On Mon, 19 Dec 2016 14:58:26 -0800 Dave Hansen <[email protected]> wrote:
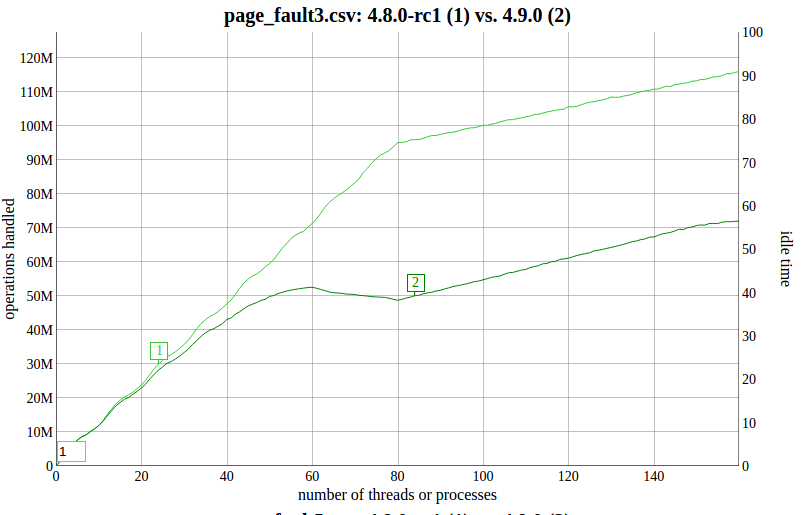
> I saw a 4.8->4.9 regression (details below) that I attributed to: > > 9dcb8b685f mm: remove per-zone hashtable of bitlock waitqueues > > That commit took the bitlock waitqueues from being dynamically-allocated > per-zone to being statically allocated and global. As suggested by > Linus, this makes them per-node, but keeps them statically-allocated. > > It leaves us with more waitqueues than the global approach, inherently > scales it up as we gain nodes, and avoids generating code for > page_zone() which was evidently quite ugly. The patch is pretty darn > tiny too. > > This turns what was a ~40% 4.8->4.9 regression into a 17% gain over > what on 4.8 did. That gain is a _bit_ surprising, but not entirely > unexpected since we now get much simpler code from no page_zone() and a > fixed-size array for which we don't have to follow a pointer (and get to > do power-of-2 math). > > This boots in a small VM and on a multi-node NUMA system, but has not > been tested widely. It definitely needs to be validated to make sure > it properly initialzes the new structure in the various node hotplug > cases before anybody goes applying it. > > Original report below (sent privately by accident). > > include/linux/mmzone.h | 5 +++++ > kernel/sched/core.c | 16 ---------------- > mm/filemap.c | 22 +++++++++++++++++++++- > mm/page_alloc.c | 5 +++++ > 4 files changed, 31 insertions(+), 17 deletions(-) > > --- > > I'm seeing a 4.8->4.9 regression: > > > https://www.sr71.net/~dave/intel/2016-12-19-page_fault_3.processes.png > > This is on a 160-thread 8-socket system. The workloads is a bunch of > processes faulting in pages to separate MAP_SHARED mappings: > > > https://github.com/antonblanchard/will-it-scale/blob/master/tests/page_fault3.c > > The smoking gun in the profiles is that __wake_up_bit() (called via > unlock_page()) goes from ~1% to 4% in the profiles. > > The workload is pretty maniacally touching random parts of the > waitqueue, and missing the cache heavily. Now that it is shared, I > suspect we're transferring cachelines across node boundaries in a way > that we were not with the per-zone waitqueues. > > This is *only* showing up with MAP_SHARED pages, not with anonymous > pages. I think we do a lock_page()/unlock_page() pair in > do_shared_fault(), which we avoid in the anonymous case. Reverting: > > 9dcb8b685f mm: remove per-zone hashtable of bitlock waitqueues > > restores things to 4.8 behavior. The fact that automated testing didn't > catch this probably means that it's pretty rare to find hardware that > actually shows the problem, so I don't think it's worth reverting > anything in mainline. I've been doing a bit of testing, and I don't know why you're seeing this. I don't think I've been able to trigger any actual page lock contention so nothing gets put on the waitqueue to really bounce cache lines around that I can see. Yes there are some loads to check the waitqueue, but those should be cached read shared among CPUs so not cause interconnect traffic I would have thought. After testing my PageWaiters patch, I'm maybe seeing 2% improvment on this workload (although powerpc doesn't do so well on this one due to virtual memory management overheads -- maybe x86 will show a bit more) But the point is that after this, there should be no waitqueue activity at all. I haven't chased up a system with a lot of IOPS connected that would be needed to realistically test contended cases (which I thought I needed to show an improvement from per-node tables, but your test suggests not...) Thanks, Nick > > ut, the commit says: > > > As part of that earlier discussion, we had a much better solution for > > the NUMA scalability issue - by just making the page lock have a > > separate contention bit, the waitqueue doesn't even have to be looked at > > for the normal case. > > So, maybe we should do that moving forward since we at least found one > case that's pretty aversely affected. > > Cc: Andreas Gruenbacher <[email protected]> > Cc: Bob Peterson <[email protected]> > Cc: Mel Gorman <[email protected]> > Cc: Peter Zijlstra <[email protected]> > Cc: Andy Lutomirski <[email protected]> > Cc: Steven Whitehouse <[email protected]> > Cc: Linus Torvalds <[email protected]> > > --- > > b/include/linux/mmzone.h | 5 +++++ > b/kernel/sched/core.c | 16 ---------------- > b/mm/filemap.c | 22 +++++++++++++++++++++- > b/mm/page_alloc.c | 5 +++++ > 4 files changed, 31 