my 2 cents: First of all create the public testing case/repository focused on this problem e.g. different font families, font size, shot text (like 0swZuoU.png), long text, etc. This could be used for finding problems/bugs, evaluating possible solutions, maybe (re)training. So synthetic data imitating real-world cases are fine. I would suggest focusing on the most common fonts as used on different platforms (e.g. on Windows Arial, Times New Roman, Courier New, Calibri, Cambria, Consolas, Segoe UI on Linux probably DejaVu, Liberation, Ubuntu, not sure about Mac&IOS ;-) I would suggest using column or paragraph style for input image (e.g to avoid problems with document layout analysis like tables, header, footer..)
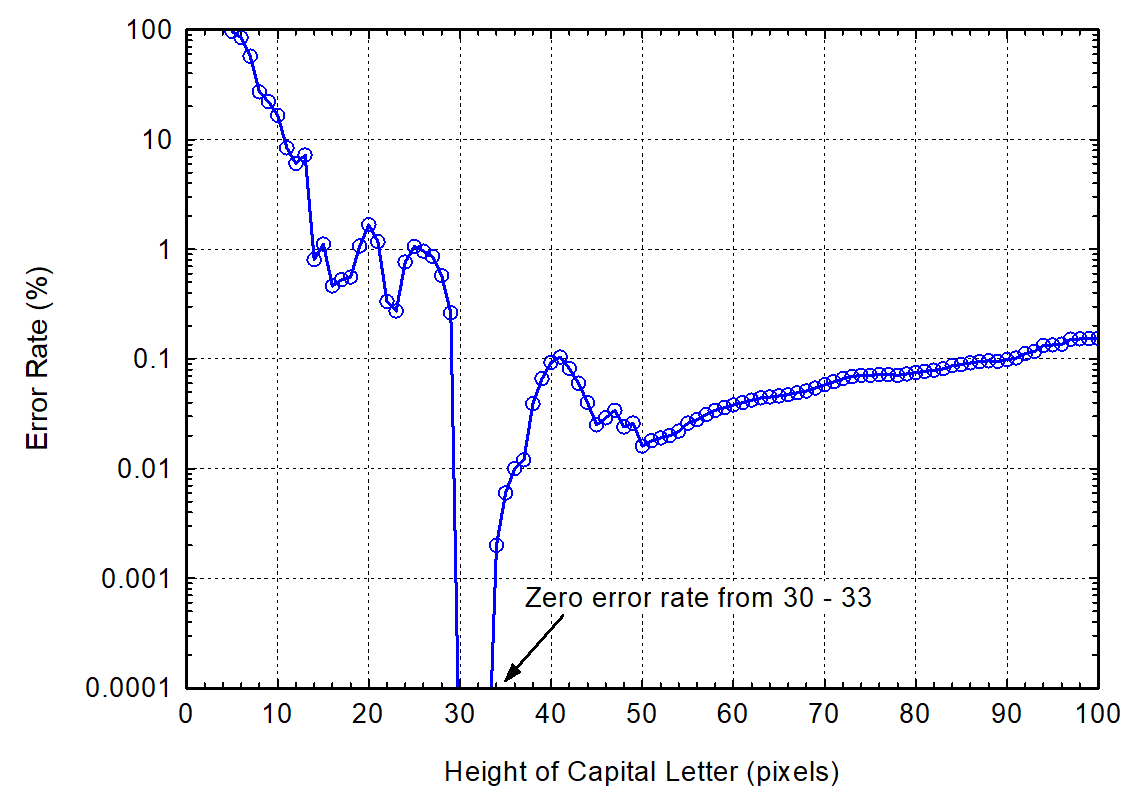
Zdenko ne 27. 2. 2022 o 14:36 Chris McClelland <[email protected]> napísal(a): > So I did a similar analysis to Willus (see link posted by Zdenko), > downscaling the images to try a range of heights for digits. Unfortunately > my result is not as nice as Willus's (where he finds that the error rate > drops to zero for capital-letter heights of 30-33 pixels). In my case I > have 336 images each containing a column of ~30 #### numbers (dataset T) > and 336 images each containing a column of ~30 #.# numbers (dataset D). > > The error rate for D seems to tend to zero for larger digit-heights (i.e > more pixels) - the most common errors for smaller sizes seem to be missing > the decimal point, e.g getting input "1.2" and producing output "12". To > eliminate those errors, I need digits about 92 pixels high. > > The error rate for T is more complex. It has a broad trough in the > digit-height range 20-48 pixels, with several points (20,32,38) with a > perfect score, but no obvious range which produces a perfect score. > > Perhaps I could train it myself? Is 336*30*4 ~ 40,000 digits of training > data enough to get meaningful results with OCR? > > Chris > > On Sunday, 27 February 2022 at 13:23:09 UTC zdenop wrote: > >> I do not know. The trick with upscaling is here from version 3.x. The >> trick with downscaling works from version 4.x >> Just looking at Willus Dotkom's chart[1] I would guess there is some >> design decision... But without explanation from original/google >> programmers, we can just guess or find a bug ;-) >> >> [1] >> https://groups.google.com/group/tesseract-ocr/attach/51b840d4782db/tess4_error_rate.png?part=0.2&view=1 >> >> >> Zdenko >> >> >> ne 27. 2. 2022 o 11:27 Merlijn B.W. Wajer <[email protected]> >> napísal(a): >> >>> Hi, >>> >>> On 27/02/2022 08:55, Zdenko Podobny wrote: >>> > tesseract fix_size.png - >>> > >>> > 0326 >>> > 0939 >>> > 1552 >>> > 2206 >>> > >>> > >>> > See doc for explaining: >>> > >>> https://github.com/tesseract-ocr/tessdoc/blob/main/ImproveQuality.md#rescaling >>> > < >>> https://github.com/tesseract-ocr/tessdoc/blob/main/ImproveQuality.md#rescaling >>> > >>> >>> Thanks for the suggestion, I'm also running into this problem in some >>> cases. Is it possible that this is also some kind of segmentation bug? I >>> wonder what Tesseract finds here in this clear image that causes it to >>> produce an extra character. >>> >>> Regards, >>> Merlijn >>> >>> -- >>> You received this message because you are subscribed to the Google >>> Groups "tesseract-ocr" group. >>> To unsubscribe from this group and stop receiving emails from it, send >>> an email to [email protected]. >>> >> To view this discussion on the web visit >>> https://groups.google.com/d/msgid/tesseract-ocr/2435ccff-11e1-0848-6d57-600a4262d963%40archive.org >>> . >>> >> -- > You received this message because you are subscribed to the Google Groups > "tesseract-ocr" group. > To unsubscribe from this group and stop receiving emails from it, send an > email to [email protected]. > To view this discussion on the web visit > https://groups.google.com/d/msgid/tesseract-ocr/33bd80fb-ece5-434c-a44a-84750b416c93n%40googlegroups.com > <https://groups.google.com/d/msgid/tesseract-ocr/33bd80fb-ece5-434c-a44a-84750b416c93n%40googlegroups.com?utm_medium=email&utm_source=footer> > . > -- You received this message because you are subscribed to the Google Groups "tesseract-ocr" group. To unsubscribe from this group and stop receiving emails from it, send an email to [email protected]. To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAJbzG8yLmYQ27k0A4ctFGB%3Dz-chfn%2BXAne7gJyeLfJ%2Bvond8Ew%40mail.gmail.com.
{kind=link}