This is an automated email from the ASF dual-hosted git repository.
zhangliang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new a85056a382d modify according to new structure (#19861)
a85056a382d is described below
commit a85056a382d9a1cb97bcb36b103a26e9240f85a0
Author: Mike0601 <[email protected]>
AuthorDate: Thu Aug 4 15:11:23 2022 +0800
modify according to new structure (#19861)
---
docs/document/content/overview/_index.cn.md | 4 +-
docs/document/content/overview/_index.en.md | 4 +-
docs/document/content/overview/advantages.cn.md | 18 -----
docs/document/content/overview/advantages.en.md | 18 -----
docs/document/content/overview/architecture.cn.md | 30 ---------
docs/document/content/overview/design.cn.md | 24 +++++++
.../overview/{architecture.en.md => design.en.md} | 16 ++---
docs/document/content/overview/distsql.cn.md | 77 ++++++++++++++++++++++
docs/document/content/overview/distsql.en.md | 76 +++++++++++++++++++++
docs/document/content/overview/glossary.cn.md | 37 -----------
docs/document/content/overview/glossary.en.md | 40 -----------
docs/document/content/overview/mode.cn.md | 20 ++++++
docs/document/content/overview/mode.en.md | 22 +++++++
docs/document/content/overview/scenarios.cn.md | 6 +-
docs/document/content/overview/scenarios.en.md | 6 +-
docs/document/content/overview/what-is-ss.cn.md | 14 ++++
docs/document/content/overview/what-is-ss.en.md | 14 ++++
.../content/reference/architecture/_index.cn.md | 13 ++++
.../content/reference/architecture/_index.en.md | 14 ++++
19 files changed, 289 insertions(+), 164 deletions(-)
diff --git a/docs/document/content/overview/_index.cn.md
b/docs/document/content/overview/_index.cn.md
index 780951248cf..3f67c4dc8f1 100644
--- a/docs/document/content/overview/_index.cn.md
+++ b/docs/document/content/overview/_index.cn.md
@@ -1,8 +1,8 @@
+++
pre = "<b>1. </b>"
-title = "项目简介"
+title = "概览"
weight = 1
chapter = true
+++
-本章介绍了什么是 Apache ShardingSphere,以及其基础架构、核心概念、产品优势和应用场景。
+本章介绍了什么是 Apache ShardingSphere,以及其设计哲学、JDBC 和 Proxy 、 DistSQL 和运行模式。
diff --git a/docs/document/content/overview/_index.en.md
b/docs/document/content/overview/_index.en.md
index fffc7b4c9fb..cd80b6caf3d 100644
--- a/docs/document/content/overview/_index.en.md
+++ b/docs/document/content/overview/_index.en.md
@@ -1,8 +1,8 @@
+++
pre = "<b>1. </b>"
-title = "Project Introduction"
+title = "Overview"
weight = 1
chapter = true
+++
-This chapter mainly introduces what Apache ShardingSphere is, as well as its
architecture, core concepts, advantages and application scenarios.
+This chapter mainly introduces what Apache ShardingSphere is, as well as its
design philosophy, JDBC and Proxy, DistSQL and operation mode.
diff --git a/docs/document/content/overview/advantages.cn.md
b/docs/document/content/overview/advantages.cn.md
deleted file mode 100644
index f7ce8eb2e75..00000000000
--- a/docs/document/content/overview/advantages.cn.md
+++ /dev/null
@@ -1,18 +0,0 @@
-+++
-pre = "<b>1.4 </b>"
-title = "产品优势"
-weight = 4
-chapter = true
-+++
-
-* 构建异构数据库上层生态和标准
-
-Apache ShardingSphere 产品定位为 Database Plus,旨在构建异构数据库上层的标准和生态。
它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere
站在数据库的上层视角,关注他们之间的协作多于数据库自身。
-
-* 在原有关系型数据库基础上提供扩展和增强
-
-Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,
并非实现一个全新的关系型数据库。关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
-
-* 支持多态接入
-
-Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和
ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合于当前业务的最佳系统架构。
diff --git a/docs/document/content/overview/advantages.en.md
b/docs/document/content/overview/advantages.en.md
deleted file mode 100644
index c27e1d5933f..00000000000
--- a/docs/document/content/overview/advantages.en.md
+++ /dev/null
@@ -1,18 +0,0 @@
-+++
-pre = "<b>1.4 </b>"
-title = "Advantages"
-weight = 4
-chapter = true
-+++
-
-- Build a standard layer & ecosystem above heterogeneous databases.
