Closed #4969.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/apache/incubator-tvm/issues/4969#event-3437024852
This feature is now supported in TVM.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/apache/incubator-tvm/issues/4969#issuecomment-643081334
@zhanghaohit It's still under investigation for different options, but it's
more likely a static shape will fall into a bucket and calling corresponding
kernel.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github
Thanks @zhiics and @FrozenGene . We have the Keras example with TVMDSOOp as
well and we will update the document in google docs later which may help to
review.
---
[Visit Topic](https://discuss.tvm.ai/t/add-the-document-for-tvmdsoop/6622/6) to
respond.
You are receiving this because you
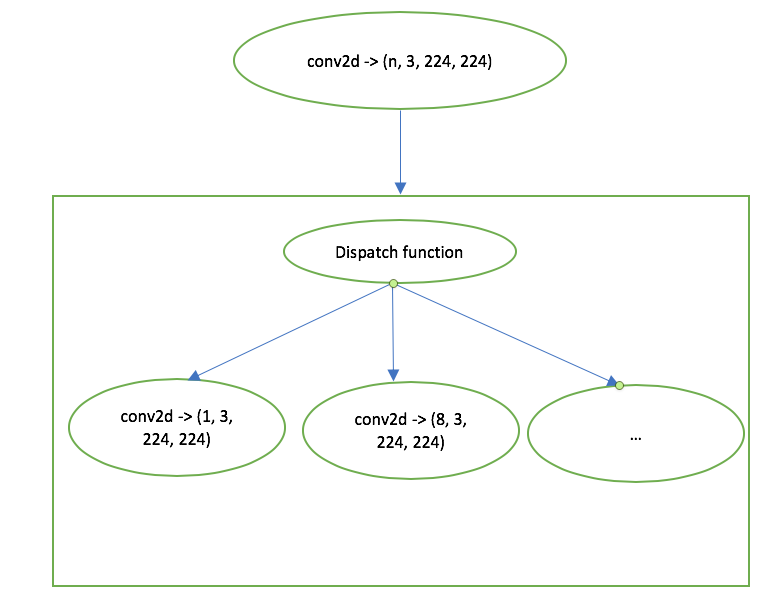
> > 
>
> I'm still curious what will happen if we have conv2d(5, 3, 224, 224)? We'll
> use conv2d(8, 3, 224, 224)? Do we need to do some padding to use the kernel
> conv2d(8, 3, 2
To keep things simple, we can disallow symbolic var in attributes and force
attributes to be constant, so if the var is symbolic dependent, we should use
the dyn variant.
---
[Visit Topic](https://discuss.tvm.ai/t/dynamic-ops-in-relay/6909/13) to respond.
You are receiving this because yo
I'm also in favor of A1 approach. I have one more question to dynamic ops.
Currently Relay allows to use symbolic var to represent a dimension. In the
world of A1, if attributes contains a symbolic var, such as new shape in
`reshape`, are we treating the op as a dynamic op or static op?
-
Agree to make `float32` as the default and throw a warning if `float` is given
without specifying the bit number. On the other hand, simply putting the
warning at a lower level may not be effective. I believe most users do not
change the log level during the development. I would prefer the way
Yah I agree with @tqchen and @mbrookhart because float is probably arch
dependent, which is not desirable in most cases. Also, there might be a lot of
uses of Float in the frontend, like importer from PyTorch, so we might have to
keep the warning level low.
---
[Visit
Topic](https://disc
+1 for making fp32 as default as fp64 may not be that useful and it could
possibly increase memory footprint and reduce performance (i.e. occupying more
SIMD lanes).
I also agree that we can make float more explicit.
---
[Visit
Topic](https://discuss.tvm.ai/t/discuss-the-meaning-of-float
I agree with @tqchen that making `float` throw a warning is a good option,
it's an ambiguous declaration, even in C, it means different things on
different systems and in different contexts. Being more precise is probably
better.
---
[Visit
Topic](https://discuss.tvm.ai/t/discuss-the-me
Any thoughts about disambiguate and force given users a warning when `float` is
used(and ask them to use `float32` or `float64`?
---
[Visit
Topic](https://discuss.tvm.ai/t/discuss-the-meaning-of-float-in-relay/6949/7)
to respond.
