On Mon, Apr 27, 2015 at 9:36 AM, Shane Curcuru <[email protected]> wrote: > I'm interested in working on some visualizations of mailing list > activity over time, in particular some simple analyses, like thread > length/participants and the like. Given that the raw data can all be > precomputed from mbox archives, is there any semi-standard way to > distill and save metadata about mboxes? >
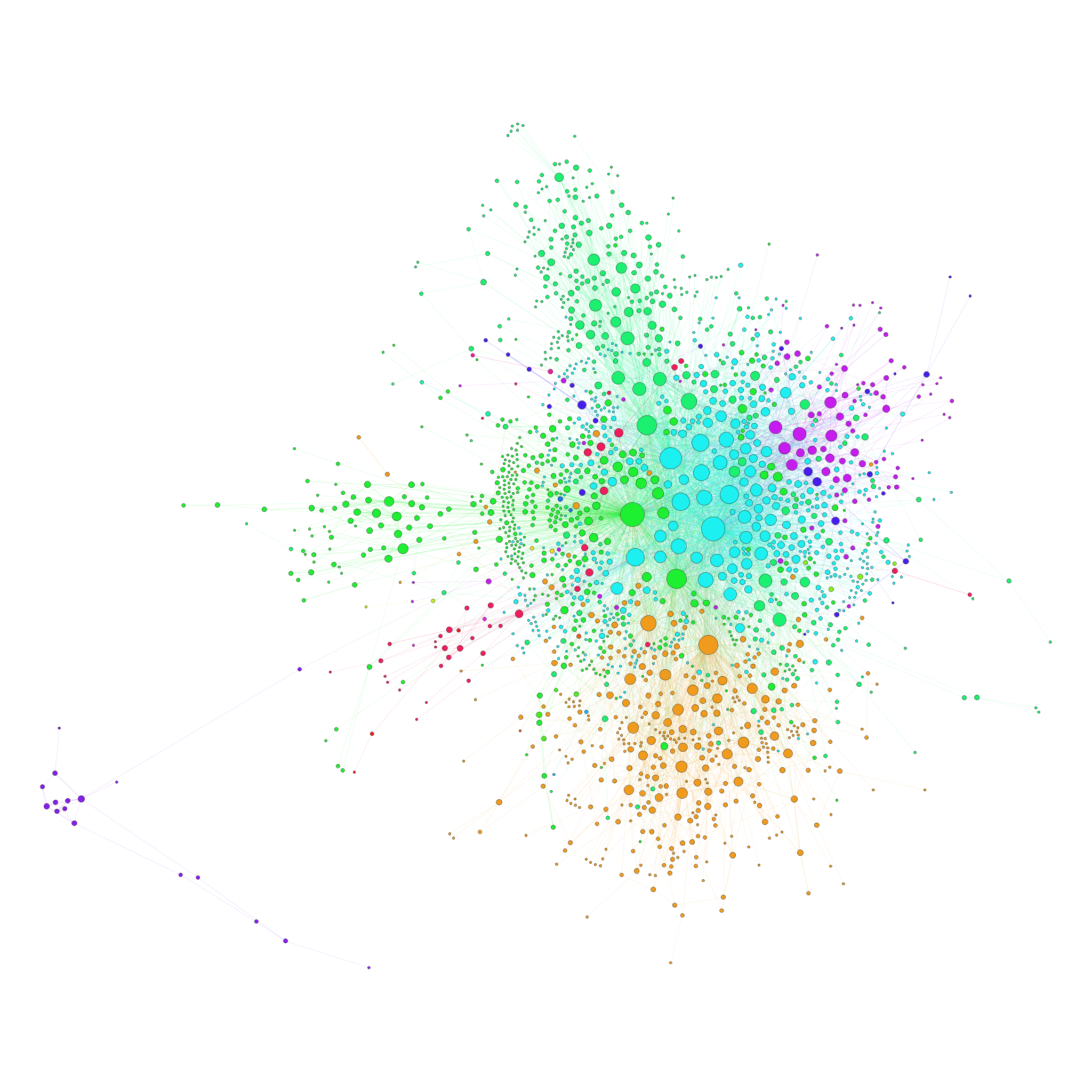
I've done some analysis of OpenOffice email archives, including some social network analysis that I wrote up here: http://www.robweir.com/blog/wp-content/uploads/2013/12/aoo-graph-large.png > If we had a generic static database of past mail metadata and statistics > (i.e. not details of contents, but perhaps overall # of lines of text or > something), it would be interesting to see what kinds of visualizations > that different people would come up with. > > Anyone have pointers to either a data format or the best parsing library > for this? I'm trying to think ahead, and work on the parsing, storing > statistics, and visualizations as separate pieces so it's easier for > different people to collaborate on something. > If you do Python, you might take a look at https://svn.apache.org/repos/asf/openoffice/devtools/list-stats/ for a simple program that could be adapted easily enough. It uses the Python mailbox library to do the parsing. The biggest challenge making sense of such data, for me at least, was the multiple email addresses a single person can use. Determining these aliases for a project you are involved in is possible, though tedious. Doing it for an unfamiliar project borders on the impossible. Another "fun" problem is getting all the post time data into the same UTC timezone. The mbox format does not seem to enforce a consistent way of encoding these. I see I have a few other analysis scripts on my harddrive I haven't checked in that handle the TZ and other issues. I'll get those checked in. It seems that, almost as good as pre-extracted data would be an easy API. Ever think of having a contest related to "Visualizing Apache"? I was considering proposing something like that for OpenOffice. Provide the data for download (already extracted from our transaction systems, so we don't get a harmful about of load on those servers) and invite the community to do the analysis, see what insights they can generate. Regards, -Rob > Thanks, > - Shane
{kind=link}