Ahh, as expected some great thoughts have gone into this. :-) Allowing the ignore of comments when parsing is not "inventing a new format", IMO. More so because the RFC allows it (section 9) and because it would be strictly opt-in. So the parser can still be said to be strictly RFC-8259 while optionally supporting such feature. I'm speculating the authors of the RFC has thought of it as a form a pre-processing when they used the word "extension" and that is indeed a good way to think about it.
In any case my goal was purely comments in the JSON, not about allowing other forms of leniency, like trailing commas, flexible quotes, etc. I feel those are in another category and not something that should (ever) be supported. I can see why someone might ask for that if comments where allowed to be ignored by the lib. The argument about slippery slope can be made. I just fear that newbies will try to build their own pre-processor, using regexp or whatever .. and get it wrong. I agree with you that JSON5 sneaks in too many odd things. Keep up the good work. /Lars On 16/05/2025 15.17, Brian Goetz wrote: > At first, we were hopeful that we could jump right to JSON5, which > appears at first glance to be a strictly lexical, more permissive > grammar for JSON (supporting comments, trailing commas, more flexible > quoting, white space, etc.) If that were actually true, this would > have been a slam dunk, since all these lexical niceties don't have an > impact on the parsed results. And JSON5 has been gaining some > traction, so it probably could have been a justifiable move to jump > right to that. > > But then we discovered that JSON5 also sneaks in some semantics, by > also supporting the exotic numeric values (NaN, infinities, signed > zero), which now has consequences for "what is a number", the numeric > representation, the API for unpacking numeric values, etc. (Having > multiple parsers is one thing; having multiple parsers that produce > different semantics is entirely another.) And inventing a new "JSON5 > but not quite" subset would be doing no one any favors. > > Jsonc seems to be entirely a MS-ecosystem thing; it does not have > broad enough traction to be the "one grammar" we accept. So pure > JSON, as specification-challenged as it is, is the logical, though > sad, conclusion (for now.) > > > > On 5/16/2025 9:02 AM, Lars Bruun-Hansen wrote: >> >> >> Great work. >> >> >> I feel the elephant in the room needs to addressed: JSON comments. I >> haven't tested the proposed lib but I cannot see it mentioned so I'm >> assuming that comments are not supported. >> >> For better or worse, the use of jsonc (JSON with comments) is >> everywhere in some ecosystems. Unsurprisingly this happens often when >> JSON is used as a config file format. Looking at you, Microsoft. >> >> It would be nice if the JDK's build-in JSON parser at least >> recognized this. >> >> I'm well aware that comments are frowned upon in JSON and not part of >> neither the spec at www.json.org nor the RFC-8259. >> >> Yet, I advocate the JDK JSON library should optionally allow comments >> to be ignored when PARSING. This should be an opt-in feature that >> would technically treat comments as whitespace during the parsing >> process. >> >> This would also be in line with what many other parsers do. For >> example, Jackson has "ALLOW_COMMENTS" feature [1]. Also, by >> comparison, the build-in parser in the .NET world, known as >> System.Text.Json, also supports this [2]. >> >> >> >> The "discoverer" of JSON, Douglas Crowford, had this to say [3] on >> the topic: >> >> >> [QUOTE] >> >> I removed comments from JSON because I saw people were using them to >> hold parsing directives, a practice which would have destroyed >> interoperability. I know that the lack of comments makes some people >> sad, but it shouldn't. >> >> Suppose you are using JSON to keep configuration files, which