Re: [PR] [FLINK-36694][Filesystems] Update Hadoop for filesystems to 3.4.1 [flink]
davidradl commented on PR #26046: URL: https://github.com/apache/flink/pull/26046#issuecomment-2606698870 I am wondering what the story is for master as this is against 120? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[PR] [FLINK-37138][sql-gateway] Fix failed SqlYARNApplicationITCase in hadoop3 profile [flink]
fsk119 opened a new pull request, #26050: URL: https://github.com/apache/flink/pull/26050 ## What is the purpose of the change *YARN deployment doesn't the directories as flink-dist does. Actually, it uses the following structures* ``` . └── ohmeatball ├── appcache │ └── application_1737534562065_0001 │ ├── container_1737534562065_0001_01_01 │ │ ├── lib │ │ ├── opt │ │ ├── plugins │ │ │ ├── external-resource-gpu │ │ │ ├── metrics-datadog │ │ │ ├── metrics-graphite │ │ │ ├── metrics-influx │ │ │ ├── metrics-jmx │ │ │ ├── metrics-otel │ │ │ ├── metrics-prometheus │ │ │ ├── metrics-slf4j │ │ │ └── metrics-statsd │ │ └── tmp │ └── filecache │ ├── 10 └── filecache ``` Actually the config.yaml is at the working directory(container_1737534562065_0001_01_01). So sql-gateway should not load the conf from the `$FLINK_CONF_DIR`. Considering `YarnApplicationClusterEntryPoint` or `KubernetesApplicationClusterEntrypoint` boths read the conf and put its content in the `StreamExecutionEnvironment`, we just get the conf from `StreamExecutionEnvironment`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-35139][Connectors/MongoDB] Drop support for Flink 1.18 and update development version to 2.0-SNAPSHOT [flink-connector-mongodb]
Jiabao-Sun commented on PR #48: URL: https://github.com/apache/flink-connector-mongodb/pull/48#issuecomment-2606702143 Hi @leonardBang, could you help review this? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [hotfix][docs] Fix dead links in Doris [flink-cdc]
ruanhang1993 merged PR #3878: URL: https://github.com/apache/flink-cdc/pull/3878 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-37138) testDeployScriptViaSqlClient failed on AZP
[
https://issues.apache.org/jira/browse/FLINK-37138?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-37138:
---
Labels: pull-request-available (was: )
> testDeployScriptViaSqlClient failed on AZP
> --
>
> Key: FLINK-37138
> URL: https://issues.apache.org/jira/browse/FLINK-37138
> Project: Flink
> Issue Type: Bug
> Components: Build System / CI
>Affects Versions: 2.0.0
>Reporter: Weijie Guo
>Assignee: Shengkai Fang
>Priority: Blocker
> Labels: pull-request-available
>
> {code:java}
> Jan 15 02:46:21 02:46:21.564 [ERROR]
> org.apache.flink.yarn.SqlYARNApplicationITCase.testDeployScriptViaSqlClient
> -- Time elapsed: 19.03 s <<< FAILURE!
> Jan 15 02:46:21 java.lang.AssertionError: Application became FAILED or KILLED
> while expecting FINISHED
> Jan 15 02:46:21 at
> org.apache.flink.yarn.YarnTestBase.waitApplicationFinishedElseKillIt(YarnTestBase.java:1286)
> Jan 15 02:46:21 at
> org.apache.flink.yarn.SqlYARNApplicationITCase.runSqlClient(SqlYARNApplicationITCase.java:152)
> Jan 15 02:46:21 at
> org.apache.flink.yarn.YarnTestBase.runTest(YarnTestBase.java:304)
> Jan 15 02:46:21 at
> org.apache.flink.yarn.SqlYARNApplicationITCase.testDeployScriptViaSqlClient(SqlYARNApplicationITCase.java:85)
> Jan 15 02:46:21 at
> java.base/java.lang.reflect.Method.invoke(Method.java:566)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:290)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinPool$WorkQueue.topLevelExec(ForkJoinPool.java:1020)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinPool.scan(ForkJoinPool.java:1656)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1594)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:183)
> Jan 15 02:46:21
> {code}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=65324&view=logs&j=245e1f2e-ba5b-5570-d689-25ae21e5302f&t=d04c9862-880c-52f5-574b-a7a79fef8e0f&l=26610
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] (FLINK-37138) testDeployScriptViaSqlClient failed on AZP
[ https://issues.apache.org/jira/browse/FLINK-37138 ]
Shengkai Fang deleted comment on FLINK-37138:
---
was (Author: fsk119):
[~Weijie Guo] Please use the origin issue to track the same problem
> testDeployScriptViaSqlClient failed on AZP
> --
>
> Key: FLINK-37138
> URL: https://issues.apache.org/jira/browse/FLINK-37138
> Project: Flink
> Issue Type: Bug
> Components: Build System / CI
>Affects Versions: 2.0.0
>Reporter: Weijie Guo
>Assignee: Shengkai Fang
>Priority: Blocker
> Labels: pull-request-available
>
> {code:java}
> Jan 15 02:46:21 02:46:21.564 [ERROR]
> org.apache.flink.yarn.SqlYARNApplicationITCase.testDeployScriptViaSqlClient
> -- Time elapsed: 19.03 s <<< FAILURE!
> Jan 15 02:46:21 java.lang.AssertionError: Application became FAILED or KILLED
> while expecting FINISHED
> Jan 15 02:46:21 at
> org.apache.flink.yarn.YarnTestBase.waitApplicationFinishedElseKillIt(YarnTestBase.java:1286)
> Jan 15 02:46:21 at
> org.apache.flink.yarn.SqlYARNApplicationITCase.runSqlClient(SqlYARNApplicationITCase.java:152)
> Jan 15 02:46:21 at
> org.apache.flink.yarn.YarnTestBase.runTest(YarnTestBase.java:304)
> Jan 15 02:46:21 at
> org.apache.flink.yarn.SqlYARNApplicationITCase.testDeployScriptViaSqlClient(SqlYARNApplicationITCase.java:85)
> Jan 15 02:46:21 at
> java.base/java.lang.reflect.Method.invoke(Method.java:566)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:290)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinPool$WorkQueue.topLevelExec(ForkJoinPool.java:1020)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinPool.scan(ForkJoinPool.java:1656)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1594)
> Jan 15 02:46:21 at
> java.base/java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:183)
> Jan 15 02:46:21
> {code}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=65324&view=logs&j=245e1f2e-ba5b-5570-d689-25ae21e5302f&t=d04c9862-880c-52f5-574b-a7a79fef8e0f&l=26610
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[PR] [FLINK-37138][sql-gateway] Fix failed SqlYARNApplicationITCase in hadoop3 profile [flink]
fsk119 opened a new pull request, #26049: URL: https://github.com/apache/flink/pull/26049 ## What is the purpose of the change *YARN deployment doesn't the directories as flink-dist does. Actually, it uses the following structures* ``` . └── ohmeatball ├── appcache │ └── application_1737534562065_0001 │ ├── container_1737534562065_0001_01_01 │ │ ├── lib │ │ ├── opt │ │ ├── plugins │ │ │ ├── external-resource-gpu │ │ │ ├── metrics-datadog │ │ │ ├── metrics-graphite │ │ │ ├── metrics-influx │ │ │ ├── metrics-jmx │ │ │ ├── metrics-otel │ │ │ ├── metrics-prometheus │ │ │ ├── metrics-slf4j │ │ │ └── metrics-statsd │ │ └── tmp │ └── filecache │ ├── 10 └── filecache ``` Actually the config.yaml is at the working directory(container_1737534562065_0001_01_01). So sql-gateway should not load the conf from the `$FLINK_CONF_DIR`. Considering `YarnApplicationClusterEntryPoint` or `KubernetesApplicationClusterEntrypoint` boths read the conf and put its content in the `StreamExecutionEnvironment`, we just get the conf from `StreamExecutionEnvironment`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-37198) AvroToRowDataConverters factory omits legacyTimestampMapping option for nested Row.
Juliusz Nadberezny created FLINK-37198:
--
Summary: AvroToRowDataConverters factory omits
legacyTimestampMapping option for nested Row.
Key: FLINK-37198
URL: https://issues.apache.org/jira/browse/FLINK-37198
Project: Flink
Issue Type: Bug
Components: API / Type Serialization System
Affects Versions: 1.20.0
Reporter: Juliusz Nadberezny
A{{{}vroToRowDataConverters#createRowConverter{}}} method skips
legacyTimestampMapping option when defining nested {{Row}} converter.
The problem is in the following line:
[https://github.com/apache/flink/blob/533ead6ae946cbc77525d276b6dea965d390181a/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/AvroToRowDataConverters.java#L149]
It should be:
{{createRowConverter((RowType) type, legacyTimestampMapping)}}
Instead of:
{{createRowConverter((RowType) type)}}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
Re: [PR] mention scylladb in docs [flink-connector-cassandra]
guy9 commented on PR #32: URL: https://github.com/apache/flink-connector-cassandra/pull/32#issuecomment-2606881550 Also interested in this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-37201) FlinkCDC Pipeline transform arithmetic functions support parameters of null and more numerical types.
