Hi James,
We see the same incredible noise from a few peers we have at RouteViews.
So much so that they put quite a stress on our backend infrastructure
(not only the collector itself, but the syncing of these updates back to
our archive, and storage.) And, longer term, do researchers who use
RouteViews data want us to keep this noise for ever and ever in our
archive, as it consumes Tbytes of compressed disk space...
And yes, like you, we reach out to the providers of the incredible
noise, and they are usually unresponsive (PeeringDB contact entries are
for what exactly I wonder). I feel your pain!! So we have to take the
(for us) drastic step of shutting down the peer - we have to keep
RouteViews useful and usable for the community, as we have been trying
to do for the (almost) last 30 years. Of course, some folks want to
study the incredible noise too, but ultimately none of it really helps
keep the Internet infrastructure stable.
I guess all we can do is keep highlighting the problem (I highlight
Geoff's BGP Update report almost every BGP Best Practice training I run
here in AsiaPac, for example) - but how to make noisy peers go away,
longer term...? :-(
philip
--
James Bensley wrote on 9/2/2025 23:43:
Hi Romain,
I have been looking at prefixes with large numbers of updates for a few years
now. As Geoff pointed out, this is a long running problem and it’s not one that
is going to (ever?) go away.
I have auto-generated daily reports of general pollution seen in the DFZ from
the previous day, which can be found here:
https://github.com/DFZ-Name-and-Shame/dnas_stats [1].
Geoff pointed out “when a prefix is being updated 33,000 times in 145 days its
basically being updated as fast as many BGP implementations will let you”,
however, there are peers generating millions of updates *per day* for the same
prefix! There are multiple issues here which need to be unpacked to fully
understand what’s going on…
* Sometimes BGP updates a prefix as fast as BGP allows (this is what Geoff has
pointed out). This could be for a range of reasons like a flapping link, or a
redistribution issue.
* Sometimes there is a software bug in BGP which re-transmits the update as
fast as TCP allows. Here is an example prefix in a daily report, which was
present in 4M updates, from a single peer of a single route collector:
https://github.com/DFZ-Name-and-Shame/dnas_stats/blob/main/2023/03/15/20230315.txt#L607
The ASN a few lines below has almost exactly the same number of BGP
advertisements for that day: AS394119 (also that name,
EXPERIMENTAL-COMPUTING-FACILITY, feels like a bit of a smoking gun!). Using a
looking glass we can confirm that 394119 is the origin of that prefix:
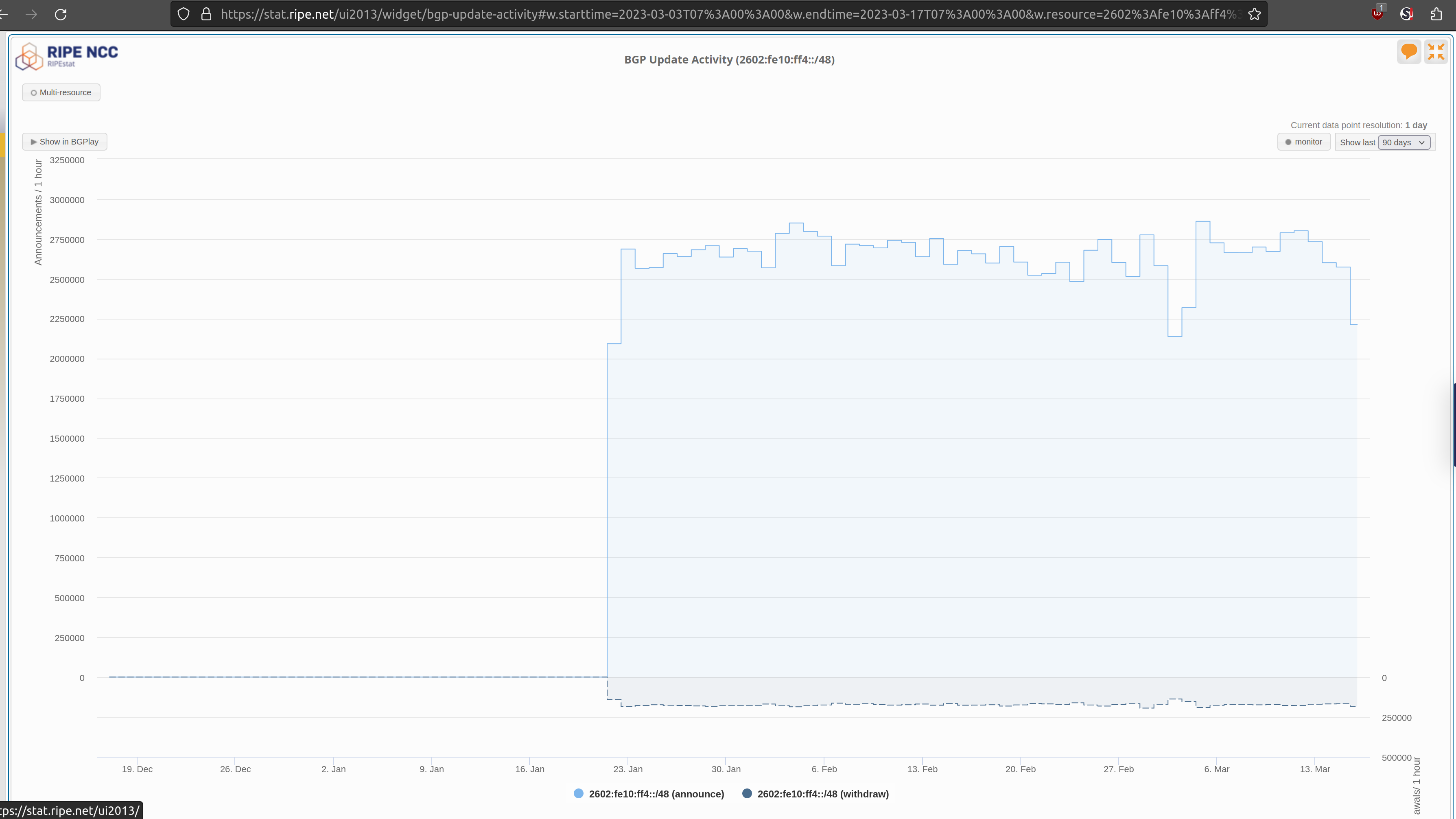
https://stat.ripe.net/widget/looking-glass#w.resource=2602:fe10:ff4::/48
Here is a screenshot from RIPE Stat at the same time, where they are recording
nearly 30M updates for the same prefix per day:
https://null.53bits.co.uk/uploads/images/networking/internetworking/ripe-prefix-count.png
The difference is that the 30M number is across all RIPE RIS collectors. I have
tried to de-dupe in my daily report and just choose the highest value from a
