This is an automated email from the ASF dual-hosted git repository.
zhangliang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new b099aa5379f Update result.cn.md (#31333)
b099aa5379f is described below
commit b099aa5379fdcec6b4fd4291a229c174a592a2a6
Author: LJ <[email protected]>
AuthorDate: Tue May 21 23:19:45 2024 +0800
Update result.cn.md (#31333)
According to the numbers in the document and the spacing between the
English format and the Chinese format, the document format is adjusted to
achieve the standardization of the document.
---
docs/blog/content/material/result.cn.md | 42 ++++++++++++++++-----------------
1 file changed, 21 insertions(+), 21 deletions(-)
diff --git a/docs/blog/content/material/result.cn.md
b/docs/blog/content/material/result.cn.md
index 13af901a879..b6c239c3e09 100644
--- a/docs/blog/content/material/result.cn.md
+++ b/docs/blog/content/material/result.cn.md
@@ -8,7 +8,7 @@ chapter = true
### 讲师介绍
-张亮,原当当架构部负责人。热爱开源,目前主导两个开源项目Elastic-Job和Sharding-Sphere(Sharding-JDBC)。擅长以java为主分布式架构以及以Kubernetes和Mesos为主的云平台方向,推崇优雅代码,对如何写出具有展现力的代码有较多研究。2018年初加入京东金融,现担任数据研发负责人。目前主要精力投入在将Sharding-Sphere打造为业界一流的金融级数据解决方案之上。
+张亮,原当当架构部负责人。热爱开源,目前主导两个开源项目 Elastic-Job 和 Sharding-Sphere(Sharding-JDBC)。擅长以
java 为主分布式架构以及以 Kubernetes 和 Mesos 为主的云平台方向,推崇优雅代码,对如何写出具有展现力的代码有较多研究。2018
年初加入京东金融,现担任数据研发负责人。目前主要精力投入在将 Sharding-Sphere 打造为业界一流的金融级数据解决方案之上。
### 简介
@@ -16,7 +16,7 @@ chapter = true
