > rebalance that resulted from the death of the first thread the next thread > dies, then a rebalance is triggered, the next thread dies, and so forth until > all stream threads are dead and the instance shuts down. Such a chain of > rebalances could be avoided if an error could be recognized as the cause of > cascading stream deaths and as a consequence the Streams' client could be > shut down after the first stream thread death. > On the other hand, some unexpected errors are transient and the stream thread > could safely be restarted without causing further errors and without the need > to restart the Streams' client. > The goal of this ticket is to classify errors and to automatically react to > the errors in a way to avoid cascading deaths and to recover stream threads > if possible. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] mumrah commented on a change in pull request #8376: KAFKA-9724 Newer clients not always sending fetch request to older brokers
mumrah commented on a change in pull request #8376:
URL: https://github.com/apache/kafka/pull/8376#discussion_r426722927
##
File path: clients/src/test/java/org/apache/kafka/clients/MetadataTest.java
##
@@ -378,26 +382,6 @@ public void testRejectOldMetadata() {
}
}
-@Test
-public void testMaybeRequestUpdate() {
Review comment:
I ended up writing a new test `testUpdateLastEpoch`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on pull request #8682: KAFKA-10011: Remove task id from lockedTaskDirectories during handleLostAll
vvcephei commented on pull request #8682: URL: https://github.com/apache/kafka/pull/8682#issuecomment-630272579 Test this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on pull request #8221: KAFKA-9561: update task input partitions after rebalance
guozhangwang commented on pull request #8221: URL: https://github.com/apache/kafka/pull/8221#issuecomment-630279061 test this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang merged pull request #8686: MINOR: Remove redundant TOC and introduction in Running Streams Applications
guozhangwang merged pull request #8686: URL: https://github.com/apache/kafka/pull/8686 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on pull request #8221: KAFKA-9561: update task input partitions after rebalance
guozhangwang commented on pull request #8221: URL: https://github.com/apache/kafka/pull/8221#issuecomment-630297298 test this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on a change in pull request #8669: MINOR: consolidate processor context for active/standby
guozhangwang commented on a change in pull request #8669:
URL: https://github.com/apache/kafka/pull/8669#discussion_r426754892
##
File path:
streams/src/test/java/org/apache/kafka/test/InternalMockProcessorContext.java
##
@@ -349,6 +353,27 @@ public Headers headers() {
return recordContext.headers();
}
+@Override
+public TaskType taskType() {
+return TaskType.ACTIVE;
+}
+
+@Override
+public void logChange(final String storeName,
+ final Bytes key,
+ final byte[] value,
+ final long timestamp) {
+recordCollector().send(
Review comment:
No I do not, just wanting to make sure we do not have any major
conflicts when rebasing the other.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on pull request #8669: MINOR: consolidate processor context for active/standby
guozhangwang commented on pull request #8669: URL: https://github.com/apache/kafka/pull/8669#issuecomment-630299683 test this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on pull request #8669: MINOR: consolidate processor context for active/standby
guozhangwang commented on pull request #8669: URL: https://github.com/apache/kafka/pull/8669#issuecomment-630299873 LGTM. Will merge after green builds. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-6520) When a Kafka Stream can't communicate with the server, it's Status stays RUNNING
[ https://issues.apache.org/jira/browse/KAFKA-6520?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110447#comment-17110447 ] Guozhang Wang commented on KAFKA-6520: -- Just to throw some more ideas here: the embedded clients are now all using async network IO and hence one would never get ClosedChannelException, instead, they will eventually get TimeoutException when the broker is actually offline. [~mjsax] is currently working on KIP-572 to let Streams be more resilient to such connectivity issues (broker unavailable is exposed the same as network in-connectivity), while if we have N tasks, we would still continue when only a subset of them cannot progress. On the other hand, a Streams client may talk to multiple brokers on behalf of different tasks, and as long as one of the tasks can still progress -- meaning, its corresponding required brokers are still reachable -- then we would not need to mark the client as disconnected. Following this train of thoughts, I feel that we would only transit to the DISCONNECTED state if none of the tasks are progressing, indicating that none of the required brokers are available at the moment. Does that make sense? If yes then the scope of it can be much simplified, and maybe we can also just piggyback the proposal as part of KIP-572 so that we do not need a separate KIP. Of course, implementation wise Vince and Matthias can still proceed independently. > When a Kafka Stream can't communicate with the server, it's Status stays > RUNNING > > > Key: KAFKA-6520 > URL: https://issues.apache.org/jira/browse/KAFKA-6520 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Michael Kohout >Priority: Major > Labels: newbie, user-experience > > KIP WIP: > [https://cwiki.apache.org/confluence/display/KAFKA/KIP-457%3A+Add+DISCONNECTED+status+to+Kafka+Streams] > When you execute the following scenario the application is always in RUNNING > state > > 1)start kafka > 2)start app, app connects to kafka and starts processing > 3)kill kafka(stop docker container) > 4)the application doesn't give any indication that it's no longer > connected(Stream State is still RUNNING, and the uncaught exception handler > isn't invoked) > > > It would be useful if the Stream State had a DISCONNECTED status. > > See > [this|https://groups.google.com/forum/#!topic/confluent-platform/nQh2ohgdrIQ] > for a discussion from the google user forum. This is a link to a related > issue. > - > Update: there are some discussions on the PR itself which leads me to think > that a more general solution should be at the ClusterConnectionStates rather > than at the Streams or even Consumer level. One proposal would be: > * Add a new metric named `failedConnection` in SelectorMetrics which is > recorded at `connect()` and `pollSelectionKeys()` functions, upon capture the > IOException / RuntimeException which indicates the connection disconnected. > * And then users of Consumer / Streams can monitor on this metric, which > normally will only have close to zero values as we have transient > disconnects, if it is spiking it means the brokers are consistently being > unavailable indicting the state. > [~Yohan123] WDYT? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] guozhangwang commented on pull request #8669: MINOR: consolidate processor context for active/standby
guozhangwang commented on pull request #8669: URL: https://github.com/apache/kafka/pull/8669#issuecomment-630320804 test this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] guozhangwang commented on pull request #8221: KAFKA-9561: update task input partitions after rebalance
guozhangwang commented on pull request #8221: URL: https://github.com/apache/kafka/pull/8221#issuecomment-630321714 `:streams:spotbugsMain` failed, cc @avalsa You can run the command locally to find out which sptobugMain rule is violated. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (KAFKA-10008) Symbol not found when running Kafka Streams with RocksDB dependency on MacOS 10.13.6
[
https://issues.apache.org/jira/browse/KAFKA-10008?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax reassigned KAFKA-10008:
---
Assignee: Matthias J. Sax
> Symbol not found when running Kafka Streams with RocksDB dependency on MacOS
> 10.13.6
>
>
> Key: KAFKA-10008
> URL: https://issues.apache.org/jira/browse/KAFKA-10008
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.6.0
> Environment: MacOS 10.13.6
>Reporter: Victoria Xia
>Assignee: Matthias J. Sax
>Priority: Major
>
> In bumping the RocksDB dependency version from 5.18.3 to 5.18.4 on trunk,
> Kafka Streams apps that require initializing RocksDB state stores fail on
> MacOS 10.13.6 with
> {code:java}
> dyld: lazy symbol binding failed: Symbol not found: chkstk_darwin
> Referenced from:
> /private/var/folders/y4/v3q4tgb559sb0x6kwpll19bmgn/T/librocksdbjni4028367213086899694.jnilib
> (which was built for Mac OS X 10.15)
> Expected in: /usr/lib/libSystem.B.dylib
> {code}
> as a result of [https://github.com/facebook/rocksdb/issues/6852]
> 2.5.0 is unaffected.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] mjsax opened a new pull request #8687: MINOR: updated MacOS compatibility statement for RocksDB
mjsax opened a new pull request #8687: URL: https://github.com/apache/kafka/pull/8687 With https://issues.apache.org/jira/browse/KAFKA-9225 Kafka Streams 2.6.0 requires MacOS 10.15. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax commented on pull request #8687: MINOR: updated MacOS compatibility statement for RocksDB
mjsax commented on pull request #8687: URL: https://github.com/apache/kafka/pull/8687#issuecomment-630327661 Call for review @ableegoldman @vcrfxia @guozhangwang This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10008) Symbol not found when running Kafka Streams with RocksDB dependency on MacOS 10.13.6
[
https://issues.apache.org/jira/browse/KAFKA-10008?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110478#comment-17110478
]
Matthias J. Sax commented on KAFKA-10008:
-
Opened a PR to update the docs: https://github.com/apache/kafka/pull/8687
> Symbol not found when running Kafka Streams with RocksDB dependency on MacOS
> 10.13.6
>
>
> Key: KAFKA-10008
> URL: https://issues.apache.org/jira/browse/KAFKA-10008
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.6.0
> Environment: MacOS 10.13.6
>Reporter: Victoria Xia
>Assignee: Matthias J. Sax
>Priority: Major
>
> In bumping the RocksDB dependency version from 5.18.3 to 5.18.4 on trunk,
> Kafka Streams apps that require initializing RocksDB state stores fail on
> MacOS 10.13.6 with
> {code:java}
> dyld: lazy symbol binding failed: Symbol not found: chkstk_darwin
> Referenced from:
> /private/var/folders/y4/v3q4tgb559sb0x6kwpll19bmgn/T/librocksdbjni4028367213086899694.jnilib
> (which was built for Mac OS X 10.15)
> Expected in: /usr/lib/libSystem.B.dylib
> {code}
> as a result of [https://github.com/facebook/rocksdb/issues/6852]
> 2.5.0 is unaffected.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (KAFKA-10012) Reducing memory overhead associated with strings in MetricName
[
https://issues.apache.org/jira/browse/KAFKA-10012?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Navina Ramesh reassigned KAFKA-10012:
-
Assignee: Navina Ramesh
> Reducing memory overhead associated with strings in MetricName
> --
>
> Key: KAFKA-10012
> URL: https://issues.apache.org/jira/browse/KAFKA-10012
> Project: Kafka
> Issue Type: Improvement
> Components: network
>Reporter: Navina Ramesh
>Assignee: Navina Ramesh
>Priority: Major
>
> {{SelectorMetrics}} has a per-connection metrics, which means the number of
> {{MetricName}} objects and the strings associated with it (such as group name
> and description) grows with the number of connections in the client. This
> overhead of duplicate string objects is amplified when there are multiple
> instances of kafka clients within the same JVM.
