Hey Piotr, I think we are broadly in agreement, hopefully.
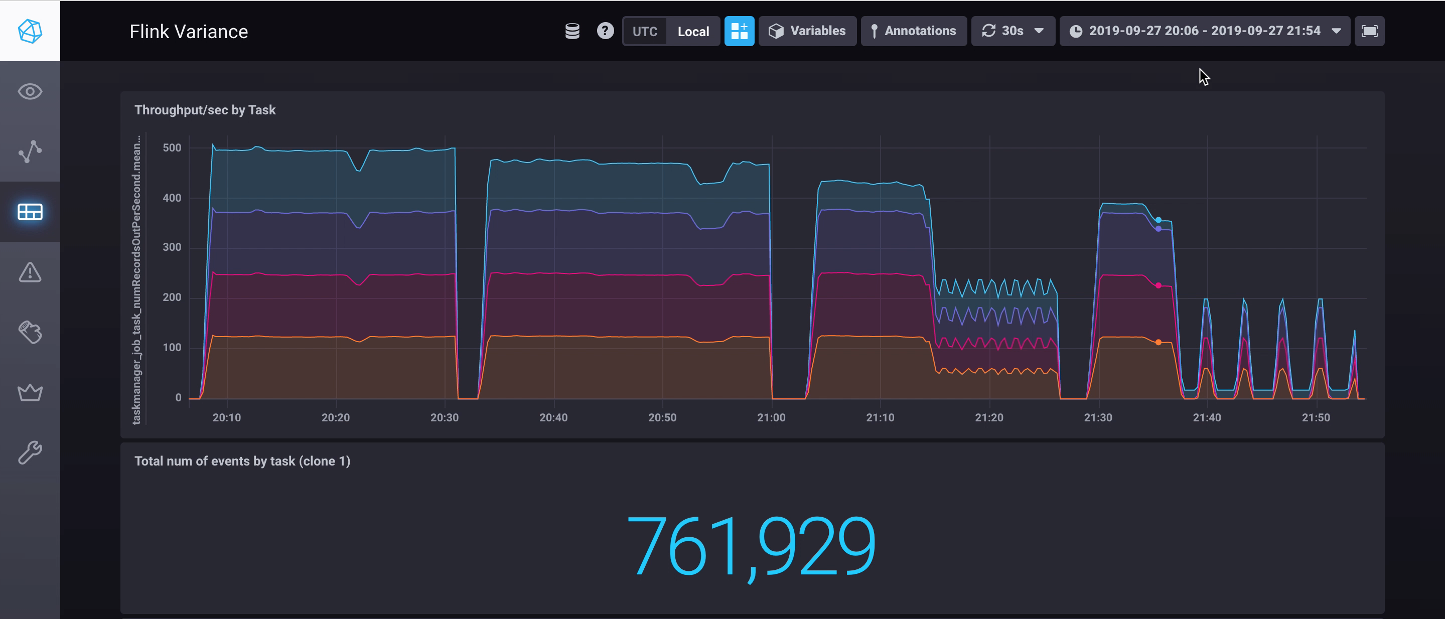
So out of the three scenarios you describe, the code is simulating scenario 2). The only additional comment I would make to this is that the additional load on a node could be an independent service or job. I am guessing we can agree, that in the context of multi-tenant Hadoop, this is quite common? For instance, assuming Flink is deployed on the datanodes then I could see the following as a few examples: - another tenant runs a heavy batch job that overlaps with our streaming datanodes - someone runs a juicy adhoc Hive query which overlaps with our datanodes - HBase performs compaction or replica movement on some of our datanodes Now in an ideal world, I might have a dedicated cluster or be deployed in the cloud. Then I have an easier life. However, there are lots of data-engineers operating in challenging multi-tenant Hadoop environments, where life is not so easy : o You stated that Flink does not support scenario 2. Typically, Spark is deployed onto the datanodes for data-locality. I had assumed the same would be true for Flink. Is that assumption incorrect? Cheers, Owen On Thu, 10 Oct 2019 at 15:23, Piotr Nowojski <pi...@ververica.com> wrote: > Hi Owen, > > Thanks for the quick response. No, I haven’t seen the previous blog post, > yes it clears the things out a bit. > > To clarify, the code is attempting to simulate a straggler node due to > high load, which therefore processes data at a slower rate - not a failing > node. Some degree of this is a feature of multi-tenant Hadoop. > > > In your benchmark you are manually slowing down just one TaskManager, so > you are testing for the failing/slow machine case, where either: > 1. the machine is slow on it’s own because it’s smaller than the others, > 2. it’s overloaded by some service independent of the Flink > 3. it's a failing node. > > Out of those three options, first two are not supported by Flink, in a > sense that Flink assumes more or less equal machines in the cluster. The > third is, as I wrote in the previous response, pretty uncommon scenario > (until you reach really huge scale). How often one of your machine fails in > a way that it is 6.6 times slower than the others? I agree Flink doesn’t > handle this automatically at the moment (currently you would be expected to > manually shut down the machine). Nevertheless there are some plans how to > address this (speculative execution and load based balancing channel > selection), but with no definite schedule. > > Also if the issue is "multi-tenant Hadoop.”, I would first try to better > assign resources in the cluster, using for example CGroups via > yarn/lxc/docker, or virtual machines. > > Cheers, Piotrek > > On 10 Oct 2019, at 16:02, Owen Rees-Hayward <owe...@googlemail.com> wrote: > > Hi Piotr, > > Thanks for getting back to me and for the info. I try to describe the > motivation around the scenarios in the original post in the series - see > the 'Backpressure - why you might care' section on > http://owenrh.me.uk/blog/2019/09/30/. Maybe it could have been clearer. > > As you note, this will not affect every Flink job. However, one persons > niche is another persons day job. I definitely agree that keyed network > exchanges, which is going to the majority of analytics queries, are in a > different problem space. However, this is not an uncommon scenario in > ingest pipelines. > > I'd be interested to know whether you saw the section in the post I > referred to above and whether this clears anything up? To clarify, the code > is attempting to simulate a straggler node due to high load, > which therefore processes data at a slower rate - not a failing node. Some > degree of this is a feature of multi-tenant Hadoop. > > Cheers, Owen > > On Thu, 10 Oct 2019 at 10:27, Piotr Nowojski <pi...