chenhu opened a new issue #1444: URL: https://github.com/apache/incubator-seatunnel/issues/1444
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/incubator-seatunnel/issues?q=is%3Aissue+label%3A%22bug%22) and found no similar issues. ### What happened When i using the jdbc input ,and clickhouse、hdfs、stdout output,the output using the same source_table,out the output result is not the same. ### SeaTunnel Version seatunnel v1.5.3 ### SeaTunnel Config ```conf spark { # You can set spark configuration here # see available properties defined by spark: https://spark.apache.org/docs/latest/configuration.html#available-properties spark.app.name = "violation_interval_ck" spark.executor.instances = 10 spark.executor.cores = 4 spark.executor.memory = "6g" spark.streaming.batchDuration = "10" spark.sql.catalogImplementation = "hive" } input { hdfs { path = "hdfs://hdp1.cdjj.com:8020/user/hdfs/checkpoint/violation/vio_force_new/maxgxsj/" result_table_name = "maxgxsj_tmp" format = "json" } jdbc { driver = "oracle.jdbc.driver.OracleDriver" url = "jdbc:oracle:thin:@10.65.32.60:1521/orcl" table = "(select WFBH,JDSLB,JDSBH,WSJYW,RYFL,JSZH,DABH,FZJG,ZJCX,DSR,ZSXZQH,ZSXXDZ,DH,LXFS,CLFL,HPZL,HPHM,JDCSYR,SYXZ,JTFS,WFSJ,XZQH,DLLX,GLXZDJ,WFDD,LDDM,DDMS,DDJDWZ,WFDZ,WFXW,WFJFS,FKJE,SCZ,BZZ,ZNJ,ZQMJ,JKFS,FXJG,FXJGMC,CLJG,CLJGMC,CFZL,CLSJ,JKBJ,JKRQ,PZBH,JSJQBJ,JLLX,LRR,LRSJ,JBR1,JBR2,SGDJ,CLDXBJ,JDCCLDXBJ,ZDJLBJ,XXLY,XRMS,DKBJ,JMZNJBJ,ZDBJ,JSJG,FSJG,GXSJ,BZ,YWJYW,ZJMC,CCLZRQ,NL,XB,HCBJ,JD,WD,YLZZ1,YLZZ2,YLZZ3,YLZZ4,YLZZ5,YLZZ6,YLZZ7,YLZZ8,CJFS,WFSJ1,WFDD1,LDDM1,DDMS1,JSRXZ,CLYT,XCFW,DZZB from trff_app.vio_force@vehicle where wfsj > to_date('2021-01-01 00:00:00','yyyy-MM-dd hh24:mi:ss') and GXSJ >= sysdate-1.5 )" result_table_name = "tmptable" user = "*****" password = "*****" } } filter { sql { sql = "select * from tmptable where GXSJ > (select