-
-Apache ShardingSphere is positioned as Database Plus and aims at building a
standard layer and ecosystem above heterogeneous databases. The project focuses
on how to maximize the original database computing and storage capabilities -
rather than creating a new database. Placed above databases, ShardingSphere
enhances database inter-compatibility and collaboration.
-
-- Provide relational databases with expansions and enhancements.
-
-Apache ShardingSphere is designed to fully unlock relational databases compute
and storage capabilities in distributed scenarios, instead of creating an
entirely new relational database. Relational databases still have a
considerable market share today and are the cornerstone of the core system of
enterprises. It is for such reasons that we believe that we should focus on
enhancing it rather than overturning it.
-
-- Support multistate access.
-
-Apache ShardingSphere is an ecosystem composed of multiple access ports. By
combining ShardingSphere-JDBC and ShardingSphere-Proxy, and using the same
registry to configure sharding strategies, it can flexibly build application
systems for various scenarios, enabling architects to adjust the system
architecture for current businesses freely.
diff --git a/docs/document/content/overview/architecture.cn.md
b/docs/document/content/overview/architecture.cn.md
deleted file mode 100644
index d0ea550cc15..00000000000
--- a/docs/document/content/overview/architecture.cn.md
+++ /dev/null
@@ -1,30 +0,0 @@
-+++
-pre = "<b>1.3 </b>"
-title = "基础架构"
-weight = 3
-chapter = true
-+++
-
-让开发者能够像使用积木一样定制属于自己的独特系统,是 Apache ShardingSphere 可插拔架构的设计目标。
-
-可插拔架构对程序架构设计的要求非常高,需要将各个模块相互独立,互不感知,并且通过一个可插拔内核,以叠加的方式将各种功能组合使用。
设计一套将功能开发完全隔离的架构体系,既可以最大限度的将开源社区的活力激发出来,也能够保障项目的质量。
-
-Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。
目前,数据分片、读写分离、数据库高可用、数据加密、影子库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL
与协议的支持,均通过插件的方式织入项目。 Apache ShardingSphere 目前已提供数十个 [SPI(Service Provider
Interface)](https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html)
作为系统的扩展点,而且仍在不断增加中。
-
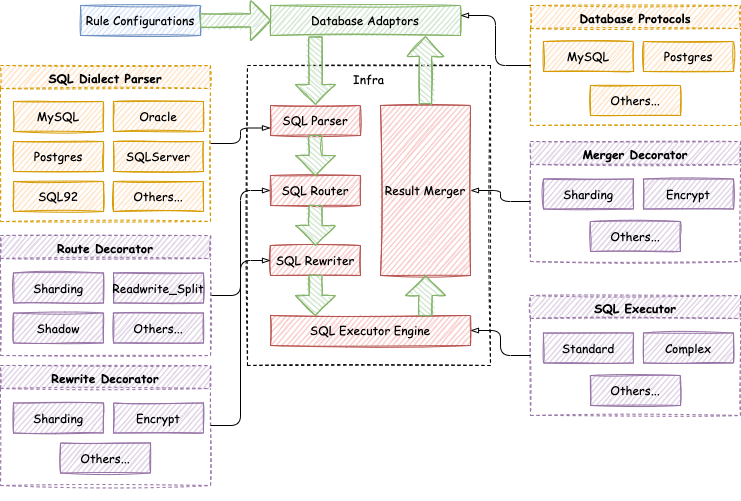
-
-
-Apache ShardingSphere 的可插拔架构划分为 3 层,它们是:L1 内核层、L2 功能层、L3 生态层。
-
-
-
-## L1 内核层
-
-是数据库基本能力的抽象,其所有组件均必须存在,但具体实现方式可通过可插拔的方式更换。
主要包括查询优化器、分布式事务引擎、分布式执行引擎、权限引擎和调度引擎等。
-
-## L2 功能层
-
-用于提供增量能力,其所有组件均是可选的,可以包含零至多个组件。组件之间完全隔离,互无感知,多组件可通过叠加的方式相互配合使用。
主要包括数据分片、读写分离、数据库高可用、数据加密、影子库等。用户自定义功能可完全面向 Apache ShardingSphere
定义的顶层接口进行定制化扩展,而无需改动内核代码。
-
-## L3 生态层
-
-用于对接和融入现有数据库生态,包括数据库协议、SQL 解析器和存储适配器,分别对应于 Apache ShardingSphere
以数据库协议提供服务的方式、SQL 方言操作数据的方式以及对接存储节点的数据库类型。
diff --git a/docs/document/content/overview/design.cn.md
b/docs/document/content/overview/design.cn.md
new file mode 100644
index 00000000000..5b355d9b1fe
--- /dev/null
+++ b/docs/document/content/overview/design.cn.md
@@ -0,0 +1,24 @@
++++
+pre = "<b>1.2 </b>"
+title = "设计哲学"
+weight = 2
+chapter = true
++++
+
+ShardingSphere 采用了 Database Plus 设计哲学,该理念致力于构建数据库上层的标准和生态,在生态中补充数据库所缺失的能力。
+
+Apache ShardingSphere 的可插拔架构划分为 3 层,它们是:L1 内核层、L2 功能层、L3 生态层。
