This is an automated email from the ASF dual-hosted git repository.
zhangliang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 60fe1ef22d3 modify template of features (#19893)
60fe1ef22d3 is described below
commit 60fe1ef22d3c7a767a4e847348c36b2734fedf77
Author: Mike0601 <[email protected]>
AuthorDate: Fri Aug 5 16:21:17 2022 +0800
modify template of features (#19893)
---
.../content/features/db-compatibility/_index.cn.md | 4 +-
.../content/features/db-compatibility/_index.en.md | 4 +-
.../content/features/db-gateway/_index.cn.md | 4 +-
.../content/features/db-gateway/_index.en.md | 4 +-
.../document/content/features/distsql/_index.cn.md | 65 -----
.../document/content/features/distsql/_index.en.md | 64 ----
.../document/content/features/encrypt/_index.cn.md | 87 +-----
.../document/content/features/encrypt/_index.en.md | 72 +----
.../content/features/encrypt/concept.cn.md | 23 ++
.../content/features/encrypt/concept.en.md | 20 ++
.../content/features/encrypt/limitations.cn.md | 9 +
.../content/features/encrypt/limitations.en.md | 9 +
docs/document/content/features/ha/_index.cn.md | 26 +-
docs/document/content/features/ha/_index.en.md | 32 +-
docs/document/content/features/ha/concept.cn.md | 12 +
docs/document/content/features/ha/concept.en.md | 14 +
.../document/content/features/ha/limitations.cn.md | 15 +
.../document/content/features/ha/limitations.en.md | 14 +
.../content/features/management/_index.cn.md | 4 +-
.../content/features/management/_index.en.md | 4 +-
.../content/features/observability/_index.cn.md | 32 +-
.../content/features/observability/_index.en.md | 34 +--
.../observability/{_index.cn.md => concept.cn.md} | 27 +-
.../observability/{_index.en.md => concept.en.md} | 29 +-
.../features/readwrite-splitting/_index.cn.md | 27 +-
.../features/readwrite-splitting/_index.en.md | 32 +-
.../features/readwrite-splitting/concept.cn.md | 16 +
.../features/readwrite-splitting/concept.en.md | 17 ++
.../features/readwrite-splitting/limitations.cn.md | 9 +
.../features/readwrite-splitting/limitations.en.md | 9 +
.../document/content/features/scaling/_index.cn.md | 46 +--
.../document/content/features/scaling/_index.en.md | 48 +--
.../content/features/scaling/concept.cn.md | 28 ++
.../content/features/scaling/concept.en.md | 32 ++
.../content/features/scaling/limitations.cn.md | 15 +
.../content/features/scaling/limitations.en.md | 15 +
docs/document/content/features/shadow/_index.cn.md | 11 +-
docs/document/content/features/shadow/_index.en.md | 52 +---
.../document/content/features/shadow/concept.cn.md | 24 ++
.../document/content/features/shadow/concept.en.md | 21 ++
.../content/features/shadow/limitations.cn.md | 32 ++
.../content/features/shadow/limitations.en.md | 35 +++
.../content/features/sharding/_index.cn.md | 325 +--------------------
.../content/features/sharding/_index.en.md | 319 +-------------------
.../content/features/sharding/concept.cn.md | 167 +++++++++++
.../content/features/sharding/concept.en.md | 168 +++++++++++
.../content/features/sharding/limitation.cn.md | 158 ++++++++++
.../content/features/sharding/limitation.en.md | 150 ++++++++++
.../content/features/transaction/_index.cn.md | 4 +-
.../content/features/transaction/_index.en.md | 4 +-
.../content/features/transaction/concept.cn.md | 9 +
.../content/features/transaction/concept.en.md | 8 +
.../content/features/transaction/limitations.cn.md | 52 ++++
.../content/features/transaction/limitations.en.md | 52 ++++
54 files changed, 1224 insertions(+), 1269 deletions(-)
diff --git a/docs/document/content/features/db-compatibility/_index.cn.md
b/docs/document/content/features/db-compatibility/_index.cn.md
index 16fadcd2492..5c290db4cf9 100644
--- a/docs/document/content/features/db-compatibility/_index.cn.md
+++ b/docs/document/content/features/db-compatibility/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.1. </b>"
+pre = "<b>3.11. </b>"
title = "数据库兼容"
-weight = 1
+weight = 11
chapter = true
+++
diff --git a/docs/document/content/features/db-compatibility/_index.en.md
b/docs/document/content/features/db-compatibility/_index.en.md
index e0960a3f442..fc950ec8f22 100644
--- a/docs/document/content/features/db-compatibility/_index.en.md
+++ b/docs/document/content/features/db-compatibility/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.1. </b>"
+pre = "<b>3.11. </b>"
title = "DB Compatibility"
-weight = 1
+weight = 11
chapter = true
+++
diff --git a/docs/document/content/features/db-gateway/_index.cn.md
b/docs/document/content/features/db-gateway/_index.cn.md
index 5dc3ffc6d19..f09d074ad27 100644
--- a/docs/document/content/features/db-gateway/_index.cn.md
+++ b/docs/document/content/features/db-gateway/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.2. </b>"
+pre = "<b>3.5. </b>"
title = "数据库网关"
-weight = 2
+weight = 5
chapter = true
+++
diff --git a/docs/document/content/features/db-gateway/_index.en.md
b/docs/document/content/features/db-gateway/_index.en.md
index 2d80ad90a67..e1fdf6dfc70 100644
--- a/docs/document/content/features/db-gateway/_index.en.md
+++ b/docs/document/content/features/db-gateway/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.2. </b>"
+pre = "<b>3.5. </b>"
title = "DB Gateway"
-weight = 2
+weight = 5
chapter = true
+++
diff --git a/docs/document/content/features/distsql/_index.cn.md
b/docs/document/content/features/distsql/_index.cn.md
deleted file mode 100644
index 32f86b79713..00000000000
--- a/docs/document/content/features/distsql/_index.cn.md
+++ /dev/null
@@ -1,65 +0,0 @@
-+++
-pre = "<b>3.11. </b>"
-title = "DistSQL"
-weight = 11
-+++
-
-## 定义
-DistSQL(Distributed SQL)是 Apache ShardingSphere 特有的操作语言。 它与标准 SQL
的使用方式完全一致,用于提供增量功能的 SQL 级别操作能力。
-
-灵活的规则配置和资源管控能力是 Apache ShardingSphere 的特点之一。
-
-在使用 4.x
及其之前版本时,开发者虽然可以像使用原生数据库一样操作数据,但却需要通过本地文件或注册中心配置资源和规则。然而,操作习惯变更,对于运维工程师并不友好。
-
-从 5.x 版本开始,DistSQL(Distributed SQL)让用户可以像操作数据库一样操作 Apache
ShardingSphere,使其从面向开发人员的框架和中间件转变为面向运维人员的数据库产品。
-
-## 相关概念
-DistSQL 细分为 RDL、RQL、RAL 和 RUL 四种类型。
-
-### RDL
-Resource & Rule Definition Language,负责资源和规则的创建、修改和删除。
-
-### RQL
-Resource & Rule Query Language,负责资源和规则的查询和展现。
-
-### RAL
-Resource & Rule Administration Language,负责强制路由、熔断、配置导入导出、数据迁移控制等管理功能。
-
-### RUL
-Resource Utility Language,负责 SQL 解析、SQL 格式化、执行计划预览等功能。
-
-## 对系统的影响
-
-### 之前
-在拥有 DistSQL 以前,用户一边使用 SQL 语句操作数据,一边使用 YAML 文件来管理 ShardingSphere 的配置,如下图:
-
-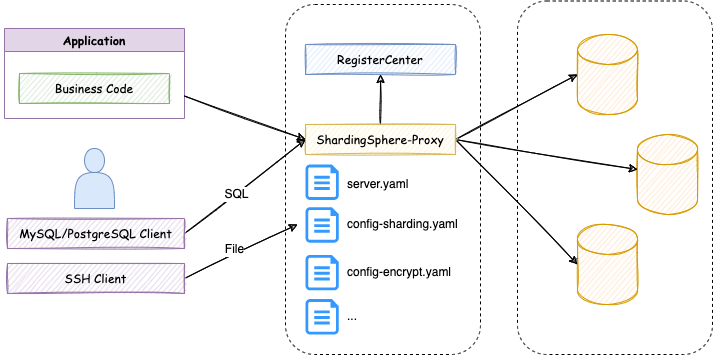
-
-这时用户不得不面对以下几个问题:
-- 需要通过不同类型的客户端来操作数据和管理 ShardingSphere 规则;
-- 多个逻辑库需要多个 YAML 文件;
-- 修改 YAML 需要文件的编辑权限;
-- 修改 YAML 后需要重启 ShardingSphere。
-
-### 之后
-随着 DistSQL 的出现,对 ShardingSphere 的操作方式也得到了改变:
-
-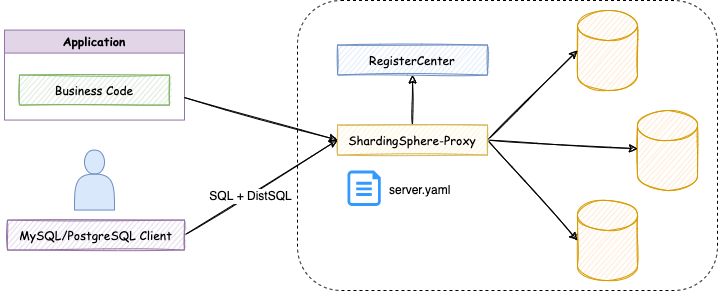
-
-现在,用户的使用体验得到了巨大改善:
-- 使用相同的客户端来管理数据和 ShardingSphere 配置;
-- 不再额外创建 YAML 文件,通过 DistSQL 管理逻辑库;
-- 不再需要文件的编辑权限,通过 DistSQL 来管理配置;
-- 配置的变更实时生效,无需重启 ShardingSphere。
-
-## 使用限制
-DistSQL 只能用于 ShardingSphere-Proxy,ShardingSphere-JDBC 暂不提供。
-
-## 原理介绍
-与标准 SQL 一样,DistSQL 由 ShardingSphere 的解析引擎进行识别,将输入语句转换为抽象语法树,进而生成各个语法对应的
`Statement`,最后由合适的 `Handler` 进行业务处理。
-整体流程如下图所示:
-
-
-
-## 相关参考
-[用户手册:DistSQL](/cn/user-manual/shardingsphere-proxy/distsql/)
diff --git a/docs/document/content/features/distsql/_index.en.md
b/docs/document/content/features/distsql/_index.en.md
deleted file mode 100644
index ebd2d71652e..00000000000
--- a/docs/document/content/features/distsql/_index.en.md
+++ /dev/null
@@ -1,64 +0,0 @@
-+++
-pre = "<b>3.11. </b>"
-title = "DistSQL"
-weight = 11
-+++
-
-## Definition
-DistSQL (Distributed SQL) is Apache ShardingSphere's specific SQL, providing
additional operation capabilities compared to standard SQL.
-
-Flexible rule configuration and resource management & control capabilities are
one of the characteristics of Apache ShardingSphere.
-
-When using 4.x and earlier versions, developers can operate data just like
using a database, but they need to configure resources and rules through YAML
file (or registry center). However, the YAML file format and the changes
brought by using the registry center made it unfriendly to DBAs.
-
-Starting from version 5.x, DistSQL enables users to operate Apache
ShardingSphere just like a database, transforming it from a framework and
middleware for developers to a database product for DBAs.
-
-## Related Concepts
-DistSQL is divided into RDL, RQL, RAL and RUL.
-
-### RDL
-Resource & Rule Definition Language, is responsible for the definition of
resources and rules.
-
-### RQL
-Resource & Rule Query Language, is responsible for the query of resources and
rules.
-
-### RAL
-Resource & Rule Administration Language, is responsible for hint, circuit
breaker, configuration import and export, scaling control and other management
functions.
-
-### RUL
-Resource Utility Language, is responsible for SQL parsing, SQL formatting,
preview execution plan, etc.
-
-## Impact on the System
-
-### Before
-Before having DistSQL, users used SQL to operate data while using YAML
configuration files to manage ShardingSphere, as shown below:
-
-
-
-At that time, users faced the following problems:
-- Different types of clients are required to operate data and manage
ShardingSphere configuration.
-- Multiple logical databases require multiple YAML files.
-- Editing a YAML file requires writing permissions.
-- Need to restart ShardingSphere after editing YAML.
-
-### After
-With the advent of DistSQL, the operation of ShardingSphere has also changed:
-
-
-
-Now, the user experience has been greatly improved:
-- Uses the same client to operate data and ShardingSphere configuration.
-- No need for additional YAML files, and the logical databases are managed
through DistSQL.
-- Editing permissions for files are no longer required, and configuration is
managed through DistSQL.
-- Configuration changes take effect in real-time without restarting
ShardingSphere.
-
-## Limitations
-DistSQL can be used only with ShardingSphere-Proxy, not with
ShardingSphere-JDBC for now.
-
-## How it works
-Like standard SQL, DistSQL is recognized by the parsing engine of
ShardingSphere. It converts the input statement into an abstract syntax tree
and then generates the `Statement` corresponding to each grammar, which is
processed by the appropriate `Handler`.
