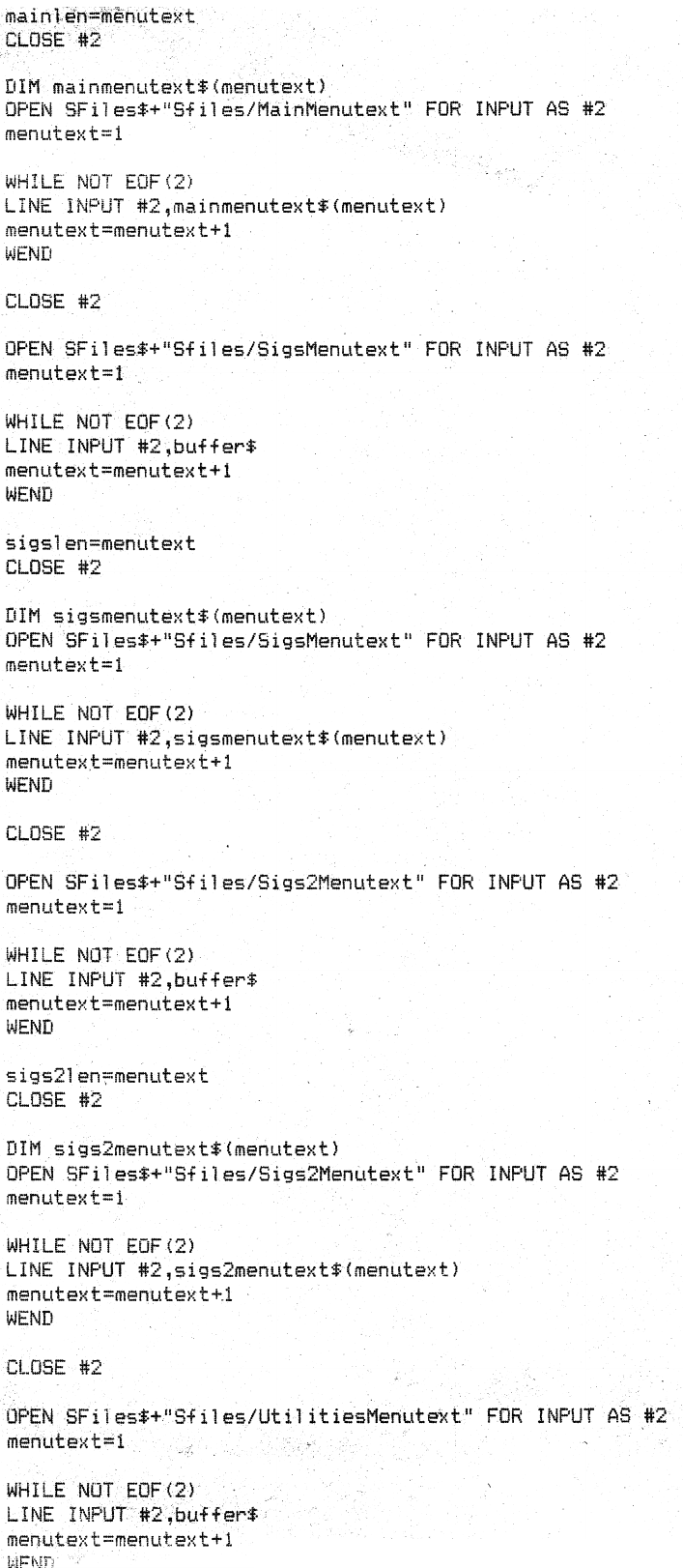
Another technique specifically for dot-matrix might be to blend multiple copies of the scan at small offsets. The idea here is that back in the old days of dot matrix, a few DTP applications had printing modes which would print dot patterns several times on the same line, but ever so slightly offset from one another to 'fill the character up'. The poor man's way to print BOLD characters that way was to print the same line multiple times at slight offsets.
