Lujun-WC opened a new issue, #8391:
URL: https://github.com/apache/hudi/issues/8391
**Describe the problem you faced**
I write a batch of data to a copy-on-write (COW) format Hudi table every 5
minutes, with roughly tens of thousands of records. However, I found that the
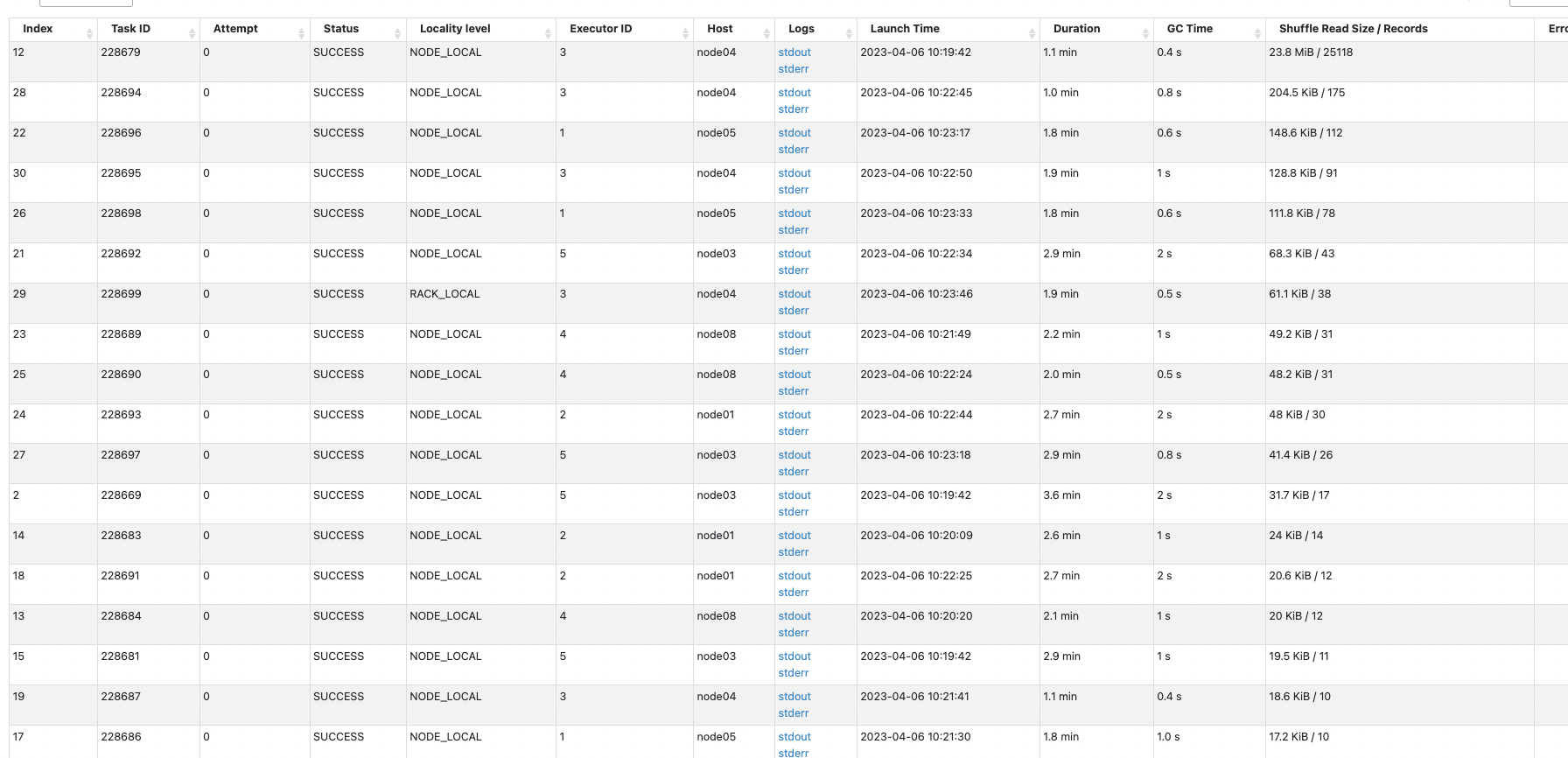
writing process is very slow. From the Spark stage page, I can see that the
specific write task takes 2-3 minutes to process just a dozen records. I don't
understand the reason behind this and don't know how to troubleshoot the cause
of the slow write.
In the data being written, 80% of the data is new, while the remaining 20%
of the data will update the data in the table.
**Environment Description**
* Hudi version : 0.13
* Spark version : 3.31
* Hive version : 3.1.1
* Hadoop version : 3.1.1
* Storage (HDFS/S3/GCS..) : HDFS
* Running on Docker? (yes/no) : no
**Additional context**
spark config:
val spark = SparkSession
.builder()
.config("spark.debug.maxToStringFields", "500")
.config("spark.sql.debug.maxToStringFields", "500")
.config("spark.sql.sources.partitionOverwriteMode", "dynamic")
.config("hive.exec.dynamic.partition", true)
.config("hive.exec.dynamic.partition.mode", "nonstrict")
.enableHiveSupport()
.getOrCreate()
hoodie.properties
hoodie.table.timeline.timezone=LOCAL
hoodie.table.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator
hoodie.table.precombine.field=sort_key
hoodie.table.version=5
hoodie.database.name=
hoodie.datasource.write.hive_style_partitioning=true
hoodie.table.checksum=2356712026
hoodie.partition.metafile.use.base.format=false
hoodie.table.cdc.enabled=false
hoodie.archivelog.folder=archived
hoodie.table.name=dwd_foo_6_order_real_batch
hoodie.populate.meta.fields=true
hoodie.table.type=COPY_ON_WRITE
hoodie.datasource.write.partitionpath.urlencode=false
hoodie.table.base.file.format=PARQUET
hoodie.datasource.write.drop.partition.columns=false
hoodie.table.metadata.partitions=files
hoodie.timeline.layout.version=1
hoodie.table.recordkey.fields=order_id
hoodie.table.partition.fields=cdt,data_source
<img width="1336" alt="Snipaste_2023-04-06_10-32-06"
src="https://user-images.githubusercontent.com/13329592/230260265-6e8df090-696c-4fb4-b1ef-aa2a982a03a1.png";>
<img width="522" alt="Snipaste_2023-04-06_10-32-22"
src="https://user-images.githubusercontent.com/13329592/230260287-cb23f978-3bde-495b-842a-45cd795a04e1.png";>
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}