[
https://issues.apache.org/jira/browse/FLINK-37161?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17929029#comment-17929029
]
xingbe commented on FLINK-37161:
--------------------------------
The above test cases have been sequentially verified.
For test cases 1, 3, 4, and 5, it has been verified that the skewed join can
handle join skew issues as expected.
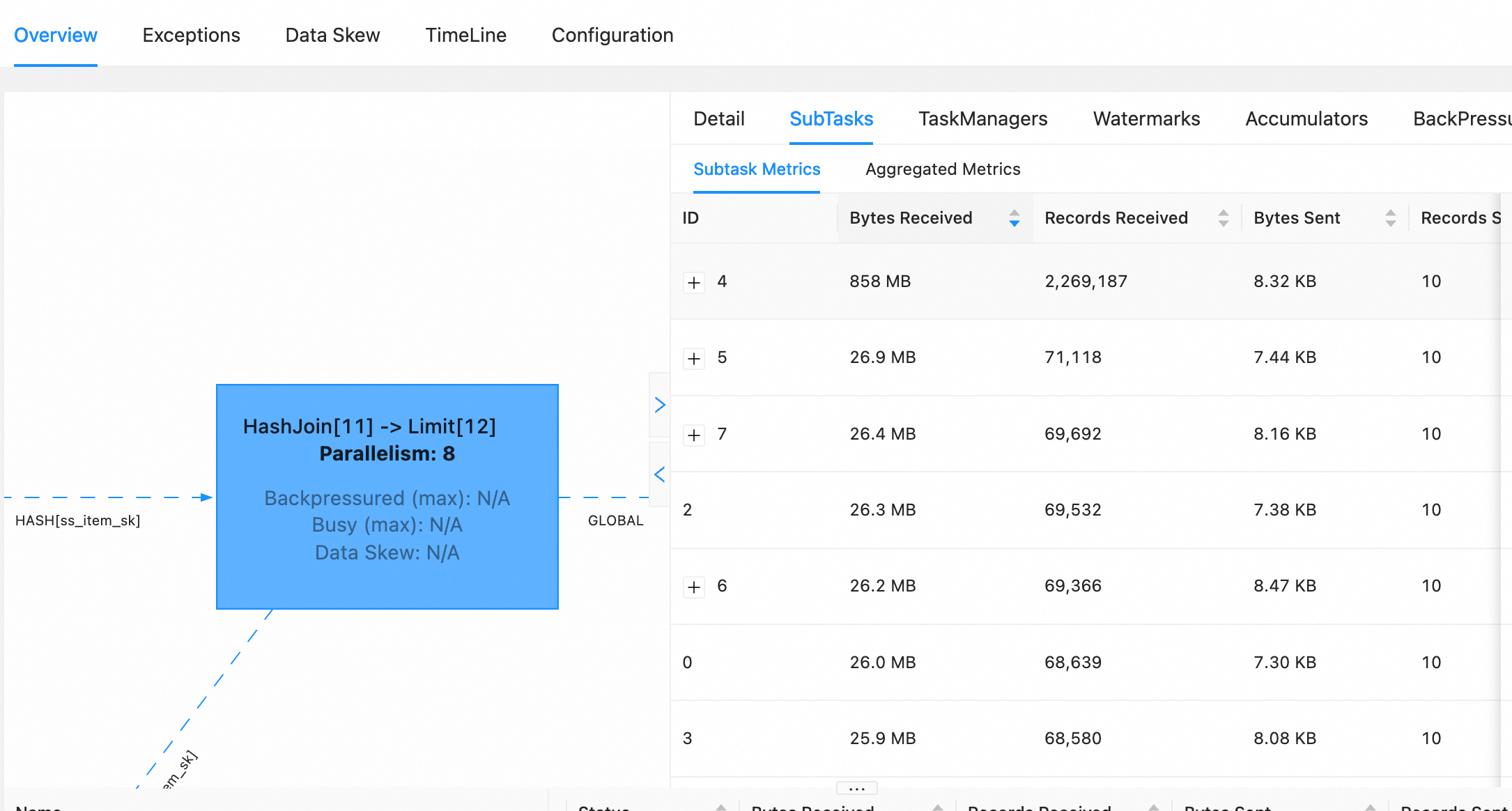
For example, the data distribution before optimization is:
!https://static.dingtalk.com/media/lQLPJxH9h4tniDfNBIzNCHqw9SDlZWw_GjwHmzXkALzlAQ_2170_1164.png|width=355,height=191!