single collector. ~4M updates per day is ~46 updates per second. So this is a
BGP speaker stuck in an infinite loop sending an update as fast as it can and
for some reason, and not registering in it’s internal state engine that the
update has been sent.
I’ve reach out to a few ASNs who’ve shown up in my daily reports for excessive
announcements, and what I have seen is that sometimes it’s the ASN peering with
the RIS collector, or sometimes it’s an ASN the route collector peer is
peering with. In multiple cases, they have simply bounced their BGP session
with their peer or with the collector, and the issues has gone away.
* Sometimes a software bug causes the state of a route to falsely change. As an
example of this, there was a bug in Cisco’s IOS-XR. If you were running soft
reconfiguration inbound and RPKI, I think any RPKI state changes (to any
prefix) was causing a route refresh. Or something like that. It’s been a couple
of years, but you needed this specific combination of features, and IOS-XR was
just churning out updates like it’s life depended on it. I reached out to an
ASN who showed up in my daily report, they confirmed they had this bug, and
eventually they fixed in.
* These problems aren’t DFZ wide. Peer A might be sending a bajillion updates
to peer B, but peer B sees there is no change in the route and correctly
doesn’t forward the update onwards to it’s peers / public collectors. So this
is probably happing a lot more than we see via RIS or RouteViews. Only some
parts of the DFZ will be receiving the gratuitous updates/withdraws.
I recall there was a conversation either here on NANOG or maybe it was at the
IETF, within the last few years, about different NOSes that were / were not
correctly identifying route updates received with no changes to the existing
RIB entry, and [not] forwarding the update onwards. I’m not sure what came of
this.
* Some people aren’t monitoring and alerting based on CPU usage. There are plenty
of old rust buckets connected to the DFZ who’s CPUs will be on fire as a result of
a buggy peer and the operator is simply unaware. Some people are running cutting
edge devices with 12 cores at 3Ghz and 64GBs of RAM, for which all this churn is
no problem, so even if their CPU usage is monitored, it will be one core at 100%
but the rest nearly idle, and crappy monitoring software will aggregate this and
report the device has having <10% usage and operators think everything is fine.
* There are no knobs in existing BGP implementations to detect and limit this
behaviour in anyway.
If you end contacting the operators of the ASNs in your original email, and
getting this problem fixed, I’d be interested to know what the cause was in
those cases. I’ve all but given up contacting operators that show up in my
daily reports. It’s an endless endeavour, and some operators simply don’t
respond to my multiple emails (also, I have a day job, and a personal life, and
I also like sleeping and eating from time to time).
With kind regards,
James.
[1] It stopped working recently, so it’s now "catching-up", which is why the
data is a few days behind.
{kind=link}