-
-
-
-## Related References
-[User Manual: DistSQL](/en/user-manual/shardingsphere-proxy/distsql/)
diff --git a/docs/document/content/features/encrypt/_index.cn.md
b/docs/document/content/features/encrypt/_index.cn.md
index 6fab6094046..4c38ddf5f69 100644
--- a/docs/document/content/features/encrypt/_index.cn.md
+++ b/docs/document/content/features/encrypt/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.9. </b>"
+pre = "<b>3.8. </b>"
title = "数据加密"
-weight = 9
+weight = 8
chapter = true
+++
@@ -10,95 +10,12 @@ chapter = true
数据加密是指对某些敏感信息通过加密规则进行数据的变形,实现敏感隐私数据的可靠保护。
涉及客户安全数据或者一些商业性敏感数据,如身份证号、手机号、卡号、客户号等个人信息按照相关部门规定,都需要进行数据加密。
-## 相关概念
-
-### 逻辑列
-
-用于计算加解密列的逻辑名称,是 SQL 中列的逻辑标识。
-逻辑列包含密文列(必须)、查询辅助列(可选)和明文列(可选)。
-
-### 密文列
-
-加密后的数据列。
-
-### 查询辅助列
-
-用于查询的辅助列。
-对于一些安全级别更高的非幂等加密算法,提供不可逆的幂等列用于查询。
-
-### 明文列
-
-存储明文的列,用于在加密数据迁移过程中仍旧提供服务。
-在洗数结束后可以删除。
-
## 对系统的影响
在真实业务场景中,相关业务开发团队则往往需要针对公司安全部门需求,自行实行并维护一套加解密系统。
而当加密场景发生改变时,自行维护的加密系统往往又面临着重构或修改风险。
此外,对于已经上线的业务,在不修改业务逻辑和 SQL 的情况下,透明化、安全低风险地实现无缝进行加密改造也相对复杂。
-## 使用限制
-
-- 需自行处理数据库中原始的存量数据;
-- 加密字段无法支持查询不区分大小写功能;
-- 加密字段无法支持比较操作,如:大于、小于、ORDER BY、BETWEEN、LIKE 等;
-- 加密字段无法支持计算操作,如:AVG、SUM 以及计算表达式。
-
-## 原理介绍
-
-Apache ShardingSphere 通过对用户输入的 SQL 进行解析,并依据用户提供的加密规则对 SQL
进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。
-在用户查询数据时,它仅从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户。
-Apache ShardingSphere 自动化 & 透明化了数据加密过程,让用户无需关注数据加密的实现细节,像使用普通数据那样使用加密数据。
-此外,无论是已在线业务进行加密改造,还是新上线业务使用加密功能,Apache ShardingSphere 都可以提供一套相对完善的解决方案。
-
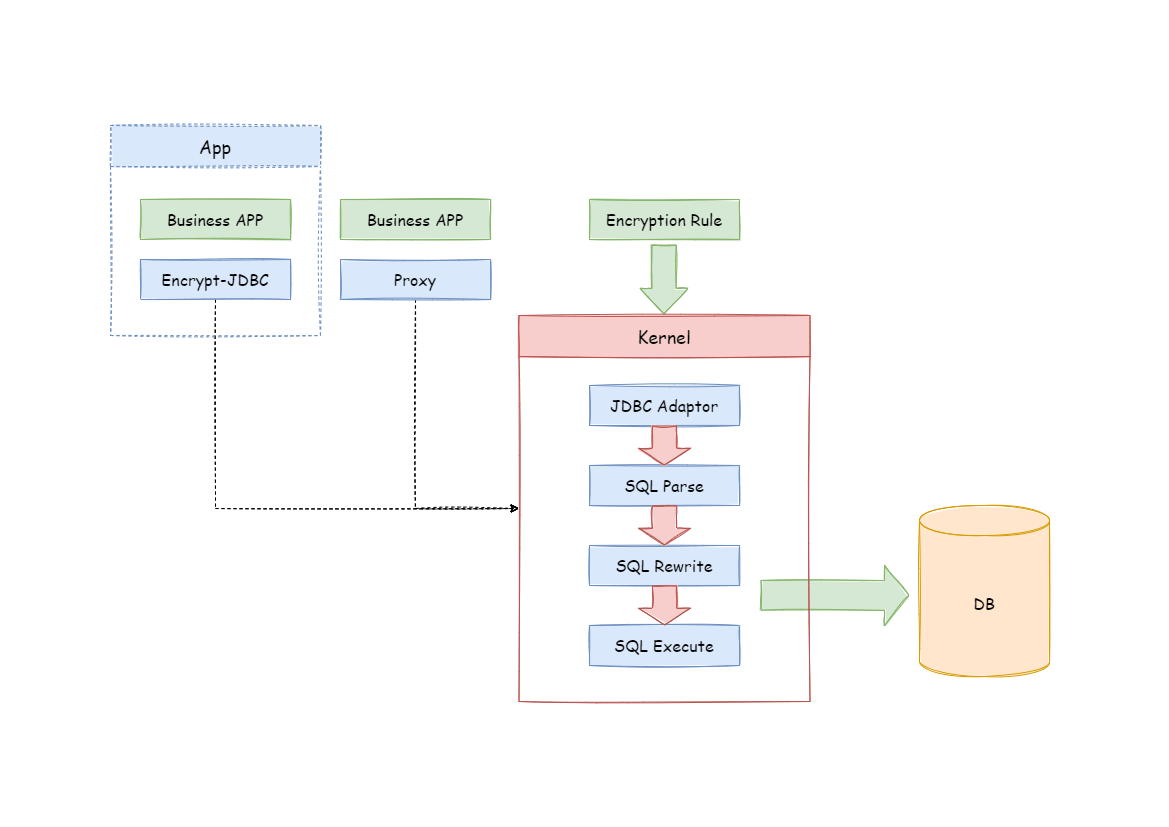
-### 整体架构
-
-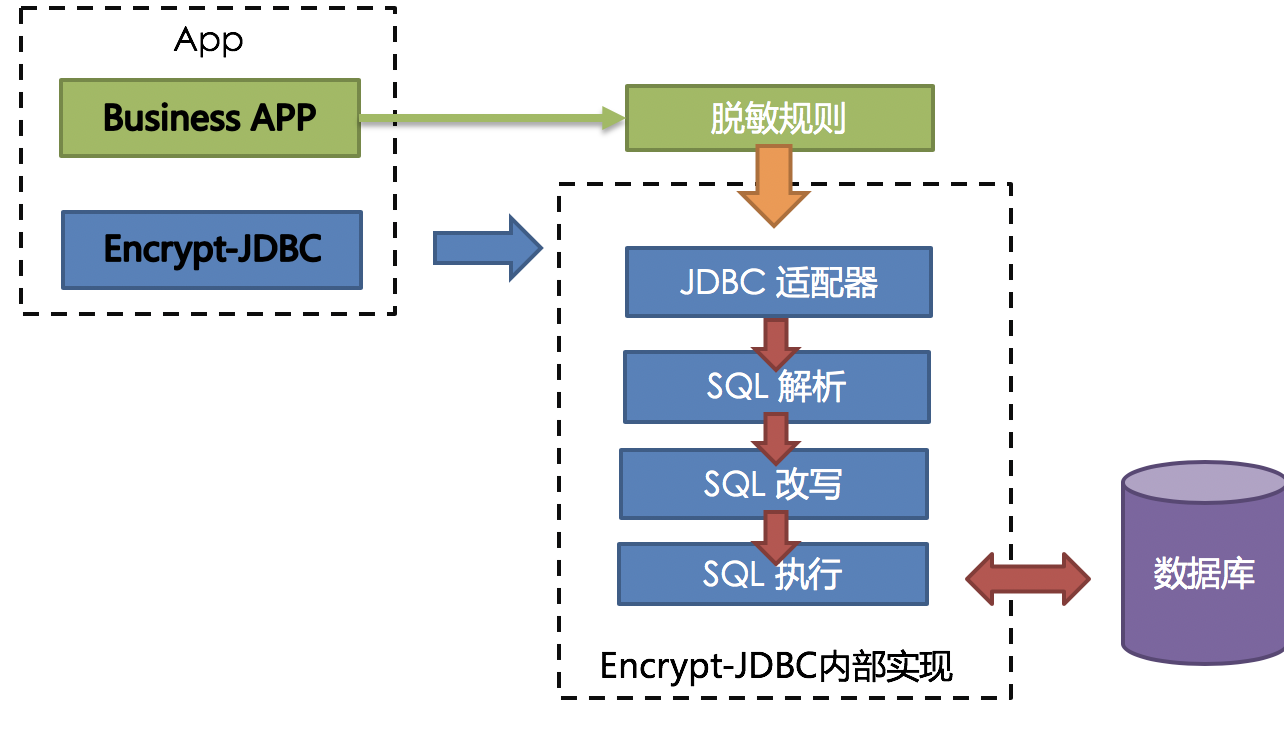
-
-加密模块将用户发起的 SQL 进行拦截,并通过 SQL 语法解析器进行解析、理解 SQL
行为,再依据用户传入的加密规则,找出需要加密的字段和所使用的加解密算法对目标字段进行加解密处理后,再与底层数据库进行交互。
-Apache ShardingSphere 会将用户请求的明文进行加密后存储到底层数据库;并在用户查询时,将密文从数据库中取出进行解密后返回给终端用户。
-通过屏蔽对数据的加密处理,使用户无需感知解析 SQL、数据加密、数据解密的处理过程,就像在使用普通数据一样使用加密数据。
-
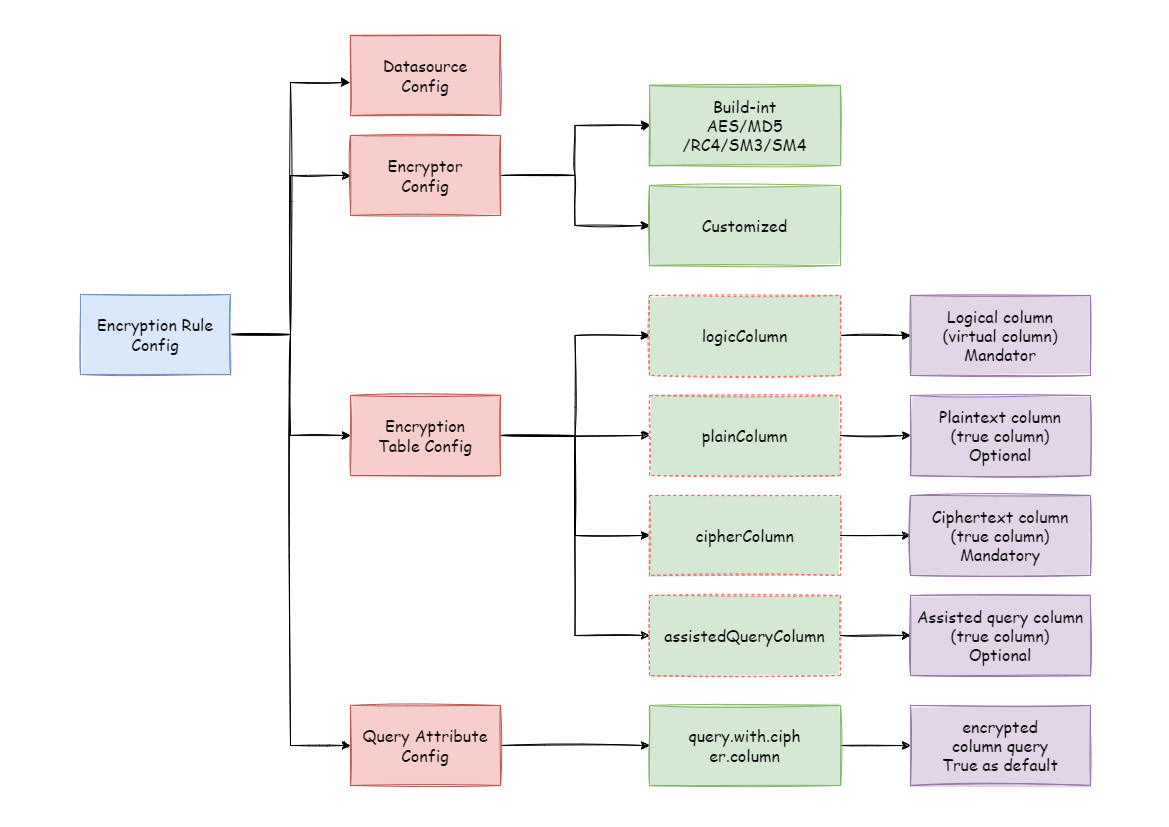
-### 加密规则
-
-在详解整套流程之前,我们需要先了解下加密规则与配置,这是认识整套流程的基础。
-加密配置主要分为四部分:数据源配置,加密算法配置,加密表配置以及查询属性配置,其详情如下图所示:
-
-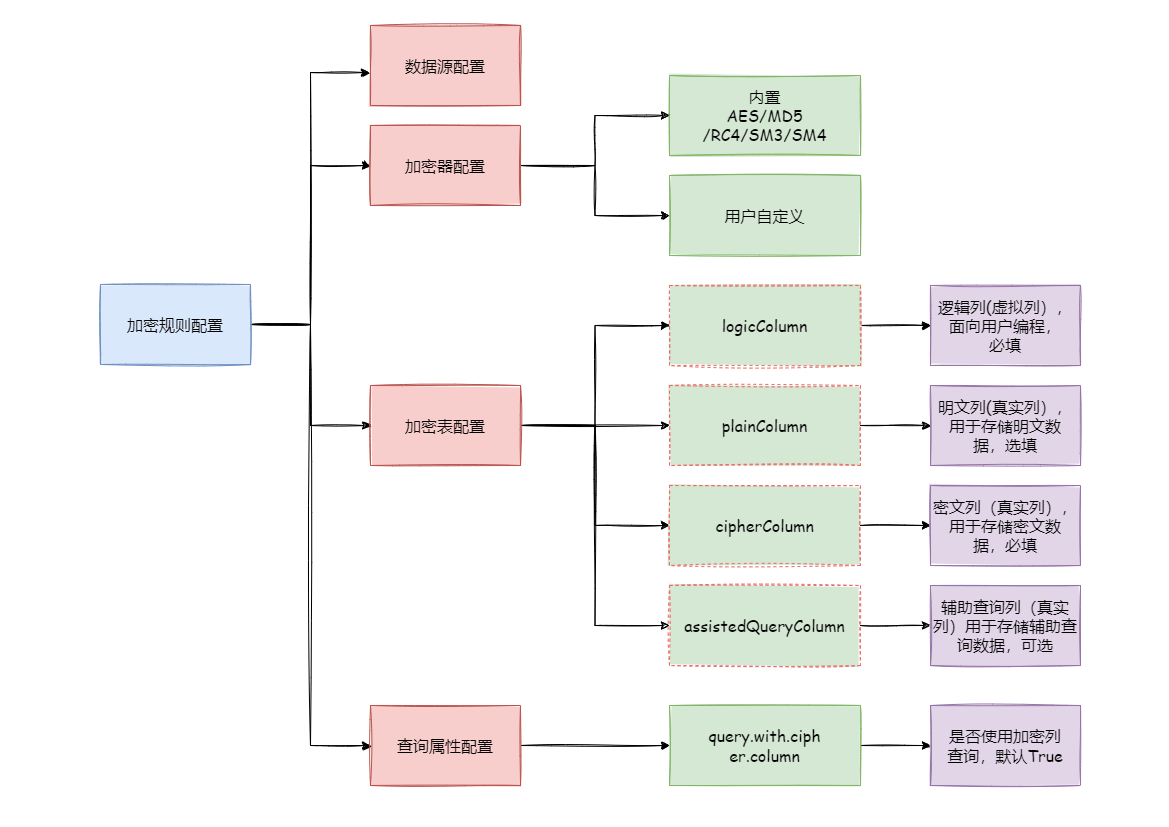
-
-**数据源配置**:指数据源配置。
-
-**加密器配置**:指使用什么加密算法进行加解密。目前 ShardingSphere 内置了三种加解密算法:AES,MD5 和 RC4。用户还可以通过实现
ShardingSphere 提供的接口,自行实现一套加解密算法。
-
-**加密表配置**:用于告诉 ShardingSphere
数据表里哪个列用于存储密文数据(cipherColumn)、哪个列用于存储明文数据(plainColumn)以及用户想使用哪个列进行 SQL
编写(logicColumn)。
-
-> 如何理解 `用户想使用哪个列进行 SQL 编写(logicColumn)`?
->
-> 我们可以从加密模块存在的意义来理解。加密模块最终目的是希望屏蔽底层对数据的加密处理,也就是说我们不希望用户知道数据是如何被加解密的、如何将明文数据存储到
plainColumn,将密文数据存储到 cipherColumn。
-> 换句话说,我们不希望用户知道 plainColumn 和 cipherColumn 的存在和使用。
->
所以,我们需要给用户提供一个概念意义上的列,这个列可以脱离底层数据库的真实列,它可以是数据库表里的一个真实列,也可以不是,从而使得用户可以随意改变底层数据库的
plainColumn 和 cipherColumn 的列名。
-> 或者删除 plainColumn,选择永远不再存储明文,只存储密文。
-> 只要用户的 SQL 面向这个逻辑列进行编写,并在加密规则里给出 logicColumn 和 plainColumn、cipherColumn
之间正确的映射关系即可。
-为什么要这么做呢?答案在文章后面,即为了让已上线的业务能无缝、透明、安全地进行数据加密迁移。
-
-**查询属性的配置**:当底层数据库表里同时存储了明文数据、密文数据后,该属性开关用于决定是直接查询数据库表里的明文数据进行返回,还是查询密文数据通过
Apache ShardingSphere 解密后返回。该属性开关支持表级别和整个规则级别配置,表级别优先级最高。
-
-### 加密处理过程
-
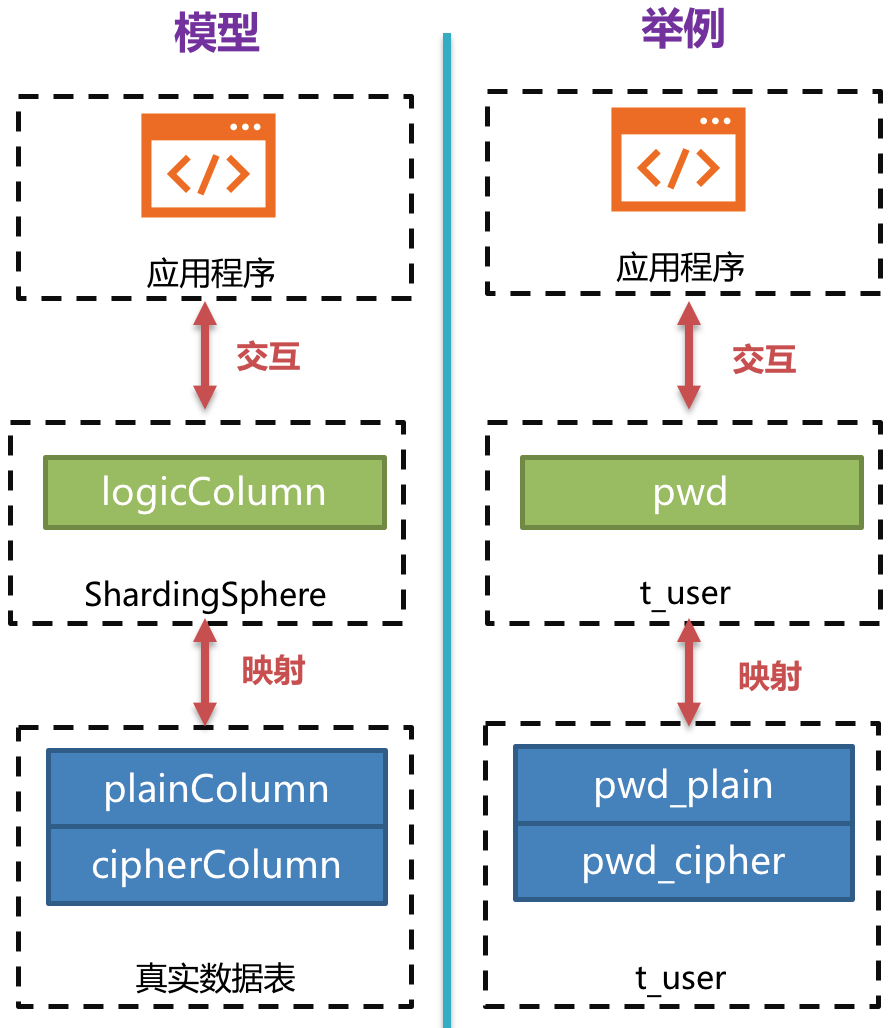
-举例说明,假如数据库里有一张表叫做 `t_user`,这张表里实际有两个字段
`pwd_plain`,用于存放明文数据、`pwd_cipher`,用于存放密文数据,同时定义 logicColumn 为 `pwd`。
-那么,用户在编写 SQL 时应该面向 logicColumn 进行编写,即 `INSERT INTO t_user SET pwd = '123'`。
-Apache ShardingSphere 接收到该 SQL,通过用户提供的加密配置,发现 `pwd` 是
logicColumn,于是便对逻辑列及其对应的明文数据进行加密处理。
-**Apache ShardingSphere 将面向用户的逻辑列与面向底层数据库的明文列和密文列进行了列名以及数据的加密映射转换。**
-如下图所示:
-
-
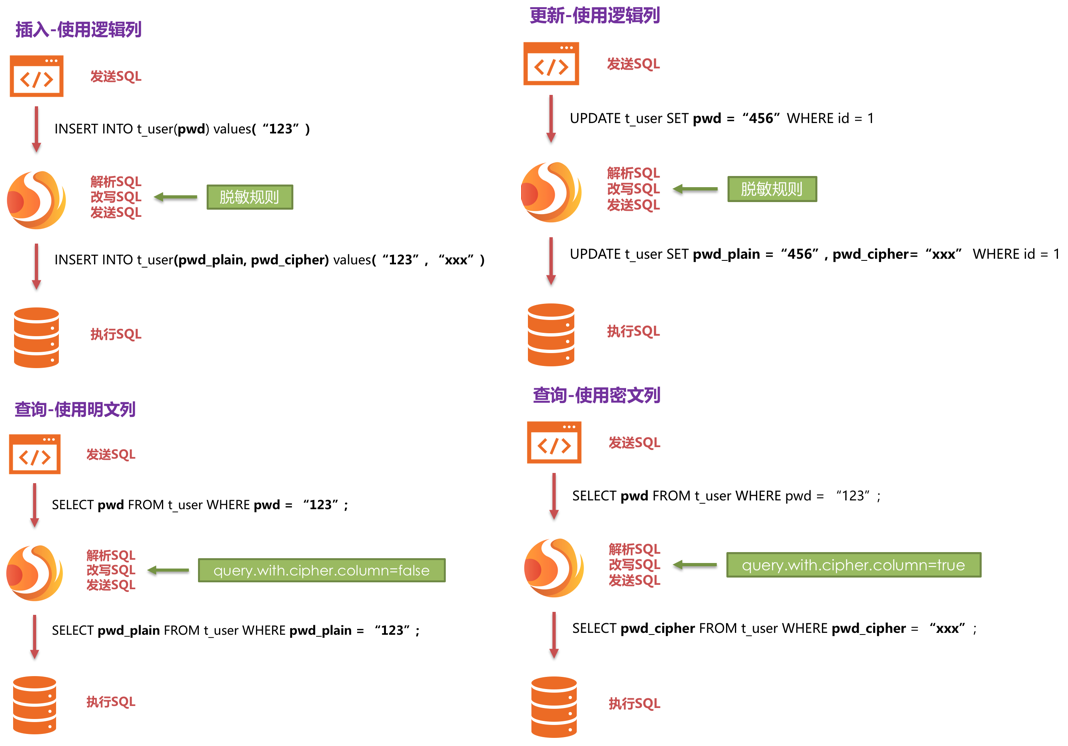
-
-即依据用户提供的加密规则,将用户 SQL 与底层数据表结构割裂开来,使得用户的 SQL 编写不再依赖于真实的数据库表结构。
-而用户与底层数据库之间的衔接、映射、转换交由 Apache ShardingSphere 进行处理。
-下方图片展示了使用加密模块进行增删改查时,其中的处理流程和转换逻辑,如下图所示。
-
-
-
## 相关参考
- [配置:数据加密](/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/encrypt/)
diff --git a/docs/document/content/features/encrypt/_index.en.md
b/docs/document/content/features/encrypt/_index.en.md
index 474aa31989d..f34b4a599f7 100644
--- a/docs/document/content/features/encrypt/_index.en.md
+++ b/docs/document/content/features/encrypt/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.9. </b>"
+pre = "<b>3.8. </b>"
title = "Encryption"
-weight = 9
+weight = 8
chapter = true
+++
@@ -9,78 +9,10 @@ chapter = true
Data encryption refers to the modification of some sensitive information
through encryption rules in order to offer reliable protection to sensitive
private data. Data related to customer security or some sensitive commercial
data, such as ID number, mobile phone number, card number, customer number, and
other personal information, shall be encrypted according to the regulations of
respective regulations.
