liyafan82 edited a comment on issue #8397: [FLINK-11421][Table SQL/Runtime]Add compilation options to allow comp… URL: https://github.com/apache/flink/pull/8397#issuecomment-492914042 > Hi @liyafan82 Thank for your nice works~ I think I have a clearer understanding now. > I think your benchmarks illustrates two points: > > 1. JCA is much better than Janino in vector computation. (150% - 200%) > 2. JCA compilation time is about 0.1 second - 1 second slower. > > But we probably don't have any vector computing right now. Can you continue to benchmark how our table works right now? (It would be better if you could provide reproducible code) Hi @JingsongLi and @KurtYoung , I have evaluated the benchmark on table work load, as you suggested. The results are as follows. Please give your valuable feedback: We use the same benchmark (TPC-H Q1, 1TB) to evaluate the effects of compilation options. This time, we use the original Flink runtime engine, instead of vectorization. The effects are notable, but not as significant as with vectorization. Likewise, we only consider operators Calc (ID = 5) and LongHashAggregate (ID = 6) in our analysis. The table below shows the average time (in ms) for each operator in processing Q1 in our cluster: Operator\Compiler | JCA | Janino -- | -- | -- Calc (ID = 5) | 4902.18 | 5482.86 LongHashAggregate (ID = 6) | 2967.2 | 3257.92 It can be seen that the code compiled by JCA runs about 9.8% faster. The following table shows the compilation time (in ms) with different compilers. The results are similar to the previous benchmark results. Operator\Compiler | JCA | Janino -- | -- | -- Calc (ID = 5) | 124 | 12 LongHashAggregate (ID = 6) | 850 | 31 GlobalHashAggregate (ID = 8) | 225 | 100 Calc (ID = 11) | 105 | 14 SinkConversion (ID = 12) | 100 | 5 Investigations on compiled class files show that, different compilers produce different class files sizes. Operator\Compiler | JCA | Janino -- | -- | -- Calc (ID = 5) | 4 KB | 3 KB LongHashAggregate (ID = 6) | 10 KB | 8 KB GlobalHashAggregate (ID = 8) | 17 KB | 12 KB Calc (ID = 11) | 4 KB | 3 KB SinkConversion (ID = 12) | 2 KB | 2 KB By analyzing the byte code, we found there are differences in the code structure of bytecodes, which accounts for the performance differences. For example, the following figure shows the bytecode of the processElement method of Calc (ID = 5): 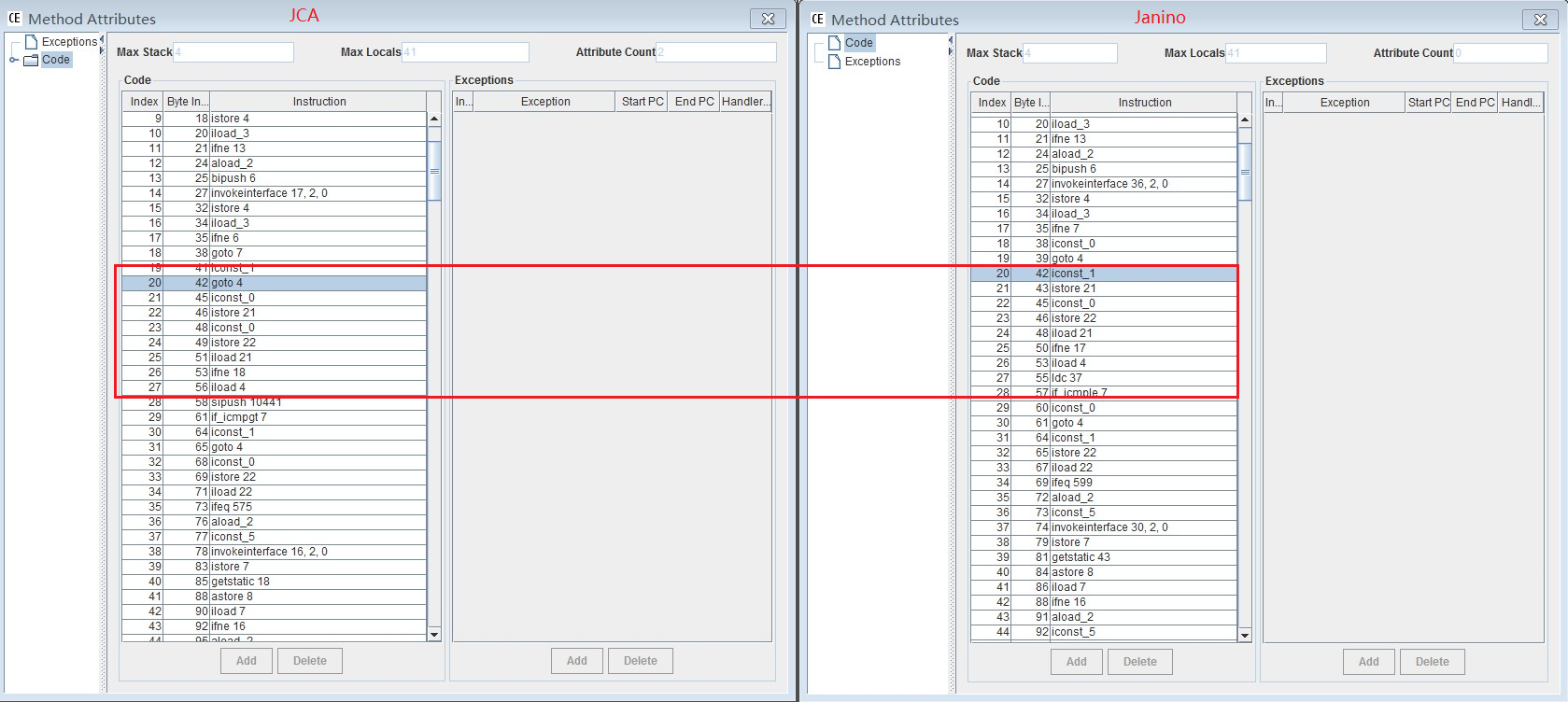 To make it more convenient to reproduce the results, we have attached the source code for generated operators. Just by compiling the code with different compilers and generating some test data set, the above results should be reproduced locally (Our results are derived from the cluster). [code.zip](https://github.com/apache/flink/files/3185415/code.zip)
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services