[ https://issues.apache.org/jira/browse/FLINK-37201?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Wenkai Qi updated FLINK-37201: -- Description: FlinkCDC Pipeline transform arithmetic functions can not support parameters of null and more numerical types. For example: ceil, floor, round and abs. When the input parameter is null or a numerical type such as int, the program will have an error. I have fixed it. > FlinkCDC Pipeline transform arithmetic functions support parameters of null > and more numerical types. > - > > Key: FLINK-37201 > URL: https://issues.apache.org/jira/browse/FLINK-37201 > Project: Flink > Issue Type: Improvement > Components: Flink CDC >Affects Versions: cdc-3.3.0 >Reporter: Wenkai Qi >Priority: Major > Original Estimate: 24h > Remaining Estimate: 24h > > FlinkCDC Pipeline transform arithmetic functions can not support parameters > of null and more numerical types. For example: ceil, floor, round and abs. > When the input parameter is null or a numerical type such as int, the program > will have an error. > I have fixed it. -- This message was sent by Atlassian Jira (v8.20.10#820010)
Re: [PR] [BP-2.0][FLINK-36838][state/forst] Fix the deadlock when quit forst state backend [flink]
flinkbot commented on PR #26054: URL: https://github.com/apache/flink/pull/26054#issuecomment-2607441606 ## CI report: * 83a855a5b573f09ea590ca499b54b6410bb45478 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
ferenc-csaky commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607471427 @He-Pin That's a good point regarding cache! Probably the CI machines has less than 10 cores. I can give it a try, I just have to do a local Pekko build myself to be able to build Flink on top of it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37175][table] Support JSON built-in function for JSON_OBJECT [flink]
gustavodemorais commented on code in PR #26022:
URL: https://github.com/apache/flink/pull/26022#discussion_r1925151673
##
flink-table/flink-table-api-java/src/main/java/org/apache/flink/table/api/Expressions.java:
##
@@ -861,9 +862,13 @@ public static ApiExpression withoutColumns(Object head,
Object... tail) {
* jsonObject(JsonOnNull.ABSENT, "K1", nullOf(DataTypes.STRING())) // "{}"
*
* // {"K1":{"K2":"V"}}
+ * jsonObject(JsonOnNull.NULL, "K1", json('{"K2":"V"}'))
Review Comment:
The string doesn't have to be escaped, I've updated the javadoc for the java
expression and added one example using string literals that show that there's
no need to escape it
```
* // {"K":{"K2":{"K3":42}}}
* jsonObject(
* JsonOnNull.NULL,
* "K",
* json("""
*{
* "K2": {
*"K3": 42
* }
*}
* """))
```
We escape in the java code since java also uses `"` to express strings. If
using single quotes in python or string literals in java, there's no need to
escape. If they're escaped, they are also processed properly as well and result
in the same json object.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [FLINK-37021][state/forst] Fix incorrect paths when reusing files for checkpoints. [flink]
AlexYinHan commented on code in PR #26040:
URL: https://github.com/apache/flink/pull/26040#discussion_r1925152740
##
flink-state-backends/flink-statebackend-forst/src/main/java/org/apache/flink/state/forst/datatransfer/CopyDataTransferStrategy.java:
##
@@ -92,97 +89,85 @@ public void transferFromCheckpoint(
StreamStateHandle sourceHandle, Path targetPath, CloseableRegistry
closeableRegistry)
throws IOException {
LOG.trace("Copy file from checkpoint: {}, {}, {}", sourceHandle,
targetPath, dbFileSystem);
-copyFileFromCheckpoint(dbFileSystem, sourceHandle, targetPath,
closeableRegistry);
+copyFileFromCheckpoint(sourceHandle, targetPath, closeableRegistry);
}
@Override
public String toString() {
return "CopyDataTransferStrategy{" + ", dbFileSystem=" + dbFileSystem
+ '}';
}
-private static HandleAndLocalPath copyFileToCheckpoint(
-FileSystem dbFileSystem,
-Path filePath,
+private HandleAndLocalPath copyFileToCheckpoint(
+Path dbFilePath,
long maxTransferBytes,
CheckpointStreamFactory checkpointStreamFactory,
CheckpointedStateScope stateScope,
CloseableRegistry closeableRegistry,
CloseableRegistry tmpResourcesRegistry)
throws IOException {
-StreamStateHandle handleByDuplicating =
-duplicateFileToCheckpoint(
-dbFileSystem, filePath, checkpointStreamFactory,
stateScope);
-if (handleByDuplicating != null) {
-LOG.trace("Duplicate file to checkpoint: {} {}", filePath,
handleByDuplicating);
-return HandleAndLocalPath.of(handleByDuplicating,
filePath.getName());
+
+// Get State handle for the DB file
+StreamStateHandle sourceStateHandle;
+if (dbFileSystem instanceof ForStFlinkFileSystem) {
+// Obtain the state handle stored in MappingEntry
+// or Construct a FileStateHandle base on the source file
+MappingEntry mappingEntry =
+((ForStFlinkFileSystem)
dbFileSystem).getMappingEntry(dbFilePath);
+Preconditions.checkNotNull(mappingEntry, "dbFile not found: " +
dbFilePath);
+sourceStateHandle = mappingEntry.getSource().toStateHandle();
+if (mappingEntry.getFileOwnership() == FileOwnership.NOT_OWNED) {
+// The file is already owned by JM, simply return the state
handle
+return HandleAndLocalPath.of(sourceStateHandle,
dbFilePath.getName());
+}
+} else {
+// Construct a FileStateHandle base on the DB file
+FileSystem sourceFileSystem = dbFilePath.getFileSystem();
+long fileLength =
sourceFileSystem.getFileStatus(dbFilePath).getLen();
+sourceStateHandle = new FileStateHandle(dbFilePath, fileLength);
+}
+
+// Try path-copying first. If failed, fallback to bytes-copying
+StreamStateHandle targetStateHandle =
+tryPathCopyingToCheckpoint(sourceStateHandle,
checkpointStreamFactory, stateScope);
+if (targetStateHandle != null) {
+LOG.trace("Path-copy file to checkpoint: {} {}", dbFilePath,
targetStateHandle);
+} else {
+targetStateHandle =
+bytesCopyingToCheckpoint(
+dbFilePath,
+maxTransferBytes,
+checkpointStreamFactory,
+stateScope,
+closeableRegistry,
+tmpResourcesRegistry);
+LOG.trace("Bytes-copy file to checkpoint: {}, {}", dbFilePath,
targetStateHandle);
}
-HandleAndLocalPath handleAndLocalPath =
-HandleAndLocalPath.of(
-writeFileToCheckpoint(
-dbFileSystem,
-filePath,
-maxTransferBytes,
-checkpointStreamFactory,
-stateScope,
-closeableRegistry,
-tmpResourcesRegistry),
-filePath.getName());
-LOG.trace("Write file to checkpoint: {}, {}", filePath,
handleAndLocalPath.getHandle());
-return handleAndLocalPath;
+return HandleAndLocalPath.of(targetStateHandle, dbFilePath.getName());
}
/**
* Duplicate file to checkpoint storage by calling {@link
CheckpointStreamFactory#duplicate} if
* possible.
Review Comment:
Added params and returns in the javadoc
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
Fo
Re: [PR] [FLINK-37021][state/forst] Fix incorrect paths when reusing files for checkpoints. [flink]
AlexYinHan commented on code in PR #26040:
URL: https://github.com/apache/flink/pull/26040#discussion_r1925152164
##
flink-state-backends/flink-statebackend-forst/src/main/java/org/apache/flink/state/forst/datatransfer/CopyDataTransferStrategy.java:
##
@@ -92,97 +89,85 @@ public void transferFromCheckpoint(
StreamStateHandle sourceHandle, Path targetPath, CloseableRegistry
closeableRegistry)
throws IOException {
LOG.trace("Copy file from checkpoint: {}, {}, {}", sourceHandle,
targetPath, dbFileSystem);
-copyFileFromCheckpoint(dbFileSystem, sourceHandle, targetPath,
closeableRegistry);
+copyFileFromCheckpoint(sourceHandle, targetPath, closeableRegistry);
}
@Override
public String toString() {
return "CopyDataTransferStrategy{" + ", dbFileSystem=" + dbFileSystem
+ '}';
}
-private static HandleAndLocalPath copyFileToCheckpoint(
-FileSystem dbFileSystem,
-Path filePath,
+private HandleAndLocalPath copyFileToCheckpoint(
+Path dbFilePath,
long maxTransferBytes,
CheckpointStreamFactory checkpointStreamFactory,
CheckpointedStateScope stateScope,
CloseableRegistry closeableRegistry,
CloseableRegistry tmpResourcesRegistry)
throws IOException {
-StreamStateHandle handleByDuplicating =
-duplicateFileToCheckpoint(
-dbFileSystem, filePath, checkpointStreamFactory,
stateScope);
-if (handleByDuplicating != null) {
-LOG.trace("Duplicate file to checkpoint: {} {}", filePath,
handleByDuplicating);
-return HandleAndLocalPath.of(handleByDuplicating,
filePath.getName());
+
+// Get State handle for the DB file
+StreamStateHandle sourceStateHandle;
+if (dbFileSystem instanceof ForStFlinkFileSystem) {
+// Obtain the state handle stored in MappingEntry
+// or Construct a FileStateHandle base on the source file
+MappingEntry mappingEntry =
+((ForStFlinkFileSystem)
dbFileSystem).getMappingEntry(dbFilePath);
+Preconditions.checkNotNull(mappingEntry, "dbFile not found: " +
dbFilePath);
+sourceStateHandle = mappingEntry.getSource().toStateHandle();
+if (mappingEntry.getFileOwnership() == FileOwnership.NOT_OWNED) {
+// The file is already owned by JM, simply return the state
handle
+return HandleAndLocalPath.of(sourceStateHandle,
dbFilePath.getName());
+}
+} else {
+// Construct a FileStateHandle base on the DB file
+FileSystem sourceFileSystem = dbFilePath.getFileSystem();
+long fileLength =
sourceFileSystem.getFileStatus(dbFilePath).getLen();
+sourceStateHandle = new FileStateHandle(dbFilePath, fileLength);
+}
+
+// Try path-copying first. If failed, fallback to bytes-copying
+StreamStateHandle targetStateHandle =
+tryPathCopyingToCheckpoint(sourceStateHandle,
checkpointStreamFactory, stateScope);
Review Comment:
Thanks for the comments. I've modified the code as suggested. PTAL
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [FLINK-37021][state/forst] Fix incorrect paths when reusing files for checkpoints. [flink]
AlexYinHan commented on code in PR #26040:
URL: https://github.com/apache/flink/pull/26040#discussion_r1925154975
##
flink-state-backends/flink-statebackend-forst/src/main/java/org/apache/flink/state/forst/datatransfer/DataTransferStrategyBuilder.java:
##
@@ -45,20 +45,25 @@ public class DataTransferStrategyBuilder {
private static final Logger LOG =
LoggerFactory.getLogger(DataTransferStrategyBuilder.class);
public static DataTransferStrategy buildForSnapshot(
+SnapshotType.SharingFilesStrategy sharingFilesStrategy,
@Nullable ForStFlinkFileSystem forStFlinkFileSystem,
@Nullable CheckpointStreamFactory checkpointStreamFactory) {
return buildForSnapshot(
+sharingFilesStrategy,
forStFlinkFileSystem,
isDbPathUnderCheckpointPathForSnapshot(
forStFlinkFileSystem, checkpointStreamFactory));
}
@VisibleForTesting
static DataTransferStrategy buildForSnapshot(
+SnapshotType.SharingFilesStrategy sharingFilesStrategy,
@Nullable ForStFlinkFileSystem forStFlinkFileSystem,
boolean isDbPathUnderCheckpointPathForSnapshot) {
DataTransferStrategy strategy;
-if (forStFlinkFileSystem == null ||
isDbPathUnderCheckpointPathForSnapshot) {
+if (sharingFilesStrategy !=
SnapshotType.SharingFilesStrategy.FORWARD_BACKWARD
Review Comment:
Indeed. I've added a check in
```ForStIncrementalSnapshotStrategy#asyncSnapshot()```. It throws an
```IllegalArgumentException``` when encountering
```SharingFilesStrategy.FORWARD```.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-37199) Update document in quickly start to guide user to add checkpoint configuration
