lsyldliu commented on code in PR #21563:
URL: https://github.com/apache/flink/pull/21563#discussion_r1058777527
##########
flink-table/flink-table-planner/src/main/scala/org/apache/flink/table/planner/plan/rules/FlinkStreamRuleSets.scala:
##########
@@ -211,6 +211,29 @@ object FlinkStreamRuleSets {
ProjectWindowTableFunctionTransposeRule.INSTANCE
)
+ /** RuleSet about project, but with
PROJECT_FILTER_TRANSPOSE_WHOLE_EXPRESSIONS. */
+ val PROJECT_RULES_V2: RuleSet = RuleSets.ofList(
Review Comment:
Why do we need to introduce PROJECT_RULES_V2? What is the difference between
rule PROJECT_FILTER_TRANSPOSE_WHOLE_EXPRESSIONS and PROJECT_FILTER_TRANSPOSE?
Can we only retain the PROJECT_RULES_V2 instead of PROJECT_RULES?
##########
flink-table/flink-table-planner/src/main/scala/org/apache/flink/table/planner/plan/utils/RexNodeExtractor.scala:
##########
@@ -538,7 +538,30 @@ class RexNodeToExpressionConverter(
}
}
- override def visitFieldAccess(fieldAccess: RexFieldAccess):
Option[ResolvedExpression] = None
+ override def visitFieldAccess(fieldAccess: RexFieldAccess):
Option[ResolvedExpression] = {
Review Comment:
Is this change unnecessary? I can't enter this method when debugging your
hive test.
##########
flink-table/flink-table-common/src/main/java/org/apache/flink/table/types/utils/DataTypeUtils.java:
##########
@@ -94,6 +99,217 @@ public static DataType projectRow(DataType dataType, int[]
indexPaths) {
return Projection.of(indexPaths).project(dataType);
}
+ public static List<RowType.RowField> buildRowFields(RowType allType,
int[][] projectedFields) {
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ for (int[] projectedField : projectedFields) {
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ allType.getFields().get(projectedField[0]),
projectedField, 0));
+ }
+ return updatedFields;
+ }
+
+ public static RowType buildRow(RowType allType, int[][] projectedFields) {
+ return new RowType(
+ allType.isNullable(), mergeRowFields(buildRowFields(allType,
projectedFields)));
+ }
+
+ public static RowType buildRow(RowType allType, List<RowType.RowField>
updatedFields) {
+ return new RowType(allType.isNullable(),
mergeRowFields(updatedFields));
+ }
+
+ public static RowType.RowField buildRowFieldInProjectFields(
+ RowType.RowField rowField, int[] fields, int index) {
+ if (fields.length == 1 || index == fields.length - 1) {
+ LogicalType rowType = rowField.getType();
+ if (rowType.is(ROW)) {
+ rowType = new RowType(rowType.isNullable(), ((RowType)
rowType).getFields());
+ }
+ return new RowField(rowField.getName(), rowType);
+ }
+ Preconditions.checkArgument(rowField.getType().is(ROW), "Row data type
expected.");
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ RowType rowtype = ((RowType) rowField.getType());
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ rowtype.getFields().get(fields[index + 1]), fields,
index + 1));
+ return new RowType.RowField(
+ rowField.getName(), new RowType(rowtype.isNullable(),
updatedFields));
+ }
+
+ public static List<RowType.RowField> mergeRowFields(List<RowType.RowField>
updatedFields) {
+ List<RowField> updatedFieldsCopy =
+
updatedFields.stream().map(RowField::copy).collect(Collectors.toList());
+ final List<String> fieldNames =
+
updatedFieldsCopy.stream().map(RowField::getName).collect(Collectors.toList());
+ if (fieldNames.stream().anyMatch(StringUtils::isNullOrWhitespaceOnly))
{
+ throw new ValidationException(
+ "Field names must contain at least one non-whitespace
character.");
+ }
+ final Set<String> duplicates =
+ fieldNames.stream()
+ .filter(n -> Collections.frequency(fieldNames, n) > 1)
+ .collect(Collectors.toSet());
+ if (duplicates.isEmpty()) {
+ return updatedFieldsCopy;
+ }
+ List<RowType.RowField> duplicatesFields =
+ updatedFieldsCopy.stream()
+ .filter(f -> duplicates.contains(f.getName()))
+ .collect(Collectors.toList());
+ updatedFieldsCopy.removeAll(duplicatesFields);
+ Map<String, List<RowField>> duplicatesMap = new HashMap<>();
+ duplicatesFields.forEach(
+ f -> {
+ List<RowField> tmp =
duplicatesMap.getOrDefault(f.getName(), new ArrayList<>());
+ tmp.add(f);
+ duplicatesMap.put(f.getName(), tmp);
+ });
+ duplicatesMap.forEach(
+ (fieldName, duplicateList) -> {
+ List<RowField> fieldsToMerge = new ArrayList<>();
+ for (RowField rowField : duplicateList) {
+ Preconditions.checkArgument(
+ rowField.getType().is(ROW), "Row data type
expected.");
+ RowType rowType = (RowType) rowField.getType();
+ fieldsToMerge.addAll(rowType.getFields());
+ }
+ RowField mergedField =
+ new RowField(
+ fieldName,
+ new RowType(
+
duplicateList.get(0).getType().isNullable(),
+ mergeRowFields(fieldsToMerge)));
+ updatedFieldsCopy.add(mergedField);
+ });
+ return updatedFieldsCopy;
+ }
+
+ public static int[][] computeProjectedFields(int[] selectFields) {
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[][] computeProjectedFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectFields = computeTopLevelFields(selectedFieldNames,
fullFieldNames);
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[] computeTopLevelFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectedFields = new int[selectedFieldNames.length];
+ for (int i = 0; i < selectedFields.length; i++) {
+ String name = selectedFieldNames[i];
+ int index = Arrays.asList(fullFieldNames).indexOf(name);
+ Preconditions.checkState(
+ index >= 0,
+ "Produced field name %s not found in table schema fields
%s",
+ name,
+ Arrays.toString(fullFieldNames));
+ selectedFields[i] = index;
+ }
+ return selectedFields;
+ }
+
+ public static Map<String, Integer> getFieldNameToIndex(List<String>
fieldNames) {
+ Map<String, Integer> fieldNameToIndex = new HashMap<>();
+ for (int i = 0; i < fieldNames.size(); i++) {
+ fieldNameToIndex.put(fieldNames.get(i), i);
+ }
+ return fieldNameToIndex;
+ }
+
+ public static boolean isVectorizationUnsupported(LogicalType t) {
Review Comment:
Whether can we extract `HiveInputFormat#isVectorizationUnsupported` method
here, only maintain one method as soon as possible?
