> Can't implementations add support as needed? I assume that the "depending on what support [it] aspires to" implies this, but if a feature isn't used in a community then it can leave it unimplemented. On the flip side, if it is used in a community (e.g. C++) is there no way to upstream it without the support of every community?
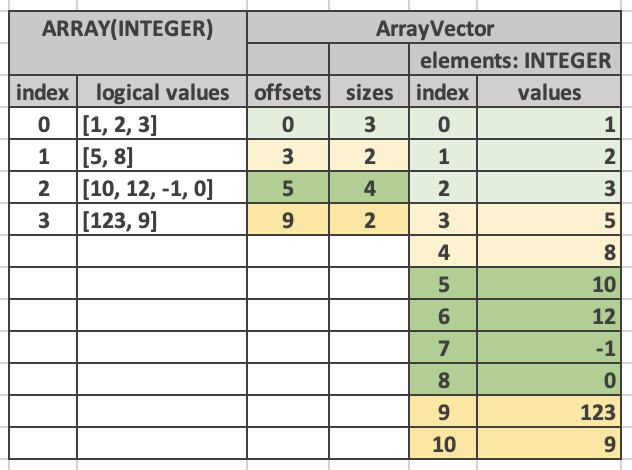
I think that is something that is more tolerable for something like REE or dictionary support which is purely additive (e.g. JS and C# don't support unions yet and can get around to it when it is important). The challenge for this kind of "alternative layout" is that you start to get a situation where some implementations choose "option A" and others choose "option B" and it's not clearly a case of "this is a feature we haven't added support for yet". On Wed, Jun 14, 2023 at 2:01 PM Antoine Pitrou <[email protected]> wrote: > > So each community would have its own version of the Arrow format? > > > Le 14/06/2023 à 22:47, Aldrin a écrit : > > > Arrow has at least 7 native "official" implementations... 5 bindings > > on C++... and likely other implementations (like arrow2 in rust) > > > >> I think it is worth remembering that depending on what level of support > > ListView aspires to, such an addition could require non trivial changes > to > > many / all of those implementations (and the APIs they expose). > > > > Can't implementations add support as needed? I assume that the > > "depending on what support [it] aspires to" implies this, but if a > > feature isn't used in a community then it can leave it unimplemented. On > > the flip side, if it is used in a community (e.g. C++) is there no way > > to upstream it without the support of every community? > > > > > > > > Sent from Proton Mail for iOS > > > > > > On Wed, Jun 14, 2023 at 13:06, Raphael Taylor-Davies > > <[email protected] <mailto:On Wed, Jun 14, 2023 at > > 13:06, Raphael Taylor-Davies <<a href=>> wrote: > >> Even something relatively straightforward becomes a huge implementation > >> effort when multiplied by a large number of codebases, users and > >> datasets. Parquet is a great source of historical examples of the > >> challenges of incremental changes that don't meaningfully unlock new > >> use-cases. To take just one, Int96 was deprecated almost a decade ago, > >> in favour of some additional metadata over an existing physical layout, > >> and yet Int96 is still to the best of my knowledge used by Spark by > >> default. > >> > >> That's not to say that I think the arrow specification should ossify and > >> we should never change it, but I'm not hugely enthusiastic about adding > >> encodings that are only incremental improvements over existing > encodings. > >> > >> I therefore wonder if there are some new use-cases I am missing that > >> would be unlocked by this change, and that wouldn't be supported by the > >> dictionary proposal? Perhaps you could elaborate here? Whilst I do agree > >> using dictionaries as proposed is perhaps a less elegant solution, I > >> don't see anything inherently wrong with it, and if it ain't broke we > >> really shouldn't be trying to fix it. > >> > >> Kind Regards, > >> > >> Raphael Taylor-Davies > >> > >> On 14 June 2023 17:52:52 BST, Felipe Oliveira Carvalho > >> <[email protected]> wrote: > >> > >> General approach to alternative formats aside, in the specific case > >> of ListView, I think the implementation complexity is being > >> overestimated in these discussions. The C++ Arrow implementation > >> shares a lot of code between List and LargeList. And with some > >> tweaks, I'm able to share that common infrastructure for ListView as > >> well. [1] ListView is similar to list: it doesn't require offsets to > >> be sorted and adds an extra buffer containing sizes. For symmetry > >> with the List and LargeList types (FixedSizeList not included), I'm > >> going to propose we add a LargeListView. That is not part of the > >> draft implementation yet, but seems like an obvious thing to have > >> now that I implemented the `if_else` specialization. [2] David Li > >> asked about this above and I can confirm now that 64-bit version of > >> ListView (LargeListView) is in the plans. Trying to avoid > >> re-implementing some kernels is not a good goal to chase, IMO, > >> because kernels need tweaks to take advantage of the format. [1] > >> https://github.com/apache/arrow/pull/35345 [2] > >> https://github.com/felipecrv/arrow/commits/list_view_backup -- > >> Felipe On Wed, Jun 14, 2023 at 12:08 PM Weston Pace > >> <[email protected]> wrote: > >> > >> perhaps we could support this use-case as a canonical > >> extension type over dictionary encoded, variable-sized arrays > >> > >> I believe this suggestion is valid and could be used to solve > >> the if-else case. The algorithm, if I understand it, would be > >> roughly: ``` // Note: Simple pseudocode, vectorization left as > >> exercise for the reader auto indices_builder = ... auto > >> list_builder = ... indices_builder.resize(batch.length); Array > >> condition_mask = condition.EvaluateBatch(batch); for row_index > >> in selected_rows(condition_mask): indices_builder[row_index] = > >> list_builder.CurrentLength(); > >> list_builder.Append(if_expr.EvaluateRow(batch, row_index)) for > >> row_index in unselected_rows(condition_mask): > >> indices_builder[row_index] = list_builder.CurrentLength(); > >> list_builder.Append(else_expr.EvaluateRow(batch, row_index)) > >> return DictionaryArray(indices_builder.Finish(), > >> list_builder.Finish()) ``` I also agree this is a slightly > >> awkward use of dictionaries (e.g. the dictionary would have the > >> same size as the # of indices) and perhaps not the most > >> intuitive way to solve the problem. My gut reaction is simply > >> "an improved if/else kernel is not, alone, enough justification > >> for a new layout" and yet... I think we are seeing the start (I > >> hope) of a trend where Arrow is not just used "between systems" > >> (e.g. to shuttle data from one place to another, or between a > >> query engine and a visualization tool) but also "within systems" > >> (e.g. UDFs, bespoke file formats and temporary tables, between > >> workers in a distributed query engine). When arrow is used > >> "within systems" I think both the number of bespoke formats and > >> the significance of conversion cost increases. For example, it's > >> easy to say that Velox should convert at the boundary as data > >> leaves Velox. But what if Velox (or datafusion or ...) were to > >> define an interface for UDFs. Would we want to use Arrow there > >> (e.g. the C data