> On Thursday 29 March 2012 15:42:42 Joe Greco wrote: > > > Hi, > > Do both 32- and 64-bit versions of FreeBSD crash?
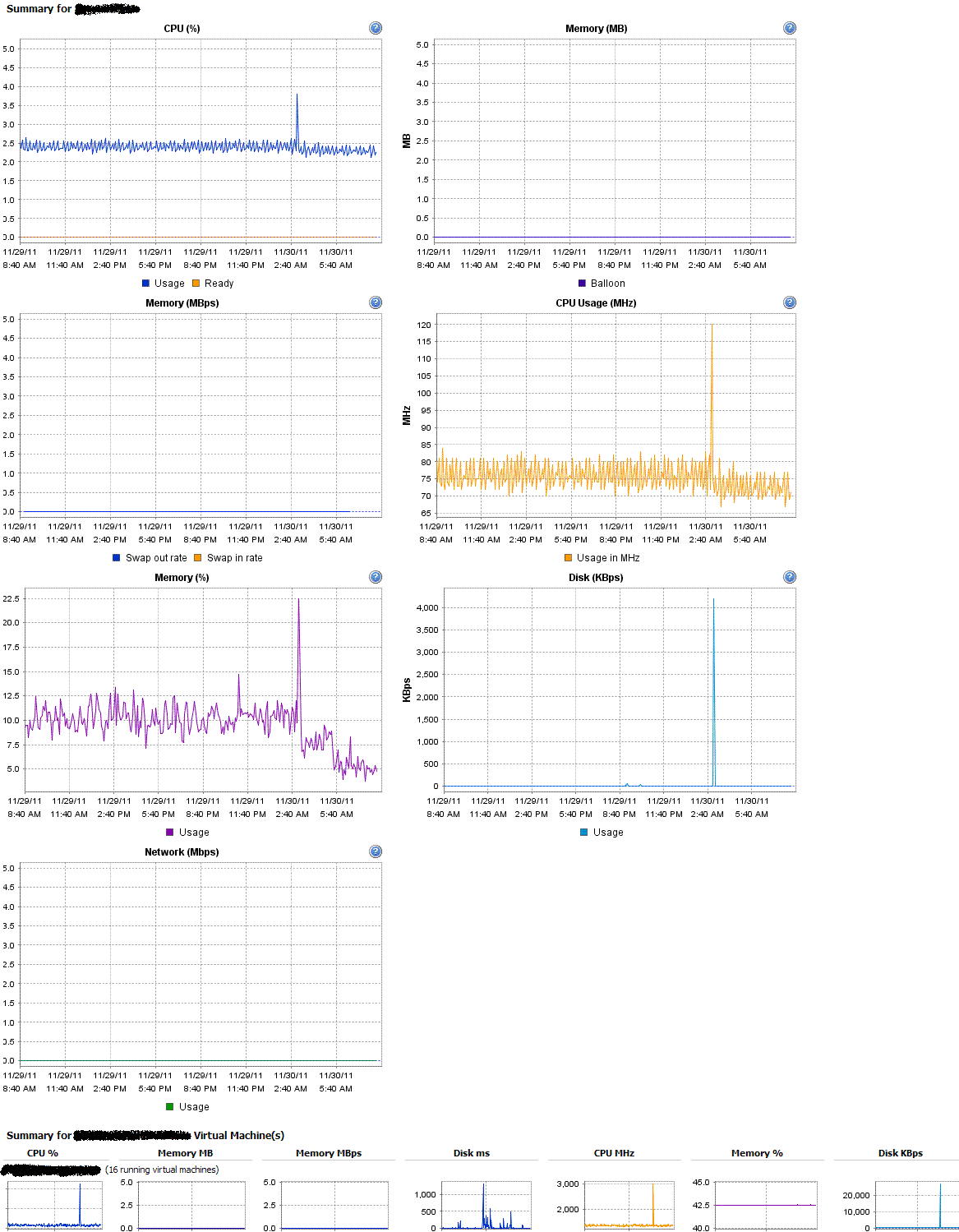
We've only seen it happen on one virtual machine. That was a 32-bit version. And it's not so much a crash as it is a "disk I/O hang". The fact that it was happening regularly to that one VM, while a bunch of other similar VM's were running alongside it without any incident, along with the problem moving with the VM as it is moved from host to host and from Opteron to Xeon, strongly points at something being wrong with the VM itself. Our systems are built mostly by script; I rebuilt the VM a few months ago and the problem vanished. The rebuilt system "should" have been virtually identical to the original. I never actually compared them though. My working theory was that something bad had happened to the VM during a migration from one datastore to another. We have a really slow-writing iSCSI server that it had been migrated onto for a little bit, which was where the problem first appeared, I believe. At first I thought it was the nightly cron jobs just exceeding the iSCSI server's capacity to cope, so we migrated the VM onto a host with local datastores, and it remained broken thereafter. So my conclusion was that it seemed likely that somehow VMware's thin provisioned disk image had gotten fouled up, and under some unknown use case, it could be teased into locking up further I/O on the VM. I wasn't able to prove it. I tried a read-dd of the entire disk - passed, flying. I tried several things to duplicate the nightly periodic tasks where it seemed so prone to locking up. They all ran fine. But if I left the machine run, it'd do it again eventually. I explained it at the time to one of my VMware friends: > But here's where it gets weird. Three times, now, one VM - our Jabber > server - has gone wonky in the wee early AM hours. Disk I/O on the VM > just locks up. You can type at the console until it does I/O, so you > can put in "root" at the login: prompt but never get a pw prompt. My > systems all run "top" from /etc/ttys and I can see that a whole bunch > of processes are stopped in "getblk". It's like the iSCSI disk has gone > away, except it hasn't, since the other VM's are all happily churning > away, on the same datastore, on the same VMware host. http://www.sol.net/tmp/freebsd/freebsd-esxi-lockup.gif > Now it's *possible* that the problem actually happens after the 3AM cron > run (note slight CPU/memory drop) but the Jabber implosion actually > happens around 0530, see drop in memory%. But the root problem at the > VM level seems to be that disk I/O has frozen. I can't tell for sure when > that happens. All three instances are similar to this. > > I can't explain this or figure out how to debug it. Since it's locked up > right now, thought I'd ping you for ideas before resetting it. Now that was actually before we migrated it back to local datastore, but when we did, the problem remained, suggesting that whatever has happened to the VM, it is contained within the VM's vmdk or other files. ... JG -- Joe Greco - sol.net Network Services - Milwaukee, WI - http://www.sol.net "We call it the 'one bite at the apple' rule. Give me one chance [and] then I won't contact you again." - Direct Marketing Ass'n position on e-mail spam(CNN) With 24 million small businesses in the US alone, that's way too many apples. _______________________________________________ freebsd-hackers@freebsd.org mailing list http://lists.freebsd.org/mailman/listinfo/freebsd-hackers To unsubscribe, send any mail to "freebsd-hackers-unsubscr...@freebsd.org"
{kind=link}