##########
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/plan/rules/logical/PushProjectIntoTableSourceScanRule.java:
##########
@@ -186,11 +193,30 @@ private boolean supportsMetadata(DynamicTableSource
tableSource) {
return tableSource instanceof SupportsReadingMetadata;
}
- private boolean supportsNestedProjection(DynamicTableSource tableSource) {
+ private boolean supportsNestedProjection(
+ DynamicTableSource tableSource, LogicalProject project) {
+ List<RexNode> projects = project.getProjects();
return supportsProjectionPushDown(tableSource)
+ && isVectorizedSupportedTypes(projects)
&& ((SupportsProjectionPushDown)
tableSource).supportsNestedProjection();
}
+ private boolean isVectorizedSupportedTypes(List<RexNode> projects) {
Review Comment:
Maybe `isVectorizedReaderSuportedTypes` is better?
##########
flink-table/flink-table-common/src/main/java/org/apache/flink/table/types/utils/DataTypeUtils.java:
##########
@@ -94,6 +99,217 @@ public static DataType projectRow(DataType dataType, int[]
indexPaths) {
return Projection.of(indexPaths).project(dataType);
}
+ public static List<RowType.RowField> buildRowFields(RowType allType,
int[][] projectedFields) {
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ for (int[] projectedField : projectedFields) {
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ allType.getFields().get(projectedField[0]),
projectedField, 0));
+ }
+ return updatedFields;
+ }
+
+ public static RowType buildRow(RowType allType, int[][] projectedFields) {
+ return new RowType(
+ allType.isNullable(), mergeRowFields(buildRowFields(allType,
projectedFields)));
+ }
+
+ public static RowType buildRow(RowType allType, List<RowType.RowField>
updatedFields) {
+ return new RowType(allType.isNullable(),
mergeRowFields(updatedFields));
+ }
+
+ public static RowType.RowField buildRowFieldInProjectFields(
+ RowType.RowField rowField, int[] fields, int index) {
+ if (fields.length == 1 || index == fields.length - 1) {
+ LogicalType rowType = rowField.getType();
+ if (rowType.is(ROW)) {
+ rowType = new RowType(rowType.isNullable(), ((RowType)
rowType).getFields());
+ }
+ return new RowField(rowField.getName(), rowType);
+ }
+ Preconditions.checkArgument(rowField.getType().is(ROW), "Row data type
expected.");
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ RowType rowtype = ((RowType) rowField.getType());
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ rowtype.getFields().get(fields[index + 1]), fields,
index + 1));
+ return new RowType.RowField(
+ rowField.getName(), new RowType(rowtype.isNullable(),
updatedFields));
+ }
+
+ public static List<RowType.RowField> mergeRowFields(List<RowType.RowField>
updatedFields) {
+ List<RowField> updatedFieldsCopy =
+
updatedFields.stream().map(RowField::copy).collect(Collectors.toList());
+ final List<String> fieldNames =
+
updatedFieldsCopy.stream().map(RowField::getName).collect(Collectors.toList());
+ if (fieldNames.stream().anyMatch(StringUtils::isNullOrWhitespaceOnly))
{
+ throw new ValidationException(
+ "Field names must contain at least one non-whitespace
character.");
+ }
+ final Set<String> duplicates =
+ fieldNames.stream()
+ .filter(n -> Collections.frequency(fieldNames, n) > 1)
+ .collect(Collectors.toSet());
+ if (duplicates.isEmpty()) {
+ return updatedFieldsCopy;
+ }
+ List<RowType.RowField> duplicatesFields =
+ updatedFieldsCopy.stream()
+ .filter(f -> duplicates.contains(f.getName()))
+ .collect(Collectors.toList());
+ updatedFieldsCopy.removeAll(duplicatesFields);
+ Map<String, List<RowField>> duplicatesMap = new HashMap<>();
+ duplicatesFields.forEach(
+ f -> {
+ List<RowField> tmp =
duplicatesMap.getOrDefault(f.getName(), new ArrayList<>());
+ tmp.add(f);
+ duplicatesMap.put(f.getName(), tmp);
+ });
+ duplicatesMap.forEach(
+ (fieldName, duplicateList) -> {
+ List<RowField> fieldsToMerge = new ArrayList<>();
+ for (RowField rowField : duplicateList) {
+ Preconditions.checkArgument(
+ rowField.getType().is(ROW), "Row data type
expected.");
+ RowType rowType = (RowType) rowField.getType();
+ fieldsToMerge.addAll(rowType.getFields());
+ }
+ RowField mergedField =
+ new RowField(
+ fieldName,
+ new RowType(
+
duplicateList.get(0).getType().isNullable(),
+ mergeRowFields(fieldsToMerge)));
+ updatedFieldsCopy.add(mergedField);
+ });
+ return updatedFieldsCopy;
+ }
+
+ public static int[][] computeProjectedFields(int[] selectFields) {
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[][] computeProjectedFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectFields = computeTopLevelFields(selectedFieldNames,
fullFieldNames);
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[] computeTopLevelFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectedFields = new int[selectedFieldNames.length];
