Hello Geoff, On Thu, 2025-03-06 at 01:24 +0000, Geoff Huston wrote: > There is a difference between taking a single vantage point (or a > small set of vantage) and looking at the behaviour of a resolution of > a large domain set, > and taking a very large set of vantage points and looking at the > behaviours of resolution of a small set of domains that exhibit > particular properties. > > The work we do at APNIC Labs is focussed on the latter mode, and this > has lead to our observations about the incremental issues arising > from the use of IPv6 transport for the DNS.
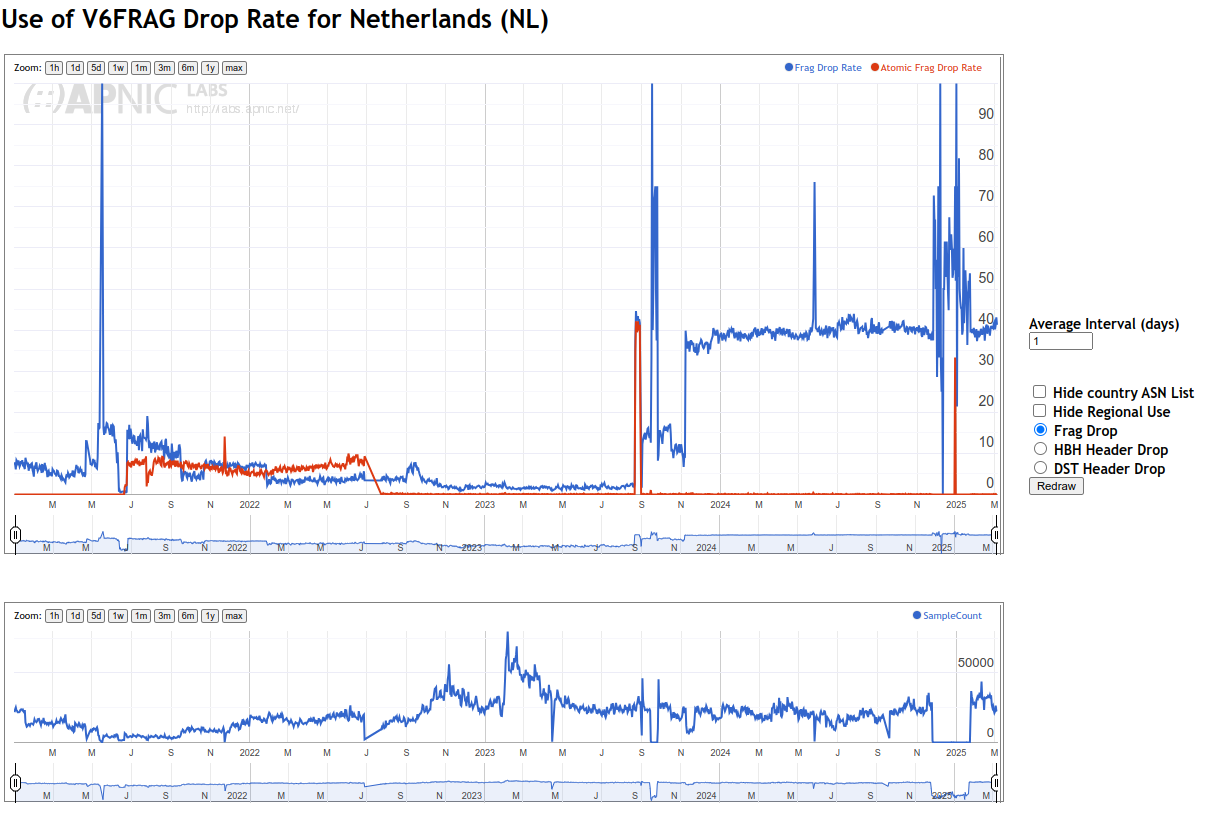
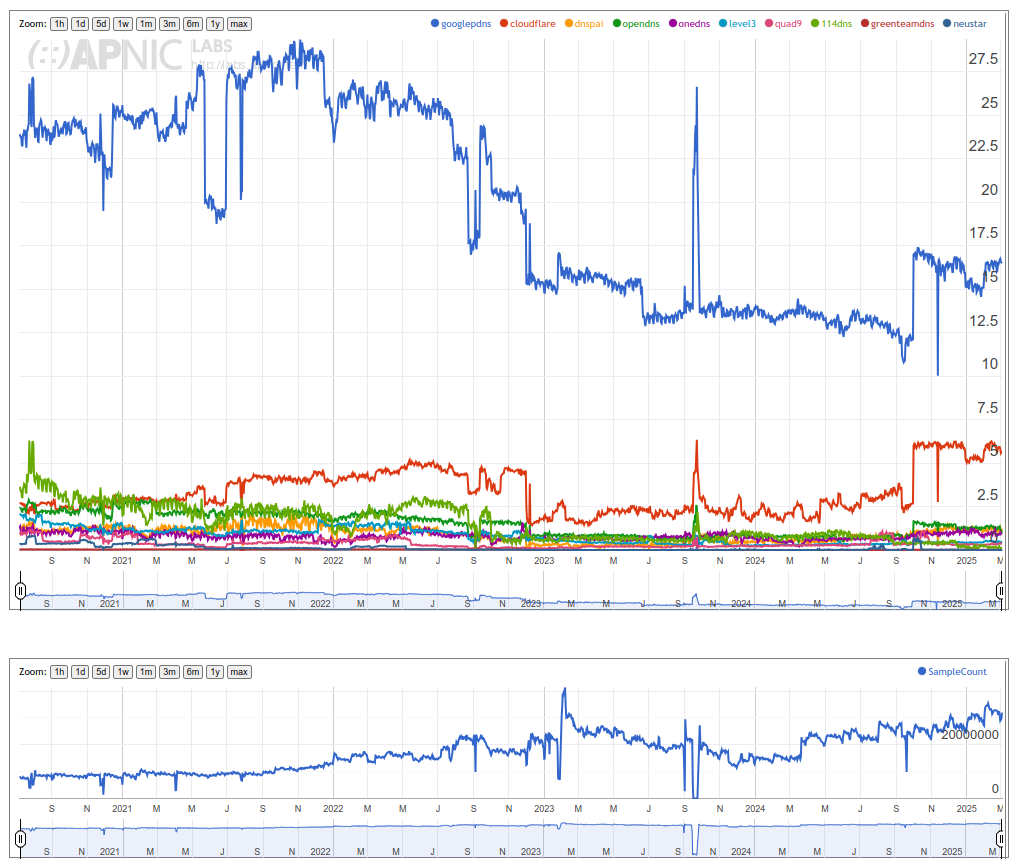
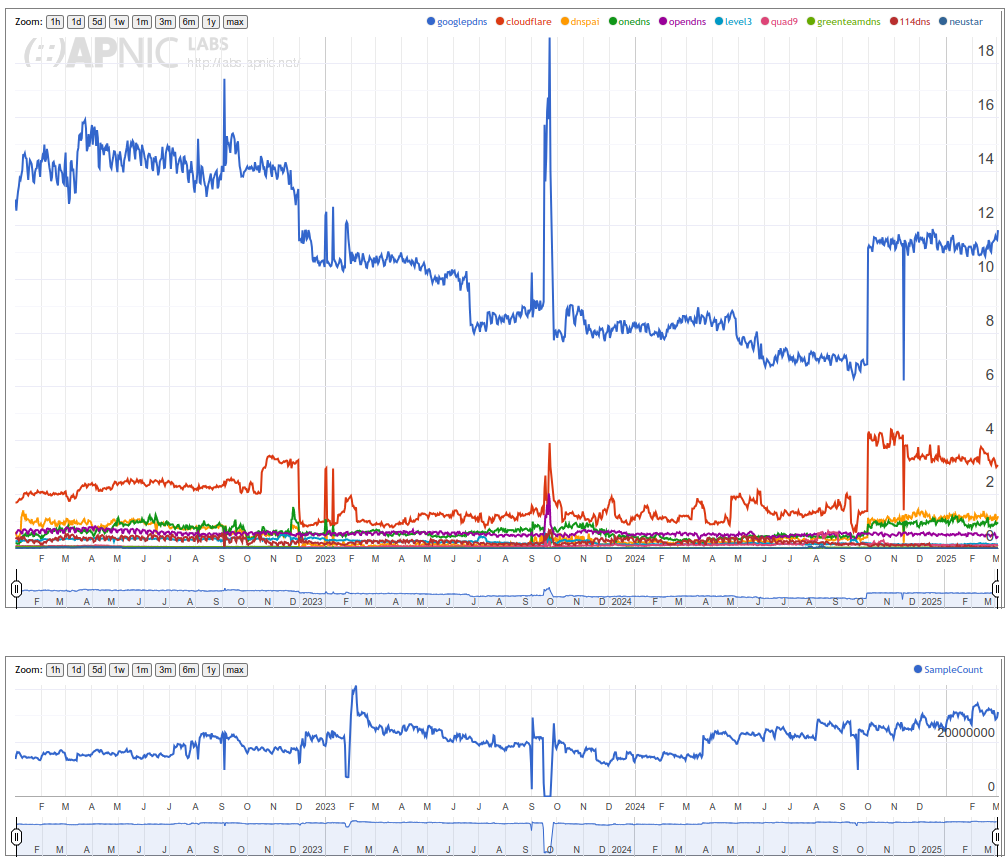
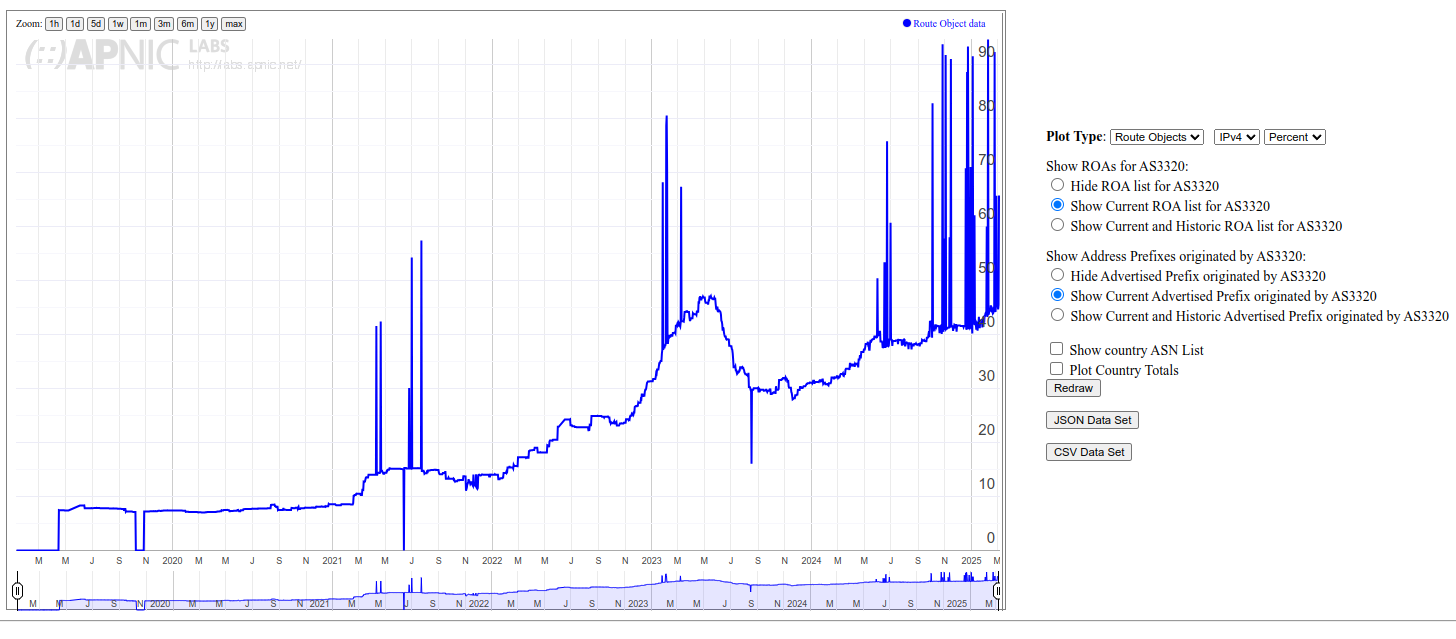
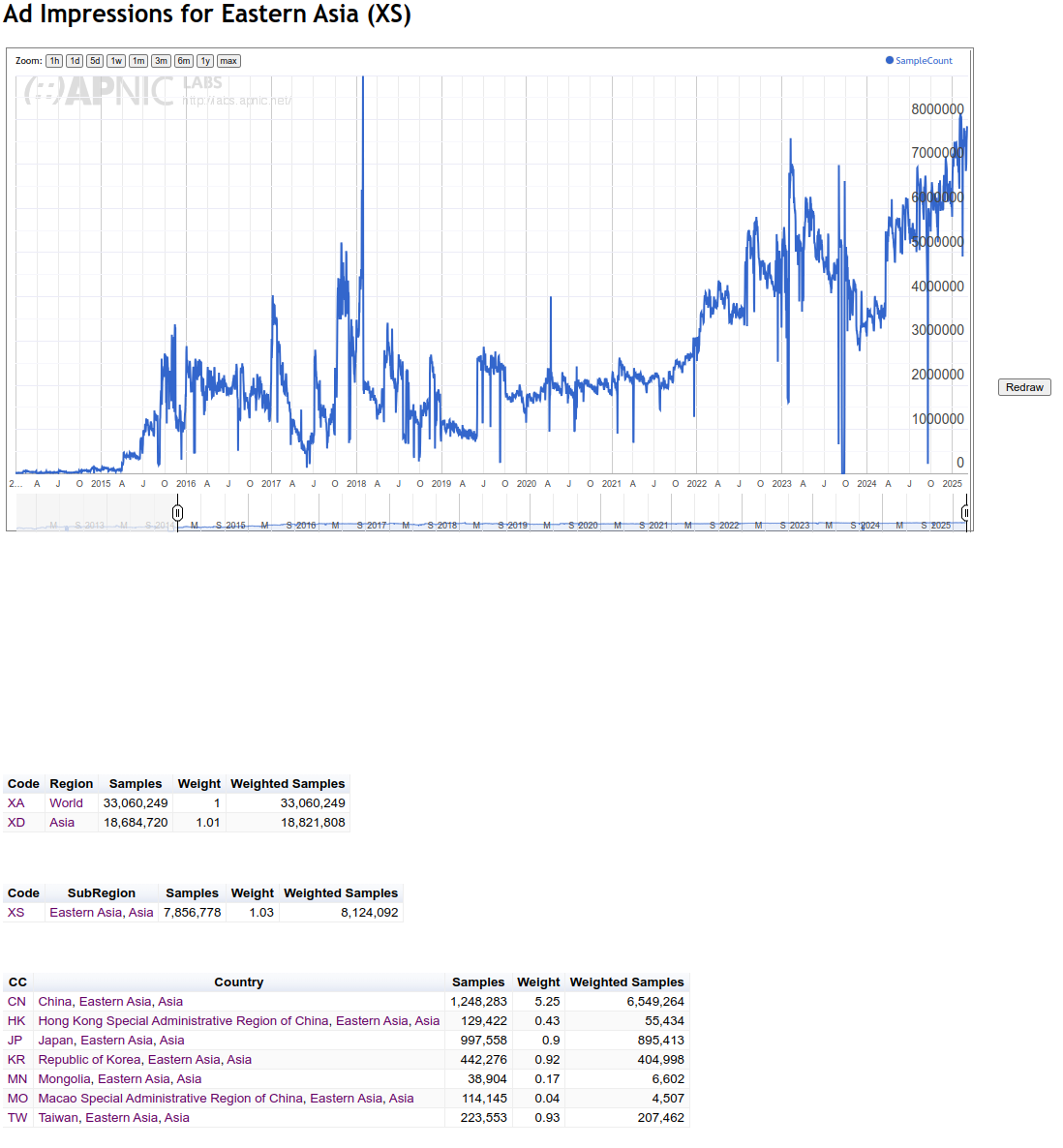
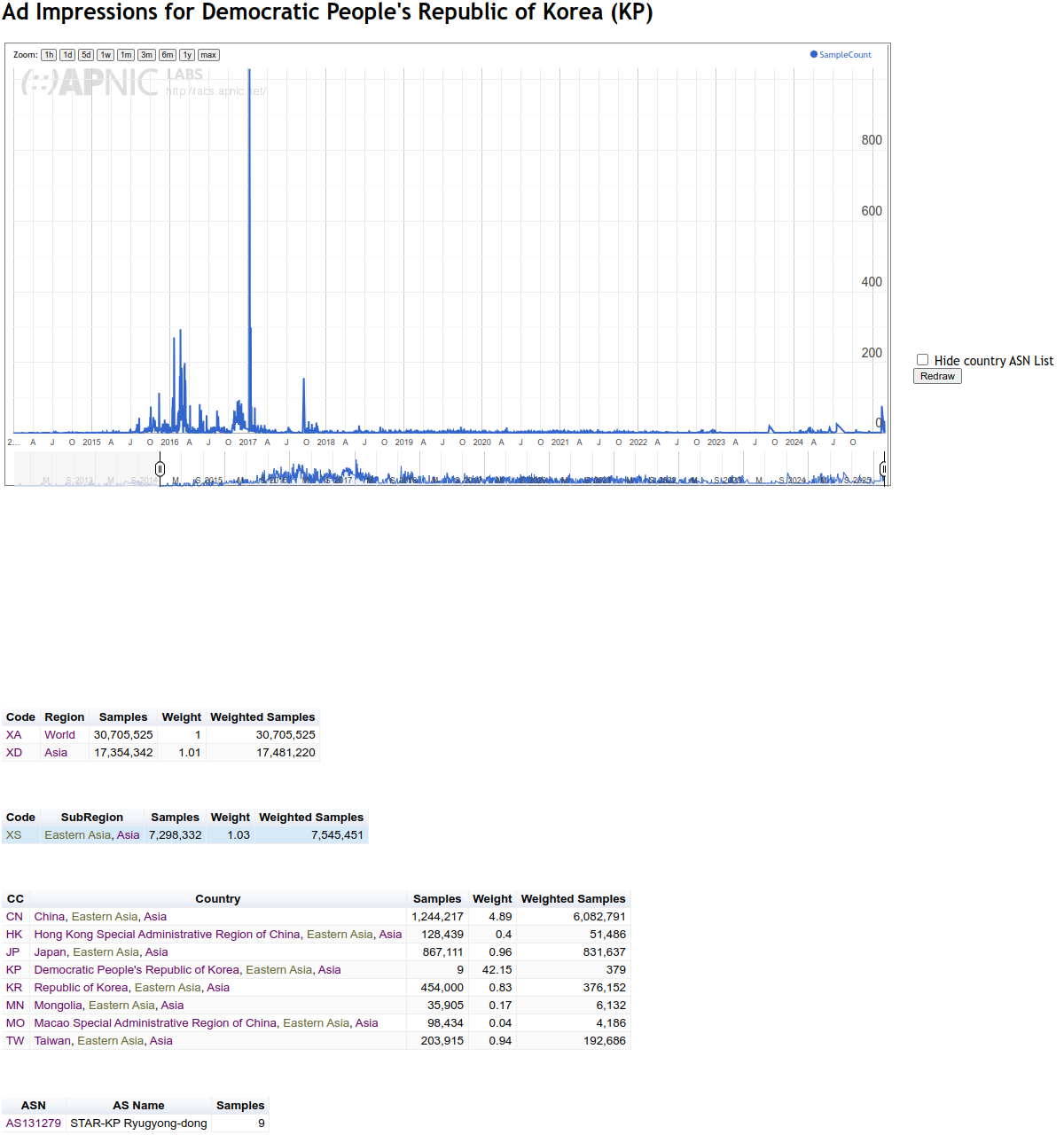
Actually, you are not using more vantage points; Given that you are inverting the measurement direction, in your setup, the authoritatives are the vantage points. > Clearly we disagree here over the quantification of this > impactarising from these differing methodologies. The problem is, that your work is very much impossible to reproduce, and raw data is not available. That makes it impossible to argue on this data, because _any_ other measurement could ultimately be argued against with 