Hi John, Currently jQuery don't have caching functions, wouldn't it be great if we add it?
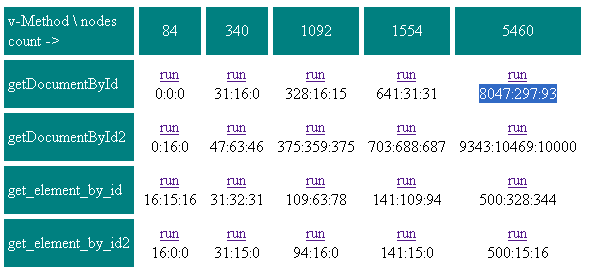
On 6月22日, 下午10時33分, "John Resig" <[EMAIL PROTECTED]> wrote: > Dimitii - > > test_results.PNG > 14K檢視下載 > > Those results are really interesting - you should post them to the jQuery > Dev list (where we discuss issues like selector speed). > > More information about the list can be found > here:http://docs.jquery.com/Discussion > > --John > > On 6/22/07, Dmitrii 'Mamut' Dimandt <[EMAIL PROTECTED]> wrote: > > > > > > > The original is in Russian: > >http://blogs.gotdotnet.ru/personal/poigraem/PermaLink.aspx?guid=88FEC... > > > Here's a quick translation: > > ------------------------ > > We've hit a problem where getElementById is working slowly on a _very_ > > large page > > > After some research we've found out some interesting facts > > > - Speed of getElementById depends on the length of ids. Tests have shown > > that for two identical documents, one with ids like aXXXX, another with ids > > like , the speed of getElementById would > > differ by a factor of two. This is especially important for ASP.NET pages > > which usually have long ids > > > - There are fast methods and slow methods: > > -- Fast > > ---- parentNode > > ---- nextSibling > > ---- ownerDocument > > ---- firstChild > > -- Slow > > ---- previousSibling > > ---- getElementById > > ---- lastChild > > > The getElemenByTagName has a paradox. It returns the list of elements very > > quickly. However, access to elements from that list is very slow. It feels > > as if it were returning a proxy of sorts. > > > In a large tree it's faster to collect a hash of all element ids than use > > getElementById. This may look like this: > > [code] > > > function build_document_id_map() > > { > > var r = document; > > map = {} > > build_id_map( r, map ) > > return map > > } > > > function build_id_map( node, map ) > > { > > for ( var e = node.firstChild; e != null; e = e.nextSibling ) > > { > > if ( e.id ) map[ e.id ] = e; > > if (e.firstChild ) build_id_map( e, map ) > > } > > } > > > var cache; > > function get_element_by_id( id ) > > { > > if ( !cache ) > > cache = build_document_id_map(id) > > return cache[id]; > > } > > > [/code] > > > To test this, you may use the test I wrote: > >http://files.rsdn.ru/11521/test.htm > > > For each type of element access the test prepares test data anew and runs > > the test three times. These three times appear in the table in milliseconds > > > *getDocumentById -* find all nodes through getDocumentById > > > *getDocumentById2 -* same, but after the test is run there is a small DOM > > manipulation in the end. See below for explanation of the test. > > > *get_element_by_id* - find all nodes using the get_element_by_id > > described above. The ids cache is cleared every time before the test is run. > > > *get_element_by_id2* - same, but the cache is not cleared. Expect to see > > speed increase in the second and the third run. > > Here's the table of results for my FF: > >http://files.rsdn.ru/11521/test_results.PNG > > [image: Test results for FF] > > > Note that FF caches results of getDocumentById and in the first test the > > second and the third pass are much faster than the first one. But as soon as > > we manipulate the DOM even a little, the cache is reset, as we see it in the > > second test > > > I'm not going to comment on the third and the fourth test, the numbers > > speak for themselves. I'm going to talk about disadvantages > > > The method works well for a static tree. If the tree is being changed, > > there's problems with adding/removing elements. The problem of adding > > elements can easily be solved by: > > > function get_element_by_id( id ) > > { > > if ( !cache ) > > cache = build_document_id_map( id ) > > if( !cache[id] ) > > cache[id] = document.getElementById( id ); > > return cache[id]; > > } > > > Removal of elements in this case can only be done by a special method > > which will correct the cache. In this case you can forget about > > > someElem.innerHTML = ""; > > > if you wish to remove a large portion of the tree > > ------------------------- 隱藏被引用文字 - > > - 顯示被引用文字 -
{kind=link}