-## Related Concepts
-
-### Logic column
-
-It is used to calculate the encryption and decryption columns and it is the
logical identifier of the column in SQL. Logical columns contain ciphertext
columns (mandatory), query-helper columns (optional), and plaintext columns
(optional).
-
-### Cipher column
-
-Encrypted data columns.
-
-### Query assistant column
-
-It is a helper column used for queries. For some non-idempotent encryption
algorithms with higher security levels, irreversible idempotent columns are
provided for queries.
-
-### Plain column
-
-The column is used to store plaintext and provide services during the
migration of encrypted data. It can be deleted after the data cleansing is
complete.
-
## Impact on the system
In real business scenarios, service development teams need to implement and
maintain a set of encryption and decryption systems based on the requirements
of the security department. When the encryption scenario changes, the
self-maintained encryption system often faces the risk of reconstruction or
modification. Additionally, for services that have been launched, it is
relatively complicated to achieve seamless encrypted transformation in a
transparent and secure manner without modifying [...]
-## Limitations
-
-- You need to process the original data on stocks in the database by yourself.
-- The case-insensitive queries are not supported for encrypted fields.
-- Comparison operations are not supported for encrypted fields, such as
GREATER THAN, LESS THAN, ORDER BY, BETWEEN, LIKE.
-- Calculation operations are not supported for encrypted fields, such as AVG,
SUM, and computation expressions.
-
-## How it works
-
-Apache ShardingSphere parses the SQL entered by users and rewrites the SQL
according to the encryption rules provided by users, to encrypt the source data
and store the source data (optional) and ciphertext data in the underlying
database.
-When a user queries data, it only retrieves ciphertext data from the database,
decrypts it, and finally returns the decrypted source data to the user. Apache
ShardingSphere achieves a transparent and automatic data encryption process.
Users can use encrypted data as normal data without paying attention to the
implementation details of data encryption.
-
-### Overall architecture
-
-
-
-The encrypted module intercepts the SQL initiated by the user and parses and
understands the SQL behavior through the SQL grammar parser. Then it finds out
the fields to be encrypted and the encryption and decryption algorithm
according to the encryption rules introduced by the user and interacts with the
underlying database.
-Apache ShardingSphere will encrypt the plaintext requested by users and store
it in the underlying database. When the user queries, the ciphertext is
extracted from the database, decrypted, and returned to the terminal user. By
shielding the data encryption process, users do not need to operate the SQL
parsing process, data encryption, and data decryption.
-
-### Encryption rules
-
-Before explaining the whole process, we need to understand the encryption
rules and configuration. Encryption configuration is mainly divided into four
parts: data source configuration, encryptor configuration, encryption table
configuration and query attribute configuration, as shown in the figure below:
-
-
-
-**Data source configuration**: literally the configuration of the data source.
-
-**Encryptor configuration**: refers to the encryption algorithm used for
encryption and decryption. Currently, ShardingSphere has three built-in
encryption and decryption algorithms: AES, MD5 and RC4. Users can also
implement a set of encryption and decryption algorithms by implementing the
interfaces provided by ShardingSphere.
-
-**Encryption table configuration**: it is used to tell ShardingSphere which
column in the data table is used to store ciphertext data (cipherColumn), which
column is used to store plaintext data (plainColumn), and which column the user
would like to use for SQL writing (logicColumn).
-
-> What does it mean by "which column the user would like to use for SQL
writing (logicColumn)"?
->
-> We have to know first why the encrypted module exists. The goal of the
encrypted module is to shield the underlying data encryption process, which
means we don't want users to know how data is encrypted and decrypted, and how
to store plaintext data into plainColumn and ciphertext data into cipherColumn.
In other words, we don't want users to know there is a plainColumn and
cipherColumn or how they are used. Therefore, we need to provide the user with
a conceptual column that can be se [...]
-
-**Query attribute configuration**: if both plaintext and ciphertext data are
stored in the underlying database table, this attribute can be used to
determine whether to query the plaintext data in the database table and return
it directly, or query the ciphertext data and return it after decryption
through Apache ShardingSphere. This attribute can be configured at the table
level and the entire rule level. The table-level has the highest priority.
-
-### Encryption process
-
-For example, if there is a table named `t_user` in the database, and there
actually are two fields in the table: `pwd_plain` for storing plaintext data
and `pwd_cipher` for storing ciphertext data, and logicColumn is defined as
`pwd`, then users should write SQL for logicColumn, that is `INSERT INTO t_user
SET pwd = '123'`. Apache ShardingSphere receives the SQL and finds that the
`pwd` is the logicColumn based on the encryption configuration provided by the
user. Therefore, it encrypts [...]
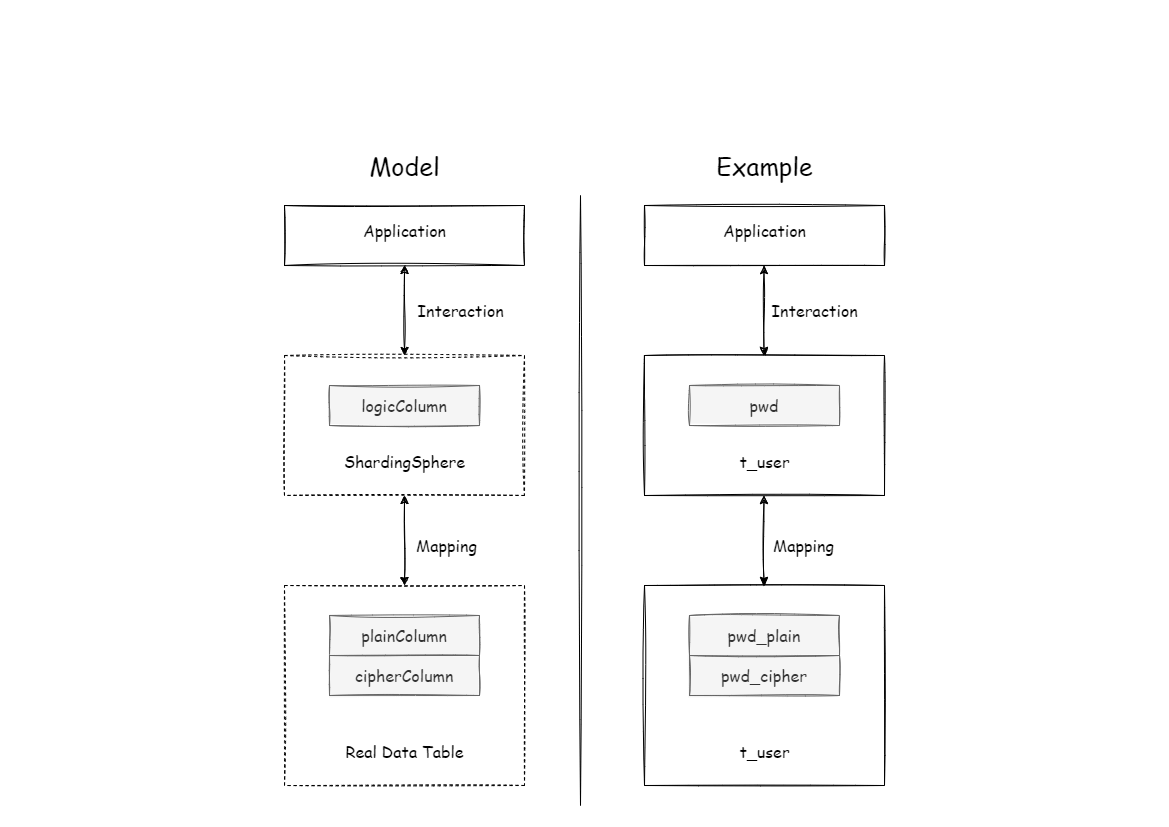
-**Apache ShardingSphere transforms the column names and data encryption
mapping between the logical columns facing users and the plaintext and
ciphertext columns facing the underlying database**. As shown in the figure
below:
-
-
-
-The user's SQL is separated from the underlying data table structure according
to the encryption rules provided by the user so that the user's SQL writing
does not depend on the real database table structure.
-The connection, mapping, and transformation between the user and the
underlying database are handled by Apache ShardingSphere.
-The picture below shows the processing flow and conversion logic when the
encryption module is used to add, delete, change and check, as shown in the
figure below.
-
-
-
## Related References
- [Configuration: Data
Encryption](/en/user-manual/shardingsphere-jdbc/yaml-config/rules/encrypt/)
diff --git a/docs/document/content/features/encrypt/concept.cn.md
b/docs/document/content/features/encrypt/concept.cn.md
new file mode 100644
index 00000000000..a606220d737
--- /dev/null
+++ b/docs/document/content/features/encrypt/concept.cn.md
@@ -0,0 +1,23 @@
++++
+title = "核心概念"
+weight = 1
++++
+
+## 逻辑列
+
+用于计算加解密列的逻辑名称,是 SQL 中列的逻辑标识。
+逻辑列包含密文列(必须)、查询辅助列(可选)和明文列(可选)。
+
+## 密文列
+
+加密后的数据列。
+
+## 查询辅助列
+
+用于查询的辅助列。
+对于一些安全级别更高的非幂等加密算法,提供不可逆的幂等列用于查询。
+
+## 明文列
+
+存储明文的列,用于在加密数据迁移过程中仍旧提供服务。
+在洗数结束后可以删除。
diff --git a/docs/document/content/features/encrypt/concept.en.md
b/docs/document/content/features/encrypt/concept.en.md
new file mode 100644
index 00000000000..fcde624f89d
--- /dev/null
+++ b/docs/document/content/features/encrypt/concept.en.md
@@ -0,0 +1,20 @@
++++
+title = "Core Concept"
+weight = 1
++++
+
+## Logic column
+
+It is used to calculate the encryption and decryption columns and it is the
logical identifier of the column in SQL. Logical columns contain ciphertext
columns (mandatory), query-helper columns (optional), and plaintext columns
(optional).
+
+## Cipher column
+
+Encrypted data columns.
+
+## Query assistant column
+
+It is a helper column used for queries. For some non-idempotent encryption
algorithms with higher security levels, irreversible idempotent columns are
provided for queries.
+
+## Plain column
+
+The column is used to store plaintext and provide services during the
migration of encrypted data. It can be deleted after the data cleansing is
complete.
diff --git a/docs/document/content/features/encrypt/limitations.cn.md
b/docs/document/content/features/encrypt/limitations.cn.md
new file mode 100644
index 00000000000..d257af35fb6
--- /dev/null
+++ b/docs/document/content/features/encrypt/limitations.cn.md
@@ -0,0 +1,9 @@
++++
+title = "使用限制"
+weight = 2
++++
+
+- 需自行处理数据库中原始的存量数据;
+- 加密字段无法支持查询不区分大小写功能;
+- 加密字段无法支持比较操作,如:大于、小于、ORDER BY、BETWEEN、LIKE 等;
+- 加密字段无法支持计算操作,如:AVG、SUM 以及计算表达式。
diff --git a/docs/document/content/features/encrypt/limitations.en.md
b/docs/document/content/features/encrypt/limitations.en.md
new file mode 100644
index 00000000000..23999232f6f
--- /dev/null
+++ b/docs/document/content/features/encrypt/limitations.en.md
@@ -0,0 +1,9 @@
++++
+title = "Limitations"
+weight = 2
++++
+
+- You need to process the original data on stocks in the database by yourself.
+- The case-insensitive queries are not supported for encrypted fields.
+- Comparison operations are not supported for encrypted fields, such as
GREATER THAN, LESS THAN, ORDER BY, BETWEEN, LIKE.
+- Calculation operations are not supported for encrypted fields, such as AVG,
SUM, and computation expressions.
diff --git a/docs/document/content/features/ha/_index.cn.md
b/docs/document/content/features/ha/_index.cn.md
index f4e71c217c6..41bf941598a 100644
--- a/docs/document/content/features/ha/_index.cn.md
+++ b/docs/document/content/features/ha/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.7. </b>"
+pre = "<b>3.4. </b>"
title = "高可用"
-weight = 7
+weight = 4
chapter = true
+++
@@ -15,25 +15,6 @@ chapter = true
尽可能的保证 7X24 小时不间断的数据库服务,是 Apache ShardingSphere 高可用模块的主要设计目标。
-## 核心概念
-
-### 高可用类型
-
-Apache ShardingSphere 不提供数据库高可用的能力,它通过第三方提供的高可用方案感知数据库主从关系的切换。 确切来说,Apache
ShardingSphere 提供数据库发现的能力,自动感知数据库主从关系,并修正计算节点对数据库的连接。
-
-### 动态读写分离
-高可用和读写分离一起使用时,读写分离无需配置具体的主库和从库。 高可用的数据源会动态的修正读写分离的主从关系,并正确地疏导读写流量。
-
-## 使用限制
-
-### 支持项
-* MySQL MGR 单主模式。
-* MySQL 主从复制模式。
-* openGauss 主从复制模式。
-
-### 不支持项
-* MySQL MGR 多主模式。
-
## 原理介绍
Apache ShardingSphere 提供的高可用方案,允许用户进行二次定制开发及实现扩展,主要分为四个步骤 :
前置检查、动态发现主库、动态发现从库、同步配置。
@@ -41,9 +22,8 @@ Apache ShardingSphere 提供的高可用方案,允许用户进行二次定制

## 相关参考
+
[Java API](/cn/user-manual/shardingsphere-jdbc/java-api/rules/ha)\
[YAML 配置](/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/ha)\
[Spring Boot
Starter](/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/ha)\
[Spring 命名空间](/cn/user-manual/shardingsphere-jdbc/spring-namespace/rules/ha)
-
-[源码](https://github.com/apache/shardingsphere/tree/master/shardingsphere-features/shardingsphere-db-discovery)
diff --git a/docs/document/content/features/ha/_index.en.md
b/docs/document/content/features/ha/_index.en.md
index 1b6c637241b..8c601a32115 100644
--- a/docs/document/content/features/ha/_index.en.md
+++ b/docs/document/content/features/ha/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.7. </b>"
+pre = "<b>3.4. </b>"
title = "HA"
-weight = 7
+weight = 4
chapter = true
+++
@@ -13,28 +13,6 @@ Stateful storage nodes are required to have capabilities
such as data consistenc
Stateless compute nodes need to sense storage nodes' changes, setup load
balancers independently, and enable service discovery and request distribution.
Apache ShardingSphere' high availability module (HA) is mainly designed to
ensure a 24/7 database service as much as possible.
-## Related Concepts
-
-### High Availability Type
-
-Apache ShardingSphere does not provide database high availability capability.
It senses the change of databases' primary-secondary relationship through a
third-party provided high availability solution.
-Specifically, ShardingSphere is capable of finding databases, automatically
sensing the primary/secondary database relationship, and correcting compute
nodes' connections to databases.
-
-### Dynamic Read/Write Splitting
-
-When high availability and read/write splitting are adopted together, it is
not necessary to configure specific primary and secondary databases for
read/write splitting.
-Highly available data sources dynamically correct the primary/secondary
relationship of read/write splitting and properly channel read/write traffic.
-
-## Limitations
-
-### Supported
-* MySQL MGR single-primary mode
-* MySQL Primary/secondary replication mode
-* openGauss Primary/secondary replication mode
-
-### Not supported
-* MySQL MGR Multi-primary mode
-
## How it works
The high availability solution provided by Apache ShardingSphere allows you to
carry out secondary custom development and achieve expansion,
@@ -43,12 +21,8 @@ which is mainly divided into four steps: pre-check, primary
database dynamic dis

## Related References
+
[Java API](/en/user-manual/shardingsphere-jdbc/java-api/rules/ha)\
[YAML Configuration](/en/user-manual/shardingsphere-jdbc/yaml-config/rules/ha)\
[Spring Boot
Starter](/en/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/ha)\
[Spring
Namespace](/en/user-manual/shardingsphere-jdbc/spring-namespace/rules/ha)
-
-[Source
Code](https://github.com/apache/shardingsphere/tree/master/shardingsphere-features/shardingsphere-db-discovery)
-
-
-
diff --git a/docs/document/content/features/ha/concept.cn.md
b/docs/document/content/features/ha/concept.cn.md
new file mode 100644
index 00000000000..697731d1e5d
--- /dev/null
+++ b/docs/document/content/features/ha/concept.cn.md
@@ -0,0 +1,12 @@
++++
+title = "核心概念"
+weight = 1
++++
+
+## 高可用类型
+
+Apache ShardingSphere 不提供数据库高可用的能力,它通过第三方提供的高可用方案感知数据库主从关系的切换。 确切来说,Apache
ShardingSphere 提供数据库发现的能力,自动感知数据库主从关系,并修正计算节点对数据库的连接。
+
+## 动态读写分离
+
+高可用和读写分离一起使用时,读写分离无需配置具体的主库和从库。 高可用的数据源会动态的修正读写分离的主从关系,并正确地疏导读写流量。
diff --git a/docs/document/content/features/ha/concept.en.md
b/docs/document/content/features/ha/concept.en.md
new file mode 100644
index 00000000000..e8c22772b31
--- /dev/null
+++ b/docs/document/content/features/ha/concept.en.md
@@ -0,0 +1,14 @@
++++
+title = "Core Concept"
+weight = 1
++++
+
+## High Availability Type
+
+Apache ShardingSphere does not provide database high availability capability.
It senses the change of databases' primary-secondary relationship through a
third-party provided high availability solution.
