[GitHub] [flink] ljz2051 opened a new pull request, #23407: [FLINK-32953][docs]Add notes about changing state ttl value
ljz2051 opened a new pull request, #23407: URL: https://github.com/apache/flink/pull/23407 ## What is the purpose of the change This pull request add notes about changing state TTL value when restore checkpoint. ## Brief change log - Add a note in "state.md" document. ## Verifying this change This change is a trivial work about document without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-32953) [State TTL]resolve data correctness problem after ttl was changed
[ https://issues.apache.org/jira/browse/FLINK-32953?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-32953: --- Labels: pull-request-available (was: ) > [State TTL]resolve data correctness problem after ttl was changed > -- > > Key: FLINK-32953 > URL: https://issues.apache.org/jira/browse/FLINK-32953 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Reporter: Jinzhong Li >Assignee: Jinzhong Li >Priority: Major > Labels: pull-request-available > > Because expired data is cleaned up in background on a best effort basis > (hashmap use INCREMENTAL_CLEANUP strategy, rocksdb use > ROCKSDB_COMPACTION_FILTER strategy), some expired state is often persisted > into snapshots. > > In some scenarios, user changes the state ttl of the job and then restore job > from the old state. If the user adjust the state ttl from a short value to a > long value (eg, from 12 hours to 24 hours), some expired data that was not > cleaned up will be alive after restore. Obviously this is unreasonable, and > may break data regulatory requirements. > > Particularly, rocksdb stateBackend may cause data correctness problems due to > level compaction in this case.(eg. One key has two versions at level-1 and > level-2,both of which are ttl expired. Then level-1 version is cleaned up by > compaction, and level-2 version isn't. If we adjust state ttl and restart > job, the incorrect data of level-2 will become valid after restore) > > To solve this problem, I think we can > 1) persist old state ttl into snapshot meta info; (eg. > RegisteredKeyValueStateBackendMetaInfo or others) > 2) During state restore, check the size between the current ttl and old ttl; > 3) If current ttl is longer than old ttl, we need to iterate over all data, > filter out expired data with old ttl, and wirte valid data into stateBackend. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-33080) The checkpoint storage configured in the job level by config option will not take effect
Junrui Li created FLINK-33080:
-
Summary: The checkpoint storage configured in the job level by
config option will not take effect
Key: FLINK-33080
URL: https://issues.apache.org/jira/browse/FLINK-33080
Project: Flink
Issue Type: Bug
Components: Runtime / State Backends
Reporter: Junrui Li
Fix For: 1.19.0
When we configure the checkpoint storage at the job level, it can only be done
through the following method:
{code:java}
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointStorage(xxx); {code}
However, configure the checkpoint storage by the job-side configuration like
the following will not take effect:
{code:java}
Configuration configuration = new Configuration();
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(configuration);
configuration.set(CheckpointingOptions.CHECKPOINT_STORAGE, "filesystem");
configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
{code}
This behavior is unexpected, we should allow this way will take effect.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Assigned] (FLINK-33080) The checkpoint storage configured in the job level by config option will not take effect
[
https://issues.apache.org/jira/browse/FLINK-33080?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lijie Wang reassigned FLINK-33080:
--
Assignee: Junrui Li
> The checkpoint storage configured in the job level by config option will not
> take effect
>
>
> Key: FLINK-33080
> URL: https://issues.apache.org/jira/browse/FLINK-33080
> Project: Flink
> Issue Type: Bug
> Components: Runtime / State Backends
>Reporter: Junrui Li
>Assignee: Junrui Li
>Priority: Major
> Fix For: 1.19.0
>
>
> When we configure the checkpoint storage at the job level, it can only be
> done through the following method:
> {code:java}
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment();
> env.getCheckpointConfig().setCheckpointStorage(xxx); {code}
> However, configure the checkpoint storage by the job-side configuration like
> the following will not take effect:
> {code:java}
> Configuration configuration = new Configuration();
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment(configuration);
> configuration.set(CheckpointingOptions.CHECKPOINT_STORAGE, "filesystem");
> configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
> {code}
> This behavior is unexpected, we should allow this way will take effect.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #23407: [FLINK-32953][docs]Add notes about changing state ttl value
flinkbot commented on PR #23407: URL: https://github.com/apache/flink/pull/23407#issuecomment-1717067773 ## CI report: * f59f7f7004c10ba16d2cdbb1dec363964414880c UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-32953) [State TTL]resolve data correctness problem after ttl was changed
[ https://issues.apache.org/jira/browse/FLINK-32953?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764518#comment-17764518 ] Jinzhong Li commented on FLINK-32953: - [~masteryhx] I publish a pr which add some notes about this issue in document. Could you please help review the pr? > [State TTL]resolve data correctness problem after ttl was changed > -- > > Key: FLINK-32953 > URL: https://issues.apache.org/jira/browse/FLINK-32953 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Reporter: Jinzhong Li >Assignee: Jinzhong Li >Priority: Major > Labels: pull-request-available > > Because expired data is cleaned up in background on a best effort basis > (hashmap use INCREMENTAL_CLEANUP strategy, rocksdb use > ROCKSDB_COMPACTION_FILTER strategy), some expired state is often persisted > into snapshots. > > In some scenarios, user changes the state ttl of the job and then restore job > from the old state. If the user adjust the state ttl from a short value to a > long value (eg, from 12 hours to 24 hours), some expired data that was not > cleaned up will be alive after restore. Obviously this is unreasonable, and > may break data regulatory requirements. > > Particularly, rocksdb stateBackend may cause data correctness problems due to > level compaction in this case.(eg. One key has two versions at level-1 and > level-2,both of which are ttl expired. Then level-1 version is cleaned up by > compaction, and level-2 version isn't. If we adjust state ttl and restart > job, the incorrect data of level-2 will become valid after restore) > > To solve this problem, I think we can > 1) persist old state ttl into snapshot meta info; (eg. > RegisteredKeyValueStateBackendMetaInfo or others) > 2) During state restore, check the size between the current ttl and old ttl; > 3) If current ttl is longer than old ttl, we need to iterate over all data, > filter out expired data with old ttl, and wirte valid data into stateBackend. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (FLINK-30400) Stop bundling connector-base in externalized connectors
[ https://issues.apache.org/jira/browse/FLINK-30400?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Leonard Xu reassigned FLINK-30400: -- Assignee: Hang Ruan > Stop bundling connector-base in externalized connectors > --- > > Key: FLINK-30400 > URL: https://issues.apache.org/jira/browse/FLINK-30400 > Project: Flink > Issue Type: Improvement > Components: Connectors / Common >Reporter: Chesnay Schepler >Assignee: Hang Ruan >Priority: Major > > Check that none of the externalized connectors bundle connector-base; if so > remove the bundling and schedule a new minor release. > Bundling this module is highly problematic w.r.t. binary compatibility, since > bundled classes may rely on internal APIs. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-33080) The checkpoint storage configured in the job level by config option will not take effect
[
https://issues.apache.org/jira/browse/FLINK-33080?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Junrui Li updated FLINK-33080:
--
Description:
When we configure the checkpoint storage at the job level, it can only be done
through the following method:
{code:java}
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointStorage(xxx); {code}
or configure filesystem storage by config option
CheckpointingOptions.CHECKPOINTS_DIRECTORY through the following method:
{code:java}
Configuration configuration = new Configuration();
configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(configuration);{code}
However, configure the other type checkpoint storage by the job-side
configuration like the following will not take effect:
{code:java}
Configuration configuration = new Configuration();
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(configuration);
configuration.set(CheckpointingOptions.CHECKPOINT_STORAGE,
"aaa.bbb.ccc.CustomCheckpointStorage");
configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
{code}
This behavior is unexpected, we should allow this way will take effect.
was:
When we configure the checkpoint storage at the job level, it can only be done
through the following method:
{code:java}
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointStorage(xxx); {code}
However, configure the checkpoint storage by the job-side configuration like
the following will not take effect:
{code:java}
Configuration configuration = new Configuration();
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(configuration);
configuration.set(CheckpointingOptions.CHECKPOINT_STORAGE, "filesystem");
configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
{code}
This behavior is unexpected, we should allow this way will take effect.
> The checkpoint storage configured in the job level by config option will not
> take effect
>
>
> Key: FLINK-33080
> URL: https://issues.apache.org/jira/browse/FLINK-33080
> Project: Flink
> Issue Type: Bug
> Components: Runtime / State Backends
>Reporter: Junrui Li
>Assignee: Junrui Li
>Priority: Major
> Fix For: 1.19.0
>
>
> When we configure the checkpoint storage at the job level, it can only be
> done through the following method:
> {code:java}
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment();
> env.getCheckpointConfig().setCheckpointStorage(xxx); {code}
> or configure filesystem storage by config option
> CheckpointingOptions.CHECKPOINTS_DIRECTORY through the following method:
> {code:java}
> Configuration configuration = new Configuration();
> configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment(configuration);{code}
> However, configure the other type checkpoint storage by the job-side
> configuration like the following will not take effect:
> {code:java}
> Configuration configuration = new Configuration();
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment(configuration);
> configuration.set(CheckpointingOptions.CHECKPOINT_STORAGE,
> "aaa.bbb.ccc.CustomCheckpointStorage");
> configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
> {code}
> This behavior is unexpected, we should allow this way will take effect.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-ml] lindong28 commented on a diff in pull request #248: [FLINK-32704] Supports spilling to disk when feedback channel memory buffer is full
lindong28 commented on code in PR #248:
URL: https://github.com/apache/flink-ml/pull/248#discussion_r1299531846
##
flink-ml-iteration/flink-ml-iteration-common/src/main/java/org/apache/flink/iteration/operator/feedback/SpillableFeedbackQueue.java:
##
@@ -0,0 +1,115 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.iteration.operator.feedback;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.core.memory.DataInputView;
+import org.apache.flink.core.memory.DataOutputSerializer;
+import org.apache.flink.core.memory.MemorySegment;
+import org.apache.flink.runtime.io.disk.InputViewIterator;
+import org.apache.flink.runtime.io.disk.SpillingBuffer;
+import org.apache.flink.runtime.io.disk.iomanager.IOManager;
+import org.apache.flink.runtime.memory.MemoryAllocationException;
+import org.apache.flink.runtime.memory.MemoryManager;
+import org.apache.flink.table.runtime.operators.sort.ListMemorySegmentPool;
+import org.apache.flink.util.MutableObjectIterator;
+
+import java.io.IOException;
+import java.util.List;
+import java.util.Objects;
+
+/**
+ * * A queue that can spill the items to disks automatically when the memory
buffer is full.
+ *
+ * @param The element type.
+ */
+@Internal
+final class SpillableFeedbackQueue {
+private final DataOutputSerializer output = new DataOutputSerializer(256);
+private final TypeSerializer serializer;
+private final IOManager ioManager;
+private final MemoryManager memoryManager;
+private final int numPages;
+
+private List segments;
+private ListMemorySegmentPool segmentPool;
+
+private SpillingBuffer target;
+private long size = 0L;
+
+SpillableFeedbackQueue(
+IOManager ioManager,
+MemoryManager memoryManager,
+TypeSerializer serializer,
+long inMemoryBufferSize,
+long pageSize)
+throws MemoryAllocationException {
+this.serializer = Objects.requireNonNull(serializer);
+this.ioManager = Objects.requireNonNull(ioManager);
+this.memoryManager = Objects.requireNonNull(memoryManager);
+
+this.numPages = (int) (inMemoryBufferSize / pageSize);
+resetSpillingBuffer();
+}
+
+void add(T item) {
+try {
+output.clear();
+serializer.serialize(item, output);
+target.write(output.getSharedBuffer(), 0, output.length());
+size++;
+} catch (IOException e) {
+throw new IllegalStateException(e);
+}
+}
+
+MutableObjectIterator iterate() {
+try {
+DataInputView input = target.flip();
+return new InputViewIterator<>(input, this.serializer);
+} catch (IOException e) {
+throw new RuntimeException(e);
+}
+}
+
+long size() {
+return size;
+}
+
+void reset() throws Exception {
+size = 0;
+close();
+resetSpillingBuffer();
Review Comment:
Just to summarize our offline discussions:
- Currently MemoryManager#allocatePages will allocate memory from JVM rather
than re-using allocated memory from a pool. We should avoid this repeated
memory allocation.
- AbstractPagedOutputView, the parent class of SpillingBuffer, provides
clear() and advance() to support writing to a buffer after it has been read. It
might be possible to let `SpillingBuffer` implement these two APIs so that we
can re-use it for writing after it is read.