> This patch address some of the memory overhead by making {{metricGrpName}} a
> constant and introducing a new constant {{perConnectionMetricGrpName}}.
> Additionally, the strings for metric name and description in {{createMeter}}
> have been interned since there are about 8 per-client and 4 per-connection
> {{Meter}} instances.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-7870) Error sending fetch request (sessionId=1578860481, epoch=INITIAL) to node 2: java.io.IOException: Connection to 2 was disconnected before the response was read.
[
https://issues.apache.org/jira/browse/KAFKA-7870?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110489#comment-17110489
]
Nicolas Martinez Varsi commented on KAFKA-7870:
---
Any news on this? We upgraded from 2.0.0 to 2.1.0 and this error started to
appear.
Besides restarting/stopping the problematic broker, are there any workarounds?
> Error sending fetch request (sessionId=1578860481, epoch=INITIAL) to node 2:
> java.io.IOException: Connection to 2 was disconnected before the response was
> read.
>
>
> Key: KAFKA-7870
> URL: https://issues.apache.org/jira/browse/KAFKA-7870
> Project: Kafka
> Issue Type: Bug
> Components: clients
>Affects Versions: 2.1.0
>Reporter: Chakhsu Lau
>Priority: Blocker
>
> We build a kafka cluster with 5 brokers. But one of brokers suddenly stopped
> running during the run. And it happened twice in the same broker. Here is the
> log and is this a bug in kafka ?
> {code:java}
> [2019-01-25 12:57:14,686] INFO [ReplicaFetcher replicaId=3, leaderId=2,
> fetcherId=0] Error sending fetch request (sessionId=1578860481,
> epoch=INITIAL) to node 2: java.io.IOException: Connection to 2 was
> disconnected before the response was read.
> (org.apache.kafka.clients.FetchSessionHandler)
> [2019-01-25 12:57:14,687] WARN [ReplicaFetcher replicaId=3, leaderId=2,
> fetcherId=0] Error in response for fetch request (type=FetchRequest,
> replicaId=3, maxWait=500, minBytes=1, maxBytes=10485760,
> fetchData={api-result-bi-heatmap-8=(offset=0, logStartOffset=0,
> maxBytes=1048576, currentLeaderEpoch=Optional[4]),
> api-result-bi-heatmap-save-12=(offset=0, logStartOffset=0, maxBytes=1048576,
> currentLeaderEpoch=Optional[4]), api-result-bi-heatmap-task-2=(offset=2,
> logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[4]),
> api-result-bi-flow-39=(offset=1883206, logStartOffset=0, maxBytes=1048576,
> currentLeaderEpoch=Optional[4]), __consumer_offsets-47=(offset=349437,
> logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[4]),
> api-result-bi-heatmap-track-6=(offset=1039889, logStartOffset=0,
> maxBytes=1048576, currentLeaderEpoch=Optional[4]),
> api-result-bi-heatmap-task-17=(offset=0, logStartOffset=0, maxBytes=1048576,
> currentLeaderEpoch=Optional[4]), __consumer_offsets-2=(offset=0,
> logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[4]),
> api-result-bi-heatmap-aggs-19=(offset=1255056, logStartOffset=0,
> maxBytes=1048576, currentLeaderEpoch=Optional[4])},
> isolationLevel=READ_UNCOMMITTED, toForget=, metadata=(sessionId=1578860481,
> epoch=INITIAL)) (kafka.server.ReplicaFetcherThread)
> java.io.IOException: Connection to 2 was disconnected before the response was
> read
> at
> org.apache.kafka.clients.NetworkClientUtils.sendAndReceive(NetworkClientUtils.java:97)
> at
> kafka.server.ReplicaFetcherBlockingSend.sendRequest(ReplicaFetcherBlockingSend.scala:97)
> at
> kafka.server.ReplicaFetcherThread.fetchFromLeader(ReplicaFetcherThread.scala:190)
> at
> kafka.server.AbstractFetcherThread.kafka$server$AbstractFetcherThread$$processFetchRequest(AbstractFetcherThread.scala:241)
> at
> kafka.server.AbstractFetcherThread$$anonfun$maybeFetch$1.apply(AbstractFetcherThread.scala:130)
> at
> kafka.server.AbstractFetcherThread$$anonfun$maybeFetch$1.apply(AbstractFetcherThread.scala:129)
> at scala.Option.foreach(Option.scala:257)
> at
> kafka.server.AbstractFetcherThread.maybeFetch(AbstractFetcherThread.scala:129)
> at kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:111)
> at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:82)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (KAFKA-10008) Symbol not found when running Kafka Streams with RocksDB dependency on MacOS 10.13.6
[
https://issues.apache.org/jira/browse/KAFKA-10008?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
John Roesler resolved KAFKA-10008.
--
Resolution: Won't Fix
Following the other comments, we've decided just to document it.
> Symbol not found when running Kafka Streams with RocksDB dependency on MacOS
> 10.13.6
>
>
> Key: KAFKA-10008
> URL: https://issues.apache.org/jira/browse/KAFKA-10008
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.6.0
> Environment: MacOS 10.13.6
>Reporter: Victoria Xia
>Assignee: Matthias J. Sax
>Priority: Major
>
> In bumping the RocksDB dependency version from 5.18.3 to 5.18.4 on trunk,
> Kafka Streams apps that require initializing RocksDB state stores fail on
> MacOS 10.13.6 with
> {code:java}
> dyld: lazy symbol binding failed: Symbol not found: chkstk_darwin
> Referenced from:
> /private/var/folders/y4/v3q4tgb559sb0x6kwpll19bmgn/T/librocksdbjni4028367213086899694.jnilib
> (which was built for Mac OS X 10.15)
> Expected in: /usr/lib/libSystem.B.dylib
> {code}
> as a result of [https://github.com/facebook/rocksdb/issues/6852]
> 2.5.0 is unaffected.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-9981) Running a dedicated mm2 cluster with more than one nodes,When the configuration is updated the task is not aware and will lose the update operation.
[
https://issues.apache.org/jira/browse/KAFKA-9981?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110488#comment-17110488
]
Chris Egerton commented on KAFKA-9981:
--
[~qq619618919] we could but it wouldn't be simple. We'd have to take care to
ensure that writes from zombie workers would be ignored, which is done right
now by only allowing the leader to write to the config topic.
I think it'd be easier to bring up the task configs endpoint for MM2 than to
re-architect the Connect framework, especially given the compatibility and
migration concerns that would have to be addressed in order to allow non-leader
workers to write to the config topic. But either approach would work.
> Running a dedicated mm2 cluster with more than one nodes,When the
> configuration is updated the task is not aware and will lose the update
> operation.
>
>
> Key: KAFKA-9981
> URL: https://issues.apache.org/jira/browse/KAFKA-9981
> Project: Kafka
> Issue Type: Bug
> Components: mirrormaker
>Affects Versions: 2.4.0, 2.5.0, 2.4.1
>Reporter: victor
>Priority: Major
>
> DistributedHerder.reconfigureConnector induction config update as follows:
> {code:java}
> if (changed) {
> List> rawTaskProps = reverseTransform(connName,
> configState, taskProps);
> if (isLeader()) {
> configBackingStore.putTaskConfigs(connName, rawTaskProps);
> cb.onCompletion(null, null);
> } else {
> // We cannot forward the request on the same thread because this
> reconfiguration can happen as a result of connector
> // addition or removal. If we blocked waiting for the response from
> leader, we may be kicked out of the worker group.
> forwardRequestExecutor.submit(new Runnable() {
> @Override
> public void run() {
> try {
> String leaderUrl = leaderUrl();
> if (leaderUrl == null || leaderUrl.trim().isEmpty()) {
> cb.onCompletion(new ConnectException("Request to
> leader to " +
> "reconfigure connector tasks failed " +
> "because the URL of the leader's REST
> interface is empty!"), null);
> return;
> }
> String reconfigUrl = RestServer.urlJoin(leaderUrl,
> "/connectors/" + connName + "/tasks");
> log.trace("Forwarding task configurations for connector
> {} to leader", connName);
> RestClient.httpRequest(reconfigUrl, "POST", null,
> rawTaskProps, null, config, sessionKey, requestSignatureAlgorithm);
> cb.onCompletion(null, null);
> } catch (ConnectException e) {
> log.error("Request to leader to reconfigure connector
> tasks failed", e);
> cb.onCompletion(e, null);
> }
> }
> });
> }
> }
> {code}
> KafkaConfigBackingStore task checks for configuration updates,such as topic
> whitelist update.If KafkaConfigBackingStore task is not running on leader
> node,an HTTP request will be send to notify the leader of the configuration
> update.However,dedicated mm2 cluster does not have the HTTP server turned
> on,so the request will fail to be sent,causing the update operation to be
> lost.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (KAFKA-9994) Catch TaskMigrated exception in task corruption code path
[
https://issues.apache.org/jira/browse/KAFKA-9994?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
John Roesler reassigned KAFKA-9994:
---
Assignee: Boyang Chen
> Catch TaskMigrated exception in task corruption code path
> --
>
> Key: KAFKA-9994
> URL: https://issues.apache.org/jira/browse/KAFKA-9994
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Reporter: Boyang Chen
>Assignee: Boyang Chen
>Priority: Major
>
> We have seen a case where the TaskMigrated exception gets thrown from
> taskManager.commit(). This should be prevented by proper catching.
> Looking at the stack trace, the TaskMigrated was thrown from preCommit() call
> inside corrupted task exception commit.