'but our data does not show this'. In fact, your measurements demonstrate several limitations highly impacting the results and conclusions. Those events range in the same order of magnitude as the _whole effects_ I am measuring. In fact, for many cases, it seems like core effects are tied to an individual operator; Btw, does somebody know someone working for LGI/Liberty Global? Fixing their fragment dropping would make a lot of things a lot better in those stats. --- # Measured fragment drop rates Given what we are discussing, fragmentation dropping as a major concern, this ist the most critical issue in the data. During my scans of authoritatives, the impact of fragments being lost was not notable for .nl. .nl saw between 0.25% and 2.5% of connections during resolution encounter fragments on UDP, with a lower share of fragments for IPv6 enabled NSSets. Naturally, fragmentation was higher for zones with DNSSEC, but not notably different between v4 and v6: https://data.measurement.network/dns-mtu-msmt/out_data/2025-03-04/plots/pcap_stats/pcap_stats_UDP_frag.pdf At the same time, the APNIC data reports ~40% drop rate for IPv6 fragments in the Netherlands. Notably, up until the second half of 2023, that rate was well below 5%. After an event at the end of August 2023, where both frag drop and atomic frag drop rate rose to ~40%, the rate seemed to plateau around 15%, followed by a steep increase in the end of November 2023, again to a rate around 40%, comparable to the high increase observed in the end of August 2023. Unlike two other constraint events since then, this is not accompanied by a corresponding decrease in the number of clients. https://rincewind.home.aperture-labs.org/~tfiebig/mtu/frag-drop-nl.png Listing this by AS, it is clear that LGI/AS33915 is the main culprit here, providing Internet for a large portion of people in the Netherlands via its subsidiary Ziggo. However, this aggregation approach highly skews the country stats; We have to convince one operator to properly handle fragments, not half a country. Furthermore, this pattern continues across countries: For PL, IE, SK, the root cause is AS6830 (LGI). For CH, the root cause is AS6730 (Sunrise, behind LGI). For BE, the root cause is AS6848 (Telenet BV, behind LGI). ... Interestingly, though, the LGI/Vodafone instance in DE (AS3209) seems to _not_ have such a high frag drop rate. At the same time, Cloudflare- -likely due to their tunnel offerings--seems to have a notable impact in the eyeball space. Hence, I would argue that we do not really have a global problem with IPv6 fragment dropping (at least in Europe). We