Why would TripleO not move to convergence at the earliest possible point? On Jan 6, 2017 10:37 PM, "Thomas Herve" <[email protected]> wrote:
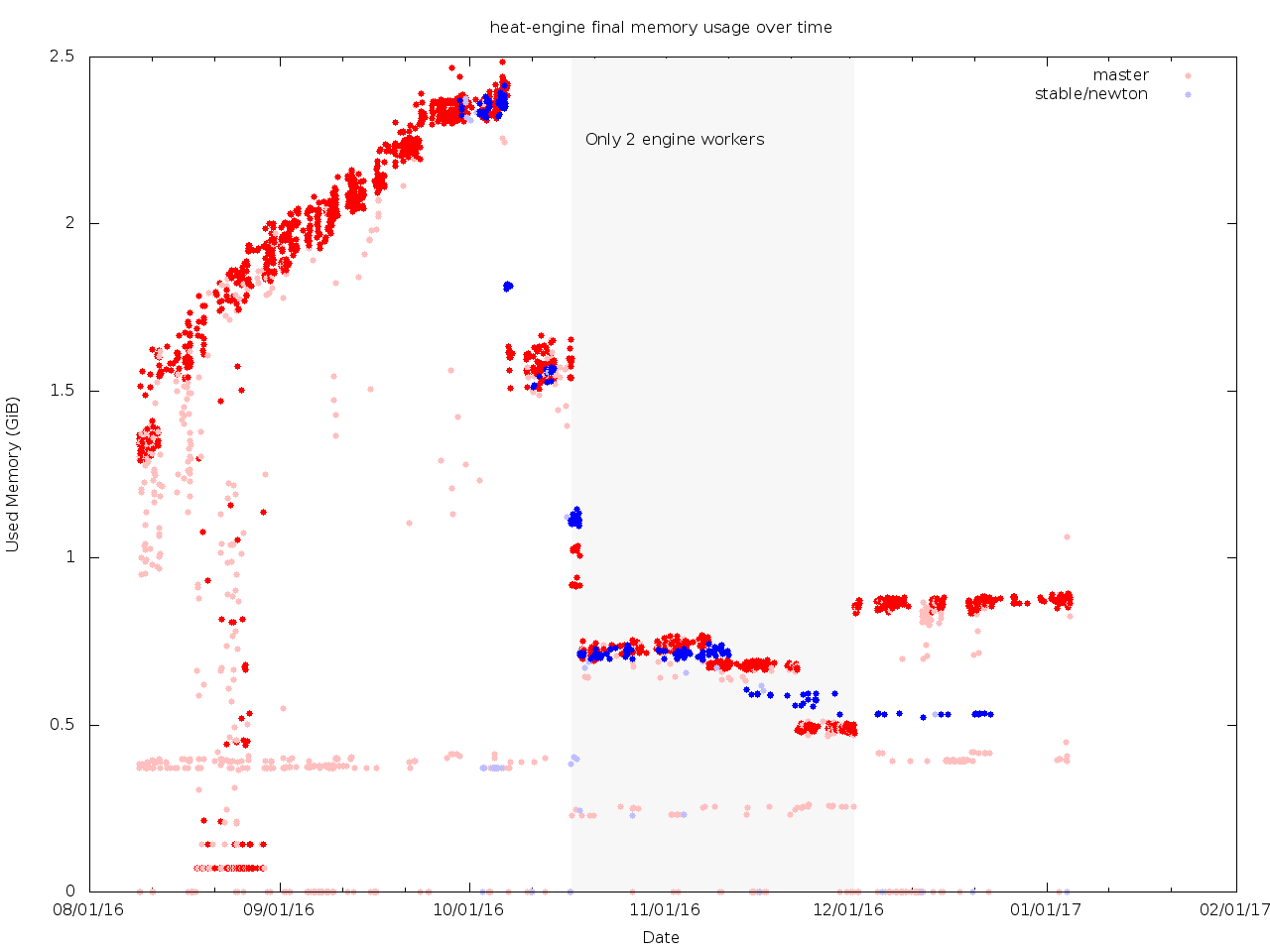
> On Fri, Jan 6, 2017 at 6:12 PM, Zane Bitter <[email protected]> wrote: > > tl;dr everything looks great, and memory usage has dropped by about 64% > > since the initial Newton release of Heat. > > > > I re-ran my analysis of Heat memory usage in the tripleo-heat-templates > > gate. (This is based on the gate-tripleo-ci-centos-7-ovb-nonha job.) > Here's > > a pretty picture: > > > > https://fedorapeople.org/~zaneb/tripleo-memory/20170105/heat_memused.png > > > > There is one major caveat here: for the period marked in grey where it > says > > "Only 2 engine workers", the job was configured to use only 2 > heat-enginer > > worker processes instead of 4, so this is not an apples-to-apples > > comparison. The inital drop at the beginning and the subsequent bounce at > > the end are artifacts of this change. Note that the stable/newton branch > is > > _still_ using only 2 engine workers. > > > > The rapidly increasing usage on the left is due to increases in the > > complexity of the templates during the Newton cycle. It's clear that if > > there has been any similar complexity growth during Ocata, it has had a > tiny > > effect on memory consumption in comparison. > > Thanks a lot for the analysis. It's great that things haven't gotten off > track. > > > I tracked down most of the step changes to identifiable patches: > > > > 2016-10-07: 2.44GiB -> 1.64GiB > > - https://review.openstack.org/382068/ merged, making ResourceInfo > classes > > more memory-efficient. Judging by the stable branch (where this and the > > following patch were merged at different times), this was responsible for > > dropping the memory usage from 2.44GiB -> 1.83GiB. (Which seems like a > > disproportionately large change?) > > Without wanting to get the credit, I believe > https://review.openstack.org/377061/ is more likely the reason here. > > > - https://review.openstack.org/#/c/382377/ merged, so we no longer > create > > multiple yaql contexts. (This was responsible for the drop from 1.83GiB > -> > > 1.64GiB.) > > > > 2016-10-17: 1.62GiB -> 0.93GiB > > - https://review.openstack.org/#/c/386696/ merged, reducing the number > of > > engine workers on the undercloud to 2. > > > > 2016-10-19: 0.93GiB -> 0.73GiB (variance also seemed to drop after this) > > - https://review.openstack.org/#/c/386247/ merged (on 