+ for (int i = 0; i < selectedFields.length; i++) {
+ String name = selectedFieldNames[i];
+ int index = Arrays.asList(fullFieldNames).indexOf(name);
+ Preconditions.checkState(
+ index >= 0,
+ "Produced field name %s not found in table schema fields
%s",
+ name,
+ Arrays.toString(fullFieldNames));
+ selectedFields[i] = index;
+ }
+ return selectedFields;
+ }
+
+ public static Map<String, Integer> getFieldNameToIndex(List<String>
fieldNames) {
+ Map<String, Integer> fieldNameToIndex = new HashMap<>();
+ for (int i = 0; i < fieldNames.size(); i++) {
+ fieldNameToIndex.put(fieldNames.get(i), i);
+ }
+ return fieldNameToIndex;
+ }
+
+ public static boolean isVectorizationUnsupported(LogicalType t) {
+ switch (t.getTypeRoot()) {
+ case CHAR:
+ case VARCHAR:
+ case BOOLEAN:
+ case BINARY:
+ case VARBINARY:
+ case DECIMAL:
+ case TINYINT:
+ case SMALLINT:
+ case INTEGER:
+ case BIGINT:
+ case FLOAT:
+ case DOUBLE:
+ case DATE:
+ case TIME_WITHOUT_TIME_ZONE:
+ case TIMESTAMP_WITHOUT_TIME_ZONE:
+ case TIMESTAMP_WITH_LOCAL_TIME_ZONE:
+ return false;
+ case ARRAY:
+ ArrayType arrayType = (ArrayType) t;
+ return
!canCreateColumnVectorAsChildrenType(arrayType.getElementType(), arrayType);
+ case MAP:
+ MapType mapType = (MapType) t;
+ return
!(canCreateColumnVectorAsChildrenType(mapType.getKeyType(), mapType)
+ &&
canCreateColumnVectorAsChildrenType(mapType.getValueType(), mapType));
+ case ROW:
+ RowType rowType = (RowType) t;
+ for (RowType.RowField rowField : rowType.getFields()) {
+ if
(!canCreateColumnVectorAsChildrenType(rowField.getType(), rowType)) {
+ return true;
+ }
+ }
+ return false;
+ case TIMESTAMP_WITH_TIME_ZONE:
+ case INTERVAL_YEAR_MONTH:
+ case INTERVAL_DAY_TIME:
+ case MULTISET:
+ case DISTINCT_TYPE:
+ case STRUCTURED_TYPE:
+ case NULL:
+ case RAW:
+ case SYMBOL:
+ default:
+ return true;
+ }
+ }
+
+ public static boolean canCreateColumnVectorAsChildrenType(LogicalType t,
LogicalType parent) {
Review Comment:
Renaming the method name to `isVectorizedReaderSupportedOfChildrenType`?
##########
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemConnectorOptions.java:
##########
@@ -68,6 +70,22 @@ public class FileSystemConnectorOptions {
+ "The statistics reporting is a heavy
operation in some cases,"
+ "this config allows users to choose the
statistics type according to different situations.");
+ public static final ConfigOption<List<String>>
+ SOURCE_NESTED_PROJECTION_PUSHDOWN_SUPPORTED_FORMATS =
+
ConfigOptions.key("source.nested.projection.pushdown.supported.formats")
Review Comment:
The option design principle is to keep the three-level hierarchy as soon as
possible, so I think we should rename it to
`source.nested-projection-pushdown.supported-formats`
##########
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemConnectorOptions.java:
##########
@@ -68,6 +70,22 @@ public class FileSystemConnectorOptions {
+ "The statistics reporting is a heavy
operation in some cases,"
+ "this config allows users to choose the
statistics type according to different situations.");
+ public static final ConfigOption<List<String>>
+ SOURCE_NESTED_PROJECTION_PUSHDOWN_SUPPORTED_FORMATS =
+
ConfigOptions.key("source.nested.projection.pushdown.supported.formats")
+ .stringType()
+ .asList()
+ .defaultValues("parquet")
+ .withDescription("supported formats for nested
projection pushdown");
Review Comment:
```suggestion
.withDescription("A comma-separated list of file
format short names for which Flink tries to push down projection for nested
columns. "
+ "Currently, only parquet
format implement this optimization. The other format doesn't support this
feature yet. "
+ "So the default value is
'parquet'.");
```
##########
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/connectors/hive/HiveTableSource.java:
##########
@@ -282,12 +296,37 @@ public void applyDynamicFiltering(List<String>
candidateFilterFields) {
@Override
public boolean supportsNestedProjection() {
- return false;
+ if (!flinkConf.get(SOURCE_NESTED_PROJECTION_PUSHDOWN_ENABLED)
+ || flinkConf.get(TABLE_EXEC_HIVE_FALLBACK_MAPRED_READER)) {
+ return false;
+ }
+ List<String> supportedFormats =
+
flinkConf.get(SOURCE_NESTED_PROJECTION_PUSHDOWN_SUPPORTED_FORMATS);
+ return supportedFormats != null
+ &&
supportedFormats.stream().anyMatch(getSerializationLib()::contains);
+ }
+
+ private String getSerializationLib() {
Review Comment:
Why do we need to use the `serializationLib ` to determine whether supports
nested projection? Here access the hive metastore is expansive, This will
lengthen the compilation time of the whole query, so I don't think it is a good
way. Can we just use `supportedFormats .cotanins("parquet")` to determine it?
cc @luoyuxia Can you give some suggestions?
