This is an automated email from the ASF dual-hosted git repository.
wuweijie pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new bd6dd4cc473 feat(blog): add new articles and images (#19798)
bd6dd4cc473 is described below
commit bd6dd4cc47346775914e00eeac1cb130ae4d097a
Author: Yumeiya <[email protected]>
AuthorDate: Thu Aug 4 16:01:16 2022 +0800
feat(blog): add new articles and images (#19798)
* add new blogs and images
* delete images
* Revert "delete images"
This reverts commit b685f405da2d32345c0fc19fbc5196ca94fd112d.
* Delete images
* Update
2022_06_08_How_does_Apache_ShardingSphere_standardize_and_format_code_We
use_Spotless.en.md
* Update
2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it’s_simpler_than_Dubbo’s.en.md
* Update
2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new API
driver_Apache_ShardingSphere_5.1.2_is_released.en.md
---
..._Governance_in_a_Cloud_Native_Environment.en.md | 137 +++++++
...andardize_and_format_code_We use_Spotless.en.md | 221 +++++++++++
...ngSphere_Enterprise_Applications_Bilibili.en.md | 93 +++++
...200\231s_simpler_than_Dubbo\342\200\231s.en.md" | 270 ++++++++++++++
...stem_RTO_60x_and_increasing_speed_by_20%.en.md" | 130 +++++++
...r_Apache_ShardingSphere_5.1.2_is_released.en.md | 407 +++++++++++++++++++++
...2022_06_30_ShardingSphere_&_Database_Mesh.en.md | 128 +++++++
7 files changed, 1386 insertions(+)
diff --git
a/docs/blog/content/material/2022_06_02_Database_Mesh_2.0_Database_Governance_in_a_Cloud_Native_Environment.en.md
b/docs/blog/content/material/2022_06_02_Database_Mesh_2.0_Database_Governance_in_a_Cloud_Native_Environment.en.md
new file mode 100644
index 00000000000..81e66666ea8
--- /dev/null
+++
b/docs/blog/content/material/2022_06_02_Database_Mesh_2.0_Database_Governance_in_a_Cloud_Native_Environment.en.md
@@ -0,0 +1,137 @@
++++
+title = "Database Mesh 2.0: Database Governance in a Cloud Native Environment"
+weight = 58
+chapter = true
++++
+
+In March 2018, an article titled [Service Mesh is the broad trend, what about
Database Mesh?](https://www.infoq.cn/article/database-mesh-sharding-jdbc), was
pubslished on [InfoQ China](https://www.infoq.com/) and went viral in the
technical community.
+In this article, Zhang Liang, the founder of [Apache
ShardingSphere](https://shardingsphere.apache.org/), described Database Mesh
concept along with the idea of [Service
Mesh](https://linkerd.io/what-is-a-service-mesh/). Four years later, the
Database Mesh concept has been integrated by several companies together with
their own tools and ecosystems. Today, in addition to Service Mesh, a variety
of “X Mesh” concepts such as [ChaosMesh](https://chaos-mesh.org/),
[EventMesh](https://eventme [...]
+
+This article reviews the background of Database Mesh, reexamines the value of
Database Mesh 1.0, and introduces the new concepts, ideas, and features of
Database Mesh 2.0. It also attempts to explore the future of Database Mesh.
+
+## 1. Reviewing Database Mesh 1.0
+In 2016, the first generation of Service Mesh was introduced to the public by
[Linkerd](https://linkerd.io/). In 2017, the second generation of Service Mesh,
was born thanks to [Istio](https://istio.io/). Its design separates the control
plane from data plane, and key behavioral factors such as traffic governance,
access control and observability in service governance are abstracted and
standardized. Then the application container and governance container are
decoupled by [Kubernetes](ht [...]
+
+
+
+Almost at the same time, [ShardingSphere](https://shardingsphere.apache.org/)
led by Zhang Liang evolved from the original
[ShardingSphere-JDBC](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-jdbc)
into the
[ShardingSphere-Proxy](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/)
we know today, that can be deployed independently. Both built in Java,
respectively representing SDK mode and Proxy mode, providi [...]
+
+Both of them have their respecitve pros and cons. In 2018, the article,
[Service Mesh is the broad trend, what about Database
Mesh?](https://www.infoq.cn/article/database-mesh-sharding-jdbc) written by
Zhang Liang (on InfoQ China) described Database Mesh as:
+
+”Database Mesh is a new term derived from Service Mesh. As its name suggests,
Database Mesh uses a mesh layer to achieve unified management of databases
scattered around the system. The network of interactions between applications
and databases, held together by mesh layers, is as complex and ordered as a
spider’s web.”
+
+According to this description, the concept of Database Mesh is similar to that
of the Service Mesh. It is called Database Mesh, not Data Mesh, because its
primary goal is not to engage data stored in the database, but to engage the
interaction between applications and databases.
+
+Database Mesh focuses on how to organically connect distributed applications
for data access with databases. It’s more focused on the interaction, and
effectively clarifies the interaction between chaotic applications and
databases.
+
+Database Mesh empowers applications that access databases, eventually forming
a huge databases grid. Applications and databases can simply be matched in the
grid and are governed by the mesh layer.
+
+This means that the implementation of Service Mesh in Kubernetes’ Sidecar
model opens new possibilities: ShardingSphere-Sidecar mode can effectively
combine the advantages and minimize the disadvantages of JDBC, Proxy and Proxy
client, and achieve a real cloud infrastructure with “elastic scaling + zero
intrusion + decentralization”.
+
+When a new technology concept is launched, it’ll be characterized hahahby
different business scenarios and patterns, different architectural design,
different infrastructure maturity, and even different engineering cultures. It
is a belief that has been fully demonstrated in the implementation of
Kubernetes, and has been reinforced by Service Mesh. What about Database Mesh?
+
+[ShardingSphere-Sidecar](https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-sidecar/)
incorporates ShardingSphere’s sharding capabilities, while some companies
delivered their own interpretation based on Database Mesh.
+
+For example, analysis and support for SQL protocol are added in Service Mesh
by means of secondary development to enhance the database traffic governance
ability, which is compatible with the unified service governance configuration.
The concept of Database Mesh is integrated into a complete set of middleware
service frameworks, and a unified access mode is provided for business
applications in the form of SDK or Sidecar to simplify the operation for
developers.
+
+Another example is the project that integrates distributed transaction
capabilities into the Database Mesh Sidecar, presenting business applications
as cloud native distributed databases. Either way, you can see that the
Database Mesh concept is taking gaining acceptance and growing into a thriving
ecosystem.
+
+
+
+Note: There are three implementations of Database Mesh 1.0:
ShardingSphere-Sidecar, Unified Mesh management, and distributed database from
left to right respectively.
+
+**So that’s Database Mesh 1.0.**
+
+## 2. Introducing Database Mesh 2.0
+In computer science, operating systems and databases are arguably the two most
important basic softwares. SQL, for example, has an impressive half-life
period. SQL not only played an important role in the early DBMS systems, but
recently has become a must-have skill in data science along with Python. The
vitality of SQL can be said to be timeless, which explains the famous paper
proclaiming “[One SQL to rule them all](https://arxiv.org/abs/1905.12133)”.
+
+If the database is perceived as a service node in the call-chain, then the
framework of Service Mesh can also be used for governance. If a database is
viewed as a stateful business application, its unique field gives rise to
governance specificities. For example, database requests cannot be randomly
routed to any peer nodes like services. More challenges are caused by the
perception and understanding of database protocols, data sharding and routing,
multiple replicas deployed by database [...]
+
+Moreover, when business applications are packaged and delivered in containers,
and they are distributed to the Kubernetes infrastructure of each data center
hundreds of thousands of times through [CI/CD
pipelines](https://www.redhat.com/en/topics/devops/what-cicd-pipeline), people
will undoubtedly think about how to achieve service governance in the upper
layer of applications and database governance. Database Mesh is an answer to
this question.
+
+Without Database Mesh, SDK and Proxy can also support the access and
governance to databases. Sidecar itself is not the core of Database Mesh.
+
+> **Database Mesh is not a static definition, but an evolving dynamic
concept.**
+
+Database Mesh 1.0 has been focusing on the governance of database traffic. It
can support data sharding, load balancing, observability, auditing and other
capabilities based on database protocol sensibility, which have tackled part of
the problems related to traffic governance. However, many capabilities are
still yet to be built for operators and database administrators (DBAs). For
instance, can a unified configuration be used to declare database access? Can
we restrict resource access [...]
+
+Developers may pay more attention to operational efficiency, cost overhead,
database protocol type and access information rather than where the data is
stored. Operators and database administrators (DBAs) are more concerned about
the automation, stability, security, monitoring and alarming of database
services. In addition, DBAs also focus on the changes, capacity, secure access,
backup and migration of data. All of these factors are tied with database
reliability engineering.
+
+It is precisely with the in-depth understanding of database governance
scenarios and the pursuit of ultimate user experience that led to the creation
of Database Mesh 2.0. Database Mesh 2.0 can achieve high-performance
scalability through programmability to address the challenge of database
governance on the cloud.
+
+**The goals of Database Mesh 2.0**
+Database Mesh 2.0 focuses on how to achieve the following goals in a cloud
native environment:
+
+- Further reduce the mental burden of developers, improve development
efficiency, and provide a transparent and intuitive user experience with
database infrastructure.
+- Build a database governance framework including database traffic, runtime
resources, reliability in a configurable, pluggable and customizable manner.
+- Provide standard user interfaces for typical scenarios in multiple database
fields such as heterogeneous data sources, cloud native databases, and
distributed databases.
+
+> **Developer experience**
+
+As mentioned above, business developers are mainly concerned about business
logic and implementation instead of infrastructure, operation and maintenance
features. Developement experience will move towards
[Serverless](https://www.redhat.com/en/topics/cloud-native-apps/what-is-serverless),
which means it will become more and more transparent and intuitive when
accessing databases. Developers only need to understand the type of data
storage required by their business, and then use preset [...]
+
+> **Programmable**
+
+For database traffic, different scenarios have different load balancing
policies and firewall rules, which can be provided to users in the form of
configuration. Furthermore, runtime resources such as traffic and bandwidth can
be restricted by loading programmable plugins. Both configurations and plugins
are designed to provide users with the maximum flexibility within the
framework, implementing the Unix design philosophy of “separation of mechanism
and policy”.
+
+> **Standard interface**
+
+In the process of migrating databases to the cloud, the migration complexity
has increased due to many issues such as deployment mode, data migration, and
data capacity. If you have a complete set of operating interfaces, you can
achieve unified governance across different database environments, thus
smoothing the process of cloud adoption in the future.
+
+**Database Mesh 2.0 governance framework**
+Database Mesh 2.0 provides a database-centric governance framework to achieve
the three goals introduced above:
+
+- Databases are first-class citizens. All abstractions are centered on
database governance, such as access control, traffic governance, and
observability.
+- Engineer-oriented experience: developers can continue to develop through
easy to use database declarations and definitions regardless of the location of
the database. For operation and maintenance personnel and DBAs, it provides a
variety of abstraction of database governance behavior to realize automatic
database reliability engineering.
+- Cloud native: it is built and implemented oriented towards cloud native,
suitable to various cloud environments with an open ecosystem and
implementation mechanism. Vendor lock-in is effectively elimated.