-Sharding-Sphere支持的结果归并从功能上分为遍历、排序、分组和分页4种类型,它们是组合而非互斥的关系。从结构划分,可分为流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
+Sharding-Sphere 支持的结果归并从功能上分为遍历、排序、分组和分页 4
种类型,它们是组合而非互斥的关系。从结构划分,可分为流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
@@ -44,23 +44,23 @@ Sharding-Sphere支持的结果归并从功能上分为遍历、排序、分组
#### 排序归并
-由于在SQL中存在ORDER
BY语句,因此每个数据结果集自身是有序的,因此只需要将数据结果集当前游标指向的数据值进行排序即可。这相当于对多个有序的数组进行排序,归并排序是最适合此场景的排序算法。
+由于在SQL中存在 ORDER BY
语句,因此每个数据结果集自身是有序的,因此只需要将数据结果集当前游标指向的数据值进行排序即可。这相当于对多个有序的数组进行排序,归并排序是最适合此场景的排序算法。
-Sharding-Sphere在对排序的查询进行归并时,将每个结果集的当前数据值进行比较(通过实现Java的Comparable接口完成),并将其放入优先级队列。每次获取下一条数据时,只需将队列顶端结果集的游标下移,并根据新游标重新进入优先级排序队列找到自己的位置即可。通过一个例子来说明Sharding-Sphere的排序归并,下图是一个通过分数进行排序的示例图。
+Sharding-Sphere 在对排序的查询进行归并时,将每个结果集的当前数据值进行比较(通过实现 Java 的 Comparable
接口完成),并将其放入优先级队列。每次获取下一条数据时,只需将队列顶端结果集的游标下移,并根据新游标重新进入优先级排序队列找到自己的位置即可。通过一个例子来说明
Sharding-Sphere 的排序归并,下图是一个通过分数进行排序的示例图。
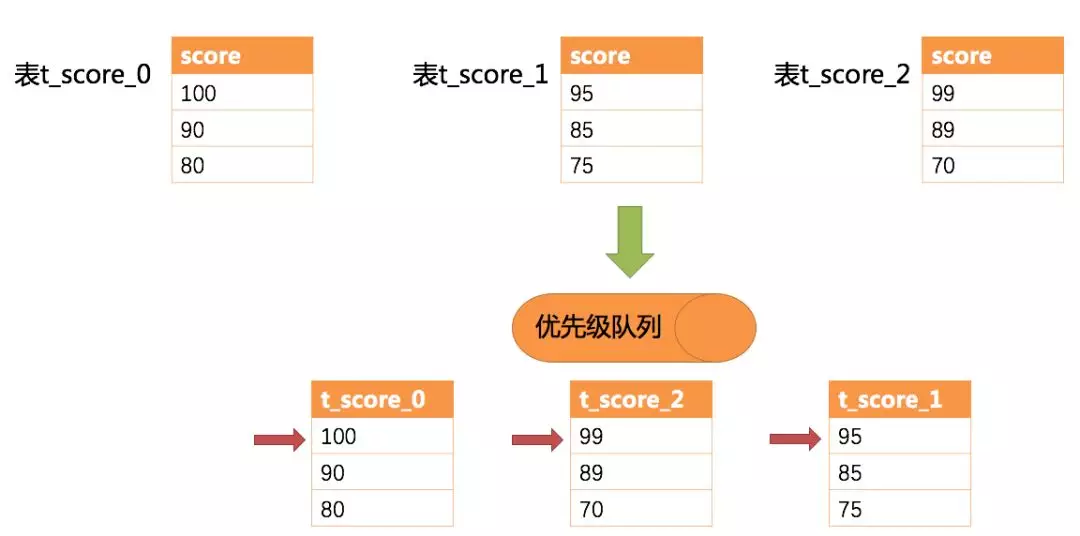
-示例中展示了3张表返回的数据结果集,每个数据结果集已经根据分数排序完毕,但是3个数据结果集之间是无序的。将3个数据结果集的当前游标指向的数据值进行排序,并放入优先级队列,t_score_0的第一个数据值最大,t_score_2的第一个数据值次之,t_score_1的第一个数据值最小,因此优先级队列根据t_score_0,t_score_2和t_score_1的方式排序队列。
+示例中展示了3张表返回的数据结果集,每个数据结果集已经根据分数排序完毕,但是 3 个数据结果集之间是无序的。将 3
个数据结果集的当前游标指向的数据值进行排序,并放入优先级队列,t_score_0 的第一个数据值最大,t_score_2
的第一个数据值次之,t_score_1 的第一个数据值最小,因此优先级队列根据 t_score_0,t_score_2 和 t_score_1 的方式排序队列。
-下图则展现了进行next调用的时候,排序归并是如何进行的。
+下图则展现了进行 next 调用的时候,排序归并是如何进行的。
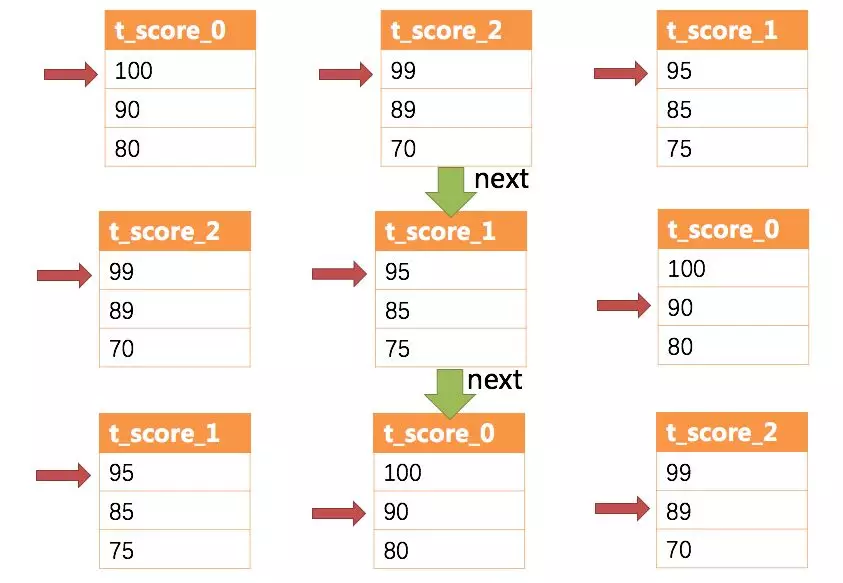
