The purpose of this email is to brainstorm some ideas about how TripleO could be scaled out for large deployments.
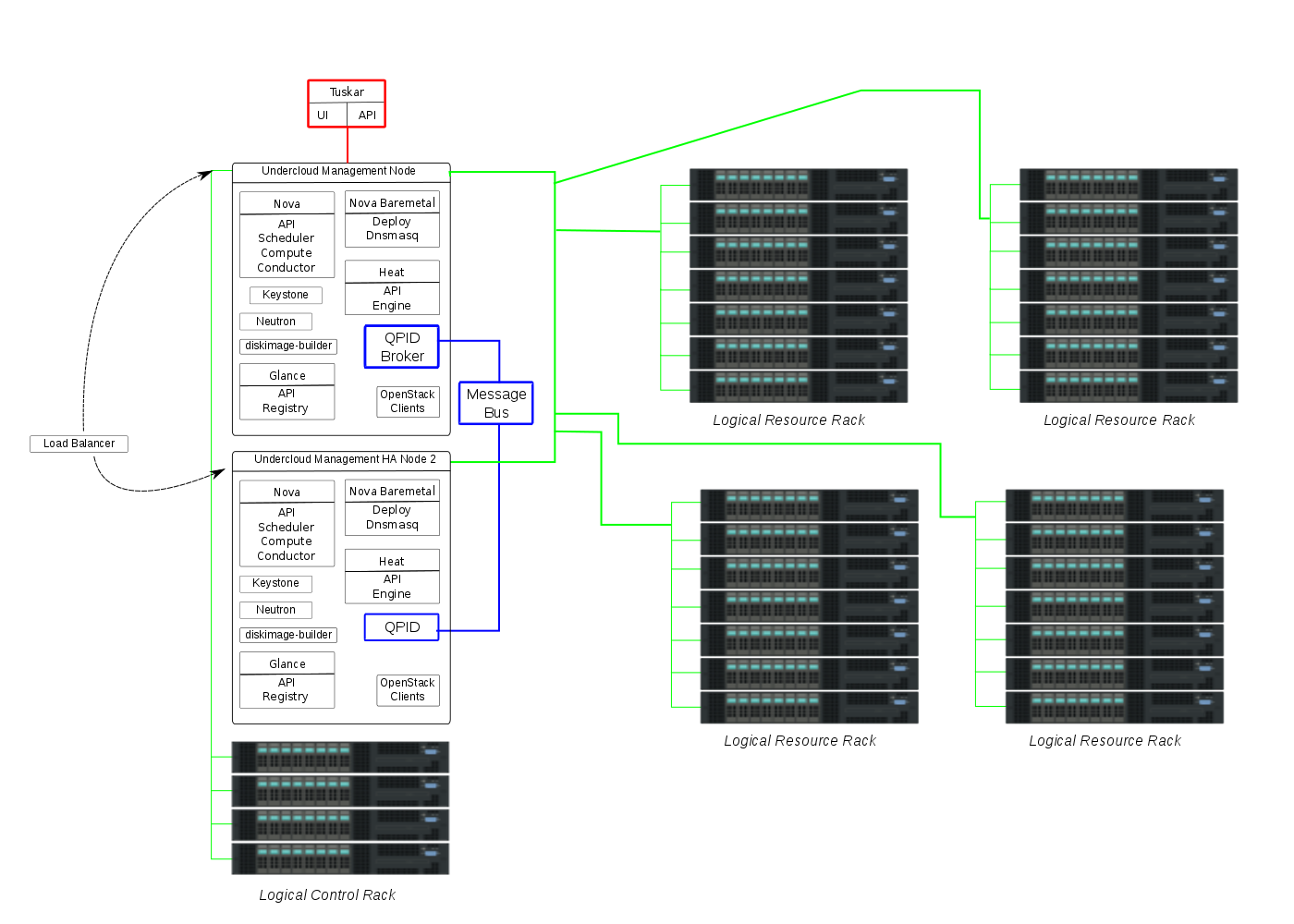
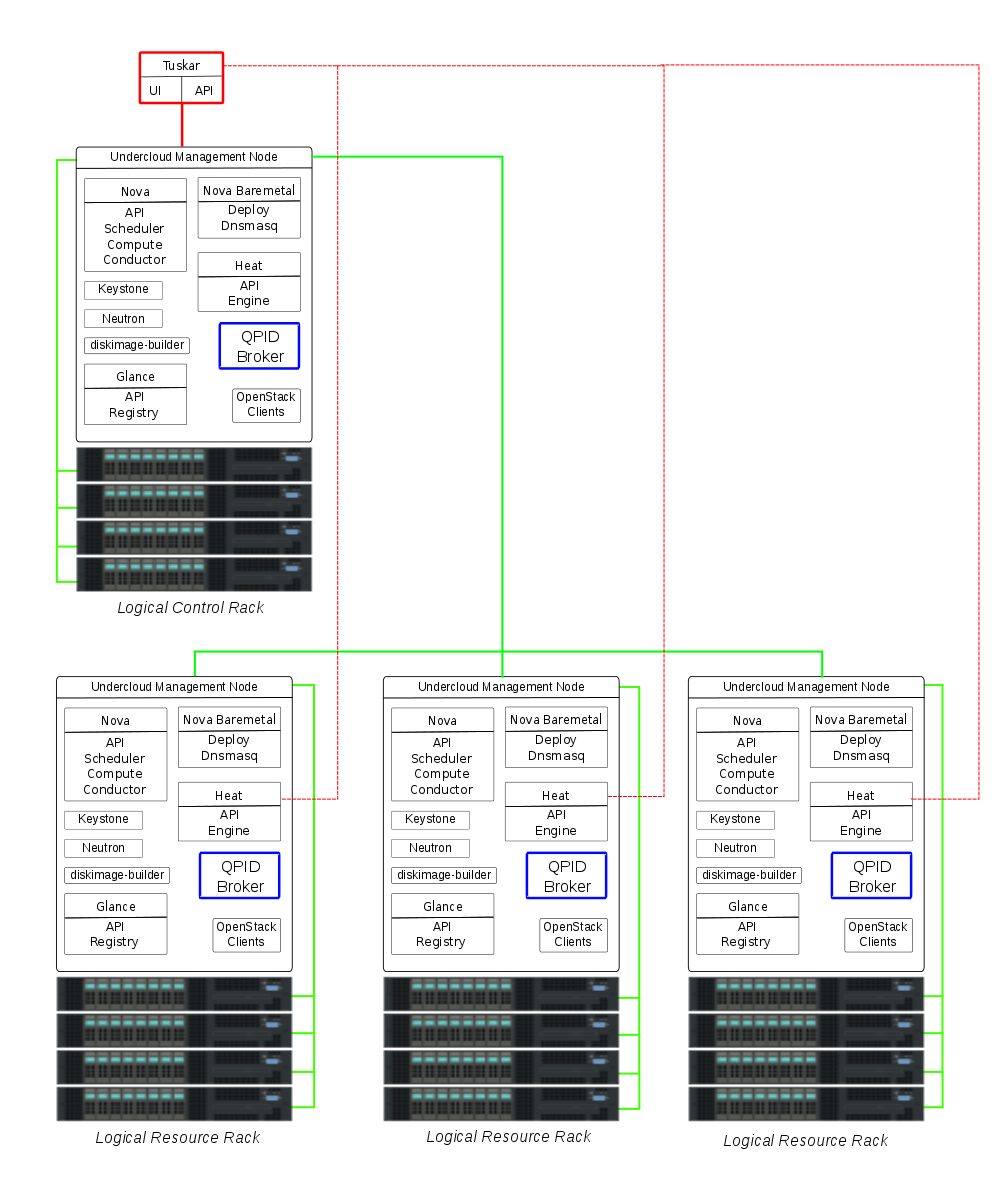
Idea 0 ------ According to what we've read (and watched), the TripleO idea is that you're going to have a single undercloud composed of at least 2 machines running the undercloud services (nova, glance, keystone, neutron, rabbitmq, mysql) in HA mode. The way you would add horizontal scale to this model is by adding more undercloud machines running the same stack of services in HA mode, so they could share the workload. Does this match others current thinking about TripleO at scale? I attempted to diagram this idea at [1]. Sorry, if it's a bit crude :). A couple points to mention about the diagram: * it's showing scalability as opposed to full HA. there's a shared message bus, would be shared db's, a load balancer in front of API services, etc. * For full HA, you can add additional nodes that didn't share single points of failures (like the bus). * The green lines are meant to show the management network domain, and can be thought of roughly as "managed by". * Logical Rack is just meant to imply "a grouping of baremetal hardware". It might be a physical rack, but it doesn't have to be. * Just of note, there's a box there representing where we feel Tuskar would get plugged in. Pros/Cons (+/-): + Easy to install (You start with only one machine in the datacenter running the whole stack of services in HA mode and from there you can just expand it to another machine, enroll the rest of the machines in the datacenter and you're ready to go.) + Easy to upgrade (Since we have fully HA, you could then turn off one machine in the control