- NormalizedKeySorter#reset supports re-using a buffer after it is read.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Assigned] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yuan Mei reassigned FLINK-33052: Assignee: Zakelly Lan (was: Yuan Mei) > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Test Infrastructure >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Major > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] JunRuiLee opened a new pull request, #23408: [FLINK-33080][runtime] Make the configured checkpoint storage in the job-side configuration will take effect.
JunRuiLee opened a new pull request, #23408: URL: https://github.com/apache/flink/pull/23408 ## What is the purpose of the change Make the configured checkpoint storage in the job-side configuration will take effect. ## Brief change log Load checkpoint storage from configuration when configure checkpointConfig ## Verifying this change This change added tests and can be verified as follows: StreamContextEnvironmentTest#testDisallowCheckpointStorageByConfiguration StreamExecutionEnvironmentTest#testConfigureCheckpointStorage ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / **not documented**) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-33080) The checkpoint storage configured in the job level by config option will not take effect
[
https://issues.apache.org/jira/browse/FLINK-33080?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-33080:
---
Labels: pull-request-available (was: )
> The checkpoint storage configured in the job level by config option will not
> take effect
>
>
> Key: FLINK-33080
> URL: https://issues.apache.org/jira/browse/FLINK-33080
> Project: Flink
> Issue Type: Bug
> Components: Runtime / State Backends
>Reporter: Junrui Li
>Assignee: Junrui Li
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.19.0
>
>
> When we configure the checkpoint storage at the job level, it can only be
> done through the following method:
> {code:java}
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment();
> env.getCheckpointConfig().setCheckpointStorage(xxx); {code}
> or configure filesystem storage by config option
> CheckpointingOptions.CHECKPOINTS_DIRECTORY through the following method:
> {code:java}
> Configuration configuration = new Configuration();
> configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment(configuration);{code}
> However, configure the other type checkpoint storage by the job-side
> configuration like the following will not take effect:
> {code:java}
> Configuration configuration = new Configuration();
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment(configuration);
> configuration.set(CheckpointingOptions.CHECKPOINT_STORAGE,
> "aaa.bbb.ccc.CustomCheckpointStorage");
> configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, checkpointDir);
> {code}
> This behavior is unexpected, we should allow this way will take effect.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #23408: [FLINK-33080][runtime] Make the configured checkpoint storage in the job-side configuration will take effect.
flinkbot commented on PR #23408: URL: https://github.com/apache/flink/pull/23408#issuecomment-1717151891 ## CI report: * 9960939d8f00229a2cd201c2a9a87db4e90a5c10 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaborgsomogyi commented on pull request #23359: [FLINK-33029][python] Drop python 3.7 support
gaborgsomogyi commented on PR #23359: URL: https://github.com/apache/flink/pull/23359#issuecomment-1717171777 Asked in the dev discussion thread whether somebody has addition, nothing arrived so I would say yes. I'm intended to merge it soon... -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-32863) Improve Flink UI's time precision from second level to millisecond level
[ https://issues.apache.org/jira/browse/FLINK-32863?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yangze Guo reassigned FLINK-32863: -- Assignee: Jufang He > Improve Flink UI's time precision from second level to millisecond level > > > Key: FLINK-32863 > URL: https://issues.apache.org/jira/browse/FLINK-32863 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Web Frontend >Affects Versions: 1.17.1 >Reporter: Runkang He >Assignee: Jufang He >Priority: Major > Labels: pull-request-available > > This an UI improvement for OLAP jobs. > OLAP queries are generally small queries which will finish at the seconds or > milliseconds, but currently the time precision displayed is second level and > not enough for OLAP queries. Millisecond part of time is very important for > users and developers, to see accurate time, for performance measurement and > optimization. The displayed time includes job duration, task duration, task > start time, end time and so on. > It would be nice to improve this for better OLAP user experience. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] KarmaGYZ commented on a diff in pull request #23403: [FLINK-32863][runtime-web] Improve Flink UI's time precision from sec…
KarmaGYZ commented on code in PR #23403:
URL: https://github.com/apache/flink/pull/23403#discussion_r1324171749
##
flink-runtime-web/web-dashboard/src/app/components/humanize-duration.pipe.ts:
##
@@ -46,23 +46,23 @@ export class HumanizeDurationPipe implements PipeTransform {
if (seconds === 0) {
return `${ms}ms`;
} else {
- return `${seconds}s`;
+ return `${seconds}s ${ms}ms`;
}
} else {
-return `${minutes}m ${seconds}s`;
+return `${minutes}m ${seconds}s ${ms}ms`;
}
} else {
if (short) {
return `${hours}h ${minutes}m`;
} else {
-return `${hours}h ${minutes}m ${seconds}s`;
+return `${hours}h ${minutes}m ${seconds}s ${ms}ms`;
}
}
} else {
if (short) {
return `${days}d ${hours}h`;
} else {
- return `${days}d ${hours}h ${minutes}m ${seconds}s`;
+ return `${days}d ${hours}h ${minutes}m ${seconds}s ${ms}ms`;
Review Comment:
nit: I think the explicit ms might be useless for jobs longer than 1h.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Closed] (FLINK-31387) StreamTaskCancellationTest.testCancelTaskShouldPreventAdditionalProcessingTimeTimersFromBeingFired failed with an assertion
[
https://issues.apache.org/jira/browse/FLINK-31387?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Piotr Nowojski closed FLINK-31387.
--
> StreamTaskCancellationTest.testCancelTaskShouldPreventAdditionalProcessingTimeTimersFromBeingFired
> failed with an assertion
> ---
>
> Key: FLINK-31387
> URL: https://issues.apache.org/jira/browse/FLINK-31387
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.18.0
>Reporter: Matthias Pohl
>Assignee: David Morávek
>Priority: Critical
> Labels: pull-request-available, test-stability
> Fix For: 1.18.0
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=46994&view=logs&j=0da23115-68bb-5dcd-192c-bd4c8adebde1&t=24c3384f-1bcb-57b3-224f-51bf973bbee8&l=9253
> {code}
> Mar 09 14:04:42 [ERROR]
> org.apache.flink.streaming.runtime.tasks.StreamTaskCancellationTest.testCancelTaskShouldPreventAdditionalProcessingTimeTimersFromBeingFired
> Time elapsed: 0.018 s <<< FAILURE!
> Mar 09 14:04:42 java.lang.AssertionError:
> Mar 09 14:04:42
> Mar 09 14:04:42 Expecting AtomicInteger(0) to have value:
> Mar 09 14:04:42 10
> Mar 09 14:04:42 but did not.
> Mar 09 14:04:42 at
> org.apache.flink.streaming.runtime.tasks.StreamTaskCancellationTest.testCancelTaskShouldPreventAdditionalTimersFromBeingFired(StreamTaskCancellationTest.java:305)
> Mar 09 14:04:42 at
> org.apache.flink.streaming.runtime.tasks.StreamTaskCancellationTest.testCancelTaskShouldPreventAdditionalProcessingTimeTimersFromBeingFired(StreamTaskCancellationTest.java:281)
> Mar 09 14:04:42 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
> Method)
> [...]
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] hejufang commented on a diff in pull request #23403: [FLINK-32863][runtime-web] Improve Flink UI's time precision from sec…
hejufang commented on code in PR #23403:
URL: https://github.com/apache/flink/pull/23403#discussion_r1324189387
##
flink-runtime-web/web-dashboard/src/app/components/humanize-duration.pipe.ts:
##
@@ -46,23 +46,23 @@ export class HumanizeDurationPipe implements PipeTransform {
if (seconds === 0) {
return `${ms}ms`;
} else {
- return `${seconds}s`;
+ return `${seconds}s ${ms}ms`;
}
} else {
-return `${minutes}m ${seconds}s`;
+return `${minutes}m ${seconds}s ${ms}ms`;
}
} else {
if (short) {
return `${hours}h ${minutes}m`;
} else {
-return `${hours}h ${minutes}m ${seconds}s`;
+return `${hours}h ${minutes}m ${seconds}s ${ms}ms`;
}
}
} else {
if (short) {
return `${days}d ${hours}h`;
} else {
- return `${days}d ${hours}h ${minutes}m ${seconds}s`;
+ return `${days}d ${hours}h ${minutes}m ${seconds}s ${ms}ms`;
Review Comment:
Thanks for your suggestion, it has been fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (FLINK-33081) Move parallelism override logic into scale method
Gyula Fora created FLINK-33081: -- Summary: Move parallelism override logic into scale method Key: FLINK-33081 URL: https://issues.apache.org/jira/browse/FLINK-33081 Project: Flink Issue Type: Improvement Components: Kubernetes Operator Reporter: Gyula Fora Assignee: Gyula Fora Fix For: kubernetes-operator-1.7.0 After FLINK-32589 the parallelism overrides are applied separately from the scale call of the autoscaler implementation. We should simplify this by a small refactoring -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] maosuhan commented on pull request #23162: [FLINK-32650][protobuf]Added the ability to split flink-protobuf code…
maosuhan commented on PR #23162: URL: https://github.com/apache/flink/pull/23162#issuecomment-1717237735 @ljw-hit Hi, thanks for your effort and the code is already in good shape to me. I have left a few comments about unit tests. And could you provide a benchmark test for this improvement? For example, how much time of encoding/decoding 10M large rows can be saved after this improvement.. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Piotr Nowojski updated FLINK-33052: --- Priority: Blocker (was: Major) > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Test Infrastructure >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Piotr Nowojski updated FLINK-33052: --- Affects Version/s: 1.18.0 > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Piotr Nowojski updated FLINK-33052: --- Component/s: Benchmarks > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764564#comment-17764564 ] Piotr Nowojski commented on FLINK-33052: Thanks for investigating this issue [~jingge]. Let me know [~ym] if you will be having troubles setting this up again. Has the backup FLINK-30890 been preserved? > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-33081) Move parallelism override logic into scale method
[ https://issues.apache.org/jira/browse/FLINK-33081?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-33081: --- Labels: pull-request-available (was: ) > Move parallelism override logic into scale method > - > > Key: FLINK-33081 > URL: https://issues.apache.org/jira/browse/FLINK-33081 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Major > Labels: pull-request-available > Fix For: kubernetes-operator-1.7.0 > > > After FLINK-32589 the parallelism overrides are applied separately from the > scale call of the autoscaler implementation. We should simplify this by a > small refactoring -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] gyfora opened a new pull request, #672: [FLINK-33081] Apply parallelism overrides in scale
gyfora opened a new pull request, #672: URL: https://github.com/apache/flink-kubernetes-operator/pull/672 ## What is the purpose of the change Simplify the scale / parallelism override flow based on previous feedback. This change is a refactor and does not introduce new behaviour. ## Brief change log - *Unify scale / applyParallelismOverride methods* - *Move scaling before reconciling spec diffs* - *Refactor JobAutoscalerImpl and extract some methods to simplify the core flow* ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changes to the `CustomResourceDescriptors`: no - Core observer or reconciler logic that is regularly executed: yes ## Documentation - Does this pull request introduce a new feature? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] echauchot commented on a diff in pull request #22985: [FLINK-21883][scheduler] Implement cooldown period for adaptive scheduler
echauchot commented on code in PR #22985:
URL: https://github.com/apache/flink/pull/22985#discussion_r1324233808
##
flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/adaptive/Executing.java:
##
@@ -124,17 +154,33 @@ private void handleDeploymentFailure(ExecutionVertex
executionVertex, JobExcepti
@Override
public void onNewResourcesAvailable() {
-maybeRescale();
+rescaleWhenCooldownPeriodIsOver();
}
@Override
public void onNewResourceRequirements() {
-maybeRescale();
+rescaleWhenCooldownPeriodIsOver();
}
private void maybeRescale() {
-if (context.shouldRescale(getExecutionGraph())) {
-getLogger().info("Can change the parallelism of job. Restarting
job.");
+final Duration timeSinceLastRescale = timeSinceLastRescale();
+rescaleScheduled = false;
+final boolean shouldForceRescale =
+(scalingIntervalMax != null)
+&& (timeSinceLastRescale.compareTo(scalingIntervalMax)
> 0)
+&& (lastRescale != Instant.EPOCH); // initial rescale
is not forced
+if (shouldForceRescale || context.shouldRescale(getExecutionGraph())) {
+if (shouldForceRescale) {
+getLogger()
+.info(
+"Time since last rescale ({}) > {} ({}).
Force-changing the parallelism of the job. Restarting the job.",
+timeSinceLastRescale,
+
JobManagerOptions.SCHEDULER_SCALING_INTERVAL_MAX.key(),
+scalingIntervalMax);
+} else {
+getLogger().info("Can change the parallelism of the job.
