Thesharing commented on a change in pull request #14868: URL: https://github.com/apache/flink/pull/14868#discussion_r584430325
########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManager.java ########## @@ -0,0 +1,89 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.HashMap; +import java.util.List; +import java.util.Map; + +import static org.apache.flink.util.Preconditions.checkState; + +/** Class that manages all the connections between tasks. */ +public class EdgeManager { + + private final Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> partitionConsumers = + new HashMap<>(); + + private final Map<ExecutionVertexID, List<ConsumedPartitionGroup>> vertexConsumedPartitions = + new HashMap<>(); + + public void addPartitionConsumers( + IntermediateResultPartitionID resultPartitionId, ConsumerVertexGroup consumerVertices) { + + checkState(!partitionConsumers.containsKey(resultPartitionId)); + + final List<ConsumerVertexGroup> consumers = getPartitionConsumers(resultPartitionId); + + // sanity check + checkState( + consumers.size() == 0, + "Currently there has to be exactly one consumer in real jobs"); + + consumers.add(consumerVertices); + } + + public void addVertexConsumedPartitions( + ExecutionVertexID executionVertexId, + ConsumedPartitionGroup partitions, + int inputNumber) { + + final List<ConsumedPartitionGroup> consumedPartitions = + getVertexConsumedPartitions(executionVertexId); + + // sanity check + checkState(consumedPartitions.size() == inputNumber); Review comment: Yes, this order is redundant, there is no limitation about order before. I prefer to remove `inputNumber` from the parameters, since currently in `EdgeManagerBuildUtils` ConsumedPartitionGroup is added one-by-one per JobEdge. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManager.java ########## @@ -0,0 +1,89 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.HashMap; +import java.util.List; +import java.util.Map; + +import static org.apache.flink.util.Preconditions.checkState; + +/** Class that manages all the connections between tasks. */ +public class EdgeManager { + + private final Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> partitionConsumers = + new HashMap<>(); + + private final Map<ExecutionVertexID, List<ConsumedPartitionGroup>> vertexConsumedPartitions = + new HashMap<>(); + + public void addPartitionConsumers( + IntermediateResultPartitionID resultPartitionId, ConsumerVertexGroup consumerVertices) { + + checkState(!partitionConsumers.containsKey(resultPartitionId)); + + final List<ConsumerVertexGroup> consumers = getPartitionConsumers(resultPartitionId); + + // sanity check + checkState( + consumers.size() == 0, + "Currently there has to be exactly one consumer in real jobs"); + + consumers.add(consumerVertices); + } + + public void addVertexConsumedPartitions( + ExecutionVertexID executionVertexId, + ConsumedPartitionGroup partitions, + int inputNumber) { + + final List<ConsumedPartitionGroup> consumedPartitions = + getVertexConsumedPartitions(executionVertexId); + + // sanity check + checkState(consumedPartitions.size() == inputNumber); + + consumedPartitions.add(partitions); + } + + public List<ConsumerVertexGroup> getPartitionConsumers( + IntermediateResultPartitionID resultPartitionId) { + return partitionConsumers.computeIfAbsent(resultPartitionId, id -> new ArrayList<>()); + } + + public List<ConsumedPartitionGroup> getVertexConsumedPartitions( + ExecutionVertexID executionVertexId) { + return vertexConsumedPartitions.computeIfAbsent(executionVertexId, id -> new ArrayList<>()); + } + + public Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> + getAllPartitionConsumers() { + return partitionConsumers; + } + + public Map<ExecutionVertexID, List<ConsumedPartitionGroup>> getAllVertexConsumedPartitions() { + return vertexConsumedPartitions; + } Review comment: Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManager.java ########## @@ -0,0 +1,89 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.HashMap; +import java.util.List; +import java.util.Map; + +import static org.apache.flink.util.Preconditions.checkState; + +/** Class that manages all the connections between tasks. */ +public class EdgeManager { + + private final Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> partitionConsumers = + new HashMap<>(); + + private final Map<ExecutionVertexID, List<ConsumedPartitionGroup>> vertexConsumedPartitions = + new HashMap<>(); + + public void addPartitionConsumers( + IntermediateResultPartitionID resultPartitionId, ConsumerVertexGroup consumerVertices) { + + checkState(!partitionConsumers.containsKey(resultPartitionId)); + + final List<ConsumerVertexGroup> consumers = getPartitionConsumers(resultPartitionId); + + // sanity check + checkState( + consumers.size() == 0, + "Currently there has to be exactly one consumer in real jobs"); + + consumers.add(consumerVertices); + } + + public void addVertexConsumedPartitions( + ExecutionVertexID executionVertexId, + ConsumedPartitionGroup partitions, + int inputNumber) { + + final List<ConsumedPartitionGroup> consumedPartitions = + getVertexConsumedPartitions(executionVertexId); + + // sanity check + checkState(consumedPartitions.size() == inputNumber); + + consumedPartitions.add(partitions); + } + + public List<ConsumerVertexGroup> getPartitionConsumers( + IntermediateResultPartitionID resultPartitionId) { + return partitionConsumers.computeIfAbsent(resultPartitionId, id -> new ArrayList<>()); + } + + public List<ConsumedPartitionGroup> getVertexConsumedPartitions( + ExecutionVertexID executionVertexId) { + return vertexConsumedPartitions.computeIfAbsent(executionVertexId, id -> new ArrayList<>()); + } + + public Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> + getAllPartitionConsumers() { + return partitionConsumers; + } Review comment: Currently this method is not used. I think we can remove this method. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionGraph.java ########## @@ -668,6 +678,29 @@ public int getTotalNumberOfVertices() { }; } + public EdgeManager getEdgeManager() { + return edgeManager; + } + + public void registerExecutionVertex(ExecutionVertexID id, ExecutionVertex vertex) { + executionVerticesById.put(id, vertex); + } + + public void registerResultPartition( + IntermediateResultPartitionID id, IntermediateResultPartition partition) { + + resultPartitionsById.put(id, partition); + } + + public ExecutionVertex getExecutionVertexOrThrow(ExecutionVertexID id) { + return checkNotNull(executionVerticesById.get(id)); + } + + public IntermediateResultPartition getResultPartitionOrThrow( + final IntermediateResultPartitionID id) { + return checkNotNull(resultPartitionsById.get(id)); + } Review comment: There are three methods can be package private, I've resolved these. `getResultPartitionOrThrow` is used in `DefaultExecutionTopologyTest`, which is outside the package. Thanks for pointing this out. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionVertex.java ########## @@ -503,16 +411,15 @@ public void connectSource( new HashSet<>(getTotalNumberOfParallelSubtasks()); // go over all inputs - for (int i = 0; i < inputEdges.length; i++) { + for (ConsumedPartitionGroup sources : allConsumedPartitions) { inputLocations.clear(); - ExecutionEdge[] sources = inputEdges[i]; if (sources != null) { // go over all input sources - for (int k = 0; k < sources.length; k++) { Review comment: Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManager.java ########## @@ -0,0 +1,89 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.HashMap; +import java.util.List; +import java.util.Map; + +import static org.apache.flink.util.Preconditions.checkState; + +/** Class that manages all the connections between tasks. */ +public class EdgeManager { Review comment: > Can this be package private? In the next pull request, we'll use `EdgeManager` to replace the connections between `DefaultExecutionVertex` and `DefaultResultPartition` in `DefaultExecutionTopology`. So I prefer not to set `EdgeManager` to package private. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManagerBuildUtil.java ########## @@ -0,0 +1,143 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.DistributionPattern; +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.Arrays; +import java.util.List; +import java.util.stream.Collectors; + +/** Utilities for building {@link EdgeManager}. */ +public class EdgeManagerBuildUtil { + + public static void connectVertexToResult( + ExecutionJobVertex vertex, + IntermediateResult ires, + int inputNumber, + DistributionPattern distributionPattern) { + + switch (distributionPattern) { + case POINTWISE: + connectPointwise(vertex.getTaskVertices(), ires, inputNumber); + break; + case ALL_TO_ALL: + connectAllToAll(vertex.getTaskVertices(), ires, inputNumber); + break; + default: + throw new RuntimeException("Unrecognized distribution pattern."); + } + } + + private static void connectAllToAll( + ExecutionVertex[] taskVertices, IntermediateResult ires, int inputNumber) { + + ConsumedPartitionGroup consumedPartitions = + new ConsumedPartitionGroup( + Arrays.stream(ires.getPartitions()) + .map(IntermediateResultPartition::getPartitionId) + .collect(Collectors.toList())); + for (ExecutionVertex ev : taskVertices) { + ev.addConsumedPartitions(consumedPartitions, inputNumber); + } + + ConsumerVertexGroup vertices = + new ConsumerVertexGroup( Review comment: Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManagerBuildUtil.java ########## @@ -0,0 +1,143 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.DistributionPattern; +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.Arrays; +import java.util.List; +import java.util.stream.Collectors; + +/** Utilities for building {@link EdgeManager}. */ +public class EdgeManagerBuildUtil { + + public static void connectVertexToResult( + ExecutionJobVertex vertex, + IntermediateResult ires, + int inputNumber, + DistributionPattern distributionPattern) { + + switch (distributionPattern) { + case POINTWISE: + connectPointwise(vertex.getTaskVertices(), ires, inputNumber); + break; + case ALL_TO_ALL: + connectAllToAll(vertex.getTaskVertices(), ires, inputNumber); + break; + default: + throw new RuntimeException("Unrecognized distribution pattern."); + } + } + + private static void connectAllToAll( + ExecutionVertex[] taskVertices, IntermediateResult ires, int inputNumber) { + + ConsumedPartitionGroup consumedPartitions = + new ConsumedPartitionGroup( + Arrays.stream(ires.getPartitions()) + .map(IntermediateResultPartition::getPartitionId) + .collect(Collectors.toList())); Review comment: Agreed and resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManager.java ########## @@ -0,0 +1,89 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.HashMap; +import java.util.List; +import java.util.Map; + +import static org.apache.flink.util.Preconditions.checkState; + +/** Class that manages all the connections between tasks. */ +public class EdgeManager { + + private final Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> partitionConsumers = + new HashMap<>(); + + private final Map<ExecutionVertexID, List<ConsumedPartitionGroup>> vertexConsumedPartitions = + new HashMap<>(); + + public void addPartitionConsumers( + IntermediateResultPartitionID resultPartitionId, ConsumerVertexGroup consumerVertices) { + + checkState(!partitionConsumers.containsKey(resultPartitionId)); + + final List<ConsumerVertexGroup> consumers = getPartitionConsumers(resultPartitionId); + + // sanity check + checkState( + consumers.size() == 0, + "Currently there has to be exactly one consumer in real jobs"); + + consumers.add(consumerVertices); + } + + public void addVertexConsumedPartitions( + ExecutionVertexID executionVertexId, + ConsumedPartitionGroup partitions, + int inputNumber) { + + final List<ConsumedPartitionGroup> consumedPartitions = + getVertexConsumedPartitions(executionVertexId); + + // sanity check + checkState(consumedPartitions.size() == inputNumber); + + consumedPartitions.add(partitions); + } + + public List<ConsumerVertexGroup> getPartitionConsumers( + IntermediateResultPartitionID resultPartitionId) { + return partitionConsumers.computeIfAbsent(resultPartitionId, id -> new ArrayList<>()); + } + + public List<ConsumedPartitionGroup> getVertexConsumedPartitions( + ExecutionVertexID executionVertexId) { + return vertexConsumedPartitions.computeIfAbsent(executionVertexId, id -> new ArrayList<>()); + } Review comment: Yes, I should be more careful about the encapsulation. Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManagerBuildUtil.java ########## @@ -0,0 +1,143 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.DistributionPattern; +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.Arrays; +import java.util.List; +import java.util.stream.Collectors; + +/** Utilities for building {@link EdgeManager}. */ +public class EdgeManagerBuildUtil { + + public static void connectVertexToResult( + ExecutionJobVertex vertex, + IntermediateResult ires, + int inputNumber, + DistributionPattern distributionPattern) { + + switch (distributionPattern) { + case POINTWISE: + connectPointwise(vertex.getTaskVertices(), ires, inputNumber); + break; + case ALL_TO_ALL: + connectAllToAll(vertex.getTaskVertices(), ires, inputNumber); + break; + default: + throw new RuntimeException("Unrecognized distribution pattern."); Review comment: Totally agreed. Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/deployment/TaskDeploymentDescriptorFactory.java ########## @@ -101,18 +102,18 @@ public TaskDeploymentDescriptor createDeploymentDescriptor( } private List<InputGateDeploymentDescriptor> createInputGateDeploymentDescriptors() { - List<InputGateDeploymentDescriptor> inputGates = new ArrayList<>(inputEdges.length); + List<InputGateDeploymentDescriptor> inputGates = new ArrayList<>(consumedPartitions.size()); - for (ExecutionEdge[] edges : inputEdges) { + for (List<IntermediateResultPartition> partitions : consumedPartitions) { // If the produced partition has multiple consumers registered, we // need to request the one matching our sub task index. // TODO Refactor after removing the consumers from the intermediate result partitions - int numConsumerEdges = edges[0].getSource().getConsumers().get(0).size(); + IntermediateResultPartition resultPartition = partitions.get(0); - int queueToRequest = subtaskIndex % numConsumerEdges; + int numConsumer = resultPartition.getConsumers().get(0).getVertices().size(); Review comment: Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManagerBuildUtil.java ########## @@ -0,0 +1,143 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.DistributionPattern; +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.Arrays; +import java.util.List; +import java.util.stream.Collectors; + +/** Utilities for building {@link EdgeManager}. */ +public class EdgeManagerBuildUtil { + + public static void connectVertexToResult( + ExecutionJobVertex vertex, + IntermediateResult ires, + int inputNumber, + DistributionPattern distributionPattern) { + + switch (distributionPattern) { + case POINTWISE: + connectPointwise(vertex.getTaskVertices(), ires, inputNumber); + break; + case ALL_TO_ALL: + connectAllToAll(vertex.getTaskVertices(), ires, inputNumber); + break; + default: + throw new RuntimeException("Unrecognized distribution pattern."); + } + } + + private static void connectAllToAll( + ExecutionVertex[] taskVertices, IntermediateResult ires, int inputNumber) { + + ConsumedPartitionGroup consumedPartitions = + new ConsumedPartitionGroup( + Arrays.stream(ires.getPartitions()) + .map(IntermediateResultPartition::getPartitionId) + .collect(Collectors.toList())); + for (ExecutionVertex ev : taskVertices) { + ev.addConsumedPartitions(consumedPartitions, inputNumber); + } + + ConsumerVertexGroup vertices = + new ConsumerVertexGroup( + Arrays.stream(taskVertices) + .map(ExecutionVertex::getID) + .collect(Collectors.toList())); + for (IntermediateResultPartition partition : ires.getPartitions()) { + partition.addConsumers(vertices); + } + } + + private static void connectPointwise( + ExecutionVertex[] taskVertices, IntermediateResult ires, int inputNumber) { + + final int sourceCount = ires.getPartitions().length; + final int targetCount = taskVertices.length; + + if (sourceCount == targetCount) { + for (int i = 0; i < sourceCount; i++) { + ExecutionVertex executionVertex = taskVertices[i]; + IntermediateResultPartition partition = ires.getPartitions()[i]; + + ConsumerVertexGroup consumerVertexGroup = + new ConsumerVertexGroup(executionVertex.getID()); + partition.addConsumers(consumerVertexGroup); + + ConsumedPartitionGroup consumedPartitionGroup = + new ConsumedPartitionGroup(partition.getPartitionId()); + executionVertex.addConsumedPartitions(consumedPartitionGroup, inputNumber); + } + } else if (sourceCount > targetCount) { + for (int index = 0; index < targetCount; index++) { + + ExecutionVertex executionVertex = taskVertices[index]; + ConsumerVertexGroup consumerVertexGroup = + new ConsumerVertexGroup(executionVertex.getID()); + + int start = index * sourceCount / targetCount; + int end = (index + 1) * sourceCount / targetCount; + + List<IntermediateResultPartitionID> consumedPartitions = + new ArrayList<>(end - start); + + for (int i = start; i < end; i++) { + IntermediateResultPartition partition = ires.getPartitions()[i]; + partition.addConsumers(consumerVertexGroup); + + consumedPartitions.add(partition.getPartitionId()); + } + + ConsumedPartitionGroup consumedPartitionGroup = + new ConsumedPartitionGroup(consumedPartitions); + executionVertex.addConsumedPartitions(consumedPartitionGroup, inputNumber); + } + } else { + for (int partitionNum = 0; partitionNum < sourceCount; partitionNum++) { + + IntermediateResultPartition partition = ires.getPartitions()[partitionNum]; + ConsumedPartitionGroup consumerPartitionGroup = + new ConsumedPartitionGroup(partition.getPartitionId()); + + float factor = ((float) targetCount) / sourceCount; + int start = (int) (Math.ceil(partitionNum * factor)); + int end = (int) (Math.ceil((partitionNum + 1) * factor)); Review comment: In the original logic of connecting upstream vertices and downstream partitions, which is located at `ExecutionVertex#connectPointwise`, there are three situations: a) upstream parallelism > downstream parallelism; b) upstream parallelism < downstream parallelism; c) upstream parallelism = downstream parallelism. For situation a) and b), their connection patterns are mirrored, as illustrated in the figure below: 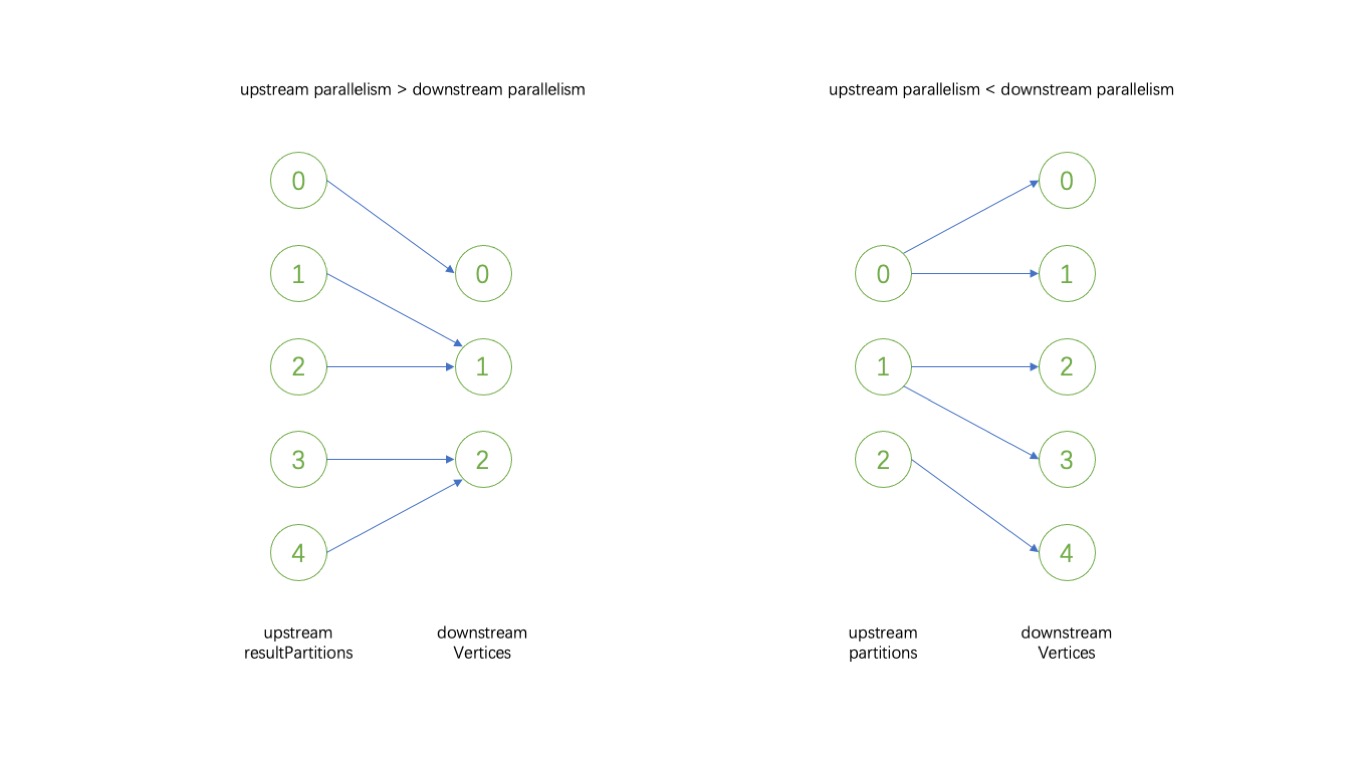 So there are two different logics to calculate the connections between upstream and downstream. For situation a), we use `Math.floor` (Truncate behaves the same as `Math.floor` when it's applied to positive number). For situation b), we use `Math.ceil`. Furthermore, we add a unit test `PointwiseTest#testPointwiseConnectionSequence` to make sure the descendant logic follows the original logic. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManagerBuildUtil.java ########## @@ -0,0 +1,143 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.DistributionPattern; +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.Arrays; +import java.util.List; +import java.util.stream.Collectors; + +/** Utilities for building {@link EdgeManager}. */ +public class EdgeManagerBuildUtil { + + public static void connectVertexToResult( Review comment: Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionGraph.java ########## @@ -668,6 +678,29 @@ public int getTotalNumberOfVertices() { }; } + public EdgeManager getEdgeManager() { Review comment: This method `getEdgeManager` will be used to build `DefaultExecutionTopology`, thus it can not be package private. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/strategy/ConsumerVertexGroup.java ########## @@ -0,0 +1,39 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.scheduler.strategy; + +import java.util.Collections; +import java.util.List; + +/** Group of consumer {@link ExecutionVertexID}s. */ +public class ConsumerVertexGroup { + private final List<ExecutionVertexID> vertices; + + public ConsumerVertexGroup(List<ExecutionVertexID> vertices) { Review comment: Same above. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/strategy/ConsumedPartitionGroup.java ########## @@ -0,0 +1,41 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.scheduler.strategy; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; + +import java.util.Collections; +import java.util.List; + +/** Group of consumed {@link IntermediateResultPartitionID}s. */ +public class ConsumedPartitionGroup { + private final List<IntermediateResultPartitionID> resultPartitions; + + public ConsumedPartitionGroup(List<IntermediateResultPartitionID> resultPartitions) { Review comment: Some methods would iterate the consumed result partitions in order, so I think it would better if we insist to init the ConsumedPartitionGroup with List<IntermediateResultPartitionID>. This will make sure no one initializes the group with `Map.values()` and other unordered collections. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionVertex.java ########## @@ -133,7 +130,7 @@ public ExecutionVertex( resultPartitions.put(irp.getPartitionId(), irp); } - this.inputEdges = new ExecutionEdge[jobVertex.getJobVertex().getInputs().size()][]; + getExecutionGraph().registerExecutionVertex(executionVertexId, this); Review comment: I'm not quite sure about this. First, we need to register the `ExecutionVertex` to the map inside `ExecutionGraph` so that `EdgeManager` works. Second, `getExecutionGraph()` and `registerExecutionVertex` are both not overridden by any subclass now. Third, there's a similar call `getExecutionGraph().registerExecution(currentExecution);` below this call. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionJobVertex.java ########## @@ -454,12 +455,7 @@ public void connectToPredecessors( this.inputs.add(ires); - int consumerIndex = ires.registerConsumer(); - - for (int i = 0; i < parallelism; i++) { - ExecutionVertex ev = taskVertices[i]; - ev.connectSource(num, ires, edge, consumerIndex); - } + connectVertexToResult(this, ires, num, edge.getDistributionPattern()); Review comment: Totally agreed. This would make it clearer. Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManagerBuildUtil.java ########## @@ -0,0 +1,143 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.DistributionPattern; +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.Arrays; +import java.util.List; +import java.util.stream.Collectors; + +/** Utilities for building {@link EdgeManager}. */ +public class EdgeManagerBuildUtil { + + public static void connectVertexToResult( Review comment: Like `EdgeManager`, we think since we didn't change the original logic, it's covered by The all-to-all edges are tested by `ExecutionGraphConstructionTest`. The pointwise edges are tested by `PointwisePatternTest`. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionVertex.java ########## @@ -321,107 +323,11 @@ public ExecutionGraph getExecutionGraph() { // Graph building // -------------------------------------------------------------------------------------------- - public void connectSource( - int inputNumber, IntermediateResult source, JobEdge edge, int consumerNumber) { - - final DistributionPattern pattern = edge.getDistributionPattern(); - final IntermediateResultPartition[] sourcePartitions = source.getPartitions(); - - ExecutionEdge[] edges; - - switch (pattern) { - case POINTWISE: - edges = connectPointwise(sourcePartitions, inputNumber); - break; - - case ALL_TO_ALL: - edges = connectAllToAll(sourcePartitions, inputNumber); - break; - - default: - throw new RuntimeException("Unrecognized distribution pattern."); - } - - inputEdges[inputNumber] = edges; - - // add the consumers to the source - // for now (until the receiver initiated handshake is in place), we need to register the - // edges as the execution graph - for (ExecutionEdge ee : edges) { - ee.getSource().addConsumer(ee, consumerNumber); - } - } - - private ExecutionEdge[] connectAllToAll( - IntermediateResultPartition[] sourcePartitions, int inputNumber) { - ExecutionEdge[] edges = new ExecutionEdge[sourcePartitions.length]; - - for (int i = 0; i < sourcePartitions.length; i++) { - IntermediateResultPartition irp = sourcePartitions[i]; - edges[i] = new ExecutionEdge(irp, this, inputNumber); - } - - return edges; - } - - private ExecutionEdge[] connectPointwise( - IntermediateResultPartition[] sourcePartitions, int inputNumber) { - final int numSources = sourcePartitions.length; - final int parallelism = getTotalNumberOfParallelSubtasks(); - - // simple case same number of sources as targets - if (numSources == parallelism) { - return new ExecutionEdge[] { - new ExecutionEdge(sourcePartitions[subTaskIndex], this, inputNumber) - }; - } else if (numSources < parallelism) { - - int sourcePartition; - - // check if the pattern is regular or irregular - // we use int arithmetics for regular, and floating point with rounding for irregular - if (parallelism % numSources == 0) { - // same number of targets per source - int factor = parallelism / numSources; - sourcePartition = subTaskIndex / factor; - } else { - // different number of targets per source - float factor = ((float) parallelism) / numSources; - sourcePartition = (int) (subTaskIndex / factor); - } Review comment: The old `ExecutionVertex#connectPointwise` is called by `ExecutionJobVertex#connectToPredecessors`. `connectToPredecessors`iterates over all ExecutionVertices and connects them to upstream result partitions. For the situation upstream parallelism < downstream parallelism, since we need to group the vertices connected to the same result partition, the most convenient way is to iterate over each result partition and add all vertices connected to one group. Thus, the calculation is different. Originally, `Math.floor` is used in `sourcePartition = (int) (subTaskIndex / factor);`. Correspondingly, `Math.ceil` is used in `int start = (int) (Math.ceil(partitionNum * factor));`. We add the unit test `PointwiseTest#testPointwiseConnectionSequence` to make sure the connections are the same as they used to be. The modified logic is: ```java for (int partitionNum = 0; partitionNum < sourceCount; partitionNum++) { IntermediateResultPartition partition = ires.getPartitions()[partitionNum]; ConsumedPartitionGroup