max(gxsj) from maxgxsj_tmp)" } convert{ source_field = "WFSJ" new_type= "string" } convert{ source_field = "WFJFS" new_type= "string" } convert{ source_field = "FKJE" new_type= "string" } convert{ source_field = "SCZ" new_type= "string" } convert{ source_field = "BZZ" new_type= "string" } convert{ source_field = "ZNJ" new_type= "string" } convert{ source_field = "CLSJ" new_type= "string" } convert{ source_field = "JKRQ" new_type= "string" } convert{ source_field = "LRSJ" new_type= "string" } convert{ source_field = "GXSJ" new_type= "string" } convert{ source_field = "WFSJ1" new_type= "string" result_table_name = "vio_force" } sql { sql = "select string(max(GXSJ)) as gxsj from vio_force" result_table_name = "max_gxsj" } } output { clickhouse { source_table_name = "vio_force" host = "es1:8123" database = "violation" table = "vio_force_new" username = "******" password = "******" bulk_size = 50000 } hdfs { source_table_name = "max_gxsj" path = "hdfs://hdp1.cdjj.com:8020/user/hdfs/checkpoint/violation/vio_force_new/maxgxsj/" save_mode = "append" format = "json" } stdout{ source_table_name = "max_gxsj" } } ``` ### Running Command ```shell /usr/Waterdrop/bin/start-waterdrop.sh --master yarn --deploy-mode client --config /usr/Waterdrop/config/vio_violation.conf ``` ### Error Exception ```log The first output is clickhouse, the max value of GXSJ column in the batch of the data is difference from the second output hdfs and also difference from the third output stdout. but the dataset of all the output is the same, and the max value of the GXSJ column should be the same. ``` ### Flink or Spark Version spark2.3 ### Java or Scala Version java8 ### Screenshots 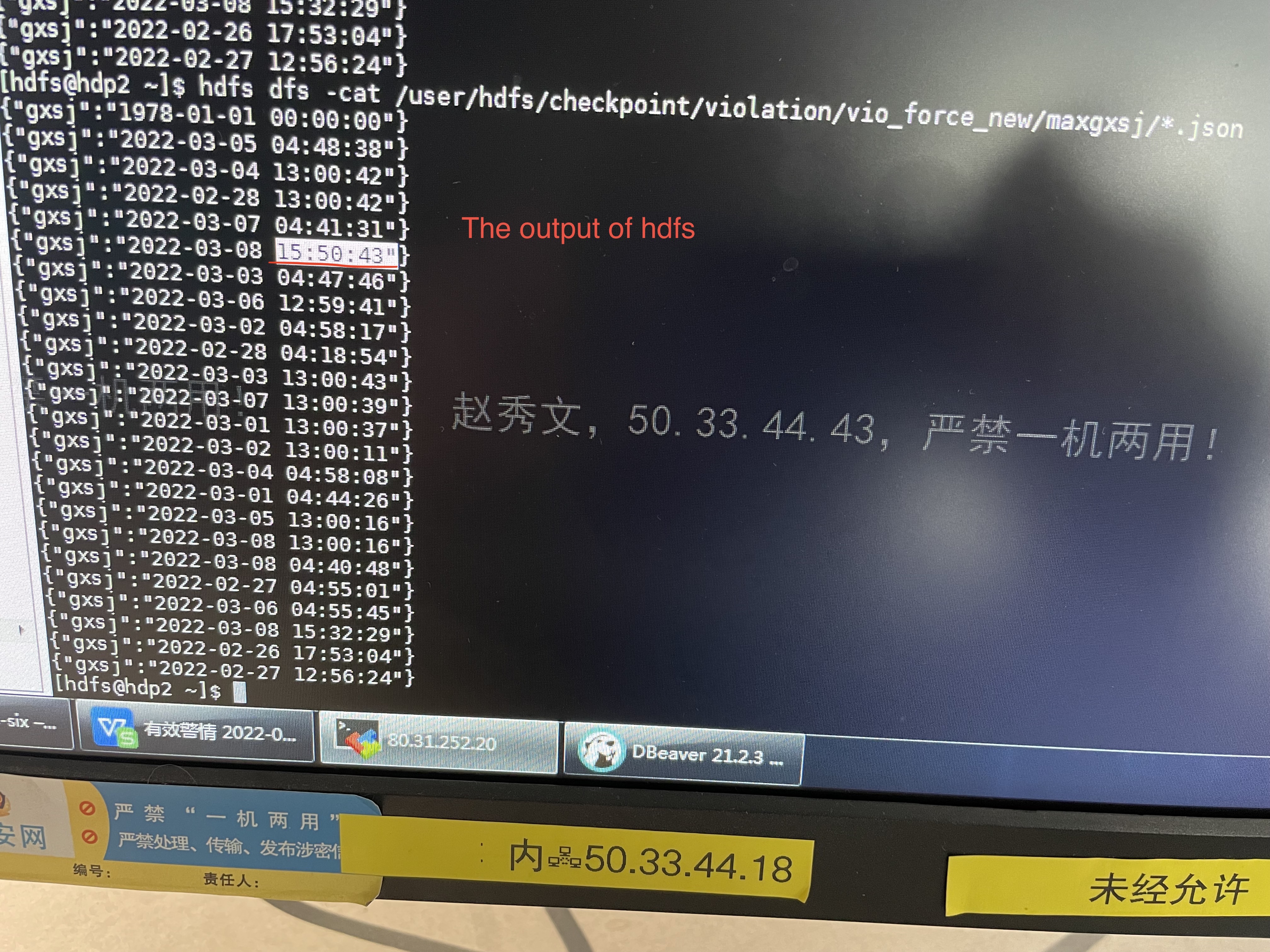 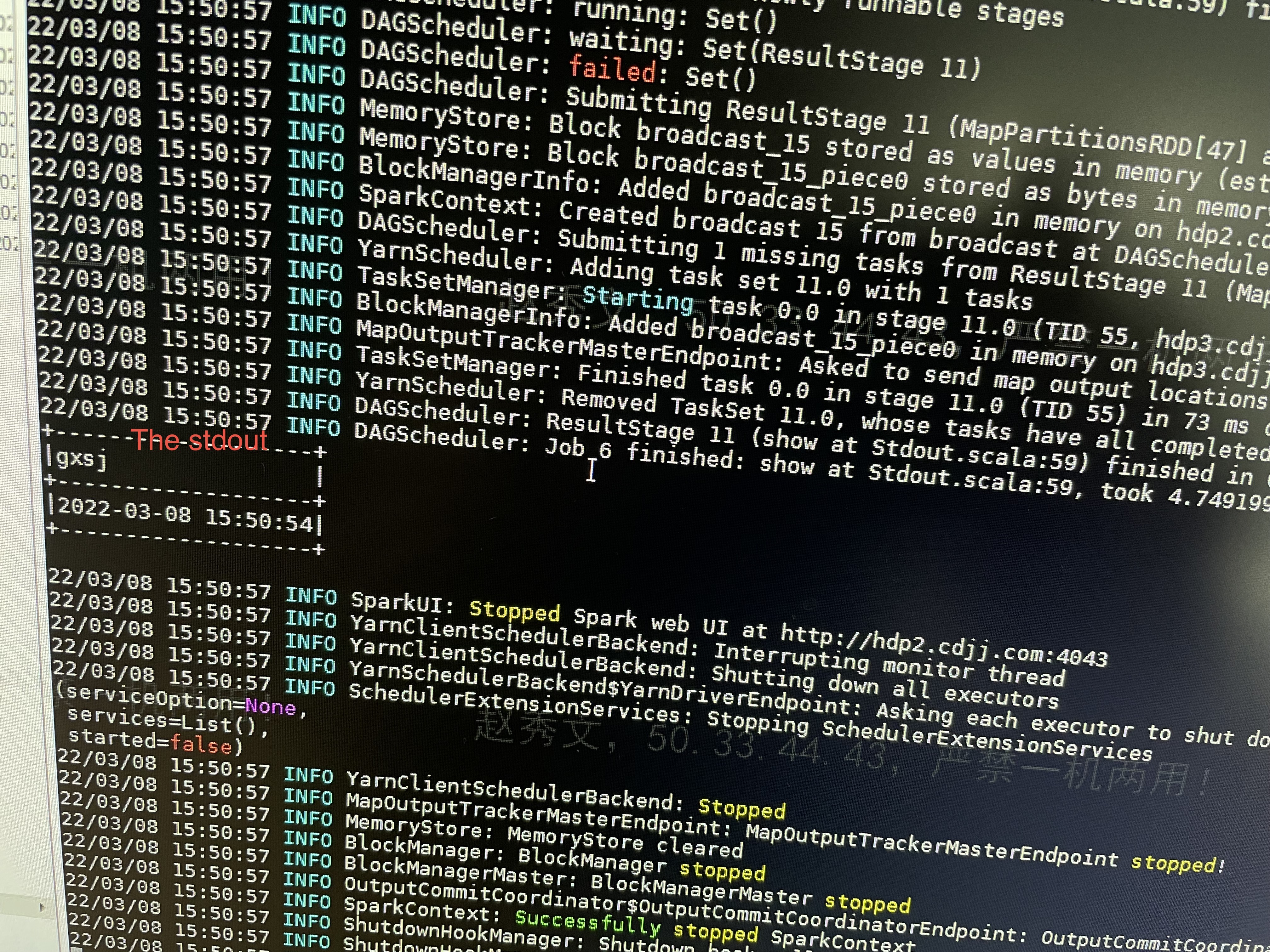 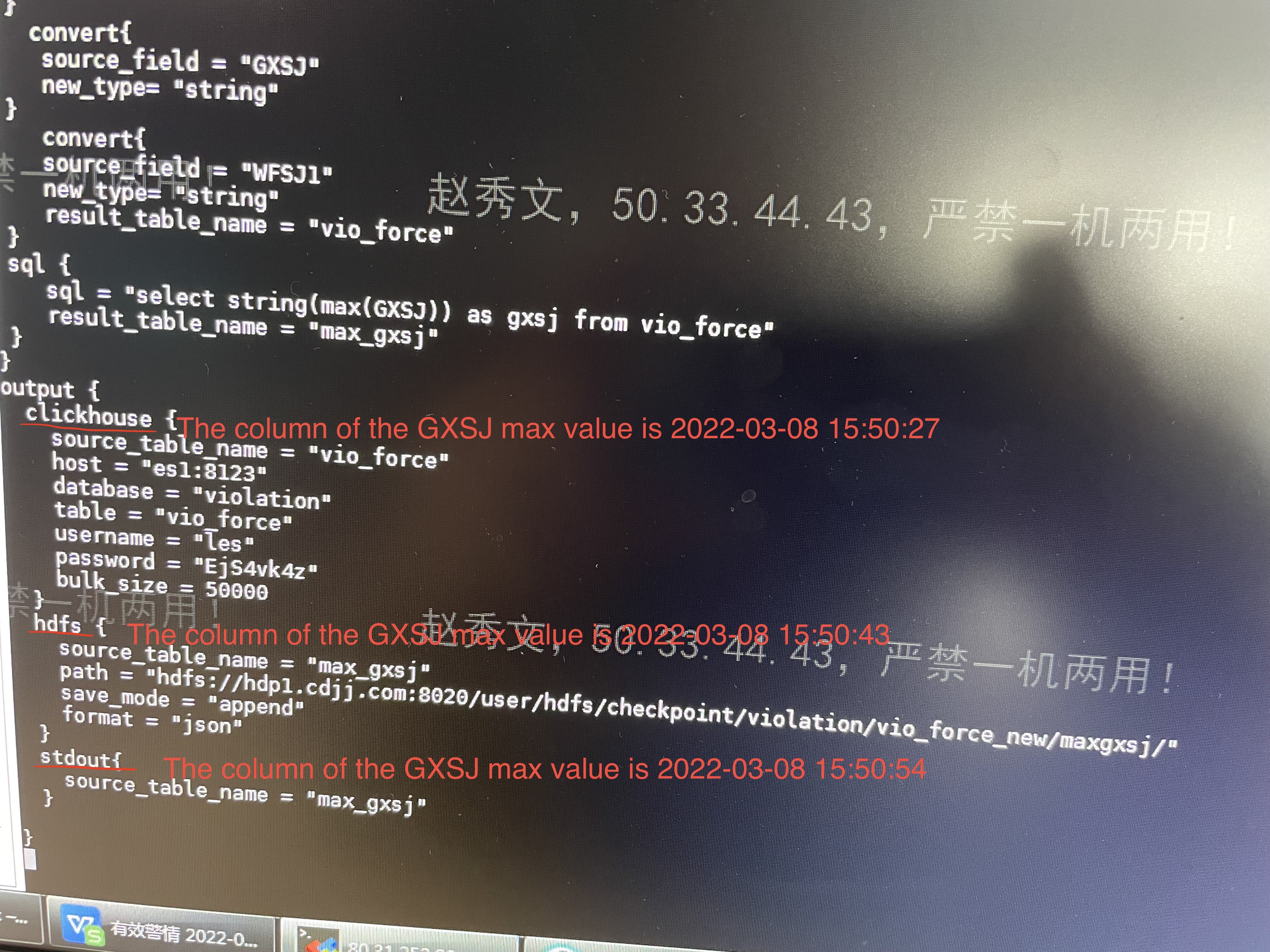  ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}