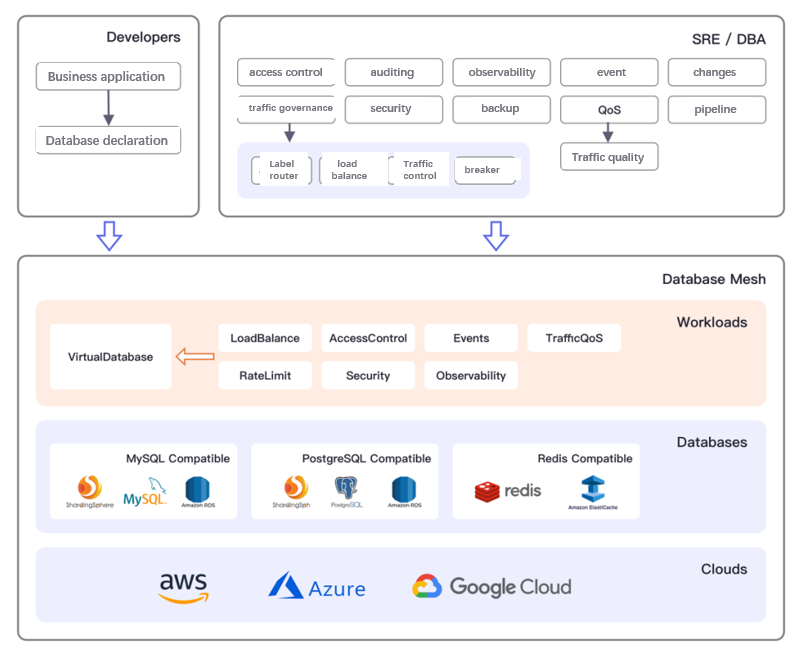
+
+
+The set of governance framework relies on the following work loads:
+
+- Virtual database: a database endpoint accessible to developers.
+- Traffic strategy: governance strategies for database access traffic such as
sharding, load balance, traffic control and circuit breaker.
+- Access control: provides fine-grained access control based on specified
rules, such as table level.
+- Security statement: data security statements such as data encryption.
+- Audit application: record applications’ operation behavior on the database,
such as accessing the risk control system.
+- Observability: configuration of database observability such as access
traffic, running state, and performance indicators etc.
+- Event bus: an event bus that accepts data changes.
+- QoS statements: resource QoS metrics set to improve the overall SLO metrics
of the database.
+- Backup plan: perform database backups as scheduled tasks.
+- `Schema` pipeline: manage database `schema` changes in code to improve the
success rate of database DDL and DML changes.
+The above design framework enables development to be more centralized and
efficient and cloud computing more user-friendly. In other words, Database Mesh
is making big strides towards scalability, ease of use and standardization.
+
+**That’s Database 2.0.**
+
+## 3. Database Mesh community
+The [Database Mesh official website](https://www.database-mesh.io/) has been
launched. The corresponding specification definition is open sourced on this
[Github](https://github.com/database-mesh/database-mesh) repository. The
community holds an online discussion every two weeks:
+
+- [Mailing list](https://groups.google.com/g/database-mesh)
+- [Biweekly meeting of English
community](https://meet.google.com/yhv-zrby-pyt) (from February 27, 2022), on
Wednesday 9:00 AM PST
+- [Biweekly meeting of Chinese
community](https://meeting.tencent.com/dm/6UXDMNsHBVQO) (from April 27, 2022),
on Wednesday 9:00 PM GMT+8
+- [Slack](https://databasemesh.slack.com/)
+- [Meeting minutes](https://bit.ly/39Fqt3x)
+
+You’re welcome to join the official community for discussion. The Database
Mesh community welcomes enthusiasts from from all over the world to build the
ecosystem together.
+
+SphereEx, a company founded by Zhang Liang (who is also the initiator of
Database Mesh), will launch [Pisanix](https://www.pisanix.io/) next month,
which is an open source solution oriented database mesh.
+
+## Authors
+**Miao Liyao**
+
+**Github:** @mlycore
+
+
+
+The Head of Cloud R&D at [SphereEx](https://www.sphere-ex.com/), a promoter of
open source, specializing in SaaS and Database Mesh
+
+In 2015, he began to study [Kubernetes](https://kubernetes.io/) and was one of
the earliest cloud native practitioners in China. In 2016, he established the
“Container Era” WeChat blog and contributed over 600 technical articles. He
previously was an infrastructure architect, cloud product leader, cloud native
R&D engineer at 株式会社ネットスターズ([NETSTARS](https://netstars.co.jp/en/)), Beijing
Chuanyang Technology, [Ant Financial Services
Group](https://www.antgroup.com/en), [YeePay](https://glo [...]
+
+**Zhang Liang**
+
+**Github:** @terrymanu
+
+
+Zhang Liang, the founder & CEO of [SphereEx](https://www.sphere-ex.com/),
served as the head of the architecture and database team of many large
well-known Internet enterprises. He is enthusiastic about open source and is
the founder and PMC chair of Apache ShardingSphere,
[ElasticJob](https://shardingsphere.apache.org/elasticjob/), and other
well-known open source projects.
+
+He is now a member of the [Apache Software
Foundation](https://www.apache.org/), [a Microsoft
MVP](https://mvp.microsoft.com/), [Tencent Cloud
TVP](https://cloud.tencent.com/tvp), and [Huawei Cloud
MVP](https://developer.huaweicloud.com/mvp) and has more than 10 years of
experience in the field of architecture and database. He advocates for elegant
code, and has made great achievements in distributed database technology and
academic research. He has served as a producer and speaker at do [...]
+
diff --git
a/docs/blog/content/material/2022_06_08_How_does_Apache_ShardingSphere_standardize_and_format_code_We
use_Spotless.en.md
b/docs/blog/content/material/2022_06_08_How_does_Apache_ShardingSphere_standardize_and_format_code_We
use_Spotless.en.md
new file mode 100644
index 00000000000..1871401d765
--- /dev/null
+++
b/docs/blog/content/material/2022_06_08_How_does_Apache_ShardingSphere_standardize_and_format_code_We
use_Spotless.en.md
@@ -0,0 +1,221 @@
++++
+title = "How does Apache ShardingSphere standardize and format code? We use
Spotless"
+weight = 59
+chapter = true
++++
+
+Why do we need to format code? Simply put, it’s to make code easier to read,
understand, and modify.
+
+As a Top-Level Apache open source project,
[ShardingSphere](https://shardingsphere.apache.org/) has 400 contributors as of
today. Since most developers do not have the same coding style, it is not easy
to standardize the project’s overall code format in a GitHub open collaboration
model. To solve this issue, ShardingSphere uses
[Spotless](https://github.com/diffplug/spotless/tree/main/plugin-maven) to
unify code formatting.
+
+## What is Spotless?
+Spotless is a multi-lingual code formatting tool that supports
[Maven](https://maven.apache.org/) and [Gradle](https://gradle.org/) building
with plugin.
+
+Devs can use Spotless in two ways: reviewing code for format-related issues,
and formatting code.
+
+> The ShardingSphere community uses Maven to build its projects — and Spotless
uses Maven for its demos.
+
+## How to use it?
+Let’s check the official demo below:
+
+```
+user@machine repo % mvn spotless:check
+[ERROR] > The following files had format violations:
+[ERROR] src\main\java\com\diffplug\gradle\spotless\FormatExtension.java
+[ERROR] -\t\t····if·(targets.length·==·0)·{
+[ERROR] +\t\tif·(targets.length·==·0)·{
+[ERROR] Run 'mvn spotless:apply' to fix these violations.
+user@machine repo % mvn spotless:apply
+[INFO] BUILD SUCCESS
+user@machine repo % mvn spotless:check
+[INFO] BUILD SUCCESS
+```
+When you check the project code with `mvn spotless:check`,an error occurs,
then you format the code with `mvn spotless:apply`. And once you check it
again, the formatting error has magically disappeared.
+
+**1. Preparing your environment**
+ShardingSphere uses Spotless to adding Java file `licenseHeader` and
formatting Java code.
+
+Spotless has several Java code formatting methods, such as:
`googleJavaFormat`, `eclipse`, `prettier` etc.
+
+For customization reasons, we chose `eclipse` for Java code formatting.
+
+
+
+```
+**a) Add `licenseHeader` according to project requirements**
+
+/*
+* Licensed to the Apache Software Foundation (ASF) under one or more
+* contributor license agreements. See the NOTICE file distributed with
+* this work for additional information regarding copyright ownership.
+* The ASF licenses this file to You under the Apache License, Version 2.0
+* (the "License"); you may not use this file except in compliance with
+* the License. You may obtain a copy of the License at
+*
+* http://www.apache.org/licenses/LICENSE-2.0
+*
+* Unless required by applicable law or agreed to in writing, software
+* distributed under the License is distributed on an "AS IS" BASIS,
+* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+* See the License for the specific language governing permissions and
+* limitations under the License.
+*/
+```
+Note: remember to include a space at the end of the `licenseHeader`. Otherwise
there will be no space between the `licenseHeader` and the package.
+
+**b) Add `shardingsphereeclipseformatter.xml`**
+
+```xml
+?xml version="1.0" encoding="UTF-8" standalone="no"?>
+<profiles version="13">
+ <profile kind="CodeFormatterProfile" name="'ShardingSphere Apache
Current'" version="13">
+ <setting id="org.eclipse.jdt.core.compiler.source" value="1.8"/>
+ <setting id="org.eclipse.jdt.core.compiler.compliance" value="1.8"/>
+ <setting id="org.eclipse.jdt.core.compiler.codegen.targetPlatform"
value="1.8"/>
+ <setting id="org.eclipse.jdt.core.formatter.indent_empty_lines"
value="true"/>
+ <setting id="org.eclipse.jdt.core.formatter.tabulation.size"
value="4"/>
+ <setting id="org.eclipse.jdt.core.formatter.lineSplit" value="200"/>
+ <setting id="org.eclipse.jdt.core.formatter.comment.line_length"
value="200"/>
+ <setting id="org.eclipse.jdt.core.formatter.tabulation.char"
value="space"/>
+ <setting id="org.eclipse.jdt.core.formatter.indentation.size"
value="1"/>
+ <setting
id="org.eclipse.jdt.core.formatter.comment.format_javadoc_comments"
value="false"/>
+ <setting id="org.eclipse.jdt.core.formatter.join_wrapped_lines"
value="false"/>
+ <setting
id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_conditional"
value="insert"/>
+ <setting
id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_default"
value="do not insert"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_enum_constants" value="16"/>
+ <setting
id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_labeled_statement"
value="do not insert"/>
+ <setting
id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_case" value="do
not insert"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_conditional_expression"
value="80"/>
+ <setting id="org.eclipse.jdt.core.formatter.alignment_for_assignment"
value="16"/>
+ <setting id="org.eclipse.jdt.core.formatter.blank_lines_after_package"
value="1"/>
+ <setting
id="org.eclipse.jdt.core.formatter.continuation_indentation_for_array_initializer"
value="2"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_resources_in_try" value="160"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_throws_clause_in_method_declaration"
value="10"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_parameters_in_method_declaration"
value="106"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_parameters_in_constructor_declaration"
value="106"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_throws_clause_in_constructor_declaration"
value="106"/>
+ <setting
id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_explicit_constructor_call.count_dependent"
value="16|5|80"/>
+ </profile>
+</profiles>
+```
+For latest rules of ShardingSphere, see
`[shardingsphereeclipseformatter.xml](https://github.com/apache/shardingsphere/blob/master/src/resources/shardingsphere_eclipse_formatter.xml)`.
For references, check the
`[eclipse-java-google-style.xml](https://github.com/google/styleguide/blob/gh-pages/eclipse-java-google-style.xml)`
file.
+
+The content of `shardingsphereeclipseformatter.xml` is tailor-made in
accordance with the ShardingSphere code specification and can be changed
flexibly.