+Specifically, ShardingSphere is capable of finding databases, automatically
sensing the primary/secondary database relationship, and correcting compute
nodes' connections to databases.
+
+## Dynamic Read/Write Splitting
+
+When high availability and read/write splitting are adopted together, it is
not necessary to configure specific primary and secondary databases for
read/write splitting.
+Highly available data sources dynamically correct the primary/secondary
relationship of read/write splitting and properly channel read/write traffic.
diff --git a/docs/document/content/features/ha/limitations.cn.md
b/docs/document/content/features/ha/limitations.cn.md
new file mode 100644
index 00000000000..4c68a2665c2
--- /dev/null
+++ b/docs/document/content/features/ha/limitations.cn.md
@@ -0,0 +1,15 @@
++++
+title = "使用限制"
+weight = 2
++++
+
+## 支持项
+
+* MySQL MGR 单主模式。
+* MySQL 主从复制模式。
+* openGauss 主从复制模式。
+
+## 不支持项
+
+* MySQL MGR 多主模式。
+
diff --git a/docs/document/content/features/ha/limitations.en.md
b/docs/document/content/features/ha/limitations.en.md
new file mode 100644
index 00000000000..67cc745231d
--- /dev/null
+++ b/docs/document/content/features/ha/limitations.en.md
@@ -0,0 +1,14 @@
++++
+title = "Limitations"
+weight = 2
++++
+
+## Supported
+
+* MySQL MGR single-primary mode
+* MySQL Primary/secondary replication mode
+* openGauss Primary/secondary replication mode
+
+## Not supported
+
+* MySQL MGR Multi-primary mode
diff --git a/docs/document/content/features/management/_index.cn.md
b/docs/document/content/features/management/_index.cn.md
index 159016cb380..154da7630cc 100644
--- a/docs/document/content/features/management/_index.cn.md
+++ b/docs/document/content/features/management/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.3. </b>"
+pre = "<b>3.6. </b>"
title = "集群管控"
-weight = 3
+weight = 6
chapter = true
+++
diff --git a/docs/document/content/features/management/_index.en.md
b/docs/document/content/features/management/_index.en.md
index 73e8e0f2b8a..3cabbe28fcf 100644
--- a/docs/document/content/features/management/_index.en.md
+++ b/docs/document/content/features/management/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.3. </b>"
+pre = "<b>3.6. </b>"
title = "Cluster Management"
-weight = 3
+weight = 6
chapter = true
+++
diff --git a/docs/document/content/features/observability/_index.cn.md
b/docs/document/content/features/observability/_index.cn.md
index 810f1d5cdb6..db25625234d 100644
--- a/docs/document/content/features/observability/_index.cn.md
+++ b/docs/document/content/features/observability/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.12. </b>"
+pre = "<b>3.10. </b>"
title = "可观察性"
-weight = 12
+weight = 10
+++
## 定义
@@ -10,30 +10,8 @@ weight = 12
登录到具体服务器的点对点运维方式,无法适用于面向大量分布式服务器的场景。
通过对可系统观察性数据的遥测是分布式系统推荐的运维方式。
-## 相关概念
-
-### Agent
-
-基于字节码增强和插件化设计,以提供 Tracing 和 Metrics 埋点,以及日志输出功能。
-需要开启 Agent 的插件功能后,才能将监控指标数据输出至第三方 APM 中展示。
-
-### APM
-
-APM 是应用性能监控的缩写。
-着眼于分布式系统的性能诊断,其主要功能包括调用链展示,应用拓扑分析等。
-
-### Tracing
-
-链路跟踪,通过探针收集调用链数据,并发送到第三方 APM 系统。
-
-### Metrics
-
-系统统计指标,通过探针收集,并且写入到时序数据库,供第三方应用展示。
-
-### Logging
-
-日志,通过 Agent 能够方便的扩展日志内容,为分析系统运行状态提供更多信息。
-
## 相关参考
-[特殊 API:可观察性](/cn/user-manual/shardingsphere-jdbc/special-api/observability/)
+- [可观察性的使用](/cn/user-manual/shardingsphere-proxy/observability/)
+- [开发者指南:可观察性](/cn/dev-manual/agent/)
+- [实现原理](/cn/reference/observability/)
diff --git a/docs/document/content/features/observability/_index.en.md
b/docs/document/content/features/observability/_index.en.md
index 1c28d802bf4..7e087e96a1f 100644
--- a/docs/document/content/features/observability/_index.en.md
+++ b/docs/document/content/features/observability/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.12. </b>"
+pre = "<b>3.10. </b>"
title = "Observability"
-weight = 12
+weight = 10
+++
## Definition
@@ -12,32 +12,8 @@ The point-to-point operation and maintenance method of
logging into a specific s
Telemetry of system-observable data is the recommended way of operating and
maintaining distributed systems.
-## Related Concepts
-
-### Agent
-
-Based on bytecode enhancement and plugin design to provide tracing, metrics
and logging features.
-
-Only after the plugin of the Agent is enabled, the monitoring indicator data
can be output to the third-party APM for display.
-
-### APM
-
-APM is an acronym for Application Performance Monitoring.
-
-Focusing on the performance diagnosis of distributed systems, its main
functions include call chain display, application topology analysis, etc.
-
-### Tracing
-
-Tracing data between distributed services or internal processes will be
collected by agent. It will then be sent to third-party APM systems.
-
-### Metrics
-
-System statistical indicators are collected through probes and written to the
time series database for display by third-party applications.
-
-### Logging
-
-The log can be easily expanded through the agent to provide more information
for analyzing the system running status.
-
## Related References
-[Special API:
Observability](/en/user-manual/shardingsphere-jdbc/special-api/observability/)
+- [Usage of observability](/en/user-manual/shardingsphere-proxy/observability/)
+- [Dev guide: observability](/en/dev-manual/agent/)
+- [Implementation](/en/reference/observability/)
diff --git a/docs/document/content/features/observability/_index.cn.md
b/docs/document/content/features/observability/concept.cn.md
similarity index 52%
copy from docs/document/content/features/observability/_index.cn.md
copy to docs/document/content/features/observability/concept.cn.md
index 810f1d5cdb6..01c56518e20 100644
--- a/docs/document/content/features/observability/_index.cn.md
+++ b/docs/document/content/features/observability/concept.cn.md
@@ -1,39 +1,26 @@
+++
-pre = "<b>3.12. </b>"
-title = "可观察性"
-weight = 12
+title = "核心概念"
+weight = 1
+++
-## 定义
-
-如何观测集群的运行状态,使运维人员可以快速掌握当前系统现状,并进行进一步的维护工作,是分布式系统的全新挑战。
-登录到具体服务器的点对点运维方式,无法适用于面向大量分布式服务器的场景。
-通过对可系统观察性数据的遥测是分布式系统推荐的运维方式。
-
-## 相关概念
-
-### Agent
+## Agent
基于字节码增强和插件化设计,以提供 Tracing 和 Metrics 埋点,以及日志输出功能。
需要开启 Agent 的插件功能后,才能将监控指标数据输出至第三方 APM 中展示。
-### APM
+## APM
APM 是应用性能监控的缩写。
着眼于分布式系统的性能诊断,其主要功能包括调用链展示,应用拓扑分析等。
-### Tracing
+## Tracing
链路跟踪,通过探针收集调用链数据,并发送到第三方 APM 系统。
-### Metrics
+## Metrics
系统统计指标,通过探针收集,并且写入到时序数据库,供第三方应用展示。
-### Logging
+## Logging
日志,通过 Agent 能够方便的扩展日志内容,为分析系统运行状态提供更多信息。
-
-## 相关参考
-
-[特殊 API:可观察性](/cn/user-manual/shardingsphere-jdbc/special-api/observability/)
diff --git a/docs/document/content/features/observability/_index.en.md
b/docs/document/content/features/observability/concept.en.md
similarity index 53%
copy from docs/document/content/features/observability/_index.en.md
copy to docs/document/content/features/observability/concept.en.md
index 1c28d802bf4..98e6b3d6aab 100644
--- a/docs/document/content/features/observability/_index.en.md
+++ b/docs/document/content/features/observability/concept.en.md
@@ -1,43 +1,28 @@
+++
-pre = "<b>3.12. </b>"
-title = "Observability"
-weight = 12
+title = "Core Concept"
+weight = 1
+++
-## Definition
-
-Observing a cluster's operation status in order to quickly grasp the system's
current status and efficiently be able to carry out maintenance work,
represents a new challenge for distributed systems.
-
-The point-to-point operation and maintenance method of logging into a specific
server cannot be applied to scenarios facing a large number of distributed
servers.
-
-Telemetry of system-observable data is the recommended way of operating and
maintaining distributed systems.
-
-## Related Concepts
-
-### Agent
+## Agent
Based on bytecode enhancement and plugin design to provide tracing, metrics
and logging features.
Only after the plugin of the Agent is enabled, the monitoring indicator data
can be output to the third-party APM for display.
-### APM
+## APM
APM is an acronym for Application Performance Monitoring.
Focusing on the performance diagnosis of distributed systems, its main
functions include call chain display, application topology analysis, etc.
-### Tracing
+## Tracing
Tracing data between distributed services or internal processes will be
collected by agent. It will then be sent to third-party APM systems.
-### Metrics
+## Metrics
System statistical indicators are collected through probes and written to the
time series database for display by third-party applications.
-### Logging
+## Logging
The log can be easily expanded through the agent to provide more information
for analyzing the system running status.
-
-## Related References
-
-[Special API:
Observability](/en/user-manual/shardingsphere-jdbc/special-api/observability/)
diff --git a/docs/document/content/features/readwrite-splitting/_index.cn.md
b/docs/document/content/features/readwrite-splitting/_index.cn.md
index 468072105c1..3a4f4235460 100644
--- a/docs/document/content/features/readwrite-splitting/_index.cn.md
+++ b/docs/document/content/features/readwrite-splitting/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.6. </b>"
+pre = "<b>3.3. </b>"
title = "读写分离"
-weight = 6
+weight = 3
chapter = true
+++
@@ -9,36 +9,19 @@ chapter = true
读写分离也就是将数据库拆分为主库和从库,即主库负责处理事务性的增删改操作,从库负责处理查询操作的数据库架构。
-## 相关概念
-
-### 主库
-添加、更新以及删除数据操作所使用的数据库,目前仅支持单主库。
-
-### 从库
-查询数据操作所使用的数据库,可支持多从库。
-
-### 主从同步
-将主库的数据异步的同步到从库的操作。 由于主从同步的异步性,从库与主库的数据会短时间内不一致。
-
-### 负载均衡策略
-通过负载均衡策略将查询请求疏导至不同从库。
-
## 对系统的影响
-用户的系统中可能存在着复杂的主从关系数据库集群,因此应用程序需要接入多个数据源,这种方式就增加了系统维护的成本和业务开发的难度。ShardingSphere
通过读写分离功能,可以让用户像使用一个数据库一样去使用数据库集群,透明化读写分离带来的影响。
-## 使用限制
-* 不处理主库和从库的数据同步
-* 不处理主库和从库的数据同步延迟导致的数据不一致
-* 不支持主库多写
-* 不处理主从库间的事务一致性。主从模型中,事务中的数据读写均用主库。
+用户的系统中可能存在着复杂的主从关系数据库集群,因此应用程序需要接入多个数据源,这种方式就增加了系统维护的成本和业务开发的难度。ShardingSphere
通过读写分离功能,可以让用户像使用一个数据库一样去使用数据库集群,透明化读写分离带来的影响。
## 原理介绍
+
ShardingSphere 的读写分离主要依赖内核的相关功能。包括解析引擎和路由引擎。解析引擎将用户的 SQL 转化为 ShardingSphere
可以识别的 Statement 信息,路由引擎根据 SQL 的读写类型以及事务的状态来做 SQL 的路由。
在从库的路由中支持多种负载均衡算法,包括轮询算法、随机访问算法、权重访问算法等,用户也可以依据 SPI
机制自行扩展所需算法。如下图所示,ShardingSphere 识别到读操作和写操作,分别会路由至不同的数据库实例。
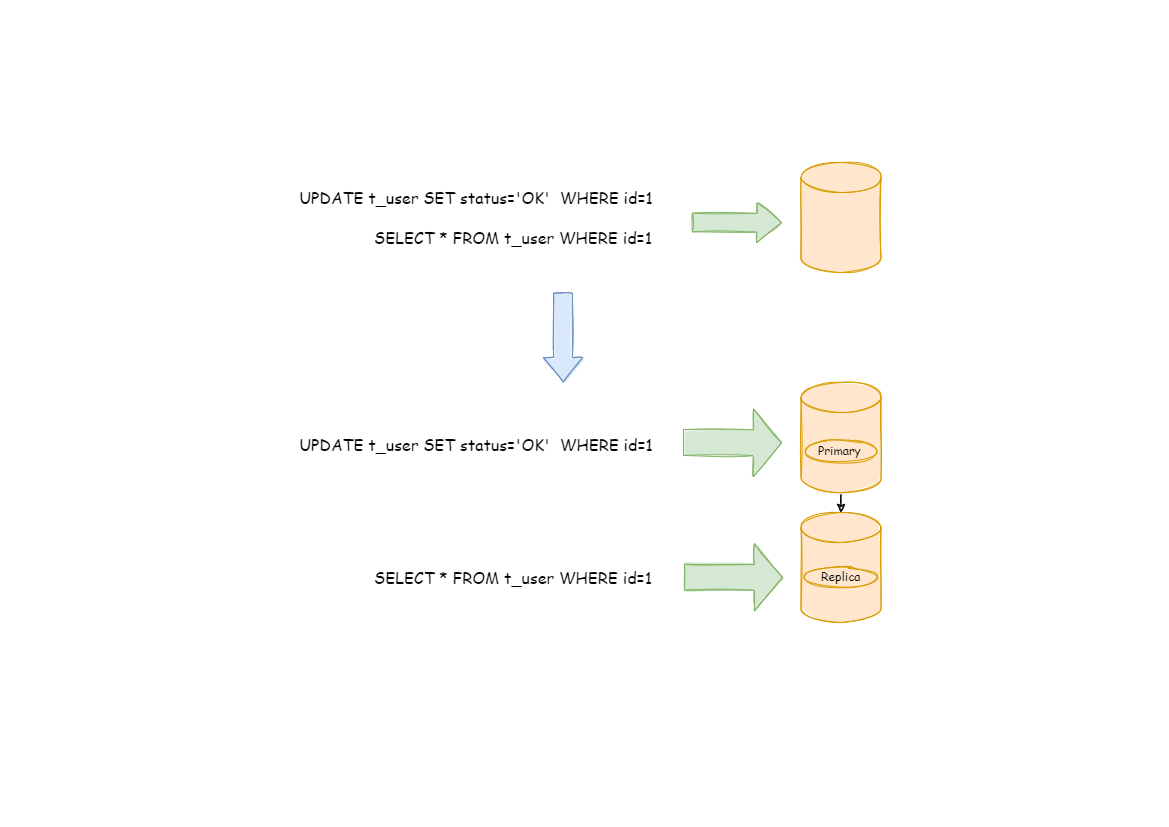
## 相关参考
+
[Java
API](/cn/user-manual/shardingsphere-jdbc/java-api/rules/readwrite-splitting)\
[YAML
配置](/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/readwrite-splitting)\
[Spring Boot
Starter](/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/readwrite-splitting)\
diff --git a/docs/document/content/features/readwrite-splitting/_index.en.md
b/docs/document/content/features/readwrite-splitting/_index.en.md
index 518764fd1fd..67822acca77 100644
--- a/docs/document/content/features/readwrite-splitting/_index.en.md
+++ b/docs/document/content/features/readwrite-splitting/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.6. </b>"
+pre = "<b>3.3. </b>"
title = "Readwrite-splitting"
-weight = 6
+weight = 3
chapter = true
+++
@@ -10,40 +10,22 @@ chapter = true
Read/write splitting is to split the database into primary and secondary
databases. The primary database is responsible for handling transactional
operations including additions, deletions and changes.
And the secondary database is responsible for the query operation of database
architecture.
-## Related Concepts
-
-### Primary database
-The primary database is used to add, update, and delete data operations.
Currently, only single primary database is supported.
-
-### Secondary database
-The secondary database is used to query data operations and multi-secondary
databases are supported.
-
-### Primary-Secondary synchronization
-It refers to the operation of asynchronously synchronizing data from a primary
database to a secondary database. Due to the asynchronism of primary-secondary
synchronization,
-data from the primary and secondary databases may be inconsistent for a short
time.
-
-### Load balancer policy
-Channel query requests to different secondary databases through load balancer
policy.
-
## Impact on the System
+
There may be complex primary-secondary relational database clusters in users'
systems, so applications need to access multiple data sources, which increases
the cost of system maintenance and the
difficulty of business development. ShardingSphere enables users to use
database clusters like a database through read/write splitting function, and
the impact of read/write splitting will be transparent to users.
-## Limitations
-* Data synchronization of primary and secondary databases is not supported.
-* Data inconsistency resulting from data synchronization delays between
primary and secondary databases is not supported.
-* Multi-write of primary database is not supported.
-* Transactional consistency between primary and secondary databases is not
supported. In the primary-secondary model, both data reads and writes in
transactions use the primary database.
-
## How it works
+
ShardingSphere's read/write splitting mainly relies on the related functions
of its kernel, including a parsing engine and a routing engine.
The parsing engine converts the user's SQL into Statement information that can
be identified by ShardingSphere, and the routing engine performs SQL routing
according to the read/write type of SQL and transactional status.
The routing from the secondary database supports a variety of load balancing
algorithms, including polling algorithm, random access algorithm, weight access
algorithm, etc.
Users can also expand the required algorithm according to the SPI mechanism.
As shown in the figure below, ShardingSphere identifies read and write
operations and routes them to different database instances respectively.