-通过图中我们可以看到,当进行第一次next调用时,排在队列首位的t\_score\_0将会被弹出队列,并且将当前游标指向的数据值(也就是100)返回至查询客户端,并且将游标下移一位之后,重新放入优先级队列。而优先级队列也会根据t\_score\_0的当前数据结果集指向游标的数据值(这里是90)进行排序,根据当前数值,t\_score\_0排列在队列的最后一位。之前队列中排名第二的t\_score\_2的数据结果集则自动排在了队列首位。
+通过图中我们可以看到,当进行第一次 next 调用时,排在队列首位的 t\_score\_0 将会被弹出队列,并且将当前游标指向的数据值(也就是
100)返回至查询客户端,并且将游标下移一位之后,重新放入优先级队列。而优先级队列也会根据 t\_score\_0 的当前数据结果集指向游标的数据值(这里是
90)进行排序,根据当前数值,t\_score\_0 排列在队列的最后一位。之前队列中排名第二的 t\_score\_2 的数据结果集则自动排在了队列首位。
-在进行第二次next时,只需要将目前排列在队列首位的t\_score\_2弹出队列,并且将其数据结果集游标指向的值返回至客户端,并下移游标,继续加入队列排队,以此类推。
+在进行第二次 next 时,只需要将目前排列在队列首位的 t\_score\_2
弹出队列,并且将其数据结果集游标指向的值返回至客户端,并下移游标,继续加入队列排队,以此类推。
@@ -68,19 +68,19 @@ Sharding-Sphere在对排序的查询进行归并时,将每个结果集的当
-可以看到,对于每个数据结果集中的数据有序,而多数据结果集整体无序的情况下,Sharding-Sphere无需将所有的数据都加在至内存即可排序,它使用的是流式归并的方式,每次next仅获取唯一正确的一条数据,极大的节省了内存的消耗。
+可以看到,对于每个数据结果集中的数据有序,而多数据结果集整体无序的情况下,Sharding-Sphere
无需将所有的数据都加在至内存即可排序,它使用的是流式归并的方式,每次 next 仅获取唯一正确的一条数据,极大的节省了内存的消耗。
-从另一个角度来说,Sharding-Sphere的排序归并,是在维护数据结果集的纵轴和横轴这两个维度的有序性。纵轴是指每个数据结果集本身,它是天然有序的,它通过包含ORDER
BY的SQL所获取。横轴是指每个数据结果集当前游标所指向的值,它需要通过优先级队列来维护其正确顺序。每一次数据结果集当前游标的下移,都需要将该数据结果集重新放入优先级队列排序,而只有排列在队列首位的数据结果集才可能发生游标下移的操作。
+从另一个角度来说,Sharding-Sphere
的排序归并,是在维护数据结果集的纵轴和横轴这两个维度的有序性。纵轴是指每个数据结果集本身,它是天然有序的,它通过包含 ORDER BY 的 SQL
所获取。横轴是指每个数据结果集当前游标所指向的值,它需要通过优先级队列来维护其正确顺序。每一次数据结果集当前游标的下移,都需要将该数据结果集重新放入优先级队列排序,而只有排列在队列首位的数据结果集才可能发生游标下移的操作。
#### 分组归并
-分组归并的情况最为复杂,它分为流式分组归并和内存分组归并。流式分组归并要求SQL的排序项与分组项的字段以及排序类型(ASC或DESC)必须保持一致,否则只能通过内存归并才能保证其数据的正确性。
+分组归并的情况最为复杂,它分为流式分组归并和内存分组归并。流式分组归并要求SQL的排序项与分组项的字段以及排序类型(ASC 或
DESC)必须保持一致,否则只能通过内存归并才能保证其数据的正确性。