+
+**c) Add Maven plugin**
+
+```xml
+<plugin>
+ <groupId>com.diffplug.spotless</groupId>
+ <artifactId>spotless-maven-plugin</artifactId>
+ <version>2.22.1</version>
+ <configuration>
+ <java>
+ <eclipse>
+
<file>${maven.multiModuleProjectDirectory}/src/resources/shardingsphere_eclipse_formatter.xml</file>
+ </eclipse>
+ <licenseHeader>
+
<file>${maven.multiModuleProjectDirectory}/src/resources/license-header</file>
+ </licenseHeader>
+ </java>
+ </configuration>
+</plugin>
+```
+
+Spotless supports specified formatting directories and the exclusion of
specified directories. For further information, see `plugin-maven#java`. If not
specified, when check or apply is executed, all of the project code will be
affected by default.
+
+**d) Execute code formatting**
+
+After performing the above three steps, you can execute commands in your
project to check the Java code for compliance with the specification, as well
as the code formatting features.
+
+```
+user@machine repo % mvn spotless:apply
+[INFO] BUILD SUCCESS
+user@machine repo % mvn spotless:check
+[INFO] BUILD SUCCESS
+```
+
+## 2. Binding the Maven Life Cycle
+In the actual ShardingSphere application, you can opt to bind Spotless apply
to the compile phase so that it is automatically formatted when mvn install is
executed locally.
+
+```xml
+<plugin>
+ <groupId>com.diffplug.spotless</groupId>
+ <artifactId>spotless-maven-plugin</artifactId>
+ <version>2.22.1</version>
+ <configuration>
+ <java>
+ <eclipse>
+
<file>${maven.multiModuleProjectDirectory}/src/resources/shardingsphere_eclipse_formatter.xml</file>
+ </eclipse>
+ <licenseHeader>
+
<file>${maven.multiModuleProjectDirectory}/src/resources/license-header</file>
+ </licenseHeader>
+ </java>
+ </configuration>
+ <executions>
+ <execution>
+ <goals>
+ <goal>apply</goal>
+ </goals>
+ <phase>compile</phase>
+ </execution>
+ </executions>
+</plugin>
+
+```
+
+## 3. IDEA formatting
+If you want to check a single file for compliance when writing code, executing
`mvn spotless:check` or `mvn spotless:apply` will be a bit unwieldy, as by
default the formatting scope is the entire project.
+
+IntelliJ IDEA’s native formatting functionality can be replaced by
shardingsphereeclipseformatter.xml.
+
+This way, you can format your code at any time during the writing process,
improving efficiency significantly.
+
+IDEA Version: 2019.3.4
+
+**a) Install the plugin Eclipse Code Formatter
+**
+
+
+**b) Select shardingsphereeclipseformatter.xml as the default formatting
template**
+
+
+
+Spotless code formatting can be done using IDEA code formatting shortcuts.
+
+## FAQ
+**1. Conflicts between Spotless and Checkstyle**
+[Checkstyle](https://github.com/checkstyle/checkstyle) is a tool for checking
Java source code for compliance with code standards or a set of validation
rules (best practices).
+
+In extreme circumstances, Spotless formatted code cannot pass Checkstyle
checking.
+
+The underlying cause is a conflict between the checking mechanism and
formatting configurations set by both. For example, Spotless formats a newline
with a 16-space indent, while Checkstyle checks for a 12-space newline.
+
+```java
+private static Collection<PreciseHintShadowValue<Comparable<?>>>
createNoteShadowValues(final ShadowDetermineCondition shadowDetermineCondition)
{
+ // format that can pass Checkstyle
+ return
shadowDetermineCondition.getSqlComments().stream().<PreciseHintShadowValue<Comparable<?>>>map(
+ each -> new PreciseHintShadowValue<>(tableName, shadowOperationType,
each)).collect(Collectors.toList());
+ // After being formatted by Spotless
+ return
shadowDetermineCondition.getSqlComments().stream().<PreciseHintShadowValue<Comparable<?>>>map(
+ each -> new PreciseHintShadowValue<>(tableName,
shadowOperationType, each)).collect(Collectors.toList());
+}
+```
+This case requires devs to weigh the trade-offs. There are two solutions:
modify Spotless’ formatting rules, or modify Checkstyle’s checking rules.
+
+**2. Formatting conflict between CRLF & LF**
+
+See
[https://github.com/diffplug/spotless/issues/1171](https://github.com/diffplug/spotless/issues/1171)
+
+## Summary
+Apache ShardingSphere uses Spotless to format legacy code, and the subsequent
standardization of code formatting, which helps keeping the project’s code tidy.
+
+Of course, Spotless is not limited to Java code formatting, but also includes
the formatting of file types such as `Pom` and `Markdown`, which will soon be
applied in ShardingSphere.
+
+## Author
+**Longtai**
+
+[Github ID](https://github.com/longtai-cn): longtai-cn
+
+[Apache ShardingSphere](https://shardingsphere.apache.org/) Contributor;
hippo4j author (2.2K GitHub stars).
diff --git
a/docs/blog/content/material/2022_06_10_Apache_ShardingSphere_Enterprise_Applications_Bilibili.en.md
b/docs/blog/content/material/2022_06_10_Apache_ShardingSphere_Enterprise_Applications_Bilibili.en.md
new file mode 100644
index 00000000000..1660cf44a61
--- /dev/null
+++
b/docs/blog/content/material/2022_06_10_Apache_ShardingSphere_Enterprise_Applications_Bilibili.en.md
@@ -0,0 +1,93 @@
++++
+title = "Apache ShardingSphere Enterprise Applications — Bilibili"
+weight = 60
+chapter = true
++++
+
+> To further understand application scenarios, and enterprises’ needs, and
improve dev teams’ understanding of Apache ShardingSphere, our community
launched the “Enterprise Visits”
+> series.
+
+
+[Apache ShardingSphere](https://shardingsphere.apache.org/)’s core contributor
team was invited to the headquarters of [Bilibili](https://www.bilibili.com/)
in Shanghai. Our PMC Chair, Zhang Liang, discussed with Bilibili’s tech team
the e-commerce and digital entertainment verticals application scenarios, and
the capabilities of different versions of ShardingSphere.
+
+With the unprecedented growth of data volume and increasingly diversified data
application scenarios, different platforms, businesses, and scenarios have
resulted in database applications’ fragmentation. The challenges facing
databases today are totally different from the ones they were conceived to
solve. This is also reflected in the growth of Bilibili’s e-commerce business.
+
+For over a decade, Bilibili has built an ecosystem community centered on
users, creators, and content, while producing high-quality videos as well. With
an increasing number of users, Bilibili has also gradually developed peripheral
business ecosystems such as its subscription revenue model. The expansion of
business lines and application scenarios brought great challenges for
Bilibili’s tech team, especially in the management and application of backend
data.
+
+During the visit, our community and Bilibili mainly discussed these three
points:
+
+## The SQL warm-up feature jointly built with Bilibili:
+When Bilibili queries goods and orders with batch priority in its business, it
is often necessary to manually warm-up SQL during the initial linking process
to improve overall performance. However, in the process of manual warm-up,
parameters of different lengths cannot be used as a SQL to warm-up due to the
use of `foreach` syntax of the
[Mybatis](https://mybatis.org/mybatis-3/index.html) framework.
+
+Apache ShardingSphere can see the SQL execution plan through the `preview`,
thus warming up the SQL. In the future, we plan to provide a separate SQL
warm-up interface and merge the SQL warm-up time into the startup time.
ShardingSphere will start on its own after SQL is warmed up.
+
+[Apache ShardingSphere](https://shardingsphere.apache.org/) is an open-source
project driven by the needs of the community. Currently, many capabilities’
development is driven by specific user requirements, which are fed back to the
community after development and gradually integrated into Apache ShardingSphere.
+
+Therefore, the ShardingSphere community invited Bilibili’s tech team to get
involved in terms of the SQL warm-up feature.
+
+With the expansion of Apache ShardingSphere’s application scenarios, there is
a higher expectation for ShardingSphere’s capabilities to adapt to a variety of
special business scenarios. In the previous “Enterprise Visits” series, the
ShardingSphere community recognized that even though it has more than 100
feature modules, enterprises from various verticals have different expectations
from ShardingSphere.
+
+## Bilibili’s circuit breaker automation in traffic spike scenarios:
+
+With the growth of Bilibili’s e-commerce scale, as is often the case with many
e-commerce businesses, started to adopt front-end strategies such as cash
rebates and flash deals in order to improve user retention.
+
+On the backend, however, when the rebate performance of the warehouse is equal
to the number of concurrent transactions while exceeding its own connection
number limit, it can only be stopped through manual disconnection via DBA based
on the number of SKU at the business level. Manual intervention is inefficient
and consumes DBAs’ energy, so
[ShardingSphere-Proxy](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/)
is expected to provide a [...]
+
+However, the flash deal scenario is too demanding, so
[Redis](https://redis.io/) still represents a better choice. Achieving
automation simply requires setting rules and thresholds.
+
+Sinking data to Proxy can also achieve the capabilities of Redis, but no
matter how the upper layer changes, the bottom of the database will not change.
Therefore, it is better for DBAs to take the initiative to operate the circuit
breaker mechanism. Otherwise, after setting a threshold, if the connection
between the application and the database has a slight timeout, a large number
of transactions will be cut off instantly, which can easily cause a business
outage.
+
+Currently, a better way is to dig out all kinds of key information and display
it on the visual interface based on Proxy, to facilitate the real-time
comparison and operation of DBA instead of achieving automation.
+
+## The Apache ShardingSphere registry:
+In the Apache ShardingSphere architecture, the registry provides distributed
governance capabilities and is fully open to users since its computing node
([Shardingsphere-proxy](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/))
is stateless without data storage capability. Therefore, user accounts and
authorization information need to be stored in the registry.
+
+Concurrently, with the help of the registry, Apache ShardingSphere can
distribute information to multiple computing nodes in the cluster in real-time,
greatly reducing maintenance costs for users when using the cluster and
improving management efficiency.
+
+In cluster mode, Apache ShardingSphere integrates third-party registry
components [ZooKeeper](https://zookeeper.apache.org/) and
[Etcd](https://etcd.io/) to achieve metadata and configuration sharing in the
cluster environment. At the same time, with the help of the notification and
coordination ability of the registry, it ensures the real-time synchronization
of the cluster when the shared data changes. And the business will not be aware
of changes from the registry.
+
+## Q&A with Bilibili
+**Q: Is there a performance loss when using JDBC to connect to the governance
center?**
+
+A: No. It only connects to the governance center during initialization, and
the governance center will send a push when there is a change.
+
+**Q: How does [Sysbench](https://wiki.gentoo.org/wiki/Sysbench) conduct a
stress test on Apache ShardingSphere?**
+
+A: The two deployment types of Apache ShardingSphere, JDBC and Proxy, are both
tested by Sysbench. ShardingSphere has a newly designed Sysbench-like Java
program on the JDBC end that can be used to conduct a pressure test to JDBC and
Proxy. It can also ensure that the official Sysbench and our Java program share
the same standard.
+
+**Q: Can ShardingSphere converge the connection number?**
+
+A: ShardingSphere-Proxy can converge the connection number, but it will
definitely lead to performance loss.
+
+**Q: Can Proxy identify slow SQL?**
+
+A: Currently, the open-source version doesn’t support this function, because
most users of the open-source version are Internet enterprises with a low
tolerance for performance loss. Thus, the number of probes is relatively small.
+
+**Q: Does [ElasticJob](https://shardingsphere.apache.org/elasticjob/) belong
to Apache ShardingSphere?**
+
+A: ElasticJob is currently used as the migration tool by Apache
ShardingSphere. Additionally, ElasticJob can also be used for liveness probes.