+
+
+
+## L1 内核层
+
+是数据库基本能力的抽象,其所有组件均必须存在,但具体实现方式可通过可插拔的方式更换。
主要包括查询优化器、分布式事务引擎、分布式执行引擎、权限引擎和调度引擎等。
+
+## L2 功能层
+
+用于提供增量能力,其所有组件均是可选的,可以包含零至多个组件。组件之间完全隔离,互无感知,多组件可通过叠加的方式相互配合使用。
主要包括数据分片、读写分离、数据库高可用、数据加密、影子库等。用户自定义功能可完全面向 Apache ShardingSphere
定义的顶层接口进行定制化扩展,而无需改动内核代码。
+
+## L3 生态层
+
+用于对接和融入现有数据库生态,包括数据库协议、SQL 解析器和存储适配器,分别对应于 Apache ShardingSphere
以数据库协议提供服务的方式、SQL 方言操作数据的方式以及对接存储节点的数据库类型。
\ No newline at end of file
diff --git a/docs/document/content/overview/architecture.en.md
b/docs/document/content/overview/design.en.md
similarity index 52%
rename from docs/document/content/overview/architecture.en.md
rename to docs/document/content/overview/design.en.md
index 8ad004ce1fa..e92cfd77607 100644
--- a/docs/document/content/overview/architecture.en.md
+++ b/docs/document/content/overview/design.en.md
@@ -1,18 +1,11 @@
+++
-pre = "<b>1.3 </b>"
-title = "Architecture"
-weight = 3
+pre = "<b>1.2 </b>"
+title = "Design Philosophy"
+weight = 2
chapter = true
+++
-Apache ShardingSphere's pluggable architecture is designed to enable
developers to customize their own unique systems by adding the desired
features, just like adding building blocks.
-
-A plugin-oriented architecture has very high requirements for program
architecture design. It requires making each module independent, and using a
pluggable kernel to combine various functions in an overlapping manner.
Designing an architecture system that completely isolates the feature
development not only fosters an active open source community, but also ensures
the quality of the project.
-
-Apache ShardingSphere began to focus on the pluggable architecture since
version 5.X, and the functional components of the project can be flexibly
extended in a pluggable manner. Currently, features such as data sharding,
read/write splitting, database high availability, data encryption, shadow DB
stress testing, and support for SQL and protocols such as MySQL, PostgreSQL,
SQLServer, Oracle, etc. are woven into the project through plugins.
-Apache ShardingSphere has provided dozens of SPIs (service provider
interfaces) as extension points of the system, with the total number still
increasing.
-
-
+ShardingSphere adopts the database plus design philosophy, which is committed
to building the standards and ecology of the upper layer of the database and
supplementing the missing capabilities of the database in the ecology.
The pluggable architecture of Apache ShardingSphere is composed of three
layers - L1 Kernel Layer, L2 Feature Layer and L3 Ecosystem Layer.
@@ -29,3 +22,4 @@ Used to provide enhancement capabilities. All components are
optional, allowing
## L3 Ecosystem Layer
It is used to integrate and merge the current database ecosystems. The
ecosystem layer includes database protocol, SQL parser and storage adapter,
corresponding to the way in which Apache ShardingSphere provides services by
database protocol, the way in which SQL dialect operates data, and the database
type that interacts with storage nodes.