Hence to simulate this sort of 'gap closing', one could scan at higher resolution, then offset the image multiple times in various directions by "half a printer dot" (or less) and blend the copies using a blending mode like Photoshop Darken. If # is a *pixel* in the image scan (which should be much small that a dot matrix printer dot), possible patterns to try to fatten & fill the print are: XXX X X X#X or # XXX X X where X is the # pixel, now offset in various directions. The first example would thus take 8 copies and the second 4. Combine this with other image processing to get a better filled-out character. If that doesn't work, there's also the option of training the dot matrix matrix, but I haven't done that sort of thing yet, so can't help you there. Search this mailing list for multiple questions and answers re custom font training to improve results. Met vriendelijke groeten / Best regards, Ger Hobbelt -------------------------------------------------- web: http://www.hobbelt.com/ http://www.hebbut.net/ mail: g...@hobbelt.com mobile: +31-6-11 120 978 -------------------------------------------------- On Fri, Jan 1, 2021 at 9:18 PM Alex Santos <santos.pol...@gmail.com> wrote: > HI Keith > > Interesting project. > > On the why hi res would yield poorer results. As you know, dot matrix > printer character output was a series of rows and columns (a grid of > circles) to render text and characters. As you scan these prints at higher > resolutions those otherwise indistinct individual dots become isolated from > the others dots and begin to appear as individual objects by the OCR > engine. To overcome this you might need to preprocess the scanned images > with some image editing software to find a sweet spot. I would probably > start by doing a high contrast medium resolution scan, then add some > gaussian blue to effectively marry the dots into a continuous shape, rather > than individual dots and then use some leveling tool to tighten the soft > blur around the edges. This will bring back some sharpness. You really need > to experiment with a 150ppi scan and from there explore a sequence of image > manipulations that can essentially eliminate the gaps (the white) between > the dots. Blending them together will reduce OCR from confusing what it > might interpret as white space. So creating a continuous path of black will > allow OCR to know what is ink and what is not. > > Googling "ocr dot matrix prints" without quotes yielded some interesting > results. Some have explored this more deeply than I. > > I attached a zip file with two tests based on the sample image you > provided. I didn't get a good chance to make all the comparisons but I > created a PNG with some gaussian blur and then contracting the levels gave > me what appear to be decent results. I also scaled the processed image to > 200% and saved it as a TIF. > > I used the following command to generate the sidecar text file and PDFs. > > ocrmypdf -v --output-type pdfa-3 --image-dpi 300 --optimize 0 > --jpeg-quality 100 --pdfa-image-compression lossless --sidecar text.txt > /Users/admin/Desktop/FNBBS/FNBBS-02_crop\ copy.png test.pdf > On Monday, December 14, 2020 at 7:41:00 AM UTC+1 Keith M wrote: > >> Hi there, >> >> I've been circling a problem with OCR'ing 90-pages of 30 year old BASIC >> code. I've been working on optimizing my scanning settings, and >> pre-processing, stuck in photoshop for hours messing around. Long couple >> days with this stuff! >> >> I've been through tessdoc, through the FAQ, through wikipedia reading >> about morphological operators. Through PPAs for 5.0.0-alpha-833-ga06c. >> >> I'm getting OK results so far, but need to process more images, my >> workflow is tedious. >> >> Sample image here >> https://www.techtravels.org/wp-content/uploads/2020/12/FNBBS-02_crop.png >> >> 150dpi image extracted via pdftoppm -png from a 1200dpi scan. While it's >> not super clear to me why, higher res scans are resulting in WORSE OCR's. >> >> *TLDR; What should be the ideal configuration of tesseract for my >> application? Disable the dictionary? Can I add BASIC commands and keywords >> to eng.user-words? From the manual "CONFIG FILES AND AUGMENTING WITH USER >> DATA" section ??* >> >> I could use some help, thanks! >> >> Keith >> >> -- > You received this message because you are subscribed to the Google Groups > "tesseract-ocr" group. > To unsubscribe from this group and stop receiving emails from it, send an > email to tesseract-ocr+unsubscr...@googlegroups.com. > To view this discussion on the web visit > https://groups.google.com/d/msgid/tesseract-ocr/1f0015f6-96ae-4ec7-812f-482dac337f92n%40googlegroups.com > <https://groups.google.com/d/msgid/tesseract-ocr/1f0015f6-96ae-4ec7-812f-482dac337f92n%40googlegroups.com?utm_medium=email&utm_source=footer> > . > -- You received this message because you are subscribed to the Google Groups "tesseract-ocr" group. To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-ocr+unsubscr...@googlegroups.com. To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAFP60foE22ip_KQhMVG%2BqSK81EkLZefLBxTcoJjmC5i1eqU%3D5g%40mail.gmail.com.
{kind=link}