you >> would like to annotate. Go ahead and insert all the comments you >> like. Then pipe it through JSMin before handing it to your JSON parser. >> >> [/QUOTE] >> >> >> By not having the ability to ignore comments when parsing we would >> effectively force users to use another parser first or a minifier. I >> doubt beginners would appreciate that. >> >> >> BTW: The test suite already has tests for comments. >> >> >> /Lars >> >> >> [1]: >> https://www.javadoc.io/static/com.fasterxml.jackson.core/jackson-core/2.19.0/com/fasterxml/jackson/core/JsonParser.Feature.html#ALLOW_COMMENTS >> >> [2]: >> https://learn.microsoft.com/en-us/dotnet/api/system.text.json.jsonreaderoptions?view=net-9.0#properties >> >> [3]: https://plus.google.com/118095276221607585885/posts/RK8qyGVaGSr >> >> >> >> >> On 16/05/2025 01.44, Ethan McCue wrote: >>> I present for your consideration the library I made when spiraling >>> about this problem space a few years ago >>> >>> https://github.com/bowbahdoe/json >>> >>> https://javadoc.io/doc/dev.mccue/json/latest/dev.mccue.json/dev/mccue/json/package-summary.html >>> >>> Notably missing during the design process here were patterns, hence >>> the JsonDecoder design. I haven't been able to evaluate how patterns >>> affect that on account of them not being out. >>> >>> I will more thoroughly peruse the draft of java.util.json at a later >>> date, but my initial observations/comments: >>> >>> * I am not sure having JsonValue be distinct from Json has value. >>> * toUntyped feels a little strange to me - the only type information >>> presumably lost is the sealed-ness of the hierarchy. The interplay >>> between that and toNumber is also a little unnerving. >>> * One notion that I found helpful was that a class could be "json >>> encodable," meaning there is a method to call to obtain a canonical >>> json representation. >>> >>> record Person(String name) implements JsonEncodable { >>> @Override >>> public Json toJson() { >>> return Json.objectBuilder() >>> .put("namen", name) >>> .build(); >>> } >>> } >>> >>> Which helper methods like Json#of(List<? extends >>> JsonEncodable>) could make use of. Json itself (JsonValue in your >>> prototype) could then have a vacuous implementation. >>> >>> * Terminology wise - I went with reading/writing for the actual >>> parsing/generation of json and encoding/decoding for the mapping of >>> those representations to/from specific classes. The merits are not >>> top of mind, just noting the difference. read/write vs >>> parse/toString+toDisplayString >>> * One thing I did was make the helper methods in Json null tolerant >>> and the ones in the specific subtypes like JsonString not. This was >>> because from what I saw of usages of javax.json/jakarta.json that >>> nullability was a footgun and correcting for it required changes to >>> code structure (breaking up builder chains with if (x != null) checks) >>> * The functionality you want from JsonNumber could be achieved by >>> making it just extend Number >>> (https://github.com/bowbahdoe/json/blob/main/src/main/java/dev/mccue/json/JsonNumber.java) >>> instead of a bespoke toNumber. You need the extra methods to go to >>> big decimal and co, but it's just an extension to the behavior of >>> Number at that point. >>> * JsonObject and JsonArray could implement Map<String, Json> and >>> List<Json> respectively. This lowers the need for toUntyped() - >>> since presumably one of the use cases for that is turning the json >>> tree into something that more generic map/list traversal code can >>> handle. It also complicates any lazy loading somewhat. >>> * Assuming patterns can be placed on interfaces, you might want to >>> consider something similar to JsonDecoder, but with a pattern >>> instead of a method that throws an exception. >>> >>> // Where here fromJson would box up the logic for testing and >>> extracting from each element in the