+
diff --git a/docs/document/content/overview/distsql.cn.md
b/docs/document/content/overview/distsql.cn.md
new file mode 100644
index 00000000000..c0319ebcd45
--- /dev/null
+++ b/docs/document/content/overview/distsql.cn.md
@@ -0,0 +1,77 @@
++++
+pre = "<b>1.4 </b>"
+title = "DistSQL"
+weight = 4
+chapter = true
++++
+
+## 定义
+
+DistSQL(Distributed SQL)是 Apache ShardingSphere 特有的操作语言。 它与标准 SQL
的使用方式完全一致,用于提供增量功能的 SQL 级别操作能力。
+
+灵活的规则配置和资源管控能力是 Apache ShardingSphere 的特点之一。
+
+在使用 4.x
及其之前版本时,开发者虽然可以像使用原生数据库一样操作数据,但却需要通过本地文件或注册中心配置资源和规则。然而,操作习惯变更,对于运维工程师并不友好。
+
+从 5.x 版本开始,DistSQL(Distributed SQL)让用户可以像操作数据库一样操作 Apache
ShardingSphere,使其从面向开发人员的框架和中间件转变为面向运维人员的数据库产品。
+
+## 相关概念
+
+DistSQL 细分为 RDL、RQL、RAL 和 RUL 四种类型。
+
+### RDL
+
+Resource & Rule Definition Language,负责资源和规则的创建、修改和删除。
+
+### RQL
+
+Resource & Rule Query Language,负责资源和规则的查询和展现。
+
+### RAL
+
+Resource & Rule Administration Language,负责强制路由、熔断、配置导入导出、数据迁移控制等管理功能。
+
+### RUL
+
+Resource Utility Language,负责 SQL 解析、SQL 格式化、执行计划预览等功能。
+
+## 对系统的影响
+
+### 之前
+
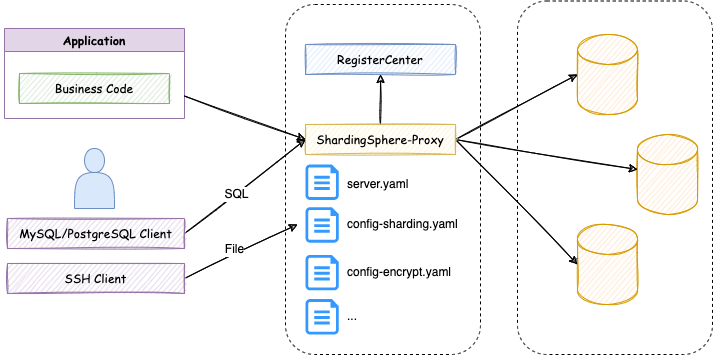
+在拥有 DistSQL 以前,用户一边使用 SQL 语句操作数据,一边使用 YAML 文件来管理 ShardingSphere 的配置,如下图:
+
+
+
+这时用户不得不面对以下几个问题:
+- 需要通过不同类型的客户端来操作数据和管理 ShardingSphere 规则;
+- 多个逻辑库需要多个 YAML 文件;
+- 修改 YAML 需要文件的编辑权限;
+- 修改 YAML 后需要重启 ShardingSphere。
+
+### 之后
+
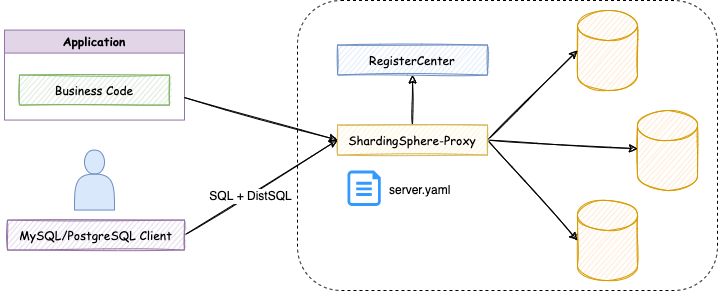
+随着 DistSQL 的出现,对 ShardingSphere 的操作方式也得到了改变:
+
+
+
+现在,用户的使用体验得到了巨大改善:
+- 使用相同的客户端来管理数据和 ShardingSphere 配置;
+- 不再额外创建 YAML 文件,通过 DistSQL 管理逻辑库;
+- 不再需要文件的编辑权限,通过 DistSQL 来管理配置;
+- 配置的变更实时生效,无需重启 ShardingSphere。
+
+## 使用限制
+
+DistSQL 只能用于 ShardingSphere-Proxy,ShardingSphere-JDBC 暂不提供。
+
+## 原理介绍
+
+与标准 SQL 一样,DistSQL 由 ShardingSphere 的解析引擎进行识别,将输入语句转换为抽象语法树,进而生成各个语法对应的
`Statement`,最后由合适的 `Handler` 进行业务处理。
+整体流程如下图所示:
+
+
+
+## 相关参考
+
+[用户手册:DistSQL](/cn/user-manual/shardingsphere-proxy/distsql/)
diff --git a/docs/document/content/overview/distsql.en.md
b/docs/document/content/overview/distsql.en.md
new file mode 100644
index 00000000000..933fb039ab3
--- /dev/null
+++ b/docs/document/content/overview/distsql.en.md
@@ -0,0 +1,76 @@
++++
+pre = "<b>1.4 </b>"
+title = "DistSQL"
+weight = 4
+chapter = true
++++
+
+## Definition
+
+DistSQL (Distributed SQL) is Apache ShardingSphere's specific SQL, providing
additional operation capabilities compared to standard SQL.
