@Massimo @Niphlod Patch for scheduler docs. Mostly clarifications and syntactical corrections. Thanks-.
On Saturday, September 1, 2012 1:00:49 PM UTC-4, Massimo Di Pierro wrote: > > The web2py book app has been rewritten > > http://www.web2py.com/book > > and the source of the app and the book itself is now on github > > https://github.com/mdipierro/web2py-book/tree/master/sources > > Hopefully this will make it easier to keep it updated. You can just send > me patches. You can also try run it yourself and see how it looks. It is no > more db based. it is file based. The syntax is markmin as documented in the > bok itself. > > Massimo > > > > > --
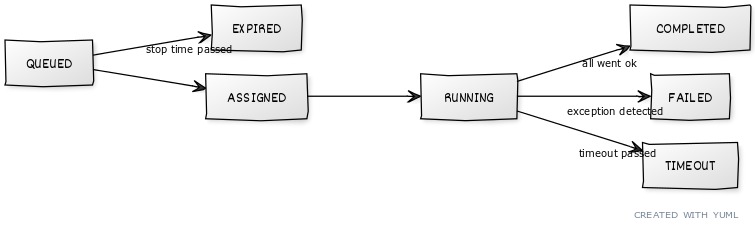
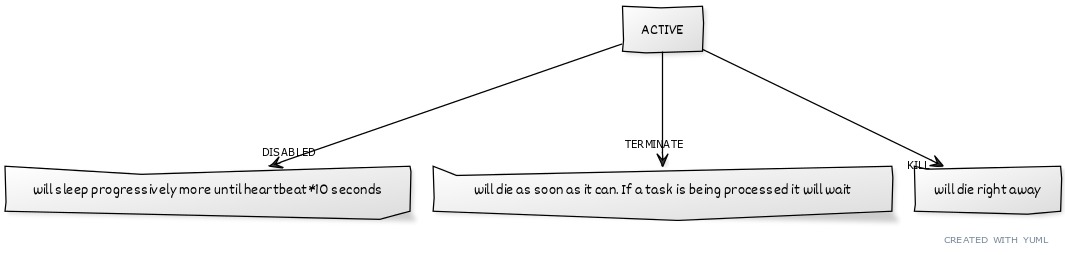
>From 0f2eef084252b641eae8e5b671ad06c1b715f0ed Mon Sep 17 00:00:00 2001 From: Yarin Kessler <[email protected]> Date: Thu, 13 Sep 2012 17:10:51 -0400 Subject: [PATCH] Squashed changes --- sources/29-web2py-english/04.markmin | 122 ++++++++++++++-------------------- 1 files changed, 51 insertions(+), 71 deletions(-) diff --git a/sources/29-web2py-english/04.markmin b/sources/29-web2py-english/04.markmin index 4280e62..8bd97bb 100644 --- a/sources/29-web2py-english/04.markmin +++ b/sources/29-web2py-english/04.markmin @@ -2105,10 +2105,9 @@ def task_add(a,b): return a+b ``:code -Tasks will always be called in the same environment seen by controllers and therefore they see all the global variables defined in models, including database connections (``db``). Tasks differ from a controller action because they are not associated with an HTTP request and therefore there is no ``request.env``. +Tasks will always be called in the same environment seen by controllers and therefore they see all the global variables defined in models, including database connections (``db``). Tasks differ from controller actions because they are not associated with an HTTP request and therefore there is no ``request.env``. -To enable the scheduler you should put into a model its instantiation. -The recommended way to enable the scheduler to your app is to create a model file named ``scheduler.py`` and define your function there. After the functions, you can put the following code into the model: +To enable the scheduler you should instantiate it inside a model. For example, it's recommended you create a model file named ``scheduler.py`` and define your functions there, followed by the code: `` from gluon.scheduler import Scheduler @@ -2118,13 +2117,14 @@ NB: If your tasks are defined in a module (as opposed to a model) you may have t ##### Parameters -The first argument of the ``Scheduler`` class must be the database to be used by the scheduler to communicate with the workers. This can be the ``db`` of the app or another dedicated ``db``, perhaps one shared by multiple apps. If you use SQLite it's recommended to use a separate db from the one used by your app in order to keep the app responsive. -Once the tasks are defined and the ``Scheduler`` is instantiated, all that is needed to do is to start the workers. You can do that in several ways: + +The ``Scheduler`` class requires a ``db`` argument that points to the database it will use to communicate with the workers. This can be the ``db`` of the app or another dedicated ``db``, perhaps one shared by multiple apps. If you use SQLite it is recommended to use a separate db from the one used by your app in order to keep the app responsive. +Once the tasks are defined and the ``Scheduler`` is instantiated, all that's needed is to start the workers. You can do that in several ways: `` python web2py.py -K myapp `` -starts a worker for the app ``myapp``. If you want start multiple workers for the same app, you can do so just passing ``myapp,myapp``. You can pass also the ``group_names`` (overriding the one set in your model) with +starts a worker for the app ``myapp``. If you want to start multiple workers for the same app, you can simply pass ``myapp,myapp``. You can also pass the ``group_names`` (overriding the one set in your model) with `` python web2py.py -K myapp:group1:group2,myotherapp:group1 @@ -2132,14 +2132,14 @@ python web2py.py -K myapp:group1:group2,myotherapp:group1 If you have a model called ``scheduler.py`` you can start/stop the