##########
flink-table/flink-table-common/src/main/java/org/apache/flink/table/types/utils/DataTypeUtils.java:
##########
@@ -94,6 +99,217 @@ public static DataType projectRow(DataType dataType, int[]
indexPaths) {
return Projection.of(indexPaths).project(dataType);
}
+ public static List<RowType.RowField> buildRowFields(RowType allType,
int[][] projectedFields) {
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ for (int[] projectedField : projectedFields) {
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ allType.getFields().get(projectedField[0]),
projectedField, 0));
+ }
+ return updatedFields;
+ }
+
+ public static RowType buildRow(RowType allType, int[][] projectedFields) {
+ return new RowType(
+ allType.isNullable(), mergeRowFields(buildRowFields(allType,
projectedFields)));
+ }
+
+ public static RowType buildRow(RowType allType, List<RowType.RowField>
updatedFields) {
+ return new RowType(allType.isNullable(),
mergeRowFields(updatedFields));
+ }
+
+ public static RowType.RowField buildRowFieldInProjectFields(
+ RowType.RowField rowField, int[] fields, int index) {
+ if (fields.length == 1 || index == fields.length - 1) {
+ LogicalType rowType = rowField.getType();
+ if (rowType.is(ROW)) {
+ rowType = new RowType(rowType.isNullable(), ((RowType)
rowType).getFields());
+ }
+ return new RowField(rowField.getName(), rowType);
+ }
+ Preconditions.checkArgument(rowField.getType().is(ROW), "Row data type
expected.");
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ RowType rowtype = ((RowType) rowField.getType());
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ rowtype.getFields().get(fields[index + 1]), fields,
index + 1));
+ return new RowType.RowField(
+ rowField.getName(), new RowType(rowtype.isNullable(),
updatedFields));
+ }
+
+ public static List<RowType.RowField> mergeRowFields(List<RowType.RowField>
updatedFields) {
Review Comment:
Ditto
##########
flink-table/flink-table-common/src/main/java/org/apache/flink/table/types/utils/DataTypeUtils.java:
##########
@@ -94,6 +99,217 @@ public static DataType projectRow(DataType dataType, int[]
indexPaths) {
return Projection.of(indexPaths).project(dataType);
}
+ public static List<RowType.RowField> buildRowFields(RowType allType,
int[][] projectedFields) {
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ for (int[] projectedField : projectedFields) {
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ allType.getFields().get(projectedField[0]),
projectedField, 0));
+ }
+ return updatedFields;
+ }
+
+ public static RowType buildRow(RowType allType, int[][] projectedFields) {
+ return new RowType(
+ allType.isNullable(), mergeRowFields(buildRowFields(allType,
projectedFields)));
+ }
+
+ public static RowType buildRow(RowType allType, List<RowType.RowField>
updatedFields) {
+ return new RowType(allType.isNullable(),
mergeRowFields(updatedFields));
+ }
+
+ public static RowType.RowField buildRowFieldInProjectFields(
+ RowType.RowField rowField, int[] fields, int index) {
+ if (fields.length == 1 || index == fields.length - 1) {
+ LogicalType rowType = rowField.getType();
+ if (rowType.is(ROW)) {
+ rowType = new RowType(rowType.isNullable(), ((RowType)
rowType).getFields());
+ }
+ return new RowField(rowField.getName(), rowType);
+ }
+ Preconditions.checkArgument(rowField.getType().is(ROW), "Row data type
expected.");
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ RowType rowtype = ((RowType) rowField.getType());
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ rowtype.getFields().get(fields[index + 1]), fields,
index + 1));
+ return new RowType.RowField(
+ rowField.getName(), new RowType(rowtype.isNullable(),
updatedFields));
+ }
+
+ public static List<RowType.RowField> mergeRowFields(List<RowType.RowField>
updatedFields) {
+ List<RowField> updatedFieldsCopy =
+
updatedFields.stream().map(RowField::copy).collect(Collectors.toList());
+ final List<String> fieldNames =
+
updatedFieldsCopy.stream().map(RowField::getName).collect(Collectors.toList());
+ if (fieldNames.stream().anyMatch(StringUtils::isNullOrWhitespaceOnly))
{
+ throw new ValidationException(
+ "Field names must contain at least one non-whitespace
character.");
+ }
+ final Set<String> duplicates =
+ fieldNames.stream()
+ .filter(n -> Collections.frequency(fieldNames, n) > 1)
+ .collect(Collectors.toSet());
+ if (duplicates.isEmpty()) {
+ return updatedFieldsCopy;
+ }
+ List<RowType.RowField> duplicatesFields =
+ updatedFieldsCopy.stream()
+ .filter(f -> duplicates.contains(f.getName()))
+ .collect(Collectors.toList());
+ updatedFieldsCopy.removeAll(duplicatesFields);
+ Map<String, List<RowField>> duplicatesMap = new HashMap<>();
+ duplicatesFields.forEach(
+ f -> {
+ List<RowField> tmp =
duplicatesMap.getOrDefault(f.getName(), new ArrayList<>());
+ tmp.add(f);
+ duplicatesMap.put(f.getName(), tmp);
+ });
+ duplicatesMap.forEach(
+ (fieldName, duplicateList) -> {
+ List<RowField> fieldsToMerge = new ArrayList<>();
+ for (RowField rowField : duplicateList) {
+ Preconditions.checkArgument(
+ rowField.getType().is(ROW), "Row data type
expected.");
+ RowType rowType = (RowType) rowField.getType();
+ fieldsToMerge.addAll(rowType.getFields());
+ }
+ RowField mergedField =
+ new RowField(
+ fieldName,
+ new RowType(
+
duplicateList.get(0).getType().isNullable(),
+ mergeRowFields(fieldsToMerge)));
+ updatedFieldsCopy.add(mergedField);
+ });
+ return updatedFieldsCopy;
+ }
+
+ public static int[][] computeProjectedFields(int[] selectFields) {
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[][] computeProjectedFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectFields = computeTopLevelFields(selectedFieldNames,
fullFieldNames);
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[] computeTopLevelFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectedFields = new int[selectedFieldNames.length];
+ for (int i = 0; i < selectedFields.length; i++) {
+ String name = selectedFieldNames[i];
+ int index = Arrays.asList(fullFieldNames).indexOf(name);
+ Preconditions.checkState(
+ index >= 0,
+ "Produced field name %s not found in table schema fields
%s",
+ name,
+ Arrays.toString(fullFieldNames));
+ selectedFields[i] = index;
+ }
+ return selectedFields;
+ }
+
+ public static Map<String, Integer> getFieldNameToIndex(List<String>
fieldNames) {
+ Map<String, Integer> fieldNameToIndex = new HashMap<>();
+ for (int i = 0; i < fieldNames.size(); i++) {
+ fieldNameToIndex.put(fieldNames.get(i), i);
+ }
+ return fieldNameToIndex;
+ }
+
+ public static boolean isVectorizationUnsupported(LogicalType t) {
+ switch (t.getTypeRoot()) {
+ case CHAR:
+ case VARCHAR:
+ case BOOLEAN:
+ case BINARY:
+ case VARBINARY:
+ case DECIMAL:
+ case TINYINT:
+ case SMALLINT:
+ case INTEGER:
+ case BIGINT:
+ case FLOAT:
+ case DOUBLE:
+ case DATE:
+ case TIME_WITHOUT_TIME_ZONE:
+ case TIMESTAMP_WITHOUT_TIME_ZONE:
+ case TIMESTAMP_WITH_LOCAL_TIME_ZONE:
+ return false;
+ case ARRAY:
+ ArrayType arrayType = (ArrayType) t;
+ return
!canCreateColumnVectorAsChildrenType(arrayType.getElementType(), arrayType);
+ case MAP:
+ MapType mapType = (MapType) t;
+ return
!(canCreateColumnVectorAsChildrenType(mapType.getKeyType(), mapType)
+ &&
canCreateColumnVectorAsChildrenType(mapType.getValueType(), mapType));
+ case ROW:
+ RowType rowType = (RowType) t;
+ for (RowType.RowField rowField : rowType.getFields()) {
+ if
(!canCreateColumnVectorAsChildrenType(rowField.getType(), rowType)) {
+ return true;
+ }
+ }
+ return false;
+ case TIMESTAMP_WITH_TIME_ZONE:
+ case INTERVAL_YEAR_MONTH:
+ case INTERVAL_DAY_TIME:
+ case MULTISET:
+ case DISTINCT_TYPE:
+ case STRUCTURED_TYPE:
+ case NULL:
+ case RAW:
+ case SYMBOL:
+ default:
+ return true;
+ }
+ }
+
+ public static boolean canCreateColumnVectorAsChildrenType(LogicalType t,
LogicalType parent) {
+ switch (t.getTypeRoot()) {
+ case BOOLEAN:
+ case TINYINT:
+ case DOUBLE:
+ case FLOAT:
+ case INTEGER:
+ case DATE:
+ case TIME_WITHOUT_TIME_ZONE:
+ case BIGINT:
+ case SMALLINT:
+ case CHAR:
+ case VARCHAR:
+ case BINARY:
+ case VARBINARY:
+ case TIMESTAMP_WITHOUT_TIME_ZONE:
+ case TIMESTAMP_WITH_LOCAL_TIME_ZONE:
+ case DECIMAL:
+ return true;
+ case ROW:
+ RowType rowType = (RowType) t;
+ if (!parent.getTypeRoot().equals(ROW)) {
Review Comment:
Why is the parent isn't ROW type, we can't support vectorized reader, the
element type of array may also be a ROW type?