+
+Flexible rule configuration and resource management & control capabilities are
one of the characteristics of Apache ShardingSphere.
+
+When using 4.x and earlier versions, developers can operate data just like
using a database, but they need to configure resources and rules through YAML
file (or registry center). However, the YAML file format and the changes
brought by using the registry center made it unfriendly to DBAs.
+
+Starting from version 5.x, DistSQL enables users to operate Apache
ShardingSphere just like a database, transforming it from a framework and
middleware for developers to a database product for DBAs.
+
+## Related Concepts
+
+DistSQL is divided into RDL, RQL, RAL and RUL.
+
+### RDL
+
+Resource & Rule Definition Language, is responsible for the definition of
resources and rules.
+
+### RQL
+
+Resource & Rule Query Language, is responsible for the query of resources and
rules.
+
+### RAL
+
+Resource & Rule Administration Language, is responsible for hint, circuit
breaker, configuration import and export, scaling control and other management
functions.
+
+### RUL
+
+Resource Utility Language, is responsible for SQL parsing, SQL formatting,
preview execution plan, etc.
+
+## Impact on the System
+
+### Before
+
+Before having DistSQL, users used SQL to operate data while using YAML
configuration files to manage ShardingSphere, as shown below:
+
+
+
+At that time, users faced the following problems:
+- Different types of clients are required to operate data and manage
ShardingSphere configuration.
+- Multiple logical databases require multiple YAML files.
+- Editing a YAML file requires writing permissions.
+- Need to restart ShardingSphere after editing YAML.
+
+### After
+
+With the advent of DistSQL, the operation of ShardingSphere has also changed:
+
+
+
+Now, the user experience has been greatly improved:
+- Uses the same client to operate data and ShardingSphere configuration.
+- No need for additional YAML files, and the logical databases are managed
through DistSQL.
+- Editing permissions for files are no longer required, and configuration is
managed through DistSQL.
+- Configuration changes take effect in real-time without restarting
ShardingSphere.
+
+## Limitations
+
+DistSQL can be used only with ShardingSphere-Proxy, not with
ShardingSphere-JDBC for now.
+
+## How it works
+
+Like standard SQL, DistSQL is recognized by the parsing engine of
ShardingSphere. It converts the input statement into an abstract syntax tree
and then generates the `Statement` corresponding to each grammar, which is
processed by the appropriate `Handler`.
+
+
+
+## Related References
+
+[User Manual: DistSQL](/en/user-manual/shardingsphere-proxy/distsql/)
diff --git a/docs/document/content/overview/glossary.cn.md
b/docs/document/content/overview/glossary.cn.md
deleted file mode 100644
index a40e6e3a1ac..00000000000
--- a/docs/document/content/overview/glossary.cn.md
+++ /dev/null
@@ -1,37 +0,0 @@
-+++
-pre = "<b>1.2 </b>"
-title = "核心概念"
-weight = 2
-chapter = true
-+++
-
-## Database Plus
-
-Database Plus 是 Apache ShardingSphere 的产品定位,旨在构建异构数据库上层的标准和生态。
它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere
站在数据库的上层视角,关注他们之间的协作多于数据库自身。
-
-连接、增量 和 可插拔是 Database Plus 的核心概念:
-
-### 连接
-
-通过对数据库协议、SQL 方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库;
-
-### 增量
-
-获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能;
-
-### 可插拔
-
-项目采用微内核 + 三层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统。
-
-## 运行模式