[ https://issues.apache.org/jira/browse/FLINK-37199?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-37199: --- Labels: pull-request-available (was: ) > Update document in quickly start to guide user to add checkpoint configuration > -- > > Key: FLINK-37199 > URL: https://issues.apache.org/jira/browse/FLINK-37199 > Project: Flink > Issue Type: Improvement > Components: Flink CDC >Affects Versions: cdc-3.3.0 >Reporter: Yanquan Lv >Priority: Major > Labels: pull-request-available > Fix For: cdc-3.4.0 > > > Many users often give feedback that according to the quick start > configuration, they can only synchronize data from the full stage, but not > from the incremental stage. This is usually because they have not enabled > checkpoints. > We should add instructions to enable checkpoints for new files after 1.19. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[PR] [FLINK-37199][doc] Update configuration in quickstart. [flink-cdc]
lvyanquan opened a new pull request, #3880: URL: https://github.com/apache/flink-cdc/pull/3880 Update configuration file for Flink 1.19+. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36564][ci] Running CI in random timezone to expose more time related bugs. [flink-cdc]
lvyanquan commented on PR #3650: URL: https://github.com/apache/flink-cdc/pull/3650#issuecomment-2606981241 Hi @leonardBang, could you help to reopen it as this will help us find more potential bugs. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37175][table] Support JSON built-in function for JSON_OBJECT [flink]
gustavodemorais commented on PR #26022: URL: https://github.com/apache/flink/pull/26022#issuecomment-2606982236 Made the changes as we discussed @twalthr. One additional thing I've changed is that we not only parse the json, but convert the json back to string before storing it. I think that makes sense, so we optimize the storage space by getting rid of unnecessary withe spaces/line breaks and so on before returning the value. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36838][state/forst] Fix the deadlock when quit forst state backend [flink]
flinkbot commented on PR #26053: URL: https://github.com/apache/flink/pull/26053#issuecomment-2607233199 ## CI report: * baf5b7d55de9f79a93d7356d9c4b3d4574886845 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [BP-2.0][FLINK-37183][clients] Fix symbolic links not being followed in "usrlib" [flink]
flinkbot commented on PR #26052: URL: https://github.com/apache/flink/pull/26052#issuecomment-2607231281 ## CI report: * 900a5e229422238ee0c3a8e6652b81574880d27a UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-37191) MySQL 'Compile and test' stage timeout after 90 minutes
[ https://issues.apache.org/jira/browse/FLINK-37191?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Leonard Xu reassigned FLINK-37191: -- Assignee: yux > MySQL 'Compile and test' stage timeout after 90 minutes > --- > > Key: FLINK-37191 > URL: https://issues.apache.org/jira/browse/FLINK-37191 > Project: Flink > Issue Type: Bug > Components: Build System / CI, Flink CDC >Affects Versions: cdc-3.3.0 >Reporter: Leonard Xu >Assignee: yux >Priority: Major > Fix For: cdc-3.4.0 > > > Error: The action 'Compile and test' has timed out after 90 minutes. > https://github.com/apache/flink-cdc/actions/runs/12862959093/job/35919670863 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[PR] [FLINK-36564][ci] Running CI in random timezone to expose more time related bugs. [flink-cdc]
lvyanquan opened a new pull request, #3650: URL: https://github.com/apache/flink-cdc/pull/3650 Refer to [this comment](https://github.com/apache/flink-cdc/pull/3648#pullrequestreview-2374769012) Copy from Paimon repo. How to verify: 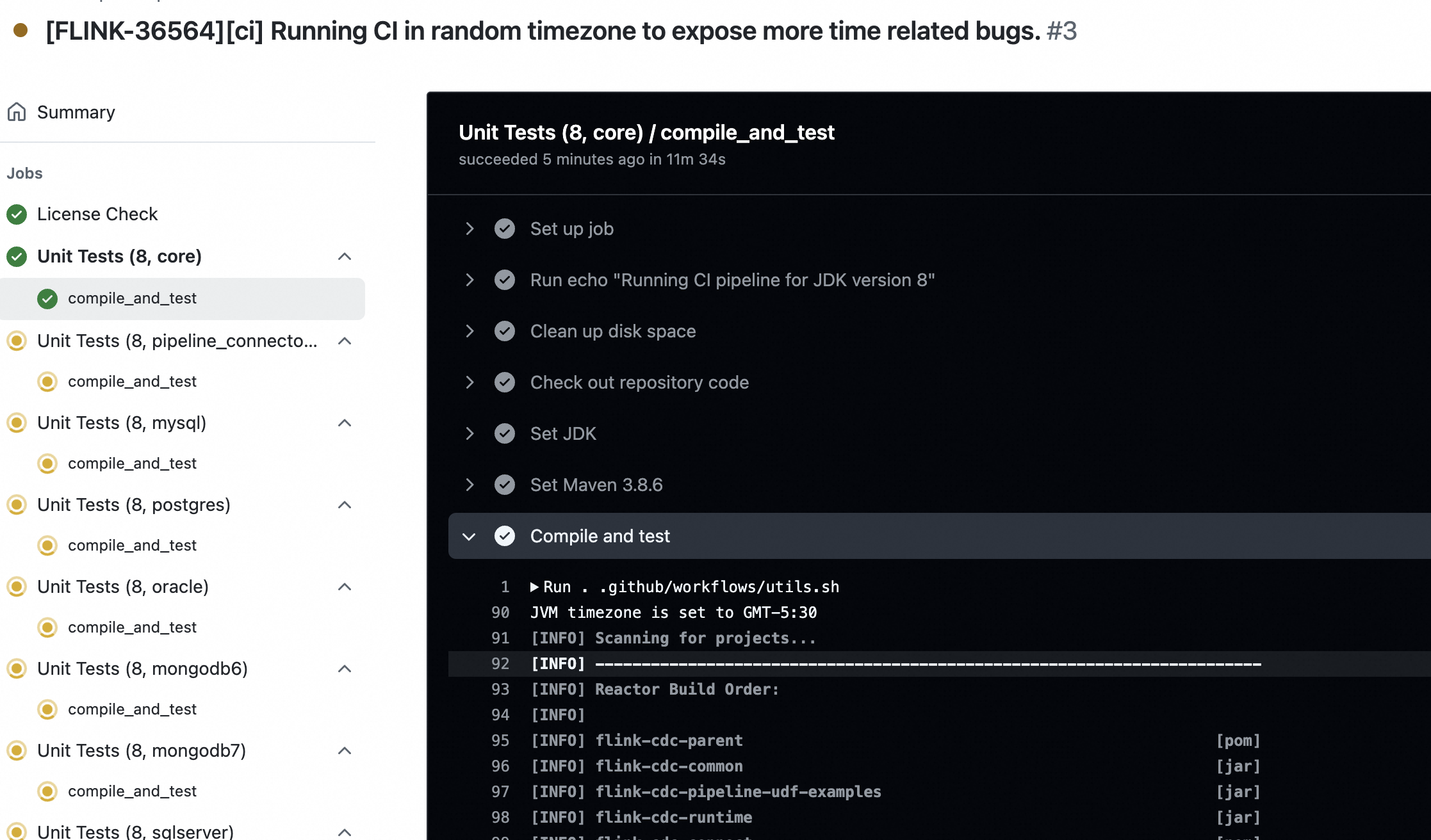 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36694][Filesystems] Update Hadoop for filesystems to 3.4.1 [flink]
bbrandt commented on PR #26046: URL: https://github.com/apache/flink/pull/26046#issuecomment-2607635603 Thanks @davidradl. Mostly using this as a temporary working area to see what the blockers are with the change in 1.20. If it high enough priority enough to move forward with, I can cherry pick my relevant changes to a PR from master, but I do not have any experience with S3 and the S3 connector is the main blocker for this moving forward. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-37203) Support AltertableCommentEvent and AlterColumnCommentEvent.
Yanquan Lv created FLINK-37203: -- Summary: Support AltertableCommentEvent and AlterColumnCommentEvent. Key: FLINK-37203 URL: https://issues.apache.org/jira/browse/FLINK-37203 Project: Flink Issue Type: Improvement Components: Flink CDC Affects Versions: cdc-3.4.0 Reporter: Yanquan Lv Fix For: cdc-3.4.0 Currently in FlinkCDC 3.3, we've support sync the comments of table and columns at the first acquisition. However, after the user modifies the comments in the source table, we cannot continue synchronizing this information. Adding AltertableCommentEvent and AlterColumnCommentEvent will us keep the comments of upstream and downstream tables as consistent as possible. -- This message was sent by Atlassian Jira (v8.20.10#820010)
Re: [PR] [FLINK-37021][state/forst] Fix incorrect paths when reusing files for checkpoints. [flink]
davidradl commented on code in PR #26040:
URL: https://github.com/apache/flink/pull/26040#discussion_r1924951833
##
flink-state-backends/flink-statebackend-forst/src/main/java/org/apache/flink/state/forst/datatransfer/CopyDataTransferStrategy.java:
##
@@ -92,97 +89,85 @@ public void transferFromCheckpoint(
StreamStateHandle sourceHandle, Path targetPath, CloseableRegistry
closeableRegistry)
throws IOException {
LOG.trace("Copy file from checkpoint: {}, {}, {}", sourceHandle,
targetPath, dbFileSystem);
-copyFileFromCheckpoint(dbFileSystem, sourceHandle, targetPath,
closeableRegistry);
+copyFileFromCheckpoint(sourceHandle, targetPath, closeableRegistry);
}
@Override
public String toString() {
return "CopyDataTransferStrategy{" + ", dbFileSystem=" + dbFileSystem
+ '}';
}
-private static HandleAndLocalPath copyFileToCheckpoint(
-FileSystem dbFileSystem,
-Path filePath,
+private HandleAndLocalPath copyFileToCheckpoint(
+Path dbFilePath,
long maxTransferBytes,
CheckpointStreamFactory checkpointStreamFactory,
CheckpointedStateScope stateScope,
CloseableRegistry closeableRegistry,
CloseableRegistry tmpResourcesRegistry)
throws IOException {
-StreamStateHandle handleByDuplicating =
-duplicateFileToCheckpoint(
-dbFileSystem, filePath, checkpointStreamFactory,
stateScope);
-if (handleByDuplicating != null) {
-LOG.trace("Duplicate file to checkpoint: {} {}", filePath,
handleByDuplicating);
-return HandleAndLocalPath.of(handleByDuplicating,
filePath.getName());
+
+// Get State handle for the DB file
+StreamStateHandle sourceStateHandle;
+if (dbFileSystem instanceof ForStFlinkFileSystem) {
+// Obtain the state handle stored in MappingEntry
+// or Construct a FileStateHandle base on the source file
+MappingEntry mappingEntry =
+((ForStFlinkFileSystem)
dbFileSystem).getMappingEntry(dbFilePath);
+Preconditions.checkNotNull(mappingEntry, "dbFile not found: " +
dbFilePath);
+sourceStateHandle = mappingEntry.getSource().toStateHandle();
+if (mappingEntry.getFileOwnership() == FileOwnership.NOT_OWNED) {
+// The file is already owned by JM, simply return the state
handle
+return HandleAndLocalPath.of(sourceStateHandle,
dbFilePath.getName());
+}
+} else {
+// Construct a FileStateHandle base on the DB file
+FileSystem sourceFileSystem = dbFilePath.getFileSystem();
+long fileLength =
sourceFileSystem.getFileStatus(dbFilePath).getLen();
+sourceStateHandle = new FileStateHandle(dbFilePath, fileLength);
+}
+
+// Try path-copying first. If failed, fallback to bytes-copying
+StreamStateHandle targetStateHandle =
+tryPathCopyingToCheckpoint(sourceStateHandle,
checkpointStreamFactory, stateScope);
Review Comment:
tryPathCopyingToCheckpoint can fail with an IOException as well as returning
null. It would be better to always return null for a failure I think -
otherwise for an IOException we will not try bytesCopyingToCheckpoint.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [FLINK-37181][build] Fix MacOS sha256sum tool compile error [flink]
gaborgsomogyi commented on PR #26034: URL: https://github.com/apache/flink/pull/26034#issuecomment-2606656369 Some unrelated tests are flaky so restarting. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37181][build] Fix MacOS sha256sum tool compile error [flink]
gaborgsomogyi commented on PR #26034: URL: https://github.com/apache/flink/pull/26034#issuecomment-2606656815 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37021][state/forst] Fix incorrect paths when reusing files for checkpoints. [flink]
davidradl commented on code in PR #26040:
URL: https://github.com/apache/flink/pull/26040#discussion_r1924954408
##
flink-state-backends/flink-statebackend-forst/src/main/java/org/apache/flink/state/forst/datatransfer/CopyDataTransferStrategy.java:
##
@@ -92,97 +89,85 @@ public void transferFromCheckpoint(
StreamStateHandle sourceHandle, Path targetPath, CloseableRegistry
closeableRegistry)
throws IOException {
LOG.trace("Copy file from checkpoint: {}, {}, {}", sourceHandle,
targetPath, dbFileSystem);
-copyFileFromCheckpoint(dbFileSystem, sourceHandle, targetPath,
closeableRegistry);
+copyFileFromCheckpoint(sourceHandle, targetPath, closeableRegistry);
}
@Override
public String toString() {
return "CopyDataTransferStrategy{" + ", dbFileSystem=" + dbFileSystem
+ '}';
}
-private static HandleAndLocalPath copyFileToCheckpoint(
-FileSystem dbFileSystem,
-Path filePath,
+private HandleAndLocalPath copyFileToCheckpoint(
+Path dbFilePath,
long maxTransferBytes,
CheckpointStreamFactory checkpointStreamFactory,
CheckpointedStateScope stateScope,
CloseableRegistry closeableRegistry,
CloseableRegistry tmpResourcesRegistry)
throws IOException {
-StreamStateHandle handleByDuplicating =
-duplicateFileToCheckpoint(
-dbFileSystem, filePath, checkpointStreamFactory,
stateScope);
-if (handleByDuplicating != null) {
-LOG.trace("Duplicate file to checkpoint: {} {}", filePath,
handleByDuplicating);
-return HandleAndLocalPath.of(handleByDuplicating,
filePath.getName());
+
+// Get State handle for the DB file
+StreamStateHandle sourceStateHandle;
+if (dbFileSystem instanceof ForStFlinkFileSystem) {
+// Obtain the state handle stored in MappingEntry
+// or Construct a FileStateHandle base on the source file
+MappingEntry mappingEntry =
+((ForStFlinkFileSystem)
dbFileSystem).getMappingEntry(dbFilePath);
+Preconditions.checkNotNull(mappingEntry, "dbFile not found: " +
dbFilePath);
+sourceStateHandle = mappingEntry.getSource().toStateHandle();
+if (mappingEntry.getFileOwnership() == FileOwnership.NOT_OWNED) {
+// The file is already owned by JM, simply return the state
handle
+return HandleAndLocalPath.of(sourceStateHandle,
dbFilePath.getName());
+}
+} else {
+// Construct a FileStateHandle base on the DB file
+FileSystem sourceFileSystem = dbFilePath.getFileSystem();
+long fileLength =
sourceFileSystem.getFileStatus(dbFilePath).getLen();
+sourceStateHandle = new FileStateHandle(dbFilePath, fileLength);
+}
+
+// Try path-copying first. If failed, fallback to bytes-copying
+StreamStateHandle targetStateHandle =
+tryPathCopyingToCheckpoint(sourceStateHandle,
checkpointStreamFactory, stateScope);
+if (targetStateHandle != null) {
+LOG.trace("Path-copy file to checkpoint: {} {}", dbFilePath,
targetStateHandle);
+} else {
+targetStateHandle =
+bytesCopyingToCheckpoint(
+dbFilePath,
+maxTransferBytes,
+checkpointStreamFactory,
+stateScope,
+closeableRegistry,
+tmpResourcesRegistry);
+LOG.trace("Bytes-copy file to checkpoint: {}, {}", dbFilePath,
targetStateHandle);