workers from web2py's default window (the one you use to set the ip address and the port). -One last nice addition: if you use the embedded webserver, you can start the webserver and the scheduler with just one line of code (this assumes you don't want the web2py window popping up, or you can use the "Schedulers" menu instead) +Finally, if you use the embedded webserver, you can start the webserver and the scheduler with just one line of code (this assumes you don't want the web2py window popping up, or you can use the "Schedulers" menu instead) `` python web2py.py -a yourpass -K myapp -X `` You can pass the usual parameters (-i, -p, here -a prevents the window from showing up), pass whatever app in the -K parameter and append a -X. The scheduler will run alongside the webserver! -Scheduler's complete signature is: +Scheduler's complete signature is as follows: `` Scheduler( @@ -2155,35 +2155,32 @@ Scheduler( ) ``:code -Let's see them in order: +Let's review them in order: -- ``db`` is the database DAL instance were you want the scheduler tables be placed. -- ``tasks`` can be a dict. Must be defined if you want to call a function not by his name, i.e. ``tasks=dict(mynameddemo1=demo1)`` will let you execute function demo1 with ``st.insert(task_name='mytask', function_name='mynameddemo1')`` or ``st.insert(task_name='mytask', function_name='demo1')``. If you don't pass this parameter, function will be searched in the app environment. +- ``db`` is the database DAL instance where you want the scheduler tables be placed. +- ``tasks`` can be a dict. This must be defined if you want to call functions by an alias, i.e. ``tasks=dict(mynameddemo1=demo1)`` will let you execute function demo1 with ``st.insert(task_name='mytask', function_name='mynameddemo1')`` or ``st.insert(task_name='mytask', function_name='demo1')``. If you don't pass this parameter, functions will be searched for in the app environment. - ``worker_name`` is None by default. As soon as the worker is started, a worker name is generated as hostname-uuid. If you want to specify that, be sure that it's unique. -- ``group_names`` is by default set to **[main]**. All tasks have a ``group_name`` parameter, set to **main** by default. Workers can only pick up tasks of their assigned group. +- ``group_names`` is by default set to **[main]**. All tasks have a ``group_name`` parameter, set to **main** by default. Workers can only pick up tasks from their assigned groups. NB: This is useful if you have different workers instances (e.g. on different machines) and you want to assign tasks to a specific worker. -NB2: It's possible to assign a worker more groups, and they can be also all the same, as -``['mygroup','mygroup']``. Tasks will be distributed taking into consideration that -a worker with group_names ``['mygroup','mygroup']`` is able to process the double of the tasks -a worker with group_names ``['mygroup']`` is. -- ``heartbeat`` is by default set to 3 seconds. This parameter is the one controlling how often a scheduler will check its status on the ``scheduler_worker`` table and see if there are any **ASSIGNED** tasks to itself to process. -- ``max_empty_runs`` is 0 by default, that means that the worker will continue to process tasks as soon as they are **ASSIGNED**. If you set this to a value of, let's say, 10, a worker will die automatically if it's **ACTIVE** and no tasks are **ASSIGNED** to it for 10 loops. A loop is when a worker searches for tasks, every 3 seconds (or the set ``heartbeat``) +NB2: It's possible to assign a worker multiple groups, and a group may also be assigned multiple times to the same worker (e.g. ``['mygroup','mygroup']``) - In this case, the distribution of tasks across multiple workers will take into account that the worker with a group assigned twice ``['mygroup','mygroup']`` is able to process double the tasks relative to a worker that has the group assigned only once- ``['mygroup']``. +- ``heartbeat`` is set to 3 seconds by default. This parameter controls how often a scheduler will check its own status on the ``scheduler_worker`` table and check if there are **ASSIGNED** tasks for it to process. +- ``max_empty_runs`` is 0 by default, which means that the worker will continue to process tasks as