-
-Apache ShardingSphere 是一套完善的产品,使用场景非常广泛。
除生产环境的集群部署之外,还为工程师在开发和自动化测试等场景提供相应的运行模式。 Apache ShardingSphere 提供的 2
种运行模式分别是单机模式和集群模式。
-源码:https://github.com/apache/shardingsphere/tree/master/shardingsphere-mode
-
-### 单机模式
-
-初始化配置或执行 SQL 等造成的元数据结果变更的操作,仅在当前进程中生效。 方便开发人员在本地搭建 Apache ShardingSphere
而无需清理运行痕迹。 它是 Apache ShardingSphere 的默认模式。
-
-### 集群模式
-
-提供了多个 Apache ShardingSphere 实例之间的元数据共享和分布式场景下状态协调的能力。
在真实部署上线的生产环境,必须使用集群模式。它能够提供计算能力水平扩展和高可用等分布式系统必备的能力。
集群环境需要通过独立部署的注册中心来存储元数据和协调节点状态。
diff --git a/docs/document/content/overview/glossary.en.md
b/docs/document/content/overview/glossary.en.md
deleted file mode 100644
index 3c9ab6f2951..00000000000
--- a/docs/document/content/overview/glossary.en.md
+++ /dev/null
@@ -1,40 +0,0 @@
-+++
-pre = "<b>1.2 </b>"
-title = "Core Concepts"
-weight = 2
-chapter = true
-+++
-
-## Database Plus
-
-Database Plus is the concept driving Apache ShardingSphere's project
positioning, and it is designed to build a standard layer and ecosystem above
heterogeneous databases. This concept focuses on how to maximize the original
database computing and storage capabilities rather than creating a new
database. Placed above databases, ShardingSphere focuses on enhancing
databases' inter-compatibility and collaboration.
-
-Connect, Enhance, and Pluggable are the core concepts of Database Plus:
-
-### Connect
-
-Through flexible adaptation to the database protocol, SQL dialect, and
database storage, ShardingSphere can quickly connect applications and
multi-model heterogeneous databases.
-
-### Enhance
-
-ShardingSphere can obtain databases' access traffic and provide transparent
enhancement features such as traffic redirection (sharding, read/write
splitting, and shadow DB), transformation (data encryption and masking),
authentication (security, audit, and permission), governance (circuit breaker
and traffic limit) and analysis (QoS and observability).
-
-### Pluggable
-
-The project adopts the micro-kernel and three-layer pluggable model, which
enables the kernel, features, and database ecosystems to be flexibly expanded.
Developers can customize their ShardingSphere just like building with LEGO
blocks.
-
-## Multi Operation Mode
-
-Apache ShardingSphere is a complete set of products applicable to a wide range
of usage scenarios. In addition to the cluster deployment of the production
environment, it also provides corresponding operation modes for engineers in
the development process and automated testing scenarios. Apache ShardingSphere
provides three operation modes: standalone mode, and cluster mode.
-
-Source code:
https://github.com/apache/shardingsphere/tree/master/shardingsphere-mode
-
-### Standalone mode
-
-Initial configuration or metadata changes caused by SQL execution take effect
only in the current process. It is ideal for engineers to build a
ShardingSphere environment locally without cleaning the running traces. This is
the default mode of Apache ShardingSphere.
-
-### Cluster mode
-
-It provides metadata sharing between multiple Apache ShardingSphere instances
and the capability to coordinate states in distributed scenarios. In an actual
production environment for deployment and release, you must use the cluster
mode.
-
-It provides the capabilities necessary for distributed systems, such as
horizontal scaling of computing capability and high availability. Clustered
environments need to store metadata and coordinate nodes' status through a
separately deployed registry center.