> {code:java}
> [2020-05-14T05:47:25-07:00]
> (streams-soak-trunk-eos_soak_i-0b5b559dda7970618_streamslog) [2020-05-14
> 12:47:25,635] ERROR
> [stream-soak-test-db8d1d42-5677-4a54-a0a1-89b7b0766493-StreamThread-1]
> stream-thread
> [stream-soak-test-db8d1d42-5677-4a54-a0a1-89b7b0766493-StreamThread-1]
> Encountered the following exception during processing and the thread is going
> to shut down: (org.apache.kafka.streams.processor.internals.StreamThread)
> [2020-05-14T05:47:25-07:00]
> (streams-soak-trunk-eos_soak_i-0b5b559dda7970618_streamslog)
> org.apache.kafka.streams.errors.TaskMigratedException: Producer got fenced
> trying to send a record [stream-thread
> [stream-soak-test-db8d1d42-5677-4a54-a0a1-89b7b0766493-StreamThread-1] task
> [1_1]]; it means all tasks belonging to this thread should be migrated.
> at
> org.apache.kafka.streams.processor.internals.StreamsProducer.send(StreamsProducer.java:216)
> at
> org.apache.kafka.streams.processor.internals.RecordCollectorImpl.send(RecordCollectorImpl.java:171)
> at
> org.apache.kafka.streams.state.internals.StoreChangeLogger.logChange(StoreChangeLogger.java:69)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingTimestampedWindowBytesStore.log(ChangeLoggingTimestampedWindowBytesStore.java:36)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.put(ChangeLoggingWindowBytesStore.java:112)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.put(ChangeLoggingWindowBytesStore.java:34)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.putAndMaybeForward(CachingWindowStore.java:111)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.lambda$initInternal$0(CachingWindowStore.java:91)
> at
> org.apache.kafka.streams.state.internals.NamedCache.flush(NamedCache.java:151)
> at
> org.apache.kafka.streams.state.internals.NamedCache.flush(NamedCache.java:109)
> at
> org.apache.kafka.streams.state.internals.ThreadCache.flush(ThreadCache.java:124)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.flush(CachingWindowStore.java:296)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.flush(WrappedStateStore.java:84)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.lambda$flush$4(MeteredWindowStore.java:200)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:804)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.flush(MeteredWindowStore.java:200)
> at
> org.apache.kafka.streams.processor.internals.ProcessorStateManager.flush(ProcessorStateManager.java:402)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.prepareCommit(StreamTask.java:317)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.commit(TaskManager.java:753)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:573)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:517)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (KAFKA-9994) Catch TaskMigrated exception in task corruption code path
[
https://issues.apache.org/jira/browse/KAFKA-9994?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
John Roesler resolved KAFKA-9994.
-
Resolution: Fixed
> Catch TaskMigrated exception in task corruption code path
> --
>
> Key: KAFKA-9994
> URL: https://issues.apache.org/jira/browse/KAFKA-9994
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Reporter: Boyang Chen
>Assignee: Boyang Chen
>Priority: Major
>
> We have seen a case where the TaskMigrated exception gets thrown from
> taskManager.commit(). This should be prevented by proper catching.
> Looking at the stack trace, the TaskMigrated was thrown from preCommit() call
> inside corrupted task exception commit.
> {code:java}
> [2020-05-14T05:47:25-07:00]
> (streams-soak-trunk-eos_soak_i-0b5b559dda7970618_streamslog) [2020-05-14
> 12:47:25,635] ERROR
> [stream-soak-test-db8d1d42-5677-4a54-a0a1-89b7b0766493-StreamThread-1]
> stream-thread
> [stream-soak-test-db8d1d42-5677-4a54-a0a1-89b7b0766493-StreamThread-1]
> Encountered the following exception during processing and the thread is going
> to shut down: (org.apache.kafka.streams.processor.internals.StreamThread)
> [2020-05-14T05:47:25-07:00]
> (streams-soak-trunk-eos_soak_i-0b5b559dda7970618_streamslog)
> org.apache.kafka.streams.errors.TaskMigratedException: Producer got fenced
> trying to send a record [stream-thread
> [stream-soak-test-db8d1d42-5677-4a54-a0a1-89b7b0766493-StreamThread-1] task
> [1_1]]; it means all tasks belonging to this thread should be migrated.
> at
> org.apache.kafka.streams.processor.internals.StreamsProducer.send(StreamsProducer.java:216)
> at
> org.apache.kafka.streams.processor.internals.RecordCollectorImpl.send(RecordCollectorImpl.java:171)
> at
> org.apache.kafka.streams.state.internals.StoreChangeLogger.logChange(StoreChangeLogger.java:69)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingTimestampedWindowBytesStore.log(ChangeLoggingTimestampedWindowBytesStore.java:36)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.put(ChangeLoggingWindowBytesStore.java:112)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.put(ChangeLoggingWindowBytesStore.java:34)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.putAndMaybeForward(CachingWindowStore.java:111)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.lambda$initInternal$0(CachingWindowStore.java:91)
> at
> org.apache.kafka.streams.state.internals.NamedCache.flush(NamedCache.java:151)
> at
> org.apache.kafka.streams.state.internals.NamedCache.flush(NamedCache.java:109)
> at
> org.apache.kafka.streams.state.internals.ThreadCache.flush(ThreadCache.java:124)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.flush(CachingWindowStore.java:296)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.flush(WrappedStateStore.java:84)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.lambda$flush$4(MeteredWindowStore.java:200)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:804)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.flush(MeteredWindowStore.java:200)
> at
> org.apache.kafka.streams.processor.internals.ProcessorStateManager.flush(ProcessorStateManager.java:402)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.prepareCommit(StreamTask.java:317)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.commit(TaskManager.java:753)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:573)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:517)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-4748) Need a way to shutdown all workers in a Streams application at the same time
[ https://issues.apache.org/jira/browse/KAFKA-4748?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110493#comment-17110493 ] Matthias J. Sax commented on KAFKA-4748: Thanks for clarifying [~astubbs] > Need a way to shutdown all workers in a Streams application at the same time > > > Key: KAFKA-4748 > URL: https://issues.apache.org/jira/browse/KAFKA-4748 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 0.10.1.1 >Reporter: Elias Levy >Priority: Major > > If you have a fleet of Stream workers for an application and attempt to shut > them down simultaneously (e.g. via SIGTERM and > Runtime.getRuntime().addShutdownHook() and streams.close())), a large number > of the workers fail to shutdown. > The problem appears to be a race condition between the shutdown signal and > the consumer rebalancing that is triggered by some of the workers existing > before others. Apparently, workers that receive the signal later fail to > exit apparently as they are caught in the rebalance. > Terminating workers in a rolling fashion is not advisable in some situations. > The rolling shutdown will result in many unnecessary rebalances and may > fail, as the application may have large amount of local state that a smaller > number of nodes may not be able to store. > It would appear that there is a need for a protocol change to allow the > coordinator to signal a consumer group to shutdown without leading to > rebalancing. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (KAFKA-9989) StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor gets assigned task
[ https://issues.apache.org/jira/browse/KAFKA-9989?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] John Roesler reassigned KAFKA-9989: --- Assignee: Boyang Chen > StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor > gets assigned task > - > > Key: KAFKA-9989 > URL: https://issues.apache.org/jira/browse/KAFKA-9989 > Project: Kafka > Issue Type: Bug > Components: streams, system tests >Reporter: Boyang Chen >Assignee: Boyang Chen >Priority: Major > > System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: > "Never saw output 'processed [0-9]* records' on ubuntu@worker6" > which if we take a closer look at, the rebalance happens but has no task > assignment. We should fix this problem by making the rebalance result as part > of the check, and skip the record processing validation when the assignment > is empty. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-6182) Automatic co-partitioning of topics via automatic intermediate topic with matching partitions
[ https://issues.apache.org/jira/browse/KAFKA-6182?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110497#comment-17110497 ] Matthias J. Sax commented on KAFKA-6182: Failing fast is not covered via KIP-221, but there are other tickets that would address it: KAFKA-10015 and KAFKA-4748 seem related for a "fail fast" feature. > Automatic co-partitioning of topics via automatic intermediate topic with > matching partitions > - > > Key: KAFKA-6182 > URL: https://issues.apache.org/jira/browse/KAFKA-6182 > Project: Kafka > Issue Type: New Feature > Components: streams >Affects Versions: 1.0.0 >Reporter: Antony Stubbs >Priority: Major > > Currently it is up to the user to ensure that two input topics for a join > have the same number of partitions, and if they don't, manually create an > intermediate topic, and send the stream #through that topic first, and then > performing the join. > It would be great to have Kafka streams detect this and at least give the > user the option to create an intermediate topic automatically with the same > number of partitions as the topic being joined with. > See > https://docs.confluent.io/current/streams/developer-guide.html#joins-require-co-partitioning-of-the-input-data -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] ableegoldman commented on pull request #8682: KAFKA-10011: Remove task id from lockedTaskDirectories during handleLostAll
ableegoldman commented on pull request #8682: URL: https://github.com/apache/kafka/pull/8682#issuecomment-630344469 Instead of removing the tasks during `handleLostAll`, can we just clear the `lockedTaskDirectories` set at the end of `releaseLockedUnassignedTaskDirectories`? This set is only used to keep track of which task directories we only temporarily locked for the rebalance, so it makes sense that it should be empty outside of a rebalance. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #8622: MINOR: Update stream documentation
ableegoldman commented on a change in pull request #8622:
URL: https://github.com/apache/kafka/pull/8622#discussion_r426808431
##
File path: docs/streams/upgrade-guide.html
##
@@ -35,7 +35,7 @@ Upgrade Guide and API Changes
Upgrading from any older version to {{fullDotVersion}} is possible:
you will need to do two rolling bounces, where during the first rolling bounce
phase you set the config upgrade.from="older version"
-(possible values are "0.10.0" - "2.3") and during the
second you remove it. This is required to safely upgrade to the new cooperative
rebalancing protocol of the embedded consumer. Note that you will remain using
the old eager
+(possible values are "0.10.0" - "2.4") and during the
second you remove it. This is required to safely upgrade to the new cooperative
rebalancing protocol of the embedded consumer. Note that you will remain using
the old eager
Review comment:
@showuon Boyang is right, there is no `upgrade.from` config for 2.4
since that's when cooperative rebalancing was enabled. So if you upgrade to 2.5
from any version lower than 2.4, you will need to go through this upgrade path
and set the config.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #8569: KIP-551: Expose disk read and write metrics
cmccabe commented on a change in pull request #8569:
URL: https://github.com/apache/kafka/pull/8569#discussion_r426808657
##
File path: core/src/main/scala/kafka/metrics/LinuxIoMetricsCollector.scala
##
@@ -0,0 +1,102 @@
+/**
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package kafka.server
+
+import java.nio.file.{Files, Paths}
+
+import org.apache.kafka.common.utils.Time
+import org.slf4j.Logger
+
+import scala.jdk.CollectionConverters._
+
+/**
+ * Retrieves Linux /proc/self/io metrics.