}
-HandleAndLocalPath handleAndLocalPath =
-HandleAndLocalPath.of(
-writeFileToCheckpoint(
-dbFileSystem,
-filePath,
-maxTransferBytes,
-checkpointStreamFactory,
-stateScope,
-closeableRegistry,
-tmpResourcesRegistry),
-filePath.getName());
-LOG.trace("Write file to checkpoint: {}, {}", filePath,
handleAndLocalPath.getHandle());
-return handleAndLocalPath;
+return HandleAndLocalPath.of(targetStateHandle, dbFilePath.getName());
}
/**
* Duplicate file to checkpoint storage by calling {@link
CheckpointStreamFactory#duplicate} if
* possible.
Review Comment:
nit: javadoc @params etc are missing.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For q
Re: [PR] [FLINK-37120][pipeline-connector/mysql] Add ending split chunk first to avoid TaskManager oom [flink-cdc]
lvyanquan commented on PR #3856: URL: https://github.com/apache/flink-cdc/pull/3856#issuecomment-2607006968 LGTM. I'm worried if this parameter is a bit complicated, what about naming it `scan.incremental.assign-max-chunk-first.enabled`? WDYT @beryllw @leonardBang? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-37201) FlinkCDC Pipeline transform arithmetic functions support parameters of null and more numerical types.
Wenkai Qi created FLINK-37201: - Summary: FlinkCDC Pipeline transform arithmetic functions support parameters of null and more numerical types. Key: FLINK-37201 URL: https://issues.apache.org/jira/browse/FLINK-37201 Project: Flink Issue Type: Improvement Components: Flink CDC Affects Versions: cdc-3.3.0 Reporter: Wenkai Qi -- This message was sent by Atlassian Jira (v8.20.10#820010)
Re: [PR] [FLINK-36698][pipeline-connector][elasticsearch] Elasticsearch Pipeline Connector support index sharding [flink-cdc]
lvyanquan commented on code in PR #3723:
URL: https://github.com/apache/flink-cdc/pull/3723#discussion_r1925186674
##
docs/content/docs/connectors/pipeline-connectors/elasticsearch.md:
##
@@ -169,7 +169,7 @@ Pipeline Connector Options
optional
(none)
Long
- Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Tables
are separated by ';'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
+ Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Default
sharding column is first partition column.Tables are separated by ';'.Table and
column are separated by ':'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
Review Comment:
What about making the separator configurable with a default value of `$`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [FLINK-35600] Add timestamp for low and high watermark [flink-cdc]
yuxiqian commented on PR #3415: URL: https://github.com/apache/flink-cdc/pull/3415#issuecomment-2607045316 After some bisect searching I believe changes in this PR will caused PolarDBX related tests to fail frequently (FLINK-37191). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36973]udf dateformat support LocalZonedTimestampData datatype [flink-cdc]
hiliuxg commented on code in PR #3863:
URL: https://github.com/apache/flink-cdc/pull/3863#discussion_r1925357513
##
flink-cdc-runtime/src/main/java/org/apache/flink/cdc/runtime/functions/SystemFunctionUtils.java:
##
@@ -105,6 +105,13 @@ public static String dateFormat(TimestampData timestamp,
String format) {
timestamp.getMillisecond(), format,
TimeZone.getTimeZone("UTC"));
}
+public static String dateFormat(LocalZonedTimestampData timestamp, String
format) {
+return DateTimeUtils.formatTimestampMillis(
+timestamp.getEpochMillisecond(),
+format,
+TimeZone.getTimeZone(ZoneId.systemDefault()));
+}
Review Comment:
Thank you for taking the time to review my code. Could you please tell me
how to fetch the yaml job pipeline configuration in systemfunctionutils class?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
He-Pin commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607651794 ouch, `but Flink does not support 2.13 at all` so seems we can't drop 2.12 support very soon! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
ferenc-csaky commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607710502 > ouch, `but Flink does not support 2.13 at all` so seems we can't drop 2.12 support very soon! We are actually trying to remove Scala from the project: https://issues.apache.org/jira/browse/FLINK-29741 I'm not sure when that happens, and maybe if upstream projects are using a more recent version would not be meaningful, but I think for the foreseeable future it will definitely stay with us. Anyways, I managed to run the tests making Pekko use the `unpooled` allocator and the test PASS on my laptop with 7MB, so it works as before. IMO this config option will be definitely useful for us. If it's meaningful enough to urge another Pekko release, I am leaning towards to not, but if @afedulov thinks we can discuss this on the mailing list. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-37199) Update document in quickly start to guide user to add checkpoint configuration
Yanquan Lv created FLINK-37199: -- Summary: Update document in quickly start to guide user to add checkpoint configuration Key: FLINK-37199 URL: https://issues.apache.org/jira/browse/FLINK-37199 Project: Flink Issue Type: Improvement Components: Flink CDC Affects Versions: cdc-3.3.0 Reporter: Yanquan Lv Fix For: cdc-3.4.0 Many users often give feedback that according to the quick start configuration, they can only synchronize data from the full stage, but not from the incremental stage. This is usually because they have not enabled checkpoints. We should add instructions to enable checkpoints for new files after 1.19. -- This message was sent by Atlassian Jira (v8.20.10#820010)
Re: [PR] [FLINK-37138][sql-gateway] Fix failed SqlYARNApplicationITCase in hadoop3 profile [flink]
fsk119 commented on PR #26049: URL: https://github.com/apache/flink/pull/26049#issuecomment-2606948334 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37138][sql-gateway] Fix failed SqlYARNApplicationITCase in hadoop3 profile [flink]
fsk119 commented on PR #26050: URL: https://github.com/apache/flink/pull/26050#issuecomment-2606948717 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-20895][flink-table-planner-blink] support local aggregate push down in blink planner [flink]
sebastianliu closed pull request #14894: [FLINK-20895][flink-table-planner-blink] support local aggregate push down in blink planner URL: https://github.com/apache/flink/pull/14894 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-37177) Update chinese documentation of json function
[ https://issues.apache.org/jira/browse/FLINK-37177?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916092#comment-17916092 ] qinghuan wang commented on FLINK-37177: --- hi, can you assign this one to me? [~gustavodemorais] [https://github.com/apache/flink/pull/26055] this is chinese documentation for json function > Update chinese documentation of json function > - > > Key: FLINK-37177 > URL: https://issues.apache.org/jira/browse/FLINK-37177 > Project: Flink > Issue Type: Improvement > Components: Documentation >Reporter: Gustavo de Morais >Priority: Major > Labels: chinese-translation, pull-request-available > > We'll introduce a json built-in function that works with json_object here > [https://github.com/apache/flink/pull/26022] > > We need to update the chinese documentation on sql_functions_zh to include > the json function based on the english version here: > https://github.com/apache/flink/pull/26022/files#diff-539fb22ee6aeee4cf07230bb4155500c6680c4cc889260e2c58bfa9d63fb7de5 > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
ferenc-csaky commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607584839 > @ferenc-csaky Cool But the pekko 1.2.x snapshot should be binary compatible with 1.1.x > > And there are nightly on https://repository.apache.org/content/groups/snapshots/org/apache/pekko/pekko-actor_2.13/1.2.0-M0+55-a75bc7a7-SNAPSHOT/ > > Hope that saves you some time. TBH I have very limited Scala knowledge, but Flink does not support 2.13 at all, so my preconception was that I need a 2.12 build. I pretty much figured out building it from the nightly GH workflow and just finished building with this cmd: ```sh sbt -Dpekko.build.scalaVersion=2.12.x "++ 2.12.x ;publishLocal;publishM2" ``` (After 1 failure because of `graphviz` missing...) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [hotfix] Fix the issue related to mounting the Logback configuration [flink]
Jam804 commented on PR #26039: URL: https://github.com/apache/flink/pull/26039#issuecomment-2607614914 I think there's nothing wrong with my code now. Thank you for your guidance. @davidradl -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[PR] [FLINK-36868][state/forst] Fix the deadlock when quit forst state backend [flink]
Zakelly opened a new pull request, #26053: URL: https://github.com/apache/flink/pull/26053 ## What is the purpose of the change In #25732 we join the async background threads of ForSt to avoid deadlock when JVM quit. That is an incomplete solution which is also problematic. The background threads are shared among multiple ForSt instances, meaning that simply join those threads may cause background job unfinished in other instances. The ForSt project has investigated the root cause and gave a solution (https://github.com/ververica/ForSt/pull/30). Thus we should bump the depended ForSt version and revert the thread joining in Flink. ## Brief change log - Bump ForSt version to 0.1.6 - Revert the change of background thread joining ## Verifying this change This change is already covered by IT case `ForStStateBackendV2Test`. If it can normally exit then the problem solved. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37138][sql-gateway] Fix failed SqlYARNApplicationITCase in hadoop3 profile [flink]
flinkbot commented on PR #26049: URL: https://github.com/apache/flink/pull/26049#issuecomment-2607036091 ## CI report: * c64f52cdc11078f135a632742918afcbfc0a857a UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37138][sql-gateway] Fix failed SqlYARNApplicationITCase in hadoop3 profile [flink]
flinkbot commented on PR #26050: URL: https://github.com/apache/flink/pull/26050#issuecomment-2607037853 ## CI report: * e616aef00b98f25ca1a60c0aca730e0b257fce09 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36698][pipeline-connector][elasticsearch] Elasticsearch Pipeline Connector support index sharding [flink-cdc]
lvyanquan commented on code in PR #3723:
URL: https://github.com/apache/flink-cdc/pull/3723#discussion_r1925186674
##
docs/content/docs/connectors/pipeline-connectors/elasticsearch.md:
##
@@ -169,7 +169,7 @@ Pipeline Connector Options
optional
(none)
Long
- Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Tables
are separated by ';'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
+ Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Default
sharding column is first partition column.Tables are separated by ';'.Table and
column are separated by ':'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
Review Comment:
What about making the separator configurable with default value of `$`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [FLINK-37005][table] Make StreamExecDeduplicate ouput insert only where possible [flink]
flinkbot commented on PR #26051: URL: https://github.com/apache/flink/pull/26051#issuecomment-2607039595 ## CI report: * 63f9ed19290ca306170c67664f67750ce8d6e8e3 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-37200) Add e2e test for ElasticSearch Sink.
