> Yep. For what it's worth, it's been enabled for about one month on > haproxy.org and till now we didn't get any bad report, which is pretty > encouraging.
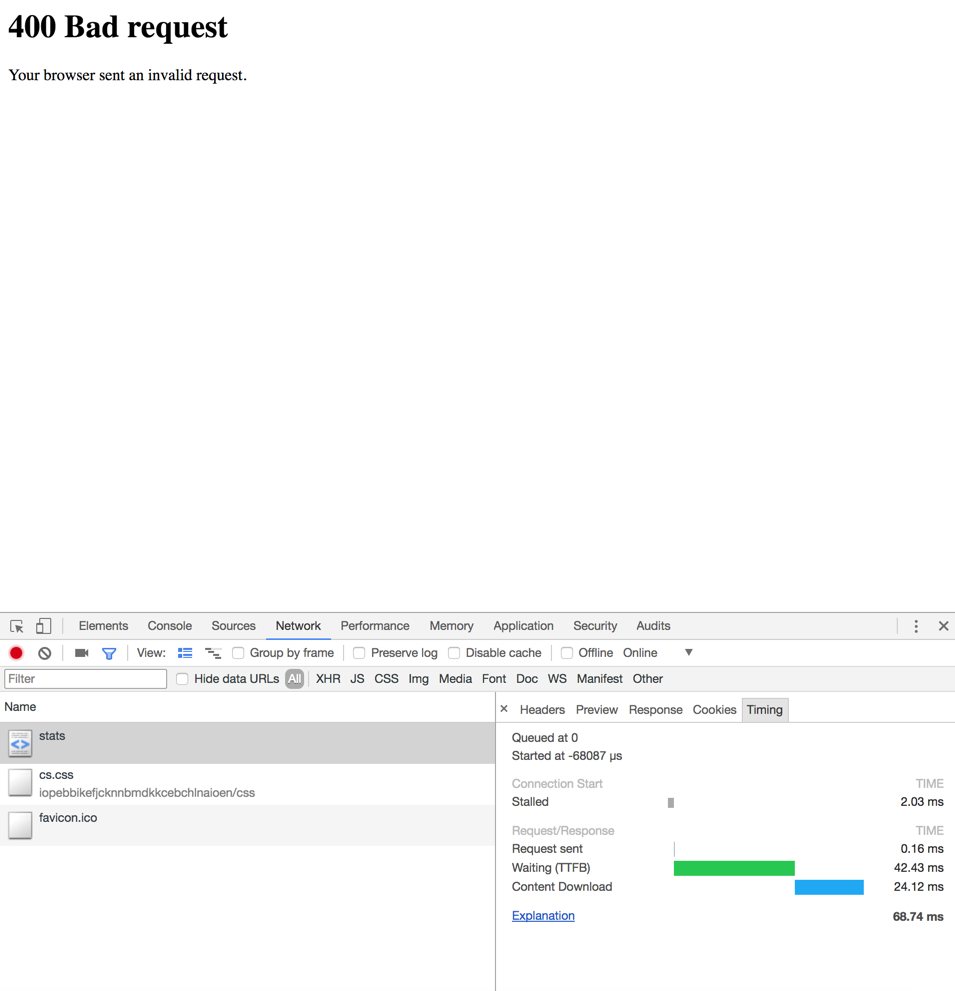
Can I ask where? The negotiated protocol I get on https://haproxy.org/ is http/1.1 in both Google Chrome and Firefox as an example. If I use curl, I can see it has ALPN enabled with http2 – however, mentioned browsers doesn’t seem to actually establish the http2 connection, but rather a 1.1 connection. > If this is met in production it definitely is a problem that we have to > address. Could you please try the attached patch to see if it fixes the issue > for you ? If so, I would at least like that we can keep some statistics on > it, and maybe even condition it. For POST requests, it’s not resolved with the patch, what I did find when getting the 400 Bad Request on POST, it sometimes actually arrive at the backend: So haproxy: Dec 29 08:01:36 localhost haproxy[4432]: 92.70.20.xx:52949 [29/Dec/2017:08:01:36.800] https_frontend~ cdn-backend/mycdn 0/0/1/-1/3 400 187 - - CH-- 1/1/0/0/0 0/0 "POST /login HTTP/1.1" Dec 29 08:01:36 localhost haproxy[4432]: 92.70.20.xx:52949 [29/Dec/2017:08:01:36.806] https_frontend~ cdn-backend/mycdn 0/0/0/-1/2 400 187 - - CH-- 1/1/0/0/0 0/0 "POST /login HTTP/1.1" Backend: 2017/12/29 08:01:36 [info] 7701#7701: *1191 epoll_wait() reported that client prematurely closed connection, so upstream connection is closed too while sending request to upstream, client: 92.70.20.xxx, server: dashboard.domain.com, request: "POST /login HTTP/1.1", upstream: "fastcgi://unix:/var/run/php-fpm/php5.sock:", host: "dashboard.domain.com", referrer: "https://dashboard.domain.com/login"; 2017/12/29 08:01:36 [info] 7701#7701: *1193 epoll_wait() reported that client prematurely closed connection, so upstream connection is closed too while sending request to upstream, client: 92.70.20.xxx, server: dashboard.domain.com, request: "POST /login HTTP/1.1", upstream: "fastcgi://unix:/var/run/php-fpm/php5.sock:", host: "dashboard.domain.com", referrer: https://dashboard.domain.com/login So haproxy says the client aborted while waiting for the server to start responding. https://snaps.hcdn.dk/AONBkWojDFwuErMjxF66Mg4VxJl9jz4KUM61jPpgcL.png - however the request is ~ 68-69 ms, and that browser is Google Chrome, so in that regard, the 400 Bad Request for POST/PUT also happens in Google Chrome. Which is the case for 1.8.2 and latest master. If I do the patch for 1.8.1 I still get BADREQ sometimes in haproxy with the “empty” GET requests. On nginx backend it looks like this: https://gist.github.com/lucasRolff/5eb0ae277c97b7457fbe546a1118e34f I do see a few connection resets, however these happen also when things work. However, that also confirms that “connection” header isn’t actually sent, despite Firefox says it’s sent in their dev tools. So, just so no misunderstandings happen, it seems there’s two things going wrong: ======= 1.8.1: - Firefox sometimes has issues with GET requests failing under http2 (Confirmed by Maximilian B) - Haproxy log shows: Dec 29 08:17:50 localhost haproxy[4881]: 92.70.20.xx:56726 [29/Dec/2017:08:17:17.178] https_frontend~ https_frontend/<NOSRV> -1/-1/-1/-1/33388 400 0 - - CR-- 24/1/0/0/0 0/0 "<BADREQ>" (CR == The client aborted before sending a full HTTP request) 1.8.2 and git master: - All browsers seem to suffer with occasional issues with POST/PUT requests, the GET requests issue still persist). (POST confirmed by Lukas T) - Haproxy log shows (for POST requests): Dec 29 08:09:27 localhost haproxy[4432]: 92.70.20.xx:54951 [29/Dec/2017:08:09:27.167] https_frontend~ cdn-backend/mycdn 0/0/0/-1/2 400 187 - - CH-- 1/1/0/0/0 0/0 "POST /login HTTP/1.1" (CH == The client aborted while waiting for the server to start responding), while backend server will see the request as aborted by the client as well. - - Client in scope of haproxy == browser - - Client in scope of backend == haproxy Semi conclusion: - Connection headers are not sent by Firefox, Safari or Webkit, despite webdev tools say so (in current versions at least) - Not able to replicate GET request failures in other browsers than Firefox despite doing thousands of requests (Tested Chrome, Safari, Opera, Webkit) - Some bug seems like it got introduced between 1.8.1 and 1.8.2 causing POST/PUT requests to fail in some cases What I’d like to know: - URL on haproxy.org that negotiates http2 correctly for Chrome and Firefox (not exactly sure why