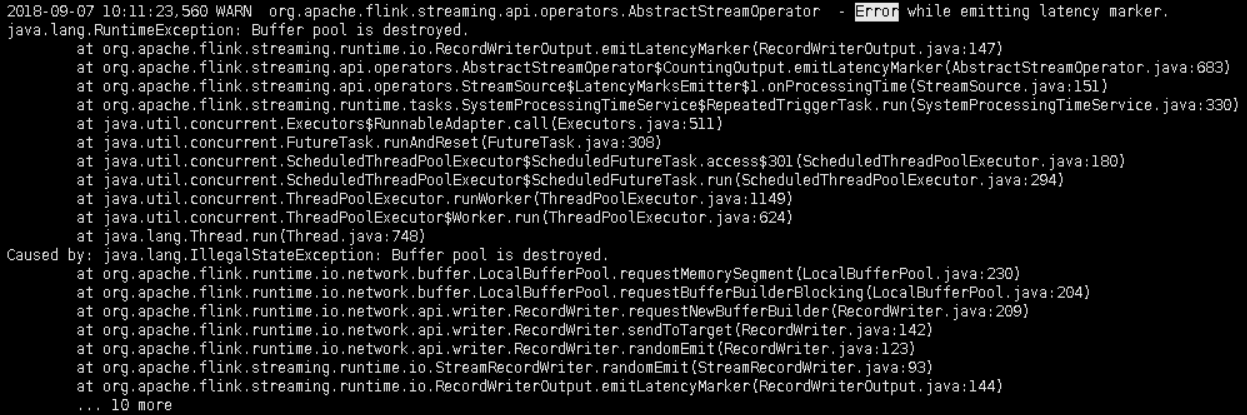
Hi all, I am encountering a weird problem when running flink 1.6 in yarn per-job clusters. The job fails in about half an hour after it starts. Related logs is attached as an imange.
This piece of log comes from one of the taskmanagers. There are not any other related log lines. No ERROR-level logs. The job just runs for tens of minutes without printing any logs and suddenly throws this exception. It is reproducable in my production environment, but not in my test environment. The 'Buffer pool is destroed' exception is always thrown while emitting latency marker.
![]() image.png
image.png
Description: Binary data
{kind=link}