soon as they are **ASSIGNED**. If you set this to a value of, let's say, 10, a worker will die automatically if it's **ACTIVE** and no tasks are **ASSIGNED** to it for 10 loops. A loop is when a worker searches for tasks, every 3 seconds (or the set ``heartbeat``) - ``discard_results`` is False by default. If set to True, no scheduler_run records will be created. NB: scheduler_run records will be created as before for **FAILED**, **TIMEOUT** and -**STOPPED** tasks's statuses. -- ``utc_time`` is False by default. If you need to coordinate with workers living in different timezones, or don't have problems with solar/DST times, supplying datetimes from different countries, etc, you can set this to True. The scheduler will honor the UTC time and work leaving the local time aside. Caveat: you need to schedule tasks with UTC times (for start_time, stop_time, and so on.) +**STOPPED** tasks' statuses. +- ``utc_time`` is False by default. In most production deployments UTC time would be the recommended way of handling scheduler times, as it solves the problem of scheduling across multiple client time zones, managing daylight savings, and handling clock variations across different servers. Note that web2py stores datetime values naively- i.e. without timezone information. Setting ``utc_time = True`` simply tells the scheduler to treat time values like ``start_time``, ``stop_time`` as UTC time instead of local server time. It is still up to your application to convert local client times into UTC time for storage and vice-versa. Now we have the infrastructure in place: defined the tasks, told the scheduler about them, started the worker(s). What remains is to actually schedule the tasks ##### Tasks -Tasks can be scheduled programmatically or via appadmin. In fact, a task is scheduled simply by adding an entry in the table "scheduler_task", which you can access via appadmin: +Tasks represent the scheduled functions that workers will execute. A task is scheduled simply by adding an entry in the ``scheduler_task`` table, either programmatically or via appadmin: `` http://127.0.0.1:8000/myapp/appadmin/insert/db/scheduler_task `` -The meaning of the fields in this table is obvious. The "args" and "vars"" fields are the values to be passed to the task in JSON format. In the case of the "task_add" above, an example of "args" and "vars" could be: +The ``args`` and ``vars`` fields are the values to be passed to the task in JSON format. In the case of the "task_add" above, an example of ``args`` and ``vars`` could be: `` args = [3, 4] @@ -2197,44 +2194,33 @@ args = [] vars = {'a':3, 'b':4} `` -The ``scheduler_task`` table is the one where tasks are organized. -All tasks follow a lifecycle +All tasks follow a lifecycle: [[scheduler tasks http://yuml.me/ce8edcc3.jpg center]] -Let's go with order. By default, when you send a task to the scheduler, you'll want that to be executed. It's in **QUEUED** status. -If you need it to be executed later, use the ``start_time`` parameter (default = now). -If for some reason you need to be sure that the task don't get executed after a certain point in time (maybe a request to a webservice -that shuts down at 1AM, a mail that needs to be sent not after the working hours, etc...) you can set a ``stop_time`` (default = None) for it. -If your task is NOT picked up by a worker before stop_time, it will be set as **EXPIRED**. -Tasks with no stop_time set or picked up **BEFORE** stop_time are **ASSIGNED** to a worker. When a workers picks up them, they become **RUNNING**. -**RUNNING** tasks may end up: -- **TIMEOUT** when more than n seconds passed with ``timeout`` parameter (default = 60 seconds) -- **FAILED** when an exception is detected -- **COMPLETED** when all went ok +Let's review these in order: +- By default, when a task is added to the scheduler, it should start in **QUEUED** status. +- The ``start_time`` parameter dictates when the task will be run. If not set, ``start_time`` will default to the current time, in which case the task will be executed by the next available worker. +- If for some reason you need to be sure that the task doesn't get executed after a certain point in time (e.g. email that needs to be sent before end of workday, etc...) you can set a ``stop_time`` (default = None) as well. If your task is NOT picked up by a worker before ``stop_time``, it will be set as **EXPIRED**. +- Tasks with no ``stop_time`` set or picked up ''before'' ``stop_time`` are **ASSIGNED** to a worker. When a worker picks up them, they become RUNNING. **RUNNING** tasks may end up: +-- **TIMEOUT** when execution time exceeds the ``timeout`` parameter (default = 60 seconds) +-- **FAILED** when an exception is detected +-- **COMPLETED** when all went ok -Additionally, you can control how many times a task should be repeated (i.e. you need to aggregate some data at specified intervals). To do so, set the ``repeats`` -parameter (default = 1 time only, 0 = unlimited). You can influence how many seconds should pass between executions with the ``period`` parameter (default = 60 seconds). -NB: the time is not calculated between the END of the first round and the START of the next, but from the START time of the first round to the START time of the next cycle) +Additionally, you can control how many times a task should be repeated (e.g. If you need to aggregate some data at specified intervals). To do so, set the ``repeats`` +parameter (default = 1 time only, 0 = unlimited). You control how many seconds should pass between executions with the ``period`` parameter (default = 60 seconds). +NB: Period is calculated relative to the ''start'' time of one cycle to the next, regardless of cycle ''end'' times. -Another nice addition, you can set how many times the function can raise an exception (i.e. requesting data from a sloooow webservice) and be queued again instead of stopping in **FAILED** status with the parameter ``retry_failed`` (default = 0, -1 = unlimited). +In addition, you can use the ``retry_failed`` (default = 0, -1 = unlimited) parameter to set the number of times a task can "fail" (e.g. An exception or timeout from a slow webservice) and be queued again before stopping in **FAILED**/**TIMEOUT** status. [[task repeats http://yuml.me/7d8b85e4.jpg center]] -Summary: you have -- ``period`` and ``repeats`` to get an automatically rescheduled function -- ``timeout`` to be sure that a function doesn't exceed a certain amount of time -- ``retry_failed`` to control how many times the task can "fail" -- ``start_time`` and ``stop_time`` to schedule a function in a restricted timeframe - ##### Reporting percentages -A special "word" encountered in the print statements of your functions clear all -the previous output. That word is ``!clear!``. -This, coupled with the ``sync_output`` parameter, allows to report percentages -a breeze. Let's see how that works: +A special "word" encountered in the print statements of your functions will clear all previous output. That word is ``!clear!``. +This, coupled with the ``sync_output`` parameter, allows you to easily report execution percentages. Let's see how that works: `` def reporting_percentages(): @@ -2253,7 +2239,7 @@ st.validate_and_insert(task_name='percentages', function_name='demo6', sync_outp `` ##### Results and output -The table "scheduler_run" stores the status of all running tasks. Each record references a task that has been picked up by a worker. One task can have multiple runs. For example, a task scheduled to repeat 10 times an hour will probably have 10 runs (unless one fails or they take longer than 1 hour). Beware that if the task has no return values, it is removed from the scheduler_run table as soon as it is finished. +The ``scheduler_run`` table stores the status of all running tasks. Each record references a task that has been picked up by a worker. A single task can have multiple runs. For example, a task scheduled to repeat 10 times an hour will probably have 10 runs (unless one fails or they take longer than 1 hour). Possible run statuses are: @@ -2261,42 +2247,36 @@ Possible run statuses are: RUNNING, COMPLETED, FAILED, TIMEOUT `` -If the run is completed, no exceptions are thrown, and there is no task timeout, the run is marked as ``COMPLETED`` and the task is marked as ``QUEUED`` or ``COMPLETED`` depending on whether it is supposed to run again at a later time. The output of the task is serialized in JSON and stored in the run record. - -When a ``RUNNING`` task throws an exception, the run is