insertions(+), 17 deletions(-) > > diff -puN include/linux/mmzone.h~static-per-zone-waitqueue > include/linux/mmzone.h > --- a/include/linux/mmzone.h~static-per-zone-waitqueue 2016-12-19 > 11:35:12.210823059 -0800 > +++ b/include/linux/mmzone.h 2016-12-19 13:11:53.335170271 -0800 > @@ -27,6 +27,9 @@ > #endif > #define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1)) > > +#define WAIT_TABLE_BITS 8 > +#define WAIT_TABLE_SIZE (1 << WAIT_TABLE_BITS) > + > /* > * PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed > * costly to service. That is between allocation orders which should > @@ -662,6 +665,8 @@ typedef struct pglist_data { > unsigned long min_slab_pages; > #endif /* CONFIG_NUMA */ > > + wait_queue_head_t wait_table[WAIT_TABLE_SIZE]; > + > /* Write-intensive fields used by page reclaim */ > ZONE_PADDING(_pad1_) > spinlock_t lru_lock; > diff -puN kernel/sched/core.c~static-per-zone-waitqueue kernel/sched/core.c > --- a/kernel/sched/core.c~static-per-zone-waitqueue 2016-12-19 > 11:35:12.212823149 -0800 > +++ b/kernel/sched/core.c 2016-12-19 11:35:12.225823738 -0800 > @@ -7509,27 +7509,11 @@ static struct kmem_cache *task_group_cac > DECLARE_PER_CPU(cpumask_var_t, load_balance_mask); > DECLARE_PER_CPU(cpumask_var_t, select_idle_mask); > > -#define WAIT_TABLE_BITS 8 > -#define WAIT_TABLE_SIZE (1 << WAIT_TABLE_BITS) > -static wait_queue_head_t bit_wait_table[WAIT_TABLE_SIZE] __cacheline_aligned; > - > -wait_queue_head_t *bit_waitqueue(void *word, int bit) > -{ > - const int shift = BITS_PER_LONG == 32 ? 5 : 6; > - unsigned long val = (unsigned long)word << shift | bit; > - > - return bit_wait_table + hash_long(val, WAIT_TABLE_BITS); > -} > -EXPORT_SYMBOL(bit_waitqueue); > - > void __init sched_init(void) > { > int i, j; > unsigned long alloc_size = 0, ptr; > > - for (i = 0; i < WAIT_TABLE_SIZE; i++) > - init_waitqueue_head(bit_wait_table + i); > - > #ifdef CONFIG_FAIR_GROUP_SCHED > alloc_size += 2 * nr_cpu_ids * sizeof(void **); > #endif > diff -puN mm/filemap.c~static-per-zone-waitqueue mm/filemap.c > --- a/mm/filemap.c~static-per-zone-waitqueue 2016-12-19 11:35:12.215823285 > -0800 > +++ b/mm/filemap.c 2016-12-19 14:51:23.881814379 -0800 > @@ -779,6 +779,26 @@ EXPORT_SYMBOL(__page_cache_alloc); > #endif > > /* > + * We need 'nid' because page_waitqueue() needs to get the waitqueue > + * for memory where virt_to_page() does not work, like highmem. > + */ > +static wait_queue_head_t *__bit_waitqueue(void *word, int bit, int nid) > +{ > + const int shift = BITS_PER_LONG == 32 ? 5 : 6; > + unsigned long val = (unsigned long)word << shift | bit; > + > + return &NODE_DATA(nid)->wait_table[hash_long(val, WAIT_TABLE_BITS)]; > +} > + > +wait_queue_head_t *bit_waitqueue(void *word, int bit) > +{ > + const int __maybe_unused nid = page_to_nid(virt_to_page(word)); > + > + return __bit_waitqueue(word, bit, nid); > +} > +EXPORT_SYMBOL(bit_waitqueue); > + > +/* > * In order to wait for pages to become available there must be > * waitqueues associated with pages. By using a hash table of > * waitqueues where the bucket discipline is to maintain all > @@ -790,7 +810,7 @@ EXPORT_SYMBOL(__page_cache_alloc); > */ > wait_queue_head_t *page_waitqueue(struct page *page) > { > - return bit_waitqueue(page, 0); > + return __bit_waitqueue(page, 0, page_to_nid(page)); > } > EXPORT_SYMBOL(page_waitqueue); > > diff -puN mm/page_alloc.c~static-per-zone-waitqueue mm/page_alloc.c > --- a/mm/page_alloc.c~static-per-zone-waitqueue 2016-12-19 > 11:35:12.219823466 -0800 > +++ b/mm/page_alloc.c 2016-12-19 13:10:56.587613213 -0800 > @@ -5872,6 +5872,7 @@ void __paginginit free_area_init_node(in > pg_data_t *pgdat = NODE_DATA(nid); > unsigned long start_pfn = 0; > unsigned long end_pfn = 0; > + int i; > > /* pg_data_t should be reset to zero when it's allocated */ > WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx); > @@ -5892,6 +5893,10 @@ void __paginginit free_area_init_node(in > zones_size, zholes_size); > > alloc_node_mem_map(pgdat); > + > + /* per-node page waitqueue initialization: */ > + for (i = 0; i < WAIT_TABLE_SIZE; i++) > + init_waitqueue_head(&pgdat->wait_table[i]); > #ifdef CONFIG_FLAT_NODE_MEM_MAP > printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, > node_mem_map %08lx\n", > nid, (unsigned long)pgdat, > _ > > -- > To unsubscribe, send a message with 'unsubscribe linux-mm' in > the body to [email protected]. For more info on Linux MM, > see: http://www.linux-mm.org/ . > Don't email: <a href=mailto:"[email protected]";> [email protected] </a>
{kind=link}