Thesharing commented on a change in pull request #16856:
URL: https://github.com/apache/flink/pull/16856#discussion_r691951701
##########
File path:
flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/DefaultExecutionGraph.java
##########
@@ -1279,10 +1279,14 @@ private void releasePartitions(final
List<IntermediateResultPartitionID> releasa
// Remove cached ShuffleDescriptor when partition is released
releasablePartitions.stream()
-
.map(IntermediateResultPartitionID::getIntermediateDataSetID)
+ .map(edgeManager::getConsumedPartitionGroupsById)
Review comment:
Thank you for reviewing this pull request, @tillrohrmann! Since a
IntermediateDataSet can be consumed by multiple consumer JobVertices, the
IntermediateResultPartition corresponding to this data set can be consumed by
multiple consumer ExecutionVertices. These ExecutionVertices belong to
different ConsumerVertexGroups. A ConsumerVertexGroup is corresponding to a
ConsumedPartitionGroup. Therefore we can say an IntermediateResultPartition can
belong to multiple ConsumedPartitionGroups. An example is illustrated in the
figure below:
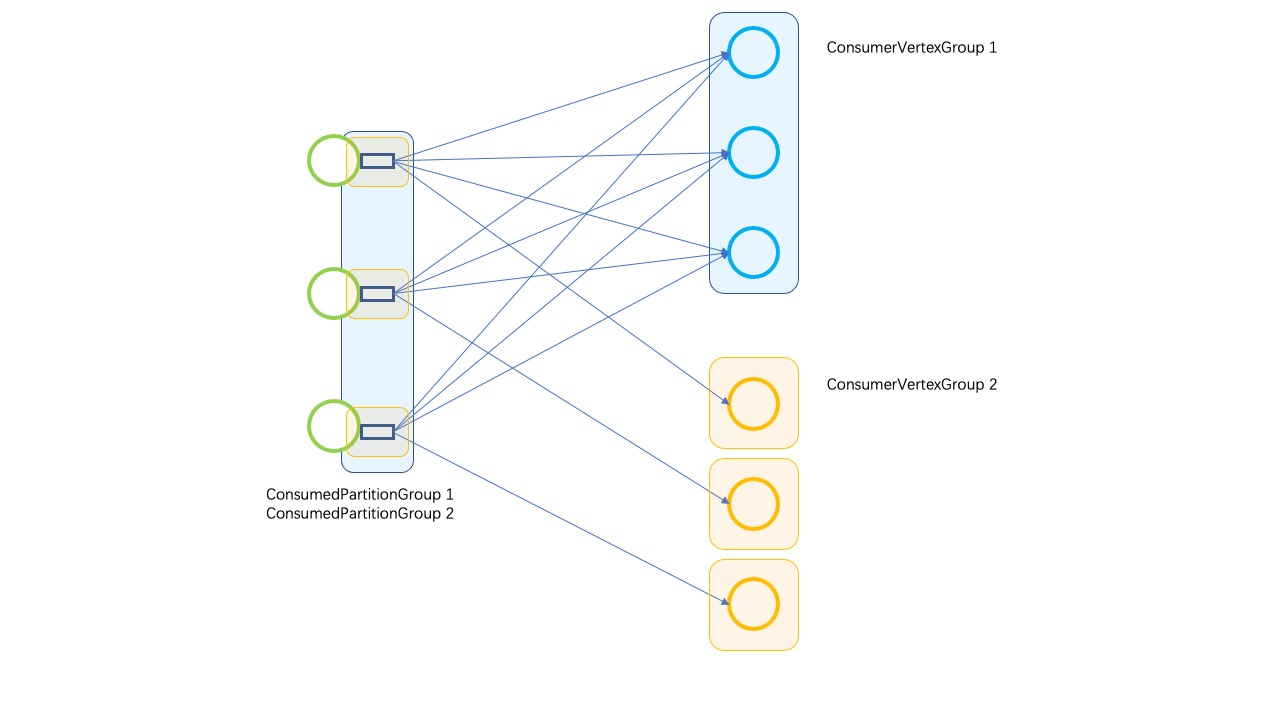
Although, currently there has to be only one consumer for each
IntermediateDataSet by design.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}