2016-10-16), > avoiding > > loading all nested stacks in a single process simultaneously much of the > > time. > > - https://review.openstack.org/#/c/383839/ merged (on 2016-10-16), > > switching output calculations to RPC to avoid almost all simultaneous > > loading of all nested stacks. > > > > 2016-11-08: 0.76GiB -> 0.70GiB > > - This one is a bit of a mystery??? > > Possibly https://review.openstack.org/390064/ ? Reducing the > environment size could have an effect. > > > 2016-11-22: 0.69GiB -> 0.50GiB > > - https://review.openstack.org/#/c/398476/ merged, improving the > efficiency > > of resource listing? > > > > 2016-12-01: 0.49GiB -> 0.88GiB > > - https://review.openstack.org/#/c/399619/ merged, returning the > number of > > engine workers on the undercloud to 4. > > > > It's not an exact science because IIUC there's a delay between a patch > > merging in Heat and it being used in subsequent t-h-t gate jobs. e.g. the > > change to getting outputs over RPC landed the day before the > > instack-undercloud patch that cut the number of engine workers, but the > > effects don't show up until 2 days after. I'd love to figure out what > > happened on the 8th of November, but I can't correlate it to anything > > obvious. The attribution of the change on the 22nd also seems dubious, > but > > the timing adds up (including on stable/newton). > > > > It's fair to say that none of the other patches we merged in an attempt > to > > reduce memory usage had any discernible effect :D > > > > It's worth reiterating that TripleO still disables convergence in the > > undercloud, so these are all tests of the legacy code path. It would be > > great if we could set up a non-voting job on t-h-t with convergence > enabled > > and start tracking memory use over time there too. As a first step, > maybe we > > could at least add an experimental job on Heat to give us a baseline? > > +1. We haven't made any huge changes into that direction, but having > some info would be great. > > -- > Thomas > > __________________________________________________________________________ > OpenStack Development Mailing List (not for usage questions) > Unsubscribe: [email protected]?subject:unsubscribe > http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev >
{kind=link}
__________________________________________________________________________ OpenStack Development Mailing List (not for usage questions) Unsubscribe: [email protected]?subject:unsubscribe http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev