I've just made a fairly significant optimisation to libcss's selection engine performance. It's now using more memory, but hopefully that's worth the extra speed. Please let me know how you get on with it.
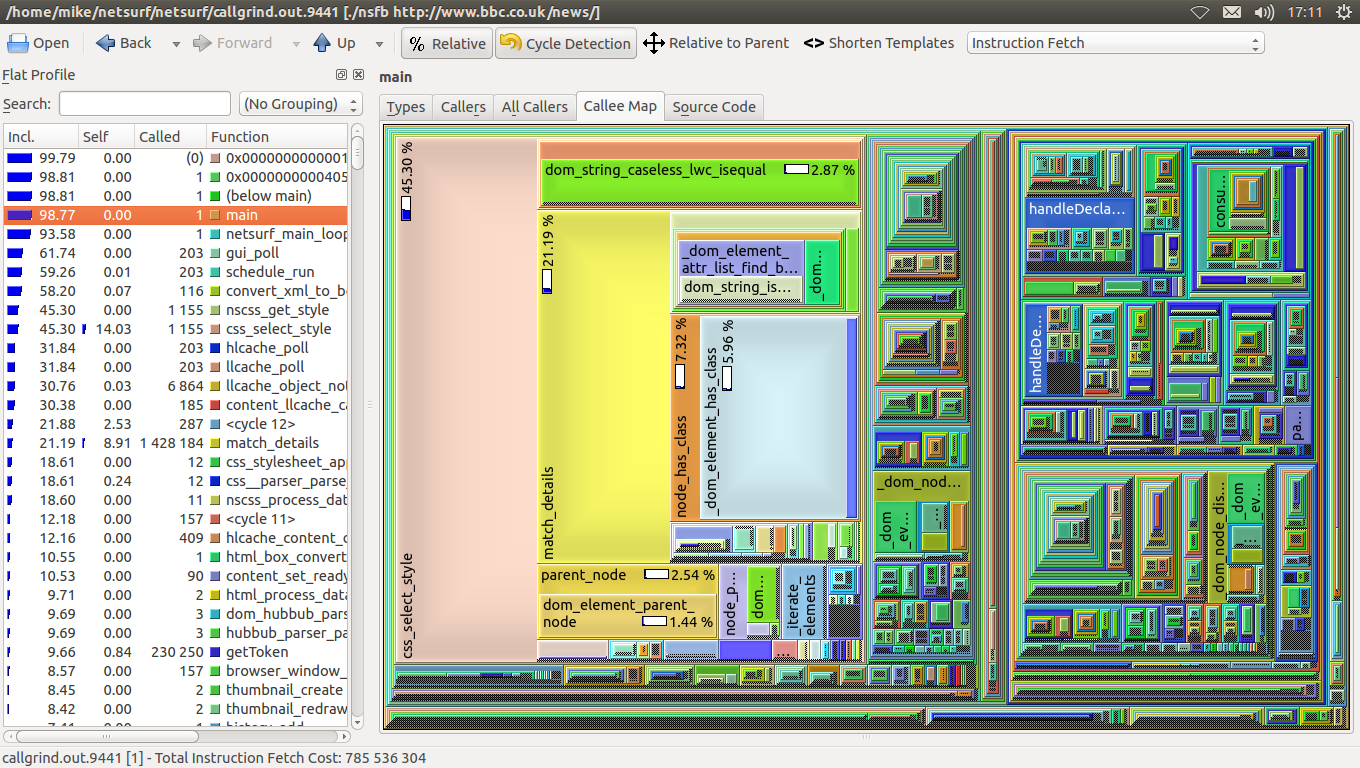
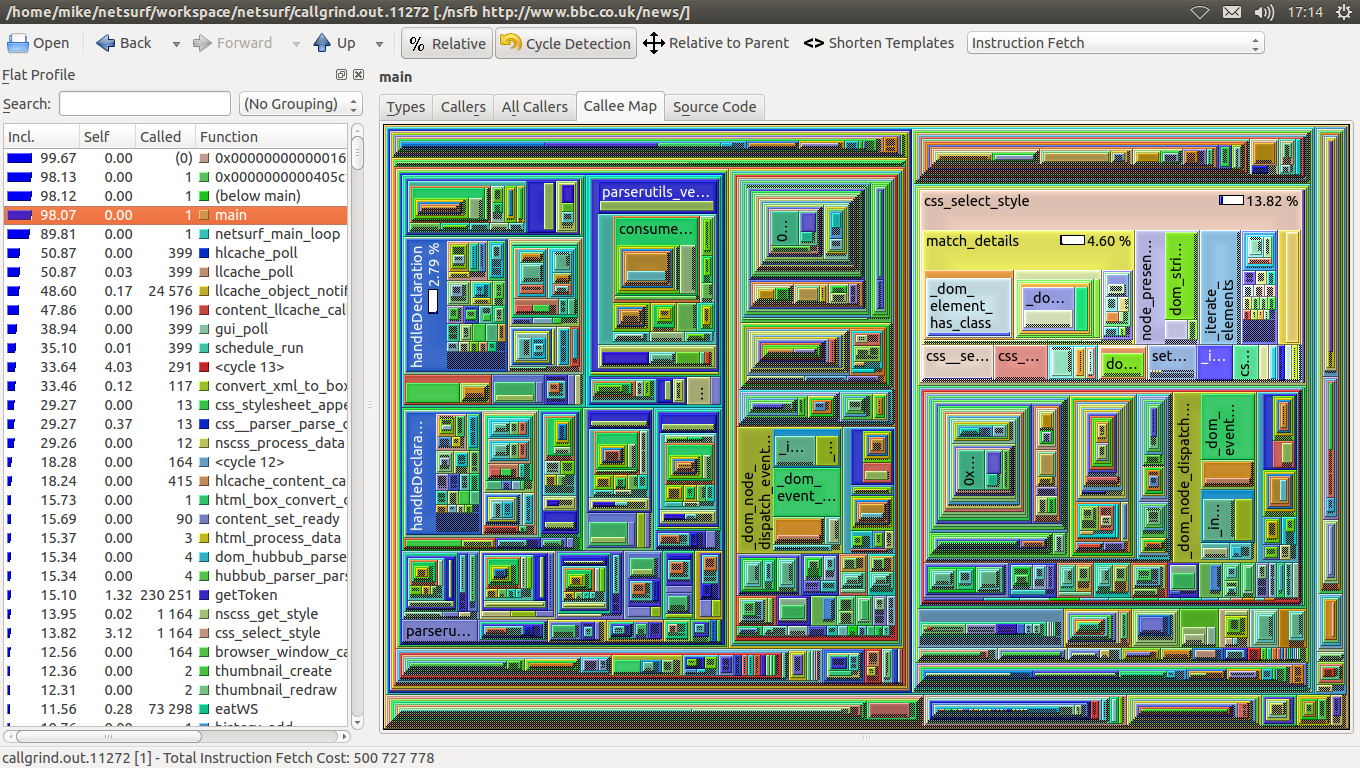
In brief, compare: Before: http://www.netsurf-browser.org/temp/sel-opt/before-bloom-main.png After: http://www.netsurf-browser.org/temp/sel-opt/bloom-04-main.png More info below. Skip to the "Selection optimisation" section if you already know why we were so slow before. How selection works ------------------- Take the following CSS rule from NetSurf's own web site: .navigation ul.languages li a:hover, .navigation ul.sitelinks li a:hover { display: block; color: #00f; padding: 0 0 0 0.2em; margin: 0; background: transparent; text-decoration: none; } It's a single rule with two selector chains. To determine whether to apply that rule the element node we're selecting for, at least one of the selector chains must match. Considering only the first selector chain, it's saying, "Match an 'a' element in the hover state who has an ancestor node which is an 'li' element who has an ancestor node which is a 'ul' element with the 'languages' class who has an ancestor node with the 'navigation' class." Libcss is able to ask the client (NetSurf) about element nodes via a series of callbacks. So to match a selector chain, libcss asks if the node being selected is an 'a' element. It then needs to ask wether the element has a ancestor of type 'li'. And so on. On the NetSurf side the callbacks are implemented with a bunch of calls to libdom to walk up the DOM tree to look for whatever libcss is enquiring after. Selection performance problem ----------------------------- CSS selection has been dominating NetSurf profiles for ages. For a site like http://www.bbc.co.uk/news/ at the current time there are 4366 selector chains to match for each of 1156 element nodes. We already had an optimisation whereby selector chains were hashed by the right most selector details. There are four hash tables for element name, class name, id name and finally for selector chains whose right most selector has no element name, class name or id name. However even with that selection is expensive. When launching framebuffer NetSurf with the BBC news homepage, and quitting as soon as the page finishes loading, over 45% of NetSurf's CPU usage is spent in the selection engine: http://www.netsurf-browser.org/temp/sel-opt/before-bloom-main.png Selection optimisation ---------------------- I've made two optimisations. The first is quite minor, though worthwhile. We skip selector chains which don't meet the following criteria: + The rule must have some bytecode, i.e. if the rule matches, there must be some style data to apply. + If the selector chain's right most selector specifies the element name, then the name of the element we're selecting for must be a match. + The rule must be applicable for the media type we're selecting for. I moved the testing for those so they happen a bit earlier. It's now done before we compare the rules that emerge from each of the selector chain hash itterators for specificity and rule index (to ensure they're applied in the correct order). The second optimisation is to generate bloom filters loosely describing node ancestry and selector chain ancestry requirements. In NetSurf, we now store a node bloom filter as user data on the libdom element nodes. This bloom filter is filled with all the node's ancestor element names, class names and id names. In libcss, for each selector chain, we store a bloom filter containing all the element/class/id names that follow an ancestor or parent, combinator (' ' or '+'). So for the first selector chain in the example rule above, we'd add the following strings to the bloom filter. "li" "languages" "ul" "navigation" To determine wether a selector chain can be ruled out without manually matching it, we simply have to see whether the selector chain bloom is a subset of the node bloom. This is a much faster operation. All the strings involved were already interned with libwapcaplet, so string hash values were already calculated and available. The size of the bloom filter can be set (at compile time) to either 4, 8, or 16 * uint32_t. I've commited it with