##########
flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/connectors/hive/read/HiveInputFormat.java:
##########
@@ -138,17 +160,27 @@ private RowType tableRowType() {
LOG.debug(String.format("Use native parquet reader for %s.",
split));
return ParquetColumnarRowInputFormat.createPartitionedFormat(
jobConfWrapper.conf(),
- producedRowType,
+ tableRowType(),
InternalTypeInfo.of(producedRowType),
+ projectedFields,
partitionKeys,
partitionFieldExtractor,
DEFAULT_SIZE,
hiveVersion.startsWith("3"),
false);
- } else if (!useMapRedReader &&
useOrcVectorizedRead(split.getHiveTablePartition())) {
+ } else if (!useMapRedReader
+ && useOrcVectorizedRead(split.getHiveTablePartition())
+ && !isNested) {
LOG.debug(String.format("Use native orc reader for %s.", split));
return createOrcFormat();
} else {
+ if (isNested) {
+ throw new FlinkRuntimeException(
+ String.format(
+ "can not find a reader for nested type: %s.
Maybe you should set %s to false",
Review Comment:
```suggestion
"Can not find a reader for nested type: %s.
Maybe you should set %s to false",
```
##########
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemTableSource.java:
##########
@@ -340,7 +342,17 @@ public void applyPartitions(List<Map<String, String>>
remainingPartitions) {
@Override
public boolean supportsNestedProjection() {
- return false;
+ return tableOptions.get(SOURCE_NESTED_PROJECTION_PUSHDOWN_ENABLED) &&
isNestedProjectable();
+ }
+
+ private boolean isNestedProjectable() {
+ return bulkReaderFormat != null
+ && bulkReaderFormat instanceof ProjectableDecodingFormat
+ && bulkReaderFormat
Review Comment:
I think `ParquetBulkDecodingFormat` should override the
`supportsNestedProjection` method in `ProjectableDecodingFormat`. We should use
the `supportsNestedProjection` to judge.
##########
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemConnectorOptions.java:
##########
@@ -68,6 +70,22 @@ public class FileSystemConnectorOptions {
+ "The statistics reporting is a heavy
operation in some cases,"
+ "this config allows users to choose the
statistics type according to different situations.");
+ public static final ConfigOption<List<String>>
+ SOURCE_NESTED_PROJECTION_PUSHDOWN_SUPPORTED_FORMATS =
+
ConfigOptions.key("source.nested.projection.pushdown.supported.formats")
+ .stringType()
+ .asList()
+ .defaultValues("parquet")
+ .withDescription("supported formats for nested
projection pushdown");
+
+ public static final ConfigOption<Boolean>
SOURCE_NESTED_PROJECTION_PUSHDOWN_ENABLED =
+ key("source.nested.projection.pushdown.enabled")
+ .booleanType()
+ .defaultValue(true)
+ .withDescription(
+ "Whether to push down nested projections, should
be configured in flink-conf.yaml")
Review Comment:
```suggestion
"Prune nested fields from a logical relation's
output which are unnecessary in "
+ "satisfying a query. This optimization
allows columnar file format readers to avoid "
+ "reading unnecessary nested column
data. Currently, only parquet is the "
+ "format that implement this
optimization.")
```
##########
flink-table/flink-table-common/src/main/java/org/apache/flink/table/expressions/RowFieldExpression.java:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.expressions;
+
+import org.apache.flink.table.types.DataType;
+
+import org.apache.commons.lang3.StringUtils;
+
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+import java.util.Objects;
+
+/** RowFieldExpression. */
+public class RowFieldExpression implements ResolvedExpression {
Review Comment:
Does this change is necessary?
##########
flink-table/flink-table-common/src/main/java/org/apache/flink/table/types/utils/DataTypeUtils.java:
##########
@@ -94,6 +99,217 @@ public static DataType projectRow(DataType dataType, int[]
indexPaths) {
return Projection.of(indexPaths).project(dataType);
}
+ public static List<RowType.RowField> buildRowFields(RowType allType,
int[][] projectedFields) {
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ for (int[] projectedField : projectedFields) {
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ allType.getFields().get(projectedField[0]),
projectedField, 0));
+ }
+ return updatedFields;
+ }
+
+ public static RowType buildRow(RowType allType, int[][] projectedFields) {
+ return new RowType(
+ allType.isNullable(), mergeRowFields(buildRowFields(allType,
projectedFields)));
+ }
+
+ public static RowType buildRow(RowType allType, List<RowType.RowField>
updatedFields) {
+ return new RowType(allType.isNullable(),
mergeRowFields(updatedFields));
+ }
+
+ public static RowType.RowField buildRowFieldInProjectFields(
Review Comment:
It would be better give some annotation about these method to help user to
read it.
