Matthias Naegler <[email protected]> added the comment:
Thanks Steven for your fast response.
> The best way to see what your string actually contains is the print the repr:
You are right. bytes.decode is correct.
Im not a python expert, so thanks for the note about "repr". With repr(...)
everything looks fine.
Nevertheless, I get an additional \r in my output. Not sure if it is a problem
of python, windows or just me.
I get the following output with the python interpretor:
Python 3.8.3rc1 (tags/v3.8.3rc1:802eb67, Apr 29 2020, 21:39:14) [MSC v.1924 64
bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.stdout.encoding
'utf-8'
>>> b = b'A\r\nA'
>>> s = b.decode('utf-8')
>>> print(b)
b'A\r\nA'
>>> print(repr(s))
'A\r\nA'
>>> print(s)
A
A
>>> sys.stdout.write(s)
A
A4
>>> with open("./test.txt", "a") as myfile:
... myfile.write(s)
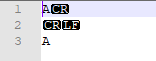
This all looks right. But the file doesn't (see attached screenshot).
I also get an additional \r in the output file if i run the script throught
"python test.py > piped.txt"
----------
Added file: https://bugs.python.org/file49215/test.png
_______________________________________
Python tracker <[email protected]>
<https://bugs.python.org/issue40863>
_______________________________________
_______________________________________________
Python-bugs-list mailing list
Unsubscribe:
https://mail.python.org/mailman/options/python-bugs-list/archive%40mail-archive.com
{kind=link}