On 25/08/16 09:49, James Slagle wrote:
On Thu, Aug 25, 2016 at 5:40 AM, Derek Higgins <[email protected]> wrote:
On 25 August 2016 at 02:56, Paul Belanger <[email protected]> wrote:
On Wed, Aug 24, 2016 at 02:11:32PM -0400, James Slagle wrote:
The latest recurring problem that is failing a lot of the nonha ssl
jobs in tripleo-ci is:
https://bugs.launchpad.net/tripleo/+bug/1616144
tripleo-ci: nonha jobs failing with Unable to establish connection to
https://192.0.2.2:13004/v1/a90407df1e7f4f80a38a1b1671ced2ff/stacks/overcloud/f9f6f712-8e89-4ea9-a34b-6084dc74b5c1
This error happens while polling for events from the overcloud stack
by tripleoclient.
I can reproduce this error very easily locally by deploying with an
ssl undercloud with 6GB ram and 2 vcpus. If I don't enable swap,
something gets OOM killed. If I do enable swap, swap gets used (< 1GB)
and then I hit this error almost every time.
The stack keeps deploying but the client has died, so the job fails.
My investigation so far has only pointed out that it's the swap
allocation that is delaying things enough to cause the failure.
We do not see this error in the ha job even though it deploys more
nodes. As of now, my only suspect is that it's the overhead of the
initial SSL connections causing the error.
If I test with 6GB ram and 4 vcpus I can't reproduce the error,
although much more swap is used due to the increased number of default
workers for each API service.
However, I suggest we just raise the undercloud specs in our jobs to
8GB ram and 4 vcpus. These seem reasonable to me because those are the
default specs used by infra in all of their devstack single and
multinode jobs spawned on all their other cloud providers. Our own
multinode job for the undercloud/overcloud and undercloud only job are
running on instances of these sizes.
Close, our current flavors are 8vCPU, 8GB RAM, 80GB HDD. I'd recommend doing
that for the undercloud just to be consistent.
The HD on most of the compute nodes are 200GB so we've been trying
really hard[1] to keep the disk usage for each instance down so that
we can fit as many instances onto each compute nodes as possible
without being restricted by the HD's. We've also allowed nova to
overcommit on storage by a factor of 3. The assumption is that all of
the instances are short lived and a most of them never fully exhaust
the storage allocated to them. Even the ones that do (the undercloud
being the one that does) hit peak at different times so everything is
tickety boo.
I'd strongly encourage against using a flavor with a 80GB HDD, if we
increase the disk space available to the undercloud to 80GB then we
will eventually be using it in CI. And 3 undercloud on the same
compute node will end up filling up the disk on that host.
I've gone ahead and made the changes to the undercloud flavor in rh1
to use 8GB ram and 4 vcpus. I left the disk at 40. I'd like to see use
the same flavor specs as the default infra flavor, but going up to
8vcpus would require configuring less workers per api service I think.
That's something we can iterate towards I think.
We should start seeing new instances coming online using the specs
from the updated undercloud flavor.
I've just completed an analysis of the memory usage of the
gate-tripleo-ci-centos-7-ovb-nonha job as run on changes to
tripleo-heat-templates. (Specifically, this is looking at the "used"
column in dstat, which IIUC excludes kernel buffers and the page cache.)