Restarting the job.");
+}
+lastRescale = Instant.now();
context.goToRestarting(
getExecutionGraph(),
Review Comment:
Here is the summary of the offline discussion @1996fanrui and I had about
`scalingIntervalMax` and forcing rescale (current code: when `added resources <
min-parallelism-increase` we force a rescale if `timeSinceLastRescale >
scalingIntervalMax`):
1. aim: the longer the pipeline runs, the more the (small) resource gain is
worth the restarting time.
2. corner case: a resource `< min-parallelism-increase` arrives when
`timeSinceLastRescale < scalingIntervalMax` and the pipeline is running for a
long time (typical case 1) => with the current code, we don't force a rescale
in that case whereas the added resource would be worth the restarting time.
=> I proposed solution 1: changing the definition of `scalingIntervalMax`
to `pipelineRuntimeRescaleMin` meaning pipeline runtime after which we force a
rescale even if `added resources < min-parallelism-increase`
=> @1996fanrui proposed solution 2: if `added resources <
min-parallelism-increase && timeSinceLastRescale < scalingIntervalMax` schedule
a tryRescale (force a rescale if there is indeed a change in the resource graph
at that time in case the last TM crashed) after `scalingIntervalMax`
@zentol you were the one who proposed the addition of `scalingIntervalMax`
in the FLIP discussion thread. Do you prefer solution 1 or solution 2 ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-18356) flink-table-planner Exit code 137 returned from process
[
https://issues.apache.org/jira/browse/FLINK-18356?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764565#comment-17764565
]
Sergey Nuyanzin commented on FLINK-18356:
-
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=53164&view=logs&j=a9db68b9-a7e0-54b6-0f98-010e0aff39e2&t=cdd32e0b-6047-565b-c58f-14054472f1be&l=11710
> flink-table-planner Exit code 137 returned from process
> ---
>
> Key: FLINK-18356
> URL: https://issues.apache.org/jira/browse/FLINK-18356
> Project: Flink
> Issue Type: Bug
> Components: Build System / Azure Pipelines, Tests
>Affects Versions: 1.12.0, 1.13.0, 1.14.0, 1.15.0, 1.16.0, 1.17.0, 1.18.0
>Reporter: Piotr Nowojski
>Assignee: Yunhong Zheng
>Priority: Critical
> Labels: pull-request-available, test-stability
> Attachments: 1234.jpg, app-profiling_4.gif,
> image-2023-01-11-22-21-57-784.png, image-2023-01-11-22-22-32-124.png,
> image-2023-02-16-20-18-09-431.png, image-2023-07-11-19-28-52-851.png,
> image-2023-07-11-19-35-54-530.png, image-2023-07-11-19-41-18-626.png,
> image-2023-07-11-19-41-37-105.png
>
>
> {noformat}
> = test session starts
> ==
> platform linux -- Python 3.7.3, pytest-5.4.3, py-1.8.2, pluggy-0.13.1
> cachedir: .tox/py37-cython/.pytest_cache
> rootdir: /__w/3/s/flink-python
> collected 568 items
> pyflink/common/tests/test_configuration.py ..[
> 1%]
> pyflink/common/tests/test_execution_config.py ...[
> 5%]
> pyflink/dataset/tests/test_execution_environment.py .
> ##[error]Exit code 137 returned from process: file name '/bin/docker',
> arguments 'exec -i -u 1002
> 97fc4e22522d2ced1f4d23096b8929045d083dd0a99a4233a8b20d0489e9bddb
> /__a/externals/node/bin/node /__w/_temp/containerHandlerInvoker.js'.
> Finishing: Test - python
> {noformat}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=3729&view=logs&j=9cada3cb-c1d3-5621-16da-0f718fb86602&t=8d78fe4f-d658-5c70-12f8-4921589024c3
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-33082) Azure Pipelines 4 is not responding on AZP
[
https://issues.apache.org/jira/browse/FLINK-33082?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sergey Nuyanzin updated FLINK-33082:
Affects Version/s: 1.17.2
> Azure Pipelines 4 is not responding on AZP
> --
>
> Key: FLINK-33082
> URL: https://issues.apache.org/jira/browse/FLINK-33082
> Project: Flink
> Issue Type: Bug
> Components: Build System / CI
>Affects Versions: 1.17.2
>Reporter: Sergey Nuyanzin
>Priority: Major
> Labels: test-stability
>
> it impacts this build for 1.17
> [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=53163&view=logs&s=9fca669f-5c5f-59c7-4118-e31c641064f0&j=6e8542d7-de38-5a33-4aca-458d6c87066d]
> {noformat}
> ##[error]We stopped hearing from agent Azure Pipelines 4. Verify the agent
> machine is running and has a healthy network connection. Anything that
> terminates an agent process, starves it for CPU, or blocks its network access
> can cause this error. For more information, see:
> https://go.microsoft.com/fwlink/?linkid=846610
> Agent: Azure Pipelines 4
> Started: Today at 4:59 AM
> Duration: 6h 24m 38s
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Created] (FLINK-33082) Azure Pipelines 4 is not responding on AZP
Sergey Nuyanzin created FLINK-33082:
---
Summary: Azure Pipelines 4 is not responding on AZP
Key: FLINK-33082
URL: https://issues.apache.org/jira/browse/FLINK-33082
Project: Flink
Issue Type: Bug
Components: Build System / CI
Reporter: Sergey Nuyanzin
it impacts this build for 1.17
[https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=53163&view=logs&s=9fca669f-5c5f-59c7-4118-e31c641064f0&j=6e8542d7-de38-5a33-4aca-458d6c87066d]
{noformat}
##[error]We stopped hearing from agent Azure Pipelines 4. Verify the agent
machine is running and has a healthy network connection. Anything that
terminates an agent process, starves it for CPU, or blocks its network access
can cause this error. For more information, see:
https://go.microsoft.com/fwlink/?linkid=846610
Agent: Azure Pipelines 4
Started: Today at 4:59 AM
Duration: 6h 24m 38s
{noformat}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-18356) flink-table-planner Exit code 137 returned from process
[
https://issues.apache.org/jira/browse/FLINK-18356?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sergey Nuyanzin updated FLINK-18356:
Affects Version/s: 1.19.0
> flink-table-planner Exit code 137 returned from process
> ---
>
> Key: FLINK-18356
> URL: https://issues.apache.org/jira/browse/FLINK-18356
> Project: Flink
> Issue Type: Bug
> Components: Build System / Azure Pipelines, Tests
>Affects Versions: 1.12.0, 1.13.0, 1.14.0, 1.15.0, 1.16.0, 1.17.0, 1.18.0,
> 1.19.0
>Reporter: Piotr Nowojski
>Assignee: Yunhong Zheng
>Priority: Critical
> Labels: pull-request-available, test-stability
> Attachments: 1234.jpg, app-profiling_4.gif,
> image-2023-01-11-22-21-57-784.png, image-2023-01-11-22-22-32-124.png,
> image-2023-02-16-20-18-09-431.png, image-2023-07-11-19-28-52-851.png,
> image-2023-07-11-19-35-54-530.png, image-2023-07-11-19-41-18-626.png,
> image-2023-07-11-19-41-37-105.png
>
>
> {noformat}
> = test session starts
> ==
> platform linux -- Python 3.7.3, pytest-5.4.3, py-1.8.2, pluggy-0.13.1
> cachedir: .tox/py37-cython/.pytest_cache
> rootdir: /__w/3/s/flink-python
> collected 568 items
> pyflink/common/tests/test_configuration.py ..[
> 1%]
> pyflink/common/tests/test_execution_config.py ...[
> 5%]
> pyflink/dataset/tests/test_execution_environment.py .
> ##[error]Exit code 137 returned from process: file name '/bin/docker',
> arguments 'exec -i -u 1002
> 97fc4e22522d2ced1f4d23096b8929045d083dd0a99a4233a8b20d0489e9bddb
> /__a/externals/node/bin/node /__w/_temp/containerHandlerInvoker.js'.
> Finishing: Test - python
> {noformat}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=3729&view=logs&j=9cada3cb-c1d3-5621-16da-0f718fb86602&t=8d78fe4f-d658-5c70-12f8-4921589024c3
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-18356) flink-table-planner Exit code 137 returned from process
[
https://issues.apache.org/jira/browse/FLINK-18356?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764568#comment-17764568
]
Sergey Nuyanzin commented on FLINK-18356:
-
https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=53161&view=logs&j=a9db68b9-a7e0-54b6-0f98-010e0aff39e2&t=cdd32e0b-6047-565b-c58f-14054472f1be&l=12718
> flink-table-planner Exit code 137 returned from process
> ---
>
> Key: FLINK-18356
> URL: https://issues.apache.org/jira/browse/FLINK-18356
> Project: Flink
> Issue Type: Bug
> Components: Build System / Azure Pipelines, Tests
>Affects Versions: 1.12.0, 1.13.0, 1.14.0, 1.15.0, 1.16.0, 1.17.0, 1.18.0
>Reporter: Piotr Nowojski
>Assignee: Yunhong Zheng
>Priority: Critical
> Labels: pull-request-available, test-stability
> Attachments: 1234.jpg, app-profiling_4.gif,
> image-2023-01-11-22-21-57-784.png, image-2023-01-11-22-22-32-124.png,
> image-2023-02-16-20-18-09-431.png, image-2023-07-11-19-28-52-851.png,
> image-2023-07-11-19-35-54-530.png, image-2023-07-11-19-41-18-626.png,
> image-2023-07-11-19-41-37-105.png
>
>
> {noformat}
> = test session starts
> ==
> platform linux -- Python 3.7.3, pytest-5.4.3, py-1.8.2, pluggy-0.13.1
> cachedir: .tox/py37-cython/.pytest_cache
> rootdir: /__w/3/s/flink-python
> collected 568 items
> pyflink/common/tests/test_configuration.py ..[
> 1%]
> pyflink/common/tests/test_execution_config.py ...[
> 5%]
> pyflink/dataset/tests/test_execution_environment.py .
> ##[error]Exit code 137 returned from process: file name '/bin/docker',
> arguments 'exec -i -u 1002
> 97fc4e22522d2ced1f4d23096b8929045d083dd0a99a4233a8b20d0489e9bddb
> /__a/externals/node/bin/node /__w/_temp/containerHandlerInvoker.js'.
> Finishing: Test - python
> {noformat}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=3729&view=logs&j=9cada3cb-c1d3-5621-16da-0f718fb86602&t=8d78fe4f-d658-5c70-12f8-4921589024c3
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] echauchot commented on a diff in pull request #22985: [FLINK-21883][scheduler] Implement cooldown period for adaptive scheduler
echauchot commented on code in PR #22985:
URL: https://github.com/apache/flink/pull/22985#discussion_r1324233808
##
flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/adaptive/Executing.java:
##
@@ -124,17 +154,33 @@ private void handleDeploymentFailure(ExecutionVertex
executionVertex, JobExcepti
@Override
public void onNewResourcesAvailable() {
-maybeRescale();
+rescaleWhenCooldownPeriodIsOver();
}
@Override
public void onNewResourceRequirements() {
-maybeRescale();
+rescaleWhenCooldownPeriodIsOver();
}
private void maybeRescale() {
-if (context.shouldRescale(getExecutionGraph())) {
-getLogger().info("Can change the parallelism of job. Restarting
job.");
+final Duration timeSinceLastRescale = timeSinceLastRescale();
+rescaleScheduled = false;
+final boolean shouldForceRescale =
+(scalingIntervalMax != null)
+&& (timeSinceLastRescale.compareTo(scalingIntervalMax)
> 0)
+&& (lastRescale != Instant.EPOCH); // initial rescale
is not forced
+if (shouldForceRescale || context.shouldRescale(getExecutionGraph())) {
+if (shouldForceRescale) {
+getLogger()
+.info(
+"Time since last rescale ({}) > {} ({}).
Force-changing the parallelism of the job. Restarting the job.",
+timeSinceLastRescale,
+
JobManagerOptions.SCHEDULER_SCALING_INTERVAL_MAX.key(),
+scalingIntervalMax);
+} else {
+getLogger().info("Can change the parallelism of the job.
Restarting the job.");
+}
+lastRescale = Instant.now();
context.goToRestarting(
getExecutionGraph(),
Review Comment:
Here is the summary of the offline discussion @1996fanrui and I had about
`scalingIntervalMax` and forcing rescale (current code: when `added resources <
min-parallelism-increase` we force a rescale if `timeSinceLastRescale >
scalingIntervalMax`):
1. aim: the longer the pipeline runs, the more the (small) resource gain is
worth the restarting time.
2. corner case: a resource `< min-parallelism-increase` arrives when
`timeSinceLastRescale < scalingIntervalMax` and the pipeline is running for a
long time (typical case 1) => with the current code, we don't force a rescale
in that case whereas the added resource would be worth the restarting time.