+ */
+class LinuxIoMetricsCollector(procRoot: String, val time: Time, val logger:
Logger) {
+ import LinuxIoMetricsCollector._
+ var lastUpdateMs = -1L
+ var cachedReadBytes = 0L
+ var cachedWriteBytes = 0L
+ val path = Paths.get(procRoot, "self", "io")
+
+ def readBytes(): Long = this.synchronized {
+val curMs = time.milliseconds()
Review comment:
Interesting idea, but that would complicate the `usable` function,
right? Probably better to leave it where it is.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-6579) Consolidate window store and session store unit tests into a single class
[
https://issues.apache.org/jira/browse/KAFKA-6579?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110508#comment-17110508
]
Sophie Blee-Goldman commented on KAFKA-6579:
No, I looked into it but the scope its nontrivial. I'll unassign it and maybe
someone from the community can pick it up ^^
> Consolidate window store and session store unit tests into a single class
> -
>
> Key: KAFKA-6579
> URL: https://issues.apache.org/jira/browse/KAFKA-6579
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Reporter: Guozhang Wang
>Assignee: Sophie Blee-Goldman
>Priority: Major
> Labels: newbie, unit-test
>
> For key value store, we have a {{AbstractKeyValueStoreTest}} that is shared
> among all its implementations; however for window and session stores, each
> class has its own independent unit test classes that do not share the test
> coverage. In fact, many of these test classes share the same unit test
> functions (e.g. {{RocksDBWindowStoreTest}},
> {{CompositeReadOnlyWindowStoreTest}} and {{CachingWindowStoreTest}}).
> It is better to use the same pattern as for key value stores to consolidate
> these test functions into a shared base class.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (KAFKA-6579) Consolidate window store and session store unit tests into a single class
[
https://issues.apache.org/jira/browse/KAFKA-6579?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sophie Blee-Goldman reassigned KAFKA-6579:
--
Assignee: (was: Sophie Blee-Goldman)
> Consolidate window store and session store unit tests into a single class
> -
>
> Key: KAFKA-6579
> URL: https://issues.apache.org/jira/browse/KAFKA-6579
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Reporter: Guozhang Wang
>Priority: Major
> Labels: newbie, unit-test
>
> For key value store, we have a {{AbstractKeyValueStoreTest}} that is shared
> among all its implementations; however for window and session stores, each
> class has its own independent unit test classes that do not share the test
> coverage. In fact, many of these test classes share the same unit test
> functions (e.g. {{RocksDBWindowStoreTest}},
> {{CompositeReadOnlyWindowStoreTest}} and {{CachingWindowStoreTest}}).
> It is better to use the same pattern as for key value stores to consolidate
> these test functions into a shared base class.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] cmccabe commented on pull request #8569: KIP-551: Expose disk read and write metrics
cmccabe commented on pull request #8569: URL: https://github.com/apache/kafka/pull/8569#issuecomment-630352959 @mumrah : Good question. I don't think anyone has looked at Sigar. I guess the question is whether we want to get into the business of doing general-purpose node monitoring. I think many people would say no. We're doing this metric mainly because it's very simple to check, and also very impactful for Kafka (starting heavy disk reads often correlates with performance tanking). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma opened a new pull request #8688: MINOR: Introduce separate methods in KafkaApis for consumer and follower fetch handling
ijuma opened a new pull request #8688: URL: https://github.com/apache/kafka/pull/8688 This is a bit odd in that it's not needed from a semantics perspective, but it would make it much easier to distinguish the cost of follower fetches versus consumer fetches when profiling. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10010) Should close standby task for safety during HandleLostAll
[
https://issues.apache.org/jira/browse/KAFKA-10010?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110518#comment-17110518
]
Sophie Blee-Goldman commented on KAFKA-10010:
-
It's possible the active <-> standby task conversion PR would actually fix this
on the side, as it skips re-registering any store that's already registered.
I'd like to avoid closing standbys during handleLostAll since this will
completely clear out any in-memory stores, for example
> Should close standby task for safety during HandleLostAll
> -
>
> Key: KAFKA-10010
> URL: https://issues.apache.org/jira/browse/KAFKA-10010
> Project: Kafka
> Issue Type: Bug
>Reporter: Boyang Chen
>Assignee: Boyang Chen
>Priority: Major
>
> The current lost all logic doesn't close standby task, which could
> potentially lead to a tricky condition like below:
> 1. The standby task was initializing as `CREATED` state, and task corrupted
> exception was thrown from registerStateStores
> 2. The task corrupted exception was caught, and do a non-affected task commit
> 3. The task commit failed due to task migrated exception
> 4. The handleLostAll didn't close the standby task, leaving it as CREATED
> state
> 5. Next rebalance complete, the same task was assigned back as standby task.
> 6. Illegal Argument exception caught :
> {code:java}
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog) [2020-05-16
> 18:56:18,050] ERROR
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> Encountered the following exception during processing and the thread is going
> to shut down: (org.apache.kafka.streams.processor.internals.StreamThread)
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog)
> java.lang.IllegalArgumentException: stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> standby-task [1_2] Store KSTREAM-AGGREGATE-STATE-STORE-07 has already
> been registered.
> at
> org.apache.kafka.streams.processor.internals.ProcessorStateManager.registerStore(ProcessorStateManager.java:269)
> at
> org.apache.kafka.streams.processor.internals.AbstractProcessorContext.register(AbstractProcessorContext.java:112)
> at
> org.apache.kafka.streams.state.internals.AbstractRocksDBSegmentedBytesStore.init(AbstractRocksDBSegmentedBytesStore.java:191)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.RocksDBWindowStore.init(RocksDBWindowStore.java:48)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.init(ChangeLoggingWindowBytesStore.java:54)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.init(CachingWindowStore.java:74)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.lambda$init$0(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:804)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.init(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.StateManagerUtil.registerStateStores(StateManagerUtil.java:82)
> at
> org.apache.kafka.streams.processor.internals.StandbyTask.initializeIfNeeded(StandbyTask.java:89)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.tryToCompleteRestoration(TaskManager.java:358)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:664)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:550)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:509)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-10010) Should close standby task for safety during HandleLostAll
[
https://issues.apache.org/jira/browse/KAFKA-10010?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110522#comment-17110522
]
Sophie Blee-Goldman commented on KAFKA-10010:
-
When I first started looking into the store registration and initialization
logic for that PR, I remember thinking there was a bug since we would attempt
to re-register stores if we hit an exception halfway through registration. I
snooped around and it seemed like there wasn't really a way to hit this bug,
but I fixed it anyways.
Seems like there actually was a way to hit this bug after all, so nice catch
[~bchen225242]
> Should close standby task for safety during HandleLostAll
> -
>
> Key: KAFKA-10010
> URL: https://issues.apache.org/jira/browse/KAFKA-10010
> Project: Kafka
> Issue Type: Bug
>Reporter: Boyang Chen
>Assignee: Boyang Chen
>Priority: Major
>
> The current lost all logic doesn't close standby task, which could
> potentially lead to a tricky condition like below:
> 1. The standby task was initializing as `CREATED` state, and task corrupted
> exception was thrown from registerStateStores
> 2. The task corrupted exception was caught, and do a non-affected task commit
> 3. The task commit failed due to task migrated exception
> 4. The handleLostAll didn't close the standby task, leaving it as CREATED
> state
> 5. Next rebalance complete, the same task was assigned back as standby task.
> 6. Illegal Argument exception caught :
> {code:java}
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog) [2020-05-16
> 18:56:18,050] ERROR
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> Encountered the following exception during processing and the thread is going
> to shut down: (org.apache.kafka.streams.processor.internals.StreamThread)
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog)
> java.lang.IllegalArgumentException: stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> standby-task [1_2] Store KSTREAM-AGGREGATE-STATE-STORE-07 has already
> been registered.