array. >>> List<Person> people = array(json, Person::fromJson); >>> >>> * I don't think there is sufficient cause for anything to be >>> non-sealed at this point. >>> * JsonBoolean and JsonNull do not have reasonable alternative >>> implementations - as far as I can imagine, maybe i'm wrong - so >>> maybe those can just be final classes? >>> * If you seal up the whole hierarchy then its pretty trivial to make >>> it serializable >>> (https://github.com/bowbahdoe/json/blob/main/src/main/java/dev/mccue/json/serialization/JsonSerializationProxy.java) >>> >>> >>> >>> >>> On Thu, May 15, 2025 at 11:29 PM Remi Forax <fo...@univ-mlv.fr> wrote: >>> >>> Hi Paul, >>> yes, not having a simple JSON API in Java is an issue for beginners. >>> >>> It's not clear to me why JsonArray (for example) has to be an >>> interface instead of a record ? >>> >>> I understand why Json.parse() only works on String and char[] >>> but the API make it too easy to have many performance issues. >>> I think you need versions using a Reader and a Path. >>> Bonus point, if there is a method walk() that also returns a >>> JsonValue but the List/Map inside JsonArray/JsonObject are >>> populated lazily. >>> >>> Minor point: Json.toDisplayString() should takes a second >>> parameters indicating the number of spaces used for the >>> indentation (like JSON.stringify in JS). >>> >>> regards, >>> Rémi >>> >>> ----- Original Message ----- >>> > From: "Paul Sandoz" <paul.san...@oracle.com> >>> > To: "core-libs-dev" <core-libs-dev@openjdk.org> >>> > Sent: Thursday, May 15, 2025 10:30:42 PM >>> > Subject: Towards a JSON API for the JDK >>> >>> > Hi, >>> > >>> > We would like to share with you our thoughts and plans towards >>> a JSON API for >>> > the JDK. >>> > Please see the document below. >>> > >>> > - >>> > >>> > We have had the pleasure of using a clone of this API in some >>> experiments we are >>> > conducting with >>> > ONNX and code reflection [1]. Using the API we were able to >>> quickly write code >>> > to ingest and convert >>> > a JSON document representing ONNX operation schema into >>> instances of records >>> > modeling the schema >>> > (see here [2]). >>> > >>> > The overall out-of-box experience with such a minimal >>> "batteries included” API >>> > has so far been positive. >>> > >>> > Thanks, >>> > Paul. >>> > >>> > [1] https://openjdk.org/projects/babylon/ >>> > [2] >>> > >>> >>> https://github.com/openjdk/babylon/blob/code-reflection/cr-examples/onnx/opgen/src/main/java/oracle/code/onnx/opgen/OpSchemaParser.java#L87 >>> > >>> > # Towards a JSON API for the JDK >>> > >>> > One of the most common requests for the JDK is an API for >>> parsing and generating >>> > JSON. While JSON originated as a text-based serialization >>> format for JSON >>> > objects ("JSON" stands for "JavaScript Object Notation"), >>> because of its simple >>> > and flexible syntax, it eventually found use outside the >>> JavaScript ecosystem as >>> > a general data interchange format, such as framework >>> configuration files and web >>> > service requests/response formats. >>> > >>> > While the JDK cannot, and should not, provide libraries for >>> every conceivable >>> > file format or protocol, the JDK philosophy is one of >>> "batteries included", >>> > which is to say we should be able to write basic programs that >>> use common >>> > protocols such as HTTP, without having to appeal to third >>> party libraries. >>> > The Java ecosystem already has plenty of JSON libraries, so >>> inclusion in >>> > the JDK is largely meant to be a convenience, rather than >>> needing to be the "one >>> > true" JSON library to meet the needs of all users. Users with >>> specific needs >>> > are always free to select one of the existing third-party >>> libraries. >>> > >>> > ## Goals and requirements >>> > >>> > Our primary goal is that the library be simple to use for >>> parsing, traversing, >>> > and