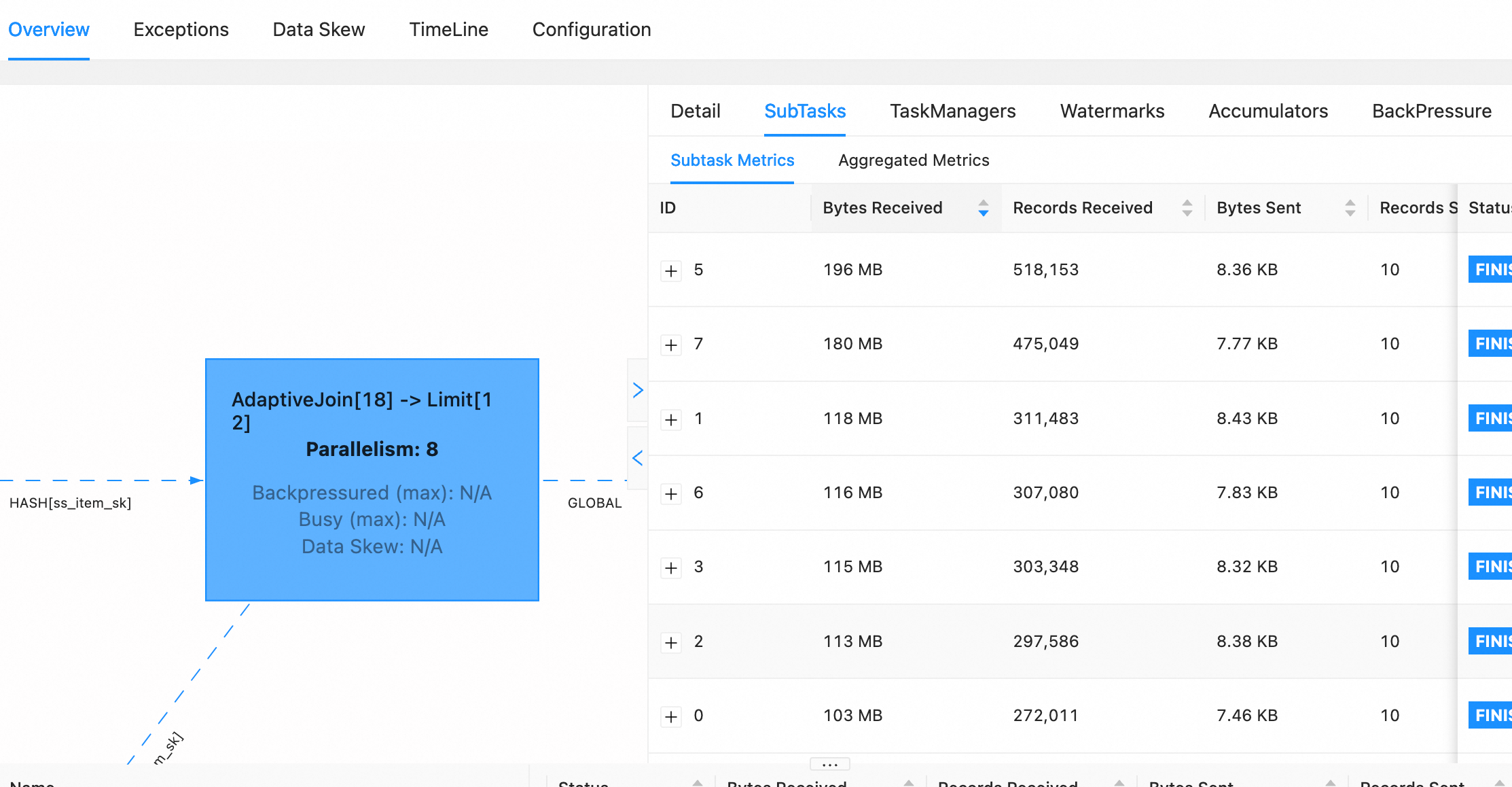
and the data distribution after optimization is:
!https://static.dingtalk.com/media/lQLPJxDsrln4yDfNBIbNCLKwBUSGUGCqbGQHmzXkALzlAA_2226_1158.png|width=362,height=188!