=> I proposed solution 1: changing the definition of `scalingIntervalMax`
to `pipelineRuntimeRescaleMin` meaning pipeline runtime after which we force a
rescale even if `added resources < min-parallelism-increase`
=> @1996fanrui proposed solution 2: if `added resources <
min-parallelism-increase && timeSinceLastRescale < scalingIntervalMax` schedule
a tryRescale after `scalingIntervalMax` : force a rescale if there is indeed a
change in the resource graph at that time in case the last TM crashed
@zentol you were the one who proposed the addition of `scalingIntervalMax`
in the FLIP discussion thread. Do you prefer solution 1 or solution 2 ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] echauchot commented on pull request #22985: [FLINK-21883][scheduler] Implement cooldown period for adaptive scheduler
echauchot commented on PR #22985: URL: https://github.com/apache/flink/pull/22985#issuecomment-1717288424 > @dmvk as you authored part on the code in that part, can you review the PR as well ? The discussions went around `scalingIntervalMax`, @zentol was the one who proposed the addition of this parameter in the FLIP discussion thread. So maybe it is not needed that we add both of you as reviewers. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-33083) SupportsReadingMetadata is not applied when loading a CompiledPlan
Dawid Wysakowicz created FLINK-33083:
Summary: SupportsReadingMetadata is not applied when loading a
CompiledPlan
Key: FLINK-33083
URL: https://issues.apache.org/jira/browse/FLINK-33083
Project: Flink
Issue Type: Bug
Components: Table SQL / Planner
Affects Versions: 1.17.1, 1.16.2
Reporter: Dawid Wysakowicz
If a few conditions are met, we can not apply ReadingMetadata interface:
# source overwrites:
{code}
@Override
public boolean supportsMetadataProjection() {
return false;
}
{code}
# source does not implement {{SupportsProjectionPushDown}}
# table has metadata columns e.g.
{code}
CREATE TABLE src (
physical_name STRING,
physical_sum INT,
timestamp TIMESTAMP_LTZ(3) NOT NULL METADATA VIRTUAL
)
{code}
# we query the table {{SELECT * FROM src}}
It fails with:
{code}
Caused by: java.lang.IllegalArgumentException: Row arity: 1, but serializer
arity: 2
at
org.apache.flink.table.runtime.typeutils.RowDataSerializer.copy(RowDataSerializer.java:124)
{code}
The reason is {{SupportsReadingMetadataSpec}} is created only in the
{{PushProjectIntoTableSourceScanRule}}, but the rule is not applied when 1 & 2
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764570#comment-17764570 ] Yuan Mei commented on FLINK-33052: -- [~pnowojski] We have the historical data backed up. But just in case, we will still have the worker node there before the new setup. Also, I would say this ticket is not a blocker for release 1.18, since 1.18 is already branch-cut and in the stage of manual testing? > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yuan Mei updated FLINK-33052: - Priority: Critical (was: Blocker) > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Critical > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] wangyang0918 commented on pull request #23164: [FLINK- 32775]Add parent dir of files to classpath using yarn.provided.lib.dirs
wangyang0918 commented on PR #23164: URL: https://github.com/apache/flink/pull/23164#issuecomment-1717326350 @architgyl Could you please verify this PR in a real YARN cluster whether it solves your original requirement about hive config? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] mbalassi commented on pull request #668: Give cluster/job role access to k8s services API
mbalassi commented on PR #668: URL: https://github.com/apache/flink-kubernetes-operator/pull/668#issuecomment-1717336055 @sbrother could you please open a ticket for this, as a good example see this one: https://issues.apache.org/jira/browse/FLINK-33066 Could you clarify what do you mean by "connect to a session cluster"? Did you mean executing `flink list` from one of containers in your JobManager pod? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] mbalassi commented on pull request #671: [FLINK-33066] Support all k8s methods to configure env variable in operatorPod
mbalassi commented on PR #671: URL: https://github.com/apache/flink-kubernetes-operator/pull/671#issuecomment-1717348931 Thanks, @dongwoo6kim. Please include the documentation in this change, unfortunately we maintain that manually here: https://github.com/apache/flink-kubernetes-operator/blob/main/docs/content/docs/operations/helm.md?plain=1#L73 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] TanYuxin-tyx commented on pull request #23401: [FLINK-30906][task] TwoInputStreamTask and MultipleInputStreamTask passes wrong configuration when create input processor
TanYuxin-tyx commented on PR #23401: URL: https://github.com/apache/flink/pull/23401#issuecomment-1717360318 @reswqa Thanks for fixing the configuration bug. LGTM -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] reswqa commented on pull request #23401: [FLINK-30906][task] TwoInputStreamTask and MultipleInputStreamTask passes wrong configuration when create input processor
reswqa commented on PR #23401: URL: https://github.com/apache/flink/pull/23401#issuecomment-1717361467 Thanks! merging... -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] reswqa merged pull request #23401: [FLINK-30906][task] TwoInputStreamTask and MultipleInputStreamTask passes wrong configuration when create input processor
reswqa merged PR #23401: URL: https://github.com/apache/flink/pull/23401 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-33084) Migrate globalJobParameter in ExecutionConfig to configuration instance
Junrui Li created FLINK-33084: - Summary: Migrate globalJobParameter in ExecutionConfig to configuration instance Key: FLINK-33084 URL: https://issues.apache.org/jira/browse/FLINK-33084 Project: Flink Issue Type: Technical Debt Components: Runtime / Configuration Reporter: Junrui Li Fix For: 1.19.0 Currently, the globalJobParameter field in ExecutionConfig has not been migrated to the Configuration. Considering the goal of unifying configuration options, it is necessary to migrate it. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764581#comment-17764581 ] Piotr Nowojski commented on FLINK-33052: We have been always treating benchmarking issues the same way as regular test issues. If CI for tests was down, that would have been a clear blocker, preventing everyone from merging any code, doing any releases. The same applies for benchmarking, the only difference is that benchmarks are asynchronous and not executed per every PR due to load that they are generating. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Critical > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-30906) TwoInputStreamTask passes wrong configuration object when creating input processor
[ https://issues.apache.org/jira/browse/FLINK-30906?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Weijie Guo closed FLINK-30906. -- Resolution: Fixed master(1.19) via 70f4c40f15f38ed404d8e031a08d534326535ced. > TwoInputStreamTask passes wrong configuration object when creating input > processor > -- > > Key: FLINK-30906 > URL: https://issues.apache.org/jira/browse/FLINK-30906 > Project: Flink > Issue Type: Bug > Components: Runtime / Task >Affects Versions: 1.17.0, 1.16.1 >Reporter: Yun Gao >Assignee: Yun Gao >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > It seems _StreamTwoInputProcessorFactory.create_ is passed with wrong > configuration object: the taskManagerConfiguration should be __ > _getEnvironment().getTaskManagerInfo().getConfiguration()._ > > And in the following logic, it seems to indeed try to load taskmanager > options from this configuration object, like state-backend and > taskmanager.memory.managed.consumer-weights > > [1]https://github.com/apache/flink/blob/111342f37bdc0d582d3f7af458d9869f0548299f/flink-streaming-java/src/main/java/org/apache/flink/streaming/runtime/tasks/TwoInputStreamTask.java#L98 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-30906) TwoInputStreamTask passes wrong configuration object when creating input processor
[ https://issues.apache.org/jira/browse/FLINK-30906?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Weijie Guo updated FLINK-30906: --- Fix Version/s: 1.19.0 > TwoInputStreamTask passes wrong configuration object when creating input > processor > -- > > Key: FLINK-30906 > URL: https://issues.apache.org/jira/browse/FLINK-30906 > Project: Flink > Issue Type: Bug > Components: Runtime / Task >Affects Versions: 1.17.0, 1.16.1 >Reporter: Yun Gao >Assignee: Yun Gao >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > It seems _StreamTwoInputProcessorFactory.create_ is passed with wrong > configuration object: the taskManagerConfiguration should be __ > _getEnvironment().getTaskManagerInfo().getConfiguration()._ > > And in the following logic, it seems to indeed try to load taskmanager > options from this configuration object, like state-backend and > taskmanager.memory.managed.consumer-weights > > [1]https://github.com/apache/flink/blob/111342f37bdc0d582d3f7af458d9869f0548299f/flink-streaming-java/src/main/java/org/apache/flink/streaming/runtime/tasks/TwoInputStreamTask.java#L98 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Piotr Nowojski updated FLINK-33052: --- Priority: Blocker (was: Critical) > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] TanYuxin-tyx commented on pull request #23404: [FLINK-33076][network] Reduce serialization overhead of broadcast emit from ChannelSelectorRecordWriter.
TanYuxin-tyx commented on PR #23404: URL: https://github.com/apache/flink/pull/23404#issuecomment-1717364731 Thanks @reswqa for fixing the bug. LGTM now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764581#comment-17764581 ] Piotr Nowojski edited comment on FLINK-33052 at 9/13/23 10:28 AM: -- We have been always treating benchmarking issues the same way as regular test issues. If CI for tests was down, that would have been a clear blocker, preventing everyone from merging any code, doing any releases. The same applies for benchmarking, the only difference is that benchmarks are asynchronous and not executed per every PR due to load that they are generating. Some of the past examples: FLINK-23153, FLINK-23879, FLINK-29886, FLINK-30015, FLINK-15171 Also as far as I remember that has been discussed on the dev mailing list at least once or twice. was (Author: pnowojski): We have been always treating benchmarking issues the same way as regular test issues. If CI for tests was down, that would have been a clear blocker, preventing everyone from merging any code, doing any releases. The same applies for benchmarking, the only difference is that benchmarks are asynchronous and not executed per every PR due to load that they are generating. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] reswqa commented on pull request #23404: [FLINK-33076][network] Reduce serialization overhead of broadcast emit from ChannelSelectorRecordWriter.
reswqa commented on PR #23404: URL: https://github.com/apache/flink/pull/23404#issuecomment-1717367967 Thanks for the review! Squashed the fix-up commit. I will merge this if pipeline passed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-33084) Migrate globalJobParameter in ExecutionConfig to configuration instance
[ https://issues.apache.org/jira/browse/FLINK-33084?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Lijie Wang reassigned FLINK-33084: -- Assignee: Junrui Li > Migrate globalJobParameter in ExecutionConfig to configuration instance > --- > > Key: FLINK-33084 > URL: https://issues.apache.org/jira/browse/FLINK-33084 > Project: Flink > Issue Type: Technical Debt > Components: Runtime / Configuration >Reporter: Junrui Li >Assignee: Junrui Li >Priority: Major > Fix For: 1.19.0 > > > Currently, the globalJobParameter field in ExecutionConfig has not been > migrated to the Configuration. Considering the goal of unifying configuration > options, it is necessary to migrate it. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-33084) Migrate globalJobParameter in ExecutionConfig to configuration instance
[ https://issues.apache.org/jira/browse/FLINK-33084?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-33084: --- Labels: pull-request-available (was: ) > Migrate globalJobParameter in ExecutionConfig to configuration instance > --- > > Key: FLINK-33084 > URL: https://issues.apache.org/jira/browse/FLINK-33084 > Project: Flink > Issue Type: Technical Debt > Components: Runtime / Configuration >Reporter: Junrui Li >Assignee: Junrui Li >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > Currently, the globalJobParameter field in ExecutionConfig has not been > migrated to the Configuration. Considering the goal of unifying configuration > options, it is necessary to migrate it. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] JunRuiLee opened a new pull request, #23409: [FLINK-33084][runtime] Migrate globalJobParameter to configuration.
JunRuiLee opened a new pull request, #23409: URL: https://github.com/apache/flink/pull/23409 ## What is the purpose of the change Migrate globalJobParameter to configuration. ## Brief change log Migrate globalJobParameter to configuration. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / **not documented**) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wangzzu commented on a diff in pull request #23399: [FLINK-33061][docs] Translate failure-enricher documentation to Chinese
wangzzu commented on code in PR #23399:
URL: https://github.com/apache/flink/pull/23399#discussion_r1324344461
##
docs/content/docs/deployment/advanced/failure_enrichers.md:
##
@@ -42,7 +42,7 @@ To implement a custom FailureEnricher plugin, you need to:
Then, create a jar which includes your `FailureEnricher`,
`FailureEnricherFactory`, `META-INF/services/` and all external dependencies.
Make a directory in `plugins/` of your Flink distribution with an arbitrary
name, e.g. "failure-enrichment", and put the jar into this directory.
-See [Flink Plugin]({% link deployment/filesystems/plugins.md %}) for more
details.
+See [Flink Plugin]({{< ref "docs/deployment/filesystems/plugins" >}}) for more
details.