plane triggering a HA failover, update that machine, bring it up, turn off another machine in the control plane, etc...) - Every node in the overcloud has to be able to talk back to controller rack (e.g. heat/nova) - Possible performance issues when bringing up a large number of machines. (think hyperscale). - Large failure domain. If the HA cluster fails, you've lost all visibility into and management of the infrastructure. - What does the IPMI network look like in this model? Can we assume full IPMI connectivity across racks, logical or physical? In addition, here are a couple of other ideas to bring to the conversation. Note that all the ideas assume 1 Overcloud. Idea 1 ------ The thought here is to have 1 Undercloud again, but be able to deploy N Undercloud Leaf Nodes as needed for scale. The Leaf Node is a smaller subset of services than what is needed on the full Undercloud Node. Essentially, it is enough services to do baremetal provisioning, Heat orchestration, and Neutron for networking. Diagram of this idea is at [2]. In the diagram, there is one Leaf Node per logical rack. In this model, the Undercloud provisions and deploys Leaf Nodes as needed when new hardware is added to the environment. The Leaf Nodes then handle deployment requests from the Undercloud for the Overcloud nodes. As such, there is some scalability built into the architecture in a distributed fashion. Adding more scalability and HA would be accomplished in a similar fashion to Idea 0, by adding additional HA Leaf Nodes, etc. Pros/Cons (+/-): + As scale is added with more Leaf Nodes, it's a smaller set of services. - Additional image management of the Leaf Node image - Additional rack space wasted for the Leaf Node + Smaller failure domain as the