[
https://issues.apache.org/jira/browse/KAFKA-19943?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=18043261#comment-18043261
]
Uladzislau Blok commented on KAFKA-19943:
-----------------------------------------
Thanks for the clarification.
Unfortunately I can't provide logs here, but after analysis of log with
teammate I can see that:
* We rebuild state store starting from local file checkpoint offset 4285116
until last offset on partition 4622401 (checkpoint was from two months old)
* There was no errors/warns in logs
I think our case is kinda specific and we often could have entities in state
store for very long period of time.
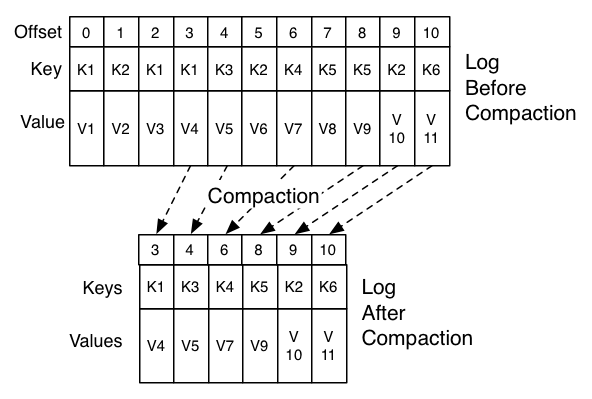
According to this diagram:
!https://docs.confluent.io/_images/log_compaction.png!
If message wasn't remove after compaction it keeps it's offset, and I think
that the root cause here. In our case it's likely that checkpoint file was
pointing to offset from two month old, but entity on this offset never was
removed and offset was available. That's the reason why KS never saw
OFFSET_OUT_OF_RANGE
> Stale values in State Store after tombstone was compacted
> ---------------------------------------------------------
>
> Key: KAFKA-19943
> URL: https://issues.apache.org/jira/browse/KAFKA-19943
> Project: Kafka
> Issue Type: Bug
> Components: streams
> Affects Versions: 3.9.1, 4.1.1
> Reporter: Uladzislau Blok
> Priority: Major
>
> h3. *Summary*
> When a Kafka Streams application with a local *state store* (backed by
> RocksDB) restarts after a period exceeding the changelog topic's
> {*}{{delete.retention.ms}}{*}, it can lead to previously deleted entities
> "magically" reappearing. This happens because the *tombstones* required to
> mark these deletions are no longer present in the compacted changelog topic.
> ----
> h3. *Details and Observed Behavior*
> The issue typically occurs in environments without *shared storage* for state
> stores (like Kubernetes with local volumes) after a *failover* or prolonged
> shutdown.
> * *Original Instance:* An entity is processed and subsequently
> {*}deleted{*}. A *tombstone* (a record with a null value) is written to the
> state store's compacted changelog topic.
> * *Downtime/Failover:* The original instance is shut down, and a new
> instance (or pod) starts after a period longer than the changelog topic's
> {{{}delete.retention.ms{}}}.
> * *Tombstone Removal:* Since the tombstone has aged past
> {{{}delete.retention.ms{}}}, the Kafka broker removes it during log
> compaction.
> * *Restart and Rehydration:*
> ** If *RocksDB files are not present* -> The new instance starts with its
> own, empty local RocksDB. It begins to *rebuild* its state store by consuming
> the compacted changelog topic.
> ** If {*}RocksDB files are present{*}, Kafka Streams starts to rebuild state
> based on the local checkpoint. This is fine until it encounters entities
> older than the configured {{delete.retention.ms}}
> * *The Bug:* The deleted entity's key, while removed from the changelog, may
> still exist in the local RocksDB of the _old_ (now failed-over) instance.
> Critically, if the old instance was running a long time ago, the key/value
> pair might have existed _before_ the deletion. Since the *tombstone* is gone,
> there is nothing in the changelog to tell the new instance to *delete* that
> key. From my POV, in this case *local files can't be source of truth*
> * *Symptom:* The previously deleted entity is unexpectedly revived in the
> new state store. We observed this because a {*}punctuator{*}, which scans the
> {*}entire state store{*}, began processing these revived, outdated entities.
>
> ----
> h3. *Reproduce issue*
> I was able to reproduce an issue, while doing local testing with state store
> and aggressive compaction config
> Entire changelog topic:
> {code:java}
> /opt/kafka/bin $ ./kafka-console-consumer.sh --bootstrap-server
> localhost:9092 --topic ks-state-store-issue-1-example-state-store-changelog
> --property "print.key=true" -- from-beginning
> 10 string10
> 12 string12
> 6 null
> 9 null
> 3 m
> 2 b
> 7 c
> 5 null
> 11 null
> 13 string13
> 4 y
> 10 null
> 3 g
> 2 m
> 7 we
> 4 o
> 7 jh
> 7 yt
> 7 vbx
> 7 kgf
> 7 cbvn {code}
> There is no entity with key: *1*
> Application logs:
> {code:java}
> 15:29:27.311
> [ks-state-store-issue-1-473580d9-4588-428b-a01e-8b5a9dbddf56-StreamThread-1]
> WARN org.bloku.SaveAndLogProcessor - Read from state store KV: KeyValue(13,
> string13)
> 15:29:27.311
> [ks-state-store-issue-1-473580d9-4588-428b-a01e-8b5a9dbddf56-StreamThread-1]
> WARN org.bloku.SaveAndLogProcessor - Read from state store KV: KeyValue(4, o)
> 15:29:27.608
> [ks-state-store-issue-1-473580d9-4588-428b-a01e-8b5a9dbddf56-StreamThread-2]
> WARN org.bloku.SaveAndLogProcessor - Read from state store KV: KeyValue(1,
> n) {code}
> *Read from state store KV: KeyValue(1, n)*
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
{kind=link}