generating conformant JSON documents. Advanced features, >>> such as data >>> > binding or path-based traversal should be possible to >>> implement as layered >>> > features, but for simplicity are not included in the core API. >>> We adopt a goal >>> > that the performance should be "good enough", but where >>> performance >>> > considerations conflict with simplicity and usability, we will >>> choose in favor >>> > of the latter. >>> > >>> > ## API design approach >>> > >>> > The description of JSON at `https:://json.org >>> <http://json.org>` describes a JSON document using >>> > the familiar "railroad diagram": >>> > 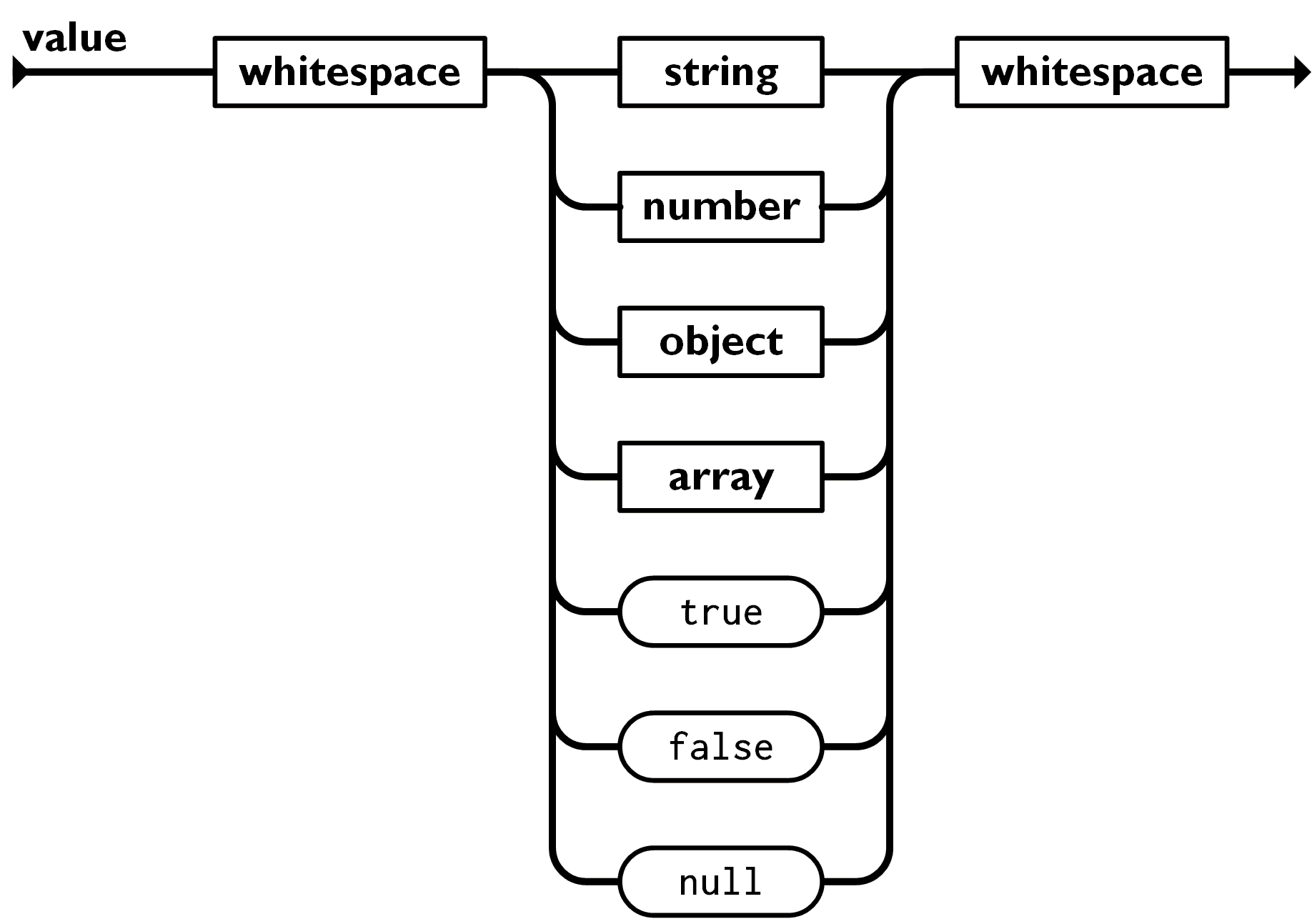 >>> > >>> > This diagram describes an algebraic data type (a sum of >>> products), which we >>> > model directly with a set of Java interfaces: >>> > >>> > ``` >>> > interface JsonValue { } >>> > interface JsonArray extends JsonValue { List<JsonValue> >>> values(); } >>> > interface JsonObject extends JsonValue { Map<String, >>> JsonValue> members(); } >>> > interface JsonNumber extends JsonValue { Number toNumber(); } >>> > interface JsonString extends JsonValue { String value(); } >>> > interface JsonBoolean extends JsonValue { boolean value(); } >>> > interface JsonNull extends JsonValue { } >>> > ``` >>> > >>> > These interfaces have (hidden) companion implementation >>> classes that admit >>> > greater flexibility of implementation than modeling them >>> directly with records >>> > would permit. >>> > Further, these interfaces are unsealed. We compromise on the >>> sealed sum of >>> > products to enable >>> > alternative implementations, for example to support >>> alternative formats that >>> > encode the same information in a JSON document but in a more >>> efficient form than >>> > text. >>> > >>> > The API has static methods for parsing strings into a >>> `JsonValue`, conversion to >>> > and from purely untyped representations (lists and maps), and >>> factory methods >>> > for building JSON documents. We apply composition >>> consistently, e.g, a >>> > JsonString has a string, a JsonObject has a map of string to >>> JsonValue, as >>> > opposed to extension for structural JSON values. >>> > >>> > It turns out that this simple API is almost all we need for >>> traversal. It gives >>> > us an immutable representation of a document, and we can use >>> pattern matching to >>> > answer the myriad questions that will come up (Does this >>> object have key X? Does >>> > it map to a number? Is that number representable as an >>> integer?) when going >>> > from an untyped format like JSON to a more strongly typed >>> domain model. >>> > Given a simple document like: >>> > >>> > ``` >>> > { >>> > "name": "John”, >>> > "age": 30 >>> > } >>> > ``` >>> > >>> > we can parse and traverse the document as follows: >>> > >>> > ``` >>> > JsonValue doc = Json.parse(inputString); >>> > if (doc instanceof JsonObject o >>> > && o.members().get("name") instanceof JsonString s >>> > && s.value() instanceof String name >>> > && o.members().get("age") instanceof JsonNumber n >>> > && n.toNumber() instanceof Long l && l instanceof int age) { >>> > // use "name" and "age" >>> > } >>> > ``` >>> > >>> > Later, when the language acquires the ability to expose >>> deconstruction patterns >>> > for arbitrary interfaces (similar to today's record patterns, see >>> > >>> >>> https://openjdk.org/projects/amber/design-notes/patterns/towards-member-patterns), >>> > this will be simplifiable to: >>> > >>> > ``` >>> > JsonValue doc = Json.parse(inputString); >>> > if (doc instanceof JsonObject(var members) >>> > && members.get("name") instanceof JsonString(String name) >>> > && members.get("age") instanceof JsonNumber(int age)) { >>> > // use "name" and "age" >>> > } >>> > ``` >>> > >>> > So, overtime, as more pattern matching features are introduced >>> we anticipate >>> > improved use of the API. This is