logical rack is only dependent on the Leaf Node. + The ratio of HA Management Nodes would be smaller because of the offloaded services. + Better security due to IPMI/RMCP isolation within the rack. Idea 2 ------ In this idea, there are N Underclouds, each with the full set of Undercloud services. As new hardware is brought online, an Undercloud is deployed (if desired) for scalability. Diagram for this idea is at [3]. A single Control Undercloud handles deployment and provisioning of the other Underclouds. This is similar to the seed vm concept of TripleO for Undercloud deployment. However, in this model, the Control Undercloud is not meant to be short lived or go away, so we didn't want to call this the seed directly. Again, HA can be added in a similar fashion to the other ideas. In a way, this idea is not all that different from Idea 0. It could be thought of as using an Idea 0 to deploy other Idea 0's. However, it allows for some additional constraints around network and security with the isolation of each Undercloud in the logical rack. Pros/Cons (+/-): + network/security isolation - multiple Undercloud complexity - Additional rack space wasted for the N Underclouds. + Smaller failure domain as the logical rack is only dependent on it's managing Undercloud. + Better security due to IPMI/RMCP isolation within the rack. + Doesn't necessarily preclude Idea 0 [1] http://fedorapeople.org/~slagle/drawing0.png [2] http://fedorapeople.org/~slagle/drawing1.png [3] http://fedorapeople.org/~slagle/drawing2.png -- -- James Slagle -- _______________________________________________ OpenStack-dev mailing list OpenStack-dev@lists.openstack.org http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev
{kind=link}
{kind=link}
{kind=link}