diff --git a/docs/document/content/overview/mode.cn.md
b/docs/document/content/overview/mode.cn.md
new file mode 100644
index 00000000000..581550e3bd1
--- /dev/null
+++ b/docs/document/content/overview/mode.cn.md
@@ -0,0 +1,20 @@
++++
+pre = "<b>1.5 </b>"
+title = "运行模式"
+weight = 5
+chapter = true
++++
+
+Apache ShardingSphere 是一套完善的产品,使用场景非常广泛。
除生产环境的集群部署之外,还为工程师在开发和自动化测试等场景提供相应的运行模式。 Apache ShardingSphere 提供的 3
种运行模式分别是内存模式、单机模式和集群模式。
+
+### 内存模式
+
+初始化配置或执行 SQL 等造成的元数据结果变更的操作,仅在当前进程中生效。 适用于集成测试的环境启动,方便开发人员在整合功能测试中集成 Apache
ShardingSphere 而无需清理运行痕迹。
+
+### 单机模式
+
+能够将数据源和规则等元数据信息持久化,但无法将元数据同步至多个 Apache ShardingSphere 实例,无法在集群环境中相互感知。
通过某一实例更新元数据之后,会导致其他实例由于获取不到最新的元数据而产生不一致的错误。 适用于工程师在本地搭建 Apache ShardingSphere
环境。
+
+### 集群模式
+
+提供了多个 Apache ShardingSphere 实例之间的元数据共享和分布式场景下状态协调的能力。
在真实部署上线的生产环境,必须使用集群模式。它能够提供计算能力水平扩展和高可用等分布式系统必备的能力。
集群环境需要通过独立部署的注册中心来存储元数据和协调节点状态。
diff --git a/docs/document/content/overview/mode.en.md
b/docs/document/content/overview/mode.en.md
new file mode 100644
index 00000000000..c0b66e451c1
--- /dev/null
+++ b/docs/document/content/overview/mode.en.md
@@ -0,0 +1,22 @@
++++
+pre = "<b>1.5 </b>"
+title = "Mode"
+weight = 5
+chapter = true
++++
+
+Apache ShardingSphere is a complete set of products applicable to a wide range
of usage scenarios. In addition to the cluster deployment of the production
environment, it also provides corresponding operation modes for engineers in
the development process and automated testing scenarios. Apache ShardingSphere
provides three operation modes: memory mode, standalone mode, and cluster mode.
+
+### Memory mode
+
+Initial configuration or metadata changes caused by SQL execution take effect
only in the current process. Suitable for environment setup of integration
testing, it makes it easy for developers to integrate Apache ShardingSphere in
integrated functional testing without cleaning the running traces. This is the
default mode of Apache ShardingSphere.
+
+### Standalone mode
+
+It can achieve data persistence in terms of metadata information such as data
sources and rules, but it is not able to synchronize metadata to multiple
Apache ShardingSphere instances or be aware of each other in a cluster
environment. Updating metadata through one instance causes inconsistencies in
other instances because they cannot get the latest metadata. It is ideal for
engineers to build a ShardingSphere environment locally.
+
+### Cluster mode
+
+It provides metadata sharing between multiple Apache ShardingSphere instances
and the capability to coordinate states in distributed scenarios. In an actual
production environment for deployment and release, you must use the cluster
mode.
+
+It provides the capabilities necessary for distributed systems, such as
horizontal scaling of computing capability and high availability. Clustered
environments need to store metadata and coordinate nodes' status through a
separately deployed registry center.
diff --git a/docs/document/content/overview/scenarios.cn.md
b/docs/document/content/overview/scenarios.cn.md
index 826f6adf077..86a3bd0ca22 100644
--- a/docs/document/content/overview/scenarios.cn.md
+++ b/docs/document/content/overview/scenarios.cn.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>1.5 </b>"
-title = "应用场景"
-weight = 5
+pre = "<b>1.3 </b>"
+title = "JDBC & Proxy"
+weight = 3
chapter = true
+++
diff --git a/docs/document/content/overview/scenarios.en.md
b/docs/document/content/overview/scenarios.en.md
index a842cecd71c..8c8c103e2b0 100644
--- a/docs/document/content/overview/scenarios.en.md
+++ b/docs/document/content/overview/scenarios.en.md
@@ -1,7 +1,7 @@
+++
-pre = "<b>1.5 </b>"
-title = "Application Scenarios"
-weight = 5
+pre = "<b>1.3 </b>"
+title = "JDBC & Proxy"
+weight = 3
chapter = true
+++
diff --git a/docs/document/content/overview/what-is-ss.cn.md
b/docs/document/content/overview/what-is-ss.cn.md
index 366a19d5210..fe0ca116a00 100644
--- a/docs/document/content/overview/what-is-ss.cn.md
+++ b/docs/document/content/overview/what-is-ss.cn.md
@@ -12,6 +12,20 @@ Apache ShardingSphere 是一款开源分布式数据库生态项目,由 JDBC
ShardingSphere 已于 2020 年 4 月 16 日成为 [Apache
软件基金会](https://apache.org/index.html#projects-list)的顶级项目。
欢迎通过[邮件列表](mailto:[email protected])参与讨论。
+## 产品优势
+
+* 构建异构数据库上层生态和标准
+
+Apache ShardingSphere 产品定位为 Database Plus,旨在构建异构数据库上层的标准和生态。
它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere
站在数据库的上层视角,关注他们之间的协作多于数据库自身。
+
+* 在原有关系型数据库基础上提供扩展和增强
+
+Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,
并非实现一个全新的关系型数据库。关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
+
+* 支持多态接入
+
+Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和
ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合于当前业务的最佳系统架构。
+
## 线路规划

diff --git a/docs/document/content/overview/what-is-ss.en.md
b/docs/document/content/overview/what-is-ss.en.md
index 17458dc6d4e..c1e69efed2e 100644
--- a/docs/document/content/overview/what-is-ss.en.md
+++ b/docs/document/content/overview/what-is-ss.en.md
@@ -15,6 +15,20 @@ The idea of the Apache ShardingSphere project is to provide
an enhanced database
ShardingSphere became an [Apache](https://apache.org/index.html#projects-list)
Top-Level Project on April 16, 2020. You are welcome to check out the mailing
list and discuss via [mail](mailto:[email protected]).
