I know it.
My question is how I can do it without implementing Interpreter.
$ find . -name \*.java|xargs grep "%table"
./hive/src/main/java/org/apache/zeppelin/hive/HiveInterpreter.java: msg = new
StringBuilder("%table ");
./ignite/src/main/java/org/apache/zeppelin/ignite/IgniteSqlInterpreter.java: StringBuilder msg =
new StringBuilder("%table ");
./lens/src/main/java/org/apache/zeppelin/lens/LensInterpreter.java: sb.append("%table " +
entry.getKey() + " \n");
./lens/src/main/java/org/apache/zeppelin/lens/LensInterpreter.java:
sb.append("%table ");
./spark/src/main/java/org/apache/zeppelin/spark/ZeppelinContext.java: return
"%table " + msg;
./tajo/src/main/java/org/apache/zeppelin/tajo/TajoInterpreter.java: msg = new
StringBuilder("%table ");
DepInterpreter you recommended doesn't implement it?
On 2015/07/02 15:36, IT CTO wrote:
Based on the documentation (
http://zeppelin.incubator.apache.org/docs/display.html) you can use the
following:
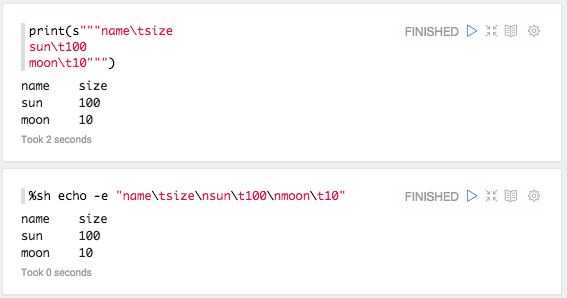
Display as Table, Chart If output starts with %table, it is interpreted as
a table. Table can be seen as chart. Output's format should be, row
separated by '\n' (newline) and column separated by '\t' (tab). First row
is header. (
http://zeppelin.incubator.apache.org/assets/themes/zeppelin/img/screenshots/display_table.png
)
Eran
On Thu, Jul 2, 2015 at 9:26 AM Koji Sekiguchi <koji.sekigu...@rondhuit.com>
wrote:
Hi IT CTO,
Thank you for the reply!
Ok, so now my question is only visualization of charts.
http://nlp4l.github.io/tutorial.html#withZeppelin_visualize
How can I use charts to display word count appearing Lucene index
without implementing Interpreter?
regards,
Koji
On 2015/07/02 15:14, IT CTO wrote:
I hope I am not missleading you but as far as I understand the "spark
interpreter" is actually a scala interpreter until the time you access
one
of the context objects, and as much as I understand from you library, you
have a stand alone library which should be loaded and accessed locally.
So - all you need to do is in you scala code use the %dep to load the
library and then call it's API.
This is just to save you time next time.
You need to write an interpreter only if you want to access a back-end
computation engine such as SPARK or ignite or any ODBC source. for local
api call %dep should be enough.
HTH,
Eran
On Wed, Jul 1, 2015 at 5:24 AM Koji Sekiguchi <
koji.sekigu...@rondhuit.com>
wrote:
Hi IT CTO,
Thank you for the reply!
Because I couldn't find any ways to use charts (bar chart, pie chart,
etc.) in Zeppelin
without having my own Interpreter... If you know it, please let me know.
And now I see the comment of DepInterpreter, it seems it is used for
Spark:
/**
* DepInterpreter downloads dependencies and pass them when
SparkInterpreter initialized.
* It extends SparkInterpreter but does not create sparkcontext
*
*/
nevertheless, it can be used for general purpose?
regards,
Koji
On 2015/06/30 20:25, IT CTO wrote:
This might be a stupid question but ....
Quick question regarding the NLP4L - why did you need to create an
interpreter for NLP4L? what is the deference from just using the %dep
and
loading from scala and then accessing it from scala paragrap?
Eran
On Tue, Jun 30, 2015 at 10:56 AM Ophir Cohen <oph...@gmail.com> wrote:
Hi Daniel and good luck.
Can you share the meetup details?
10x
On Mon, Jun 29, 2015 at 9:30 AM, Daniel Haviv <
daniel.ha...@veracity-group.com> wrote:
Hi everybody,
We are going to arrange a meetup in Israel where I'm going to
dedicate
45
minutes to introduce Zeppelin to the Big Data community in Israel.
I'm going to display general usage of the Spark cli via zeppelin (and
it's charting capabilities) and the WordCloud.
Please share any cool examples you have of Zeppelin I can use.
After the meetup, I will make sure these examples will be publicly
available.
Thanks,
Daniel Haviv
{kind=link}