[
https://issues.apache.org/jira/browse/FLINK-9190?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16447519#comment-16447519
]
ASF GitHub Bot commented on FLINK-9190:
---------------------------------------
Github user sihuazhou commented on a diff in the pull request:
https://github.com/apache/flink/pull/5881#discussion_r183269424
--- Diff:
flink-yarn/src/main/java/org/apache/flink/yarn/YarnResourceManager.java ---
@@ -265,6 +272,29 @@ protected void initialize() throws
ResourceManagerException {
}
}
+ @Override
+ public CompletableFuture<RegistrationResponse> registerTaskExecutor(
--- End diff --
I've moved the `ack the pending registration` to `workerStarted()`. but I
found it still a little chance could lead the registration to be failed...
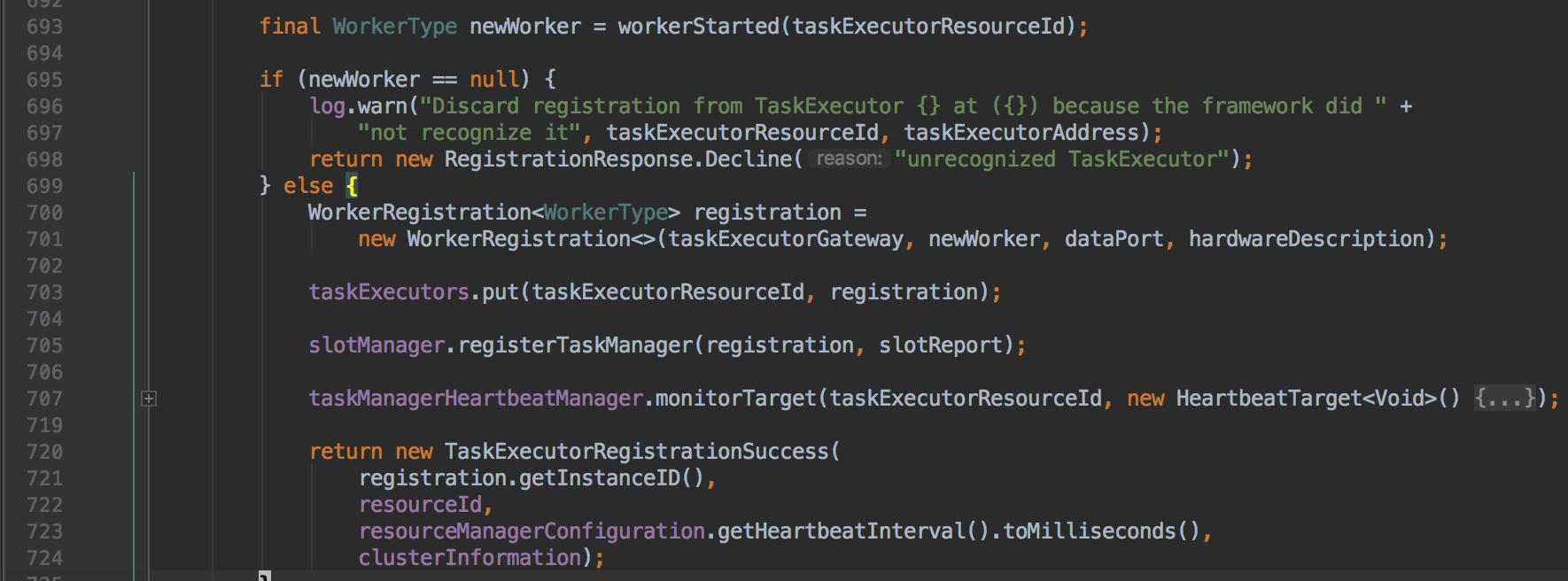
e.g, if the some unexpected things occur between lines `700` and `720`,
then the registration can still fail... I think maybe we should override the
`registerTaskExecutor()` and ack the pending registration only when the future
of `super.registerTaskExecutor()` is completed, what do you think?
> YarnResourceManager sometimes does not request new Containers
> -------------------------------------------------------------
>
> Key: FLINK-9190
> URL: https://issues.apache.org/jira/browse/FLINK-9190
> Project: Flink
> Issue Type: Bug
> Components: Distributed Coordination, YARN
> Affects Versions: 1.5.0
> Environment: Hadoop 2.8.3
> ZooKeeper 3.4.5
> Flink 71c3cd2781d36e0a03d022a38cc4503d343f7ff8
> Reporter: Gary Yao
> Assignee: Sihua Zhou
> Priority: Blocker
> Labels: flip-6
> Fix For: 1.5.0
>
> Attachments: yarn-logs
>
>
> *Description*
> The {{YarnResourceManager}} does not request new containers if
> {{TaskManagers}} are killed rapidly in succession. After 5 minutes the job is
> restarted due to {{NoResourceAvailableException}}, and the job runs normally
> afterwards. I suspect that {{TaskManager}} failures are not registered if the
> failure occurs before the {{TaskManager}} registers with the master. Logs are
> attached; I added additional log statements to
> {{YarnResourceManager.onContainersCompleted}} and
> {{YarnResourceManager.onContainersAllocated}}.
> *Expected Behavior*
> The {{YarnResourceManager}} should recognize that the container is completed
> and keep requesting new containers. The job should run as soon as resources
> are available.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}