-举例说明,假设根据科目分片,表结构中包含考生的姓名(为了简单起见,不考虑重名的情况)和分数。通过SQL获取每位考生的总分,可通过如下SQL:
+举例说明,假设根据科目分片,表结构中包含考生的姓名(为了简单起见,不考虑重名的情况)和分数。通过 SQL 获取每位考生的总分,可通过如下 SQL:

@@ -88,12 +88,12 @@ Sharding-Sphere在对排序的查询进行归并时,将每个结果集的当
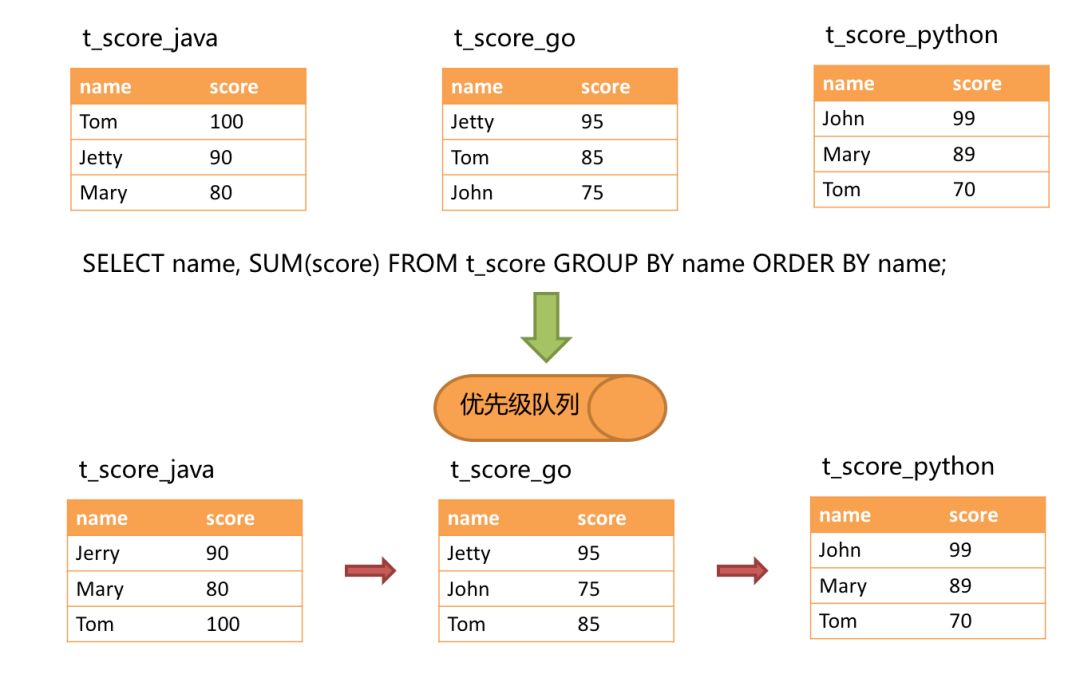
-进行归并时,逻辑与排序归并类似。下图展现了进行next调用的时候,流式分组归并是如何进行的。
+进行归并时,逻辑与排序归并类似。下图展现了进行 next 调用的时候,流式分组归并是如何进行的。
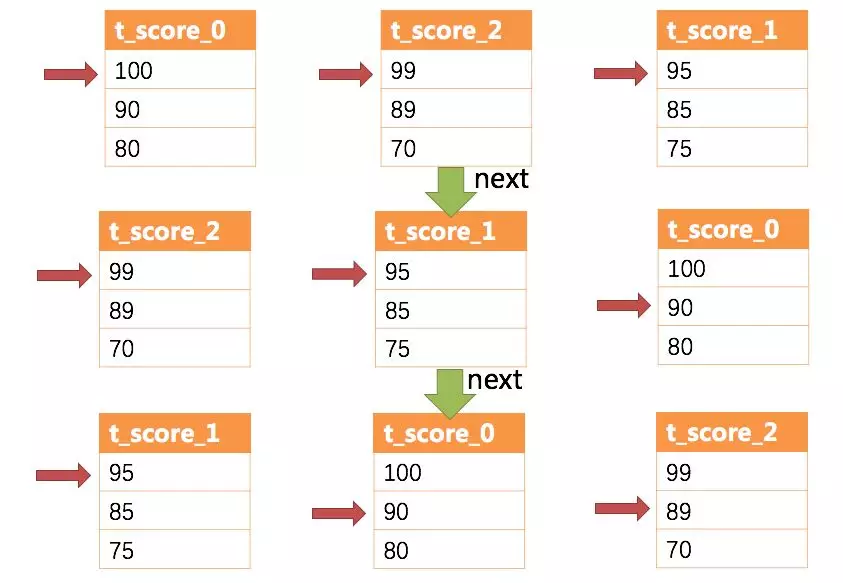
-通过图中我们可以看到,当进行第一次next调用时,排在队列首位的t\_score\_java将会被弹出队列,并且将分组值同为“Jetty”的其他结果集中的数据一同弹出队列。在获取了所有的姓名为“Jetty”的同学的分数之后,进行累加操作,那么,在第一次next调用结束后,取出的结果集是“Jetty”的分数总和。于此同时,所有的数据结果集中的游标都将下移至数据值“Jetty”的下一个不同的数据值,并且根据数据结果集当前游标指向的值进行重排序。因此,包含名字顺着第二位的“John”的相关数据结果集则排在的队列的前列。
+通过图中我们可以看到,当进行第一次 next 调用时,排在队列首位的 t\_score\_java
将会被弹出队列,并且将分组值同为“Jetty”的其他结果集中的数据一同弹出队列。在获取了所有的姓名为“Jetty”的同学的分数之后,进行累加操作,那么,在第一次
next
调用结束后,取出的结果集是“Jetty”的分数总和。于此同时,所有的数据结果集中的游标都将下移至数据值“Jetty”的下一个不同的数据值,并且根据数据结果集当前游标指向的值进行重排序。因此,包含名字顺着第二位的“John”的相关数据结果集则排在的队列的前列。
@@ -116,7 +116,7 @@ Sharding-Sphere在对排序的查询进行归并时,将每个结果集的当
-当SQL中只包含分组语句时,根据不同数据库的实现,其排序的顺序不一定与分组顺序一致。但由于排序语句的缺失,则表示此SQL并不在意排序顺序。因此,Sharding-Sphere通过SQL优化的改写,自动增加与分组项一致的排序项,使其能够从消耗内存的内存分组归并方式转化为流式分组归并方案。
+当SQL中只包含分组语句时,根据不同数据库的实现,其排序的顺序不一定与分组顺序一致。但由于排序语句的缺失,则表示此SQL并不在意排序顺序。因此,Sharding-Sphere
通过 SQL 优化的改写,自动增加与分组项一致的排序项,使其能够从消耗内存的内存分组归并方式转化为流式分组归并方案。
@@ -124,27 +124,27 @@ Sharding-Sphere在对排序的查询进行归并时,将每个结果集的当
-比较类型的聚合函数是指MAX和MIN。它们需要对每一个同组的结果集数据进行比较,并且直接返回其最大或最小值即可。
+比较类型的聚合函数是指 MAX 和 MIN。它们需要对每一个同组的结果集数据进行比较,并且直接返回其最大或最小值即可。