-
+
+
+## Related References
-## 相关参考
[Java
API](/en/user-manual/shardingsphere-jdbc/java-api/rules/readwrite-splitting)\
[YAML
Configuration](/en/user-manual/shardingsphere-jdbc/yaml-config/rules/readwrite-splitting)\
[Spring Boot
Starter](/en/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/readwrite-splitting)\
diff --git a/docs/document/content/features/readwrite-splitting/concept.cn.md
b/docs/document/content/features/readwrite-splitting/concept.cn.md
new file mode 100644
index 00000000000..730ac7c911b
--- /dev/null
+++ b/docs/document/content/features/readwrite-splitting/concept.cn.md
@@ -0,0 +1,16 @@
++++
+title = "核心概念"
+weight = 1
++++
+
+## 主库
+添加、更新以及删除数据操作所使用的数据库,目前仅支持单主库。
+
+## 从库
+查询数据操作所使用的数据库,可支持多从库。
+
+## 主从同步
+将主库的数据异步的同步到从库的操作。 由于主从同步的异步性,从库与主库的数据会短时间内不一致。
+
+## 负载均衡策略
+通过负载均衡策略将查询请求疏导至不同从库。
diff --git a/docs/document/content/features/readwrite-splitting/concept.en.md
b/docs/document/content/features/readwrite-splitting/concept.en.md
new file mode 100644
index 00000000000..941b6f4bf76
--- /dev/null
+++ b/docs/document/content/features/readwrite-splitting/concept.en.md
@@ -0,0 +1,17 @@
++++
+title = "Core Concept"
+weight = 1
++++
+
+## Primary database
+The primary database is used to add, update, and delete data operations.
Currently, only single primary database is supported.
+
+## Secondary database
+The secondary database is used to query data operations and multi-secondary
databases are supported.
+
+## Primary-Secondary synchronization
+It refers to the operation of asynchronously synchronizing data from a primary
database to a secondary database. Due to the asynchronism of primary-secondary
synchronization,
+data from the primary and secondary databases may be inconsistent for a short
time.
+
+## Load balancer policy
+Channel query requests to different secondary databases through load balancer
policy.
diff --git
a/docs/document/content/features/readwrite-splitting/limitations.cn.md
b/docs/document/content/features/readwrite-splitting/limitations.cn.md
new file mode 100644
index 00000000000..6adcc529a17
--- /dev/null
+++ b/docs/document/content/features/readwrite-splitting/limitations.cn.md
@@ -0,0 +1,9 @@
++++
+title = "使用限制"
+weight = 2
++++
+
+* 不处理主库和从库的数据同步
+* 不处理主库和从库的数据同步延迟导致的数据不一致
+* 不支持主库多写
+* 不处理主从库间的事务一致性。主从模型中,事务中的数据读写均用主库。
diff --git
a/docs/document/content/features/readwrite-splitting/limitations.en.md
b/docs/document/content/features/readwrite-splitting/limitations.en.md
new file mode 100644
index 00000000000..e123bbedcc0
--- /dev/null
+++ b/docs/document/content/features/readwrite-splitting/limitations.en.md
@@ -0,0 +1,9 @@
++++
+title = "Limitations"
+weight = 2
++++
+
+* Data synchronization of primary and secondary databases is not supported.
+* Data inconsistency resulting from data synchronization delays between
primary and secondary databases is not supported.
+* Multi-write of primary database is not supported.
+* Transactional consistency between primary and secondary databases is not
supported. In the primary-secondary model, both data reads and writes in
transactions use the primary database.
diff --git a/docs/document/content/features/scaling/_index.cn.md
b/docs/document/content/features/scaling/_index.cn.md
index 7a78807d21d..58988fc7fc6 100644
--- a/docs/document/content/features/scaling/_index.cn.md
+++ b/docs/document/content/features/scaling/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.8. </b>"
+pre = "<b>3.7. </b>"
title = "数据迁移"
-weight = 8
+weight = 7
chapter = true
+++
@@ -9,45 +9,7 @@ chapter = true
数据迁移是指准备从一个存储集群提取数据,然后将数据写入到新的存储集群,并校验数据一致性。
-## 相关概念
-
-### 节点
-运行计算层或存储层组件进程的实例,可以是物理机、虚拟机、容器等。
-
-### 集群
-为了提供特定服务而集合在一起的多个节点。
-
-### 源端
-原始数据所在的存储集群。
-
-### 目标端
-原始数据将要迁移的目标存储集群。
-
-### 数据迁移作业
-
-把数据从某一个存储集群复制到另一个存储集群的完整流程。
-
-### 存量数据
-
-在数据迁移作业开始前,数据节点中已有的数据。
-
-### 增量数据
-
-在数据迁移作业执行过程中,业务系统所产生的新数据。
-
-## 使用限制
-
-### 支持项
-
-* 将外围数据迁移至 Apache ShardingSphere 所管理的数据库;
-* 整型或字符串主键表迁移。
-
-### 不支持项
-
-* 无主键表迁移;
-* 复合主键表迁移;
-* 不支持在当前存储节点之上做迁移,需要准备一个全新的数据库集群作为迁移目标库。
-
## 相关参考
-[数据迁移的配置](/cn/user-manual/shardingsphere-proxy/scaling/)
+- [数据迁移的配置](/cn/user-manual/shardingsphere-proxy/scaling/)
+- [数据迁移的实现原理](/cn/reference/scaling/)
diff --git a/docs/document/content/features/scaling/_index.en.md
b/docs/document/content/features/scaling/_index.en.md
index a790f834a76..6e3d231df2e 100644
--- a/docs/document/content/features/scaling/_index.en.md
+++ b/docs/document/content/features/scaling/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.8. </b>"
+pre = "<b>3.7. </b>"
title = "Data Migration"
-weight = 8
+weight = 7
chapter = true
+++
@@ -9,47 +9,7 @@ chapter = true
Data migration refers to the preparation of data extraction from one storage
cluster, the writing of that data to a new storage cluster and the verification
of data consistency.
-## Related Concepts
-
-### Nodes
-
-Instances for running compute or storage tier component processes. These can
either be physical machines, virtual machines, or containers, etc.
-
-### Cluster
-Multiple nodes that are assembled together to provide a specified service.
-
-### Source
-
-The storage cluster where the original data resides.
-
-### Target
-
-The target storage cluster to which the original data is to be migrated.
-
-### Data Migration Process
-
-The entire process of replicating data from one storage cluster to another.
-
-### Stock Data
-
-The data that was already in the data node before the data migration operation
started.
-
-### Incremental Data
-
-New data generated by operational systems during the execution of data
migration operations.
-
-## Limitations
-### Procedures Supported
-
-* Migration of peripheral data to databases managed by Apache ShardingSphere.
-* Migration of integer or string primary key tables.
-
-### Procedures not supported
-
-* Migration without primary key tables.
-* Migration of composite primary key tables.
-* Migration on top of the current storage node is not supported, so a brand
new database cluster needs to be prepared as the migration target cluster.
-
-## References
+## Related References
[Configurations of data migration
](/en/user-manual/shardingsphere-proxy/scaling/)
+[Reference of data migration](/en/reference/scaling/)
\ No newline at end of file
diff --git a/docs/document/content/features/scaling/concept.cn.md
b/docs/document/content/features/scaling/concept.cn.md
new file mode 100644
index 00000000000..6b8962b750c
--- /dev/null
+++ b/docs/document/content/features/scaling/concept.cn.md
@@ -0,0 +1,28 @@
++++
+title = "核心概念"
+weight = 1
++++
+
+## 节点
+运行计算层或存储层组件进程的实例,可以是物理机、虚拟机、容器等。
+
+## 集群
+为了提供特定服务而集合在一起的多个节点。
+
+## 源端
+原始数据所在的存储集群。
+
+## 目标端
+原始数据将要迁移的目标存储集群。
+
+## 数据迁移作业
+
+把数据从某一个存储集群复制到另一个存储集群的完整流程。
+
+## 存量数据
+
+在数据迁移作业开始前,数据节点中已有的数据。
+
+## 增量数据
+
+在数据迁移作业执行过程中,业务系统所产生的新数据。
diff --git a/docs/document/content/features/scaling/concept.en.md
b/docs/document/content/features/scaling/concept.en.md
new file mode 100644
index 00000000000..5b57676c966
--- /dev/null
+++ b/docs/document/content/features/scaling/concept.en.md
@@ -0,0 +1,32 @@
++++
+title = "Core Concept"
+weight = 1
++++
+
+## Nodes
+
+Instances for running compute or storage tier component processes. These can
either be physical machines, virtual machines, or containers, etc.
+
+## Cluster
+
+Multiple nodes that are assembled together to provide a specified service.
+
+## Source
+
+The storage cluster where the original data resides.
+
+## Target
+
+The target storage cluster to which the original data is to be migrated.
+
+## Data Migration Process
+
+The entire process of replicating data from one storage cluster to another.
+
+## Stock Data
+
+The data that was already in the data node before the data migration operation
started.
+
+## Incremental Data
+
+New data generated by operational systems during the execution of data
migration operations.
diff --git a/docs/document/content/features/scaling/limitations.cn.md
b/docs/document/content/features/scaling/limitations.cn.md
new file mode 100644
index 00000000000..5670369fc8d
--- /dev/null
+++ b/docs/document/content/features/scaling/limitations.cn.md
@@ -0,0 +1,15 @@
++++
+title = "使用限制"
+weight = 2
++++
+
+## 支持项
+
+* 将外围数据迁移至 Apache ShardingSphere 所管理的数据库;
+* 整型或字符串主键表迁移。
+
+## 不支持项
+
+* 无主键表迁移;
+* 复合主键表迁移;
+* 不支持在当前存储节点之上做迁移,需要准备一个全新的数据库集群作为迁移目标库。
diff --git a/docs/document/content/features/scaling/limitations.en.md
b/docs/document/content/features/scaling/limitations.en.md
new file mode 100644
index 00000000000..962d34a6d54
--- /dev/null
+++ b/docs/document/content/features/scaling/limitations.en.md
@@ -0,0 +1,15 @@
++++
+title = "Limitations"
+weight = 2
++++
+
+## Procedures Supported
+
+* Migration of peripheral data to databases managed by Apache ShardingSphere.
+* Migration of integer or string primary key tables.
+
+## Procedures not supported
+
+* Migration without primary key tables.
+* Migration of composite primary key tables.
+* Migration on top of the current storage node is not supported, so a brand
new database cluster needs to be prepared as the migration target cluster.
diff --git a/docs/document/content/features/shadow/_index.cn.md
b/docs/document/content/features/shadow/_index.cn.md
index 0a953a6cc33..8f42cad3779 100644
--- a/docs/document/content/features/shadow/_index.cn.md
+++ b/docs/document/content/features/shadow/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.10. </b>"
+pre = "<b>3.9. </b>"
title = "影子库"
-weight = 10
+weight = 9
+++
## 定义
@@ -53,3 +53,10 @@ Apache ShardingSphere 全链路在线压测场景下,在数据库层面对于
| BETWEEN | SELECT/UPDATE/DELETE ... WHERE column BETWEEN value1 AND value2
| 不支持 |
| GROUP BY ... HAVING... | SELECT/UPDATE/DELETE ... WHERE ... GROUP BY
column HAVING column > value | 不支持 |
| 子查询 | SELECT/UPDATE/DELETE ... WHERE column = (SELECT column FROM table
WHERE column = value) | 不支持 |
+
+## 相关参考
+
+- [Java API:影子库](/cn/user-manual/shardingsphere-jdbc/java-api/rules/shadow/)
+- [YAML 配置:影子库](/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/shadow/)
+- [Spring Boot
Starter:影子库](/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/shadow/)
+- [Spring
命名空间:影子库](/cn/user-manual/shardingsphere-jdbc/spring-namespace/rules/shadow/)
diff --git a/docs/document/content/features/shadow/_index.en.md
b/docs/document/content/features/shadow/_index.en.md
index da7990a838e..ed7123813e9 100644
--- a/docs/document/content/features/shadow/_index.en.md
+++ b/docs/document/content/features/shadow/_index.en.md
@@ -1,52 +1,16 @@
+++
-pre = "<b>3.10. </b>"
+pre = "<b>3.9. </b>"
title = "Shadow"
-weight = 10
+weight = 9
+++
## Definition
-Solution for stress testing data governance at the database level, under the
online full link stress testing scenario of Apache ShardingSphere.
-
-## Related Concepts
-
-### Production Database
-Database for production data
-
-### Shadow Database
-The Database for stress test data isolation. Configurations should be the same
as the Production Database.
-### Shadow Algorithm
-Shadow Algorithm, which is closely related to business operations, currently
has 2 types.
-
-- Column based shadow algorithm
-Routing to shadow database by recognizing data from SQL. Suitable for stress
test scenario that has an emphasis on data list.
-- Hint based shadow algorithm
-Routing to shadow database by recognizing comments from SQL. Suitable for
stress test driven by the identification of upstream system passage.
-
-## Limitations
-
-### Hint based shadow algorithm
-No
+Solution for stress testing data governance at the database level, under the
online full link stress testing scenario of Apache ShardingSphere.
-### Column based shadow algorithm
-Does not support DDL.
-Does not support scope, group, subqueries such as BETWEEN, GROUP BY ...
HAVING, etc.
-SQL support list
+## Related References
- - INSERT
-
- | *SQL* | *support or not* |
- | ------- | ------------ |
- | INSERT INTO table (column,...) VALUES (value,...) | support |
- | INSERT INTO table (column,...) VALUES (value,...),(value,...),... |
support |
- | INSERT INTO table (column,...) SELECT column1 from table1 where column1 =
value1 | do not support |
- - SELECT/UPDATE/DELETE
-
- | *condition categories* | *SQL* | *support or not* |
- | ------------ | -------- | ----------- |
- | = | SELECT/UPDATE/DELETE ... WHERE column = value | support |
- | LIKE/NOT LIKE | SELECT/UPDATE/DELETE ... WHERE column LIKE/NOT LIKE value
| support |
- | IN/NOT IN | SELECT/UPDATE/DELETE ... WHERE column IN/NOT IN
(value1,value2,...) | support |
- | BETWEEN | SELECT/UPDATE/DELETE ... WHERE column BETWEEN value1 AND value2
| do not support |
- | GROUP BY ... HAVING... | SELECT/UPDATE/DELETE ... WHERE ... GROUP BY
column HAVING column > value | do not support |
- | Sub Query | SELECT/UPDATE/DELETE ... WHERE column = (SELECT column FROM
table WHERE column = value) | do not support |
+- [Java API: shadow DB
](/en/user-manual/shardingsphere-jdbc/java-api/rules/shadow/)
+- [YAML configuration: shadow DB
](/en/user-manual/shardingsphere-jdbc/yaml-config/rules/shadow/)
+- [Spring Boot Starter: shadow DB
](/en/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/shadow/)
+- [Spring Namespace: shadow DB
](/en/user-manual/shardingsphere-jdbc/spring-namespace/rules/shadow/)
diff --git a/docs/document/content/features/shadow/concept.cn.md
b/docs/document/content/features/shadow/concept.cn.md
new file mode 100644
index 00000000000..04c8cee2b15
--- /dev/null
+++ b/docs/document/content/features/shadow/concept.cn.md
@@ -0,0 +1,24 @@
++++
+title = "核心概念"
+weight = 1
++++
+
+## 生产库
+
+生产环境使用的数据库。
+
+## 影子库
+
+压测数据隔离的影子数据库,与生产数据库应当使用相同的配置。
+
+## 影子算法
+
+影子算法和业务实现紧密相关,目前提供 2 种类型影子算法。
+
+- 基于列的影子算法
+ 通过识别 SQL 中的数据,匹配路由至影子库的场景。
+ 适用于由压测数据名单驱动的压测场景。
+
+- 基于 Hint 的影子算法
+ 通过识别 SQL 中的注释,匹配路由至影子库的场景。
+ 适用于由上游系统透传标识驱动的压测场景。
diff --git a/docs/document/content/features/shadow/concept.en.md
b/docs/document/content/features/shadow/concept.en.md
new file mode 100644
index 00000000000..9b1cff0d31e
--- /dev/null
+++ b/docs/document/content/features/shadow/concept.en.md
@@ -0,0 +1,21 @@
++++
+title = "Core Concept"
+weight = 1
++++
+
+## Production Database
+
+Database for production data
+
+## Shadow Database
+
+The Database for stress test data isolation. Configurations should be the same
as the Production Database.
+
+## Shadow Algorithm
+
+Shadow Algorithm, which is closely related to business operations, currently
has 2 types.
+
+- Column based shadow algorithm
+Routing to shadow database by recognizing data from SQL. Suitable for stress
test scenario that has an emphasis on data list.
+- Hint based shadow algorithm
+Routing to shadow database by recognizing comments from SQL. Suitable for
stress test driven by the identification of upstream system passage.
diff --git a/docs/document/content/features/shadow/limitations.cn.md
b/docs/document/content/features/shadow/limitations.cn.md
new file mode 100644
index 00000000000..02570dca21f
--- /dev/null
+++ b/docs/document/content/features/shadow/limitations.cn.md
@@ -0,0 +1,32 @@
++++
+title = "使用限制"
+weight = 2
++++
+
+## 基于 Hint 的影子算法
+
+* 无。
+
+## 基于列的影子算法
+
+* 不支持 DDL;
+* 不支持范围、分组和子查询,如:BETWEEN、GROUP BY ... HAVING 等。
+ SQL 支持列表:
+ - INSERT
+
+ | *SQL*
| *是否支持* |
+ |
--------------------------------------------------------------------------------
| ----------- |
+ | INSERT INTO table (column,...) VALUES (value,...)
| 支持 |
+ | INSERT INTO table (column,...) VALUES (value,...),(value,...),...
| 支持 |
+ | INSERT INTO table (column,...) SELECT column1 from table1 where column1 =
value1 | 不支持 |
+
+ - SELECT/UPDATE/DELETE
+
+ | *条件类型* | *SQL*
| *是否支持* |
+ | ---------------------- |
----------------------------------------------------------------------------------------
| ----------- |
+ | = | SELECT/UPDATE/DELETE ... WHERE column = value
| 支持 |
+ | LIKE/NOT LIKE | SELECT/UPDATE/DELETE ... WHERE column LIKE/NOT
LIKE value | 支持 |
+ | IN/NOT IN | SELECT/UPDATE/DELETE ... WHERE column IN/NOT IN
(value1,value2,...) | 支持 |
+ | BETWEEN | SELECT/UPDATE/DELETE ... WHERE column BETWEEN
value1 AND value2 | 不支持 |
+ | GROUP BY ... HAVING... | SELECT/UPDATE/DELETE ... WHERE ... GROUP BY
column HAVING column > value | 不支持 |
+ | 子查询 | SELECT/UPDATE/DELETE ... WHERE column = (SELECT
column FROM table WHERE column = value) | 不支持 |
diff --git a/docs/document/content/features/shadow/limitations.en.md
b/docs/document/content/features/shadow/limitations.en.md
new file mode 100644
index 00000000000..663d5a42175
--- /dev/null
+++ b/docs/document/content/features/shadow/limitations.en.md
@@ -0,0 +1,35 @@
++++
+title = "Limitations"
+weight = 2
++++
+
+## Hint based shadow algorithm
+
+No
+
+## Column based shadow algorithm
+
+Does not support DDL.