##########
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/plan/rules/logical/PushProjectIntoTableSourceScanRule.java:
##########
@@ -186,11 +193,30 @@ private boolean supportsMetadata(DynamicTableSource
tableSource) {
return tableSource instanceof SupportsReadingMetadata;
}
- private boolean supportsNestedProjection(DynamicTableSource tableSource) {
+ private boolean supportsNestedProjection(
+ DynamicTableSource tableSource, LogicalProject project) {
+ List<RexNode> projects = project.getProjects();
return supportsProjectionPushDown(tableSource)
+ && isVectorizedSupportedTypes(projects)
&& ((SupportsProjectionPushDown)
tableSource).supportsNestedProjection();
}
+ private boolean isVectorizedSupportedTypes(List<RexNode> projects) {
+ List<LogicalType> logicalTypes = new ArrayList<>();
+ for (RexNode rexNode : projects) {
+ LogicalType logicalType =
FlinkTypeFactory.toLogicalType(rexNode.getType());
+ if (isVectorizationUnsupported(logicalType)) {
+ LOG.info(
+ "unsupported nested type for vectorized reader:{},
will not push down nested projections and falling back to MR reader",
Review Comment:
```suggestion
"Unsupported nested type for vectorized reader:{},
will not push down nested projections and falling back to MR reader",
```
##########
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/plan/rules/logical/PushProjectIntoTableSourceScanRule.java:
##########
@@ -186,11 +193,30 @@ private boolean supportsMetadata(DynamicTableSource
tableSource) {
return tableSource instanceof SupportsReadingMetadata;
}
- private boolean supportsNestedProjection(DynamicTableSource tableSource) {
+ private boolean supportsNestedProjection(
+ DynamicTableSource tableSource, LogicalProject project) {
+ List<RexNode> projects = project.getProjects();
return supportsProjectionPushDown(tableSource)
+ && isVectorizedSupportedTypes(projects)
&& ((SupportsProjectionPushDown)
tableSource).supportsNestedProjection();
}
+ private boolean isVectorizedSupportedTypes(List<RexNode> projects) {
+ List<LogicalType> logicalTypes = new ArrayList<>();
+ for (RexNode rexNode : projects) {
+ LogicalType logicalType =
FlinkTypeFactory.toLogicalType(rexNode.getType());
+ if (isVectorizationUnsupported(logicalType)) {
+ LOG.info(
Review Comment:
```suggestion
LOG.debug(
```
##########
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/plan/rules/logical/PushProjectIntoTableSourceScanRule.java:
##########
@@ -186,11 +193,30 @@ private boolean supportsMetadata(DynamicTableSource
tableSource) {
return tableSource instanceof SupportsReadingMetadata;
}
- private boolean supportsNestedProjection(DynamicTableSource tableSource) {
+ private boolean supportsNestedProjection(
+ DynamicTableSource tableSource, LogicalProject project) {
+ List<RexNode> projects = project.getProjects();
return supportsProjectionPushDown(tableSource)
+ && isVectorizedSupportedTypes(projects)
&& ((SupportsProjectionPushDown)
tableSource).supportsNestedProjection();
}
+ private boolean isVectorizedSupportedTypes(List<RexNode> projects) {
+ List<LogicalType> logicalTypes = new ArrayList<>();
+ for (RexNode rexNode : projects) {
+ LogicalType logicalType =
FlinkTypeFactory.toLogicalType(rexNode.getType());
+ if (isVectorizationUnsupported(logicalType)) {
+ LOG.info(
+ "unsupported nested type for vectorized reader:{},
will not push down nested projections and falling back to MR reader",
+ logicalType);
+ return false;
+ }
+ logicalTypes.add(logicalType);
+ }
+ LOG.info("will pushdown nested type for vectorized reader, Row
fields={}", logicalTypes);
Review Comment:
```suggestion
LOG.debug("Pushdown nested type for vectorized reader, Row
fields={}", logicalTypes);
```
##########
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemConnectorOptions.java:
##########
@@ -68,6 +70,22 @@ public class FileSystemConnectorOptions {
+ "The statistics reporting is a heavy
operation in some cases,"
+ "this config allows users to choose the
statistics type according to different situations.");
+ public static final ConfigOption<List<String>>
+ SOURCE_NESTED_PROJECTION_PUSHDOWN_SUPPORTED_FORMATS =
+
ConfigOptions.key("source.nested.projection.pushdown.supported.formats")
+ .stringType()
+ .asList()
+ .defaultValues("parquet")
+ .withDescription("supported formats for nested
projection pushdown");
+
+ public static final ConfigOption<Boolean>
SOURCE_NESTED_PROJECTION_PUSHDOWN_ENABLED =
+ key("source.nested.projection.pushdown.enabled")
Review Comment:
```suggestion
key("source.nested-projection-pushdown.enabled")
```
##########
flink-connectors/flink-connector-files/src/main/java/org/apache/flink/connector/file/table/FileSystemConnectorOptions.java:
##########
@@ -68,6 +70,22 @@ public class FileSystemConnectorOptions {
+ "The statistics reporting is a heavy
operation in some cases,"
+ "this config allows users to choose the
statistics type according to different situations.");
+ public static final ConfigOption<List<String>>
+ SOURCE_NESTED_PROJECTION_PUSHDOWN_SUPPORTED_FORMATS =
+
ConfigOptions.key("source.nested.projection.pushdown.supported.formats")
+ .stringType()
+ .asList()
+ .defaultValues("parquet")
+ .withDescription("supported formats for nested
projection pushdown");
+
+ public static final ConfigOption<Boolean>
SOURCE_NESTED_PROJECTION_PUSHDOWN_ENABLED =
+ key("source.nested.projection.pushdown.enabled")
+ .booleanType()
+ .defaultValue(true)
+ .withDescription(
+ "Whether to push down nested projections, should
be configured in flink-conf.yaml")
+ .withDeprecatedKeys("nested.projection.pushdown");
Review Comment:
Where is this deprecated key from? I didn't find it flink project.