Yanquan Lv created FLINK-37200: -- Summary: Add e2e test for ElasticSearch Sink. Key: FLINK-37200 URL: https://issues.apache.org/jira/browse/FLINK-37200 Project: Flink Issue Type: Improvement Components: Flink CDC Affects Versions: cdc-3.3.0 Reporter: Yanquan Lv Fix For: cdc-3.4.0 Add e2e test for ElasticSearch Sink. For example: ``` source: type: mysql name: MySQL Source hostname: 127.0.0.1 port: 3306 username: admin password: pass tables: adb.\.*, bdb.user_table_[0-9]+, [app|web].order_\.* server-id: 5401-5404 sink: type: elasticsearch name: Elasticsearch Sink hosts: http://127.0.0.1:9092,http://127.0.0.1:9093 route: - source-table: adb.\.* sink-table: default_index description: sync adb.\.* table to default_index pipeline: name: MySQL to Elasticsearch Pipeline parallelism: 2 ``` -- This message was sent by Atlassian Jira (v8.20.10#820010)
[PR] [BP-2.0][FLINK-36838][state/forst] Fix the deadlock when quit forst state backend [flink]
Zakelly opened a new pull request, #26054: URL: https://github.com/apache/flink/pull/26054 This is a backport PR to 2.0 for #26053 ## What is the purpose of the change In #25732 we join the async background threads of ForSt to avoid deadlock when JVM quit. That is an incomplete solution which is also problematic. The background threads are shared among multiple ForSt instances, meaning that simply join those threads may cause background job unfinished in other instances. The ForSt project has investigated the root cause and gave a solution (https://github.com/ververica/ForSt/pull/30). Thus we should bump the depended ForSt version and revert the thread joining in Flink. ## Brief change log - Bump ForSt version to 0.1.6 - Revert the change of background thread joining ## Verifying this change This change is already covered by IT case `ForStStateBackendV2Test`. If it can normally exit then the problem solved. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-37201) FlinkCDC Pipeline transform arithmetic functions support parameters of null and more numerical types.
[ https://issues.apache.org/jira/browse/FLINK-37201?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-37201: --- Labels: pull-request-available (was: ) > FlinkCDC Pipeline transform arithmetic functions support parameters of null > and more numerical types. > - > > Key: FLINK-37201 > URL: https://issues.apache.org/jira/browse/FLINK-37201 > Project: Flink > Issue Type: Improvement > Components: Flink CDC >Affects Versions: cdc-3.3.0 >Reporter: Wenkai Qi >Priority: Major > Labels: pull-request-available > Original Estimate: 24h > Remaining Estimate: 24h > > FlinkCDC Pipeline transform arithmetic functions can not support parameters > of null and more numerical types. For example: ceil, floor, round and abs. > When the input parameter is null or a numerical type such as int, the program > will have an error. > I have fixed it. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-37177) Update chinese documentation of json function
[ https://issues.apache.org/jira/browse/FLINK-37177?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-37177: --- Labels: chinese-translation pull-request-available (was: chinese-translation) > Update chinese documentation of json function > - > > Key: FLINK-37177 > URL: https://issues.apache.org/jira/browse/FLINK-37177 > Project: Flink > Issue Type: Improvement > Components: Documentation >Reporter: Gustavo de Morais >Priority: Major > Labels: chinese-translation, pull-request-available > > We'll introduce a json built-in function that works with json_object here > [https://github.com/apache/flink/pull/26022] > > We need to update the chinese documentation on sql_functions_zh to include > the json function based on the english version here: > https://github.com/apache/flink/pull/26022/files#diff-539fb22ee6aeee4cf07230bb4155500c6680c4cc889260e2c58bfa9d63fb7de5 > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[PR] [FLINK-37177][table] Update chinese documentation of json function [flink]
wangqinghuan opened a new pull request, #26055: URL: https://github.com/apache/flink/pull/26055 ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change Please make sure both new and modified tests in this PR follow [the conventions for tests defined in our code quality guide](https://flink.apache.org/how-to-contribute/code-style-and-quality-common/#7-testing). *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluster with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
He-Pin commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607565950 @ferenc-csaky Cool But the pekko 1.2.x snapshot should be binary compatible with 1.1.x And there are nightly on https://repository.apache.org/content/groups/snapshots/org/apache/pekko/pekko-actor_2.13/1.2.0-M0+55-a75bc7a7-SNAPSHOT/ Hope that saves you some time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] Update cdc version to 3.4-SNAPSHOT and add release-3.3 docs [flink-cdc]
leonardBang merged PR #3870: URL: https://github.com/apache/flink-cdc/pull/3870 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [docs] Fix maxcompute connector typo in examples section [flink-cdc]
leonardBang merged PR #3875: URL: https://github.com/apache/flink-cdc/pull/3875 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [docs] Fix maxcompute connector typo in examples section [flink-cdc]
leonardBang commented on PR #3875: URL: https://github.com/apache/flink-cdc/pull/3875#issuecomment-2606733305 CI passed, merging... -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37005][table] Make StreamExecDeduplicate ouput insert only where possible [flink]
pnowojski commented on PR #26051: URL: https://github.com/apache/flink/pull/26051#issuecomment-2606730242 @lincoln-lil @xuyangzhong can you take a look at this? You were recently involved in a couple of changes around here: FLINK-36837 and FLINK-34702. I could try to implement the async append-only row-time version, but I would probably need a bit of guidance from your side. For example, the function that I introduced `RowTimeDeduplicateKeepFirstRowFunction` doesn't output the data in one step and it also relies on firing timers. Are there any guarantees to the order of firing timers interleaved with pending async state access for the given key? In other words, if I implement async version of the `processElement`, is it guaranteed that it will finish before any timer for that key can be fired? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-37202) Introduce TDengine connector
kevinmen created FLINK-37202: Summary: Introduce TDengine connector Key: FLINK-37202 URL: https://issues.apache.org/jira/browse/FLINK-37202 Project: Flink Issue Type: New Feature Reporter: kevinmen Hi Community, We have developed the tdengine connector(https://github.com/taosdata/flink-connector-tdengine), currently we are using Flink in the current Project. We have huge amount of data to process using Flink which resides in TDengine. We have a requirement of parallel data connectivity in between Flink and TDengine for both reads/writes. Currently we are planning to create this connector and contribute to the Community. I will update the further details once I receive your feedback Please let us know if you have any concerns. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-37202) Introduce TDengine connector
[ https://issues.apache.org/jira/browse/FLINK-37202?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916044#comment-17916044 ] David Radley commented on FLINK-37202: -- Hi there, I think a new connector is an improvement that requires a [Flip|https://cwiki.apache.org/confluence/display/FLINK/Flink+Improvement+Proposals] so this can be discussed and voted on by the community, Kind regards, David. > Introduce TDengine connector > > > Key: FLINK-37202 > URL: https://issues.apache.org/jira/browse/FLINK-37202 > Project: Flink > Issue Type: New Feature >Reporter: kevinmen >Priority: Major > > Hi Community, > > We have developed the tdengine > connector(https://github.com/taosdata/flink-connector-tdengine), currently we > are using Flink in the current Project. We have huge amount of data to > process using Flink which resides in TDengine. We have a requirement of > parallel data connectivity in between Flink and TDengine for both > reads/writes. Currently we are planning to create this connector and > contribute to the Community. > > I will update the further details once I receive your feedback > > Please let us know if you have any concerns. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[PR] [hotfix][docs] Fix dead links in Doris [flink-cdc]
ruanhang1993 opened a new pull request, #3878: URL: https://github.com/apache/flink-cdc/pull/3878 (no comment) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36945] MySQL CDC supports parsing RENAME TABLE Statement with multiple tables [flink-cdc]
yoheimuta commented on PR #3876: URL: https://github.com/apache/flink-cdc/pull/3876#issuecomment-2606833211 @Mielientiev It's similar but not related. The fixed PR for #3668 does not address the issue presented here. And, I’m unsure if this fix resolves potential issues with gh-ost or pt-ost. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36945] MySQL CDC supports parsing RENAME TABLE Statement with multiple tables [flink-cdc]
mielientiev commented on PR #3876: URL: https://github.com/apache/flink-cdc/pull/3876#issuecomment-2606818887 Quick question isn't this related to https://github.com/apache/flink-cdc/pull/3668? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37194][tests] Fix NPE issue in WatermarkITCase [flink]
flinkbot commented on PR #26048: URL: https://github.com/apache/flink/pull/26048#issuecomment-2606839429 ## CI report: * c227934d08287a0311e85f563c2026da5dff452e UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-37005) Make StreamExecDeduplicate ouput insert only where possible
[
https://issues.apache.org/jira/browse/FLINK-37005?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-37005:
---
Labels: pull-request-available (was: )
> Make StreamExecDeduplicate ouput insert only where possible
> ---
>
> Key: FLINK-37005
> URL: https://issues.apache.org/jira/browse/FLINK-37005
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner, Table SQL / Runtime
>Affects Versions: 2.0.0
>Reporter: Piotr Nowojski
>Assignee: Piotr Nowojski
>Priority: Major
> Labels: pull-request-available
>
> According to planner, {{StreamExecDeduplicate}} currently always outputs
> updates/retractions, even when this is currently not the case in the runtime.
> This can performance problems, for example forcing planner to add
> {{SinkUpsertMaterializer}} operator down stream from the deduplication, while
> it's actually not necessary.
> In this ticket, I would like to both support outputing insert only and
> increase number of cases where that's actually the case.