@ververica.com> wrote: > >> Hi, >> >> I’m not entirely sure what you are testing. I have looked at your code >> (only the constant straggler scenario) and please correct me if’m wrong, in >> your job you are basically measuring throughput of >> `Thread.sleep(straggler.waitMillis)`. >> >> In the first RichMap task (`subTaskId == 0`), per every record you do the >> sleep(50ms), so after filling in all of the network buffers your whole job >> will be bottlenecked by this throughput cap of 20 records / second. Every >> so often when this struggling task will be able to process and free up some >> buffer from the backlog. This briefly unblocks other three tasks (which are >> capped at 133 records / second). Apart from those short stints, those other >> tasks can not process constant 133 records / seconds, because records are >> evenly distributed by the source between all of those tasks. Which is I >> think clearly visible on the charts and every system would behave in >> exactly the same way. >> >> But what scenario are you really trying to simulate? >> >> A data skew when one task is 6.65 (133 / 20 ) times more >> overloaded/processing heavier records than the others? Yes, this is >> expected behaviour, but your benchmark is testing this in a bit convoluted >> way. >> >> A failing machine which has 6.65 times less performance? With keyed >> network exchanges there is again very little that you can do (except of the >> speculative execution). Without keyed network exchanges, OK, I agree. In >> this case, randomly/evenly distributing the records is not the optimal >> shuffling strategy and there is some room for the improvement in Flink (we >> could distribute records not randomly but to the less busy machines). >> However this is a pretty much niche feature (failing machine + non keyed >> exchanges) and you are not saying anywhere that this is what you are >> testing for. >> >> Piotrek >> >> On 8 Oct 2019, at 18:10, Owen Rees-Hayward <owe...@googlemail.com> wrote: >> >> Hi, >> >> I am having a few issues with the Flink (v1.8.1) backpressure default >> settings, which lead to poor throughput in a comparison I am doing between >> Storm, Spark and Flink. >> >> I have a setup that simulates a progressively worse straggling task that >> Storm and Spark cope with the relatively well. Flink not so much. Code can >> be found here - https://github.com/owenrh/flink-variance. >> >> See this throughput chart for the an idea of how badly - >> https://owenrh.me.uk/assets/images/blog/smackdown/flink-constant-straggler.png >> >> I do not have any production experience with Flink, but I have had a look >> at the Flink docs and there is nothing in there that jumps out at me to >> explain or address this. I presume I am missing something, as I cannot >> believe Flink is this weak in the face of stragglers. It must be >> configuration right? >> >> Would appreciate any help on this. I've got a draft blog post that I will >> publish in a day or two, and don't want to criticise the Flink backpressure >> implementation for what seems most likely some default configuration issue. >> >> Thanks in advance, Owen >> >> -- >> Owen Rees-Hayward >> 07912 876046 >> twitter.com/owen4d >> >> >> > > -- > Owen Rees-Hayward > 07912 876046 > twitter.com/owen4d > > > -- Owen Rees-Hayward 07912 876046 twitter.com/owen4d
{kind=link}