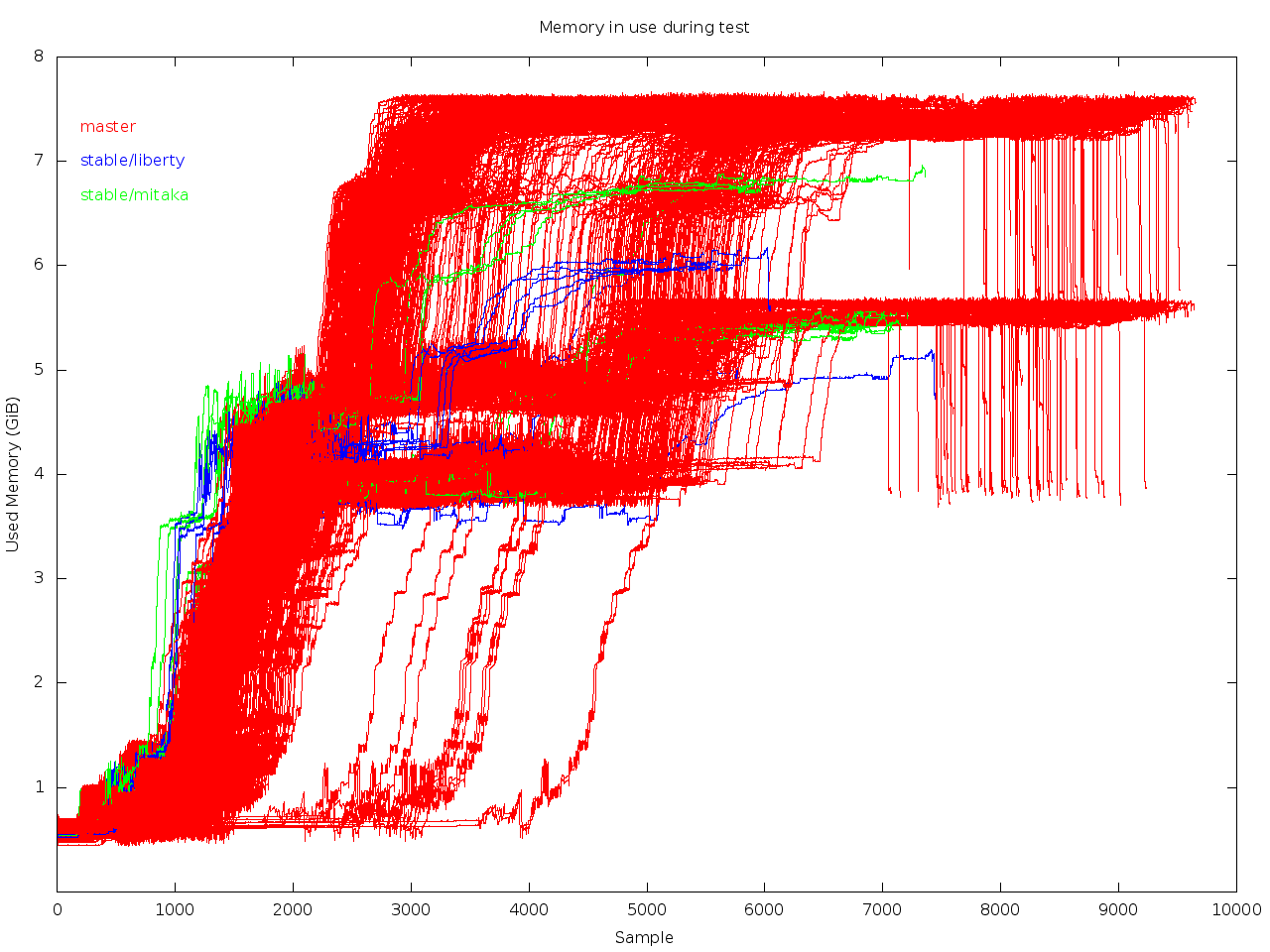
Here's the memory consumption history during the test of all 863
successful runs of that check job:
https://zaneb.fedorapeople.org/tripleo-memory/20160930/memused.png
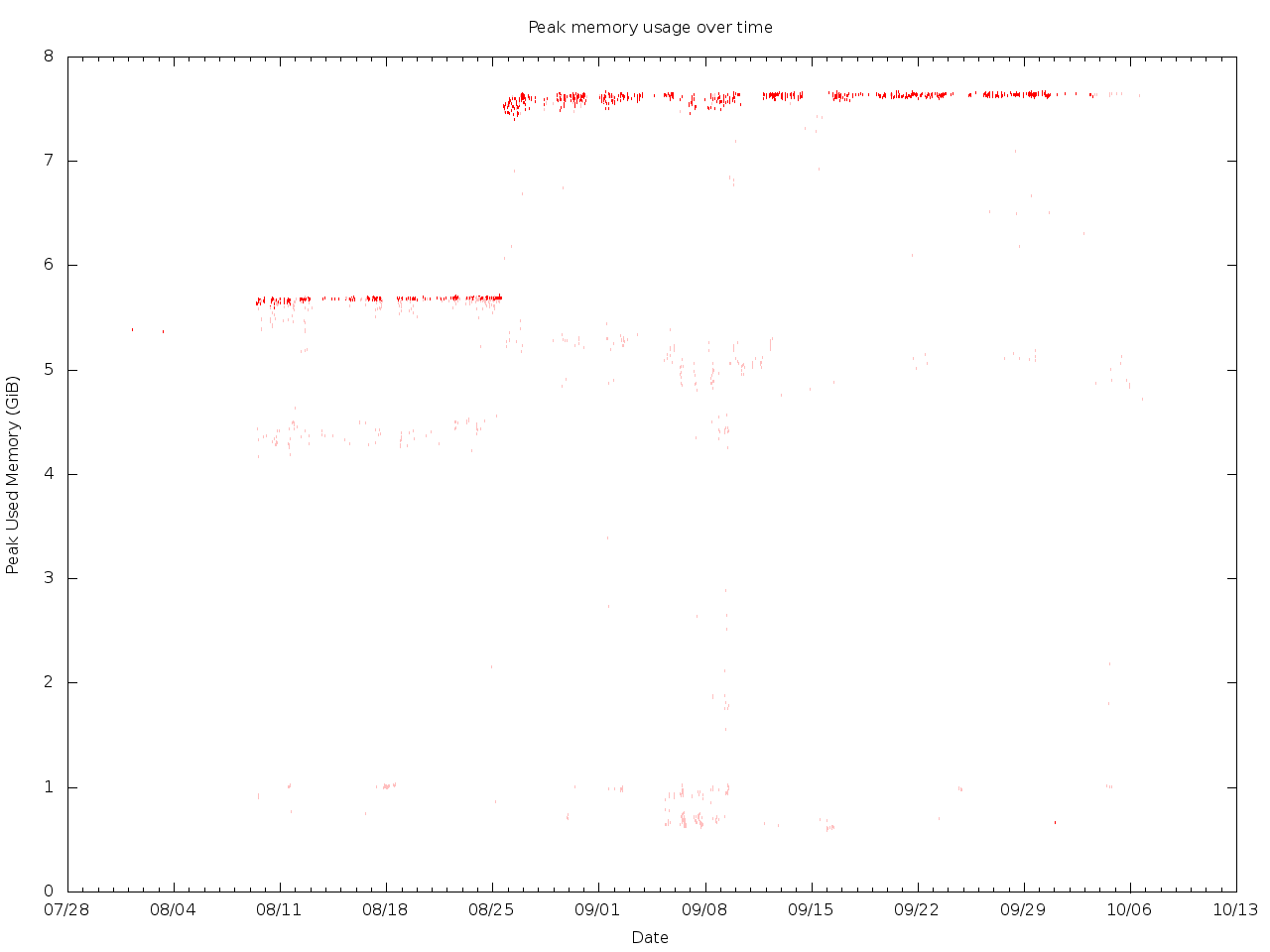
There was a step change to the peak usage from around 5.7GiB to around
7.5GiB some time between a test that started at 12:47Z and one that
started at 17:01Z on the 25th of August:
https://zaneb.fedorapeople.org/tripleo-memory/20160930/max_memused.png
For reference, the email to which I am replying was sent at 13:49Z on
the same day.
This suggests to me that there could be some process that endeavours to
use some large percentage (75%?) of the physical RAM on a box, and that
short of providing absurd amounts of RAM we may always be in reach of
the OOM killer on a box without swap. (I have no idea what process that
might be, but MongoDB is always guilty unless proven innocent. I'm just
saying.)
Current used memory peaks are around 7.6GiB for master, 6.8GiB for
stable/mitaka (up from around 5.6GiB) and 6.1GiB for stable/liberty.