have an issue with LGI's network (or a specific device/vendor/configuration used only in specific countries). Does somebody know someone working there? # Impact of vantage point location in a fragment-dropping AS Interestingly, though, AS63949 AKAMAI-LINODE-AP Akamai Connected Cloud, shows up prominently in the data for .NL; According to the APNIC data, this AS shows a volatile drop rate, averaging well above 50%. This is also the AS in which the vantage points seem to be located. It is unclear, in how far this additionally impacts the measurements' reliability. --- Beyond those aspects, there are several other aspects which raise some doubts w.r.t. the reliability of the meausrement platform: # Noise Effects The measurements exhibit strange cliffs with volatile jumps in the range of orders of magnitude impacting all measured endpoints with no clear root-cause; See, for example, the suspicious cliff in q1 use from late 2022 until late 2024: https://rincewind.home.aperture-labs.org/~tfiebig/mtu/dns-resolver-use-all-resolvers.png https://rincewind.home.aperture-labs.org/~tfiebig/mtu/dns-resolver-use-first.png Similar noise effects occur in other measurements as well, for example the RPKI validation data (for example for AS3320's announced prefixes): https://rincewind.home.aperture-labs.org/~tfiebig/mtu/AS3320-RPKI.png # High participation from North Korea Some time ago I remarked that I found the high number of daily users from NK a bit odd; Indeed, it seems like KP is no longer listed as part of Eastern Asia: https://rincewind.home.aperture-labs.org/~tfiebig/mtu/adds_eastern_asia.png However, looking at the country-site for 'KP', that data still seems to be there, also receiving a comparatively high 'Weight' for the number of samples: https://rincewind.home.aperture-labs.org/~tfiebig/mtu/KP-samples-over-time.png Interestingly, the AS responsible for this has actually less v4 announced than me, and seems to also contain a fair bit of hosted services in those prefixes: https://bgp.tools/prefix/175.45.179.0/24#dns https://bgp.tools/prefix/175.45.176.0/24#dns For comparison, look at, e.g., FFMUC: https://rincewind.home.aperture-labs.org/~tfiebig/mtu/FFMUC-samples-over-time.png This eyeball project as ~2-4k concurrently active users; See: https://stats.ffmuc.net/d/kUoZ2DRWz/network-overview?orgId=1&from=now-7d&to=now&timezone=browser&refresh=1m # Impact of MTU mingeling from hypervisors As I noted before, the set of vantage points for your measurements is actually somewhat limited, effectively to the number (iirc <=10) authoritatives put up. Furthermore, as far as I know, you are