+
+Does not support scope, group, subqueries such as BETWEEN, GROUP BY ...
HAVING, etc.
+
+SQL support list
+
+ - INSERT
+
+ | *SQL*
| *support or not* |
+ |
--------------------------------------------------------------------------------
| ------------------ |
+ | INSERT INTO table (column,...) VALUES (value,...)
| support |
+ | INSERT INTO table (column,...) VALUES (value,...),(value,...),...
| support |
+ | INSERT INTO table (column,...) SELECT column1 from table1 where column1 =
value1 | do not support |
+
+ - SELECT/UPDATE/DELETE
+
+ | *condition categories*| *SQL*
| *support or not* |
+ | ---------------------- |
---------------------------------------------------------------------------------------
| ------------------ |
+ | = | SELECT/UPDATE/DELETE ... WHERE column = value
| support |
+ | LIKE/NOT LIKE | SELECT/UPDATE/DELETE ... WHERE column LIKE/NOT
LIKE value | support |
+ | IN/NOT IN | SELECT/UPDATE/DELETE ... WHERE column IN/NOT IN
(value1,value2,...) | support |
+ | BETWEEN | SELECT/UPDATE/DELETE ... WHERE column BETWEEN
value1 AND value2 | do not support |
+ | GROUP BY ... HAVING... | SELECT/UPDATE/DELETE ... WHERE ... GROUP BY
column HAVING column > value | do not support |
+ | Sub Query | SELECT/UPDATE/DELETE ... WHERE column = (SELECT
column FROM table WHERE column = value) | do not support |
diff --git a/docs/document/content/features/sharding/_index.cn.md
b/docs/document/content/features/sharding/_index.cn.md
index 01949c2b5e1..0b88a2289e2 100644
--- a/docs/document/content/features/sharding/_index.cn.md
+++ b/docs/document/content/features/sharding/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.4. </b>"
+pre = "<b>3.1. </b>"
title = "数据分片"
-weight = 4
+weight = 1
chapter = true
+++
@@ -32,170 +32,6 @@ chapter = true
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
-## 相关概念
-
-### 表
-
-表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
-
-#### 逻辑表
-
-相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 `t_order_0` 到
`t_order_9`,他们的逻辑表名为 `t_order`。
-
-#### 真实表
-
-在水平拆分的数据库中真实存在的物理表。 即上个示例中的 `t_order_0` 到 `t_order_9`。
-
-#### 绑定表
-
-指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
例如:`t_order` 表和 `t_order_item` 表,均按照 `order_id` 分片,并且使用 `order_id`
进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
-
-```sql
-SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE
o.order_id in (10, 11);
-```
-
-在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4
条,它们呈现为笛卡尔积:
-
-```sql
-SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-```
-
-在配置绑定表关系,并且使用 `order_id` 进行关联后,路由的 SQL 应该为 2 条:
-
-```sql
-SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-```
-
-其中 `t_order` 表由于指定了分片条件,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么
`t_order_item` 表的分片计算将会使用 `t_order` 的条件。
-
-#### 广播表
-
-指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
-
-#### 单表
-
-指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
-
-### 数据节点
-
-数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0。
-逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
-
-#### 均匀分布
-
-指数据表在每个数据源内呈现均匀分布的态势, 例如:
-
-```Nginx
-db0
- ├── t_order0
- └── t_order1
-db1
- ├── t_order0
- └── t_order1
-```
-
-数据节点的配置如下:
-
-```CSS
-db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
-```
-
-#### 自定义分布
-
-指数据表呈现有特定规则的分布, 例如:
-
-```Nginx
-db0
- ├── t_order0
- └── t_order1
-db1
- ├── t_order2
- ├── t_order3
- └── t_order4
-```
-
-数据节点的配置如下:
-
-```CSS
-db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
-```
-
-### 分片
-
-#### 分片键
-
-用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。
除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
-
-#### 分片算法
-
-用于将数据分片的算法,支持 `=`、`>=`、`<=`、`>`、`<`、`BETWEEN` 和 `IN` 进行分片。 分片算法可由开发者自行实现,也可使用
Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
-
-#### 自动化分片算法
-
-分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
-
-#### 自定义分片算法
-
-提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
-
-- 标准分片算法
-
-用于处理使用单一键作为分片键的 `=`、`IN`、`BETWEEN AND`、`>`、`<`、`>=`、`<=` 进行分片的场景。
-
-- 复合分片算法
-
-用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
-
-- Hint 分片算法
-
-用于处理使用 `Hint` 行分片的场景。
-
-#### 分片策略
-
-包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
-
-#### 强制分片路由
-
-对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。 例:按照员工登录主键分库,而数据库中并无此字段。 SQL
Hint 支持通过 Java API 和 SQL 注释两种方式使用。 详情请参见强制分片路由。
-
-### 行表达式
-
-行表达式是为了解决配置的简化与一体化这两个主要问题。在繁琐的数据分片规则配置中,随着数据节点的增多,大量的重复配置使得配置本身不易被维护。
通过行表达式可以有效地简化数据节点配置工作量。
-
-对于常见的分片算法,使用 Java 代码实现并不有助于配置的统一管理。 通过行表达式书写分片算法,可以有效地将规则配置一同存放,更加易于浏览与存储。
-
-行表达式的使用非常直观,只需要在配置中使用 `${ expression }` 或 `$->{ expression }` 标识行表达式即可。
目前支持数据节点和分片算法这两个部分的配置。 行表达式的内容使用的是 Groovy 的语法,Groovy 能够支持的所有操作,行表达式均能够支持。 例如:
-
-`${begin..end}` 表示范围区间
-`${[unit1, unit2, unit_x]}` 表示枚举值
-
-行表达式中如果出现连续多个 `${ expression }` 或 `$->{ expression }`
表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
-
-例如,以下行表达式:
-
-```Groovy
-${['online', 'offline']}_table${1..3}
-```
-
-最终会解析为:
-```PlainText
-online_table1, online_table2, online_table3, offline_table1, offline_table2,
offline_table3
-```
-
-### 分布式主键
-
-传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。
虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
-
-目前有许多第三方解决方案可以完美解决这个问题,如 UUID
等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere
不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
-
## 对系统的影响
虽然数据分片解决了性能、可用性以及单点备份恢复等问题,但分布式的架构在获得了收益的同时,也引入了新的问题。
@@ -206,164 +42,7 @@ online_table1, online_table2, online_table3,
offline_table1, offline_table2, off
跨库事务也是分布式的数据库集群要面对的棘手事情。
合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。
在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA
的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
-## 使用限制
-
-兼容全部常用的路由至单数据节点的 SQL; 路由至多数据节点的 SQL 由于场景复杂,分为稳定支持、实验性支持和不支持这三种情况。
-
-### 稳定支持
-
-全面支持 DML、DDL、DCL、TCL 和常用 DAL。 支持分页、去重、排序、分组、聚合、表关联等复杂查询。 支持 PostgreSQL 和
openGauss 数据库 SCHEMA DDL 和 DML 语句。
-
-#### 常规查询
-
-- SELECT 主语句
-
-```sql
-SELECT select_expr [, select_expr ...] FROM table_reference [, table_reference
...]
-[WHERE predicates]
-[GROUP BY {col_name | position} [ASC | DESC], ...]
-[ORDER BY {col_name | position} [ASC | DESC], ...]
-[LIMIT {[offset,] row_count | row_count OFFSET offset}]
-```
-
-- select_expr
-
-```sql
-* |
-[DISTINCT] COLUMN_NAME [AS] [alias] |
-(MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] |
-COUNT(* | COLUMN_NAME | alias) [AS] [alias]
-```
-
-- table_reference
-
-```sql
-tbl_name [AS] alias] [index_hint_list]
-| table_reference ([INNER] | {LEFT|RIGHT} [OUTER]) JOIN table_factor [JOIN ON
conditional_expr | USING (column_list)]
-```
-
-#### 子查询
-
-子查询和外层查询同时指定分片键,且分片键的值保持一致时,由内核提供稳定支持。
-
-例如:
-
-```sql
-SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
1;
-```
-
-用于[分页](https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/pagination)的子查询,由内核提供稳定支持。
-
-例如:
-
-```sql
-SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT * FROM t_order) row_
WHERE rownum <= ?) WHERE rownum > ?;
-```
-
-#### 分页查询
-
-完全支持 MySQL、PostgreSQL、openGauss,Oracle 和 SQLServer 由于分页查询较为复杂,仅部分支持。
-
-Oracle 和 SQLServer 的分页都需要通过子查询来处理,ShardingSphere 支持分页相关的子查询。
-
-- Oracle
-
-支持使用 rownum 进行分页:
-
-```sql
-SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT o.order_id as
order_id FROM t_order o JOIN t_order_item i ON o.order_id = i.order_id) row_
WHERE rownum <= ?) WHERE rownum > ?
-```
-
-- SQLServer
-
-支持使用 TOP + ROW_NUMBER() OVER 配合进行分页:
-
-```sql
-SELECT * FROM (SELECT TOP (?) ROW_NUMBER() OVER (ORDER BY o.order_id DESC) AS
rownum, * FROM t_order o) AS temp WHERE temp.rownum > ? ORDER BY temp.order_id
-```
-支持 SQLServer 2012 之后的 OFFSET FETCH 的分页方式:
-
-```sql
-SELECT * FROM t_order o ORDER BY id OFFSET ? ROW FETCH NEXT ? ROWS ONLY
-```
-
-- MySQL, PostgreSQL 和 openGauss
-
-MySQL、PostgreSQL 和 openGauss 都支持 LIMIT 分页,无需子查询:
-
-```sql
-SELECT * FROM t_order o ORDER BY id LIMIT ? OFFSET ?
-```
-
-#### 运算表达式中包含分片键
-
-当分片键处于运算表达式中时,无法通过 SQL `字面` 提取用于分片的值,将导致全路由。
-例如,假设 `create_time` 为分片键:
-
-```sql
-SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
-```
-
-### 实验性支持
-
-实验性支持特指使用 Federation 执行引擎提供支持。 该引擎处于快速开发中,用户虽基本可用,但仍需大量优化,是实验性产品。
-
-#### 子查询
-
-子查询和外层查询未同时指定分片键,或分片键的值不一致时,由 Federation 执行引擎提供支持。
-
-例如:
-
-```sql
-SELECT * FROM (SELECT * FROM t_order) o;
-
-SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1;
-
-SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o;
-
-SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
2;
-```
-
-#### 跨库关联查询
-
-当关联查询中的多个表分布在不同的数据库实例上时,由 Federation 执行引擎提供支持。 假设 `t_order` 和 `t_order_item`
是多数据节点的分片表,并且未配置绑定表规则,`t_user` 和 `t_user_role` 是分布在不同的数据库实例上的单表,那么 Federation
执行引擎能够支持如下常用的关联查询:
-
-```sql
-SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id
WHERE o.order_id = 1;
-
-SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE
o.user_id = 1;
-
-SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE
o.user_id = 1;
-
-SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE
i.user_id = 1;
-
-SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id
WHERE i.user_id = 1;
-
-SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE
u.user_id = 1;
-```
-
-### 不支持
-
-#### CASE WHEN
-以下 CASE WHEN 语句不支持:
-
-- CASE WHEN 中包含子查询
-- CASE WHEN 中使用逻辑表名(请使用表别名)
-
-#### 分页查询
-
-Oracle 和 SQLServer 由于分页查询较为复杂,目前有部分分页查询不支持,具体如下:
-
-- Oracle
-
-目前不支持 rownum + BETWEEN 的分页方式。
-
-- SQLServer
-
-目前不支持使用 WITH xxx AS (SELECT …) 的方式进行分页。由于 Hibernate 自动生成的 SQLServer 分页语句使用了
WITH 语句,因此目前并不支持基于 Hibernate 的 SQLServer 分页。 目前也不支持使用两个 TOP + 子查询的方式实现分页。
-
## 相关参考
- [数据分片的配置](/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding/)
- [数据分片的开发者指南](/cn/dev-manual/sharding/)
--
源码:https://github.com/apache/shardingsphere/tree/master/shardingsphere-features/shardingsphere-sharding
diff --git a/docs/document/content/features/sharding/_index.en.md
b/docs/document/content/features/sharding/_index.en.md
index 3dd0ec77797..b74ea2c5d1d 100644
--- a/docs/document/content/features/sharding/_index.en.md
+++ b/docs/document/content/features/sharding/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.4. </b>"
+pre = "<b>3.1. </b>"
title = "Sharding"
-weight = 4
+weight = 1
chapter = true
+++
@@ -31,172 +31,6 @@ Horizontal sharding is also called transverse sharding.
Compared with the catego
Theoretically, horizontal sharding has overcome the limitation of data
processing volume in single machine and can be extended relatively freely, so
it can be taken as a standard solution to database sharding and table sharding.
-## Related Concepts
-
-### Table
-
-Tables are a key concept for transparent data sharding. Apache ShardingSphere
adapts to the data sharding requirements under different scenarios by providing
diverse table types.
-
-#### Logic Table
-
-The logical name of the horizontally sharded database (table) of the same
structure is the logical identifier of the table in SQL. Example: Order data is
split into 10 tables according to the primary key endings, are `t_order_0` to
`t_order_9`, and their logical table names are `t_order`.
-
-#### Actual Table
-
-Physical tables that exist in the horizontally sharded databases. Those are,
`t_order_0` to `t_order_9` in the previous example.
-
-
-#### Binding Table
-
-Refers to a set of sharded tables with consistent sharding rules. When using
binding tables for multi-table associated query, a sharding key must be used
for the association, otherwise, Cartesian product association or cross-library
association will occur, affecting query efficiency.
-
-For example, if the `t_order` table and `t_order_item` table are both sharded
according to `order_id` and are correlated using `order_id`, the two tables are
binding tables. The multi-table associated queries between binding tables will
not have a Cartesian product association, so the associated queries will be
much more effective. Here is an example,
-
-If SQL is:
-
-```sql
-SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE
o.order_id in (10, 11);
-```
-
-In the case where no binding table relationships are being set, assume that
the sharding key `order_id` routes the value 10 to slice 0 and the value 11 to
slice 1, then the routed SQL should be 4 items, which are presented as a
Cartesian product:
-
-```sql
-SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-```
-
-After the relationships between binding tables are configured and associated
with order_id, the routed SQL should then be 2 items:
-
-```sql
-SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-
-SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
-```
-
-The t_order table will be used by ShardingSphere as the master table for the
entire binding table since it specifies the sharding condition. All routing
calculations will use only the policy of the primary table, then the sharding
calculations for the `t_order_item` table will use the `t_order` condition.
-
-#### Broadcast data frame
-
-Refers to tables that exist in all sharded data sources. The table structure
and its data are identical in each database. Suitable for scenarios where the
data volume is small and queries are required to be associated with tables of
massive data, e.g., dictionary tables.
-
-#### Single Table
-
-Refers to the only table that exists in all sharded data sources. Suitable for
tables with a small amount of data and do not need to be sharded.
-
-### Data Nodes
-
-The smallest unit of the data shard, consists of the data source name and the
real table. Example: `ds_0.t_order_0`.
-
-The mapping relationship between the logical table and the real table can be
classified into two forms: uniform distribution and custom distribution.
-
-#### Uniform Distribution
-
-refers to situations where the data table exhibits a uniform distribution
within each data source. For example:
-
-```Nginx
-db0
- ├── t_order0
- └── t_order1
-db1
- ├── t_order0
- └── t_order1
-```
-
-The configuration of data nodes:
-
-```CSS
-db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
-```
-
-#### Customized Distribution
-
-Data table exhibiting a patterned distribution. For example:
-
-```Nginx
-db0
- ├── t_order0
- └── t_order1
-db1
- ├── t_order2
- ├── t_order3
- └── t_order4
-```
-
-configuration of data nodes:
-
-```CSS
-db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
-```
-
-### Sharding
-
-#### Sharding key
-
-A database field is used to split a database (table) horizontally. Example: If
the order primary key in the order table is sharded by modulo, the order
primary key is a sharded field. If there is no sharded field in SQL, full
routing will be executed, of which performance is poor. In addition to the
support for single-sharding fields, Apache ShardingSphere also supports
sharding based on multiple fields.
-
-#### Sharding Algorithm
-
-Algorithm for sharding data, supporting `=`, `>=`, `<=`, `>`, `<`, `BETWEEN`
and `IN`. The sharding algorithm can be implemented by the developers
themselves or can use the Apache ShardingSphere built-in sharding algorithm,
syntax sugar, which is very flexible.
-
-#### Automatic Sharding Algorithm
-
-Sharding algorithm—syntactic sugar is for conveniently hosting all data nodes
without users having to concern themselves with the physical distribution of
actual tables. Includes implementations of common sharding algorithms such as
modulo, hash, range, and time.
-
-#### Customized Sharding Algorithm
-
-Provides a portal for application developers to implement their sharding
algorithms that are closely related to their business operations, while
allowing users to manage the physical distribution of actual tables themselves.
Customized sharding algorithms are further divided into:
-- Standard Sharding Algorithm
-Used to deal with scenarios where sharding is performed using a single key as
the sharding key `=`, `IN`, `BETWEEN AND`, `>`, `<`, `>=`, `<=`.
-- Composite Sharding Algorithm
-Used to cope with scenarios where multiple keys are used as sharding keys. The
logic containing multiple sharding keys is very complicated and requires the
application developers to handle it on their own.
-- Hint Sharding Algorithm
-For scenarios involving Hint sharding.
-
-#### Sharding Strategy
-
-Consisting of a sharding key and sharding algorithm, which is abstracted
independently due to the independence of the sharding algorithm. What is viable
for sharding operations is the sharding key + sharding algorithm, known as
sharding strategy.
-
-#### Mandatory Sharding routing
-
-For the scenario where the sharded field is not determined by SQL but by other
external conditions, you can use SQL Hint to inject the shard value. Example:
Conduct database sharding by employee login primary key, but there is no such
field in the database. SQL Hint can be used both via Java API and SQL
annotation. See Mandatory Sharding Routing for details.
-
-#### Row Value Expressions
-
-Row expressions are designed to address the two main issues of configuration
simplification and integration. In the cumbersome configuration rules of data
sharding, the large number of repetitive configurations makes the configuration
itself difficult to maintain as the number of data nodes increases. The data
node configuration workload can be effectively simplified by row expressions.
-
-For the common sharding algorithm, using Java code implementation does not
help to manage the configuration uniformly. But by writing the sharding
algorithm through line expressions, the rule configuration can be effectively
stored together, which is easier to browse and store.