+
+**Q: Are Internet enterprises using Proxy on a large scale?**
+
+A: Most Internet users choose the mixed deployment model, using JDBC for
development and better performance, and Proxy for management. Financial
customers prefer to use Proxy because they can take Proxy as a database for
unified management without additional learning costs.
+
+**Q: We are currently using ShardingSphere version 4.1.1, what does it support
for transactions?**
+
+A: Both versions 4.11 and 5.1.0 support
[XA](https://docs.oracle.com/database/121/TTCDV/xa_dtp.htm#TTCDV327)
distributed transaction management. We plan to develop the global transaction
manager
([GTM](https://docs.oracle.com/cd/E17276_01/html/programmer_reference/xa_build.html))
which is scheduled to start in the second half of this year.
+
+## Get in touch with us
+If you have applied Apache ShardingSphere solutions in your business or if you
want to quickly understand and introduce the Apache ShardingSphere 5.X
ecosystem to your business, you’ll probably like for someone from our community
to help you out and share the Apache ShardingSphere technology with your team.
+
+Feel free to reach out to us on one of our official community channels, such
as Twitter or Slack.
+
+If we both agree that ShardingSphere is suitable for your business scenarios,
our community team will be happy to connect with you and your engineers to take
their questions.
+
+**Apache ShardingSphere Project Links:**
+
+[ShardingSphere
Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere
Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
diff --git
"a/docs/blog/content/material/2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it\342\200\231s_simpler_than_Dubbo\342\200\231s.en.md"
"b/docs/blog/content/material/2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it\342\200\231s_simpler_than_Dubbo\342\200\231s.en.md"
new file mode 100644
index 00000000000..3354bc44f22
--- /dev/null
+++
"b/docs/blog/content/material/2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it\342\200\231s_simpler_than_Dubbo\342\200\231s.en.md"
@@ -0,0 +1,270 @@
++++
+title = "Understanding Apache ShardingSphere's SPI, and why it’s simpler than
Dubbo’s"
+weight = 61
+chapter = true
++++
+
+
+
+
+## Why learn [ShardingSphere](https://shardingsphere.apache.org/)’s SPI?
+You might already be familiar with [Java](https://www.java.com/en/) and
[Dubbo](https://dubbo.apache.org/en/)’s SPI ([Service Provider
Interface](https://en.wikipedia.org/wiki/Service_provider_interface))
mechanism, so you may wonder “why would I learn about
[ShardingSphere](https://shardingsphere.apache.org/)’s SPI mechanism?” The
reasons are quite simple:
+
+1. ShardingSphere’s source code is simpler and easier to adapt.
+2. The execution of ShardingSphere’s SPI mechanism is quite smooth, with less
code required for day-to-day operations. Unlike Dubbo’s SPI mechanism and its
additional features related to
[IoC](https://medium.com/@amitkma/understanding-inversion-of-control-ioc-principle-163b1dc97454),
the one in ShardingSphere only preserves the fundamental structure, making it
effortless to use.
+
+## Understanding ShardingSphere’s SPI
+We also have to mention some shortcomings found in the [Java
SPI](https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html) mechanism:
+
+1. Instances of the
[ServiceLoader](https://docs.oracle.com/javase/8/docs/api/java/util/ServiceLoader.html)
class with multiple concurrent threads are not safe to use.
+2. Each time you get an element, you need to iterate through all the elements,
and you can’t load them on demand.
+3. When the implementation class fails to load, an exception is prompted
without indicating the real reason, making the error difficult to locate.
+4. The way to get an implementation class is not flexible enough. It can only
be obtained through the
[Iterator](https://docs.oracle.com/javase/8/docs/api/java/util/Iterator.html)
form, not based on one parameter to get the corresponding implementation class.
+
+In light of this, let’s see how
[ShardingSphere](https://shardingsphere.apache.org/) solves these problems in a
simple way.
+
+## Loading SPI class
+Dubbo is a direct rewrite of its own SPI, including the SPI file name and the
way the file is configured, in stark contrast to
[JDK](https://www.oracle.com/java/technologies/downloads/). Let’s briefly
compare the differences between the uses of these two:
+
+**Java SPI**
+
+Add interface implementation class under the folder `META-INF/services`
+
+```
+optimusPrime = org.apache.spi.OptimusPrime
+bumblebee = org.apache.spi.Bumblebee
+```
+
+**Dubbo SPI**
+
+Add the implementation class of the interface to the folder
`META-INF/services`, configure by means of `key`, `value` like the following
example:
+
+```
+optimusPrime = org.apache.spi.OptimusPrime
+bumblebee = org.apache.spi.Bumblebee
+```
+
+We can see now that Dubbo’s Java SPI is completely different from the JDK SPI.
+
+## How does ShardingSphere easily extend the JDK SPI?
+
+Unlike the Dubbo implementation concept, ShardingSphere extends the JDK SPI
with less code.
+
+1. The configuration is exactly the same as in the Java SPI.
+Let’s take the `DialectTableMetaDataLoader` interface implementation class as
an example:
+
+`DialectTableMetaDataLoader.class`
+
+```java
+public interface DialectTableMetaDataLoader extends StatelessTypedSPI {
+ /**
+ * Load table meta data.
+ *
+ * @param dataSource data source
+ * @param tables tables
+ * @return table meta data map
+ * @throws SQLException SQL exception
+ */
+ Map<String, TableMetaData> load(DataSource dataSource, Collection<String>
tables) throws SQLException;
+}
+public interface TypedSPI {
+ /**
+ * Get type.
+ *
+ * @return type
+ */
+ String getType();
+ /**
+ * Get type aliases.
+ *
+ * @return type aliases
+ */
+ default Collection<String> getTypeAliases() {
+ return Collections.emptyList();
+ }
+}
+```
+`StatelessTypedSPI` interface takes it from `TypedSPI` and multiple interfaces
are used to meet the principle of single interface responsibility. `TypedSPI`
is the key of the `Map` where subclasses need to specify their own SPI.
+
+Here you don’t need to care about what methods are defined by the
`DialectTableMetaDataLoader` interface, you just have to focus on how the
subclasses are loaded by SPI. If it is a Java SPI, to load the subclasses, you
just define it by the full class name in `META-INF/services`.
+
+
+
+As you can see, it is exactly the same as the native java SPI configuration.
So how about its shortcomings?
+
+## Using the Factory Method Pattern
+For every interface that needs to be extended and created by SPI, there
usually is a similar `xxDataLoaderFactory` for creating and acquiring the
specified SPI extension class.
+
+`DialectTableMetaDataLoaderFactory`
+
+```java
+@NoArgsConstructor(access = AccessLevel.PRIVATE)
+public final class DialectTableMetaDataLoaderFactory {
+ static {
+ ShardingSphereServiceLoader.register(DialectTableMetaDataLoader.class);
+ }
+ /**
+ * Create new instance of dialect table meta data loader.
+ *
+ * @param databaseType database type
+ * @return new instance of dialect table meta data loader
+ */
+ public static Optional<DialectTableMetaDataLoader> newInstance(final
DatabaseType databaseType) {
+ return
TypedSPIRegistry.findRegisteredService(DialectTableMetaDataLoader.class,
databaseType.getName());
+ }
+}
+```
+Here you can see that a static block is used, and all the
`DialectTableMetaDataLoader` implementation classes are registered through
`ShardingSphereServiceLoader.register` while class loading is in process. By
using `TypedSPIRegistry.findRegisteredService`, we can get our specified spi
extension class.
+
+```
+TypedSPIRegistry.findRegisteredService(final Class<T> spiClass, final String
type)
+```
+So we just have to pay attention to `ShardingSphereServiceLoader.register` and
`ypedSPIRegistry.findRegisteredService` approaches.
+
+**`ShardingSphereServiceLoader`**
+
+```java
+@NoArgsConstructor(access =AccessLevel.PRIVATE)
+public final class ShardingSphereServiceLoader {
+ private static final Map<Class<?>, Collection<object>> SERVICES = new
ConcurrentHashMap<>();
+ /**
+ *Register service.
+ *
+ *@param serviceInterface service interface
+ */
+ public static void register(final Class<?> serviceInterface){
+ if (!SERVICES.containsKey(serviceInterface)) {
+ SERVICES.put(serviceInterface, load(serviceInterface) ) ;
+ }
+ }
+
+ private static <T> Collection<Object> load(final Class<T>
serviceInterface) {
+ Collection<Object> result = new LinkedList<>();
+ for (T each: ServiceLoader. load(serviceInterface)) {
+ result.add(each);
+ }
+ return result;
+ }
+
+ /**
+ *Get singleton service instances.
+ *
+ *@param service service class
+ * @param <T> type of service
+ *@return service instances
+ */
+ @SuppressWarnings("unchecked")
+ public static <T> Collection<T> getSingletonServiceInstances(final
Class<T> service) {
+ return (Collection<T>)
SERVICES.getorDefault(service,Collections.emptyList());
+ }
+
+ /**
+ *New service instances.
+ *
+ * eparam service service class
+ *@param <T> type of service
+ *@return service instances
+ */
+ @SuppressWarnings ("unchecked" )
+ public static <T> Collection<T> newserviceInstances(final Class<T>
service){
+ if(!SERVICES.containskey(service)) {
+ return Collections.emptyList();
+ }
+ Collection<object> services = SERVICES.get(service);
+ if (services.isEmpty()){
+ return Collections.emptyList();
+ }
+ Collection<T> result = new ArrayList<>(services.size());
+ for (Object each: services) {
+ result.add((T) newServiceInstance(each.getClass()));
+ }
+ return result;
+ }
+
+ private static Object newServiceInstance(final Class<?> clazz) {
+ try{
+ return clazz.getDeclaredConstructor( ) . newInstance( ) ;
+ } catch (final ReflectiveOperationException ex) {
+ throw new ServiceLoaderInstantiationException(clazz, ex);
+ }
+ }
+}
+```
+We can see that all SPI classes are placed in this `SERVICES`property.
+
+```java
+private static final Map<Class<?>, Collection<Object>> SERVICES = new
ConcurrentHashMap<>();
+```
+
+
+And registering is pretty simple too, just use the SPI api embedded in java.
+
+```java
+public static void register(final Class<?> serviceInterface) {
+ if (!SERVICES.containsKey(serviceInterface)) {
+ SERVICES.put(serviceInterface, load(serviceInterface));
+ }
+ }
+private static <T> Collection<Object> load(final Class<T> serviceInterface) {
+ Collection<Object> result = new LinkedList<>();
+ for (T each : ServiceLoader.load(serviceInterface)) {
+ result.add(each);
+ }
+ return result;
+ }
+```
+**`TypedSPIRegistry`**
+
+The `findRegisteredService` method in `TypedSPIRegistry` is essentially a call
to the `getSingletonServiceInstancesmethod` of the
`ShardingSphereServiceLoader`.
+
+```java
+public static <T extends StatelessTypedSPI> Optional<T>
findRegisteredService(final Class<T> spiClass, final String type) {
+ for (T each :
ShardingSphereServiceLoader.getSingletonServiceInstances(spiClass)) {
+ if (matchesType(type, each)) {
+ return Optional.of(each);
+ }
+ }
+ return Optional.empty();
+ }
+private static boolean matchesType(final String type, final TypedSPI typedSPI)
{
+ return typedSPI.getType().equalsIgnoreCase(type) ||
typedSPI.getTypeAliases().contains(type);
+ }
+```
+Here you can see that the class extension is using `getType` or
`getTypeAliases` in `TypedSPI` to get a match, which is why each SPI needs to
implement the `TypedSPI` interface.