running the authoritatives on virtual machines rented from a commodity hoster. The problem there is that the use of VirtIO NICs can actually heavily impact MTU behavior in a way transparent to the virtual machine. The only way I managed to force my systems to fragment and drop 'correctly' was not only forcing TSO/GRO et al. to off on the host, but also explicitly doing so on the nic of the Hypervisor. # Zone-path of measurement domain One of the domains involved in the measurements seems to be dotnxdomain.net: % dig +short NS dotnxdomain.net ns1.dotnxdomain.net. ns3.dotnxdomain.net. At least from an EU PoP, these do resolve to IPs in Australia (ns1.) and SoCal (ns3.); % dig +short A ns1.dotnxdomain.net 203.133.248.6 % dig +short A ns3.dotnxdomain.net 173.230.146.214 % dig +short AAAA ns1.dotnxdomain.net 2401:2000:6660::6 % dig +short AAAA ns3.dotnxdomain.net 2600:3c01::f03c:93ff:fe02:be25 This induces notable latency and sources of error along the path, even if the final resolution for the <cc/region> names thereunder used in the actual measurements are different. Essentially, it adds 'traversing half the planet' to the set of noise sources. # Measurement Setup / Config Location The measurements seem to (have been) configured via cfg.dotnxdomain.net; This name (again, via the aforementioned NS) resolves to three distinct IPs, located in AP, EU, and NA: % dig +short A cfg.dotnxdomain.net 139.162.2.194 139.162.149.100 45.79.7.112 % dig +short AAAA cfg.dotnxdomain.net 2a01:7e01::f03c:91ff:fe12:6bfe 2400:8901::f03c:91ff:fe98:63d6 2600:3c00::f03c:91ff:fe98:16c8 The problem with that is that clients may end up on a rather remote cfg. host of these. That, in turn, may lead to self-selection depending on clock and timeout settings. At least for cfg. retrieval, the timeout seems to be 10000ms, which should be mostly save. Nevertheless, the added latency may lead clients to abandon the ad; Also, I am not sure what timeout behavior modern browsers are forcing. When throwing these names into Atlas with resolve-on-probe, at least, RTT and hit end-point vary wildly and are not congruent with the physical locations of probes: v4: https://atlas.ripe.net/measurements/89419109/overview v6: https://atlas.ripe.net/measurements/89419368/overview --- So, in summary, I am not convinced that the data commonly referenced is robust enough to allow the strength of conclusions drawn on fragment handling for IPv6. With best regards, Tobias _______________________________________________ DNSOP mailing list -- [email protected] To unsubscribe send an email to [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}