-
-Row expressions are very intuitive, just use `${ expression }` or `$->{
expression }` in the configuration to identify the row expressions. Data nodes
and sharding algorithms are currently supported. The content of row expressions
uses Groovy syntax, and all operations supported by Groovy are supported by row
expressions. For example:
-
-`${begin..end}` denotes the range interval
-
-`${[unit1, unit2, unit_x]}` denotes the enumeration value
-
-If there are multiple `${ expression }` or `$->{ expression }` expressions in
a row expression, the final result of the whole expression will be a Cartesian
combination based on the result of each sub-expression.
-
-e.g. The following row expression:
-
-```Groovy
-${['online', 'offline']}_table${1..3}
-```
-
-Finally, it can be parsed as this:
-
-```PlainText
-online_table1, online_table2, online_table3, offline_table1, offline_table2,
offline_table3
-```
-
-#### Distributed Primary Key
-
-In traditional database software development, automatic primary key generation
is a basic requirement. Various databases provide support for this requirement,
such as self-incrementing keys of MySQL, self-incrementing sequences of Oracle,
etc. After data sharding, it is very tricky to generate global unique primary
keys for different data nodes. Self-incrementing keys between different actual
tables within the same logical table generate repetitive primary keys because
they are not mutua [...]
-
-Many third-party solutions can perfectly solve this problem, such as UUID,
which relies on specific algorithms to self-generate non-repeating keys, or by
introducing primary key generation services. To facilitate users and meet their
demands for different scenarios, Apache ShardingSphere not only provides
built-in distributed primary key generators, such as UUID and SNOWFLAKE but
also abstracts the interface of distributed primary key generators to enable
users to implement their own cus [...]
-
## Impact on the system
Although data sharding solves problems regarding performance, availability,
and backup recovery of single points, the distributed architecture has
introduced new problems while gaining benefits.
@@ -207,156 +41,7 @@ Another challenge is that SQL that works correctly in one
single-node database d
Cross-library transactions are also tricky for a distributed database cluster.
Reasonable use of table splitting can minimize the use of local transactions
while reducing the amount of data in a single table, and appropriate use of
different tables in the same database can effectively avoid the trouble caused
by distributed transactions. In scenarios where cross-library transactions
cannot be avoided, some businesses might still be in the need to maintain
transaction consistency. The XA- [...]
-## Limitations
-
-Compatible with all commonly used SQL that routes to single data nodes; SQL
routing to multiple data nodes is divided, because of complexity issues, into
three conditions: stable support, experimental support, and no support.
-
-### Stable Support
-
-Full support for DML, DDL, DCL, TCL, and common DALs. Support for complex
queries such as paging, de-duplication, sorting, grouping, aggregation, table
association, etc. Support SCHEMA DDL and DML statements of PostgreSQL and
openGauss database.
-
-#### Normal Queries
-
-- main statement SELECT
-
-```sql
-SELECT select_expr [, select_expr ...] FROM table_reference [, table_reference
...]
-[WHERE predicates]
-[GROUP BY {col_name | position} [ASC | DESC], ...]
-[ORDER BY {col_name | position} [ASC | DESC], ...]
-[LIMIT {[offset,] row_count | row_count OFFSET offset}]
-```
-
-- select_expr
-
-```sql
-* |
-[DISTINCT] COLUMN_NAME [AS] [alias] |
-(MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] |
-COUNT(* | COLUMN_NAME | alias) [AS] [alias]
-```
-
-- table_reference
-
-```sql
-tbl_name [AS] alias] [index_hint_list]
-| table_reference ([INNER] | {LEFT|RIGHT} [OUTER]) JOIN table_factor [JOIN ON
conditional_expr | USING (column_list)]
-```
-
-#### Sub-query
-
-Stable support is provided by the kernel when both the subquery and the outer
query specify a shard key and the values of the slice key remain consistent.
-e.g:
-
-```sql
-SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
1;
-```
-Sub-query for
[pagination](https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/pagination/)
can be stably supported by the kernel.
-e.g.:
-
-```sql
-SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT * FROM t_order) row_
WHERE rownum <= ?) WHERE rownum > ?;
-```
-
-#### Pagination Query
-
-MySQL, PostgreSQL, and openGauss are fully supported, Oracle and SQLServer are
only partially supported due to more intricate paging queries.
-
-Pagination for Oracle and SQLServer needs to be handled by subqueries, and
ShardingSphere supports paging-related subqueries.
-
-- Oracle
-Support pagination by rownum
-
-```sql
-SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT o.order_id as
order_id FROM t_order o JOIN t_order_item i ON o.order_id = i.order_id) row_
WHERE rownum <= ?) WHERE rownum > ?
-```
-
-- SQL Server
-Support pagination that coordinates TOP + ROW_NUMBER() OVER
-
-```sql
-SELECT * FROM (SELECT TOP (?) ROW_NUMBER() OVER (ORDER BY o.order_id DESC) AS
rownum, * FROM t_order o) AS temp WHERE temp.rownum > ? ORDER BY temp.order_id
-```
-
-Support pagination by OFFSET FETCH after SQLServer 2012
-
-```sql
-SELECT * FROM t_order o ORDER BY id OFFSET ? ROW FETCH NEXT ? ROWS ONLY
-```
-
-- MySQL, PostgreSQL and openGauss all support LIMIT pagination without the
need for sub-query:
-
-```sql
-SELECT * FROM t_order o ORDER BY id LIMIT ? OFFSET ?
-```
-
-#### Shard keys included in operation expressions
-
-When the sharding key is contained in an expression, the value used for
sharding cannot be extracted through the SQL letters and will result in full
routing.
-
-For example, assume `create_time` is a sharding key.
-
-```sql
-SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
-```
-
-### Experimental Support
-
-Experimental support refers specifically to support provided by implementing
Federation execution engine, an experimental product that is still under
development. Although largely available to users, it still requires significant
optimization.
-
-#### Sub-query
-
-The Federation execution engine provides support for subqueries and outer
queries that do not both specify a sharding key or have inconsistent values for
the sharding key.
-
-e.g:
-
-```sql
-SELECT * FROM (SELECT * FROM t_order) o;
-
-SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1;
-
-SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o;
-
-SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
2;
-```
-
-#### Cross-database Associated query
-
-When multiple tables in an associated query are distributed across different
database instances, the Federation execution engine can provide support.
Assuming that t_order and t_order_item are sharded tables with multiple data
nodes while no binding table rules are configured, and t_user and t_user_role
are single tables distributed across different database instances, then the
Federation execution engine can support the following common associated queries.
-
-```sql
-SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id
WHERE o.order_id = 1;
-
-SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE
o.user_id = 1;
-
-SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE
o.user_id = 1;
-
-SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE
i.user_id = 1;
-
-SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id
WHERE i.user_id = 1;
-
-SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE
u.user_id = 1;
-```
-
-### Do not Support
-
-#### CASE WHEN
-
-The following CASE WHEN statements are not supported:
-- `CASE WHEN` contains sub-query
-- Logic names are used in `CASE WHEN`( Please use an alias)
-
-#### Pagination Query
-
-Due to the complexity of paging queries, there are currently some paging
queries that are not supported for Oracle and SQLServer, such as:
-- Oracle
-The paging method of rownum + BETWEEN is not supported at present
-
-- SQLServer
-Currently, pagination with WITH xxx AS (SELECT ...) is not supported. Since
the SQLServer paging statement automatically generated by Hibernate uses the
WITH statement, Hibernate-based SQLServer paging is not supported at this
moment. Pagination using two TOP + subquery also cannot be supported at this
time.
-
## Related References
- User Guide:
[sharding](https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding/)
- Developer Guide:
[sharding](https://shardingsphere.apache.org/document/current/en/dev-manual/sharding/)
-- Source Codes:
https://github.com/apache/shardingsphere/tree/master/shardingsphere-features/shardingsphere-sharding
diff --git a/docs/document/content/features/sharding/concept.cn.md
b/docs/document/content/features/sharding/concept.cn.md
new file mode 100644
index 00000000000..74718b65575
--- /dev/null
+++ b/docs/document/content/features/sharding/concept.cn.md
@@ -0,0 +1,167 @@
++++
+title = "核心概念"
+weight = 1
++++
+
+## 表
+
+表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
+
+### 逻辑表
+
+相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 `t_order_0` 到
`t_order_9`,他们的逻辑表名为 `t_order`。
+
+### 真实表
+
+在水平拆分的数据库中真实存在的物理表。 即上个示例中的 `t_order_0` 到 `t_order_9`。
+
+### 绑定表
+
+指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
例如:`t_order` 表和 `t_order_item` 表,均按照 `order_id` 分片,并且使用 `order_id`
进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
+
+```sql
+SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE
o.order_id in (10, 11);
+```
+
+在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4
条,它们呈现为笛卡尔积:
+
+```sql
+SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+```
+
+在配置绑定表关系,并且使用 `order_id` 进行关联后,路由的 SQL 应该为 2 条:
+
+```sql
+SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+```
+
+其中 `t_order` 表由于指定了分片条件,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么
`t_order_item` 表的分片计算将会使用 `t_order` 的条件。
+
+### 广播表
+
+指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
+
+### 单表
+
+指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
+
+## 数据节点
+
+数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0。
+逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
+
+### 均匀分布
+
+指数据表在每个数据源内呈现均匀分布的态势, 例如:
+
+```Nginx
+db0
+ ├── t_order0
+ └── t_order1
+db1
+ ├── t_order0
+ └── t_order1
+```
+
+数据节点的配置如下:
+
+```CSS
+db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
+```
+
+### 自定义分布
+
+指数据表呈现有特定规则的分布, 例如:
+
+```Nginx
+db0
+ ├── t_order0
+ └── t_order1
+db1
+ ├── t_order2
+ ├── t_order3
+ └── t_order4
+```
+
+数据节点的配置如下:
+
+```CSS
+db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
+```
+
+## 分片
+
+### 分片键
+
+用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。
除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
+
+### 分片算法
+
+用于将数据分片的算法,支持 `=`、`>=`、`<=`、`>`、`<`、`BETWEEN` 和 `IN` 进行分片。 分片算法可由开发者自行实现,也可使用
Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
+
+### 自动化分片算法
+
+分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
+
+### 自定义分片算法
+
+提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
+
+- 标准分片算法
+
+用于处理使用单一键作为分片键的 `=`、`IN`、`BETWEEN AND`、`>`、`<`、`>=`、`<=` 进行分片的场景。
+
+- 复合分片算法
+
+用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
+
+- Hint 分片算法
+
+用于处理使用 `Hint` 行分片的场景。
+
+### 分片策略
+
+包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
+
+### 强制分片路由
+
+对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。 例:按照员工登录主键分库,而数据库中并无此字段。 SQL
Hint 支持通过 Java API 和 SQL 注释两种方式使用。 详情请参见强制分片路由。
+
+## 行表达式
+
+行表达式是为了解决配置的简化与一体化这两个主要问题。在繁琐的数据分片规则配置中,随着数据节点的增多,大量的重复配置使得配置本身不易被维护。
通过行表达式可以有效地简化数据节点配置工作量。
+
+对于常见的分片算法,使用 Java 代码实现并不有助于配置的统一管理。 通过行表达式书写分片算法,可以有效地将规则配置一同存放,更加易于浏览与存储。
+
+行表达式的使用非常直观,只需要在配置中使用 `${ expression }` 或 `$->{ expression }` 标识行表达式即可。
目前支持数据节点和分片算法这两个部分的配置。 行表达式的内容使用的是 Groovy 的语法,Groovy 能够支持的所有操作,行表达式均能够支持。 例如:
+
+`${begin..end}` 表示范围区间
+`${[unit1, unit2, unit_x]}` 表示枚举值
+
+行表达式中如果出现连续多个 `${ expression }` 或 `$->{ expression }`
表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
+
+例如,以下行表达式:
+
+```Groovy
+${['online', 'offline']}_table${1..3}
+```
+
+最终会解析为:
+```PlainText
+online_table1, online_table2, online_table3, offline_table1, offline_table2,
offline_table3
+```
+
+## 分布式主键
+
+传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。
虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
+
+目前有许多第三方解决方案可以完美解决这个问题,如 UUID
等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere
不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
+
diff --git a/docs/document/content/features/sharding/concept.en.md
b/docs/document/content/features/sharding/concept.en.md
new file mode 100644
index 00000000000..58b1c3ba161
--- /dev/null
+++ b/docs/document/content/features/sharding/concept.en.md
@@ -0,0 +1,168 @@
++++
+title = "Core Concept"
+weight = 1
++++
+
+## Table
+
+Tables are a key concept for transparent data sharding. Apache ShardingSphere
adapts to the data sharding requirements under different scenarios by providing
diverse table types.
+
+### Logic Table
+
+The logical name of the horizontally sharded database (table) of the same
structure is the logical identifier of the table in SQL. Example: Order data is
split into 10 tables according to the primary key endings, are `t_order_0` to
`t_order_9`, and their logical table names are `t_order`.
+
+### Actual Table
+
+Physical tables that exist in the horizontally sharded databases. Those are,
`t_order_0` to `t_order_9` in the previous example.
+
+
+### Binding Table
+
+Refers to a set of sharded tables with consistent sharding rules. When using
binding tables for multi-table associated query, a sharding key must be used
for the association, otherwise, Cartesian product association or cross-library
association will occur, affecting query efficiency.
+
+For example, if the `t_order` table and `t_order_item` table are both sharded
according to `order_id` and are correlated using `order_id`, the two tables are
binding tables. The multi-table associated queries between binding tables will
not have a Cartesian product association, so the associated queries will be
much more effective. Here is an example,
+
+If SQL is:
+
+```sql
+SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE
o.order_id in (10, 11);
+```
+
+In the case where no binding table relationships are being set, assume that
the sharding key `order_id` routes the value 10 to slice 0 and the value 11 to
slice 1, then the routed SQL should be 4 items, which are presented as a
Cartesian product:
+
+```sql
+SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+```
+
+After the relationships between binding tables are configured and associated
with order_id, the routed SQL should then be 2 items:
+
+```sql
+SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+
+SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);
+```
+
+The t_order table will be used by ShardingSphere as the master table for the
entire binding table since it specifies the sharding condition. All routing
calculations will use only the policy of the primary table, then the sharding
calculations for the `t_order_item` table will use the `t_order` condition.
+
+### Broadcast data frame
+
+Refers to tables that exist in all sharded data sources. The table structure
and its data are identical in each database. Suitable for scenarios where the
data volume is small and queries are required to be associated with tables of
massive data, e.g., dictionary tables.
+
+### Single Table
+
+Refers to the only table that exists in all sharded data sources. Suitable for
tables with a small amount of data and do not need to be sharded.
+
+## Data Nodes
+
+The smallest unit of the data shard, consists of the data source name and the
real table. Example: `ds_0.t_order_0`.
+
+The mapping relationship between the logical table and the real table can be
classified into two forms: uniform distribution and custom distribution.
+
+### Uniform Distribution
+
+refers to situations where the data table exhibits a uniform distribution
within each data source. For example:
+
+```Nginx
+db0
+ ├── t_order0
+ └── t_order1
+db1
+ ├── t_order0
+ └── t_order1
+```
+
+The configuration of data nodes:
+
+```CSS
+db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
+```
+
+### Customized Distribution
+
+Data table exhibiting a patterned distribution. For example:
+
+```Nginx
+db0
+ ├── t_order0
+ └── t_order1
+db1
+ ├── t_order2
+ ├── t_order3
+ └── t_order4
+```
+
+configuration of data nodes:
+
+```CSS
+db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
+```
+
+## Sharding
+
+### Sharding key
+
+A database field is used to split a database (table) horizontally. Example: If
the order primary key in the order table is sharded by modulo, the order
primary key is a sharded field. If there is no sharded field in SQL, full
routing will be executed, of which performance is poor. In addition to the
support for single-sharding fields, Apache ShardingSphere also supports
sharding based on multiple fields.
+
+### Sharding Algorithm
+
+Algorithm for sharding data, supporting `=`, `>=`, `<=`, `>`, `<`, `BETWEEN`
and `IN`. The sharding algorithm can be implemented by the developers
themselves or can use the Apache ShardingSphere built-in sharding algorithm,
syntax sugar, which is very flexible.
+
+### Automatic Sharding Algorithm
+
+Sharding algorithm—syntactic sugar is for conveniently hosting all data nodes
without users having to concern themselves with the physical distribution of
actual tables. Includes implementations of common sharding algorithms such as
modulo, hash, range, and time.
+
+### Customized Sharding Algorithm
+
+Provides a portal for application developers to implement their sharding
algorithms that are closely related to their business operations, while
allowing users to manage the physical distribution of actual tables themselves.
Customized sharding algorithms are further divided into:
+- Standard Sharding Algorithm
+Used to deal with scenarios where sharding is performed using a single key as
the sharding key `=`, `IN`, `BETWEEN AND`, `>`, `<`, `>=`, `<=`.
+- Composite Sharding Algorithm
+Used to cope with scenarios where multiple keys are used as sharding keys. The
logic containing multiple sharding keys is very complicated and requires the
application developers to handle it on their own.
+- Hint Sharding Algorithm
+For scenarios involving Hint sharding.
+
+### Sharding Strategy
+
+Consisting of a sharding key and sharding algorithm, which is abstracted
independently due to the independence of the sharding algorithm. What is viable
for sharding operations is the sharding key + sharding algorithm, known as
sharding strategy.
+
+### Mandatory Sharding routing
+
+For the scenario where the sharded field is not determined by SQL but by other
external conditions, you can use SQL Hint to inject the shard value. Example:
Conduct database sharding by employee login primary key, but there is no such
field in the database. SQL Hint can be used both via Java API and SQL
annotation. See Mandatory Sharding Routing for details.
+
+### Row Value Expressions
+
+Row expressions are designed to address the two main issues of configuration
simplification and integration. In the cumbersome configuration rules of data
sharding, the large number of repetitive configurations makes the configuration
itself difficult to maintain as the number of data nodes increases. The data
node configuration workload can be effectively simplified by row expressions.
+
+For the common sharding algorithm, using Java code implementation does not
help to manage the configuration uniformly. But by writing the sharding
algorithm through line expressions, the rule configuration can be effectively
stored together, which is easier to browse and store.
+
+Row expressions are very intuitive, just use `${ expression }` or `$->{
expression }` in the configuration to identify the row expressions. Data nodes
and sharding algorithms are currently supported. The content of row expressions
uses Groovy syntax, and all operations supported by Groovy are supported by row
expressions. For example:
+
+`${begin..end}` denotes the range interval
+
+`${[unit1, unit2, unit_x]}` denotes the enumeration value
+
+If there are multiple `${ expression }` or `$->{ expression }` expressions in
a row expression, the final result of the whole expression will be a Cartesian
combination based on the result of each sub-expression.