+
+Now let’s see the `newServiceInstances` method in `ShardingSphereServiceLoader`
+
+```java
+public static <T> Collection<T> newServiceInstances(final Class<T> service) {
+ if (!SERVICES.containsKey(service)) {
+ return Collections.emptyList();
+ }
+ Collection<Object> services = SERVICES.get(service);
+ if (services.isEmpty()) {
+ return Collections.emptyList();
+ }
+ Collection<T> result = new ArrayList<>(services.size());
+ for (Object each : services) {
+ result.add((T) newServiceInstance(each.getClass()));
+ }
+ return result;
+ }
+```
+You can see that it is also very simple to find all implementations class
returns of the interface directly in `SERVICES` registered through the static
code block.
+
+Although short, this short walkthrough basically introduced ShardingSphere’s
SPI source code. We’re sure that you have already noticed it’s much easier and
simpler to work with ShardingSphere’s SPI than Dubbo's SPI mechanism.
+
+## Summary
+Both ShardingSphere and Dubbo’s SPIs meet the requirement of finding the
specified implementation class by key, without having to reload all the
implementation classes every time you use it, solving the concurrent loading
problem. However, compared to Dubbo, the ShardingSphere SPI is more streamlined
and easier to use.
+
+You can refer to the ShardingSphere implementation later on when writing your
own SPI extensions, as it is simpler to implement, and elegant to work with.
You can write an expandable configuration file parser based on SPI so that we
can understand what SPI is capable of as well as its application scenarios.
+
+**Apache ShardingSphere Project Links:**
+
+[ShardingSphere
Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere
Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
diff --git
"a/docs/blog/content/material/2022_06_21_Heterogeneous_migration_reducing_Dangdang\342\200\231s_customer_system_RTO_60x_and_increasing_speed_by_20%.en.md"
"b/docs/blog/content/material/2022_06_21_Heterogeneous_migration_reducing_Dangdang\342\200\231s_customer_system_RTO_60x_and_increasing_speed_by_20%.en.md"
new file mode 100644
index 00000000000..07ca575f588
--- /dev/null
+++
"b/docs/blog/content/material/2022_06_21_Heterogeneous_migration_reducing_Dangdang\342\200\231s_customer_system_RTO_60x_and_increasing_speed_by_20%.en.md"
@@ -0,0 +1,130 @@
++++
+title = "Heterogeneous migration: reducing Dangdang’s customer system RTO 60x
and increasing speed by 20%"
+weight = 62
+chapter = true
++++
+
+> [Apache ShardingSphere](https://shardingsphere.apache.org/) helps
[Dangdang](https://www.crunchbase.com/organization/dangdang-com) rebuild its
customer system with 350 million users, and seamlessly transition from a
[PHP](https://www.php.net/)+[SQL
Server](https://www.microsoft.com/en-us/sql-server/sql-server-downloads)
technology stack to a Java+ShardingSphere+[MySQL](https://www.mysql.com/)
stack. The performance, availability, and maintainability of its customer
system have been sig [...]
+
+## Dangdang’s customer system
+Dangdang’s customer system is mainly responsible for account registration,
login, and privacy data maintenance. Its previous technology stack was based on
PHP and SQL Server, which means a standard centralized architecture, as shown
in the figure below.
+
+
+
+Before the rebuild project started, several business modules of the customer
system had encountered multiple problems and technical challenges, such as
logical decentralization, low throughput, and high operation & maintenance
costs.
+
+To improve customers’ shopping experience, Dangdang’s technical team decided
to optimize the business logic and underlying data architecture to achieve the
availability, scalability, and comprehensive improvement of the customer system
in multiple scenarios. The rebuild also introduced many technological
innovations such as cross-data source double write, read/write splitting,
intelligent gateway, and gray release.
+
+Dangdang’s technical team completed the system rebuild within half a year,
from demand design, sharding planning, logic optimization, and stress testing
to its official launch.
+
+The project used Java to reconstruct more than ten modules, build distributed
database solutions through ShardingSphere & MySQL, and finally complete the
online migration of heterogeneous databases. The project boasts the following
highlights:
+
+- Reconstruct PHP business code using Java language.
+- Replace SQL Server with ShardingSphere & MySQL.
+- Complete online data migration of 350 million users.
+- Complete a seamless launch through the data double-write scheme.
+
+## Pain points & challenges
+
+**Business pain points**
+At the business level, the registration and login logic of some modules of the
customer system was scattered at different ends. This resulted in high
maintenance costs, and the old technical architecture was limited in terms of
performance improvement and high availability.
+
+- **Maintenance difficulty:** the registration and login logic of multiple
platforms is scattered, so business maintenance is complicated.
+- **Limited performance:** the PHP & SQL Server, a centralized technical
architecture, had insufficient throughput.
+- **Poor availability and security:** If the active/standby status of SQL
Server changes, the subscription database becomes invalid and the
reconfiguration takes a window of time. The security of SQL Server running on
Windows Server is poor due to viruses, and the upgrading takes a long time
(>30min) after the patch is installed.
+
+**Challenges**
+
+- **Data integrity:** the customer system involves data of more than 350
million users. It is necessary to ensure data consistency and integrity after
migrating from SQL Server to MySQL.
+- **API transparency:** the API is transparent to the caller to ensure that
the caller does not change and to minimize the change of interface.
+- **Seamless switch:** the business system must be seamlessly switched over
without impact on business.
+- **Time is short:** the system will be blocked before and after “[618 (aka
JD.com
Day)](https://edition.cnn.com/2020/06/18/tech/jd-618-china-coronavirus-intl-hnk/index.html)
and [11.11 (aka Singles Day)](https://en.wikipedia.org/wiki/Singles%27_Day)”
(two online shopping festivals in China), so we need to switch it between the
two shopping promotions in a limited window of time, and then undergo the tests
to prepare for the 11.11 shopping festival.
+
+## Solutions
+**Overall planning**
+To improve the maintainability, availability, and performance of the customer
system, the R&D team reorganized the customer system architecture.
+
+At the application layer, the goal was to unify the function logic of all
terminals and improve business maintainability.
+
+At the database layer, the centralized architecture was transformed into a
distributed database architecture to improve performance and availability,
which is exactly the open-source distributed solution built by ShardingSphere &
MySQL.
+
+- **Application layer:** As Dangdang’s overall technology stack changed, its
business development language changed from PHP to Java.
+- **Middleware:** As a mature open-source database middleware, ShardingSphere,
was used to achieve data sharding.
+- **Database:** Multiple MySQL clusters were used to replace SQL Server
databases.
+
+
+The overall architecture design introduced multiple schemes, such as
distributed primary-key generation strategy, shard management, data migration
verification, and gray release.
+
+## Distributed primary-key generation strategy
+
+Distributed primary-key generation strategy is the first problem to be solved
if database architecture is to be transformed from a centralized architecture
to a distributed one based on middleware.
+
+During the system rebuild, we chose to build two or more database
ID-generating servers. Each server had a `Sequence` table that records the
current `ID` of each table. The step size of `ID` that increases in the
`Sequence` table is the number of servers. The starting values are staggered so
that the ID generation is hashed to each server node.
+
+## Implementing sharding (Apache ShardingSphere)
+During the customer system rebuild, database sharding was completed through
Apache ShardingSphere, and the read/write splitting function was also enabled.
+
+Due to the requirements of the customer system for high concurrency and low
latency, the access end chose
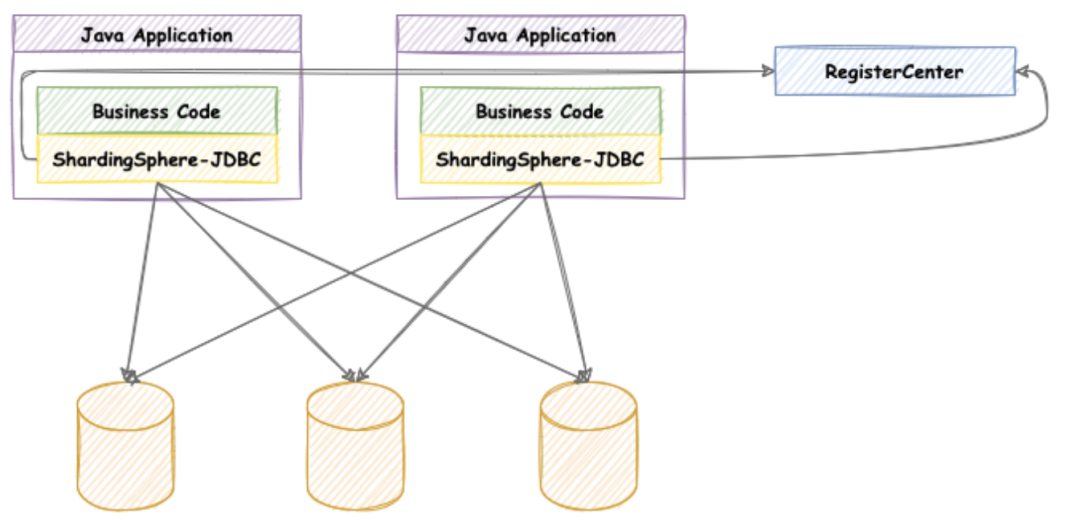
[ShardingSphere-JDBC](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-jdbc),
which is positioned as a lightweight Java framework and provides additional
services in Java’s JDBC layer.
+
+It connects directly to the database via the client and provides services in
the form of a `jar` package without additional deployment and dependence. It
can be viewed as an enhanced version of the JDBC driver, fully compatible with
JDBC and various
[ORM](https://www.techopedia.com/definition/24200/object-relational-mapping--orm)
frameworks.
+
+
+
+**Sharding:** ShardingSphere supports a complete set of sharding algorithms,
including `modulo` operation, `hash`, `range`, `time`, and customized
algorithms. Customers use the `modulo` sharding algorithm to split large tables.
+**Read-write splitting:** in addition to Sharding, ShardingSphere’s read/write
splitting function is also enabled to make full use of
[MHA](https://myheroacademia.fandom.com/wiki/Cluster) cluster resources and
improve system throughput capacity.
+
+
+
+## Double-write & data synchronization
+Data synchronization runs through the whole rebuild project, and the integrity
and consistency of data migration are vital to the rebuild.
+
+This example periodically synchronizes SQL Server’s historical data to MySQL
based on Elastic-Job synchronization. During the database switchover, a backup
scheme is used to double-write the database to ensure data consistency. The
process consists of:
+
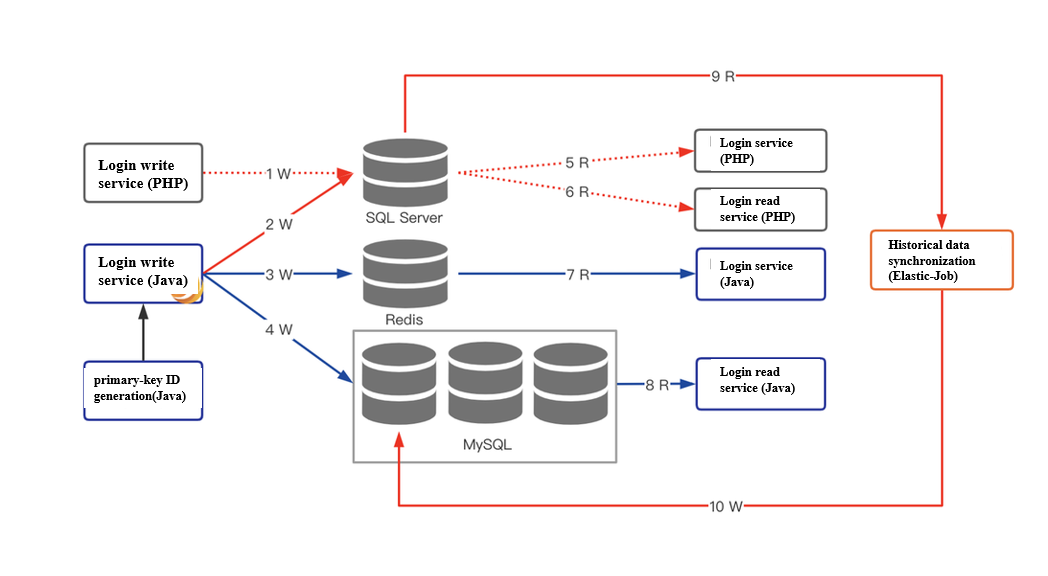
+**Step 1:** implement the double-write mechanism
+
+Disconnect link 1, get through links 2, 3, 4, and then 9, 10.