it doesn’t do it already?) ( https://snaps.hcdn.dk/JFsEzPmxspw9hnXuFyM5G4QGYst7Q6R2zXmkZbRRjz.png ) Best Regards, Lucas Rolff On 29/12/2017, 08.13, "Willy Tarreau" <[email protected]> wrote: Hi Lucas, On Fri, Dec 29, 2017 at 06:06:49AM +0000, Lucas Rolff wrote: > As much as I agree about that specs should be followed, I realized that even > if there's people that want to follow the spec 100%, there will always be > implementations used in large scale that won't be following the spec 100% - Absolutely, and the general principle always applies : "be strict in what you send, be liberal in what you accept". > the reasoning behind this can be multiple - one I could imagine is the fact > when browsers or servers start implementing a new protocol (h2 is a good > example) before the spec is actually 100% finalized - when it's then > finalized, the vendor might end up with a implementation that is slightly > violating the actual spec, but however either won't fix it because the > violations are minor or because the violations are not by any way "breaking" > when you also compare it to the other implementations done. Oh I know this pretty well, and you forget one of the most important aspects which is that browsers first implemented SPDY and then modified it to create H2. So some of the H2 rules were not closely followed initially because they were not possible to implement with the initial SPDY code. Also this early implementation before the protocol is 100% finalized is responsible for some of the dirty things that were promised to be fixed before the RFC but were rejected by some implementers who had already deployed (hpack header ordering, hpack encoding). > In this case if I understand you correctly, the errors are related to the > fact that certain clients didn't implement the spec correctly in first place. Yes but here we were speaking about a very recent client, which doesn't make much sense, especially with such an important header. > I was very curious why e.g. the Connection header (even if it isn't sent by > Firefox or Safari/Webkit even though their webdev tools say it is), would > work in nginx, and Apache for that matter, so I asked on their mailing list > why they were violating the spec. > > Valentin gave a rather interesting answer why they in their software actually > decided to sometimes violate specific parts, it all boiled down to client > support, because they also realized the fact that many browsers (that might > be EOL and never get updated), might have implementations that would not work > with http2 in that case. > > http://mailman.nginx.org/pipermail/nginx/2017-December/055356.html Oh I totally agree with all the points Valentin made there. We've all been forced to swallow a lot of ugly stuff to be compatible with existing deployments. Look at "option accept-invalid-http-requests/responses" to get an idea. Such ugly things even ended up as relaxed rules in the updated HTTP spec (723x), like support for multiple content-length headers that some clients or servers send and that we check for correctness. > I know that it's different software, and that how others decide to design > their software is completely up to them. It's important to keep in mind that haproxy's H2 support came very late. I participated a lot to the spec, even authored a proposal 6 years ago. But despite this I didn't have enough time to start implementing in haproxy by then. Most implementers already had a working SPDY implementation to start from, allowing them to progress much faster. Nginx was one of them, and as such they had to face all the early implementations and their issues. It's totally normal that they had to proceed like this. > Violating specs on purpose is generally bad, no doubt about that - but if > it's a requirement to be able to get good coverage in regards to clients > (both new and old browsers that are actually in use), then I understand why > one would go to such lengths as having to "hack" a bit to make sure generally > used browsers can use the protocol. We're always doing the same. Violating the specs on stuff you send is a big interoperability problem because you force all other ones to in turn violate the spec to support you. But violating the specs on stuff you accept is less big of a deal as long as it doesn't cause vulnerabilities. Silently dropping the connection-specific headers is no big deal, and clearly something we may have to do in the future if some trouble with existing clients