-累加类型的聚合函数是指SUM和COUNT。它们需要将每一个同组的结果集数据进行累加。
+累加类型的聚合函数是指 SUM 和 COUNT。它们需要将每一个同组的结果集数据进行累加。
-求平均值的聚合函数只有AVG。它必须通过SQL改写的SUM和COUNT进行计算,相关内容已在SQL改写的内容中涵盖,不再赘述。
+求平均值的聚合函数只有 AVG。它必须通过 SQL 改写的 SUM 和 COUNT 进行计算,相关内容已在SQL改写的内容中涵盖,不再赘述。
#### 分页归并
-上文所述的所有归并类型都可能进行分页。分页是追加在其他归并类型之上的装饰器,Sharding-Sphere通过装饰者模式来增加对数据结果集进行分页的能力。分页归并负责将无需获取的数据过滤掉。
+上文所述的所有归并类型都可能进行分页。分页是追加在其他归并类型之上的装饰器,Sharding-Sphere
通过装饰者模式来增加对数据结果集进行分页的能力。分页归并负责将无需获取的数据过滤掉。
-Sharding-Sphere的分页功能比较容易让使用者误解,用户通常认为分页归并会占用大量内存。在分布式的场景中,将LIMIT 10000000,
10改写为LIMIT 0,
10000010,才能保证其数据的正确性。用户非常容易产生Sharding-Sphere会将大量无意义的数据加载至内存中,造成内存溢出风险的错觉。其实,通过流式归并的原理可知,会将数据全部加载到内存中的只有内存分组归并这一种情况,而通常来说,进行OLAP的分组SQL,不会产生大量的结果数据,它更多的用于大量的计算,以及少量结果产出的场景。除了内存分组归并这种情况之外,其他情况都通过流式归并获取数据结果集,因此Sharding-Sphere会通过结果集的next方法将无需取出的数据全部跳过,并不会将其存入内存。
+Sharding-Sphere 的分页功能比较容易让使用者误解,用户通常认为分页归并会占用大量内存。在分布式的场景中,将LIMIT 10000000, 10
改写为 LIMIT 0, 10000010,才能保证其数据的正确性。用户非常容易产生 Sharding-Sphere
会将大量无意义的数据加载至内存中,造成内存溢出风险的错觉。其实,通过流式归并的原理可知,会将数据全部加载到内存中的只有内存分组归并这一种情况,而通常来说,进行
OLAP 的分组
SQL,不会产生大量的结果数据,它更多的用于大量的计算,以及少量结果产出的场景。除了内存分组归并这种情况之外,其他情况都通过流式归并获取数据结果集,因此
Sharding-Sphere 会通过结果集的 next 方法将无需取出的数据全部跳过,并不会将其存入内存。
-但同时需要注意的是,由于排序的需要,大量的数据仍然需要传输到Sharding-Sphere的内存空间。因此,采用LIMIT这种方式分页,并非最佳实践。
由于LIMIT并不能通过索引查询数据,因此如果可以保证ID的连续性,通过ID进行分页是比较好的解决方案,例如:
+但同时需要注意的是,由于排序的需要,大量的数据仍然需要传输到 Sharding-Sphere 的内存空间。因此,采用 LIMIT
这种方式分页,并非最佳实践。 由于 LIMIT 并不能通过索引查询数据,因此如果可以保证ID的连续性,通过ID进行分页是比较好的解决方案,例如:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}