+
+**Step 2:** switch the login service
+
+Disconnect links 9,10, get through link 7 and disconnect link 5.
+
+**Step 3:** switch read service
+
+Get through link 8 and disconnect link 6.
+
+**Step 4:** cancel the double-write mechanism
+
+Disconnect link 2 and complete the switchover.
+
+
+
+Data verification is performed periodically on both the service side and the
database side. Different frequencies are used in different time periods to
sample or fully check data integrity. `COUNT/SUM` is also verified on the
database side.
+
+Customer system reconstruction adopts an apollo-based gray release. In the
process of new login processing, configuration items are gradually released and
sequential cutover within a small range is implemented to ensure the launch
success rate. The rebuilt system architecture is shown in the following figure.
+
+
+
+## Advantages
+After the rebuild, the response speed of Dangdang’s customer system is
significantly improved, and the daily operation & maintenance costs are also
reduced.
+
+The distributed solution provided by ShardingSphere plays a big part in this.
The solution is suitable for various high-traffic Internet platform services,
as well as e-commerce platforms and other data-processing systems.
+
+- **Performance improvement:** response speed increased by more than 20%.
+- **High availability:** RTO is reduced to less than 30s owing to the
ShardingSphere & MySQL design.
+- **Easy to maintain:** business logic and database maintainability are
significantly improved.
+- **Seamless migration:** complete online cutover of each module within 6
months, and window time is zero.
+
+## Conclusion
+This is ShardingSphere’s second implementation by Dangdang, following the
previous one we shared in the post “[Asia’s E-Commerce Giant Dangdang Increases
Order Processing Speed by 30% — Saves Over Ten Million in Technology Budget
with Apache
ShardingSphere](https://shardingsphere.medium.com/asias-e-commerce-giant-dangdang-increases-order-processing-speed-by-30-saves-over-ten-million-113a976e0165)”.
+
+Apache ShardingSphere provides strong support for enterprise systems, as the
project strives for simplicity and perfection, to achieve simpler business
logic and maximum performance.
+
+**Apache ShardingSphere Project Links:**
+
+[ShardingSphere
Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere
Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
diff --git
a/docs/blog/content/material/2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new
API driver_Apache_ShardingSphere_5.1.2_is_released.en.md
b/docs/blog/content/material/2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new
API driver_Apache_ShardingSphere_5.1.2_is_released.en.md
new file mode 100644
index 00000000000..7aae790320b
--- /dev/null
+++
b/docs/blog/content/material/2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new
API driver_Apache_ShardingSphere_5.1.2_is_released.en.md
@@ -0,0 +1,407 @@
++++
+title = "Cloud native deployment for a high-performance data gateway + new API
driver: Apache ShardingSphere 5.1.2 is released"
+weight = 63
+chapter = true
++++
+
+Following the release of Apache ShardingSphere 5.1.1, our community integrated
1,028 PRs from contributors all over the world to bring you the latest 5.1.2
version. The new version includes a lot of improvements in terms of functions,
performance, tests, documentation, examples, etc.
+
+Standout new features include:
+
+- ShardingSphere-Proxy Helm Chart.
+- SQL dialect translation.
+- Using ShardingSphere-JDBC as a Driver.
+
+These new capabilities boosted ShardingSphere’s data gateway capability,
enabling ShardingSphere to be deployed on the cloud while optimizing user
experience.
+
+In addition to the above-mentioned new features, this update also improves SQL
parsing support, kernel, runtime mode, and elastic scaling support for
[PostgreSQL](https://www.postgresql.org/) /
[openGauss](https://opengauss.org/en/) schema, auto-scaling, transactions, and
[DistSQL](https://medium.com/nerd-for-tech/intro-to-distsql-an-open-source-more-powerful-sql-bada4099211)
in terms of user experience.
+
+This post will give you an overview of the ShardingSphere 5.1.2 updates.
+
+## New Features
+**ShardingSphere-Proxy configuration using Helm**
+ShardingSphere-Proxy provides Docker images for deployment in containers.
However, for those who need to deploy ShardingSphere-Proxy on
[Kubernetes](https://kubernetes.io/), you have to go through some procedures
such as database driver mounting, configuration mounting, custom algorithm
mounting, etc., which make the deployment process relatively tedious and causes
high operation & maintenance costs.
+
+This update brings the new ShardingSphere-Proxy Helm Chart, a new feature
donated to the Apache ShardingSphere community by
[SphereEx](https://www.sphere-ex.com/), a provider of enterprise-grade,
cloud-native data-enhanced computing products, and solutions. This development
allows Apache ShardingSphere to embrace ahead cloud-native computing.
+
+
+
+ShardingSphere relies on a registry to store metadata in cluster mode, and
ShardingSphere-Proxy’s Helm Chart can automatically deploy ZooKeeper clusters
allowing you to quickly build ShardingSphere-Proxy clusters.
+
+Due to the limits imposed by open source protocol, ShardingSphere-Proxy’s
binary distribution package and Docker image are not packaged with MySQL JDBC
driver, so users need to manually add the MySQL JDBC driver to the classpath to
use MySQL as ShardingSphere’s storage node.
+
+For such cases, ShardingSphere-Proxy Helm Chart can automatically obtain the
MySQL JDBC driver in the Pod’s Init container, reducing your deployment
operation costs.
+
+**SQL dialect translation**
+With increased database diversification, the coexistence of multiple types of
databases is now the norm. The scenarios in which heterogeneous databases are
accessed using one SQL dialect are becoming a trend.
+
+The existence of multiple diversified databases makes it difficult to
standardize SQL dialects for accessing databases, meaning that engineers need
to use different dialects for different types of databases - lacking a unified
query platform.
+
+Automatically translating different types of database dialects into one
dialect that can be used by back-end databases allows engineers to access all
back-end heterogeneous databases using any one database dialect, significantly
reducing development and maintenance costs.
+
+Apache ShardingSphere 5.1.2 is an important step to building a highly
productive data gateway. This update enables a new SQL dialect translation
capability that supports dialect conversion between major open source databases.
+
+For example, you can use a [MySQL](https://www.mysql.com/) client to connect
to ShardingSphere-Proxy and send SQL based on MySQL dialect, and ShardingSphere
can automatically recognize the user protocol and storage node type to complete
SQL dialect translation, accessing heterogeneous storage nodes such as
PostgreSQL and vice versa.
+
+
+
+## Using ShardingSphere-JDBC as Driver
+In past versions, ShardingSphere-JDBC was available for users in the form of
`Datasource`. Projects or tools that do not use `Datasource`, previously would
need to first be modified in order to be able to introduce ShardingSphere-JDBC,
which increases development costs.
+
+In Apache ShardingSphere 5.1.2, ShardingSphere-JDBC implements the
standardized JDBC Driver interface, which allows you to introduce
ShardingSphere-JDBC as a Driver.
+
+Users can obtain `Connection` directly through `DriverManager`:
+
+```java
+Class.forName("org.apache.shardingsphere.driver.ShardingSphereDriver");
+Connection conn =
DriverManager.getConnection("jdbc:shardingsphere:classpath:config.yaml");
+```
+
+Or use `Datasource` to obtain `Connection`:
+
+```java
+// Take HikariCP as an example
+HikariDataSource dataSource = new HikariDataSource();
+dataSource.setDriverClassName("org.apache.shardingsphere.driver.ShardingSphereDriver");
+dataSource.setJdbcUrl("jdbc:shardingsphere:classpath:config.yaml");
+Connection conn = dataSource.getConnection();
+```
+
+## Optimizations of the existing capabilities
+**Kernel**
+In this update, ShardingSphere merged lots of PRs to improve SQL parsing
support. SQL parsing optimizations take up a large proportion of the update log.
+
+ShardingSphere provided preliminary support for PostgreSQL / openGauss schema
in 5.1.1.
+
+In this 5.1.2 update, the kernel, cluster mode, and auto-scaling support for
PostgreSQL / openGauss schema has been improved. For example, support for
schema structure has been added to metadata pairs, and schema customization is
also supported in kernel and auto-scaling.
+
+**ShardingSphere-Proxy**
+As the market for servers using ARM CPUs becomes more popular,
ShardingSphere-Proxy also provides images for arm64 architecture on Docker as
well.
+
+When it comes to MySQL, ShardingSphere-Proxy fixed the issue where packets
longer than 8 MB could not be received, and further supports receiving data
larger than 16 MB in total.
+
+**Auto-scaling**
+In addition to supporting PostgreSQL schema customization, auto-scaling also
implements automatic table creation when migrating PostgreSQL, and fixes the
problem where PostgreSQL incremental migration would report errors when
encountering null fields values. In addition to these features, auto-scaling
also reduces resource consumption during migration and provides support for
incremental migration in openGauss 3.0.
+
+## Release notes
+The full release note for ShardingSphere 5.1.2 can be found in the following
sections. Note that this update adjusts a small number of APIs, so please refer
to the API Adjustments section for more details.
+
+**New Features**
+Kernel: alpha version of SQL dialect conversion for MySQL and PostgreSQL.
+
+Kernel: Support for PostgreSQL and openGauss custom schema.
+
+Kernel: Support for PostgreSQL and openGauss `create`/`alter`/`drop` view
statements.
+
+Kernel: support for openGauss cursor statements.
+
+Kernel: support for using system libraries customization.
+
+Kernel: support acquisition of openGauss and MySQL create table statements.
+
+Kernel: support acquisition of PostgreSQL create table statements.
+
+Access terminal: officially support rapid deployment of a ShardingSphere-Proxy
cluster that includes a ZooKeeper cluster in Kubernetes using Helm.
+
+Access terminal: support for ShardingSphere JDBC Driver.
+
+Auto Scaling: support for PostgreSQL automatic table building.
+
+Auto Scaling: support for PostgreSQL and openGauss custom schema table
migration.
+
+Auto Scaling: support migration of string primary key table.
+
+Operation mode: Governance Center supports PG/openGauss three-level structure.
+
+Operation mode: Governance Center supports Database level distributed locking.
+
+**Optimization**
+Kernel: support for PostgreSQL and openGauss copy statements.
+
+Kernel: support for PostgreSQL alter/ drop index statements.
+
+Kernel: support for MySQL update force index statements.
+
+Kernel: support for openGauss `create`/`alter`/`drop` schema statements.
+
+Kernel: optimize `RoundRobinReplicaLoadBalanceAlgorithm` and
`RoundRobinTrafficLoadBalanceAlgorithm` algorithm logic.
+
+Kernel: optimize metadata loading logic when front-end driver database type
and back-end do not match.
+
+Kernel: refactor metadata loading logic.
+
+Kernel: optimization of show processlist statement function.
+
+Kernel: improved loading performance in scenarios involving a large number of
tables.
+
+Kernel: support for comment statement execution
+
+Kernel: support for view statement execution in PostgreSQL and openGauss
sharding scenarios.
+
+Kernel: support for Oracle `CREATE ROLLBACK SEGMENT` statement.