You are receiving this because you enabled mailing list mo
I think fp32 makes sense, the problem is that NumPy defaults are arch. specific
and on 32-bit platforms the default sizing for both integers ("int") and
floating point ("float") are different. A problem that has plagued us
repeatedly. The behavior of `const` iirc is trying to normalize away th
Agree with @junrushao1994. I think we should use fp32 as default instead of
fp64 as it's more common in deep learning.
---
[Visit
Topic](https://discuss.tvm.ai/t/discuss-the-meaning-of-float-in-relay/6949/5)
to respond.
You are receiving this because you enabled mailing list mode.
To un
The problem is whether we want to be 100% numpy compatible.
As far as I could understand, the goal and benefit of being XXX-compatible is
to bring convenience to end users who is familiar with XXX.
As in this case, as a deep learning compiler stack, or any other DL framework,
fp32 is used as
CC: @antinucleon as well
---
[Visit
Topic](https://discuss.tvm.ai/t/discuss-the-meaning-of-float-in-relay/6949/3)
to respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [click
here](https://discuss.tvm.ai/email/unsubscribe/78aa01a8d44
cc @jroesch @zhiics @comaniac @liangfu @junrushao1994
---
[Visit
Topic](https://discuss.tvm.ai/t/discuss-the-meaning-of-float-in-relay/6949/2)
to respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [click
here](https://discuss.tvm.ai/
Hi,
so here is something I bumped into: `"float"` means different things in
different places, not always as expected.
The background is that C/C++, PyTorch, and others will interpret float to mean
32 bit floating point numbers aka float32 and arguably float32 is the most
common datatype in de
yeah, I thought about positional ordering as well. But it looks pass variables
might be safer. For a CSourceModule external codegen we generate a wrapper like
`float* a = const_0;` `const_0` would need to be produced by the initializer
later. So we would anyway need a name for it.
---
[Vi
Yah, I think it is fair to pass in names of each variable. Another way is to
rely on the positional ordering of the constant themselves(so the variable name
is implicit).
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/30) to
respond.
You are receiving
BTW, we will need to have the variables as well, i.e. %x1, %x2, %x3, something
as I mentioned above. This is because we need to know which variable a ndarray
should be assigned to.
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/29) to
respond.
You are
Yeah, let me give it a try.
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/28) to
respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [click
here](https://discuss.tvm.ai/email/unsubscribe/5b20458f6a
Do you think if it is possible to do C1? since it reduces the requirement for
passing Map
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/27) to
respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [c
Unfortunately I'm not able to reproduce in a docker right now. I'll update here
if I find a way to reproduce it
---
[Visit
Topic](https://discuss.tvm.ai/t/conflict-with-xgboost-when-thrust-is-enabled/6889/4)
to respond.
You are receiving this because you enabled mailing list mode.
To un
Yeah, I would prefer C1 or C2. C2 was pretty much what I was doing.
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/26) to
respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [click
here](https://dis
Also @liangfu Thanks for agreeing, I gave you a 15 minute slot on the agenda
(but we should be flexible for shorter or longer).
Here's the timezone conversions for next week if that helps people as well:

https://everytimezone.com/s
Thanks everyone for the great feedback on here and the agenda. Please [register
for the event here ahead of
time](https://us02web.zoom.us/meeting/register/tZ0pduyvrT4sGNFSF1LTMn9kW8S953ufskKR).
A recording will be uploaded to the OctoML Youtube channel immediately
afterwards as we did last ti
Hi @FrozenGene ,
I gave it another go, but switching legalization on the strategy seems very
hard (since we would need the auto-tuner to pick the best data-type for us).
So for now, we have to content with the `_alter_conv2d_layout` workaround and
try to think a bit more on how we can infer th
cc @FrozenGene as it is also related to module exportation format
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/25) to
respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [click
here](https://discu
Indeed it is a tradeoff, and in this case there can certainly be multiple
choices. The key problem we want to answer is how do we want to expose pass
"symbol" of meta data to each engine. This is an important topi as it can
affect the serialization convention of our future packages, let us thi
Yeah, I think I didn't make it very clear. The problem was because we may have
multiple subgraphs, each of them may have "var_name: NDarray" pairs. I was
trying to just have one `ModuleInitWrapper` to take charge of the
initialization of engines for all subgraphs so that users don't need to
o
Would Array of NDArray be sufficient?
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/22) to
respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from these emails, [click
here](https://discuss.tvm.ai/email/unsubscribe
Hi @elnaz92
Thanks for your interest. Yes, we've tested some models, e.g., Resnet_XX.