> at
> org.apache.kafka.streams.processor.internals.ProcessorStateManager.registerStore(ProcessorStateManager.java:269)
> at
> org.apache.kafka.streams.processor.internals.AbstractProcessorContext.register(AbstractProcessorContext.java:112)
> at
> org.apache.kafka.streams.state.internals.AbstractRocksDBSegmentedBytesStore.init(AbstractRocksDBSegmentedBytesStore.java:191)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.RocksDBWindowStore.init(RocksDBWindowStore.java:48)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.init(ChangeLoggingWindowBytesStore.java:54)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.init(CachingWindowStore.java:74)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.lambda$init$0(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:804)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.init(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.StateManagerUtil.registerStateStores(StateManagerUtil.java:82)
> at
> org.apache.kafka.streams.processor.internals.StandbyTask.initializeIfNeeded(StandbyTask.java:89)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.tryToCompleteRestoration(TaskManager.java:358)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:664)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:550)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:509)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] guozhangwang commented on pull request #8669: MINOR: consolidate processor context for active/standby
guozhangwang commented on pull request #8669: URL: https://github.com/apache/kafka/pull/8669#issuecomment-630370157 test this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma closed pull request #8688: MINOR: Introduce separate methods in KafkaApis for consumer and follower fetch handling
ijuma closed pull request #8688: URL: https://github.com/apache/kafka/pull/8688 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #8688: MINOR: Introduce separate methods in KafkaApis for consumer and follower fetch handling
ijuma commented on pull request #8688: URL: https://github.com/apache/kafka/pull/8688#issuecomment-630376046 Closing this for now as there may be a better way to achieve this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] apovzner commented on pull request #8650: MINOR: Added unit tests for ConnectionQuotas
apovzner commented on pull request #8650: URL: https://github.com/apache/kafka/pull/8650#issuecomment-630379942 It looks like the build couldn't even run tests: ``` 15:15:09 ERROR: Error cloning remote repo 'origin' ... 15:15:18 stderr: fatal: Unable to look up github.com (port 9418) (Name or service not known) ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on pull request #8675: KAFKA-10004: Fix the default broker configs cannot be displayed when using kafka-configs.sh --describe
cmccabe commented on pull request #8675: URL: https://github.com/apache/kafka/pull/8675#issuecomment-630389772 ok to test This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #8684: KAFKA-10012 Reducing memory overhead associated with strings in Metri…
ijuma commented on pull request #8684: URL: https://github.com/apache/kafka/pull/8684#issuecomment-630391729 Thanks for the PR. Java's built in string interning mechanism is known to have issues. Not sure we want to do that. Maybe we can remove that part of the change from this PR? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #8685: KAFKA-10014 Always try to close all channels in Selector#close
ijuma commented on a change in pull request #8685:
URL: https://github.com/apache/kafka/pull/8685#discussion_r426850232
##
File path: clients/src/main/java/org/apache/kafka/common/network/Selector.java
##
@@ -363,23 +363,14 @@ public void wakeup() {
@Override
public void close() {
List connections = new ArrayList<>(channels.keySet());
-try {
-for (String id : connections)
-close(id);
-} finally {
-// If there is any exception thrown in close(id), we should still
be able
-// to close the remaining objects, especially the sensors because
keeping
-// the sensors may lead to failure to start up the
ReplicaFetcherThread if
-// the old sensors with the same names has not yet been cleaned up.
-AtomicReference firstException = new
AtomicReference<>();
-Utils.closeQuietly(nioSelector, "nioSelector", firstException);
-Utils.closeQuietly(sensors, "sensors", firstException);
-Utils.closeQuietly(channelBuilder, "channelBuilder",
firstException);
-Throwable exception = firstException.get();
-if (exception instanceof RuntimeException && !(exception
instanceof SecurityException)) {
-throw (RuntimeException) exception;
-}
-
+AtomicReference firstException = new AtomicReference<>();
Review comment:
Have we considered using `Utils.closeAll`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #8685: KAFKA-10014 Always try to close all channels in Selector#close
ijuma commented on a change in pull request #8685:
URL: https://github.com/apache/kafka/pull/8685#discussion_r426850232
##
File path: clients/src/main/java/org/apache/kafka/common/network/Selector.java
##
@@ -363,23 +363,14 @@ public void wakeup() {
@Override
public void close() {
List connections = new ArrayList<>(channels.keySet());
-try {
-for (String id : connections)
-close(id);
-} finally {
-// If there is any exception thrown in close(id), we should still
be able
-// to close the remaining objects, especially the sensors because
keeping
-// the sensors may lead to failure to start up the
ReplicaFetcherThread if
-// the old sensors with the same names has not yet been cleaned up.
-AtomicReference firstException = new
AtomicReference<>();
-Utils.closeQuietly(nioSelector, "nioSelector", firstException);
-Utils.closeQuietly(sensors, "sensors", firstException);
-Utils.closeQuietly(channelBuilder, "channelBuilder",
firstException);
-Throwable exception = firstException.get();
-if (exception instanceof RuntimeException && !(exception
instanceof SecurityException)) {
-throw (RuntimeException) exception;
-}
-
+AtomicReference firstException = new AtomicReference<>();
Review comment:
Have we considered using `Utils.closeAll` instead of multiple
`closeQuietly`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] mjsax merged pull request #8687: MINOR: updated MacOS compatibility statement for RocksDB
mjsax merged pull request #8687: URL: https://github.com/apache/kafka/pull/8687 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-10016) Support For Purge Topic
David Mollitor created KAFKA-10016:
--
Summary: Support For Purge Topic
Key: KAFKA-10016
URL: https://issues.apache.org/jira/browse/KAFKA-10016
Project: Kafka
Issue Type: Improvement
Reporter: David Mollitor
Some discussions about how to purge a topic. Please add native support for
this operation. Is there a "starting offset" for each topic? Such a vehicle
would allow for this value to be easily set with the current offeset and the
brokers will skip (and clean) everything before that.
[https://stackoverflow.com/questions/16284399/purge-kafka-topic]
{code:none}
kafka-topics --topic mytopic --purge
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] hachikuji commented on a change in pull request #8238: KAFKA-9130: KIP-518 Allow listing consumer groups per state
hachikuji commented on a change in pull request #8238:
URL: https://github.com/apache/kafka/pull/8238#discussion_r426867775
##
File path: clients/src/main/resources/common/message/ListGroupsRequest.json
##
@@ -20,8 +20,14 @@
// Version 1 and 2 are the same as version 0.
//
// Version 3 is the first flexible version.
- "validVersions": "0-3",
+ //
+ // Version 4 adds the States flexible field (KIP-518).
+ "validVersions": "0-4",
"flexibleVersions": "3+",
"fields": [
+{ "name": "States", "type": "[]string", "versions": "4+", "tag": 0,
"taggedVersions": "4+",
Review comment:
Sorry I missed this from the discussion, but why are we bumping the
version if we are only adding tagged fields? Is it so that we can detect
whether the capability is supported? If so, then I wonder why we don't make
this a regular field.
##
File path:
clients/src/main/java/org/apache/kafka/clients/admin/ListConsumerGroupsOptions.java
##
@@ -26,4 +31,34 @@
*/
@InterfaceStability.Evolving
public class ListConsumerGroupsOptions extends
AbstractOptions {
+
+private Optional> states = Optional.empty();
+
+/**
+ * Only groups in these states will be returned by listConsumerGroups()
Review comment:
Probably worth adding a comment about broker compatibility with this API.
##
File path:
clients/src/main/java/org/apache/kafka/clients/admin/ListConsumerGroupsOptions.java
##
@@ -26,4 +31,34 @@
*/
@InterfaceStability.Evolving
public class ListConsumerGroupsOptions extends
AbstractOptions {
+
+private Optional> states = Optional.empty();
+
+/**
+ * Only groups in these states will be returned by listConsumerGroups()
+ * If not set, all groups are returned without their states
+ * throw IllegalArgumentException if states is empty
+ */
+public ListConsumerGroupsOptions inStates(Set states) {
+if (states == null || states.isEmpty()) {
+throw new IllegalArgumentException("states should not be null or
empty");
+}
+this.states = Optional.of(states);
+return this;
+}
+
+/**
+ * All groups with their states will be returned by listConsumerGroups()
+ */
+public ListConsumerGroupsOptions inAnyState() {
+this.states = Optional.of(EnumSet.allOf(ConsumerGroupState.class));
Review comment:
Hmm.. We have an `UNKNOWN` state in `ConsumerGroupState` in case the
group coordinator adds a new state that the client isn't aware of. Currently
we're going to pass this through the request, which is a bit odd. Furthermore,
if the coordinator _does_ add new states, we will be unable to see them using
this API. I think it might be better to use a `null` list of states in the
request to indicate that any state is needed.
##
File path: core/src/main/scala/kafka/server/KafkaApis.scala
##
@@ -1397,29 +1398,32 @@ class KafkaApis(val requestChannel: RequestChannel,
}
def handleListGroupsRequest(request: RequestChannel.Request): Unit = {
-val (error, groups) = groupCoordinator.handleListGroups()
+val listGroupsRequest = request.body[ListGroupsRequest]
+val states = listGroupsRequest.data.states.asScala.toList
+
+def createResponse(throttleMs: Int, groups: List[GroupOverview], error:
Errors): AbstractResponse = {
+ new ListGroupsResponse(new ListGroupsResponseData()
+.setErrorCode(error.code)
+.setGroups(groups.map { group =>
+val listedGroup = new ListGroupsResponseData.ListedGroup()
+ .setGroupId(group.groupId)
+ .setProtocolType(group.protocolType)
+if (!states.isEmpty)
Review comment:
Why don't we always return the state? I don't think overhead is a huge
concern for an api like this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] abbccdda commented on a change in pull request #8680: KAFKA-9755: Implement read path for feature versioning system (KIP-584)
abbccdda commented on a change in pull request #8680:
URL: https://github.com/apache/kafka/pull/8680#discussion_r426806321
##
File path: clients/src/main/java/org/apache/kafka/common/feature/Features.java
##
@@ -0,0 +1,143 @@
+package org.apache.kafka.common.feature;
+
+import java.util.HashMap;
+import java.util.Map;
+import java.util.stream.Collectors;
+import java.util.Objects;
+
+import static java.util.stream.Collectors.joining;
+
+/**
+ * Represents an immutable dictionary with key being feature name, and value
being VersionRangeType.
+ * Also provides API to serialize/deserialize the features and their version
ranges to/from a map.
+ *
+ * This class can be instantiated only using its factory functions, with the
important ones being:
+ * Features.supportedFeatures(...) and Features.finalizedFeatures(...).
+ *
+ * @param is the type of version range.
+ */
+public class Features {
+private final Map features;
+
+/**
+ * Constructor is made private, as for readability it is preferred the
caller uses one of the
+ * static factory functions for instantiation (see below).
+ *
+ * @param features Map of feature name to type of VersionRange, as the
backing data structure
+ * for the Features object.
+ */
+private Features(Map features) {
+this.features = features;
+}
+
+/**
+ * @param features Map of feature name to VersionRange, as the backing
data structure
+ * for the Features object.
+ * @return Returns a new Features object representing
"supported" features.
+ */
+public static Features supportedFeatures(Map features) {
+return new Features(features);
+}
+
+/**
+ * @param features Map of feature name to VersionLevelRange, as the
backing data structure
+ * for the Features object.