+
+Kernel: support for parsing openGauss `DROP TYPE`
+
+Kernel: support for parsing openGauss `ALTER TYPE`
+
+Kernel: support for parsing Oracle `DROP DISKGROUP`
+
+Kernel: support for parsing Oracle `CREATE DISKGROUP`
+
+Kernel: support for parsing Oracle `DROP FLASHBACK ARCHIVE`
+
+Kernel: support parsing openGauss `CHECKPOINT`
+
+Kernel: support parsing Oracle `CREATE FLASHBACK ARCHIVE`
+
+Kernel: support parsing PostgreSQL `Close`
+
+Kernel: support parsing openGauss `DROP CAST`
+
+Kernel: support parsing openGauss `CREATE CAST`
+
+Kernel: support parsing Oracle `CREATE CONTROL FILE`
+
+Kernel: support parsing openGauss `DROP DIRECTORY`
+
+Kernel: support parsing openGauss `ALTER DIRECTORY`
+
+Kernel: support parsing openGauss `CREATE DIRECTORY`
+
+Kernel: support parsing PostgreSQL Checkpoint
+
+Kernel: support parsing openGauss `DROP SYNONYM`
+
+Kernel: support parsing openGauss `CREATE SYNONYM`
+
+Kernel: support parsing openGauss `ALTER SYNONYM`
+
+Kernel: support parsing PostgreSQL `CALL` statement
+
+Kernel: support parsing Oracle `CREATE PFILE`
+
+Kernel: support parsing Oracle `CREATE SPFILE`
+
+Kernel: support parsing Oracle `ALTER SEQUENCE`
+
+Kernel: support parsing Oracle `CREATE CONTEXT`
+
+Kernel: support for parsing Oracle `ALTER PACKAGE`
+
+Kernel: support for parsing Oracle `CREATE SEQUENCE`
+
+Kernel: support for parsing Oracle `ALTER ATTRIBUTE DIMENSION`
+
+Kernel: support for parsing Oracle `ALTER ANALYTIC VIEW`
+
+Kernel: loading `SQLVisitorFacade` with ShardingSphere Spi
+
+Kernel: loading `DatabaseTypedSQLParserFacade` with ShardingSphere Spi
+
+Kernel: support parsing Oracle `ALTER OUTLINE`
+
+Kernel: support parsing Oracle `DROP OUTLINE`
+
+Kernel: support parsing Oracle `drop edition`
+
+Kernel: support parsing SQLServer `WITH` Common Table Expression
+
+Kernel: optimize SubquerySegment’s start and end indexes in with statements
+
+Kernel: reconstructing `JoinTableSegment`
+
+Kernel: support parsing Oracle `DROP SYNONYM`
+
+Kernel: support parsing Oracle `CREATE DIRECTORY`
+
+Kernel: support parsing Oracle `CREATE SYNONYM
+`
+Kernel: support parsing SQLServer `XmlNamespaces` clause
+
+Kernel: support parsing Oracle `Alter Database Dictionary`
+
+Kernel: support parsing SQLServer clause of `SELECT` statement
+
+Kernel: support parsing Oracle `ALTER DATABASE LINK`
+
+Kernel: support for parsing Oracle `CREATE EDITION`
+
+Kernel: support parsing Oracle `ALTER TRIGGER`
+
+Kernel: support parsing SQLServer `REVERT` statement
+
+Kernel: support parsing PostgreSQL `DROP TEXT SEARCH`
+
+Kernel: support parsing PostgreSQL `drop server`
+
+Kernel: support parsing Oracle `ALTER VIEW`
+
+Kernel: support parsing PostgreSQL `drop access method`
+
+Kernel: support parsing PostgreSQL `DROP ROUTINE`
+
+Kernel: support parsing SQLServer `DROP USER`
+
+Kernel: support parsing Oracle `DROP TRIGGER`
+
+Kernel: support parsing PostgreSQL `drop subscription`
+
+Kernel: support parsing PostgreSQL `drop operator class`
+
+Kernel: support parsing PostgreSQL `DROP PUBLICATION`
+
+Kernel: support parsing Oracle `DROP VIEW`
+
+Kernel: support parsing PostgreSQL `DROP TRIGGER
+`
+Kernel: support parsing Oracle `DROP DIRECTORY`
+
+Kernel: support parsing PostgreSQL `DROP STATISTICS`
+
+Kernel: support parsing PostgreSQL `drop type`
+
+Kernel: support parsing PostgreSQL `DROP RULE`
+
+Kernel: support parsing SQLServer `ALTER LOGIN`
+
+Kernel: support parsing PostgreSQL `DROP FOREIGN DATA WRAPPER`
+
+Kernel: support parsing PostgreSQL `DROP EVENT TRIGGER` statement.
+
+Access Terminal: ShardingSphere-Proxy MySQL supports receiving request packets
over 16 MB in size.
+
+Access Terminal: ShardingSphere-Proxy adds `SO_BACKLOG` configuration item.
+
+Access Terminal: ShardingSphere-Proxy `SO_REUSEADDR` is enabled by default.
+
+Access Terminal: ShardingSphere-Proxy Docker image with aarch64 support.
+
+Access Terminal: ShardingSphere-Proxy MySQL support default MySQL version
number.
+
+Access Terminal: ShardingSphere-Proxy PostgreSQL /openGauss supports more
character sets.
+
+Access Terminal: ShardingSphere-Proxy adds default port configuration items.
+
+Auto Scaling: scaling is compatible with the HA port for data synchronization
when thread_pool is enabled in openGauss 3.0.
+
+Auto Scaling: optimize the logic of Zookeeper event handling in
`PipelineJobExecutor` to avoid zk blocking events.
+
+Auto Scaling: scaling data synchronization is case-insensitive for table names.
+
+Auto Scaling: improved PostgreSQL/openGauss replication slot cleanup.
+
+Auto Scaling: improved lock protection in preparation phase
+
+Auto Scaling: improve data synchronization in PostgreSQL rebuild scenarios
after the same record is deleted.
+
+Auto Scaling: data sources created by scaling are not cached at the bottom.
+
+Resilient Scaling: reuse data sources as much as possible to reduce database
connection occupancy.
+
+DistSQL: `REFRESH TABLE METADATA` supports specified PostgreSQL’s schema.
+
+DistSQL: add check for binding tables under `ALTER SHARDING TABLE RULE`
+
+Operational mode: ShardingSphere-JDBC support for configuring database
connection names.
+
+Distributed transactions: prohibit DistSQL execution in transactions.
+
+Distributed transaction: autocommit = 0, DML will automatically open
transaction in DDL part.
+
+## Bug fixes
+Kernel: fix PostgreSQL and openGauss show statement parsing exceptions.
+
+Kernel: fix PostgreSQL and openGauss time extract function parsing exceptions.
+
+Kernel: fix PostgreSQL and openGauss select mod function parsing exceptions.
+
+Kernel: fix the execution exception of multiple schema join statements in
read/write separation scenario.
+
+Kernel: fix exception in execution executing create schema statement in
encryption scenario.
+
+Kernel: fix drop schema if exist statement exception.
+
+Kernel: fix routing error with `LAST_INSERT_ID()`
+
+Kernel: fix use database execution exception in no data source state.
+
+Kernel: fix function creation statement with set var.
+
+Access: fix null pointer caused by field case mismatch in ShardingSphere-Proxy
PostgreSQL /openGauss `Describe PreparedStatement`
+
+Access: fix ShardingSphere-Proxy PostgreSQL /openGauss not returning to
correct tag after schema DDL execution.
+
+Auto Scaling: fix MySQL unsigned type error in the scaling process.
+
+Auto Scaling: fix a connection leak problem when the consistency check fails
to create a data source.
+
+Auto Scaling: fixes an issue where `ShardingSphereDataSource` initialization
process ignores rules other than sharding.
+
+Auto-scaling: support for jobs being closed in the preparation phase.
+
+Auto-scaling: fixes data source url and jdbcurl compatibility issues.
+
+Auto-scaling: fixes creation timing issues of openGauss data replication to
avoid possible incremental data loss.
+
+Auto-scaling: improve job state persistence to ensure that special cases are
not overwritten with the old state.
+
+Auto-scaling: fix PostgreSQL’s inability to correctly resolve null when using
TestDecoder for incremental migration.
+
+DistSQL: fix `SET VARIABLE` changes not taking effect in standalone and
in-memory modes.
+
+DistSQL: fix the problem where `SHOW INSTANCE LIST` is not consistent with
actual data.
+
+DistSQL: fix the case-sensitive problem in sharding rules.
+
+Run mode: fix the problem of metadata missing in the new version after the
scaling feature changes the table splitting rules.
+
+Distributed transaction: fix the problem that `indexinfo` obtained according
to catalog is empty.
+
+## Refactoring
+Auto-scaling: refactoring `jobConfig` to facilitate reuse and extension of new
types of jobs.
+
+Run mode: optimize the storage structure of compute nodes in the registry
center.
+
+Run mode: use `uuid` to substitute `ip@port` as a unique instance identifier.
+
+## API Adjustments
+DistSQL: `EXPORT SCHEMA CONFIG` is adjusted to `EXPORT DATABASE CONFIG`
+
+DistSQL: `IMPORT SCHEMA CONFIG` is adjusted to `IMPORT DATABASE CONFIG`
+
+Run mode: Adjust `db-discovery` algorithm configuration.
+
+DistSQL: `SHOW SCHEMA RESOURCES` is adjusted to `SHOW DATABASE RESOURCES`
+
+DistSQL: `COUNT SCHEMA RULES` is adjusted to `COUNT DATABASE RULES`
+
+Permissions: permission provider `ALL_PRIVILEGES_PERMITTED` updated to
`ALL_PERMITTED`
+
+Permissions: Permissions provider `SCHEMA_PRIVILEGES_PERMITTED` updated to
`DATABASE_PERMITTED`
+
+## Community shoutout
+Thanks to the efforts made by the 54 ShardingSphere contributors, who
submitted a total of 1028 PRs, to make the ShardingSphere 5.1.2 release
possible.
+
+
+
+**Relevant links:**
+
+[ShardingSphere
Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
+
+[ShardingSphere twitter
+](https://twitter.com/ShardingSphere)
+
+[ShardingSphere
Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+
+[Download
Link](https://shardingsphere.apache.org/document/current/cn/downloads/)
+
+[Release
Notes](https://github.com/apache/shardingsphere/blob/master/RELEASE-NOTES.md)
+
+## Author
+**Weijie Wu**
+
+**SphereEx Infrastructure R&D Engineer, Apache ShardingSphere PMC**
+
+Weijie focuses on the R&D of Apache ShardingSphere’s Access Terminal and
ShardingSphere’s subproject
[ElasticJob](https://shardingsphere.apache.org/elasticjob/).
diff --git
a/docs/blog/content/material/2022_06_30_ShardingSphere_&_Database_Mesh.en.md
b/docs/blog/content/material/2022_06_30_ShardingSphere_&_Database_Mesh.en.md
new file mode 100644
index 00000000000..1928ede9f65
--- /dev/null
+++ b/docs/blog/content/material/2022_06_30_ShardingSphere_&_Database_Mesh.en.md
@@ -0,0 +1,128 @@
++++
+title = "ShardingSphere & Database Mesh"
+weight = 64
+chapter = true
++++
+
+Some time ago, [SphereEx](https://www.sphere-ex.com/en/), a startup formed by
[Apache ShardingSphere](https://shardingsphere.apache.org/)’s core contributor
team, officially launched the [Database Mesh
2.0](https://faun.pub/database-mesh-2-0-database-governance-in-a-cloud-native-environment-ac24080349eb)
concept and its associated open source solution “Pisanix”, sparking discussion
and reflection in the community about ShardingSphere and Database Mesh.