+## Advantages
+
+- Build a standard layer & ecosystem above heterogeneous databases.
+
+Apache ShardingSphere is positioned as Database Plus and aims at building a
standard layer and ecosystem above heterogeneous databases. The project focuses
on how to maximize the original database computing and storage capabilities -
rather than creating a new database. Placed above databases, ShardingSphere
enhances database inter-compatibility and collaboration.
+
+- Provide relational databases with expansions and enhancements.
+
+Apache ShardingSphere is designed to fully unlock relational databases compute
and storage capabilities in distributed scenarios, instead of creating an
entirely new relational database. Relational databases still have a
considerable market share today and are the cornerstone of the core system of
enterprises. It is for such reasons that we believe that we should focus on
enhancing it rather than overturning it.
+
+- Support multistate access.
+
+Apache ShardingSphere is an ecosystem composed of multiple access ports. By
combining ShardingSphere-JDBC and ShardingSphere-Proxy, and using the same
registry to configure sharding strategies, it can flexibly build application
systems for various scenarios, enabling architects to adjust the system
architecture for current businesses freely.
+
## Roadmap

diff --git a/docs/document/content/reference/architecture/_index.cn.md
b/docs/document/content/reference/architecture/_index.cn.md
new file mode 100644
index 00000000000..f43d52cda8b
--- /dev/null
+++ b/docs/document/content/reference/architecture/_index.cn.md
@@ -0,0 +1,13 @@
++++
+pre = "<b>7.13. </b>"
+title = "基础架构"
+weight = 13
++++
+
+让开发者能够像使用积木一样定制属于自己的独特系统,是 Apache ShardingSphere 可插拔架构的设计目标。
+
+可插拔架构对程序架构设计的要求非常高,需要将各个模块相互独立,互不感知,并且通过一个可插拔内核,以叠加的方式将各种功能组合使用。
设计一套将功能开发完全隔离的架构体系,既可以最大限度的将开源社区的活力激发出来,也能够保障项目的质量。
+
+Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。
目前,数据分片、读写分离、数据库高可用、数据加密、影子库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL
与协议的支持,均通过插件的方式织入项目。 Apache ShardingSphere 目前已提供数十个 [SPI(Service Provider
Interface)](https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html)
作为系统的扩展点,而且仍在不断增加中。
+
+
diff --git a/docs/document/content/reference/architecture/_index.en.md
b/docs/document/content/reference/architecture/_index.en.md
new file mode 100644
index 00000000000..f0e9c92edb3
--- /dev/null
+++ b/docs/document/content/reference/architecture/_index.en.md
@@ -0,0 +1,14 @@
++++
+pre = "<b>7.13. </b>"
+title = "Architecture"
+weight = 13
++++
+
+Apache ShardingSphere's pluggable architecture is designed to enable
developers to customize their own unique systems by adding the desired
features, just like adding building blocks.
+
+A plugin-oriented architecture has very high requirements for program
architecture design. It requires making each module independent, and using a
pluggable kernel to combine various functions in an overlapping manner.
Designing an architecture system that completely isolates the feature
development not only fosters an active open source community, but also ensures
the quality of the project.
+
+Apache ShardingSphere began to focus on the pluggable architecture since
version 5.X, and the functional components of the project can be flexibly
extended in a pluggable manner. Currently, features such as data sharding,
read/write splitting, database high availability, data encryption, shadow DB
stress testing, and support for SQL and protocols such as MySQL, PostgreSQL,
SQLServer, Oracle, etc. are woven into the project through plugins.
+Apache ShardingSphere has provided dozens of SPIs (service provider
interfaces) as extension points of the system, with the total number still
increasing.
+
+
\ No newline at end of file
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}