> # Proc time keep first row is currently already implemented in such a way
> that it outputs inserts only, but this is not actually used/marked in the
> planner (planner change only)
> # Row time keep first row, could be also implemented to output inserts only,
> with an operator that emits deduplication result on watermark, instead of on
> each record (planner + runtime change)
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[PR] [FLINK-37005][table] Make StreamExecDeduplicate ouput insert only where possible [flink]
pnowojski opened a new pull request, #26051: URL: https://github.com/apache/flink/pull/26051 ## What is the purpose of the change This PR: - implements the `RowTimeDeduplicateKeepFirstRowFunction` using watermarks to avoid retracting previous results - changes planner to take into account that both proc time and rowtime deduplicate in keep first row variants are append only Thanks to that, planner can avoid costly operators like `SinkUpsertMaterializer` downstream the whole query can be append-only - removing a need for retracting/upserting results from the output table. Currently there is no variant for the async state backend. ## Verifying this change This adds new tests and is also covered by existing ITCases. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (**yes** / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (**not applicable** / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37021][state/forst] Fix incorrect paths when reusing files for checkpoints. [flink]
Zakelly commented on code in PR #26040:
URL: https://github.com/apache/flink/pull/26040#discussion_r1925014517
##
flink-state-backends/flink-statebackend-forst/src/main/java/org/apache/flink/state/forst/datatransfer/DataTransferStrategyBuilder.java:
##
@@ -45,20 +45,25 @@ public class DataTransferStrategyBuilder {
private static final Logger LOG =
LoggerFactory.getLogger(DataTransferStrategyBuilder.class);
public static DataTransferStrategy buildForSnapshot(
+SnapshotType.SharingFilesStrategy sharingFilesStrategy,
@Nullable ForStFlinkFileSystem forStFlinkFileSystem,
@Nullable CheckpointStreamFactory checkpointStreamFactory) {
return buildForSnapshot(
+sharingFilesStrategy,
forStFlinkFileSystem,
isDbPathUnderCheckpointPathForSnapshot(
forStFlinkFileSystem, checkpointStreamFactory));
}
@VisibleForTesting
static DataTransferStrategy buildForSnapshot(
+SnapshotType.SharingFilesStrategy sharingFilesStrategy,
@Nullable ForStFlinkFileSystem forStFlinkFileSystem,
boolean isDbPathUnderCheckpointPathForSnapshot) {
DataTransferStrategy strategy;
-if (forStFlinkFileSystem == null ||
isDbPathUnderCheckpointPathForSnapshot) {
+if (sharingFilesStrategy !=
SnapshotType.SharingFilesStrategy.FORWARD_BACKWARD
Review Comment:
I think for `ForStIncrementalSnapshotStrategy`, the
`SnapshotType.SharingFilesStrategy.FORWARD` is not supported since it breaks
the precondition of file sharing between CP and DB.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [FLINK-37175][table] Support JSON built-in function for JSON_OBJECT [flink]
gustavodemorais commented on PR #26022: URL: https://github.com/apache/flink/pull/26022#issuecomment-2607001419 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-35578][state/rocksdb] Bump frocksdbjni to 8.10.0-ververica-1.0 [flink]
fredia commented on PR #26033: URL: https://github.com/apache/flink/pull/26033#issuecomment-2607013048 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
He-Pin commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607379254 @ferenc-csaky I think the cache depends on how many cores you have, would you like to test the pekko 1.2.x nightly too, I would like too, but don't know how. refs: https://github.com/apache/pekko/pull/1709 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37175][table] Support JSON built-in function for JSON_OBJECT [flink]
gustavodemorais closed pull request #26022: [FLINK-37175][table] Support JSON built-in function for JSON_OBJECT URL: https://github.com/apache/flink/pull/26022 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
ferenc-csaky commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607368545 @afedulov So on my M4 Pro chip MacBook the test starts to run with 11MB consistentlt, and consistently fail with anything under that, since TMs cannot even start because there are not enough resource to allocate for Netty. Since the CI runs on x86 machines, and only fail once in a while, it makes me think CPU architecture matters here and it allocates less memory on a non-ARM architecture. All in all this points me to think we should get away with 12MB for these tests for 1.19 and 1.20. In the meantime I also thought a bit about where that `90mb` memory the backported commit added, and I think they just multiplied the 4M chunk by the task slot number and added some extra margin: `4m x 20 + 10 = 90m`, which is semantically wrong. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
He-Pin commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607796620 I knew , after alibaba acquired, then more Java, thanks for that information. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
ferenc-csaky commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607825560 > @He-Pin now that it is confirmed that the "unpooled" config solves the issue for us, how realistic do you think it is to get a Pekko release with the allocator config support included soon? > > @ferenc-csaky I would prefer not to postpone much longer unless we get the Pekko release ASAP. Please drop a line in response to @pjfanning's question here: [apache/pekko#1709 (comment)](https://github.com/apache/pekko/pull/1709#issuecomment-2605291102) In parallel, let's assume that there won't be a new Pekko release in the upcoming day or two. Should we simply bump from 7 to 12MB and hope it does it, what do you think? I agree with moving forward and adjusting the off-heap memory to 12MB. Will comment to the Pekko PR in a bit. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36694][Filesystems] Update Hadoop for filesystems to 3.4.1 [flink]
bbrandt closed pull request #26046: [FLINK-36694][Filesystems] Update Hadoop for filesystems to 3.4.1 URL: https://github.com/apache/flink/pull/26046 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [BP-2.0][FLINK-37183][clients] Fix symbolic links not being followed in "usrlib" [flink]
ferenc-csaky closed pull request #26052: [BP-2.0][FLINK-37183][clients] Fix symbolic links not being followed in "usrlib" URL: https://github.com/apache/flink/pull/26052 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [BP-2.0][FLINK-37183][clients] Fix symbolic links not being followed in "usrlib" [flink]
ferenc-csaky commented on PR #26052: URL: https://github.com/apache/flink/pull/26052#issuecomment-2607997344 The `flink-clients` test module ran correctly, merging this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-37183) Usrlib symlinks are not followed
[
https://issues.apache.org/jira/browse/FLINK-37183?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17915937#comment-17915937
]
Ferenc Csaky edited comment on FLINK-37183 at 1/22/25 6:54 PM:
---
[{{52d6691}}|https://github.com/apache/flink/commit/52d6691d2ef98d3a43c611c19e1eb9cc45da834d]
in master
{{[95450ed|https://github.com/apache/flink/commit/95450ed676fa8b895637b0d34ec38edf6357b588]}}
in release-2.0
[{{4d1d066}}|https://github.com/apache/flink/commit/4d1d0664253f47b165b44e96ea75461c35bc30a2]
in release-1.20
[{{1233a25}}|https://github.com/apache/flink/commit/1233a25bdf988decc93d0a754c9df508d844f003]
in release-1.19
was (Author: JIRAUSER306586):
[{{52d6691}}|https://github.com/apache/flink/commit/52d6691d2ef98d3a43c611c19e1eb9cc45da834d]
in master
[{{4d1d066}}|https://github.com/apache/flink/commit/4d1d0664253f47b165b44e96ea75461c35bc30a2]
in release-1.20
[{{1233a25}}|https://github.com/apache/flink/commit/1233a25bdf988decc93d0a754c9df508d844f003]
in release-1.19
> Usrlib symlinks are not followed
>
>
> Key: FLINK-37183
> URL: https://issues.apache.org/jira/browse/FLINK-37183
> Project: Flink
> Issue Type: Bug
> Components: Client / Job Submission
>Affects Versions: 1.20.0, 1.19.1, 2.0-preview
>Reporter: Joery
>Assignee: Joery
>Priority: Minor
> Labels: pull-request-available
> Fix For: 2.0.0, 1.19.2, 1.20.1
>
>
> https://issues.apache.org/jira/browse/FLINK-35358 has changed the Java File
> API that is used to traverse the usrlib from Files.list to Files.walk.
> Files.list was following symlinks, but Files.walk needs an option passed to
> follow symlinks. This caused symlinks to no longer be followed. Which seems
> like an unintended side effect and broke my setup.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33926) Can't start a job with a jar in the system classpath in native k8s mode
[
https://issues.apache.org/jira/browse/FLINK-33926?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916171#comment-17916171
]
Trystan edited comment on FLINK-33926 at 1/22/25 7:32 PM:
--
I think it makes sense to me. Not sure how something like this is handled with
Flink 2.0 on the horizon, though.
This issue still crops up and bites us from time to time, so I think this would
be a positive change.
was (Author: trystan):
I think it makes sense to me. Not sure how something like this is handled with
Flink 2.0 on the horizon, though.
This issue still crops up and bites us from time to time, so I think this would
be a positive change.
> Can't start a job with a jar in the system classpath in native k8s mode
> ---
>
> Key: FLINK-33926
> URL: https://issues.apache.org/jira/browse/FLINK-33926
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Affects Versions: kubernetes-operator-1.6.0
>Reporter: Trystan
>Assignee: Gantigmaa Selenge
>Priority: Major
> Labels: pull-request-available
>
> It appears that the combination of the running operator-controlled jobs in
> native k8s + application mode + using a job jar in the classpath is invalid.
> Avoiding dynamic classloading (as specified in the
> [docs|https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/ops/debugging/debugging_classloading/#avoiding-dynamic-classloading-for-user-code])
> is beneficial for some jobs. This affects at least Flink 1.16.1 and
> Kubernetes Operator 1.6.0.
>
> FLINK-29288 seems to have addressed this for standalone mode. If I am
> misunderstanding how to correctly build jars for this native k8s scenario,
> apologies for the noise and any pointers would be appreciated!
>
> Perhaps related, the [spec
> documentation|https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/docs/custom-resource/reference/#jobspec]
> declares it optional, but isn't clear about under what conditions that
> applies.
> * Putting the jar in the system classpath and pointing *jarURI* to that jar
> leads to linkage errors.
> * Not including *jarURI* leads to NullPointerExceptions in the operator:
> {code:java}
> {"type":"org.apache.flink.kubernetes.operator.exception.ReconciliationException","message":"java.lang.NullPointerException","stackTrace":"org.apache.flink.kubernetes.operator.exception.ReconciliationException:
> java.lang.NullPointerException\n\tat
> org.apache.flink.kubernetes.operator.controller.FlinkDeploymentController.reconcile(FlinkDeploymentController.java:148)\n\tat
>
> org.apache.flink.kubernetes.operator.controller.FlinkDeploymentController.reconcile(FlinkDeploymentController.java:56)\n\tat
>
> io.javaoperatorsdk.operator.processing.Controller$1.execute(Controller.java:138)\n\tat
>
> io.javaoperatorsdk.operator.processing.Controller$1.execute(Controller.java:96)\n\tat
>
> org.apache.flink.kubernetes.operator.metrics.OperatorJosdkMetrics.timeControllerExecution(OperatorJosdkMetrics.java:80)\n\tat
>
> io.javaoperatorsdk.operator.processing.Controller.reconcile(Controller.java:95)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.reconcileExecution(ReconciliationDispatcher.java:139)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.handleReconcile(ReconciliationDispatcher.java:119)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.handleDispatch(ReconciliationDispatcher.java:89)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.handleExecution(ReconciliationDispatcher.java:62)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.EventProcessor$ReconcilerExecutor.run(EventProcessor.java:414)\n\tat
> java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown
> Source)\n\tat
> java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown
> Source)\n\tat java.base/java.lang.Thread.run(Unknown Source)\nCaused by:
> java.lang.NullPointerException\n\tat
> org.apache.flink.kubernetes.utils.KubernetesUtils.checkJarFileForApplicationMode(KubernetesUtils.java:407)\n\tat
>
> org.apache.flink.kubernetes.KubernetesClusterDescriptor.deployApplicationCluster(KubernetesClusterDescriptor.java:207)\n\tat
>
> org.apache.flink.client.deployment.application.cli.ApplicationClusterDeployer.run(ApplicationClusterDeployer.java:67)\n\tat
>
> org.apache.flink.kubernetes.operator.service.NativeFlinkService.deployApplicationCluster(Native","additionalMetadata":{},"throwableList":[{"type":"java.lang.NullPointerException","additionalMetadata":{}}]}
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-33926) Can't start a job with a jar in the system classpath in native k8s mode
[
https://issues.apache.org/jira/browse/FLINK-33926?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916171#comment-17916171
]
Trystan commented on FLINK-33926:
-
I think it makes sense to me. Not sure how something like this is handled with
Flink 2.0 on the horizon, though.