CSS_BLOOM_SIZE of 4. That means 4 * 4 bytes per DOM node, and per selector chain. For the example of http://www.bbc.co.uk/news/ that's: DOM nodes: 16 * 1156 = 18,496 Bytes Selector chains: 16 * 4366 = 69,856 Bytes ------------ 88,352 Bytes The selector chain cost is shared between pages that share the same external stylesheets. However, there are over 20,000 element nodes alone for a page like: http://git.netsurf-browser.org/netsurf.git/tree/render/layout.c I have run tests with the larger bloom filters and it does reduce false positive rates, however I judge the overall improvement/cost ratio to be best with a CSS_BLOOM_SIZE of 4 at the moment. Test | Total Instruction Fetch Cost | In selection --------------+------------------------------+------------- Before bloom | 785,536,304 | 45.30% Bloom size 4 | 500,727,778 | 13.95% Bloom size 8 | 484,935,082 | 11.94% Bloom size 16 | 480,928,151 | 11.06% What's interesting is that from bloom size 4 to 16 there isn't a huge drop in total computation required, but the number of calls to match_details (used in matching selector chains manually) drops sharply: Test | match_details calls --------------+-------------------- Before bloom | 1,428,184 Bloom size 4 | 171,451 Bloom size 8 | 101,397 Bloom size 16 | 54,112 That shows that with a bloom size of 4, there are plenty of false positives, but the cost of testing bloom filters for being a subset is getting quite heavy with the longer filters. See the other profile results using the 8 and 16 settings: http://www.netsurf-browser.org/temp/sel-opt/ What next? ---------- I pushed my changes at this stage since they were showing a decent improvement, but there are some more things I plan to experiment with. I tried generating the selector chain bloom filters on the fly, which was quite costly, so they're currently stored with the selector chains. It may be faster to avoid generating selector chain bloom filters at all and walk the selector chain using css_bloom_has_hash on each relevant string. We could dismiss the selector chain as soon as css_bloom_has_hash returns false. -- Michael Drake (tlsa) http://www.netsurf-browser.org/
{kind=link}
{kind=link}