##########
flink-table/flink-table-common/src/main/java/org/apache/flink/table/types/utils/DataTypeUtils.java:
##########
@@ -94,6 +99,217 @@ public static DataType projectRow(DataType dataType, int[]
indexPaths) {
return Projection.of(indexPaths).project(dataType);
}
+ public static List<RowType.RowField> buildRowFields(RowType allType,
int[][] projectedFields) {
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ for (int[] projectedField : projectedFields) {
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ allType.getFields().get(projectedField[0]),
projectedField, 0));
+ }
+ return updatedFields;
+ }
+
+ public static RowType buildRow(RowType allType, int[][] projectedFields) {
+ return new RowType(
+ allType.isNullable(), mergeRowFields(buildRowFields(allType,
projectedFields)));
+ }
+
+ public static RowType buildRow(RowType allType, List<RowType.RowField>
updatedFields) {
+ return new RowType(allType.isNullable(),
mergeRowFields(updatedFields));
+ }
+
+ public static RowType.RowField buildRowFieldInProjectFields(
+ RowType.RowField rowField, int[] fields, int index) {
+ if (fields.length == 1 || index == fields.length - 1) {
+ LogicalType rowType = rowField.getType();
+ if (rowType.is(ROW)) {
+ rowType = new RowType(rowType.isNullable(), ((RowType)
rowType).getFields());
+ }
+ return new RowField(rowField.getName(), rowType);
+ }
+ Preconditions.checkArgument(rowField.getType().is(ROW), "Row data type
expected.");
+ final List<RowType.RowField> updatedFields = new ArrayList<>();
+ RowType rowtype = ((RowType) rowField.getType());
+ updatedFields.add(
+ buildRowFieldInProjectFields(
+ rowtype.getFields().get(fields[index + 1]), fields,
index + 1));
+ return new RowType.RowField(
+ rowField.getName(), new RowType(rowtype.isNullable(),
updatedFields));
+ }
+
+ public static List<RowType.RowField> mergeRowFields(List<RowType.RowField>
updatedFields) {
+ List<RowField> updatedFieldsCopy =
+
updatedFields.stream().map(RowField::copy).collect(Collectors.toList());
+ final List<String> fieldNames =
+
updatedFieldsCopy.stream().map(RowField::getName).collect(Collectors.toList());
+ if (fieldNames.stream().anyMatch(StringUtils::isNullOrWhitespaceOnly))
{
+ throw new ValidationException(
+ "Field names must contain at least one non-whitespace
character.");
+ }
+ final Set<String> duplicates =
+ fieldNames.stream()
+ .filter(n -> Collections.frequency(fieldNames, n) > 1)
+ .collect(Collectors.toSet());
+ if (duplicates.isEmpty()) {
+ return updatedFieldsCopy;
+ }
+ List<RowType.RowField> duplicatesFields =
+ updatedFieldsCopy.stream()
+ .filter(f -> duplicates.contains(f.getName()))
+ .collect(Collectors.toList());
+ updatedFieldsCopy.removeAll(duplicatesFields);
+ Map<String, List<RowField>> duplicatesMap = new HashMap<>();
+ duplicatesFields.forEach(
+ f -> {
+ List<RowField> tmp =
duplicatesMap.getOrDefault(f.getName(), new ArrayList<>());
+ tmp.add(f);
+ duplicatesMap.put(f.getName(), tmp);
+ });
+ duplicatesMap.forEach(
+ (fieldName, duplicateList) -> {
+ List<RowField> fieldsToMerge = new ArrayList<>();
+ for (RowField rowField : duplicateList) {
+ Preconditions.checkArgument(
+ rowField.getType().is(ROW), "Row data type
expected.");
+ RowType rowType = (RowType) rowField.getType();
+ fieldsToMerge.addAll(rowType.getFields());
+ }
+ RowField mergedField =
+ new RowField(
+ fieldName,
+ new RowType(
+
duplicateList.get(0).getType().isNullable(),
+ mergeRowFields(fieldsToMerge)));
+ updatedFieldsCopy.add(mergedField);
+ });
+ return updatedFieldsCopy;
+ }
+
+ public static int[][] computeProjectedFields(int[] selectFields) {
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[][] computeProjectedFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectFields = computeTopLevelFields(selectedFieldNames,
fullFieldNames);
+ int[][] projectedFields = new int[selectFields.length][1];
+ for (int i = 0; i < selectFields.length; i++) {
+ projectedFields[i][0] = selectFields[i];
+ }
+ return projectedFields;
+ }
+
+ public static int[] computeTopLevelFields(
+ String[] selectedFieldNames, String[] fullFieldNames) {
+ int[] selectedFields = new int[selectedFieldNames.length];
+ for (int i = 0; i < selectedFields.length; i++) {
+ String name = selectedFieldNames[i];
+ int index = Arrays.asList(fullFieldNames).indexOf(name);
+ Preconditions.checkState(
+ index >= 0,
+ "Produced field name %s not found in table schema fields
%s",
+ name,
+ Arrays.toString(fullFieldNames));
+ selectedFields[i] = index;
+ }
+ return selectedFields;
+ }
+
+ public static Map<String, Integer> getFieldNameToIndex(List<String>
fieldNames) {
+ Map<String, Integer> fieldNameToIndex = new HashMap<>();
+ for (int i = 0; i < fieldNames.size(); i++) {
+ fieldNameToIndex.put(fieldNames.get(i), i);
+ }
+ return fieldNameToIndex;
+ }
+
+ public static boolean isVectorizationUnsupported(LogicalType t) {
+ switch (t.getTypeRoot()) {
+ case CHAR:
+ case VARCHAR:
+ case BOOLEAN:
+ case BINARY:
+ case VARBINARY:
+ case DECIMAL:
+ case TINYINT:
+ case SMALLINT:
+ case INTEGER:
+ case BIGINT:
+ case FLOAT:
+ case DOUBLE:
+ case DATE:
+ case TIME_WITHOUT_TIME_ZONE:
+ case TIMESTAMP_WITHOUT_TIME_ZONE:
+ case TIMESTAMP_WITH_LOCAL_TIME_ZONE:
+ return false;
+ case ARRAY:
+ ArrayType arrayType = (ArrayType) t;
+ return
!canCreateColumnVectorAsChildrenType(arrayType.getElementType(), arrayType);
+ case MAP:
+ MapType mapType = (MapType) t;
+ return
!(canCreateColumnVectorAsChildrenType(mapType.getKeyType(), mapType)
+ &&
canCreateColumnVectorAsChildrenType(mapType.getValueType(), mapType));
+ case ROW:
+ RowType rowType = (RowType) t;
+ for (RowType.RowField rowField : rowType.getFields()) {
+ if
(!canCreateColumnVectorAsChildrenType(rowField.getType(), rowType)) {
+ return true;
+ }
+ }
+ return false;
+ case TIMESTAMP_WITH_TIME_ZONE:
+ case INTERVAL_YEAR_MONTH:
+ case INTERVAL_DAY_TIME:
+ case MULTISET:
Review Comment:
The MULTISET type is similar to MAP, so I think it should also support
vectorized read.