+
+e.g. The following row expression:
+
+```Groovy
+${['online', 'offline']}_table${1..3}
+```
+
+Finally, it can be parsed as this:
+
+```PlainText
+online_table1, online_table2, online_table3, offline_table1, offline_table2,
offline_table3
+```
+
+### Distributed Primary Key
+
+In traditional database software development, automatic primary key generation
is a basic requirement. Various databases provide support for this requirement,
such as self-incrementing keys of MySQL, self-incrementing sequences of Oracle,
etc. After data sharding, it is very tricky to generate global unique primary
keys for different data nodes. Self-incrementing keys between different actual
tables within the same logical table generate repetitive primary keys because
they are not mutua [...]
+
+Many third-party solutions can perfectly solve this problem, such as UUID,
which relies on specific algorithms to self-generate non-repeating keys, or by
introducing primary key generation services. To facilitate users and meet their
demands for different scenarios, Apache ShardingSphere not only provides
built-in distributed primary key generators, such as UUID and SNOWFLAKE but
also abstracts the interface of distributed primary key generators to enable
users to implement their own cus [...]
diff --git a/docs/document/content/features/sharding/limitation.cn.md
b/docs/document/content/features/sharding/limitation.cn.md
new file mode 100644
index 00000000000..cbfeac93463
--- /dev/null
+++ b/docs/document/content/features/sharding/limitation.cn.md
@@ -0,0 +1,158 @@
++++
+title = "使用限制"
+weight = 2
++++
+
+兼容全部常用的路由至单数据节点的 SQL; 路由至多数据节点的 SQL 由于场景复杂,分为稳定支持、实验性支持和不支持这三种情况。
+
+## 稳定支持
+
+全面支持 DML、DDL、DCL、TCL 和常用 DAL。 支持分页、去重、排序、分组、聚合、表关联等复杂查询。 支持 PostgreSQL 和
openGauss 数据库 SCHEMA DDL 和 DML 语句。
+
+### 常规查询
+
+- SELECT 主语句
+
+```sql
+SELECT select_expr [, select_expr ...] FROM table_reference [, table_reference
...]
+[WHERE predicates]
+[GROUP BY {col_name | position} [ASC | DESC], ...]
+[ORDER BY {col_name | position} [ASC | DESC], ...]
+[LIMIT {[offset,] row_count | row_count OFFSET offset}]
+```
+
+- select_expr
+
+```sql
+* |
+[DISTINCT] COLUMN_NAME [AS] [alias] |
+(MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] |
+COUNT(* | COLUMN_NAME | alias) [AS] [alias]
+```
+
+- table_reference
+
+```sql
+tbl_name [AS] alias] [index_hint_list]
+| table_reference ([INNER] | {LEFT|RIGHT} [OUTER]) JOIN table_factor [JOIN ON
conditional_expr | USING (column_list)]
+```
+
+### 子查询
+
+子查询和外层查询同时指定分片键,且分片键的值保持一致时,由内核提供稳定支持。
+
+例如:
+
+```sql
+SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
1;
+```
+
+用于[分页](https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/pagination)的子查询,由内核提供稳定支持。
+
+例如:
+
+```sql
+SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT * FROM t_order) row_
WHERE rownum <= ?) WHERE rownum > ?;
+```
+
+### 分页查询
+
+完全支持 MySQL、PostgreSQL、openGauss,Oracle 和 SQLServer 由于分页查询较为复杂,仅部分支持。
+
+Oracle 和 SQLServer 的分页都需要通过子查询来处理,ShardingSphere 支持分页相关的子查询。
+
+- Oracle
+
+支持使用 rownum 进行分页:
+
+```sql
+SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT o.order_id as
order_id FROM t_order o JOIN t_order_item i ON o.order_id = i.order_id) row_
WHERE rownum <= ?) WHERE rownum > ?
+```
+
+- SQLServer
+
+支持使用 TOP + ROW_NUMBER() OVER 配合进行分页:
+
+```sql
+SELECT * FROM (SELECT TOP (?) ROW_NUMBER() OVER (ORDER BY o.order_id DESC) AS
rownum, * FROM t_order o) AS temp WHERE temp.rownum > ? ORDER BY temp.order_id
+```
+支持 SQLServer 2012 之后的 OFFSET FETCH 的分页方式:
+
+```sql
+SELECT * FROM t_order o ORDER BY id OFFSET ? ROW FETCH NEXT ? ROWS ONLY
+```
+
+- MySQL, PostgreSQL 和 openGauss
+
+MySQL、PostgreSQL 和 openGauss 都支持 LIMIT 分页,无需子查询:
+
+```sql
+SELECT * FROM t_order o ORDER BY id LIMIT ? OFFSET ?
+```
+
+### 运算表达式中包含分片键
+
+当分片键处于运算表达式中时,无法通过 SQL `字面` 提取用于分片的值,将导致全路由。
+例如,假设 `create_time` 为分片键:
+
+```sql
+SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
+```
+
+## 实验性支持
+
+实验性支持特指使用 Federation 执行引擎提供支持。 该引擎处于快速开发中,用户虽基本可用,但仍需大量优化,是实验性产品。
+
+### 子查询
+
+子查询和外层查询未同时指定分片键,或分片键的值不一致时,由 Federation 执行引擎提供支持。
+
+例如:
+
+```sql
+SELECT * FROM (SELECT * FROM t_order) o;
+
+SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1;
+
+SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o;
+
+SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
2;
+```
+
+### 跨库关联查询
+
+当关联查询中的多个表分布在不同的数据库实例上时,由 Federation 执行引擎提供支持。 假设 `t_order` 和 `t_order_item`
是多数据节点的分片表,并且未配置绑定表规则,`t_user` 和 `t_user_role` 是分布在不同的数据库实例上的单表,那么 Federation
执行引擎能够支持如下常用的关联查询:
+
+```sql
+SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id
WHERE o.order_id = 1;
+
+SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE
o.user_id = 1;
+
+SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE
o.user_id = 1;
+
+SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE
i.user_id = 1;
+
+SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id
WHERE i.user_id = 1;
+
+SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE
u.user_id = 1;
+```
+
+## 不支持
+
+### CASE WHEN
+以下 CASE WHEN 语句不支持:
+
+- CASE WHEN 中包含子查询
+- CASE WHEN 中使用逻辑表名(请使用表别名)
+
+### 分页查询
+
+Oracle 和 SQLServer 由于分页查询较为复杂,目前有部分分页查询不支持,具体如下:
+
+- Oracle
+
+目前不支持 rownum + BETWEEN 的分页方式。
+
+- SQLServer
+
+目前不支持使用 WITH xxx AS (SELECT …) 的方式进行分页。由于 Hibernate 自动生成的 SQLServer 分页语句使用了
WITH 语句,因此目前并不支持基于 Hibernate 的 SQLServer 分页。 目前也不支持使用两个 TOP + 子查询的方式实现分页。
diff --git a/docs/document/content/features/sharding/limitation.en.md
b/docs/document/content/features/sharding/limitation.en.md
new file mode 100644
index 00000000000..c270432b50c
--- /dev/null
+++ b/docs/document/content/features/sharding/limitation.en.md
@@ -0,0 +1,150 @@
++++
+title = "Limitations"
+weight = 2
++++
+
+Compatible with all commonly used SQL that routes to single data nodes; SQL
routing to multiple data nodes is divided, because of complexity issues, into
three conditions: stable support, experimental support, and no support.
+
+## Stable Support
+
+Full support for DML, DDL, DCL, TCL, and common DALs. Support for complex
queries such as paging, de-duplication, sorting, grouping, aggregation, table
association, etc. Support SCHEMA DDL and DML statements of PostgreSQL and
openGauss database.
+
+### Normal Queries
+
+- main statement SELECT
+
+```sql
+SELECT select_expr [, select_expr ...] FROM table_reference [, table_reference
...]
+[WHERE predicates]
+[GROUP BY {col_name | position} [ASC | DESC], ...]
+[ORDER BY {col_name | position} [ASC | DESC], ...]
+[LIMIT {[offset,] row_count | row_count OFFSET offset}]
+```
+
+- select_expr
+
+```sql
+* |
+[DISTINCT] COLUMN_NAME [AS] [alias] |
+(MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] |
+COUNT(* | COLUMN_NAME | alias) [AS] [alias]
+```
+
+- table_reference
+
+```sql
+tbl_name [AS] alias] [index_hint_list]
+| table_reference ([INNER] | {LEFT|RIGHT} [OUTER]) JOIN table_factor [JOIN ON
conditional_expr | USING (column_list)]
+```
+
+### Sub-query
+
+Stable support is provided by the kernel when both the subquery and the outer
query specify a shard key and the values of the slice key remain consistent.
+e.g:
+
+```sql
+SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
1;
+```
+Sub-query for
[pagination](https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/pagination/)
can be stably supported by the kernel.
+e.g.:
+
+```sql
+SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT * FROM t_order) row_
WHERE rownum <= ?) WHERE rownum > ?;
+```
+
+### Pagination Query
+
+MySQL, PostgreSQL, and openGauss are fully supported, Oracle and SQLServer are
only partially supported due to more intricate paging queries.
+
+Pagination for Oracle and SQLServer needs to be handled by subqueries, and
ShardingSphere supports paging-related subqueries.
+
+- Oracle
+Support pagination by rownum
+
+```sql
+SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT o.order_id as
order_id FROM t_order o JOIN t_order_item i ON o.order_id = i.order_id) row_
WHERE rownum <= ?) WHERE rownum > ?
+```
+
+- SQL Server
+Support pagination that coordinates TOP + ROW_NUMBER() OVER
+
+```sql
+SELECT * FROM (SELECT TOP (?) ROW_NUMBER() OVER (ORDER BY o.order_id DESC) AS
rownum, * FROM t_order o) AS temp WHERE temp.rownum > ? ORDER BY temp.order_id
+```
+
+Support pagination by OFFSET FETCH after SQLServer 2012
+
+```sql
+SELECT * FROM t_order o ORDER BY id OFFSET ? ROW FETCH NEXT ? ROWS ONLY
+```
+
+- MySQL, PostgreSQL and openGauss all support LIMIT pagination without the
need for sub-query:
+
+```sql
+SELECT * FROM t_order o ORDER BY id LIMIT ? OFFSET ?
+```
+
+### Shard keys included in operation expressions
+
+When the sharding key is contained in an expression, the value used for
sharding cannot be extracted through the SQL letters and will result in full
routing.
+
+For example, assume `create_time` is a sharding key.
+
+```sql
+SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
+```
+
+## Experimental Support
+
+Experimental support refers specifically to support provided by implementing
Federation execution engine, an experimental product that is still under
development. Although largely available to users, it still requires significant
optimization.
+
+### Sub-query
+
+The Federation execution engine provides support for subqueries and outer
queries that do not both specify a sharding key or have inconsistent values for
the sharding key.
+
+e.g:
+
+```sql
+SELECT * FROM (SELECT * FROM t_order) o;
+
+SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1;
+
+SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o;
+
+SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id =
2;
+```
+
+### Cross-database Associated query
+
+When multiple tables in an associated query are distributed across different
database instances, the Federation execution engine can provide support.
Assuming that t_order and t_order_item are sharded tables with multiple data
nodes while no binding table rules are configured, and t_user and t_user_role
are single tables distributed across different database instances, then the
Federation execution engine can support the following common associated queries.
+
+```sql
+SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id
WHERE o.order_id = 1;
+
+SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE
o.user_id = 1;
+
+SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE
o.user_id = 1;
+
+SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE
i.user_id = 1;
+
+SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id
WHERE i.user_id = 1;
+
+SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE
u.user_id = 1;
+```
+
+## Do not Support
+
+### CASE WHEN
+
+The following CASE WHEN statements are not supported:
+- `CASE WHEN` contains sub-query
+- Logic names are used in `CASE WHEN`( Please use an alias)
+
+### Pagination Query
+
+Due to the complexity of paging queries, there are currently some paging
queries that are not supported for Oracle and SQLServer, such as:
+- Oracle
+The paging method of rownum + BETWEEN is not supported at present
+
+- SQLServer
+Currently, pagination with WITH xxx AS (SELECT ...) is not supported. Since
the SQLServer paging statement automatically generated by Hibernate uses the
WITH statement, Hibernate-based SQLServer paging is not supported at this
moment. Pagination using two TOP + subquery also cannot be supported at this
time.
diff --git a/docs/document/content/features/transaction/_index.cn.md
b/docs/document/content/features/transaction/_index.cn.md
index 06d09de697b..46a26ffed75 100644
--- a/docs/document/content/features/transaction/_index.cn.md
+++ b/docs/document/content/features/transaction/_index.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.5. </b>"
+pre = "<b>3.2. </b>"
title = "分布式事务"
-weight = 5
+weight = 2
chapter = true
+++
diff --git a/docs/document/content/features/transaction/_index.en.md
b/docs/document/content/features/transaction/_index.en.md
index b38bfdec792..38d3f420d16 100644
--- a/docs/document/content/features/transaction/_index.en.md
+++ b/docs/document/content/features/transaction/_index.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>3.5. </b>"
+pre = "<b>3.2. </b>"
title = "Distributed Transaction"
-weight = 5
+weight = 2
chapter = true
+++
diff --git a/docs/document/content/features/transaction/concept.cn.md
b/docs/document/content/features/transaction/concept.cn.md
new file mode 100644
index 00000000000..8ee6733a5a9
--- /dev/null
+++ b/docs/document/content/features/transaction/concept.cn.md
@@ -0,0 +1,9 @@
++++
+title = "核心概念"
+weight = 1
++++
+
+## XA 协议
+
+XA 协议最早的分布式事务模型是由 `X/Open` 国际联盟提出的 `X/Open Distributed Transaction Processing
(DTP)` 模型,简称 XA 协议。
+
diff --git a/docs/document/content/features/transaction/concept.en.md
b/docs/document/content/features/transaction/concept.en.md
new file mode 100644
index 00000000000..0d2404e2bf9
--- /dev/null
+++ b/docs/document/content/features/transaction/concept.en.md
@@ -0,0 +1,8 @@
++++
+title = "Core Concept"
+weight = 1
++++
+
+## XA Protocol
+
+The original distributed transaction model of XA protocol is the "X/Open
Distributed Transaction Processing (DTP)" model, XA protocol for short, which
was proposed by the X/Open international consortium.
diff --git a/docs/document/content/features/transaction/limitations.cn.md
b/docs/document/content/features/transaction/limitations.cn.md
new file mode 100644
index 00000000000..658351b0c6c
--- /dev/null
+++ b/docs/document/content/features/transaction/limitations.cn.md
@@ -0,0 +1,52 @@
++++
+title = "使用限制"
+weight = 2
++++
+
+虽然 Apache ShardingSphere 希望能够完全兼容所有的分布式事务场景,并在性能上达到最优,但在 CAP
定理所指导下,分布式事务必然有所取舍。
+Apache ShardingSphere 希望能够将分布式事务的选择权交给使用者,在不同的场景用使用最适合的分布式事务解决方案。
+
+## LOCAL 事务
+
+### 支持项
+
+* 完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中;
+* 完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能够回滚。
+
+### 不支持项
+
+* 不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交,且无法回滚。
+
+## XA 事务
+
+### 支持项
+
+* 支持 Savepoint 嵌套事务;
+* PostgreSQL/OpenGauss 事务块内,SQL 执行出现异常,执行 `Commit`,事务自动回滚;
+* 支持数据分片后的跨库事务;
+* 两阶段提交保证操作的原子性和数据的强一致性;
+* 服务宕机重启后,提交/回滚中的事务可自动恢复;
+* 支持同时使用 XA 和非 XA 的连接池。
+
+### 不支持项
+
+* 服务宕机后,在其它机器上恢复提交/回滚中的数据;
+* MySQL 事务块内,SQL 执行出现异常,执行 `Commit`,数据保持一致。
+
+## BASE 事务
+
+### 支持项
+
+* 支持数据分片后的跨库事务;
+* 支持 RC 隔离级别;
+* 通过 undo 快照进行事务回滚;
+* 支持服务宕机后的,自动恢复提交中的事务。
+
+### 不支持项
+
+* 不支持除 RC 之外的隔离级别。
+
+### 待优化项
+
+* Apache ShardingSphere 和 SEATA 重复 SQL 解析。
+
diff --git a/docs/document/content/features/transaction/limitations.en.md
b/docs/document/content/features/transaction/limitations.en.md
new file mode 100644
index 00000000000..0336a4e4e5b
--- /dev/null
+++ b/docs/document/content/features/transaction/limitations.en.md
@@ -0,0 +1,52 @@
++++
+title = "Limitations"
+weight = 2
++++
+
+Though Apache ShardingSphere intends to be compatible with all distributed
scenario and best performance, under CAP theorem guidance, there is no sliver
bullet with distributed transaction solution.
+
+Apache ShardingSphere wants to give the user choice of distributed transaction
type and use the most suitable solution in different scenarios.
+
+## LOCAL Transaction
+
+### Supported
+
+* Support none-cross-database transactions. For example, sharding table or
sharding database with its route result in same database;
+* Support cross-database transactions caused by logic exceptions. For example,
update two databases in transaction with exception thrown, data can rollback in
both databases.
+
+### Unsupported
+
+* Do not support the cross-database transactions caused by network or hardware
crash. For example, when update two databases in transaction, if one database
crashes before commit, then only the data of the other database can commit.
+
+## XA Transaction
+
+### Supported
+
+* Support Savepoint;
+* PostgreSQL/OpenGauss, in the transaction block, the SQL execution is
abnormal,then run `Commit`,transactions are automatically rollback;
+* Support cross-database transactions after sharding;
+* Operation atomicity and high data consistency in 2PC transactions;
+* When service is down and restarted, commit and rollback transactions can be
recovered automatically;
+* Support use XA and non-XA connection pool together.
+
+### Unsupported
+
+* Recover committing and rolling back in other machines after the service is
down;
+* MySQL,in the transaction block, the SQL execution is abnormal, and run
`Commit`, and data remains consistent.
+
+## BASE Transaction
+
+### Supported
+
+* Support cross-database transactions after sharding;
+* Support RC isolation level;
+* Rollback transaction according to undo log;
+* Support recovery committing transaction automatically after the service is
down.
+
+### Unsupported
+
+* Do not support other isolation level except RC.
+
+### To Be Optimized
+
+* SQL parsed twice by Apache ShardingSphere and SEATA.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}