This issue still crops up and bites us from time to time, so I think this would
be a positive change.
> Can't start a job with a jar in the system classpath in native k8s mode
> ---
>
> Key: FLINK-33926
> URL: https://issues.apache.org/jira/browse/FLINK-33926
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Affects Versions: kubernetes-operator-1.6.0
>Reporter: Trystan
>Assignee: Gantigmaa Selenge
>Priority: Major
> Labels: pull-request-available
>
> It appears that the combination of the running operator-controlled jobs in
> native k8s + application mode + using a job jar in the classpath is invalid.
> Avoiding dynamic classloading (as specified in the
> [docs|https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/ops/debugging/debugging_classloading/#avoiding-dynamic-classloading-for-user-code])
> is beneficial for some jobs. This affects at least Flink 1.16.1 and
> Kubernetes Operator 1.6.0.
>
> FLINK-29288 seems to have addressed this for standalone mode. If I am
> misunderstanding how to correctly build jars for this native k8s scenario,
> apologies for the noise and any pointers would be appreciated!
>
> Perhaps related, the [spec
> documentation|https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/docs/custom-resource/reference/#jobspec]
> declares it optional, but isn't clear about under what conditions that
> applies.
> * Putting the jar in the system classpath and pointing *jarURI* to that jar
> leads to linkage errors.
> * Not including *jarURI* leads to NullPointerExceptions in the operator:
> {code:java}
> {"type":"org.apache.flink.kubernetes.operator.exception.ReconciliationException","message":"java.lang.NullPointerException","stackTrace":"org.apache.flink.kubernetes.operator.exception.ReconciliationException:
> java.lang.NullPointerException\n\tat
> org.apache.flink.kubernetes.operator.controller.FlinkDeploymentController.reconcile(FlinkDeploymentController.java:148)\n\tat
>
> org.apache.flink.kubernetes.operator.controller.FlinkDeploymentController.reconcile(FlinkDeploymentController.java:56)\n\tat
>
> io.javaoperatorsdk.operator.processing.Controller$1.execute(Controller.java:138)\n\tat
>
> io.javaoperatorsdk.operator.processing.Controller$1.execute(Controller.java:96)\n\tat
>
> org.apache.flink.kubernetes.operator.metrics.OperatorJosdkMetrics.timeControllerExecution(OperatorJosdkMetrics.java:80)\n\tat
>
> io.javaoperatorsdk.operator.processing.Controller.reconcile(Controller.java:95)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.reconcileExecution(ReconciliationDispatcher.java:139)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.handleReconcile(ReconciliationDispatcher.java:119)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.handleDispatch(ReconciliationDispatcher.java:89)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.ReconciliationDispatcher.handleExecution(ReconciliationDispatcher.java:62)\n\tat
>
> io.javaoperatorsdk.operator.processing.event.EventProcessor$ReconcilerExecutor.run(EventProcessor.java:414)\n\tat
> java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown
> Source)\n\tat
> java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown
> Source)\n\tat java.base/java.lang.Thread.run(Unknown Source)\nCaused by:
> java.lang.NullPointerException\n\tat
> org.apache.flink.kubernetes.utils.KubernetesUtils.checkJarFileForApplicationMode(KubernetesUtils.java:407)\n\tat
>
> org.apache.flink.kubernetes.KubernetesClusterDescriptor.deployApplicationCluster(KubernetesClusterDescriptor.java:207)\n\tat
>
> org.apache.flink.client.deployment.application.cli.ApplicationClusterDeployer.run(ApplicationClusterDeployer.java:67)\n\tat
>
> org.apache.flink.kubernetes.operator.service.NativeFlinkService.deployApplicationCluster(Native","additionalMetadata":{},"throwableList":[{"type":"java.lang.NullPointerException","additionalMetadata":{}}]}
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
Re: [PR] [BP-2.0][FLINK-37099][docs] Document memory/performance considerations and config possibilities for Netty4 [flink]
flinkbot commented on PR #26056: URL: https://github.com/apache/flink/pull/26056#issuecomment-2608371874 ## CI report: * ea7a81374111aed2e7869ef3e8860e7fe41146e1 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-37177][Doc] Update chinese documentation of json function [flink]
flinkbot commented on PR #26055: URL: https://github.com/apache/flink/pull/26055#issuecomment-2607876888 ## CI report: * 3f2569c82e8b1ba329f9a25dd86fb883ae5f11b7 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36698][pipeline-connector][elasticsearch] Elasticsearch Pipeline Connector support index sharding [flink-cdc]
beryllw commented on code in PR #3723:
URL: https://github.com/apache/flink-cdc/pull/3723#discussion_r1926193705
##
docs/content/docs/connectors/pipeline-connectors/elasticsearch.md:
##
@@ -169,7 +169,7 @@ Pipeline Connector Options
optional
(none)
Long
- Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Tables
are separated by ';'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
+ Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Default
sharding column is first partition column.Tables are separated by ';'.Table and
column are separated by ':'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
Review Comment:
agree
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Re: [PR] [FLINK-36698][pipeline-connector][elasticsearch] Elasticsearch Pipeline Connector support index sharding [flink-cdc]
beryllw commented on code in PR #3723:
URL: https://github.com/apache/flink-cdc/pull/3723#discussion_r1926193705
##
docs/content/docs/connectors/pipeline-connectors/elasticsearch.md:
##
@@ -169,7 +169,7 @@ Pipeline Connector Options
optional
(none)
Long
- Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Tables
are separated by ';'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
+ Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Default
sharding column is first partition column.Tables are separated by ';'.Table and
column are separated by ':'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
Review Comment:
agree
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-32212) Job restarting indefinitely after an IllegalStateException from BlobLibraryCacheManager
[
https://issues.apache.org/jira/browse/FLINK-32212?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916238#comment-17916238
]
Vineeth Naroju commented on FLINK-32212:
We encountered same error just now in Flink 1.16.2 and 1.8.0 k8s operator.
I was debugging an issue with flink + kafka job, then I killed job manager pod
in k9s, it went into image pull back error due to missing image and after
resolving it, all jm and tm pods threw same error. This happened during a flink
job that was unable to consume from kafka topic while restarting job manager
with old and new task managers alive.
> Job restarting indefinitely after an IllegalStateException from
> BlobLibraryCacheManager
> ---
>
> Key: FLINK-32212
> URL: https://issues.apache.org/jira/browse/FLINK-32212
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.16.1
> Environment: Apache Flink Kubernetes Operator 1.4
>Reporter: Matheus Felisberto
>Priority: Major
>
> After running for a few hours the job starts to throw IllegalStateException
> and I can't figure out why. To restore the job, I need to manually delete the
> FlinkDeployment to be recreated and redeploy everything.
> The jar is built-in into the docker image, hence is defined accordingly with
> the Operator's documentation:
> {code:java}
> // jarURI: local:///opt/flink/usrlib/my-job.jar {code}
> I've tried to move it into /opt/flink/lib/my-job.jar but it didn't work
> either.
>
> {code:java}
> // Source: my-topic (1/2)#30587
> (b82d2c7f9696449a2d9f4dc298c0a008_bc764cd8ddf7a0cff126f51c16239658_0_30587)
> switched from DEPLOYING to FAILED with failure cause:
> java.lang.IllegalStateException: The library registration references a
> different set of library BLOBs than previous registrations for this job:
> old:[p-5d91888083d38a3ff0b6c350f05a3013632137c6-7237ecbb12b0b021934b0c81aef78396]
> new:[p-5d91888083d38a3ff0b6c350f05a3013632137c6-943737c6790a3ec6870cecd652b956c2]
> at
> org.apache.flink.runtime.execution.librarycache.BlobLibraryCacheManager$ResolvedClassLoader.verifyClassLoader(BlobLibraryCacheManager.java:419)
> at
> org.apache.flink.runtime.execution.librarycache.BlobLibraryCacheManager$ResolvedClassLoader.access$500(BlobLibraryCacheManager.java:359)
> at
> org.apache.flink.runtime.execution.librarycache.BlobLibraryCacheManager$LibraryCacheEntry.getOrResolveClassLoader(BlobLibraryCacheManager.java:235)
> at
> org.apache.flink.runtime.execution.librarycache.BlobLibraryCacheManager$LibraryCacheEntry.access$1100(BlobLibraryCacheManager.java:202)
> at
> org.apache.flink.runtime.execution.librarycache.BlobLibraryCacheManager$DefaultClassLoaderLease.getOrResolveClassLoader(BlobLibraryCacheManager.java:336)
> at
> org.apache.flink.runtime.taskmanager.Task.createUserCodeClassloader(Task.java:1024)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:612)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:550)
> at java.base/java.lang.Thread.run(Unknown Source) {code}
> If there is any other information that can help to identify the problem,
> please let me know.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
He-Pin commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607805457 Would you like to comment on the pr against 1.1.x too. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [1.20][FLINK-37100][tests] Fix `test_netty_shuffle_memory_control.sh` in CI for JDK11+ [flink]
afedulov commented on PR #25955: URL: https://github.com/apache/flink/pull/25955#issuecomment-2607804741 @He-Pin now that it is confirmed that the "unpooled" config solves the issue for us, how realistic do you think it is to get a Pekko release with the allocator config support included soon? @ferenc-csaky I would prefer not to postpone much longer unless we get the Pekko release ASAP. Please drop a line in response to @pjfanning's question here: https://github.com/apache/pekko/pull/1709#issuecomment-2605291102 In parallel, let's assume that there won't be a new Pekko release in the upcoming day or two. Should we simply bump from 7 to 12MB and hope it does it, what do you think? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-37148) Add documentation for datastream v2 api
[ https://issues.apache.org/jira/browse/FLINK-37148?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-37148: --- Labels: pull-request-available (was: ) > Add documentation for datastream v2 api > --- > > Key: FLINK-37148 > URL: https://issues.apache.org/jira/browse/FLINK-37148 > Project: Flink > Issue Type: New Feature >Reporter: Weijie Guo >Assignee: xuhuang >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-37201) FlinkCDC Pipeline transform arithmetic functions support parameters of null and more numerical types.
[ https://issues.apache.org/jira/browse/FLINK-37201?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Leonard Xu reassigned FLINK-37201: -- Assignee: Wenkai Qi > FlinkCDC Pipeline transform arithmetic functions support parameters of null > and more numerical types. > - > > Key: FLINK-37201 > URL: https://issues.apache.org/jira/browse/FLINK-37201 > Project: Flink > Issue Type: Improvement > Components: Flink CDC >Affects Versions: cdc-3.3.0 >Reporter: Wenkai Qi >Assignee: Wenkai Qi >Priority: Major > Labels: pull-request-available > Original Estimate: 24h > Remaining Estimate: 24h > > FlinkCDC Pipeline transform arithmetic functions can not support parameters > of null and more numerical types. For example: ceil, floor, round and abs. > When the input parameter is null or a numerical type such as int, the program > will have an error. > I have fixed it. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-37200) Add e2e test for ElasticSearch Sink.