+ * @return Returns a new Features object representing
"finalized" features.
+ */
+public static Features finalizedFeatures(Map features) {
+return new Features(features);
+}
+
+public static Features emptyFinalizedFeatures() {
Review comment:
Is this function only used in unit test?
##
File path: clients/src/main/java/org/apache/kafka/common/feature/Features.java
##
@@ -0,0 +1,143 @@
+package org.apache.kafka.common.feature;
+
+import java.util.HashMap;
+import java.util.Map;
+import java.util.stream.Collectors;
+import java.util.Objects;
+
+import static java.util.stream.Collectors.joining;
+
+/**
+ * Represents an immutable dictionary with key being feature name, and value
being VersionRangeType.
+ * Also provides API to serialize/deserialize the features and their version
ranges to/from a map.
+ *
+ * This class can be instantiated only using its factory functions, with the
important ones being:
+ * Features.supportedFeatures(...) and Features.finalizedFeatures(...).
+ *
+ * @param is the type of version range.
+ */
+public class Features {
+private final Map features;
+
+/**
+ * Constructor is made private, as for readability it is preferred the
caller uses one of the
+ * static factory functions for instantiation (see below).
+ *
+ * @param features Map of feature name to type of VersionRange, as the
backing data structure
+ * for the Features object.
+ */
+private Features(Map features) {
+this.features = features;
+}
+
+/**
+ * @param features Map of feature name to VersionRange, as the backing
data structure
+ * for the Features object.
+ * @return Returns a new Features object representing
"supported" features.
+ */
+public static Features supportedFeatures(Map features) {
+return new Features(features);
Review comment:
Could be simplified as new Features<>
##
File path: clients/src/main/java/org/apache/kafka/common/feature/Features.java
##
@@ -0,0 +1,143 @@
+package org.apache.kafka.common.feature;
+
+import java.util.HashMap;
+import java.util.Map;
+import java.util.stream.Collectors;
+import java.util.Objects;
+
+import static java.util.stream.Collectors.joining;
+
+/**
+ * Represents an immutable dictionary with key being feature name, and value
being VersionRangeType.
Review comment:
nit: we could use {@link VersionRangeType} to reference to the classes.
##
File path: clients/src/main/java/org/apache/kafka/common/feature/Features.java
##
@@ -0,0 +1,143 @@
+package org.apache.kafka.common.feature;
+
+import java.util.HashMap;
+import java.util.Map;
+import java.util.stream.Collectors;
+import java.util.Objects;
+
+import static java.util.stream.Collectors.joining;
+
+/**
+ * Represents an immutable dictionary with key being feature name, and value
being VersionRangeType.
+ * Also provides API to serialize/deserialize the features and their version
ranges to/from a map.
+
[jira] [Commented] (KAFKA-4327) Move Reset Tool from core to streams
[
https://issues.apache.org/jira/browse/KAFKA-4327?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110609#comment-17110609
]
Jorge Esteban Quilcate Otoya commented on KAFKA-4327:
-
[~mjsax] [~guozhang] I'd like to help closing this one as things have changed
since it got created:
* zookeeper dependency has been removed and
* zookeeper argument deprecated.
This tool carries a dependency to an argument parser that I'm not sure we would
like to pull into streams module.
I'd like to propose and agree in the following changes before moving forward:
* move StreamsResetter to `tools` module
* translate jopt parser (scala) into argparser (java)
* remove zookeeper parameter
If we agree on this, I can draft a small KIP to get this done.
> Move Reset Tool from core to streams
>
>
> Key: KAFKA-4327
> URL: https://issues.apache.org/jira/browse/KAFKA-4327
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Reporter: Matthias J. Sax
>Assignee: Jorge Esteban Quilcate Otoya
>Priority: Blocker
> Labels: needs-kip
> Fix For: 3.0.0
>
>
> This is a follow up on https://issues.apache.org/jira/browse/KAFKA-4008
> Currently, Kafka Streams Application Reset Tool is part of {{core}} module
> due to ZK dependency. After KIP-4 got merged, this dependency can be dropped
> and the Reset Tool can be moved to {{streams}} module.
> This should also update {{InternalTopicManager#filterExistingTopics}} that
> revers to ResetTool in an exception message:
> {{"Use 'kafka.tools.StreamsResetter' tool"}}
> -> {{"Use '" + kafka.tools.StreamsResetter.getClass().getName() + "' tool"}}
> Doing this JIRA also requires to update the docs with regard to broker
> backward compatibility -- not all broker support "topic delete request" and
> thus, the reset tool will not be backward compatible to all broker versions.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-10017) Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta[true]
Sophie Blee-Goldman created KAFKA-10017: --- Summary: Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta[true] Key: KAFKA-10017 URL: https://issues.apache.org/jira/browse/KAFKA-10017 Project: Kafka Issue Type: Bug Components: streams Reporter: Sophie Blee-Goldman Creating a new ticket for this since the root cause is different than https://issues.apache.org/jira/browse/KAFKA-9966 h3. Stacktrace java.lang.AssertionError: Did not receive all 20 records from topic multiPartitionOutputTopic within 6 ms Expected: is a value equal to or greater than <20> but: <15> was less than <20> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] cmccabe merged pull request #8569: KIP-551: Expose disk read and write metrics
cmccabe merged pull request #8569: URL: https://github.com/apache/kafka/pull/8569 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (KAFKA-9292) KIP-551: Expose disk read and write metrics
[ https://issues.apache.org/jira/browse/KAFKA-9292?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Colin McCabe resolved KAFKA-9292. - Fix Version/s: 2.6.0 Resolution: Fixed > KIP-551: Expose disk read and write metrics > --- > > Key: KAFKA-9292 > URL: https://issues.apache.org/jira/browse/KAFKA-9292 > Project: Kafka > Issue Type: Improvement >Reporter: Colin McCabe >Assignee: Colin McCabe >Priority: Major > Fix For: 2.6.0 > > > It's often helpful to know how many bytes Kafka is reading and writing from > the disk. The reason is because when disk access is required, there may be > some impact on latency and bandwidth. We currently don't have a metric that > measures this directly. It would be useful to add one. > See > https://cwiki.apache.org/confluence/display/KAFKA/KIP-551%3A+Expose+disk+read+and+write+metrics -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] navina commented on pull request #8684: KAFKA-10012 Reducing memory overhead associated with strings in Metri…
navina commented on pull request #8684: URL: https://github.com/apache/kafka/pull/8684#issuecomment-630444877 @ijuma What issues with intern are you referring to? I know that there can be a performance hit when there are a lot of intern strings. I believe string interning mechanism has been improved in the later versions of java such as jdk8 / 9. I would like to understand the concern better before removing the string interning showed here. Thanks for the quick feedback! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10017) Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta[true]
[ https://issues.apache.org/jira/browse/KAFKA-10017?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110633#comment-17110633 ] Sophie Blee-Goldman commented on KAFKA-10017: - h3. Stacktrace java.lang.AssertionError: Did not receive all 10 records from topic multiPartitionOutputTopic within 6 ms Expected: is a value equal to or greater than <10> but: <5> was less than <10> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) > Flaky Test > EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta[true] > - > > Key: KAFKA-10017 > URL: https://issues.apache.org/jira/browse/KAFKA-10017 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: Sophie Blee-Goldman >Priority: Major > Labels: flaky-test, unit-test > > Creating a new ticket for this since the root cause is different than > https://issues.apache.org/jira/browse/KAFKA-9966 > h3. Stacktrace > java.lang.AssertionError: Did not receive all 20 records from topic > multiPartitionOutputTopic within 6 ms Expected: is a value equal to or > greater than <20> but: <15> was less than <20> at > org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] navina edited a comment on pull request #8684: KAFKA-10012 Reducing memory overhead associated with strings in Metri…
navina edited a comment on pull request #8684: URL: https://github.com/apache/kafka/pull/8684#issuecomment-630444877 @ijuma What issues with `intern()` are you referring to? I know that there can be a performance hit when there are a lot of intern strings. I believe string interning mechanism has been improved in the later versions of java such as jdk8 / 9. I would like to understand the concern better before removing the string interning showed here. Thanks for the quick feedback! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10010) Should close standby task for safety during HandleLostAll
[
https://issues.apache.org/jira/browse/KAFKA-10010?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110636#comment-17110636
]
Boyang Chen commented on KAFKA-10010:
-
Had offline discussion with the team, so far some action items:
# Make the state store registration idempotent to unblock the trunk soak
# Add a logic to avoid aborting the txn when the task is in initialization
phase (Get a separate ticket)
> Should close standby task for safety during HandleLostAll
> -
>
> Key: KAFKA-10010
> URL: https://issues.apache.org/jira/browse/KAFKA-10010
> Project: Kafka
> Issue Type: Bug
>Reporter: Boyang Chen
>Assignee: Boyang Chen
>Priority: Major
>
> The current lost all logic doesn't close standby task, which could
> potentially lead to a tricky condition like below:
> 1. The standby task was initializing as `CREATED` state, and task corrupted
> exception was thrown from registerStateStores
> 2. The task corrupted exception was caught, and do a non-affected task commit
> 3. The task commit failed due to task migrated exception
> 4. The handleLostAll didn't close the standby task, leaving it as CREATED
> state
> 5. Next rebalance complete, the same task was assigned back as standby task.
> 6. Illegal Argument exception caught :
> {code:java}
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog) [2020-05-16
> 18:56:18,050] ERROR
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> Encountered the following exception during processing and the thread is going
> to shut down: (org.apache.kafka.streams.processor.internals.StreamThread)
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog)
> java.lang.IllegalArgumentException: stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> standby-task [1_2] Store KSTREAM-AGGREGATE-STATE-STORE-07 has already
> been registered.