Review Comment:
Good advice, here I fixed it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #23409: [FLINK-33084][runtime] Migrate globalJobParameter to configuration.
flinkbot commented on PR #23409: URL: https://github.com/apache/flink/pull/23409#issuecomment-1717412004 ## CI report: * 20e1f350e3ef6dd6a37701317ea7a9feccab9b0e UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-21949) Support ARRAY_AGG aggregate function
[ https://issues.apache.org/jira/browse/FLINK-21949?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jiabao Sun updated FLINK-21949: --- Summary: Support ARRAY_AGG aggregate function (was: Support collect to array aggregate function) > Support ARRAY_AGG aggregate function > > > Key: FLINK-21949 > URL: https://issues.apache.org/jira/browse/FLINK-21949 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Affects Versions: 1.12.0 >Reporter: Jiabao Sun >Assignee: Jiabao Sun >Priority: Minor > Fix For: 1.19.0 > > > Some nosql databases like mongodb and elasticsearch support nested data types. > Aggregating multiple rows into ARRAY is a common requirement. > The CollectToArray function is similar to Collect, except that it returns > ARRAY instead of MULTISET. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-33085) Improve the error message when the invalidate lookupTableSource without primary key is used as temporal join table
Yunhong Zheng created FLINK-33085: - Summary: Improve the error message when the invalidate lookupTableSource without primary key is used as temporal join table Key: FLINK-33085 URL: https://issues.apache.org/jira/browse/FLINK-33085 Project: Flink Issue Type: Improvement Components: Table SQL / Planner Affects Versions: 1.19.0 Reporter: Yunhong Zheng Fix For: 1.19.0 Improve the error message when the invalidate lookupTableSource without primary key is used as temporal join table. This pr can check the legality of temporary table join syntax in sqlToRel phase and make the thrown error clearer. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (FLINK-33011) Operator deletes HA data unexpectedly
[
https://issues.apache.org/jira/browse/FLINK-33011?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Gyula Fora closed FLINK-33011.
--
Fix Version/s: kubernetes-operator-1.7.0
Resolution: Fixed
merged to main 82739f62adda33e686da7d8aa30cbd41ea13012f
> Operator deletes HA data unexpectedly
> -
>
> Key: FLINK-33011
> URL: https://issues.apache.org/jira/browse/FLINK-33011
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Affects Versions: 1.17.1, kubernetes-operator-1.6.0
> Environment: Flink: 1.17.1
> Flink Kubernetes Operator: 1.6.0
>Reporter: Ruibin Xing
>Assignee: Gyula Fora
>Priority: Blocker
> Labels: pull-request-available
> Fix For: kubernetes-operator-1.7.0
>
> Attachments: flink_operator_logs_0831.csv
>
>
> We encountered a problem where the operator unexpectedly deleted HA data.
> The timeline is as follows:
> 12:08 We submitted the first spec, which suspended the job with savepoint
> upgrade mode.
> 12:08 The job was suspended, while the HA data was preserved, and the log
> showed the observed job deployment status was MISSING.
> 12:10 We submitted the second spec, which deployed the job with the last
> state upgrade mode.
> 12:10 Logs showed the operator deleted both the Flink deployment and the HA
> data again.
> 12:10 The job failed to start because the HA data was missing.
> According to the log, the deletion was triggered by
> https://github.com/apache/flink-kubernetes-operator/blob/a728ba768e20236184e2b9e9e45163304b8b196c/flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/reconciler/deployment/ApplicationReconciler.java#L168
> I think this would only be triggered if the job deployment status wasn't
> MISSING. But the log before the deletion showed the observed job status was
> MISSING at that moment.
> Related logs:
>
> {code:java}
> 2023-08-30 12:08:48.190 + o.a.f.k.o.s.AbstractFlinkService [INFO
> ][default/pipeline-pipeline-se-3] Cluster shutdown completed.
> 2023-08-30 12:10:27.010 + o.a.f.k.o.o.d.ApplicationObserver [INFO
> ][default/pipeline-pipeline-se-3] Observing JobManager deployment. Previous
> status: MISSING
> 2023-08-30 12:10:27.533 + o.a.f.k.o.l.AuditUtils [INFO
> ][default/pipeline-pipeline-se-3] >>> Event | Info | SPECCHANGED |
> UPGRADE change(s) detected (Diff: FlinkDeploymentSpec[image :
> docker-registry.randomcompany.com/octopus/pipeline-pipeline-online:0835137c-362
> ->
> docker-registry.randomcompany.com/octopus/pipeline-pipeline-online:23db7ae8-365,
> podTemplate.metadata.labels.app.kubernetes.io~1version :
> 0835137cd803b7258695eb53a6ec520cb62a48a7 ->
> 23db7ae84bdab8d91fa527fe2f8f2fce292d0abc, job.state : suspended -> running,
> job.upgradeMode : last-state -> savepoint, restartNonce : 1545 -> 1547]),
> starting reconciliation.
> 2023-08-30 12:10:27.679 + o.a.f.k.o.s.NativeFlinkService [INFO
> ][default/pipeline-pipeline-se-3] Deleting JobManager deployment and HA
> metadata.
> {code}
> A more complete log file is attached. Thanks.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] swuferhong opened a new pull request, #23410: [FLINK-33085][table-planner] Improve the error message when the invalidated lookupTableSource without primary key is used as temporal joi
swuferhong opened a new pull request, #23410: URL: https://github.com/apache/flink/pull/23410 ## What is the purpose of the change Improve the error message when the invalidate `lookupTableSource` without primary key is used as temporal join table. This pr can check the legality of temporary table join syntax in `sqlToRel` phase and make the thrown error clearer. ## Brief change log - Adding the check logical in `SqlToRelConverter`. - Adding test in `LookupJoinTest` and `TemporalJoinTest` ## Verifying this change - Adding test in `LookupJoinTest` and `TemporalJoinTest` ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? no docs -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-33085) Improve the error message when the invalidate lookupTableSource without primary key is used as temporal join table
[ https://issues.apache.org/jira/browse/FLINK-33085?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-33085: --- Labels: pull-request-available (was: ) > Improve the error message when the invalidate lookupTableSource without > primary key is used as temporal join table > -- > > Key: FLINK-33085 > URL: https://issues.apache.org/jira/browse/FLINK-33085 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Planner >Affects Versions: 1.19.0 >Reporter: Yunhong Zheng >Priority: Major > Labels: pull-request-available > Fix For: 1.19.0 > > > Improve the error message when the invalidate lookupTableSource without > primary key is used as temporal join table. This pr can check the legality > of temporary table join syntax in sqlToRel phase and make the thrown error > clearer. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-ml] lindong28 commented on pull request #248: [FLINK-32704] Supports spilling to disk when feedback channel memory buffer is full
lindong28 commented on PR #248: URL: https://github.com/apache/flink-ml/pull/248#issuecomment-1717534003 Thanks for the update! LGTM. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] lindong28 merged pull request #248: [FLINK-32704] Supports spilling to disk when feedback channel memory buffer is full
lindong28 merged PR #248: URL: https://github.com/apache/flink-ml/pull/248 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-32704) Supports spilling to disk when feedback channel memory buffer is full
[ https://issues.apache.org/jira/browse/FLINK-32704?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dong Lin reassigned FLINK-32704: Assignee: Jiang Xin > Supports spilling to disk when feedback channel memory buffer is full > - > > Key: FLINK-32704 > URL: https://issues.apache.org/jira/browse/FLINK-32704 > Project: Flink > Issue Type: Improvement > Components: Library / Machine Learning >Reporter: Jiang Xin >Assignee: Jiang Xin >Priority: Major > Labels: pull-request-available > Fix For: ml-2.4.0 > > > Currently, the Flink ML Iteration cache feedback data in memory, which would > cause OOM in some cases. We need to support spilling to disk when feedback > channel memory buffer is full. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-32704) Supports spilling to disk when feedback channel memory buffer is full
[ https://issues.apache.org/jira/browse/FLINK-32704?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764635#comment-17764635 ] Dong Lin commented on FLINK-32704: -- Merged to apache/flink-ml master branch 865404910caf53259df5cea1fc25ca29f96ae9bd > Supports spilling to disk when feedback channel memory buffer is full > - > > Key: FLINK-32704 > URL: https://issues.apache.org/jira/browse/FLINK-32704 > Project: Flink > Issue Type: Improvement > Components: Library / Machine Learning >Reporter: Jiang Xin >Assignee: Jiang Xin >Priority: Major > Labels: pull-request-available > Fix For: ml-2.4.0 > > > Currently, the Flink ML Iteration cache feedback data in memory, which would > cause OOM in some cases. We need to support spilling to disk when feedback > channel memory buffer is full. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #23410: [FLINK-33085][table-planner] Improve the error message when the invalidated lookupTableSource without primary key is used as temporal join t
flinkbot commented on PR #23410: URL: https://github.com/apache/flink/pull/23410#issuecomment-1717541375 ## CI report: * a5f93f4153d0b8430d836a35a6f79b80caa76457 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-33053) Watcher leak in Zookeeper HA mode
[
https://issues.apache.org/jira/browse/FLINK-33053?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764640#comment-17764640
]
Yangze Guo commented on FLINK-33053:
JFYI, I'm still investigating the root cause of this, but I found the issue
will be fixed if we add a safetynet in
ZooKeeperLeaderRetrievalDriver#close like this:
{code:java}
client.watchers()
.removeAll()
.ofType(Watcher.WatcherType.Any)
.forPath(connectionInformationPath);{code}
> Watcher leak in Zookeeper HA mode
> -
>
> Key: FLINK-33053
> URL: https://issues.apache.org/jira/browse/FLINK-33053
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.17.0, 1.18.0, 1.17.1
>Reporter: Yangze Guo
>Priority: Blocker
> Attachments: 26.dump.zip, 26.log,
> taskmanager_flink-native-test-117-taskmanager-1-9_thread_dump (1).json
>
>
> We observe a watcher leak in our OLAP stress test when enabling Zookeeper HA
> mode. TM's watches on the leader of JobMaster has not been stopped after job
> finished.
> Here is how we re-produce this issue:
> - Start a session cluster and enable Zookeeper HA mode.
> - Continuously and concurrently submit short queries, e.g. WordCount to the
> cluster.
> - echo -n wchp | nc \{zk host} \{zk port} to get current watches.
