Dennis Sweeney <[email protected]> added the comment:
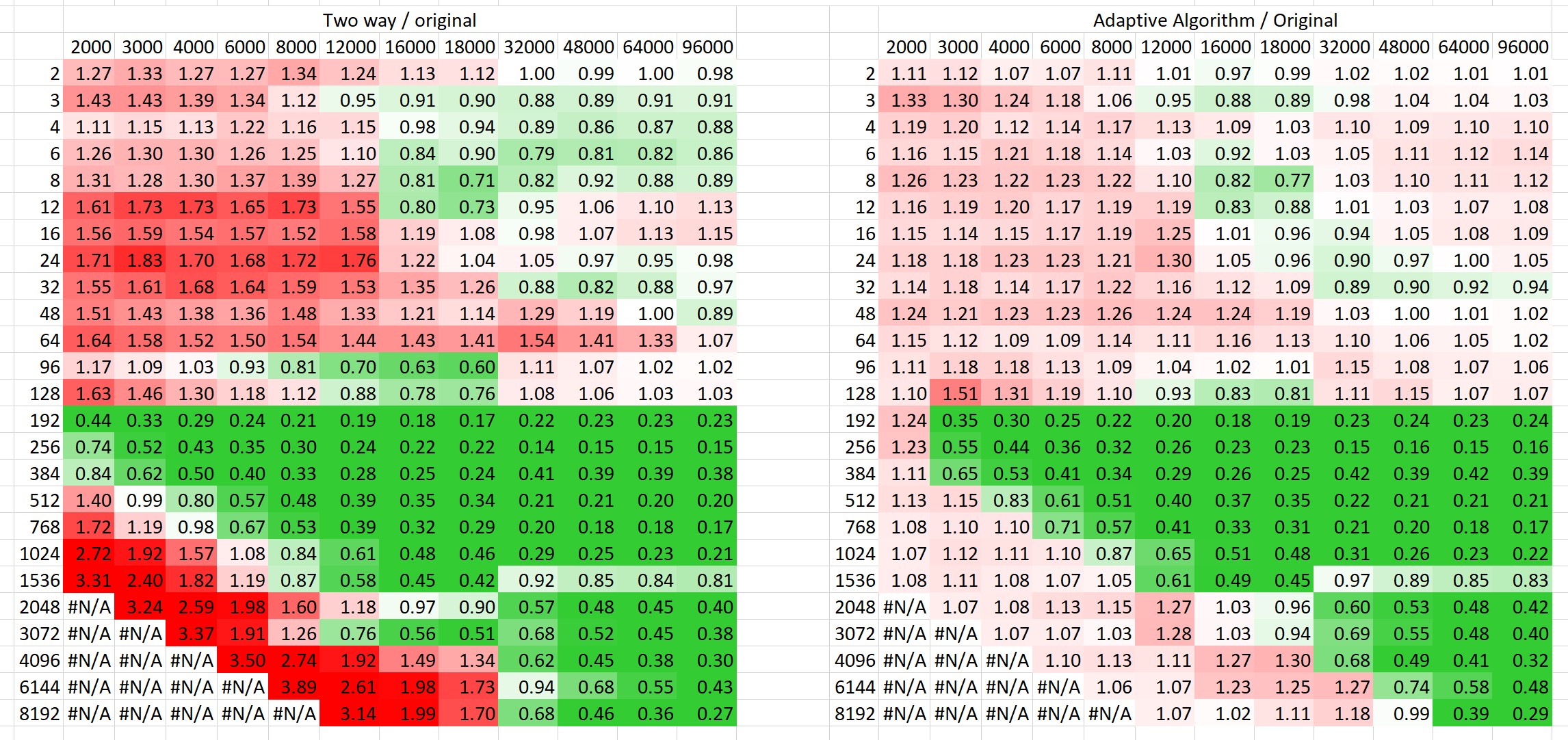
PR 22904 now adds a text document explaining how the Two-Way algorithm works in much more detail. I was looking at more benchmarking results, and I came to a couple of conclusions about cutoffs. There's a consistent benefit to using the two-way algorithm whenever both strings are long enough and the needle is less than 20% the length of the haystack. If that percentage is higher, the preprocessing cost starts to dominate, and the Two-Way algorithm is slower than the status quo in average such cases. This doesn't change the fact that in cases like OP's original example, the Two-way algorithm can be thousands of times faster than the status quo, even though the needle is a significant percentage of the length of the haystack. So to handle that, I tried an adaptive/introspective algorithm like Tim suggested: it counts the number of matched characters that don't lead to full matches, and once that total exceeds O(m), the Two-Way preprocessing cost will surely be worth it. The only way I could figure out how to not damage the speed of the usual small-string cases is to duplicate that code. See comparison.jpg for how much better the adaptive version is as opposed to always using two-way on this Zipf benchmark, while still guaranteeing O(m + n). ---------- Added file: https://bugs.python.org/file49746/comparison.jpg _______________________________________ Python tracker <[email protected]> <https://bugs.python.org/issue41972> _______________________________________ _______________________________________________ Python-bugs-list mailing list Unsubscribe: https://mail.python.org/mailman/options/python-bugs-list/archive%40mail-archive.com
{kind=link}