Eric Appelt added the comment:
Here are my test results - I'll re-describe the issue and test so people don't
have to read through all the previous text and for completeness.
-------------------------------------
The basic test case ("letter test"):
Consider the set of the first seven letters - {'a', 'b', 'c', 'd', 'e', 'f',
'g'}. If one constructs frozensets of all 128 possible subsets of this set, and
computes their hashes, in principle they should have good collision statistics.
To check, the hashes of all 128 frozensets are computed and the last 7 bits of
each hash are compared. The quality of the hashing algorithm is indicated by
how many unique values of the last 7 bits are present in the set of 128 hashes.
Too few unique values and the collision statistics are poor.
In the python testing suite, this particular test is run and if the number of
unique values is 32 or less the test fails. Since the hash of a string depends
on the value of the PYTHONHASHSEED which is random by default, and the hashes
of frozensets are dependent on their entries, this test is not deterministic.
My earlier tests show that this will fail for one out of every few thousand
seeds.
--------------------------
The implementation issue and proposed fix:
The hash of a frozen set is computed by taking the hash of each element,
shuffling the bits in a deterministic way, and then XORing it into a hash for
the frozenset (starting with zero). The size of the frozenset is then also
shuffled and XORed into that result.
Finally, in order to try to remove patterns incurred by XORing similar
combinations of elements as with nested sets, the resulting hash is sent
through a simple LCG to arrive at a final value:
hash = hash * 69069U + 907133923UL;
The hypothesis is that this LCG is not effective in improving collision rates
for this particular test case. As an alternative, the proposal is to take the
result of the XORs, and run that through the hashing algorithm set in the
compiled python executable for hashing bytes (i.e. FNV or SipHash24). This
rehashing may do a better job of removing patterns set up by combinations of
common elements.
-------------------------------------
The experiment:
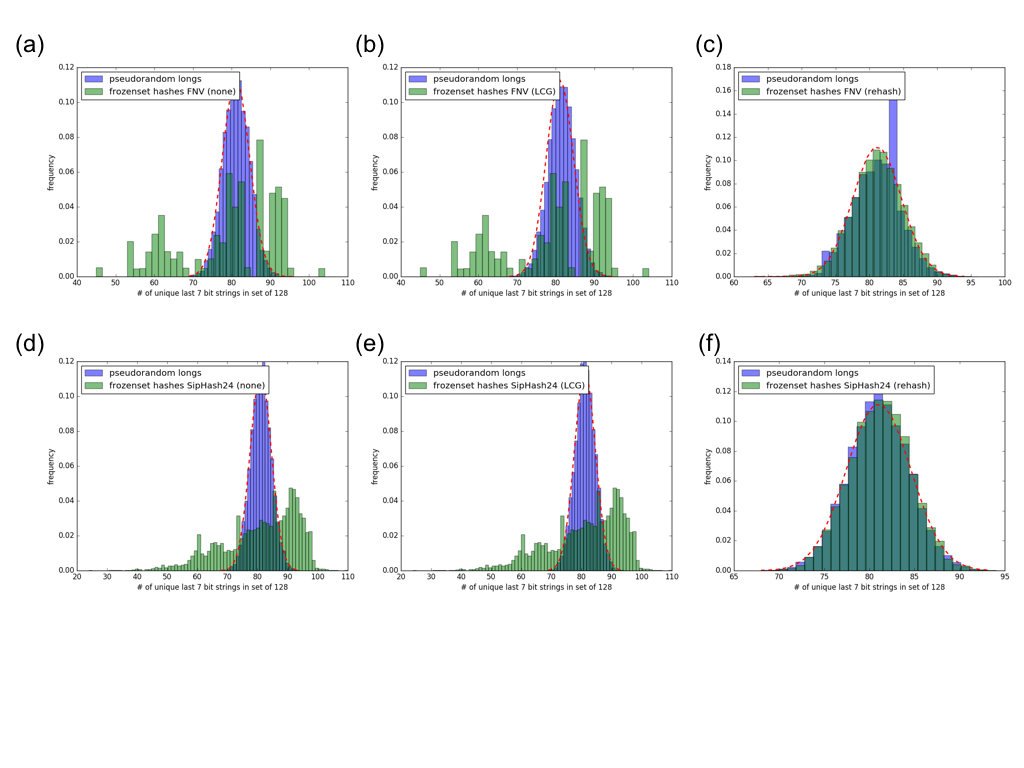
To more robustly check the properties of the frozenset hashing algorithm, the
letter test is run many times setting different PYTHONHASHSEED values from 0 to
10000. This produces a distribution of unique sequences (u) of the last 7 hash
bits in the set of 128 frozensets.
To compare against the optimal case, the same distribution (u) is produced from
a set of pseudorandom integers generated with "random.randint(0, 2**64)". Which
is found to have be a normal distribution with a mean of ~81 and standard
deviation of ~3.5.
Six different test cases are considered and the results are shown in the
attached figure (figure1.png)
- Compile using the FNV algorithm. For control, do not shuffle the XORed result
to compute the frozenset hash. (Fig 1-a)
- Compile using the FNV algorithm. For the current implementation, shuffle the
XORed result using the LCG to compute the frozenset hash. (Fig 1-b)
- Compile using the FNV algorithm. For the current implementation, shuffle the
XORed result using the FNV algorithm to compute the frozenset hash. (Fig 1-c)
- Compile using the SipHash24 algorithm. For control, do not shuffle the XORed
result to compute the frozenset hash. (Fig 1-d)
- Compile using the SipHash24 algorithm. For the current implementation,
shuffle the XORed result using the LCG to compute the frozenset hash. (Fig 1-e)
- Compile using the SipHash24 algorithm. For the current implementation,
shuffle the XORed result using the SipHash24 algorithm to compute the frozenset
hash. (Fig 1-f)
--------------------------------
Results:
Using the LCG to shuffle the XORed result of the entry and size hashes to
finish computing the frozenset hash did not improve the results of the letter
test, and appeared to have no effect on the distribution at all.
Rehashing with the configured algorithm to shuffle the XORed result of the
entry and size hashes to finish computing the frozenset hash did not improve
the results of the letter test, and appeared to have no effect on the
distribution at all.
The FNV results were odd in that specific outlying values of u were often
repeated for different seeds, such as 45 and 104. There was no apparent
periodic behavior in these repeated outlying results.
----------
Added file: http://bugs.python.org/file45306/fig1.png
_______________________________________
Python tracker <[email protected]>
<http://bugs.python.org/issue26163>
_______________________________________
_______________________________________________
Python-bugs-list mailing list
Unsubscribe:
https://mail.python.org/mailman/options/python-bugs-list/archive%40mail-archive.com
{kind=link}