But for test case 2, when there is an aggregation node with the same hash key
downstream of the join node, it was found that the Join operator cannot be
converted into an AdaptiveJoin operator.
> Cross-team verification for "Adaptive skewed join optimization for batch jobs"
> ------------------------------------------------------------------------------
>
> Key: FLINK-37161
> URL: https://issues.apache.org/jira/browse/FLINK-37161
> Project: Flink
> Issue Type: Sub-task
> Reporter: Junrui Lee
> Assignee: xingbe
> Priority: Blocker
> Fix For: 2.0.0
>
>
> In Flink 2.0, we support the capability of adaptive skewed join optimization
> for batch jobs, which will allow the Join operator to dynamically split
> skewed and splittable partitions based on runtime input statistics, thereby
> mitigating the long-tail problem caused by skewed data.
> We may need the following tests:
> #
> Test the case where {{table.optimizer.skewed-join-optimization.strategy}} is
> set to {{{}auto{}}}. We need to construct a simple join case with data skewed
> on a single key (e.g., making the data of a specified join key N times larger
> than other join keys, where N is defined by
> {{{}table.optimizer.skewed-join-optimization.skewed-factor{}}}). And ensuring
> the data volume for the skewed join key exceeds the skewed-threshold (defined
> by {{{}table.optimizer.skewed-join-optimization.skewed-threshold{}}}).
> Finally, observe whether the ratio of the maximum data volume to the median
> data volume processed by concurrent join tasks is less than the skew factor.
> #
> Test the case where {{table.optimizer.skewed-join-optimization.strategy}} is
> set to {{{}forced{}}}. Construct a skewed join instance similar to Test 1,
> but with the following difference: the join case should be connected to a
> downstream operator that performs hashing on the same field (e.g., hash
> aggregation or group by). It is recommended to set different parallelisms for
> the join operator and the downstream operator to prevent the out edge from
> being optimized to a forward edge. Finally, observe whether the ratio of the
> maximum data volume to the median data volume processed by concurrent join
> tasks is less than the skew factor.
> #
> Test the case where
> {{{}table.optimizer.skewed-join-optimization.strategy{}}}as none, and verify
> that the join operator will not be optimized into an adaptive join operator
> under any circumstances.
> # Test the case with customized
> {{{}table.optimizer.skewed-join-optimization.skewed-factor{}}}. We need to
> construct a skewed join instance similar to Test 1, setting different skewed
> factors and observing whether the ratio of the maximum data volume to the
> median data volume processed by concurrent join tasks is less than the skew
> factor. Note that currently, Flink can only reduce the ratio to 2.0, and
> please ensure that the skewed-factor is greater than 2.0 during testing.
> # Test the case with customized
> {{{}table.optimizer.skewed-join-optimization.skewed-threshold{}}}. We need to
> construct a skewed join instance similar to Test 1, setting different
> skewed-threshold and observing whether the optimization is effective only
> when the data volume processed by the skewed join instance is greater than
> the skewed threshold.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
{kind=link}
{kind=link}