+
+Some community users might be wondering why would you go through the trouble of
+starting from scratch in a new field when you’re already part of a successful
open source project like Apache ShardingSphere? Another question that can come
to mind is whether with the cloud-native trend, ShardingSphere will gradually
be incorporated into the Database Mesh concept in the future?
+
+With the introduction of the Database Mesh 2.0 concept, SphereEx has charted a
different course for open source development, seemingly in conflict with the
already successful ShardingSphere, but in reality, the two complement each
other while being interdependent.
+
+This post will focus on the ShardingSphere community’s views of the Database
Mesh concept, and the future development path and will walk you through the
guiding philosophy of Apache ShardingSphere, Database Plus, and how it’s
related to the Database Mesh concept.
+
+## What changed from microservices governance to service governance under
cloud-native databases?
+
+Compared with microservices, cloud-native database governance has a different
focus in terms of feature selection.
+
+First, databases have status and requests that cannot be routed to peer nodes
at will as happens with services, making data sharding important for databases.
Since database connections are inherently related to the status, starting or
stopping a new database instance often means data synchronization and
replication, making the ability to auto-discover instances less important
compared to microservices.
+
+If the database is viewed as a microservice, although database access can be
governed via Service Mesh, it is still subjected to many limitations. At the
same time, databases have some special governance attributes, like
communication protocols, resource management, load balancing based on data
requests, database, and table splitting, observability, access control, etc.,
all of which cannot be simply understood and solved just by applying the
concept of service, and must rely on database [...]
+
+Hence the development of Database Mesh. SphereEx put forward the Database Mesh
2.0 concept which focuses on how to achieve the following goals in a
cloud-native environment:
+
+1. Reduce the burden on developers, improve development efficiency, and
provide a transparent and seamless experience when using the database
infrastructure.
+2. Implement a governance framework covering database traffic, runtime
resources, and stability guarantees in a way that is easier to configure, plug,
and program.
+3. Provide a standard user interface for typical scenarios in multiple
database domains such as heterogeneous data sources, cloud-native databases,
and distributed databases.
+4. Provide capabilities such as data sharding, load balancing, observability,
auditing, etc., which have helped solve some traffic governance problems in
database governance.
+
+Recently, when business applications started to be packaged and delivered in
containers and to be released numerous times every day to Kubernetes
infrastructures in various data centers using CI/CD streams, we couldn’t help
but think about how to implement database reliability engineering in cloud
environments and finally came up with Database Mesh 2.0.
+
+## The difference between ShardingSphere’s Database Plus and Database Mesh
+
+**First, the philosophy is different. In fact, judging from their principles
and concepts, Database Plus and Database Mesh are quite different.**
+
+When it comes to Database Mesh, SphereEx believes that cloud-native database
governance has some common ground but also possesses its own uniqueness. The
common issues can be solved by standardization and automation, while the unique
ones can be solved by providing a flexible scaling mechanism that allows
engineers to configure and implement on-demand. This requires a high capacity
for programming in order to meet scaling requirements when addressing database
governance challenges on the cloud.
+
+As for Database Plus, the Apache ShardingSphere community sees it as a design
for a distributed database system that aims to build an overall ecosystem
including fragmented heterogeneous databases, providing global scalability and
overlay computational capabilities on the premise of maximizing the native
computational capabilities of the database. It makes the interaction between
applications and databases directed by the standards built by Database Plus,
shielding the impact database fr [...]
+
+With the inevitable trend of cloud-native databases, Database Mesh and
Database Plus are bound to have some overlap. In a cloud-native and distributed
database scenario, there will be more interactions between ShardingSphere and
Database Mesh.
+
+**Second, application scenarios are different too.**
+
+ShardingSphere, guided by the Database Plus concept, is primarily used in
distributed database scenarios, while Database Mesh is primarily implemented to
guide more specific practices for database reliability in cloud-native
scenarios.
+
+Being two different designs in two different domains, Database Plus and
Database Mesh both represent innovative ideas in their respective data
governance scenarios, leading to the creation of the two open-source solutions
ShardingSphere and [Pisanix](https://github.com/database-mesh/pisanix).
+
+Database Mesh 2.0 aspires to provide a database-centered governance framework:
+
+1. Databases as a priority: all actions revolve around database governance,
such as access control, traffic governance, observability, etc.
+2. Engineer-oriented experience: developers, can work on convenient and
easy-to-use database declarations and definitions, without caring about the
database location. For maintenance & operations teams and DBAs, multiple
abstract methods for database governance are provided to automate database
reliability engineering.
+3. Cloud-native: suitable for different cloud environments with an open
ecosystem and implementation mechanism, to build and achieve cloud-native
orientation without worrying about vendor lock-in.
+
+On the other hand, with the prospect of achieving connectivity, enhancement,
and pluggability, Database Plus aims to build a computing ecosystem on top of
fragmented heterogeneous databases to solve the problems of local architecture
selection, technology and maintenance & operation high complexity, lack of
standards in the databases’ upper layer, and lack of coordination and
management among databases.
+
+In a nutshell, Apache ShardingSphere, a project guided by the Database Plus
concept, is of great practical value for distributed database scenarios while
Database Mesh is the ideal solution for difficulties in database governance in
cloud-native scenarios.
+
+**Finally, the business scenarios and demands are different**
+
+From relational databases to distributed databases, multiple database
coexistence for enterprise applications has become the norm as application
scenarios keep expanding and database performance varies in different scenarios.
+
+Fragmentation is the trend since one single database category cannot be
applied to all scenarios. Driven by business scenarios, the use of distributed
database solutions has achieved industry consensus, to cope with heavy traffic,
higher concurrency, and increasing pressure on the database.
+
+In different scenarios and from different user perspectives, developers are
more concerned about operational efficiency, cost overhead, and database
protocol types and access information, not so much about where the data is
stored. Maintenance & operations teams and DBAs are more concerned about
automation, stability, security, monitoring and alerting of database services,
etc.
+
+Additionally, DBAs also pay attention to data changes, capacity, secure
access, backup, migration, etc. It is the deep understanding of database
governance scenarios and the pursuit for a better user experience that together
gave birth to the core idea of Database Mesh 2.0: to achieve high performance
scaling through programming, and meet the challenges of database governance on
the cloud.
+
+## With cloud-native applications booming: will there be a disconnect between
ShardingSphere and the cloud?
+
+Back in 2018, when Service Mesh was gaining traction, Apache ShardingSphere
PMC Chair Zhang Liang had already taken advantage of Service Mesh and proposed
the Database Mesh concept, envisioning whether there was a model that could
effectively combine the advantages of JDBC and Proxy clients while avoiding
their disadvantages to achieve a true cloud-based infrastructure with
auto-scaling + zero intrusion + decentralization. The ShardingSphere Sidecar
was the solution born during Database [...]
+
+As distributed approaches and cloud-native went on to become the trend,
ShardingSphere, with characteristics of being a community-oriented, open-source
project, must keep up with rapid changes happening in different business
operations and different scenarios. It has therefore undergone a transformation
from Sharding-JDBC to ShardingSphere, changing not only its name but also its
positioning and technological ecosystem construction.
+
+**Is Pisanix a cloud-based version of ShardingSphere rewritten in Rust and
Go?**
+
+Recently, SphereEx introduced Pisanix, an open source solution for Database
Mesh. As for Pisa-Proxy, the core component of Pisanix for database traffic, it
shares similarities with ShardingSphere-Proxy making it easy to think of these
two as a result of refactoring.
+
+Of course, it is not just Pisanix and ShardingSphere-Proxy, but all MySQL
database proxies have a similar architectural design. Especially in regards to
databases, there is a certain amount of similarity. The key is to find
differences between products. For Pisanix and ShardingSphere-Proxy, they differ
in what you want to achieve when you get the data and what problems you want to
solve.
+
+Therefore, Pisanix cannot simply be considered a rewrite of ShardingSphere
with Rust. They are completely different, except at the entry point because
there are always similarities when it comes to databases.
+
+
+
+On the other hand, many users will naturally identify Database Mesh and
ShardingSphere-Sidecar as the same thing. However, the two are very different
at the kernel level.
+
+As an implementation of the Database Mesh concept, Pisanix is now able to take
on some of the data governance capabilities of the original
ShardingSphere-Sidecar in a cloud-native environment, making it easy for users
to use ShardingSphere in a cloud-based environment.
+
+Sidecar does not serve as the kernel of Database Mesh, which must be oriented
towards a specific, engineering-related problem, and Sidecar is just one of the
forms of deployment Database Mesh concept. It is possible that one-day
Pisanix-Proxy will not be structured as Sidecar, or that it evolves into a very
thin middle layer. All in all, Sidecar is just a means to achieve governance
capabilities.
+
+Database Mesh’s real core focuses on the expansion of user experience and
database service governance. If more database types are available in the future
and more scenarios, both cloud-based and off the cloud, emerge, the concept of
Database Mesh will also be further expanded, which is exactly what Database
Mesh is aiming at.
+
+What Database Mesh wants to do is to block out various factors on the cloud,
and unify the various behaviors of the upper layer database to govern. However,
protocols and maintenance & operation properties of different databases are
quite different, so the tricky part lies in whether we can abstract a standard
governance behavior.
+
+The technical solution itself is one of many choices, but the essential part
is always the user experience. Whether to choose Java or Rust or Python is only
one part of the technical solution, with the objective being the vitality of
the project and its ecosystem, which must be considered carefully.
+
+## A glance at the future of databases: ShardingSphere + Database Mesh +….
+
+## Can Database Mesh govern ShardingSphere?
+If you think of ShardingSphere as a high-performance distributed database,
governing ShardingSphere is the same as governing MySQL, TiDB, and other
databases for Database Mesh.
+
+So while it can be governed, ShardingSphere itself does not necessarily
require support as its design concept, Database Plus, is to enhance those
capabilities that MySQL itself does not inherently possess through
connectivity, enhancement, and pluggability. Through ShardingSphere, a native
database can be combined with the underlying database to deploy more computing
power on the application side, turning it into a high-performance distributed
database that avoids wasting resources and p [...]
+
+## Opportunities in cloud-native scenarios
+Next, let’s take a look at the industry. As we all know, the cloud represents
the future, the irreversible direction. Therefore, whether a project, a
product, or an idea can serve this cause will directly affect its lifecycle and
impact. This is why ShardingSphere is so committed to its cloud-based
initiatives.
+
+Guided by the Database Plus concept, Apache ShardingSphere can extend existing
features to provide enterprises and cloud computing platforms with more
powerful capabilities across different database products. The underlying
compatibility with multiple databases and with all kinds of database products
in the cloud makes R&D tasks seamless.
+
+Maintaining its neutral position, ShardingSphere can also ensure that the
cloud experience is the same as the experience with local operations,
supporting multi-cloud architectures and providing the same experience in
different cloud infrastructures, which is precisely what ShardingSphere is good
at in cloud-native scenarios.
+
+As two completely independent design philosophies, Database Plus and Database
Mesh are not in competition with each other. On the contrary, Database Mesh and
Database Plus can work well with each other.
+
+Both can provide solutions based on the existing fragmented ecosystem of
databases and major issues that users are facing. Despite their different
approaches, they both represent the best ways to solve data governance problems
in different scenarios.
+
+**Relevant links:**
+[ShardingSphere
Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere
Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+
+[Download
Link](https://shardingsphere.apache.org/document/current/cn/downloads/)
+
+[Database Mesh](https://www.database-mesh.io/)
+
+[Pisanix Project](https://github.com/database-mesh/pisanix)
\ No newline at end of file
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}