Currently we're using Intel A10. The performance on Cloud FPGA is much better
than Edge FPGA (e.g., ultra96), as we have more resources to enlarge the GEMM
core size. We're still doing much performance opt
Thank you @zhanghaohit.
In one of your posts above you mentioned that you have implemented theproposal.
Have you tested it with some models? which fpga board you used? what are the
performance numbers compared to vta on fpga soc? Is your code available in a
repo somewhere? I really like to te
> Hi @FrozenGene ,
> I agree that different strategies should be available to the auto-tuner. See
> if the solution proposed is good enough for you (at least as a temporary
> work-around). For Armv7-A or NCHW, nothing changes, we follow exactly the
> previous path.
>
> For Armv8-A and NHWC we d
I agree with @zhiics. Official tutorial is important. Besides @zhiics's
content, we could also list one example how to integrate it with one tensorflow
model end to end, not just the low level `tvm.build`. This will be the common
situation the users want to use.
---
[Visit Topic](https:
Hi @FrozenGene ,
I agree that different strategies should be available to the auto-tuner. See if
the solution proposed is good enough for you (at least as a temporary
work-around). For Armv7-A or NCHW, nothing changes, we follow exactly the
previous path.
For Armv8-A and NHWC we don't convert
@giuseros I suddenly think of auto scheduler will have one environment value.
So the change of legalization won't affect auto scheduler. We could check the
value of this environment value for auto scheduler and use `smlal`. However,
this problem I think we still should resolve that we should ha
> So I mean to add a `convert_data_type` pass that is similar to
> `alter_op_layout` but converts datatype (and we can do something like `if
> topi_impl == 'spatial_nhwc' converts to int16`.
I think this is one interesting pass. Like we have `_alter_op_layout` and will
have different logic for
So I mean to add a `convert_data_type` pass that is similar to
`alter_op_layout` but converts datatype (and we can do something like `if
topi_impl == 'spatial_nhwc' converts to int16`.
This doesn't seem possible directly in the `alter_op_layout` because only the
shapes are passed to that funct
> Hi @FrozenGene ,
>
> The idea of adding the algorithm name to the attributes would work if the
> legalization step was run after we pick the strategy. It is instead run
> before, so it is unaware of the strategy picked.
>
>
>
> Maybe we could add a new pass that runs based on the strategy?
Hi @FrozenGene ,
The idea of adding the algorithm name to the attributes would work if the
legalization step was run after we pick the strategy. It is instead run before,
so it is unaware of the strategy picked.
Maybe we could add a new pass that runs based on the strategy? Or we can hack
in `
> 1. It will be hard to do this. The point is that the legalization is done in
> Relay before picking the strategy (thus, it is unaware of the strategy
> picked). To keep both legalizations I need somehow to pass information from
> the strategy (e.g., the name of the algorithm, or something like
Hi @FrozenGene
Just to clarify: I am enjoying the discussion, and since the optimization space
is wild, I agree that is worth valuating different approaches.
* About the Raspberry+mobilenet v2, good to know you are working on Armv8-A
(sorry to have assumed otherwise). However, there is still th
Currently there is no way to initialize the output tensor of a reduction with
another Tensor.
One use case for such a functionality is when we have a fused **convolution
with bias-add** operation. Currently define 2 compute operations, where the
first one defines the reduction in the convolu
Hi @FrozenGene ,
About the code changes.
1) It will be hard to do this. The point is that the legalization is done in
Relay before picking the strategy (thus, it is unaware of the strategy picked).
To keep both legalizations I need somehow to pass information from the strategy
(e.g., the name o
Glad to see we have the same thought we should let autotvm select the best.
Autoscheduler reley on the legalization pass to generate smlal inst(After auto
scheduler is released, let us make it better together.) One information I
missed before, my testing rasp 3b+ os is Ubuntu 64 bits, not 32 bit
Hi @FrozenGene ,
Thanks a lot for your comments. I will address general replies here, and code
comments in a separate reply.
* I indeed read your discuss
[post](https://discuss.tvm.ai/t/tflite-and-tvm-comparison-for-quantized-models/6577/4),
but I thought the work was orthogonal to this one. M
Another alternate might be having a compilation flag to indicate whether to put
this hash map into runtime
---
[Visit
Topic](https://discuss.tvm.ai/t/byoc-runtime-json-runtime-for-byoc/6579/21) to
respond.
You are receiving this because you enabled mailing list mode.
To unsubscribe from
49 matches
Mail list logo