> at
> org.apache.kafka.streams.processor.internals.ProcessorStateManager.registerStore(ProcessorStateManager.java:269)
> at
> org.apache.kafka.streams.processor.internals.AbstractProcessorContext.register(AbstractProcessorContext.java:112)
> at
> org.apache.kafka.streams.state.internals.AbstractRocksDBSegmentedBytesStore.init(AbstractRocksDBSegmentedBytesStore.java:191)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.RocksDBWindowStore.init(RocksDBWindowStore.java:48)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.init(ChangeLoggingWindowBytesStore.java:54)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.init(CachingWindowStore.java:74)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.lambda$init$0(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:804)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.init(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.StateManagerUtil.registerStateStores(StateManagerUtil.java:82)
> at
> org.apache.kafka.streams.processor.internals.StandbyTask.initializeIfNeeded(StandbyTask.java:89)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.tryToCompleteRestoration(TaskManager.java:358)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:664)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:550)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:509)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-10017) Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta
[ https://issues.apache.org/jira/browse/KAFKA-10017?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sophie Blee-Goldman updated KAFKA-10017: Summary: Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta (was: Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta[true]) > Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta > --- > > Key: KAFKA-10017 > URL: https://issues.apache.org/jira/browse/KAFKA-10017 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: Sophie Blee-Goldman >Priority: Major > Labels: flaky-test, unit-test > > Creating a new ticket for this since the root cause is different than > https://issues.apache.org/jira/browse/KAFKA-9966 > h3. Stacktrace > java.lang.AssertionError: Did not receive all 20 records from topic > multiPartitionOutputTopic within 6 ms Expected: is a value equal to or > greater than <20> but: <15> was less than <20> at > org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-10017) Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta
[ https://issues.apache.org/jira/browse/KAFKA-10017?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110633#comment-17110633 ] Sophie Blee-Goldman edited comment on KAFKA-10017 at 5/18/20, 9:36 PM: --- With injectError = false: h3. Stacktrace java.lang.AssertionError: Did not receive all 10 records from topic multiPartitionOutputTopic within 6 ms Expected: is a value equal to or greater than <10> but: <5> was less than <10> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) was (Author: ableegoldman): h3. Stacktrace java.lang.AssertionError: Did not receive all 10 records from topic multiPartitionOutputTopic within 6 ms Expected: is a value equal to or greater than <10> but: <5> was less than <10> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) > Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta > --- > > Key: KAFKA-10017 > URL: https://issues.apache.org/jira/browse/KAFKA-10017 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: Sophie Blee-Goldman >Priority: Major > Labels: flaky-test, unit-test > > Creating a new ticket for this since the root cause is different than > https://issues.apache.org/jira/browse/KAFKA-9966 > With injectError = true: > h3. Stacktrace > java.lang.AssertionError: Did not receive all 20 records from topic > multiPartitionOutputTopic within 6 ms Expected: is a value equal to or > greater than <20> but: <15> was less than <20> at > org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-10017) Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta
[ https://issues.apache.org/jira/browse/KAFKA-10017?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sophie Blee-Goldman updated KAFKA-10017: Description: Creating a new ticket for this since the root cause is different than https://issues.apache.org/jira/browse/KAFKA-9966 With injectError = true: h3. Stacktrace java.lang.AssertionError: Did not receive all 20 records from topic multiPartitionOutputTopic within 6 ms Expected: is a value equal to or greater than <20> but: <15> was less than <20> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) was: Creating a new ticket for this since the root cause is different than https://issues.apache.org/jira/browse/KAFKA-9966 h3. Stacktrace java.lang.AssertionError: Did not receive all 20 records from topic multiPartitionOutputTopic within 6 ms Expected: is a value equal to or greater than <20> but: <15> was less than <20> at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) at org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) at org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) at org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) > Flaky Test EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta > --- > > Key: KAFKA-10017 > URL: https://issues.apache.org/jira/browse/KAFKA-10017 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: Sophie Blee-Goldman >Priority: Major > Labels: flaky-test, unit-test > > Creating a new ticket for this since the root cause is different than > https://issues.apache.org/jira/browse/KAFKA-9966 > With injectError = true: > h3. Stacktrace > java.lang.AssertionError: Did not receive all 20 records from topic > multiPartitionOutputTopic within 6 ms Expected: is a value equal to or > greater than <20> but: <15> was less than <20> at > org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20) at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.lambda$waitUntilMinKeyValueRecordsReceived$1(IntegrationTestUtils.java:563) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:429) > at > org.apache.kafka.test.TestUtils.retryOnExceptionWithTimeout(TestUtils.java:397) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:559) > at > org.apache.kafka.streams.integration.utils.IntegrationTestUtils.waitUntilMinKeyValueRecordsReceived(IntegrationTestUtils.java:530) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.readResult(EosBetaUpgradeIntegrationTest.java:973) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.verifyCommitted(EosBetaUpgradeIntegrationTest.java:961) > at > org.apache.kafka.streams.integration.EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta(EosBetaUpgradeIntegrationTest.java:427) -- This message was sent by Atlassian Jira (v8.3.4#803005
[GitHub] [kafka] ableegoldman commented on pull request #8669: MINOR: consolidate processor context for active/standby
ableegoldman commented on pull request #8669: URL: https://github.com/apache/kafka/pull/8669#issuecomment-630448469 Failed due to flaky `EosBetaUpgradeIntegrationTest.shouldUpgradeFromEosAlphaToEosBeta` and `ConnectorTopicsIntegrationTest.testGetActiveTopics` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10010) Should close standby task for safety during HandleLostAll
[
https://issues.apache.org/jira/browse/KAFKA-10010?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110638#comment-17110638
]
Boyang Chen commented on KAFKA-10010:
-
For more context, the
[reason|[https://github.com/apache/kafka/pull/8440/files#r407722022]] we have
to keep the txn commit before handle task corruption, since otherwise under EOS
beta the stream thread could actually abort other healthy tasks.
> Should close standby task for safety during HandleLostAll
> -
>
> Key: KAFKA-10010
> URL: https://issues.apache.org/jira/browse/KAFKA-10010
> Project: Kafka
> Issue Type: Bug
>Reporter: Boyang Chen
>Assignee: Boyang Chen
>Priority: Major
>
> The current lost all logic doesn't close standby task, which could
> potentially lead to a tricky condition like below:
> 1. The standby task was initializing as `CREATED` state, and task corrupted
> exception was thrown from registerStateStores
> 2. The task corrupted exception was caught, and do a non-affected task commit
> 3. The task commit failed due to task migrated exception
> 4. The handleLostAll didn't close the standby task, leaving it as CREATED
> state
> 5. Next rebalance complete, the same task was assigned back as standby task.
> 6. Illegal Argument exception caught :
> {code:java}
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog) [2020-05-16
> 18:56:18,050] ERROR
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> Encountered the following exception during processing and the thread is going
> to shut down: (org.apache.kafka.streams.processor.internals.StreamThread)
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog)
> java.lang.IllegalArgumentException: stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> standby-task [1_2] Store KSTREAM-AGGREGATE-STATE-STORE-07 has already
> been registered.
> at
> org.apache.kafka.streams.processor.internals.ProcessorStateManager.registerStore(ProcessorStateManager.java:269)
> at
> org.apache.kafka.streams.processor.internals.AbstractProcessorContext.register(AbstractProcessorContext.java:112)
> at
> org.apache.kafka.streams.state.internals.AbstractRocksDBSegmentedBytesStore.init(AbstractRocksDBSegmentedBytesStore.java:191)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.RocksDBWindowStore.init(RocksDBWindowStore.java:48)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.init(ChangeLoggingWindowBytesStore.java:54)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.init(CachingWindowStore.java:74)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.lambda$init$0(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:804)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.init(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.StateManagerUtil.registerStateStores(StateManagerUtil.java:82)
> at
> org.apache.kafka.streams.processor.internals.StandbyTask.initializeIfNeeded(StandbyTask.java:89)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.tryToCompleteRestoration(TaskManager.java:358)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:664)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:550)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:509)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] guozhangwang merged pull request #8669: MINOR: consolidate processor context for active/standby
guozhangwang merged pull request #8669: URL: https://github.com/apache/kafka/pull/8669 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-7271) Fix ignored test in streams_upgrade_test.py: test_upgrade_downgrade_brokers
[ https://issues.apache.org/jira/browse/KAFKA-7271?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17110643#comment-17110643 ] Bill Bejeck commented on KAFKA-7271: [~mjsax] I don't think I'll have time for this one, so I've unassigned myself. > Fix ignored test in streams_upgrade_test.py: test_upgrade_downgrade_brokers > --- > > Key: KAFKA-7271 > URL: https://issues.apache.org/jira/browse/KAFKA-7271 > Project: Kafka > Issue Type: Improvement > Components: streams, system tests >Reporter: John Roesler >Priority: Blocker > Fix For: 2.6.0 > > > Fix in the oldest branch that ignores the test and cherry-pick forward. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (KAFKA-7271) Fix ignored test in streams_upgrade_test.py: test_upgrade_downgrade_brokers
[ https://issues.apache.org/jira/browse/KAFKA-7271?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bill Bejeck reassigned KAFKA-7271: -- Assignee: (was: Bill Bejeck) > Fix ignored test in streams_upgrade_test.py: test_upgrade_downgrade_brokers > --- > > Key: KAFKA-7271 > URL: https://issues.apache.org/jira/browse/KAFKA-7271 > Project: Kafka > Issue Type: Improvement > Components: streams, system tests >Reporter: John Roesler >Priority: Blocker > Fix For: 2.6.0 > > > Fix in the oldest branch that ignores the test and cherry-pick forward. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] cadonna opened a new pull request #8689: KAFKA-6145: Add unit tests to verify fix of bug KAFKA-9173
cadonna opened a new pull request #8689: URL: https://github.com/apache/kafka/pull/8689 Unit tests - shouldAssignActiveStatefulTasksEvenlyOverClientsAndStreamThreadsWithMoreStreamThreadsThanTasks() - shouldAssignWarmUpTasksIfStatefulActiveTasksBalancedOverStreamThreadsButNotOverClients() - shouldEvenlyAssignActiveStatefulTasksIfClientsAreWarmedUpToBalanceTaskOverClients() verify that bug KAFKA-9173 is fixed with the new HighAvailabilityTaskAssignor. shouldAssignActiveStatefulTasksEvenlyOverClientsAndStreamThreadsWithMoreStreamThreadsThanTasks() ensures that tasks are evenly assigned over clients when all overprovisioned clients join simultaneously. shouldAssignWarmUpTasksIfStatefulActiveTasksBalancedOverStreamThreadsButNotOverClients() ensures that warm-up tasks are assigned to two new clients that join the group although the assignment is already balanced over stream threads. shouldEvenlyAssignActiveStatefulTasksIfClientsAreWarmedUpToBalanceTaskOverClients() ensures that stateful active tasks are balanced over previous and warmed-up client although it the previous assignment is balanced over stream threads. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on pull request #8689: KAFKA-6145: Add unit tests to verify fix of bug KAFKA-9173
cadonna commented on pull request #8689: URL: https://github.com/apache/kafka/pull/8689#issuecomment-630467234 Call for review: @vvcephei @ableegoldman This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on a change in pull request #8689: KAFKA-6145: Add unit tests to verify fix of bug KAFKA-9173
cadonna commented on a change in pull request #8689:
URL: https://github.com/apache/kafka/pull/8689#discussion_r426924669
##
File path:
streams/src/test/java/org/apache/kafka/streams/processor/internals/assignment/HighAvailabilityTaskAssignorTest.java
##
@@ -170,7 +171,7 @@ public void
shouldAssignActiveStatefulTasksEvenlyOverUnevenlyDistributedStreamTh
}
@Test
-public void
shouldAssignActiveStatefulTasksEvenlyOverClientsWithLessClientsThanTasks() {
+public void
shouldAssignActiveStatefulTasksEvenlyOverClientsWithMoreClientsThanTasks() {
Review comment:
This name seemed not correct.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (KAFKA-10010) Should make state store registration idempotent
[
https://issues.apache.org/jira/browse/KAFKA-10010?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Boyang Chen updated KAFKA-10010:
Summary: Should make state store registration idempotent (was: Should
close standby task for safety during HandleLostAll)
> Should make state store registration idempotent
> ---
>
> Key: KAFKA-10010
> URL: https://issues.apache.org/jira/browse/KAFKA-10010
> Project: Kafka
> Issue Type: Bug
>Reporter: Boyang Chen
>Assignee: Boyang Chen
>Priority: Major
>
> The current lost all logic doesn't close standby task, which could
> potentially lead to a tricky condition like below:
> 1. The standby task was initializing as `CREATED` state, and task corrupted
> exception was thrown from registerStateStores
> 2. The task corrupted exception was caught, and do a non-affected task commit
> 3. The task commit failed due to task migrated exception
> 4. The handleLostAll didn't close the standby task, leaving it as CREATED
> state
> 5. Next rebalance complete, the same task was assigned back as standby task.
> 6. Illegal Argument exception caught :
> {code:java}
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog) [2020-05-16
> 18:56:18,050] ERROR
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> Encountered the following exception during processing and the thread is going
> to shut down: (org.apache.kafka.streams.processor.internals.StreamThread)
> [2020-05-16T11:56:18-07:00]
> (streams-soak-trunk-eos-beta_soak_i-065b27929d3e7014a_streamslog)
> java.lang.IllegalArgumentException: stream-thread
> [stream-soak-test-ce5e4abb-24f5-48cd-9608-21c59b6b42a3-StreamThread-1]
> standby-task [1_2] Store KSTREAM-AGGREGATE-STATE-STORE-07 has already
> been registered.
> at
> org.apache.kafka.streams.processor.internals.ProcessorStateManager.registerStore(ProcessorStateManager.java:269)
> at
> org.apache.kafka.streams.processor.internals.AbstractProcessorContext.register(AbstractProcessorContext.java:112)
> at
> org.apache.kafka.streams.state.internals.AbstractRocksDBSegmentedBytesStore.init(AbstractRocksDBSegmentedBytesStore.java:191)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.RocksDBWindowStore.init(RocksDBWindowStore.java:48)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.ChangeLoggingWindowBytesStore.init(ChangeLoggingWindowBytesStore.java:54)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.CachingWindowStore.init(CachingWindowStore.java:74)
> at
> org.apache.kafka.streams.state.internals.WrappedStateStore.init(WrappedStateStore.java:48)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.lambda$init$0(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl.maybeMeasureLatency(StreamsMetricsImpl.java:804)
> at
> org.apache.kafka.streams.state.internals.MeteredWindowStore.init(MeteredWindowStore.java:85)
> at
> org.apache.kafka.streams.processor.internals.StateManagerUtil.registerStateStores(StateManagerUtil.java:82)
> at
> org.apache.kafka.streams.processor.internals.StandbyTask.initializeIfNeeded(StandbyTask.java:89)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.tryToCompleteRestoration(TaskManager.java:358)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runOnce(StreamThread.java:664)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.runLoop(StreamThread.java:550)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:509)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-9989) StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor gets assigned task
[ https://issues.apache.org/jira/browse/KAFKA-9989?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Boyang Chen updated KAFKA-9989: --- Description: System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: "Never saw output 'processed [0-9]* records' on ubuntu@worker6" which if we take a closer look at, the rebalance happens but has no task assignment. We should fix this problem by making the rebalance result as part of the check, and wait for the finalized assignment before kicking off the record processing validation. was: System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: "Never saw output 'processed [0-9]* records' on ubuntu@worker6" which if we take a closer look at, the rebalance happens but has no task assignment. We should fix this problem by making the rebalance result as part of the check, and skip the record processing validation when the assignment is empty. > StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor > gets assigned task > - > > Key: KAFKA-9989 > URL: https://issues.apache.org/jira/browse/KAFKA-9989 > Project: Kafka > Issue Type: Bug > Components: streams, system tests >Reporter: Boyang Chen >Assignee: Boyang Chen >Priority: Major > > System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: > "Never saw output 'processed [0-9]* records' on ubuntu@worker6" > which if we take a closer look at, the rebalance happens but has no task > assignment. We should fix this problem by making the rebalance result as part > of the check, and wait for the finalized assignment before kicking off the > record processing validation. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (KAFKA-9989) StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor gets assigned task
[ https://issues.apache.org/jira/browse/KAFKA-9989?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Boyang Chen reassigned KAFKA-9989: -- Assignee: (was: Boyang Chen) > StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor > gets assigned task > - > > Key: KAFKA-9989 > URL: https://issues.apache.org/jira/browse/KAFKA-9989 > Project: Kafka > Issue Type: Bug > Components: streams, system tests >Reporter: Boyang Chen >Priority: Major > > System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: > "Never saw output 'processed [0-9]* records' on ubuntu@worker6" > which if we take a closer look at, the rebalance happens but has no task > assignment. We should fix this problem by making the rebalance result as part > of the check, and wait for the finalized assignment before kicking off the > record processing validation. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-9989) StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor gets assigned task
[ https://issues.apache.org/jira/browse/KAFKA-9989?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Boyang Chen updated KAFKA-9989: --- Labels: newbie (was: ) > StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor > gets assigned task > - > > Key: KAFKA-9989 > URL: https://issues.apache.org/jira/browse/KAFKA-9989 > Project: Kafka > Issue Type: Bug > Components: streams, system tests >Reporter: Boyang Chen >Priority: Major > Labels: newbie > > System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: > "Never saw output 'processed [0-9]* records' on ubuntu@worker6" > which if we take a closer look at, the rebalance happens but has no task > assignment. We should fix this problem by making the rebalance result as part > of the check, and wait for the finalized assignment before kicking off the > record processing validation. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-9989) StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor gets assigned task
[ https://issues.apache.org/jira/browse/KAFKA-9989?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Boyang Chen updated KAFKA-9989: --- Description: System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: "Never saw output 'processed [0-9]* records' on ubuntu@worker6" which if we take a closer look at, the rebalance happens but has no task assignment. We should fix this problem by making the rebalance result as part of the check, and wait for the finalized assignment (non-empty) before kicking off the record processing validation. was: System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: "Never saw output 'processed [0-9]* records' on ubuntu@worker6" which if we take a closer look at, the rebalance happens but has no task assignment. We should fix this problem by making the rebalance result as part of the check, and wait for the finalized assignment before kicking off the record processing validation. > StreamsUpgradeTest.test_metadata_upgrade could not guarantee all processor > gets assigned task > - > > Key: KAFKA-9989 > URL: https://issues.apache.org/jira/browse/KAFKA-9989 > Project: Kafka > Issue Type: Bug > Components: streams, system tests >Reporter: Boyang Chen >Priority: Major > Labels: newbie > > System test StreamsUpgradeTest.test_metadata_upgrade could fail due to: > "Never saw output 'processed [0-9]* records' on ubuntu@worker6" > which if we take a closer look at, the rebalance happens but has no task > assignment. We should fix this problem by making the rebalance result as part > of the check, and wait for the finalized assignment (non-empty) before > kicking off the record processing validation. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] cmccabe opened a new pull request #8690: KAFKA-9965: Fix uneven distribution in RoundRobinPartitioner
cmccabe opened a new pull request #8690: URL: https://github.com/apache/kafka/pull/8690 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] xiaodongdu opened a new pull request #8691: KAFKA-9960: implement KIP-606 to add metadata context to MetricsReporter
xiaodongdu opened a new pull request #8691: URL: https://github.com/apache/kafka/pull/8691 Implement KIP-606, add metadata context to MetricsReporter: Added a new api to MetricsReporter to allow client to expose additional metadata fields to reporter plugin. Added an interface MetricsContext to encapsulate metadata. Deprecated JmexReporter(String prefix) constructor. The prefix will be passed to the reporter via MetricsContext. Replaced existing usage of JmxReporter with the default ImxReporter and pass JMX prefix to MetricsContext using _namespace as key. From Kafka broker, populate MetricsContext with: kafka.cluster.id and kafka.nroker.id From Connect, populate MetricsContext with: connect.kafka.cluster.id, connect.group.id Committer Checklist (excluded from commit message) Verify design and implementation Verify test coverage and CI build status Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org