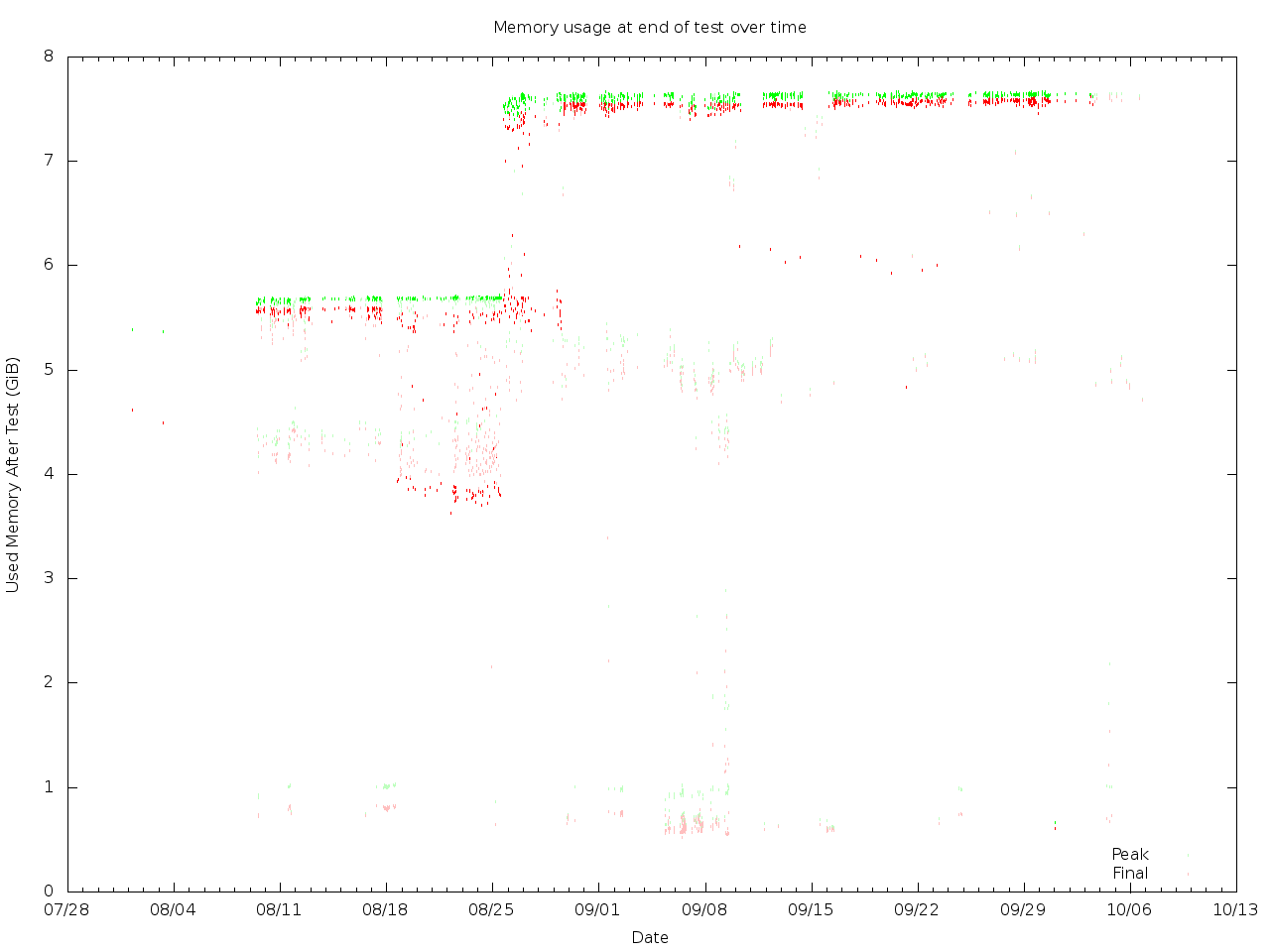
The phenomenon where a couple of GB get suddenly freed just before the
end of the test seems interesting. It suggests that maybe something
other than a daemon is using a lot of memory - python-tripleoclient
being the obvious suspect. However a time-based analysis reveals that it
only ever happened sporadically and only over the time course of about a
week and a half in late August:
https://zaneb.fedorapeople.org/tripleo-memory/20160930/last_memused.png
Fwiw, I tested Giulio's python-tripleoclient patch in my environment
where I can reproduce the failure and it did not help with this
specific issue, although I think the patch is still a step in the
right direction.
The data confirm that there is no appreciable change in peak memory
usage corresponding to the time https://review.openstack.org/#/c/360141/
merged.
Unfortunately none of this leaves me any the wiser as to the cause of
the increase in Heat memory usage documented in
https://bugs.launchpad.net/heat/+bug/1626675 - there was only one jump
in the data and it seems to be caused by a change in the test setup. Do
we have a dataset that goes back earlier than the 9th of August that I
could try running the same analysis on?
cheers,
Zane.
__________________________________________________________________________
OpenStack Development Mailing List (not for usage questions)
Unsubscribe: [email protected]?subject:unsubscribe
http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev
{kind=link}
{kind=link}
{kind=link}