> We can see a lot of watches on
> /flink/\{cluster_name}/leader/\{job_id}/connection_info.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] dongwoo6kim commented on pull request #671: [FLINK-33066] Support all k8s methods to configure env variable in operatorPod
dongwoo6kim commented on PR #671: URL: https://github.com/apache/flink-kubernetes-operator/pull/671#issuecomment-1717548787 Thanks @mbalassi. I have updated the docs -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] hejufang commented on pull request #23403: [FLINK-32863][runtime-web] Improve Flink UI's time precision from sec…
hejufang commented on PR #23403: URL: https://github.com/apache/flink/pull/23403#issuecomment-1717554816 @masteryhx Thank you for your suggestion. I have adjusted the precision of checkpoint related time. please review. cc @KarmaGYZ  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-32704) Supports spilling to disk when feedback channel memory buffer is full
[ https://issues.apache.org/jira/browse/FLINK-32704?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dong Lin closed FLINK-32704. Resolution: Fixed > Supports spilling to disk when feedback channel memory buffer is full > - > > Key: FLINK-32704 > URL: https://issues.apache.org/jira/browse/FLINK-32704 > Project: Flink > Issue Type: Improvement > Components: Library / Machine Learning >Reporter: Jiang Xin >Assignee: Jiang Xin >Priority: Major > Labels: pull-request-available > Fix For: ml-2.4.0 > > > Currently, the Flink ML Iteration cache feedback data in memory, which would > cause OOM in some cases. We need to support spilling to disk when feedback > channel memory buffer is full. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] Jiabao-Sun opened a new pull request, #23411: [FLINK-21949][table] Support ARRAY_AGG aggregate function
Jiabao-Sun opened a new pull request, #23411: URL: https://github.com/apache/flink/pull/23411 ## What is the purpose of the change [FLINK-21949][table] Support ARRAY_AGG aggregate function Some nosql databases like mongodb and elasticsearch support nested data types. Aggregating multiple rows into ARRAY is a common requirement. ## Brief change log Introduce built in function `ARRAY_AGG([ ALL | DISTINCT ] expression)` to return an array that concatenates the input rows and returns NULL if there are no input rows. NULL values will be ignored. Use DISTINCT for one unique instance of each value. ```sql SELECT ARRAY_AGG(f1) FROM tmp GROUP BY f0 ``` 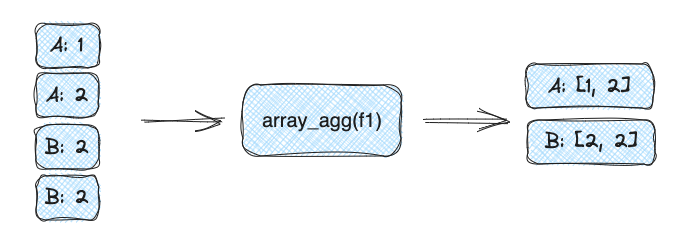 Note that we have made some simplifications based on Calcite's `SqlLibraryOperators.ARRAY_AGG`. ```sql -- calcite ARRAY_AGG([ ALL | DISTINCT ] value [ RESPECT NULLS | IGNORE NULLS ] [ ORDER BY orderItem [, orderItem ]* ] ) -- flink ARRAY_AGG([ ALL | DISTINCT ] expression) ``` **The differences from Calcite are as follows:** 1. **Null values are ignored.** 2. **The order by expression within the function is not supported because the complete row record cannot be accessed within the function implementation.** 3. **The function returns null when there's no input rows, but calcite definition returns an empty array. The behavior was referenced from BigQuery and Postgres.** - https://cloud.google.com/bigquery/docs/reference/standard-sql/aggregate_functions#array_agg - https://www.postgresql.org/docs/8.4/functions-aggregate.html ## Verifying this change ITCase and UnitCase are added. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes) - The serializers: (no ) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (docs) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-21949) Support ARRAY_AGG aggregate function
[ https://issues.apache.org/jira/browse/FLINK-21949?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-21949: --- Labels: pull-request-available (was: ) > Support ARRAY_AGG aggregate function > > > Key: FLINK-21949 > URL: https://issues.apache.org/jira/browse/FLINK-21949 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Affects Versions: 1.12.0 >Reporter: Jiabao Sun >Assignee: Jiabao Sun >Priority: Minor > Labels: pull-request-available > Fix For: 1.19.0 > > > Some nosql databases like mongodb and elasticsearch support nested data types. > Aggregating multiple rows into ARRAY is a common requirement. > The CollectToArray function is similar to Collect, except that it returns > ARRAY instead of MULTISET. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-21949) Support ARRAY_AGG aggregate function
[
https://issues.apache.org/jira/browse/FLINK-21949?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764658#comment-17764658
]
Jiabao Sun commented on FLINK-21949:
The pull request is ready for review now.
This implementation made some simplifications based on Calcite's
SqlLibraryOperators.ARRAY_AGG.
{code:java}
// calcite
ARRAY_AGG([ ALL | DISTINCT ] value [ RESPECT NULLS | IGNORE NULLS ] [ ORDER BY
orderItem [, orderItem ]* ] )
// flink
ARRAY_AGG([ ALL | DISTINCT ] expression)
{code}
The differences from Calcite are as follows:
# Null values are ignored.
# The order by expression within the function is not supported because the
complete row record cannot be accessed within the function implementation.
# The function returns null when there's no input rows, but calcite definition
returns an empty array. The behavior was referenced from BigQuery and Postgres.
https://cloud.google.com/bigquery/docs/reference/standard-sql/aggregate_functions#array_agg
https://www.postgresql.org/docs/8.4/functions-aggregate.html
> Support ARRAY_AGG aggregate function
>
>
> Key: FLINK-21949
> URL: https://issues.apache.org/jira/browse/FLINK-21949
> Project: Flink
> Issue Type: Sub-task
> Components: Table SQL / API
>Affects Versions: 1.12.0
>Reporter: Jiabao Sun
>Assignee: Jiabao Sun
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.19.0
>
>
> Some nosql databases like mongodb and elasticsearch support nested data types.
> Aggregating multiple rows into ARRAY is a common requirement.
> The CollectToArray function is similar to Collect, except that it returns
> ARRAY instead of MULTISET.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #23411: [FLINK-21949][table] Support ARRAY_AGG aggregate function
flinkbot commented on PR #23411: URL: https://github.com/apache/flink/pull/23411#issuecomment-1717597767 ## CI report: * 10081ad9bdba84b3dac22fb7a6137994cc79622b UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-33083) SupportsReadingMetadata is not applied when loading a CompiledPlan
[
https://issues.apache.org/jira/browse/FLINK-33083?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764666#comment-17764666
]
Yunhong Zheng commented on FLINK-33083:
---
It looks like this is a planner bug, and we don't have related tests to cover
the situation that connector implement
SupportsReadingMetadata and supportsMetadataProjection return false:
{code:java}
default boolean supportsMetadataProjection() {
return false;
}{code}
> SupportsReadingMetadata is not applied when loading a CompiledPlan
> --
>
> Key: FLINK-33083
> URL: https://issues.apache.org/jira/browse/FLINK-33083
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.16.2, 1.17.1
>Reporter: Dawid Wysakowicz
>Priority: Major
>
> If a few conditions are met, we can not apply ReadingMetadata interface:
> # source overwrites:
> {code}
> @Override
> public boolean supportsMetadataProjection() {
> return false;
> }
> {code}
> # source does not implement {{SupportsProjectionPushDown}}
> # table has metadata columns e.g.
> {code}
> CREATE TABLE src (
> physical_name STRING,
> physical_sum INT,
> timestamp TIMESTAMP_LTZ(3) NOT NULL METADATA VIRTUAL
> )
> {code}
> # we query the table {{SELECT * FROM src}}
> It fails with:
> {code}
> Caused by: java.lang.IllegalArgumentException: Row arity: 1, but serializer
> arity: 2
> at
> org.apache.flink.table.runtime.typeutils.RowDataSerializer.copy(RowDataSerializer.java:124)
> {code}
> The reason is {{SupportsReadingMetadataSpec}} is created only in the
> {{PushProjectIntoTableSourceScanRule}}, but the rule is not applied when 1 & 2
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Assigned] (FLINK-33083) SupportsReadingMetadata is not applied when loading a CompiledPlan
[
https://issues.apache.org/jira/browse/FLINK-33083?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Dawid Wysakowicz reassigned FLINK-33083:
Assignee: Dawid Wysakowicz
> SupportsReadingMetadata is not applied when loading a CompiledPlan
> --
>
> Key: FLINK-33083
> URL: https://issues.apache.org/jira/browse/FLINK-33083
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.16.2, 1.17.1
>Reporter: Dawid Wysakowicz
>Assignee: Dawid Wysakowicz
>Priority: Major
>
> If a few conditions are met, we can not apply ReadingMetadata interface:
> # source overwrites:
> {code}
> @Override
> public boolean supportsMetadataProjection() {
> return false;
> }
> {code}
> # source does not implement {{SupportsProjectionPushDown}}
> # table has metadata columns e.g.
> {code}
> CREATE TABLE src (
> physical_name STRING,
> physical_sum INT,
> timestamp TIMESTAMP_LTZ(3) NOT NULL METADATA VIRTUAL
> )
> {code}
> # we query the table {{SELECT * FROM src}}
> It fails with:
> {code}
> Caused by: java.lang.IllegalArgumentException: Row arity: 1, but serializer
> arity: 2
> at
> org.apache.flink.table.runtime.typeutils.RowDataSerializer.copy(RowDataSerializer.java:124)
> {code}
> The reason is {{SupportsReadingMetadataSpec}} is created only in the
> {{PushProjectIntoTableSourceScanRule}}, but the rule is not applied when 1 & 2
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-28758) FlinkKafkaConsumer fails to stop with savepoint
[
https://issues.apache.org/jira/browse/FLINK-28758?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764673#comment-17764673
]
Piotr Nowojski commented on FLINK-28758:
I will try to take care of that
> FlinkKafkaConsumer fails to stop with savepoint
>
>
> Key: FLINK-28758
> URL: https://issues.apache.org/jira/browse/FLINK-28758
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.15.0, 1.17.0, 1.16.1
> Environment: Flink version:1.15.0
> deploy mode :K8s applicaiton Mode. local mini cluster also have this
> problem.
> Kafka Connector : use Kafka SourceFunction . No new Api.
>Reporter: hjw
>Assignee: Piotr Nowojski
>Priority: Critical
> Attachments: image-2022-10-13-19-47-56-635.png
>
>
> I post a stop with savepoint request to Flink Job throught rest api.
> A Error happened in Kafka connector close.
> The job will enter restarting .
> It is successful to use savepoint command alone.
> {code:java}
> 13:33:42.857 [Kafka Fetcher for Source: nlp-kafka-source -> nlp-clean
> (1/1)#0] DEBUG org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer
> clientId=consumer-hjw-3, groupId=hjw] Kafka consumer has been closed
> 13:33:42.857 [Kafka Fetcher for Source: cpp-kafka-source -> cpp-clean
> (1/1)#0] INFO org.apache.kafka.common.utils.AppInfoParser - App info
> kafka.consumer for consumer-hjw-4 unregistered
> 13:33:42.857 [Kafka Fetcher for Source: cpp-kafka-source -> cpp-clean
> (1/1)#0] DEBUG org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer
> clientId=consumer-hjw-4, groupId=hjw] Kafka consumer has been closed
> 13:33:42.860 [Source: nlp-kafka-source -> nlp-clean (1/1)#0] DEBUG
> org.apache.flink.streaming.runtime.tasks.StreamTask - Cleanup StreamTask
> (operators closed: false, cancelled: false)
> 13:33:42.860 [jobmanager-io-thread-4] INFO
> org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Decline
> checkpoint 5 by task eeefcb27475446241861ad8db3f33144 of job
> d6fed247feab1c0bcc1b0dcc2cfb4736 at 79edfa88-ccc3-4140-b0e1-7ce8a7f8669f @
> 127.0.0.1 (dataPort=-1).
> org.apache.flink.util.SerializedThrowable: Task name with subtask : Source:
> nlp-kafka-source -> nlp-clean (1/1)#0 Failure reason: Task has failed.
> at
> org.apache.flink.runtime.taskmanager.Task.declineCheckpoint(Task.java:1388)
> at
> org.apache.flink.runtime.taskmanager.Task.lambda$triggerCheckpointBarrier$3(Task.java:1331)
> at
> java.util.concurrent.CompletableFuture.uniHandle(CompletableFuture.java:822)
> at
> java.util.concurrent.CompletableFuture$UniHandle.tryFire(CompletableFuture.java:797)
> at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474)
> at
> java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:343)
> Caused by: org.apache.flink.util.SerializedThrowable:
> org.apache.flink.streaming.connectors.kafka.internals.Handover$ClosedException
> at
> java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)
> at
> java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)
> at
> java.util.concurrent.CompletableFuture.uniCompose(CompletableFuture.java:943)
> at
> java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:926)
> ... 3 common frames omitted
> Caused by: org.apache.flink.util.SerializedThrowable: null
> at
> org.apache.flink.streaming.connectors.kafka.internals.Handover.close(Handover.java:177)
> at
> org.apache.flink.streaming.connectors.kafka.internals.KafkaFetcher.cancel(KafkaFetcher.java:164)
> at
> org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.cancel(FlinkKafkaConsumerBase.java:945)
> at
> org.apache.flink.streaming.api.operators.StreamSource.stop(StreamSource.java:128)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask.stopOperatorForStopWithSavepoint(SourceStreamTask.java:305)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask.lambda$triggerStopWithSavepointAsync$1(SourceStreamTask.java:285)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.runThrowing(StreamTaskActionExecutor.java:93)
> at org.apache.flink.streaming.runtime.tasks.mailbox.Mail.run(Mail.java:90)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMailsWhenDefaultActionUnavailable(MailboxProcessor.java:338)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMail(MailboxProcessor.java:324)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMai
[jira] [Assigned] (FLINK-28758) FlinkKafkaConsumer fails to stop with savepoint
[
https://issues.apache.org/jira/browse/FLINK-28758?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Piotr Nowojski reassigned FLINK-28758:
--
Assignee: Piotr Nowojski (was: Mark Cho)
> FlinkKafkaConsumer fails to stop with savepoint
>
>
> Key: FLINK-28758
> URL: https://issues.apache.org/jira/browse/FLINK-28758
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.15.0, 1.17.0, 1.16.1
> Environment: Flink version:1.15.0
> deploy mode :K8s applicaiton Mode. local mini cluster also have this
> problem.
> Kafka Connector : use Kafka SourceFunction . No new Api.
>Reporter: hjw
>Assignee: Piotr Nowojski
>Priority: Critical
> Attachments: image-2022-10-13-19-47-56-635.png
>
>
> I post a stop with savepoint request to Flink Job throught rest api.
> A Error happened in Kafka connector close.
> The job will enter restarting .
> It is successful to use savepoint command alone.
> {code:java}
> 13:33:42.857 [Kafka Fetcher for Source: nlp-kafka-source -> nlp-clean
> (1/1)#0] DEBUG org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer
> clientId=consumer-hjw-3, groupId=hjw] Kafka consumer has been closed
> 13:33:42.857 [Kafka Fetcher for Source: cpp-kafka-source -> cpp-clean
> (1/1)#0] INFO org.apache.kafka.common.utils.AppInfoParser - App info
> kafka.consumer for consumer-hjw-4 unregistered
> 13:33:42.857 [Kafka Fetcher for Source: cpp-kafka-source -> cpp-clean
> (1/1)#0] DEBUG org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer
> clientId=consumer-hjw-4, groupId=hjw] Kafka consumer has been closed
> 13:33:42.860 [Source: nlp-kafka-source -> nlp-clean (1/1)#0] DEBUG
> org.apache.flink.streaming.runtime.tasks.StreamTask - Cleanup StreamTask
> (operators closed: false, cancelled: false)
> 13:33:42.860 [jobmanager-io-thread-4] INFO
> org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Decline
> checkpoint 5 by task eeefcb27475446241861ad8db3f33144 of job
> d6fed247feab1c0bcc1b0dcc2cfb4736 at 79edfa88-ccc3-4140-b0e1-7ce8a7f8669f @
> 127.0.0.1 (dataPort=-1).
> org.apache.flink.util.SerializedThrowable: Task name with subtask : Source:
> nlp-kafka-source -> nlp-clean (1/1)#0 Failure reason: Task has failed.
> at
> org.apache.flink.runtime.taskmanager.Task.declineCheckpoint(Task.java:1388)
> at
> org.apache.flink.runtime.taskmanager.Task.lambda$triggerCheckpointBarrier$3(Task.java:1331)
> at
> java.util.concurrent.CompletableFuture.uniHandle(CompletableFuture.java:822)
> at
> java.util.concurrent.CompletableFuture$UniHandle.tryFire(CompletableFuture.java:797)
> at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474)
> at
> java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:343)
> Caused by: org.apache.flink.util.SerializedThrowable:
> org.apache.flink.streaming.connectors.kafka.internals.Handover$ClosedException
> at
> java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)
> at
> java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)
> at
> java.util.concurrent.CompletableFuture.uniCompose(CompletableFuture.java:943)
> at
> java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:926)
> ... 3 common frames omitted
> Caused by: org.apache.flink.util.SerializedThrowable: null
> at
> org.apache.flink.streaming.connectors.kafka.internals.Handover.close(Handover.java:177)
> at
> org.apache.flink.streaming.connectors.kafka.internals.KafkaFetcher.cancel(KafkaFetcher.java:164)
> at
> org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.cancel(FlinkKafkaConsumerBase.java:945)
> at
> org.apache.flink.streaming.api.operators.StreamSource.stop(StreamSource.java:128)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask.stopOperatorForStopWithSavepoint(SourceStreamTask.java:305)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask.lambda$triggerStopWithSavepointAsync$1(SourceStreamTask.java:285)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.runThrowing(StreamTaskActionExecutor.java:93)
> at org.apache.flink.streaming.runtime.tasks.mailbox.Mail.run(Mail.java:90)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMailsWhenDefaultActionUnavailable(MailboxProcessor.java:338)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMail(MailboxProcessor.java:324)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:201)
>
[jira] [Commented] (FLINK-31966) Flink Kubernetes operator lacks TLS support
[ https://issues.apache.org/jira/browse/FLINK-31966?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764674#comment-17764674 ] Gyula Fora commented on FLINK-31966: [~tagarr] I think that sounds reasonable. I think this would work but I don't really know the exact expectation of users requiring this feature unfortunately :) > Flink Kubernetes operator lacks TLS support > > > Key: FLINK-31966 > URL: https://issues.apache.org/jira/browse/FLINK-31966 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.4.0 >Reporter: Adrian Vasiliu >Priority: Major > > *Summary* > The Flink Kubernetes operator lacks support inside the FlinkDeployment > operand for configuring Flink with TLS (both one-way and mutual) for the > internal communication between jobmanagers and taskmanagers, and for the > external REST endpoint. Although a workaround exists to configure the job and > task managers, this breaks the operator and renders it unable to reconcile. > *Additional information* > * The Apache Flink operator supports passing through custom flink > configuration to be applied to job and task managers. > * If you supply SSL-based properties, the operator can no longer speak to > the deployed job manager. The operator is reading the flink conf and using it > to create a connection to the job manager REST endpoint, but it uses the > truststore file paths within flink-conf.yaml, which are unresolvable from the > operator. This leaves the operator hanging in a pending state as it cannot > complete a reconcile. > *Proposal* > Our proposal is to make changes to the operator code. A simple change exists > that would be enough to enable anonymous SSL at the REST endpoint, but more > invasive changes would be required to enable full mTLS throughout. > The simple change to enable anonymous SSL would be for the operator to parse > flink-conf and podTemplate to identify the Kubernetes resource that contains > the certificate from the job manager keystore and use it inside the > operator’s trust store. > In the case of mutual TLS, further changes are required: the operator would > need to generate a certificate signed by the same issuing authority as the > job manager’s certificates and then use it in a keystore when challenged by > that job manager. We propose that the operator becomes responsible for making > CertificateSigningRequests to generate certificates for job manager, task > manager and operator. The operator can then coordinate deploying the job and > task managers with the correct flink-conf and volume mounts. This would also > work for anonymous SSL. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei commented on FLINK-33052: -- # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:30 PM: --- Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. was (Author: ym): # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:31 PM: --- Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. was (Author: ym): Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:31 PM: --- Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. was (Author: ym): Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:31 PM: --- Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. was (Author: ym): Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-connector-kafka] boring-cyborg[bot] commented on pull request #48: [FLINK-28758] Fix stop-with-savepoint for FlinkKafkaConsumer
boring-cyborg[bot] commented on PR #48: URL: https://github.com/apache/flink-connector-kafka/pull/48#issuecomment-1717647945 Thanks for opening this pull request! Please check out our contributing guidelines. (https://flink.apache.org/contributing/how-to-contribute.html) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-28758) FlinkKafkaConsumer fails to stop with savepoint
[
https://issues.apache.org/jira/browse/FLINK-28758?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-28758:
---
Labels: pull-request-available (was: )
> FlinkKafkaConsumer fails to stop with savepoint
>
>
> Key: FLINK-28758
> URL: https://issues.apache.org/jira/browse/FLINK-28758
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.15.0, 1.17.0, 1.16.1
> Environment: Flink version:1.15.0
> deploy mode :K8s applicaiton Mode. local mini cluster also have this
> problem.
> Kafka Connector : use Kafka SourceFunction . No new Api.
>Reporter: hjw
>Assignee: Piotr Nowojski
>Priority: Critical
> Labels: pull-request-available
> Attachments: image-2022-10-13-19-47-56-635.png
>
>
> I post a stop with savepoint request to Flink Job throught rest api.
> A Error happened in Kafka connector close.
> The job will enter restarting .
> It is successful to use savepoint command alone.
> {code:java}
> 13:33:42.857 [Kafka Fetcher for Source: nlp-kafka-source -> nlp-clean
> (1/1)#0] DEBUG org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer
> clientId=consumer-hjw-3, groupId=hjw] Kafka consumer has been closed
> 13:33:42.857 [Kafka Fetcher for Source: cpp-kafka-source -> cpp-clean
> (1/1)#0] INFO org.apache.kafka.common.utils.AppInfoParser - App info
> kafka.consumer for consumer-hjw-4 unregistered
> 13:33:42.857 [Kafka Fetcher for Source: cpp-kafka-source -> cpp-clean
> (1/1)#0] DEBUG org.apache.kafka.clients.consumer.KafkaConsumer - [Consumer
> clientId=consumer-hjw-4, groupId=hjw] Kafka consumer has been closed
> 13:33:42.860 [Source: nlp-kafka-source -> nlp-clean (1/1)#0] DEBUG
> org.apache.flink.streaming.runtime.tasks.StreamTask - Cleanup StreamTask
> (operators closed: false, cancelled: false)
> 13:33:42.860 [jobmanager-io-thread-4] INFO
> org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Decline
> checkpoint 5 by task eeefcb27475446241861ad8db3f33144 of job
> d6fed247feab1c0bcc1b0dcc2cfb4736 at 79edfa88-ccc3-4140-b0e1-7ce8a7f8669f @
> 127.0.0.1 (dataPort=-1).
> org.apache.flink.util.SerializedThrowable: Task name with subtask : Source:
> nlp-kafka-source -> nlp-clean (1/1)#0 Failure reason: Task has failed.
> at
> org.apache.flink.runtime.taskmanager.Task.declineCheckpoint(Task.java:1388)
> at
> org.apache.flink.runtime.taskmanager.Task.lambda$triggerCheckpointBarrier$3(Task.java:1331)
> at
> java.util.concurrent.CompletableFuture.uniHandle(CompletableFuture.java:822)
> at
> java.util.concurrent.CompletableFuture$UniHandle.tryFire(CompletableFuture.java:797)
> at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474)
> at
> java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:343)
> Caused by: org.apache.flink.util.SerializedThrowable:
> org.apache.flink.streaming.connectors.kafka.internals.Handover$ClosedException
> at
> java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)
> at
> java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)
> at
> java.util.concurrent.CompletableFuture.uniCompose(CompletableFuture.java:943)
> at
> java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:926)
> ... 3 common frames omitted
> Caused by: org.apache.flink.util.SerializedThrowable: null
> at
> org.apache.flink.streaming.connectors.kafka.internals.Handover.close(Handover.java:177)
> at
> org.apache.flink.streaming.connectors.kafka.internals.KafkaFetcher.cancel(KafkaFetcher.java:164)
> at
> org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.cancel(FlinkKafkaConsumerBase.java:945)
> at
> org.apache.flink.streaming.api.operators.StreamSource.stop(StreamSource.java:128)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask.stopOperatorForStopWithSavepoint(SourceStreamTask.java:305)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask.lambda$triggerStopWithSavepointAsync$1(SourceStreamTask.java:285)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.runThrowing(StreamTaskActionExecutor.java:93)
> at org.apache.flink.streaming.runtime.tasks.mailbox.Mail.run(Mail.java:90)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMailsWhenDefaultActionUnavailable(MailboxProcessor.java:338)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMail(MailboxProcessor.java:324)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMai
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:35 PM: --- Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 (RC0 is out, waiting for RC1) # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker for 1.18, we can chat off-line as well. was (Author: ym): Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker for 1.18, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:35 PM: --- Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker for 1.18, we can chat off-line as well. was (Author: ym): Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:39 PM: --- Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 (RC0 is out, waiting for RC1) # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker for 1.18, we can chat off-line as well. Or at least I do not want this to block the RC? was (Author: ym): Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 (RC0 is out, waiting for RC1) # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker for 1.18, we can chat off-line as well. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:41 PM: --- Hey [~pnowojski] # Strictly speaking, yes it is a blocker for release. # But since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged), maybe we should not make this a blocker issue for RC1 of 1.18 (RC0 is out, waiting for RC1)? # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # I agree we should have this set up before 1.18 release. was (Author: ym): Hey [~pnowojski] # I think this issue is very critical as you mentioned # Since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged). I do not see why this should be a blocker issue for release 1.18 (RC0 is out, waiting for RC1) # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # If you think this is indeed a blocker for 1.18, we can chat off-line as well. Or at least I do not want this to block the RC? > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 1:44 PM: --- Hey [~pnowojski] # Strictly speaking, yes it is a blocker for release. # But since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged), maybe we should not make this a blocker issue for RC? # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # I agree we should have this set up before 1.18 release. was (Author: ym): Hey [~pnowojski] # Strictly speaking, yes it is a blocker for release. # But since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged), maybe we should not make this a blocker issue for RC1 of 1.18 (RC0 is out, waiting for RC1)? # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # I agree we should have this set up before 1.18 release. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] mxm commented on a diff in pull request #672: [FLINK-33081] Apply parallelism overrides in scale
mxm commented on code in PR #672:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/672#discussion_r1324308777
##
flink-kubernetes-operator-autoscaler/src/main/java/org/apache/flink/kubernetes/operator/autoscaler/JobAutoScalerImpl.java:
##
@@ -74,6 +76,36 @@ public JobAutoScalerImpl(
this.infoManager = new AutoscalerInfoManager();
}
+@Override
+public void scale(FlinkResourceContext ctx) {
+var conf = ctx.getObserveConfig();
+var resource = ctx.getResource();
+var resourceId = ResourceID.fromResource(resource);
+var autoscalerMetrics = getOrInitAutoscalerFlinkMetrics(ctx,
resourceId);
+
+try {
+if (resource.getSpec().getJob() == null ||
!conf.getBoolean(AUTOSCALER_ENABLED)) {
+LOG.debug("Autoscaler is disabled");
+return;
+}
+
+// Initialize metrics only if autoscaler is enabled
+var status = resource.getStatus();
+if (status.getLifecycleState() != ResourceLifecycleState.STABLE
+||
!status.getJobStatus().getState().equals(JobStatus.RUNNING.name())) {
+LOG.info("Autoscaler is waiting for RUNNING job state");
+lastEvaluatedMetrics.remove(resourceId);
+return;
+}
+
+updateParallelismOverrides(ctx, conf, resource, resourceId,
autoscalerMetrics);
+} catch (Throwable e) {
+onError(ctx, resource, autoscalerMetrics, e);
+} finally {
+applyParallelismOverrides(ctx);
Review Comment:
At first sight, this looks like the overrides will get applied, even if the
autoscaler is disabled. There is another check though that prevents this here:
https://github.com/apache/flink-kubernetes-operator/pull/672/files?diff=unified&w=1#diff-7df0c6b50a32c0055e6a1dcfcf9ab25cddb2a245b2125119fd9b57d65918698dR128
(line 128)
A bit confusing. See other comment line 88.
