[
https://issues.apache.org/jira/browse/CLOUDSTACK-9114?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16411343#comment-16411343
]
ASF GitHub Bot commented on CLOUDSTACK-9114:
--------------------------------------------
rhtyd opened a new pull request #2508: CLOUDSTACK-9114: Reduce VR downtime
during network restart
URL: https://github.com/apache/cloudstack/pull/2508
## Description
<!--- Describe your changes in detail -->
Note *WIP*, but working for both non-redundant and redundant network VRs :)
Every time there is a major CloudStack version that requires a new
systemvmtemplate, admins need to restart VRs which can take few (sometimes
several) minutes. The aim of this project is three parts:
- Reduce systemvmtemplate size, see #2506. Smaller the image size, faster it
will be to copy template to primary storage to provision new VR.
- Perform rolling reboot/deployment of VRs, by provisioning new VRs first
and then killing old ones.
- Make isolated VRs future proof (have keepalived+conntrackd preconfigured
TBD)
- Refactor systemvm python code to speed up VR programming or rule
application
- Speed up iptables and misc rules application from the VR's .json files
Future:
- Move away from iptables, move to nftables
- Move away from Python2 codebase to Python3 or something else like Go? TBD
Todos:
[ ] Implement rolling reboot for VPC based on #2436
[ ] Speed up iptables and rules application based on #2083
<!-- For new features, provide link to FS, dev ML discussion etc. -->
<!-- In case of bug fix, the expected and actual behaviours, steps to
reproduce. -->
## Types of changes
<!--- What types of changes does your code introduce? Put an `x` in all the
boxes that apply: -->
- [ ] Breaking change (fix or feature that would cause existing
functionality to change)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Bug fix (non-breaking change which fixes an issue)
- [ ] Enhancement (improves an existing feature and functionality)
- [ ] Cleanup (Code refactoring and cleanup, that may add test cases)
## Screenshots (if appropriate):
Screenshot shows ping drops from a guest VM, in a non-redundant isolated
network: (2-5 ping drops observed)
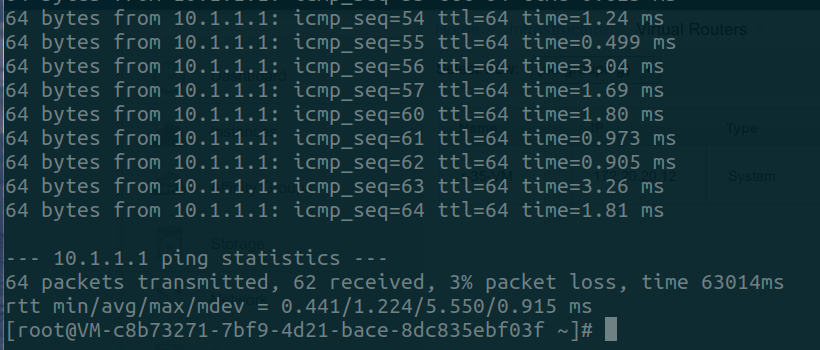
In case of rVRs, 0-1 ping drops are observed
## How Has This Been Tested?
<!-- Please describe in detail how you tested your changes. -->
<!-- Include details of your testing environment, and the tests you ran to
-->
<!-- see how your change affects other areas of the code, etc. -->
## Checklist:
<!--- Go over all the following points, and put an `x` in all the boxes that
apply. -->
<!--- If you're unsure about any of these, don't hesitate to ask. We're here
to help! -->
- [ ] I have read the
[CONTRIBUTING](https://github.com/apache/cloudstack/blob/master/CONTRIBUTING.md)
document.
- [ ] My code follows the code style of this project.
- [ ] My change requires a change to the documentation.
- [ ] I have updated the documentation accordingly.
- [ ] I have added tests to cover my changes.
- [ ] All new and existing tests passed.
<!-- The following will kick a packaging job, remove if as applicable -->
@blueorangutan package
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
> restartnetwork with cleanup should not update/restart both routers at once
> --------------------------------------------------------------------------
>
> Key: CLOUDSTACK-9114
> URL: https://issues.apache.org/jira/browse/CLOUDSTACK-9114
> Project: CloudStack
> Issue Type: Improvement
> Security Level: Public(Anyone can view this level - this is the
> default.)
> Reporter: Wei Zhou
> Assignee: Wei Zhou
> Priority: Major
>
> for now, restartnetwork with cleanup will stop both RVRs at first, then start
> two new RVRs.
> to reduce the downtime of network, we'd better restart the RVRs one by one.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}