[ https://issues.apache.org/jira/browse/FLINK-37200?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Leonard Xu reassigned FLINK-37200: -- Assignee: Yanquan Lv > Add e2e test for ElasticSearch Sink. > > > Key: FLINK-37200 > URL: https://issues.apache.org/jira/browse/FLINK-37200 > Project: Flink > Issue Type: Improvement > Components: Flink CDC >Affects Versions: cdc-3.3.0 >Reporter: Yanquan Lv >Assignee: Yanquan Lv >Priority: Major > Fix For: cdc-3.4.0 > > > Add e2e test for ElasticSearch Sink. > For example: > ``` > source: > type: mysql > name: MySQL Source > hostname: 127.0.0.1 > port: 3306 > username: admin > password: pass > tables: adb.\.*, bdb.user_table_[0-9]+, [app|web].order_\.* > server-id: 5401-5404 > sink: > type: elasticsearch > name: Elasticsearch Sink > hosts: http://127.0.0.1:9092,http://127.0.0.1:9093 > route: > - source-table: adb.\.* > sink-table: default_index > description: sync adb.\.* table to default_index > pipeline: > name: MySQL to Elasticsearch Pipeline > parallelism: 2 > ``` > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-35671) Support Iceberg CDC Pipeline Sink
[ https://issues.apache.org/jira/browse/FLINK-35671?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916246#comment-17916246 ] Leonard Xu commented on FLINK-35671: Hey [~m.orazow] , do you have time to work for this ticket? > Support Iceberg CDC Pipeline Sink > - > > Key: FLINK-35671 > URL: https://issues.apache.org/jira/browse/FLINK-35671 > Project: Flink > Issue Type: Improvement > Components: Flink CDC >Reporter: Muhammet Orazov >Assignee: Muhammet Orazov >Priority: Major > Fix For: cdc-3.4.0 > > > Similar to other [CDC pipeline > sinks|https://nightlies.apache.org/flink/flink-cdc-docs-master/docs/connectors/pipeline-connectors/overview/], > we should support Iceberg as a pipeline sink. -- This message was sent by Atlassian Jira (v8.20.10#820010)
Re: [PR] Draft: [FLINK-36061] Support Iceberg CDC Pipeline SinkV2 [flink-cdc]
melin commented on PR #3877: URL: https://github.com/apache/flink-cdc/pull/3877#issuecomment-2608746353 Add compaction optimization? For example, commit 100 times and execute a compaction. Similar to this demos approach: https://github.com/aws-samples/iceberg-streaming-examples/blob/main/src/main/java/com/aws/emr/spark/iot/SparkCustomIcebergIngest.java -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
Re: [PR] [FLINK-36698][pipeline-connector][elasticsearch] Elasticsearch Pipeline Connector support index sharding [flink-cdc]
beryllw commented on code in PR #3723:
URL: https://github.com/apache/flink-cdc/pull/3723#discussion_r1926291799
##
docs/content/docs/connectors/pipeline-connectors/elasticsearch.md:
##
@@ -169,7 +169,7 @@ Pipeline Connector Options
optional
(none)
Long
- Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Tables
are separated by ';'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
+ Sharding suffix key for each table, allow setting sharding suffix
key for multiTables.Default sink table name is test_table${suffix_key}.Default
sharding column is first partition column.Tables are separated by ';'.Table and
column are separated by ':'.For example, we can set sharding.suffix.key by
'table1:col1;table2:col2'.
Review Comment:
May be '_' is better?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Resolved] (FLINK-36061) Support Apache iceberg for pipeline connector
[ https://issues.apache.org/jira/browse/FLINK-36061?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Leonard Xu resolved FLINK-36061. Resolution: Duplicate > Support Apache iceberg for pipeline connector > - > > Key: FLINK-36061 > URL: https://issues.apache.org/jira/browse/FLINK-36061 > Project: Flink > Issue Type: New Feature > Components: Flink CDC >Reporter: ZhengYu Chen >Priority: Major > Labels: pull-request-available > Fix For: cdc-3.4.0 > > > Support Apache iceberg for pipeline connector -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-36061) Support Apache iceberg for pipeline connector
[ https://issues.apache.org/jira/browse/FLINK-36061?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916248#comment-17916248 ] Leonard Xu commented on FLINK-36061: [~rmoff]You're right, this is a duplicated issue and should be closed soon. I've pinged the contributor of FLINK-35671, will assign that ticket to you [~czy006] after some days as that issue has not any progress in past half a year. > Support Apache iceberg for pipeline connector > - > > Key: FLINK-36061 > URL: https://issues.apache.org/jira/browse/FLINK-36061 > Project: Flink > Issue Type: New Feature > Components: Flink CDC >Reporter: ZhengYu Chen >Priority: Major > Labels: pull-request-available > Fix For: cdc-3.4.0 > > > Support Apache iceberg for pipeline connector -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-36061) Support Apache iceberg for pipeline connector
[ https://issues.apache.org/jira/browse/FLINK-36061?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916250#comment-17916250 ] Leonard Xu commented on FLINK-36061: [~melin] +1 for your proposal, compaction optimization is necessary for lake format Sink. > Support Apache iceberg for pipeline connector > - > > Key: FLINK-36061 > URL: https://issues.apache.org/jira/browse/FLINK-36061 > Project: Flink > Issue Type: New Feature > Components: Flink CDC >Reporter: ZhengYu Chen >Priority: Major > Labels: pull-request-available > Fix For: cdc-3.4.0 > > > Support Apache iceberg for pipeline connector -- This message was sent by Atlassian Jira (v8.20.10#820010)
Re: [PR] [FLINK-37120][pipeline-connector/mysql] Add ending split chunk first to avoid TaskManager oom [flink-cdc]
beryllw commented on PR #3856: URL: https://github.com/apache/flink-cdc/pull/3856#issuecomment-2608748868 > LGTM. I'm worried if this parameter is a bit complicated, what about naming it `scan.incremental.assign-max-chunk-first.enabled` to avoid using `ending`? As `chunk` is a concept in snapshot phase. WDYT @beryllw @leonardBang? What about 'scan.incremental.assign-ending-chunk-first.enabled', when the write throughput is low, the ending chunk is not equal to the maximum chunk. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-36838) [state] Join background threads when ForSt state backend quit
[ https://issues.apache.org/jira/browse/FLINK-36838?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17916258#comment-17916258 ] Zakelly Lan commented on FLINK-36838: - follow-up merge: * master: 7b2e9c410344126a265ed318c81f9b9cad8fbe63 * 2.0: c6265bff574afb1cbee41ff68bb7ebde7a7b1de9 > [state] Join background threads when ForSt state backend quit > - > > Key: FLINK-36838 > URL: https://issues.apache.org/jira/browse/FLINK-36838 > Project: Flink > Issue Type: Sub-task > Components: Runtime / State Backends >Reporter: Zakelly Lan >Assignee: Zakelly Lan >Priority: Major > Labels: pull-request-available > Fix For: 2.0.0 > > > Currently there is an issue in the forst db core, where the background cannot > properly quit when db close. Thus we manually join those threads in backend > side. This is a temporary solution until the forst db fix the bug. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-37161) Cross-team verification for "Adaptive skewed join optimization for batch jobs"
[
https://issues.apache.org/jira/browse/FLINK-37161?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Junrui Lee updated FLINK-37161:
---
Description:
In Flink 2.0, we support the capability of adaptive skewed join optimization
for batch jobs, which will allow the Join operator to dynamically split skewed
and splittable partitions based on runtime input statistics, thereby mitigating
the long-tail problem caused by skewed data.
We may need the following tests:
#
Test the case where {{table.optimizer.skewed-join-optimization.strategy}} is
set to {{{}auto{}}}. We need to construct a simple join case with data skewed
on a single key (e.g., making the data of a specified join key N times larger
than other join keys, where N is defined by
{{{}table.optimizer.skewed-join-optimization.skewed-factor{}}}). And ensuring
the data volume for the skewed join key exceeds the skewed-threshold (defined
by {{{}table.optimizer.skewed-join-optimization.skewed-threshold{}}}). Finally,
observe whether the ratio of the maximum data volume to the median data volume
processed by concurrent join tasks is less than the skew factor.
#
Test the case where {{table.optimizer.skewed-join-optimization.strategy}} is
set to {{{}forced{}}}. Construct a skewed join instance similar to Test 1, but
with the following difference: the join case should be connected to a
downstream operator that performs hashing on the same field (e.g., hash
aggregation or group by). It is recommended to set different parallelisms for
the join operator and the downstream operator to prevent the out edge from
being optimized to a forward edge. Finally, observe whether the ratio of the
maximum data volume to the median data volume processed by concurrent join
tasks is less than the skew factor.
#
Test the case where {{{}table.optimizer.skewed-join-optimization.strategy{}}}as
none, and verify that the join operator will not be optimized into an adaptive
join operator under any circumstances.
# Test the case with customized
{{{}table.optimizer.skewed-join-optimization.skewed-factor{}}}. We need to
construct a skewed join instance similar to Test 1, setting different skewed
factors and observing whether the ratio of the maximum data volume to the
median data volume processed by concurrent join tasks is less than the skew
factor. Note that currently, Flink can only reduce the ratio to 2.0, and please
ensure that the skewed-factor is greater than 2.0 during testing.
# Test the case with customized
{{{}table.optimizer.skewed-join-optimization.skewed-threshold{}}}. We need to
construct a skewed join instance similar to Test 1, setting different
skewed-threshold and observing whether the optimization is effective only when
the data volume processed by the skewed join instance is greater than the
skewed threshold.
was:
In Flink 2.0, we support the capability of adaptive skewed join optimization
for batch jobs, which will allow the Join operator to dynamically split skewed
and splittable partitions based on runtime input statistics, thereby mitigating
the long-tail problem caused by skewed data.
We may need the following tests:
#
Test the case where {{table.optimizer.skewed-join-optimization.strategy}} is
set to {{{}auto{}}}. We need to construct a simple join case with data skewed
on a single key (e.g., making the data of a specified join key N times larger
than other join keys, where N is defined by
{{{}table.optimizer.skewed-join-optimization.skewed-factor{}}}). And ensuring
the data volume for the skewed join key exceeds the skewed-threshold (defined
by {{{}table.optimizer.skewed-join-optimization.skewed-threshold{}}}). Finally,
observe whether the ratio of the maximum data volume to the median data volume
processed by concurrent join tasks is less than the skew factor.
#
Test the case where {{table.optimizer.skewed-join-optimization.strategy}} is
set to {{{}forced{}}}. Construct a skewed join instance similar to Test 1, but
with the following difference: the join case should be connected to a
downstream operator that performs hashing on the same field (e.g., hash
aggregation or group by). It is recommended to set different parallelisms for
the join operator and the downstream operator to prevent the out edge from
being optimized to a forward edge. Finally, observe whether the ratio of the
maximum data volume to the median data volume processed by concurrent join
tasks is less than the skew factor.
#
Test the case where {{{}table.optimizer.skewed-join-optimization.strategy{}}}as
none, and verify that the join operator will not be optimized into an adaptive
join operator under any circumstances.
#
Test the case with customized
{{{}table.optimizer.skewed-join-optimization.skewed-factor{}}}. We need to
construct a skewed join instance similar to Test 1, setting different skewed
factors and observing whether the ratio of the maximum dat