are reported. Similarly when you run h2spec you'll see that sometimes we prefer to close using RST_STREAM than GOAWAY because the latter would require us to keep the stream "long enough" to remember about it, and we're not going to keep millions of streams in memory just for the sake of not breaking a connection once in a while. > > So at least my analysis for now is that for a reason still to be > > determined, this version of firefox didn't correctly interoperate with > > haproxy in a given environment > > Downgrading Firefox to earlier versions (such as 55, which is "pre"-quantum) > reveals the same issue with bad requests. Then I don't understand as it seems that different people are seeing different things. And even for me, 45.7, 52.0.2 and 57alpha never caused this to happen. I'm wondering if any browser plugin could be responsible for this header being emitted. This should clearly be asked on some firefox support list to confirm when this happens and why. > Hopefully you'll not have to violate the http2 spec in any way - but I do see > a valid point explained by Valentin - the fact that you cannot guarantee all > clients to be 100% compliant by the spec, and there might be a bunch of > (used) EOL devices around. I have no problem with this, and I agree with him about the fact that most of the rules result from overengineering, and from a wish to let the protocol fail very quickly on bad implementations to help all of them converge quickly. It's just that I want to have a *clear* and *reliable* report of the issue before starting to open holes in the spec and deal with complaints from people reporting that we're not compliant. And till now we don't know why this version of FF sometimes works and sometimes fails. > I used to work at a place where haproxy were used extensively, so seeing > http2 support getting better and better is a really awesome thing, because it > would actually mean that http2 could be implemented in that specific > environment - I do hope in a few releases that http2 in haproxy gets to a > point where we could rate it as "production ready", with no real visible bugs > from a customer perspective, at that point I think it would be good to > implement in a large scale environment (for a percentage of the requests) to > see how much traffic might actually get dropped in case the spec is followed > - to see from some real world workload how many clients actually violate the > spec. Yep. For what it's worth, it's been enabled for about one month on haproxy.org and till now we didn't get any bad report, which is pretty encouraging. > For now, I'll personally leave http2 support disabled - since it's breaking > my applications for a big percentage of my users, and I'll have to find an > intermediate solution until at least the bug in regards to Firefox losing > connections (this thing): > > Dec 28 21:22:35 localhost haproxy[1534]: 80.61.160.xxx:64921 [28/Dec/2017:21:22:12.309] https_frontend~ https_frontend/<NOSRV> -1/-1/-1/-1/22978 400 0 - - CR-- 1/1/0/0/0 0/0 "<BADREQ>" > Dec 28 21:22:40 localhost haproxy[1534]: 80.61.160.xxx:64972 [28/Dec/2017:21:22:35.329] https_frontend~ cdn-backend/mycdn 0/0/1/0/5001 200 995 - - ---- 1/1/0/1/0 0/0 "GET /js/app.js?v=1 HTTP/1.1" If this is met in production it definitely is a problem that we have to address. Could you please try the attached patch to see if it fixes the issue for you ? If so, I would at least like that we can keep some statistics on it, and maybe even condition it. > I never expect software to be bug free - but at this given point, this > specific issue that happens causes too much visible "trouble" for end-users > for me to be able to keep it enabled I'm all for working around visible issues. We're among the rare software on which the finger is always pointed because it's inserted in the middle of a chain and when something changes it's haproxy's fault (while sometimes it only reveals a long problem), forcing us to adapt. So if the attached patch fixes the problem for you we'll have to adapt. I still would like to figure when the browsers send this and why because I would hate it that the patch is later reverted because someone tries version 60 saying "look the header is not sent anymore" while it's not in the same condition. > I'll figure out if I can replicate the same issue in more browsers (without > connection: keep-alive header), maybe that would give us more insight. That could indeed help. Cheers, Willy
{kind=link}
{kind=link}