consumerPartitionGroup = new ConsumedPartitionGroup(partition.getPartitionId()); float factor = ((float) targetCount) / sourceCount; int start = (int) (Math.ceil(partitionNum * factor)); int end = (int) (Math.ceil((partitionNum + 1) * factor)); List<ExecutionVertexID> consumers = new ArrayList<>(end - start); for (int i = start; i < end; i++) { ExecutionVertex executionVertex = taskVertices[i]; executionVertex.addConsumedPartitions(consumerPartitionGroup, inputNumber); consumers.add(executionVertex.getID()); } ConsumerVertexGroup consumerVertexGroup = new ConsumerVertexGroup(consumers); partition.addConsumers(consumerVertexGroup); } ``` ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionVertex.java ########## @@ -321,107 +323,11 @@ public ExecutionGraph getExecutionGraph() { // Graph building // -------------------------------------------------------------------------------------------- - public void connectSource( - int inputNumber, IntermediateResult source, JobEdge edge, int consumerNumber) { - - final DistributionPattern pattern = edge.getDistributionPattern(); - final IntermediateResultPartition[] sourcePartitions = source.getPartitions(); - - ExecutionEdge[] edges; - - switch (pattern) { - case POINTWISE: - edges = connectPointwise(sourcePartitions, inputNumber); - break; - - case ALL_TO_ALL: - edges = connectAllToAll(sourcePartitions, inputNumber); - break; - - default: - throw new RuntimeException("Unrecognized distribution pattern."); - } - - inputEdges[inputNumber] = edges; - - // add the consumers to the source - // for now (until the receiver initiated handshake is in place), we need to register the - // edges as the execution graph - for (ExecutionEdge ee : edges) { - ee.getSource().addConsumer(ee, consumerNumber); - } - } - - private ExecutionEdge[] connectAllToAll( - IntermediateResultPartition[] sourcePartitions, int inputNumber) { - ExecutionEdge[] edges = new ExecutionEdge[sourcePartitions.length]; - - for (int i = 0; i < sourcePartitions.length; i++) { - IntermediateResultPartition irp = sourcePartitions[i]; - edges[i] = new ExecutionEdge(irp, this, inputNumber); - } - - return edges; - } - - private ExecutionEdge[] connectPointwise( - IntermediateResultPartition[] sourcePartitions, int inputNumber) { - final int numSources = sourcePartitions.length; - final int parallelism = getTotalNumberOfParallelSubtasks(); - - // simple case same number of sources as targets - if (numSources == parallelism) { - return new ExecutionEdge[] { - new ExecutionEdge(sourcePartitions[subTaskIndex], this, inputNumber) - }; - } else if (numSources < parallelism) { - - int sourcePartition; - - // check if the pattern is regular or irregular - // we use int arithmetics for regular, and floating point with rounding for irregular - if (parallelism % numSources == 0) { - // same number of targets per source - int factor = parallelism / numSources; - sourcePartition = subTaskIndex / factor; - } else { - // different number of targets per source - float factor = ((float) parallelism) / numSources; - sourcePartition = (int) (subTaskIndex / factor); - } - - return new ExecutionEdge[] { - new ExecutionEdge(sourcePartitions[sourcePartition], this, inputNumber) - }; - } else { - if (numSources % parallelism == 0) { - // same number of targets per source - int factor = numSources / parallelism; - int startIndex = subTaskIndex * factor; - - ExecutionEdge[] edges = new ExecutionEdge[factor]; - for (int i = 0; i < factor; i++) { - edges[i] = - new ExecutionEdge(sourcePartitions[startIndex + i], this, inputNumber); - } - return edges; - } else { - float factor = ((float) numSources) / parallelism; + public void addConsumedPartitions(ConsumedPartitionGroup consumedPartitions, int inputNum) { - int start = (int) (subTaskIndex * factor); - int end = - (subTaskIndex == getTotalNumberOfParallelSubtasks() - 1) - ? sourcePartitions.length - : (int) ((subTaskIndex + 1) * factor); Review comment: For the situation source parallelism < target parallelism, we still iterate over all the vertices as before. Thus, the modified version is the same as the original version. @zhuzhurk points out that this logic can be simplified as: ```java for (int index = 0; index < targetCount; index++) { ExecutionVertex executionVertex = taskVertices[index]; ConsumerVertexGroup consumerVertexGroup = new ConsumerVertexGroup(executionVertex.getID()); int start = index * sourceCount / targetCount; int end = (index + 1) * sourceCount / targetCount; List<IntermediateResultPartitionID> consumedPartitions = new ArrayList<>(end - start); for (int i = start; i < end; i++) { IntermediateResultPartition partition = ires.getPartitions()[i]; partition.addConsumers(consumerVertexGroup); consumedPartitions.add(partition.getPartitionId()); } ConsumedPartitionGroup consumedPartitionGroup = new ConsumedPartitionGroup(consumedPartitions); executionVertex.addConsumedPartitions(consumedPartitionGroup, inputNumber); } ``` Here, `(int) (subTaskIndex * factor)` is equal to `index * sourceCount / targetCount`, and `(int) ((subTaskIndex + 1) * factor)` is equal to `(index + 1) * sourceCount / targetCount` We validated several simple cases, and it works. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManager.java ########## @@ -0,0 +1,89 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.HashMap; +import java.util.List; +import java.util.Map; + +import static org.apache.flink.util.Preconditions.checkState; + +/** Class that manages all the connections between tasks. */ +public class EdgeManager { + + private final Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> partitionConsumers = + new HashMap<>(); + + private final Map<ExecutionVertexID, List<ConsumedPartitionGroup>> vertexConsumedPartitions = + new HashMap<>(); + + public void addPartitionConsumers( + IntermediateResultPartitionID resultPartitionId, ConsumerVertexGroup consumerVertices) { + + checkState(!partitionConsumers.containsKey(resultPartitionId)); + + final List<ConsumerVertexGroup> consumers = getPartitionConsumers(resultPartitionId); + + // sanity check + checkState( + consumers.size() == 0, Review comment: Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionVertex.java ########## @@ -503,16 +411,15 @@ public void connectSource( new HashSet<>(getTotalNumberOfParallelSubtasks()); // go over all inputs - for (int i = 0; i < inputEdges.length; i++) { + for (ConsumedPartitionGroup sources : allConsumedPartitions) { inputLocations.clear(); - ExecutionEdge[] sources = inputEdges[i]; if (sources != null) { // go over all input sources Review comment: Resolved. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/EdgeManager.java ########## @@ -0,0 +1,89 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.executiongraph; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; +import org.apache.flink.runtime.scheduler.strategy.ConsumedPartitionGroup; +import org.apache.flink.runtime.scheduler.strategy.ConsumerVertexGroup; +import org.apache.flink.runtime.scheduler.strategy.ExecutionVertexID; + +import java.util.ArrayList; +import java.util.HashMap; +import java.util.List; +import java.util.Map; + +import static org.apache.flink.util.Preconditions.checkState; + +/** Class that manages all the connections between tasks. */ +public class EdgeManager { Review comment: > Do we need some tests for this class? We think it's covered by existing tests. The all-to-all edges are tested by `ExecutionGraphConstructionTest`. The pointwise edges are tested by `PointwisePatternTest`. ########## File path: flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/strategy/ConsumedPartitionGroup.java ########## @@ -0,0 +1,41 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License + */ + +package org.apache.flink.runtime.scheduler.strategy; + +import org.apache.flink.runtime.jobgraph.IntermediateResultPartitionID; + +import java.util.Collections; +import java.util.List; + +/** Group of consumed {@link IntermediateResultPartitionID}s. */ +public class ConsumedPartitionGroup { + private final List<IntermediateResultPartitionID> resultPartitions; + + public ConsumedPartitionGroup(List<IntermediateResultPartitionID> resultPartitions) { + this.resultPartitions = resultPartitions; + } + + public ConsumedPartitionGroup(IntermediateResultPartitionID resultPartition) { + this(Collections.singletonList(resultPartition)); + } + + public List<IntermediateResultPartitionID> getResultPartitions() { + return Collections.unmodifiableList(resultPartitions); + } Review comment: Totally agreed. This will make the call of `ConsumedPartitionGroup` more simplified. After discussing with @zhuzhurk, we decided to have the following methods: * `iterator()` * `size()` * `getFirst()` (to replace `get(0)`) * `isEmpty()` ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
{kind=link}