mark as ``FAILED`` and the task is marked as ``FAILED``. The traceback is stored in the run record. - -Similarly, when a run exceeds the timeout, it is stopped and marked as ``TIMEOUT``, and the task is marked as ``TIMEOUT``. +If the run is completed, no exceptions are thrown, and there is no task timeout, the run is marked as **COMPLETED**. If the run produces return values then the output is serialized in JSON and stored in the run record. If a run returns no output, however, it is removed from the ``scheduler_run`` table as soon as it is finished. -In any case, the stdout is captured and also logged into the run record. +If a **RUNNING** task throws an exception, the run is mark as **FAILED** and the traceback is stored in the run record. Similarly, when a run exceeds the timeout, it is stopped and marked as **TIMEOUT**. -Using appadmin, one can check all ``RUNNING`` tasks, the output of ``COMPLETED`` tasks, the error of ``FAILED`` tasks, etc. +The task status will likewise be updated to **COMPLETED**, **FAILED**, or **TIMEOUT** based on the result of the last run, unless it is scheduled to run again at a later time, in which case it will be set to **QUEUED**. -The scheduler also creates one more table called "scheduler_worker", which stores the workers' heartbeat and their status. Possible worker statuses are: +Using appadmin, one can check all **RUNNING** tasks, the output of **COMPLETED** tasks, the error of **FAILED** tasks, etc. ##### Managing processes -Worker fine management is hard. This module tries not to leave behind any platform (Mac, Win, Linux) . -When you start a worker, you may want later to: +When you start a worker, you may later want to: - kill it "no matter what it's doing" - kill it only if it's not processing tasks - put it to sleep -Maybe you have yet some tasks queued, and you want to save some resources. -You know you want them processed every hour, so, you'll want to: +Or if you have tasks queued to process every hour, but want to save some resources, you may want to: - process all queued tasks and die automatically -All of these things are possible managing ``Scheduler`` parameters or the ``scheduler_worker`` table. -To be more precise, for started workers you will change the ``status`` value of any worker to influence -its behavior. -As tasks, workers can be in some fixed statuses : ACTIVE, DISABLED, TERMINATE or KILLED. -**ACTIVE** and **DISABLED** are "persistent", while **TERMINATE** or **KILL**, as statuses -name suggest, are more "commands" than real statuses. -Hitting ctrl+c is equal to set a worker to **KILL** +You can control how workers behave through the ``Scheduler`` parameters or by editing the ``scheduler_worker`` table, which stores the workers' heartbeat and their status. Possible worker statuses are: + +`` +ACTIVE, DISABLED, TERMINATE or KILL +`` + +**ACTIVE** and **DISABLED** are "persistent" statuses, while **TERMINATE** or **KILL**, as the names suggest, are more "commands" than real statuses. [[workers statuses http://yuml.me/bd891eed.jpg center]] -Everything that one can do via appadmin one can do programmatically by inserting and updating records in these tables. +##### Usage -Anyway, one should not update records relative to ``RUNNING`` tasks as this may create an un-expected behavior. The best practice is to queue tasks using "validate_and_insert". For example: +Everything that one can do via appadmin one can do programmatically by inserting and updating records in the ``scheduler_worker`` and ``scheduler_task`` tables. However, one should not update records relative to **RUNNING** tasks as this may create an un-expected behavior. The best practice is to queue tasks using ``validate_and_insert``. For example: `` db.scheduler_task._validate_and_insert( @@ -2309,7 +2289,7 @@ db.scheduler_task._validate_and_insert( ) ``:code -Notice that fields "times_run", "last_run_time" and "assigned_worker_name" are not provided at schedule time but are filled automatically by the workers. +Notice that fields ``times_run``, ``last_run_time`` and ``assigned_worker_name`` are not provided at schedule time but are filled in automatically by the workers. You can also retrieve the output of completed tasks: -- 1.7.6
{kind=link}
{kind=link}
{kind=link}