interface is a good fit)? If so, wouldn't the > >> conversion cost be more significant? > >> > >> Also, I'm very lukewarm towards the concept of "alternative > >> layouts" suggested somewhere else in this thread. It does > >> not seem a good choice to complexify the Arrow format that > >> much. > >> > >> I think, in my opinion, this depends on how many of these > >> alternative layouts exist. If there are just a few, then I > >> agree, we should just adopt them as formal first-class layouts. > >> If there are many, then I think it will be too much complexity > >> in Arrow to have all the different choices. Or, we could say > >> there are many, but the alternatives don't belong in Arrow at > >> all. In that case I think it's the same question as the above > >> paragraph, "do we want Arrow to be used within systems? Or just > >> between systems?" On Wed, Jun 14, 2023 at 2:07 AM Antoine Pitrou > >> <[email protected]> wrote: > >> > >> I agree that ListView cannot be an extension type, given > >> that it features a new layout, and therefore cannot > >> reasonably be backed by an existing storage type (AFAICT). > >> Also, I'm very lukewarm towards the concept of "alternative > >> layouts" suggested somewhere else in this thread. It does > >> not seem a good choice to complexify the Arrow format that > >> much. Regards Antoine. Le 07/06/2023 à 00:21, Felipe > >> Oliveira Carvalho a écrit : > >> > >> +1 on what Ian said. And as I write kernels for this new > >> format, I’m learning that it’s > >> > >> possible > >> > >> to re-use the common infrastructure used by List and > >> LargeList to > >> > >> implement > >> > >> the ListView related features with some adjustments. IMO > >> having this format as a second-class citizen would more > >> likely complicate things because it would make this > >> unification harder. — Felipe On Tue, 6 Jun 2023 at 18:45 > >> Ian Cook <[email protected]> wrote: > >> > >> To clarify why we cannot simply propose adding > >> ListView as a new “canonical extension type”: The > >> extension type mechanism in Arrow depends on the > >> underlying data being organized in an existing Arrow > >> layout—that way an implementation that does not > >> support the extension type can still handle the > >> underlying data. But ListView is a wholly new > >> layout. I strongly agree with Weston’s idea that it > >> is a good time for Arrow to introduce the notion of > >> “canonical alternative layouts.” Taken together, I > >> think that canonical extension types and canonical > >> alternative layouts could serve as an “incubator” > >> for proposed new representations. For example, if a > >> proposed canonical alternative layout ends up being > >> broadly adopted, then that will serve as a signal > >> that we should consider adding it as a primary > >> layout in the core spec. It seems to me that most > >> projects that are implementing Arrow today are not > >> aiming to provide complete coverage of Arrow; rather > >> they are adopting Arrow because of its role as a > >> standard and they are implementing only as much of > >> the Arrow standard as they require to achieve some > >> goal. I believe that such projects are important > >> Arrow stakeholders, and I believe that this proposed > >> notion of canonical alternative layouts will serve > >> them well and will create efficiencies by > >> standardizing implementations around a shared set of > >> alternatives. However I think that the documentation > >> for canonical alternative layouts should strongly > >> encourage implementers to default to using the > >> primary layouts defined in the core spec and only > >> use alternative layouts in cases where the primary > >> layouts do not meet their needs. On Sat, May 27, > >> 2023 at 7:44 PM Micah Kornfield < > >> > >> [email protected]> > >> > >> wrote: > >> > >> This sounds reasonable to me but my main concern > >> is, I'm not sure > >> > >> there > >> > >> is > >> > >> a great mechanism to enforce canonical layouts > >> don't somehow become > >> > >> default > >> > >> (or the only implementation). Even for these new > >> layouts, I think it might be worth rethinking > >> > >> binding > >> > >> a > >> > >> layout into the schema versus having a different > >> concept of encoding > >> > >> (and > >> > >> changing some of the corresponding data > >> structures). On Mon, May 22, 2023 at 10:37 AM > >> Weston Pace <[email protected]> > >> > >> wrote: > >> > >> Trying to settle on one option is a > >> fruitless endeavor. Each type > >> > >> has > >> > >> pros > >> > >> and cons. I would also predict that the > >> largest existing usage of > >> > >> Arrow is > >> > >> shuttling data from one system to another. > >> The newly proposed > >> > >> format > >> > >> doesn't appear to have any significant > >> advantage for that use case > >> > >> (if > >> > >> anything, the existing format is arguably > >> better as it is more > >> > >> compact). > >> > >> I am very biased towards historical > >> precedent and avoiding breaking changes. We > >> have "canonical extension types", perhaps it > >> is time for > >> > >> "canonical > >> > >> alternative layouts". We could define it as > >> such: * There are one or more primary > >> layouts * Existing layouts are automatically > >> considered primary layouts, > >> > >> even if > >> > >> they wouldn't have been primary layouts > >> initially (e.g. large list) * A new layout, > >> if it is semantically equivalent to another, is > >> > >> considered > >> > >> an alternative layout * An alternative > >> layout still has the same requirements for > >> > >> adoption > >> > >> (two > >> > >> implementations and a vote) * An > >> implementation should not feel pressured to > >> rush and > >> > >> implement > >> > >> the > >> > >> new layout. It would be good if they > >> contribute in the discussion and > >> > >> consider the > >> > >> layout and vote if they feel it would be an > >> acceptable design. * We can define and vote > >> and approve as many canonical alternative > >> > >> layouts > >> > >> as we want: * A canonical alternative layout > >> should, at a minimum, have some reasonable > >> justification, such as improved performance for > >> > >> algorithm X > >> > >> * Arrow implementations MUST support the > >> primary layouts * An Arrow implementation > >> MAY support a canonical alternative, > >> > >> however: > >> > >> * An Arrow implementation MUST first support > >> the primary layout * An Arrow implementation > >> MUST support conversion to/from the > >> > >> primary > >> > >> and canonical layout * An Arrow > >> implementation's APIs MUST only provide data > >> in the alternative layout if it is > >> explicitly asked for (e.g. schema inference > >> > >> should > >> > >> prefer the primary layout). * We can still > >> vote for new primary layouts (e.g. promoting a > >> > >> canonical > >> > >> alternative) but, in these votes we don't > >> only consider the value (e.g. performance) of > >> > >> the > >> > >> layout > >> > >> but also the interoperability. In other > >> words, a layout can only become a primary > >> layout if > >> > >> there > >> > >> is > >> > >> significant evidence that most > >> implementations plan to adopt it. This lets > >> us evolve support for new layouts more > >> naturally. We can generally assume that > >> users will not, initially, be aware of these > >> alternative layouts. However, everything > >> will just work. They may > >> > >> start > >> > >> to see a performance penalty stemming from a > >> lack of support for > >> > >> these > >> > >> layouts. If this performance penalty becomes > >> significant then they > >> > >> will > >> > >> discover it and become aware of the problem. > >> They can then ask > >> > >> whatever > >> > >> library they are using to add support for > >> the alternative layout. > >> > >> As > >> > >> enough users find a need for it then > >> libraries will add support. Eventually, > >> enough libraries will support it that we can > >> adopt it > >> > >> as a > >> > >> primary layout. Also, it allows libraries to > >> adopt alternative layouts more > >> > >> aggressively if > >> > >> they would like while still hopefully > >> ensuring that we eventually > >> > >> all > >> > >> converge on the same implementation of the > >> alternative layout. On Mon, May 22, 2023 at > >> 9:35 AM Will Jones <[email protected] > >> > >> wrote: > >> > >> Hello Arrow devs, I don't understand why > >> we would start deprecating features in the > >> > >> Arrow > >> > >> format. Even starting this talk > >> might already be a bad idea > >> > >> PR-wise. > >> > >> I agree we don't want to make breaking > >> changes to the Arrow format. > >> > >> But > >> > >> several maintainers have already stated > >> they have no interest in maintaining > >> both list types with full compute > >> functionality [1][2], > >> > >> so I > >> > >> think it's very likely one list type or > >> the other will be implicitly preferred > >> in the ecosystem if this data type was > >> added. > >> > >> If > >> > >> that's the case, I'd prefer that we > >> agreed as a community which one > >> > >> should > >> > >> be preferred. Maybe that's not the best > >> path; it's just one way for > >> > >> us to > >> > >> balance stability, maintenance burden, > >> and relevance. Can someone help distill > >> down the primary rationale and usecase for > >> > >> adding ArrayView to the Arrow Spec? > >> > >> Looking back at that old thread, I think > >> one of the main > >> > >> motivations > >> > >> is > >> > >> to > >> > >> try to prevent query engine implementers > >> from feeling there is a > >> > >> tradeoff > >> > >> between having state-of-the-art > >> performance and being Arrow-native. > >> > >> For > >> > >> some of the new array types, we had both > >> Velox and DuckDB use them, > >> > >> so it > >> > >> was reasonable to expect they were > >> innovations that might > >> > >> proliferate. > >> > >> I'm > >> > >> not sure if the ArrayView is part of > >> that. From Wes earlier [3]: The idea is > >> that in a world of data and query > >> federation (for > >> > >> example, > >> > >> consider [1] where Arrow is being > >> used as a data federation layer > >> > >> with > >> > >> many > >> > >> query engines), we want to increase > >> the amount of data in-flight > >> > >> and > >> > >> in-memory that is in Arrow format. > >> So if query engines are having > >> > >> to > >> > >> depart > >> > >> substantially from the Arrow format > >> to get performance, then this > >> > >> creates a > >> > >> potential lose-lose situation: * > >> Depart from Arrow: get better > >> > >> performance > >> > >> but pay serialization costs to read > >> and write Arrow (the > >> > >> performance > >> > >> and > >> > >> resource utilization benefits > >> outweigh the serialization costs). > >> > >> This > >> > >> puts > >> > >> additional pressure on query engines > >> to build specialized > >> > >> components > >> > >> for > >> > >> solving problems rather than making > >> use of off-the-shelf > >> > >> components > >> > >> that > >> > >> use Arrow. This has knock-on effects > >> on ecosystem fragmentation. * > >> > >> Or > >> > >> use > >> > >> Arrow, and accept suboptimal query > >> processing performance > >> > >> Will mentions one usecase is Velox > >> consuming python UDF output, > >> > >> which > >> > >> seems > >> > >> to be mostly about how fast Velox > >> can consume this format, not how > >> > >> fast > >> > >> it > >> > >> can be written. Are there other > >> usecases? > >> > >> To be clear, I don't know if that's the > >> use case they want. That's > >> > >> just > >> > >> me > >> > >> speculating. I still have some questions > >> myself: 1. Is this array type currently > >> only used in Velox? (not DuckDB > >> > >> like > >> > >> some > >> > >> of the other new types?) What evidence > >> do we have that it will > >> > >> become > >> > >> used > >> > >> outside of Velox? 2. We already have > >> three list types: list, large list (64-bit > >> > >> offsets), > >> > >> and > >> > >> fixed size list. Do we think we will > >> only want a view version of > >> > >> the > >> > >> 32-bit > >> > >> offset variable length list? Or are we > >> potentially talking about > >> > >> view > >> > >> variants for all three? Best, Will Jones > >> [1] > >> > >> https://lists.apache.org/thread/smn13j1rnt23mb3fwx75sw3f877k3nwx > >> > >> [2] > >> > >> https://lists.apache.org/thread/cc4w3vs3foj1fmpq9x888k51so60ftr3 > >> > >> [3] > >> > >> https://lists.apache.org/thread/mk2yn62y6l8qtngcs1vg2qtwlxzbrt8t > >> > >> On Mon, May 22, 2023 at 3:48 AM Andrew > >> Lamb <[email protected]> > >> > >> wrote: > >> > >> Can someone help distill down the > >> primary rationale and usecase > >> > >> for > >> > >> adding ArrayView to the Arrow Spec? > >> From the above discussions, the > >> stated rationale seems to be fast > >> (zero-copy) interchange with Velox. > >> This thread has qualitatively > >> enumerated the benefits of > >> > >> (offset+len) > >> > >> encoding over the existing Arrow > >> ListArray (offets) approach, but > >> > >> I > >> > >> haven't > >> > >> seen any performance measurements > >> that might help us to gauge the > >> > >> tradeoff > >> > >> in additional complexity vs runtime > >> overhead. Will mentions one usecase > >> is Velox consuming python UDF output, > >> > >> which > >> > >> seems > >> > >> to be mostly about how fast Velox > >> can consume this format, not how > >> > >> fast > >> > >> it > >> > >> can be written. Are there other > >> usecases? Do we have numbers showing > >> how much overhead converting to /from > >> > >> Velox's > >> > >> internal representation and the > >> existing ListArray adds? Has > >> > >> anyone in > >> > >> Velox land considered adding faster > >> support for Arrow style > >> > >> ListArray > >> > >> encoding? Andrew On Mon, May 22, > >> 2023 at 4:38 AM Antoine Pitrou < > >> > >> [email protected] > >> > >> wrote: > >> > >> Hi, I don't understand why we > >> would start deprecating features > >> in the > >> > >> Arrow > >> > >> format. Even starting this talk > >> might already be a bad idea > >> > >> PR-wise. > >> > >> As for implementing conversions > >> at the I/O boundary, it's a > >> > >> reasonably > >> > >> policy, but it still requires > >> work by implementors and it's not > >> > >> granted > >> > >> that all consumers of the Arrow > >> format will grow such > >> conversions if/when we add > >> non-trivial types such as > >> ListView or StringView. Regards > >> Antoine. Le 22/05/2023 à 00:39, > >> Will Jones a écrit : > >> > >> One more thing: Looking back > >> on the previous discussion[1] > >> > >> (which > >> > >> Weston > >> > >> pointed out in his earlier > >> message), Jorge suggested > >> that the > >> > >> old > >> > >> list > >> > >> types might be deprecated in > >> favor of view variants [2]. > >> Others > >> > >> were > >> > >> worried that it might > >> undermine the perception > >> that the Arrow > >> > >> format > >> > >> is > >> > >> stable. I think it might be > >> worth thinking about "soft > >> > >> deprecating" > >> > >> the > >> > >> old > >> > >> list type: suggesting new > >> implementations prefer the list > >> > >> view, but > >> > >> reassuring that > >> implementations should > >> support the old format, > >> > >> even > >> > >> if > >> > >> they > >> > >> just convert to the new > >> format. To be clear, this > >> wouldn't > >> > >> mean we > >> > >> plan > >> > >> to > >> > >> create breaking changes in > >> the format; but if we ever > >> did for > >> > >> other > >> > >> reasons, the old list type > >> might go. Arrow compute > >> libraries could choose > >> either format for compute > >> > >> support, > >> > >> and > >> > >> plan to do conversion at the > >> boundaries. Libraries that use > >> > >> the new > >> > >> type > >> > >> will have cheap conversion > >> when reading the old type. > >> Meanwhile > >> > >> those > >> > >> that > >> > >> are still on the old type > >> will have some incentive to > >> move > >> > >> towards > >> > >> the > >> > >> new > >> > >> one, since that conversion > >> will not be as efficient. [1] > >> > >> https://lists.apache.org/thread/49qzofswg1r5z7zh39pjvd1m2ggz2kdq > >> > >> > >> [2] > >> > >> https://lists.apache.org/thread/smn13j1rnt23mb3fwx75sw3f877k3nwx > >> > >> > >> On Sun, May 21, 2023 at > >> 3:07 PM Will Jones < > >> > >> [email protected]> > >> > >> wrote: > >> > >> Hello, I think Sasha > >> brings up a good point, > >> that the advantages of > >> > >> this > >> > >> format > >> > >> seem to be primarily > >> about query processing. > >> Other encodings > >> > >> like > >> > >> REE > >> > >> and > >> > >> dictionary have > >> space-saving advantages > >> that justify them > >> > >> simply > >> > >> in > >> > >> terms > >> > >> of space efficiency > >> (although they have > >> query processing > >> > >> advantages > >> > >> as > >> > >> well). As discussed, > >> most use cases are > >> already well served by > >> > >> existing > >> > >> list types and > >> dictionary encoding. I > >> agree that there are > >> cases where transferring > >> this type > >> > >> without > >> > >> conversion would be > >> ideal. One use case I > >> can think of is if > >> > >> Velox > >> > >> wants to > >> > >> be able to take > >> Arrow-based UDFs > >> (possibly written with > >> > >> PyArrow, > >> > >> for > >> > >> example) that operate on > >> this column type and > >> therefore wants > >> > >> zero-copy > >> > >> exchange over the C Data > >> Interface. One big > >> question I have: we > >> already have three list > >> types: > >> > >> list, > >> > >> large > >> > >> list (64-bit offsets), > >> and fixed size list. Do > >> we think we > >> > >> will > >> > >> only > >> > >> want a > >> > >> view version of the > >> 32-bit offset variable > >> length list? Or > >> > >> are we > >> > >> potentially talking > >> about view variants for > >> all three? Best, Will > >> Jones On Sun, May 21, > >> 2023 at 2:19 PM Felipe > >> Oliveira Carvalho < > >> [email protected]> wrote: > >> > >> The benefit of > >> having a memory > >> format that’s > >> friendly to > >> > >> non-deterministic > >> > >> order writes is > >> unlocked by the > >> transport and > >> processing of > >> > >> the > >> > >> data > >> > >> being > >> > >> agnostic to the > >> physical order as > >> much as possible. > >> Requiring a > >> conversion could > >> cancel out that > >> benefit. But it > >> > >> can > >> > >> be a > >> > >> provisory step for > >> compatibility > >> between systems that > >> don’t > >> > >> understand > >> > >> the > >> > >> format yet. This is > >> similar to the > >> situation with > >> compression > >> > >> schemes > >> > >> like > >> > >> run-end encoding — > >> the goal is > >> processing the > >> compressed data > >> > >> directly > >> > >> without an expansion > >> step whenever > >> possible. This is > >> why having it as > >> part of the open > >> Arrow format is so > >> > >> important: > >> > >> everyone can agree > >> on a format that’s > >> friendly to parallel > >> > >> and/or > >> > >> vectorized compute > >> kernels without > >> introducing multiple > >> > >> incompatible > >> > >> formats to the > >> ecosystem and > >> without imposing a > >> conversion > >> > >> step > >> > >> between > >> > >> the different > >> systems. — Felipe On > >> Sat, 20 May 2023 at > >> 20:04 Aldrin > >> > >> <[email protected]> > >> > >> wrote: > >> > >> I don't feel > >> like this > >> representation > >> is necessarily a > >> > >> detail of > >> > >> the > >> > >> query > >> > >> engine, but I am > >> also not sure > >> why this > >> representation > >> would > >> > >> have > >> > >> to > >> > >> be > >> > >> converted to a > >> non-view format > >> when > >> serializing. > >> Could you > >> > >> clarify > >> > >> that? My > >> > >> impression is > >> that this > >> representation > >> could