##
flink-kubernetes-operator-autoscaler/src/main/java/org/apache/flink/kubernetes/operator/autoscaler/JobAutoScalerImpl.java:
##
@@ -74,6 +76,36 @@ public JobAutoScalerImpl(
this.infoManager = new AutoscalerInfoManager();
}
+@Override
+public void scale(FlinkResourceContext ctx) {
+var conf = ctx.getObserveConfig();
+var resource = ctx.getResource();
+var resourceId = ResourceID.fromResource(resource);
+var autoscalerMetrics = getOrInitAutoscalerFlinkMetrics(ctx,
resourceId);
+
+try {
+if (resource.getSpec().getJob() == null ||
!conf.getBoolean(AUTOSCALER_ENABLED)) {
+LOG.debug("Autoscaler is disabled");
+return;
+}
+
+// Initialize metrics only if autoscaler is enabled
+var status = resource.getStatus();
+if (status.getLifecycleState() != ResourceLifecycleState.STABLE
+||
!status.getJobStatus().getState().equals(JobStatus.RUNNING.name())) {
+LOG.info("Autoscaler is waiting for RUNNING job state");
+lastEvaluatedMetrics.remove(resourceId);
+return;
+}
+
+updateParallelismOverrides(ctx, conf, resource, resourceId,
autoscalerMetrics);
Review Comment:
```suggestion
runScalingLogic(ctx, conf, resource, resourceId,
autoscalerMetrics);
```
##
flink-kubernetes-operator-autoscaler/src/main/java/org/apache/flink/kubernetes/operator/autoscaler/JobAutoScalerImpl.java:
##
@@ -74,6 +76,36 @@ public JobAutoScalerImpl(
this.infoManager = new AutoscalerInfoManager();
}
+@Override
+public void scale(FlinkResourceContext ctx) {
+var conf = ctx.getObserveConfig();
+var resource = ctx.getResource();
+var resourceId = ResourceID.fromResource(resource);
+var autoscalerMetrics = getOrInitAutoscalerFlinkMetrics(ctx,
resourceId);
+
+try {
+if (resource.getSpec().getJob() == null ||
!conf.getBoolean(AUTOSCALER_ENABLED)) {
+LOG.debug("Autoscaler is disabled");
Review Comment:
Would reset the overrides here.
##
flink-kubernetes-operator-autoscaler/src/main/java/org/apache/flink/kubernetes/operator/autoscaler/JobAutoScalerImpl.java:
##
@@ -74,6 +76,36 @@ public JobAutoScalerImpl(
this.infoManager = new AutoscalerInfoManager();
}
+@Override
+public void scale(FlinkResourceContext ctx) {
+var conf = ctx.getObserveConfig();
+var resource = ctx.getResource();
+var resourceId = ResourceID.fromResource(resource);
+var autoscalerMetrics = getOrInitAutoscalerFlinkMetrics(ctx,
resourceId);
+
Review Comment:
An alternative would be to apply the current overrides here and the new
overrides after the scaling. That would get rid of the finally block.
--
This is an automated message from the Apache G
[jira] [Commented] (FLINK-33053) Watcher leak in Zookeeper HA mode
[
https://issues.apache.org/jira/browse/FLINK-33053?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764702#comment-17764702
]
Zili Chen commented on FLINK-33053:
---
I noticed that the {{TreeCache}}'s close call {{removeWatches}} instead of
{{removeAllWatches}} called by your scripts above.
{{removeWatches}} only remove the watcher in client side so remain the server
side watcher as is.
> Watcher leak in Zookeeper HA mode
> -
>
> Key: FLINK-33053
> URL: https://issues.apache.org/jira/browse/FLINK-33053
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.17.0, 1.18.0, 1.17.1
>Reporter: Yangze Guo
>Priority: Blocker
> Attachments: 26.dump.zip, 26.log,
> taskmanager_flink-native-test-117-taskmanager-1-9_thread_dump (1).json
>
>
> We observe a watcher leak in our OLAP stress test when enabling Zookeeper HA
> mode. TM's watches on the leader of JobMaster has not been stopped after job
> finished.
> Here is how we re-produce this issue:
> - Start a session cluster and enable Zookeeper HA mode.
> - Continuously and concurrently submit short queries, e.g. WordCount to the
> cluster.
> - echo -n wchp | nc \{zk host} \{zk port} to get current watches.
> We can see a lot of watches on
> /flink/\{cluster_name}/leader/\{job_id}/connection_info.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Comment Edited] (FLINK-33052) codespeed server is down
[ https://issues.apache.org/jira/browse/FLINK-33052?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764675#comment-17764675 ] Yuan Mei edited comment on FLINK-33052 at 9/13/23 2:14 PM: --- Hey [~pnowojski] # Strictly speaking, yes it is a blocker for release. # But since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged), maybe we should not make this a blocker issue for RC? # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # I agree we should have this set up as soon as possible, best before 1.18 release. was (Author: ym): Hey [~pnowojski] # Strictly speaking, yes it is a blocker for release. # But since 1.18 has been branch cut and most of the tests have already been done (No feature is allowed to be merged), maybe we should not make this a blocker issue for RC? # [~Zakelly] has already been working on this, but as you can see this issue takes time (applying grants for buying new machines and set up everything, e.t.c) # I agree we should have this set up before 1.18 release. > codespeed server is down > > > Key: FLINK-33052 > URL: https://issues.apache.org/jira/browse/FLINK-33052 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Test Infrastructure >Affects Versions: 1.18.0 >Reporter: Jing Ge >Assignee: Zakelly Lan >Priority: Blocker > > No update in #flink-dev-benchmarks slack channel since 25th August. > It was a EC2 running in a legacy aws account. Currently on one knows which > account it is. > > https://apache-flink.slack.com/archives/C0471S0DFJ9/p1693932155128359 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] dawidwys opened a new pull request, #23412: [FLINK-33083] Properly apply ReadingMetadataSpec for a TableSourceScan
dawidwys opened a new pull request, #23412: URL: https://github.com/apache/flink/pull/23412 ## What is the purpose of the change The PR fixes creating a TableSourceScan to also include a proper ReadingMetadataSpec which has been applied on the source. ## Brief change log * revert the solution added in #22894 because it works around the outcome of the bug rather than fixes the bug * create a ReadingMetadataSpec when applying it on the `TableSource` in a `TableSourceScan` ## Verifying this change * tests added in #22894 should still pass * added a dedicated test `TableSourceJsonPlanITCase#testReadingMetadataWithProjectionPushDownDisabled` ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (**not applicable** / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-33083) SupportsReadingMetadata is not applied when loading a CompiledPlan
[
https://issues.apache.org/jira/browse/FLINK-33083?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-33083:
---
Labels: pull-request-available (was: )
> SupportsReadingMetadata is not applied when loading a CompiledPlan
> --
>
> Key: FLINK-33083
> URL: https://issues.apache.org/jira/browse/FLINK-33083
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.16.2, 1.17.1
>Reporter: Dawid Wysakowicz
>Assignee: Dawid Wysakowicz
>Priority: Major
> Labels: pull-request-available
>
> If a few conditions are met, we can not apply ReadingMetadata interface:
> # source overwrites:
> {code}
> @Override
> public boolean supportsMetadataProjection() {
> return false;
> }
> {code}
> # source does not implement {{SupportsProjectionPushDown}}
> # table has metadata columns e.g.
> {code}
> CREATE TABLE src (
> physical_name STRING,
> physical_sum INT,
> timestamp TIMESTAMP_LTZ(3) NOT NULL METADATA VIRTUAL
> )
> {code}
> # we query the table {{SELECT * FROM src}}
> It fails with:
> {code}
> Caused by: java.lang.IllegalArgumentException: Row arity: 1, but serializer
> arity: 2
> at
> org.apache.flink.table.runtime.typeutils.RowDataSerializer.copy(RowDataSerializer.java:124)
> {code}
> The reason is {{SupportsReadingMetadataSpec}} is created only in the
> {{PushProjectIntoTableSourceScanRule}}, but the rule is not applied when 1 & 2
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #23412: [FLINK-33083] Properly apply ReadingMetadataSpec for a TableSourceScan
flinkbot commented on PR #23412: URL: https://github.com/apache/flink/pull/23412#issuecomment-1717739419 ## CI report: * 75b651538a1fa083c211ab8c4020822590b89043 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-33053) Watcher leak in Zookeeper HA mode
[
https://issues.apache.org/jira/browse/FLINK-33053?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764721#comment-17764721
]
Zili Chen commented on FLINK-33053:
---
See https://lists.apache.org/thread/3b9hn9j4c05yfztlr2zcctbg7sqwdh58.
This seems to be a ZK issue that I met one year ago..
> Watcher leak in Zookeeper HA mode
> -
>
> Key: FLINK-33053
> URL: https://issues.apache.org/jira/browse/FLINK-33053
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.17.0, 1.18.0, 1.17.1
>Reporter: Yangze Guo
>Priority: Blocker
> Attachments: 26.dump.zip, 26.log,
> taskmanager_flink-native-test-117-taskmanager-1-9_thread_dump (1).json
>
>
> We observe a watcher leak in our OLAP stress test when enabling Zookeeper HA
> mode. TM's watches on the leader of JobMaster has not been stopped after job
> finished.
> Here is how we re-produce this issue:
> - Start a session cluster and enable Zookeeper HA mode.
> - Continuously and concurrently submit short queries, e.g. WordCount to the
> cluster.
> - echo -n wchp | nc \{zk host} \{zk port} to get current watches.
> We can see a lot of watches on
> /flink/\{cluster_name}/leader/\{job_id}/connection_info.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (FLINK-33053) Watcher leak in Zookeeper HA mode
[
https://issues.apache.org/jira/browse/FLINK-33053?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17764723#comment-17764723
]
Zili Chen commented on FLINK-33053:
---
But we don't have other shared watchers so we can force remove watches as above.
> Watcher leak in Zookeeper HA mode
> -
>
> Key: FLINK-33053
> URL: https://issues.apache.org/jira/browse/FLINK-33053
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Coordination
>Affects Versions: 1.17.0, 1.18.0, 1.17.1
>Reporter: Yangze Guo
>Priority: Blocker
> Attachments: 26.dump.zip, 26.log,
> taskmanager_flink-native-test-117-taskmanager-1-9_thread_dump (1).json
>
>
> We observe a watcher leak in our OLAP stress test when enabling Zookeeper HA
> mode. TM's watches on the leader of JobMaster has not been stopped after job
> finished.
> Here is how we re-produce this issue:
> - Start a session cluster and enable Zookeeper HA mode.
> - Continuously and concurrently submit short queries, e.g. WordCount to the
> cluster.
> - echo -n wchp | nc \{zk host} \{zk port} to get current watches.
> We can see a lot of watches on
> /flink/\{cluster_name}/leader/\{job_id}/connection_info.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink-kubernetes-operator] sbrother commented on pull request #668: Give cluster/job role access to k8s services API
sbrother commented on PR #668: URL: https://github.com/apache/flink-kubernetes-operator/pull/668#issuecomment-1717779633 No problem, I just requested an Apache Jira account. And yes, I think that's what I mean. I had created a Flink Session Controller using a basic FlinkDeployment manifest with no job listed (I'm not 100% on the naming of all the different pods, but this is the pod that exposes the Flink dashboard over port 8081). When I sshed into this pod I was surprised that I couldn't run `flink list`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org