##########
flink-formats/flink-parquet/src/main/java/org/apache/flink/formats/parquet/ParquetVectorizedInputFormat.java:
##########
@@ -123,7 +151,7 @@ public ParquetReader createReader(final Configuration
config, final SplitT split
FilterCompat.Filter filter = getFilter(hadoopConfig.conf());
List<BlockMetaData> blocks = filterRowGroups(filter,
footer.getBlocks(), fileSchema);
- MessageType requestedSchema = clipParquetSchema(fileSchema);
+ MessageType requestedSchema = clipParquetSchema(fileSchema,
builtProjectedRowType);
Review Comment:
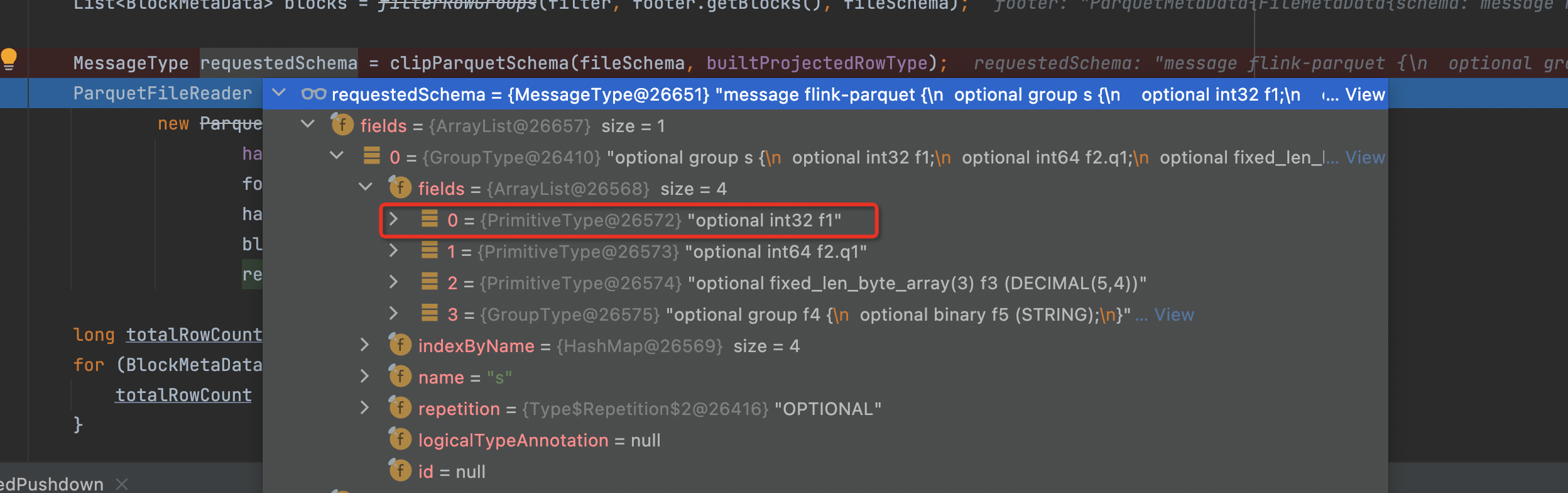
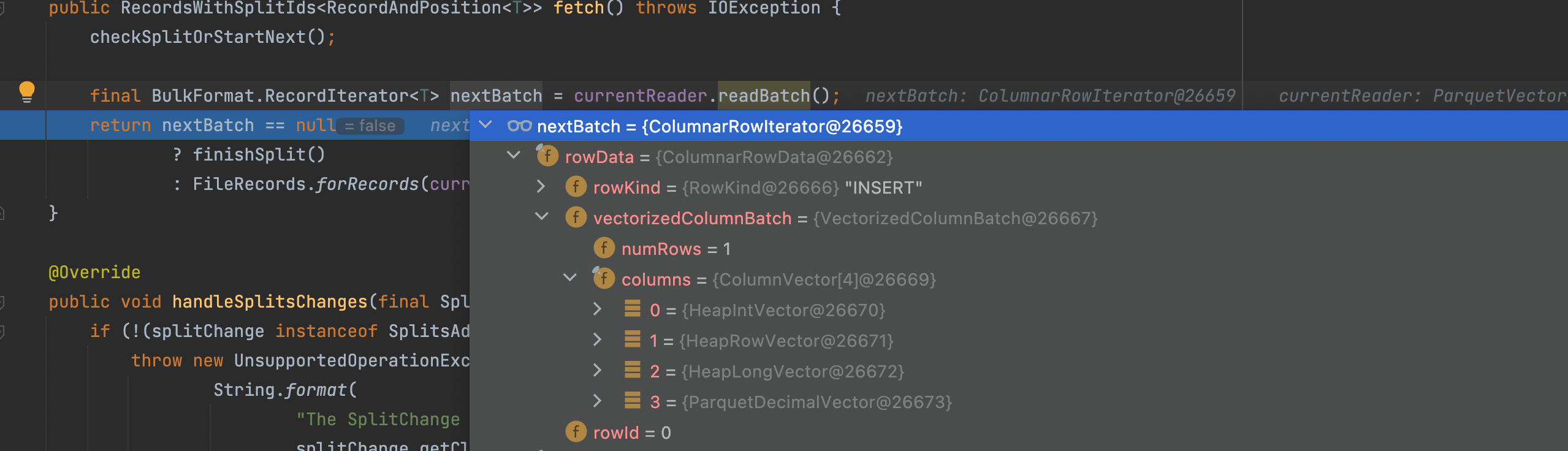
When debugging your test to parquet reader, I found the `requestedSchema `
still contains all children fields of `s`, it doesn't project the `f1` field,
wether can we project the `f1` when constructing the MessageType? Please
correct me if my understand is not correted.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}
{kind=link}