a primary reason why the API >>> is so minimal. >>> > Convenience methods we add today, such as a method that >>> accesses a JSON >>> > object component as say a JSON string or throws an exception, >>> will become >>> > redundant in the future. >>> > >>> > ## JSON numbers >>> > >>> > The specification of JSON number makes no explicit distinction >>> between integral >>> > and decimal numbers, nor specifies limits on the size of those >>> numbers. >>> > This is a common source of interoperability issues when >>> consuming JSON >>> > documents. Generally users cannot always but often do assume >>> JSON numbers are >>> > parsable, without loss of precision, to IEEE double-precision >>> floating point >>> > numbers or 32-bit signed integers. >>> > >>> > In this respect the API provides three means to operate on the >>> JSON number, >>> > giving the user full control: >>> > >>> > 1. Underlying string representation can be obtained, if >>> preserving syntactic >>> > details such as leading or trailing zeros is important. >>> > 2. The string representation can be parsed to an instance of >>> `BigDecimal`, using >>> > `toBigDecimal` if preserving decimal numbers is important. >>> > 3. The string representation can be parsed into an instance of >>> `Long`, `Double`, >>> > `BigInteger`, or `BigDecimal`, using `toNumber`. The result >>> of this method >>> > depends on how the representation can be parsed, possibly >>> losing precision, >>> > choosing a suitably convenient numeric type that can then be >>> pattern >>> > matched on. >>> > >>> > Primitive pattern matching will help as will further pattern >>> matching features >>> > enabling the user to partially match. >>> > >>> > ## Prototype implementation >>> > >>> > The prototype implementation is currently located into the JDK >>> sandbox >>> > repository >>> > under the `json` branch, see >>> > here >>> > >>> >>> https://github.com/openjdk/jdk-sandbox/tree/json/src/java.base/share/classes/java/util/json >>> > The prototype API javadoc generated from the repository is >>> also available at >>> > >>> >>> https://cr.openjdk.org/~naoto/json/javadoc/api/java.base/java/util/json/package-summary.html >>> > >>> > ### Testing and conformance >>> > >>> > The prototype implementation passes all conformance test cases >>> but two, >>> > available >>> > on https://github.com/nst/JSONTestSuite. The two exceptions >>> are the ones which >>> > the >>> > prototype specifically prohibits, i.e, duplicated names in >>> JSON objects >>> > >>> >>> (https://cr.openjdk.org/~naoto/json/conformance/results/parsing.html#35). >>> > >>> > ### Performance >>> > >>> > Our main focus so far has been on the API design and a functional >>> > implementation. >>> > Hence, there has been less focus on performance even though we >>> know there are a >>> > number of performance enhancements we can make eventually. >>> > We are reasonably happy with the current performance. The >>> > implementation performs well when compared to other JSON >>> implementations >>> > parsing from string instances and traversing documents. >>> > >>> > An example of where we may choose simplicity and usability >>> over performance >>> > is the rejection of JSON documents containing objects that in >>> turn contain >>> > members >>> > with duplicate names. That may increase the cost of parsing, >>> but simplifies the >>> > user >>> > experience for the majority of cases since if we reasonably >>> assume JsonObjects >>> > are >>> > map-like, what should the user do with such members, pick one >>> the last one? >>> > merge >>> > the values? or reject? >>> > >>> > ## A JSON JEP? >>> > >>> > We plan to draft JEP when we are ready. Attentive readers will >>> observe that >>> > a JEP already exists, JEP 198: Light-Weight JSON API >>> > (https://openjdk.org/jeps/198). We will >>> > either update this JEP, or withdraw it and draft a new one. >>> >
{kind=link}