be used for > >> > >> persistence > >> > >> or > >> > >> data transfer, > >> though it can be > >> more complex to > >> guarantee > >> > >> the > >> > >> portion > >> > >> of > >> > >> the buffer that > >> an index points > >> to is also > >> present in > >> > >> memory. > >> > >> Sent from Proton > >> Mail for iOS On > >> Sat, May 20, > >> 2023 at 15:00, > >> Sasha Krassovsky < > >> > >> [email protected] > >> > >> > >> <On+Sat,+May+20,+2023+at+15:00,+Sasha+Krassovsky+%3C%3Ca+href=>> > >> > >> > >> wrote: > >> > >> Hi everyone, I > >> understand that > >> there are > >> numerous > >> benefits to this > >> > >> representation > >> > >> during query > >> processing, but > >> would it be fair > >> to say that > >> > >> this > >> > >> is > >> > >> an > >> > >> implementation > >> detail of the > >> query engine? > >> Query engines > >> > >> don’t > >> > >> necessarily > >> > >> need to conform > >> to the Arrow > >> format > >> internally, only at > >> > >> ingest/egress > >> > >> points, and > >> performing a > >> conversion from > >> the non-view to > >> > >> view > >> > >> format > >> > >> seems > >> > >> like it would be > >> very cheap > >> (though I > >> understand not > >> > >> necessarily > >> > >> the > >> > >> other > >> > >> way around, but > >> you’d need to do > >> that anyway if > >> you’re > >> > >> serializing). > >> > >> Sasha Krassovsky > >> > >> 20 мая 2023 > >> г., в 13:00, > >> Will Jones < > >> > >> [email protected]> > >> > >> написал(а): > >> > >> Thanks for > >> sharing > >> these > >> details, > >> Pedro. The > >> conditional > >> > >> branches > >> > >> argument > >> > >> makes a lot > >> of sense to > >> me. The > >> tensors > >> point brings > >> up some > >> interesting > >> issues. For > >> > >> now, > >> > >> we've > >> > >> defined > >> > >> our only > >> tensor > >> extension > >> type to be > >> built on a > >> fixed size > >> > >> list. > >> > >> If a > >> > >> use > >> > >> case of this > >> might be > >> manipulating > >> tensors with > >> zero copy, > >> > >> perhaps > >> > >> that > >> > >> suggests > >> that we want > >> a fixed size > >> list > >> variant? In > >> > >> addition, > >> > >> would > >> > >> we > >> > >> have > >> > >> to define > >> another > >> extension > >> type to be a > >> ListView > >> variant? > >> > >> Or > >> > >> would > >> > >> we > >> > >> want > >> > >> to think > >> about making > >> extension > >> types > >> somehow > >> valid across > >> > >> various > >> > >> encodings of > >> the same > >> "logical type"? > >> > >> On Fri, > >> May 19, > >> 2023 at > >> 1:59 PM > >> Pedro > >> Eugenio > >> Rocha > >> > >> Pedreira > >> > >> <[email protected]> > >> wrote: > >> Hi all, > >> This is > >> Pedro > >> from the > >> Velox > >> team at > >> Meta. > >> This is my > >> > >> first > >> > >> time > >> > >> here, > >> > >> so > >> > >> nice to > >> e-meet > >> you! > >> Adding > >> to what > >> Felipe > >> said, > >> the main > >> reason > >> we created > >> > >> “ListView” > >> > >> (though > >> > >> we just > >> call > >> them > >> ArrayVector/MapVector > >> in > >> Velox) > >> is that, > >> > >> along > >> > >> with > >> > >> StringViews > >> for > >> strings, > >> they > >> allow us > >> to write > >> any > >> > >> columnar > >> > >> buffer > >> > >> out-or-order, > >> regardless > >> of their > >> types or > >> encodings. > >> > >> This is > >> > >> naturally > >> > >> doable > >> for all > >> primitive > >> types > >> (fixed-size), > >> but not for > >> > >> types > >> > >> that > >> > >> don’t > >> > >> have > >> fixed > >> size and > >> are > >> required > >> to be > >> contiguous. > >> The > >> > >> StringView > >> > >> and > >> > >> ListView > >> formats > >> allow us > >> to keep > >> this > >> invariant > >> in > >> Velox. > >> Being > >> able to > >> write > >> vectors > >> out-of-order > >> is > >> useful when > >> > >> executing > >> > >> conditionals > >> like > >> IF/SWITCH > >> statements, > >> which are > >> > >> pervasive > >> > >> among > >> > >> our > >> > >> workloads. > >> To fully > >> vectorize > >> it, one > >> first > >> evaluates > >> the > >> > >> expression, > >> > >> then > >> > >> generate > >> a bitmap > >> containing > >> which > >> rows > >> take the > >> THEN and > >> > >> which > >> > >> take > >> > >> the > >> > >> ELSE > >> branch. > >> Then you > >> populate > >> all rows > >> that > >> match the > >> > >> first > >> > >> branch > >> > >> by > >> > >> evaluating > >> the THEN > >> expression > >> in a > >> vectorized > >> > >> (branch-less > >> > >> and > >> > >> cache > >> > >> friendly) > >> way, and > >> subsequently > >> the ELSE > >> branch. > >> If you > >> > >> can’t > >> > >> write > >> > >> them > >> > >> out-of-order, > >> you > >> would > >> either > >> have a > >> big > >> branch > >> per row > >> > >> dispatching > >> > >> to > >> > >> the > >> > >> right > >> expression > >> (slow), > >> or > >> populate > >> two > >> distinct > >> vectors > >> > >> then > >> > >> merging > >> > >> them > >> > >> at the > >> end > >> (potentially > >> even > >> slower). > >> How much > >> faster our > >> > >> approach > >> > >> is > >> > >> highly > >> depends > >> on the > >> buffer > >> sizes > >> and > >> expressions, > >> but we > >> > >> found > >> > >> it > >> > >> to > >> > >> be > >> > >> faster > >> enough > >> on > >> average > >> to > >> justify > >> us > >> extending > >> the > >> > >> underlying > >> > >> layout. > >> > >> With > >> that > >> said, > >> this is > >> all > >> within a > >> single > >> thread of > >> > >> execution. > >> > >> Parallelization > >> is done > >> by > >> feeding > >> each > >> thread > >> its own > >> > >> vector/data. > >> > >> As > >> > >> pointed > >> out in a > >> previous > >> message, > >> this > >> also > >> gives > >> you the > >> > >> flexibility > >> > >> to > >> > >> implement > >> cardinality > >> increasing/reducing > >> operations, > >> but > >> > >> we > >> > >> don’t > >> > >> use > >> > >> it > >> > >> for that > >> purpose. > >> Operations > >> like > >> filtering, > >> joining, > >> > >> unnesting > >> > >> and > >> > >> similar > >> > >> are done > >> by > >> wrapping > >> the > >> internal > >> vector > >> in a > >> dictionary, > >> > >> as > >> > >> these > >> > >> need > >> > >> to > >> > >> work not > >> only on > >> “ListViews” > >> but on > >> any data > >> types with > >> > >> any > >> > >> encoding. > >> > >> There > >> > >> are more > >> details > >> on > >> Section > >> 4.2.1 in > >> [1] > >> Beyond > >> this, it > >> also > >> gives > >> function/kernel > >> developers > >> more > >> > >> flexibility > >> > >> to > >> > >> implement > >> operations > >> that > >> manipulate > >> Arrays/Maps. > >> For > >> > >> example, > >> > >> operations > >> > >> that > >> slice > >> these > >> containers > >> can be > >> implemented > >> in a > >> > >> zero-copy > >> > >> manner > >> > >> by > >> > >> just > >> rearranging > >> the > >> lengths/offsets > >> indices, > >> without > >> ever > >> > >> touching > >> > >> the > >> > >> larger > >> internal > >> buffers. > >> This is > >> a > >> similar > >> motivation > >> as > >> > >> for > >> > >> StringView > >> > >> (think > >> of > >> substr(), > >> trim(), > >> and > >> similar). > >> One nice > >> last > >> > >> property > >> > >> is > >> > >> that > >> > >> this > >> layout > >> allows > >> for > >> overlapping > >> ranges. > >> This is > >> > >> something > >> > >> discussed > >> > >> with > >> > >> our ML > >> people > >> to allow > >> deduping > >> feature > >> values > >> in a tensor > >> > >> (which > >> > >> is > >> > >> fairly > >> > >> common), > >> but not > >> something > >> we have > >> leveraged > >> just > >> yet. [1] > >> - > >> https://vldb.org/pvldb/vol15/p3372-pedreira.pdf > >> Best, -- > >> Pedro > >> Pedreira > >> ------------------------------------------------------------------------ > >> From: > >> Felipe > >> Oliveira > >> Carvalho > >> <[email protected]> > >> Sent: > >> Friday, > >> May 19, > >> 2023 > >> 10:01 AM > >> To: > >> [email protected] > >> <[email protected]> > >> Cc: > >> Pedro > >> Eugenio > >> Rocha > >> Pedreira > >> <[email protected]> > >> Subject: > >> Re: > >> [DISCUSS][Format] > >> Starting > >> the draft > >> > >> implementation > >> > >> of > >> > >> the > >> > >> ArrayView > >> array > >> format > >> +pedroerp > >> On Thu, > >> 11 May > >> 2023 at > >> 17: 51 > >> Raphael > >> > >> Taylor-Davies > >> > >> <r. > >> > >> taylordavies@ > >> googlemail. > >> com. > >> invalid> > >> wrote: > >> Hi All, > > >> > >> if > >> > >> we > >> > >> added > >> > >> this, do > >> we think > >> many > >> Arrow > >> and > >> query > > >> engine > >> > >> implementations > >> > >> (for > >> > >> example, > >> DataFusion) > >> will be > >> ZjQcmQRYFpfptBannerStart > >> This > >> Message > >> Is From > >> an > >> External > >> Sender > >> ZjQcmQRYFpfptBannerEnd > >> +pedroerp > >> On Thu, > >> 11 May > >> 2023 at > >> 17:51 > >> Raphael > >> Taylor-Davies > >> <[email protected]> > >> wrote: > >> Hi All, > >> > >> if > >> we > >> added > >> this, > >> do > >> we > >> think > >> many > >> Arrow > >> and > >> query > >> engine > >> implementations > >> (for > >> example, > >> DataFusion) > >> will be > >> > >> eager > >> > >> to > >> > >> add > >> > >> full > >> > >> support > >> for > >> the > >> type, > >> including > >> compute > >> kernels? > >> Or are > >> > >> they > >> > >> likely > >> > >> to > >> > >> just > >> > >> convert > >> this > >> type > >> to > >> ListArray > >> at > >> import > >> boundaries? > >> > >> > >> I can't > >> speak > >> for > >> query > >> engines > >> in > >> general, > >> but at > >> least > >> > >> for > >> > >> arrow-rs > >> > >> and by > >> extension > >> DataFusion, > >> and > >> based on > >> my current > >> > >> understanding > >> > >> of > >> > >> the > >> use-cases > >> I would > >> be > >> rather > >> hesitant > >> to add > >> support > >> > >> to the > >> > >> kernels > >> > >> for this > >> array > >> type, > >> definitely > >> instead > >> favouring > >> > >> conversion > >> > >> at > >> > >> the > >> > >> edges. > >> We > >> already > >> have > >> issues > >> with the > >> amount > >> of code > >> > >> generation > >> > >> resulting > >> in > >> binary > >> bloat > >> and long > >> compile > >> times, > >> and I > >> > >> worry > >> > >> this > >> > >> would > >> > >> worsen > >> this > >> situation > >> whilst > >> not > >> really > >> providing > >> > >> compelling > >> > >> advantages > >> > >> for the > >> vast > >> majority > >> of > >> workloads > >> that > >> don't > >> interact > >> > >> with > >> > >> Velox. > >> > >> Whilst I > >> can > >> definitely > >> see that > >> the > >> ListView > >> > >> representation > >> > >> is > >> > >> probably > >> > >> a better > >> way to > >> represent > >> variable > >> length > >> lists > >> than what > >> > >> arrow > >> > >> settled > >> > >> upon, > >> I'm not > >> yet > >> convinced > >> it is > >> sufficiently > >> better to > >> > >> incentivise > >> > >> broad > >> ecosystem > >> adoption. > >> Kind > >> Regards, > >> Raphael > >> Taylor-Davies > >> > >> > >> On > >> 11/05/2023 > >> 21:20, > >> Will > >> Jones > >> wrote: > >> Hi > >> Felipe, > >> Thanks > >> for > >> the > >> additional > >> details. > >> > >> > >> Velox > >> kernels > >> benefit > >> from > >> being > >> able > >> to > >> append > >> data > >> to > >> > >> the > >> > >> array > >> > >> from > >> > >> different > >> threads > >> without > >> care > >> for > >> strict > >> ordering. > >> > >> > >> Only the > >> > >> offsets > >> > >> array > >> > >> has > >> to > >> be > >> written > >> according > >> to > >> logical > >> order > >> but > >> that > >> is > >> > >> potentially a > >> > >> much > >> > >> smaller > >> buffer > >> than > >> the > >> values > >> buffer. > >> > >> > >> It > >> still > >> seems > >> to > >> me > >> like > >> applications > >> are > >> still > >> pretty > >> > >> niche, > >> > >> as I > >> > >> suspect > >> > >> in > >> most > >> cases > >> the > >> benefits > >> are > >> outweighed > >> by > >> the > >> costs. > >> > >> The > >> > >> benefit > >> > >> here > >> > >> seems > >> pretty > >> limited: > >> if > >> you > >> are > >> trying > >> to > >> split > >> work > >> > >> between > >> > >> threads, > >> > >> usually > >> you > >> will > >> have > >> other > >> levels > >> such > >> as > >> array > >> chunks > >> > >> to > >> > >> parallelize. > >> > >> And > >> > >> if > >> you > >> have > >> an > >> incoming > >> stream > >> of > >> row > >> data, > >> you'll > >> want > >> > >> to > >> > >> append > >> > >> in > >> > >> predictable > >> order > >> to > >> match > >> the > >> order > >> of > >> the > >> other > >> > >> arrays. Am > >> > >> I > >> > >> missing > >> > >> something? > >> And, > >> IIUC, > >> the > >> cost > >> of > >> using > >> ListView > >> with > >> out-of-order > >> > >> > >> values > >> > >> over > >> > >> ListArray > >> is > >> you > >> lose > >> memory > >> locality; > >> the > >> values > >> of > >> > >> element > >> > >> 2 > >> > >> are > >> > >> no > >> > >> longer > >> adjacent > >> to > >> the > >> values > >> of > >> element > >> 1. > >> What > >> do you > >> > >> think > >> > >> about > >> > >> that > >> > >> tradeoff? > >> I > >> don't > >> mean > >> to > >> be > >> difficult > >> about > >> this. > >> I'm > >> excited > >> for > >> > >> both > >> > >> the > >> > >> REE > >> > >> and > >> > >> StringView > >> arrays, > >> but > >> this > >> one > >> I'm > >> not > >> so > >> sure > >> about > >> > >> yet. I > >> > >> suppose > >> > >> what I > >> > >> am > >> trying > >> to > >> ask > >> is, > >> if > >> we > >> added > >> this, > >> do > >> we > >> think > >> many > >> > >> Arrow > >> > >> and > >> > >> query > >> > >> engine > >> implementations > >> (for > >> example, > >> DataFusion) > >> will be > >> > >> eager > >> > >> to > >> > >> add > >> > >> full > >> > >> support > >> for > >> the > >> type, > >> including > >> compute > >> kernels? > >> Or are > >> > >> they > >> > >> likely > >> > >> to > >> > >> just > >> > >> convert > >> this > >> type > >> to > >> ListArray > >> at > >> import > >> boundaries? > >> Because > >> if > >> it > >> turns > >> out > >> to > >> be > >> the > >> latter, > >> then > >> we > >> might > >> > >> as > >> > >> well > >> > >> ask > >> > >> Velox > >> > >> to > >> export > >> this > >> type > >> as > >> ListArray > >> and > >> save > >> the > >> rest > >> of the > >> > >> ecosystem > >> > >> some > >> > >> work. > >> Best, > >> Will > >> Jones > >> On > >> Thu, > >> May > >> 11, > >> 2023 > >> at > >> 12:32 PM > >> Felipe > >> Oliveira > >> > >> > >> Carvalho < > >> > >> [email protected]<mailto:[email protected] > >> <mailto:[email protected]>>> > >> wrote: > >> > >> Initial > >> reason > >> for > >> ListView > >> arrays > >> in > >> Arrow > >> is > >> zero-copy > >> > >> > >> compatibility > >> > >> with > >> > >> Velox > >> which > >> uses > >> this > >> format. > >> Velox > >> kernels > >> benefit > >> from > >> being > >> able > >> to > >> append > >> data > >> to > >> > >> the > >> > >> array > >> > >> from > >> > >> different > >> threads > >> without > >> care > >> for > >> strict > >> ordering. > >> > >> > >> Only the > >> > >> offsets > >> > >> array > >> > >> has > >> to > >> be > >> written > >> according > >> to > >> logical > >> order > >> but > >> that > >> is > >> > >> potentially a > >> > >> much > >> > >> smaller > >> buffer > >> than > >> the > >> values > >> buffer. > >> Acero > >> kernels > >> could > >> take > >> advantage > >> of > >> that > >> in > >> the > >> > >> future. > >> > >> In > >> implementing > >> ListViewArray/Type > >> I > >> was > >> able > >> to > >> reuse > >> > >> > >> some > >> > >> C++ > >> > >> templates > >> > >> used > >> for > >> ListArray > >> which > >> can > >> reduce > >> some > >> of > >> the > >> burden > >> > >> > >> on > >> > >> kernel > >> > >> implementations > >> that > >> aim > >> to > >> work > >> with > >> all > >> the > >> types. > >> I’m > >> can > >> fix > >> Acero > >> kernels > >> for > >> working > >> with > >> ListView. > >> > >> > >> This is > >> > >> similar > >> > >> to > >> > >> the > >> > >> work > >> I’ve > >> doing > >> in > >> kernels > >> dealing > >> with > >> run-end > >> encoded > >> > >> > >> arrays. > >> > >> — > >> Felipe > >> On > >> Wed, > >> 26 > >> Apr > >> 2023 > >> at > >> 01:03 > >> Will > >> Jones > >> < > >> > >> [email protected] > >> > >> <mailto:[email protected] > >> <mailto:[email protected]>>> > >> wrote: > >> > >> I > >> suppose > >> one > >> common > >> use > >> case > >> is > >> materializing > >> list > >> > >> > >> columns > >> > >> after > >> > >> some > >> > >> expanding > >> operation > >> like > >> a > >> join > >> or > >> unnest. > >> That's > >> a > >> > >> > >> case > >> > >> where > >> > >> I > >> > >> could > >> > >> imagine > >> a > >> lot > >> of > >> repetition > >> of > >> values. > >> Haven't > >> yet > >> > >> > >> thought > >> > >> of > >> > >> common > >> > >> cases > >> > >> > >> where > >> there > >> is > >> overlap > >> but > >> not > >> full > >> duplication, > >> but > >> am > >> > >> > >> eager > >> > >> to > >> > >> hear > >> > >> any. > >> > >> > >> The > >> dictionary > >> encoding > >> point > >> Raphael > >> makes > >> is > >> > >> > >> interesting, > >> > >> especially > >> > >> given > >> the > >> existence > >> of > >> LargeList > >> and > >> FixedSizeList. > >> For > >> > >> > >> many > >> > >> operations, > >> > >> it > >> > >> might > >> make > >> more > >> sense > >> to > >> just > >> compose > >> those > >> existing > >> > >> > >> types. > >> > >> IIUC > >> the > >> operations > >> that > >> would > >> be > >> unique > >> to > >> the > >> > >> > >> ArrayView > >> > >> are > >> > >> ones > >> > >> altering > >> > >> > >> the > >> shape. > >> One > >> could > >> truncate > >> each > >> array > >> to > >> a > >> certain > >> > >> > >> length > >> > >> cheaply > >> > >> simply > >> > >> > >> by > >> replacing > >> the > >> sizes > >> buffer. > >> Or > >> perhaps > >> there > >> are > >> > >> > >> interesting > >> > >> operations > >> > >> > >> on > >> tensors > >> that > >> would > >> benefit. > >> On > >> Tue, > >> Apr > >> 25, > >> 2023 > >> at > >> 7:47 PM > >> Raphael > >> Taylor-Davies > >> <[email protected]> > >> wrote: > >> > >> > >> Unless > >> I > >> am > >> missing > >> something, > >> I > >> think > >> the > >> selection > >> > >> > >> use-case > >> > >> could > >> > >> be > >> > >> equally > >> well > >> served > >> by > >> a > >> dictionary-encoded > >> > >> > >> BinarArray/ListArray, > >> > >> and > >> > >> would > >> > >> > >> have > >> the > >> benefit > >> of > >> not > >> requiring > >> any > >> modifications > >> > >> > >> to the > >> > >> existing > >> > >> format > >> > >> > >> or > >> kernels. > >> The > >> major > >> additional > >> flexibility > >> of > >> the > >> proposed > >> > >> > >> encoding > >> > >> would > >> > >> be > >> > >> permitting > >> disjoint > >> or > >> overlapping > >> ranges, > >> are > >> these > >> > >> > >> common > >> > >> enough > >> > >> in > >> > >> practice > >> to > >> represent > >> a > >> meaningful > >> bottleneck? > >> On > >> 26 > >> April > >> 2023 > >> 01:40:14 > >> BST, > >> David > >> Li > >> < > >> > >> > >> [email protected] > >> > >> <mailto: <mailto:> > >> > >> [email protected]>> > >> wrote: > >> > >> Is > >> there > >> a > >> need > >> for > >> a > >> 64-bit > >> offsets > >> version > >> the > >> > >> > >> same way > >> > >> we > >> > >> have > >> > >> List > >> > >> and > >> LargeList? > >> > >> > >> And > >> just > >> to > >> be > >> clear, > >> the > >> difference > >> with > >> List > >> is > >> > >> > >> that > >> > >> the > >> > >> lists > >> > >> don't > >> > >> have > >> to > >> be > >> stored > >> in > >> their > >> logical > >> order > >> (or > >> in > >> other > >> > >> > >> words, > >> > >> offsets > >> > >> do > >> > >> not > >> > >> > >> have > >> to > >> be > >> nondecreasing > >> and > >> so > >> we > >> also > >> need > >> sizes)? > >> > >> > >> On > >> Wed, > >> Apr > >> 26, > >> 2023, > >> at > >> 09:37, > >> Weston > >> Pace > >> wrote: > >> > >> > >> For > >> context, > >> there > >> was > >> some > >> discussion > >> on > >> this > >> back > >> > >> > >> in > >> > >> [1]. > >> > >> At > >> > >> that > >> > >> time > >> > >> > >> this > >> was > >> called > >> "sequence > >> view" > >> but > >> I > >> do > >> not > >> like > >> > >> > >> that > >> > >> name. > >> > >> However, > >> > >> > >> array-view > >> array > >> is > >> a > >> little > >> confusing. > >> Given > >> this > >> > >> > >> is > >> > >> similar > >> > >> to > >> > >> list > >> > >> > >> can > >> > >> > >> we > >> go > >> with > >> list-view > >> array? > >> > >> > >> Thanks > >> for > >> the > >> introduction. > >> I'd > >> be > >> interested > >> to > >> > >> > >> hear > >> > >> about > >> > >> the > >> > >> applications > >> Velox > >> has > >> found > >> for > >> these > >> vectors, > >> > >> > >> and in > >> > >> what > >> > >> situations > >> > >> > >> they > >> > >> > >> are > >> useful. > >> This > >> could > >> be > >> contrasted > >> with > >> the > >> > >> > >> current > >> > >> ListArray > >> > >> implementations. > >> > >> > >> I > >> believe > >> one > >> significant > >> benefit > >> is > >> that > >> take > >> (and > >> > >> > >> by > >> > >> proxy, > >> > >> filter) > >> > >> > >> and > >> > >> > >> sort > >> are > >> O(# > >> of > >> items) > >> with > >> the > >> proposed > >> format > >> and > >> > >> > >> O(# > >> > >> of > >> > >> bytes) > >> > >> with > >> > >> > >> the > >> > >> > >> current > >> format. > >> Jorge > >> did > >> some > >> profiling > >> to > >> this > >> > >> > >> effect > >> > >> in > >> > >> [1]. > >> > >> [1] > >> > >> > >> https://lists.apache.org/thread/49qzofswg1r5z7zh39pjvd1m2ggz2kdq< > >> > >> > >> https://lists.apache.org/thread/49qzofswg1r5z7zh39pjvd1m2ggz2kdq> > >> > >> > >> On > >> Tue, > >> Apr > >> 25, > >> 2023 > >> at > >> 3:13 PM > >> Will > >> Jones > >> < > >> > >> > >> [email protected] > >> > >> > >> <mailto:[email protected] > >> <mailto:[email protected]>> > >> > >> > >> wrote: > >> > >> > >> Hi > >> Felipe, > >> Thanks > >> for > >> the > >> introduction. > >> I'd > >> be > >> interested > >> to > >> > >> > >> hear > >> > >> about > >> > >> the > >> > >> applications > >> Velox > >> has > >> found > >> for > >> these > >> vectors, > >> > >> > >> and in > >> > >> what > >> > >> situations > >> > >> > >> they > >> > >> > >> are > >> useful. > >> This > >> could > >> be > >> contrasted > >> with > >> the > >> > >> > >> current > >> > >> ListArray > >> > >> implementations. > >> IIUC > >> it > >> would > >> be > >> fairly > >> cheap > >> to > >> transform > >> a > >> > >> > >> ListArray > >> > >> to > >> > >> an > >> > >> ArrayView, > >> but > >> > >> > >> expensive > >> to > >> go > >> the > >> other > >> way. > >> Best, > >> Will > >> Jones > >> On > >> Tue, > >> Apr > >> 25, > >> 2023 > >> at > >> 3:00 PM > >> Felipe > >> Oliveira > >> > >> > >> Carvalho > >> > >> < > >> > >> [email protected]<mailto:[email protected] > >> <mailto:[email protected]>>> > >> > >> > >> wrote: > >> > >> Hi > >> folks, > >> I > >> would > >> like > >> to > >> start > >> a > >> public > >> discussion > >> on > >> the > >> > >> > >> inclusion > >> > >> of a > >> > >> new > >> > >> array > >> > >> > >> format > >> to > >> Arrow > >> — > >> array-view > >> array. > >> The > >> name > >> is > >> > >> > >> also > >> > >> up > >> > >> for > >> > >> debate. > >> > >> > >> This > >> format > >> is > >> inspired > >> by > >> Velox's > >> ArrayVector > >> > >> > >> format > >> > >> [1]. > >> > >> Logically, > >> > >> > >> this > >> > >> > >> array > >> represents > >> an > >> array > >> of > >> arrays. > >> Each > >> element > >> > >> > >> is > >> > >> an > >> > >> array-view > >> > >> > >> (offset > >> > >> > >> and > >> size > >> pair) > >> that > >> points > >> to > >> a > >> range > >> within > >> a > >> > >> > >> nested > >> > >> "values" > >> > >> array > >> > >> > >> (called > >> "elements" > >> in > >> Velox > >> docs). > >> The > >> nested > >> > >> > >> array > >> > >> can > >> > >> be > >> > >> of > >> > >> any > >> > >> type, > >> > >> > >> which > >> makes > >> this > >> format > >> very > >> flexible > >> and > >> > >> > >> powerful. > >> > >> [image: > >> ../_images/array-vector.png] > >> < > >> > >> > >> https://facebookincubator.github.io/velox/_images/array-vector.png > >> > >> > >> < > >> > >> https://facebookincubator.github.io/velox/_images/array-vector.png > >> > >> I'm > >> currently > >> working > >> on > >> a > >> C++ > >> implementation > >> and > >> > >> > >> plan > >> > >> to > >> > >> work > >> > >> on > >> a > >> > >> Go > >> > >> > >> implementation > >> to > >> fulfill > >> the > >> two-implementations > >> > >> > >> requirement > >> > >> for > >> > >> format > >> > >> > >> changes. > >> The > >> draft > >> design: > >> - > >> 3 > >> buffers: > >> [validity_bitmap, > >> int32 > >> offsets > >> > >> > >> buffer, > >> > >> int32 > >> > >> sizes > >> > >> buffer] > >> > >> > >> - > >> 1 > >> child > >> array: > >> "values" > >> as > >> an > >> array > >> of > >> the > >> type > >> > >> > >> parameter > >> > >> validity_bitmap > >> is > >> used > >> to > >> differentiate > >> between > >> > >> > >> empty > >> > >> array > >> > >> views > >> > >> > >> (sizes[i] > >> == > >> 0) > >> and > >> NULL > >> array > >> views > >> > >> > >> (validity_bitmap[i] > >> > >> == > >> > >> 0). > >> > >> When > >> the > >> validity_bitmap[i] > >> is > >> 0, > >> both > >> sizes > >> and > >> > >> > >> offsets > >> > >> are > >> > >> undefined > >> > >> > >> (as > >> > >> > >> usual), > >> and > >> when > >> sizes[i] > >> == > >> 0, > >> offsets[i] > >> is > >> > >> > >> undefined. 0 > >> > >> is > >> > >> recommended > >> > >> > >> if > >> setting > >> a > >> value > >> is > >> not > >> an > >> issue > >> to > >> the > >> system > >> > >> > >> producing > >> > >> the > >> > >> arrays. > >> > >> > >> offsets > >> buffer > >> is > >> not > >> required > >> to > >> be > >> ordered > >> and > >> > >> > >> views > >> > >> don't > >> > >> have > >> > >> to > >> > >> > >> be > >> > >> > >> disjoint. > >> [1] > >> > >> > >> > https://facebookincubator.github.io/velox/develop/vectors.html#arrayvector > >> > >> > >> < > >> > >> > https://facebookincubator.github.io/velox/develop/vectors.html#arrayvector > >> > >> > >> Thanks, > >> Felipe > >> O. > >> Carvalho > >> > >
{kind=link}